Introduction to the Guix Data Service, the missing blog post
The Guix Data Service processes, stores and provides data about Guix over time, at least that is what the README says. It's been around since the start of 2019, and while there have been plenty of long emails to the guix-devel mailing list about it and a blog post about a related Outreachy project, this is the first blog post covering what it is and why it exists.
Why?
The initial motivation came from trying to automate aspects of reviewing patches for Guix. If you have some patches for Guix, one aspect of review might be to apply the patches and then build the affected packages. How do you know what packages are affected though?
You could try and guess based on the content of the patches, and this
could work some of the time, but because Guix packages relate to one
another, changing one package may cause dependent packages to change.
Additionally, there are places in Guix where small changes could
affect a large number of packages, build systems for example. The
guix refresh -l command is really helpful when testing packages
locally, but it can in some cases miss some packages that are effected
by changes, as it only explores the package graph.
The approach taken to working out what packages are affected by a set of patches, was to record information about all the packages in the "base" revision of Guix, prior to applying the patches, and also record information about the "target" revision generated from applying the patches. With all that information about the two revisions, you can then compare the data to determine what's changed. This goes beyond finding out what packages are affected, and includes things like looking at changes to lint warnings, channel news entries, and more.
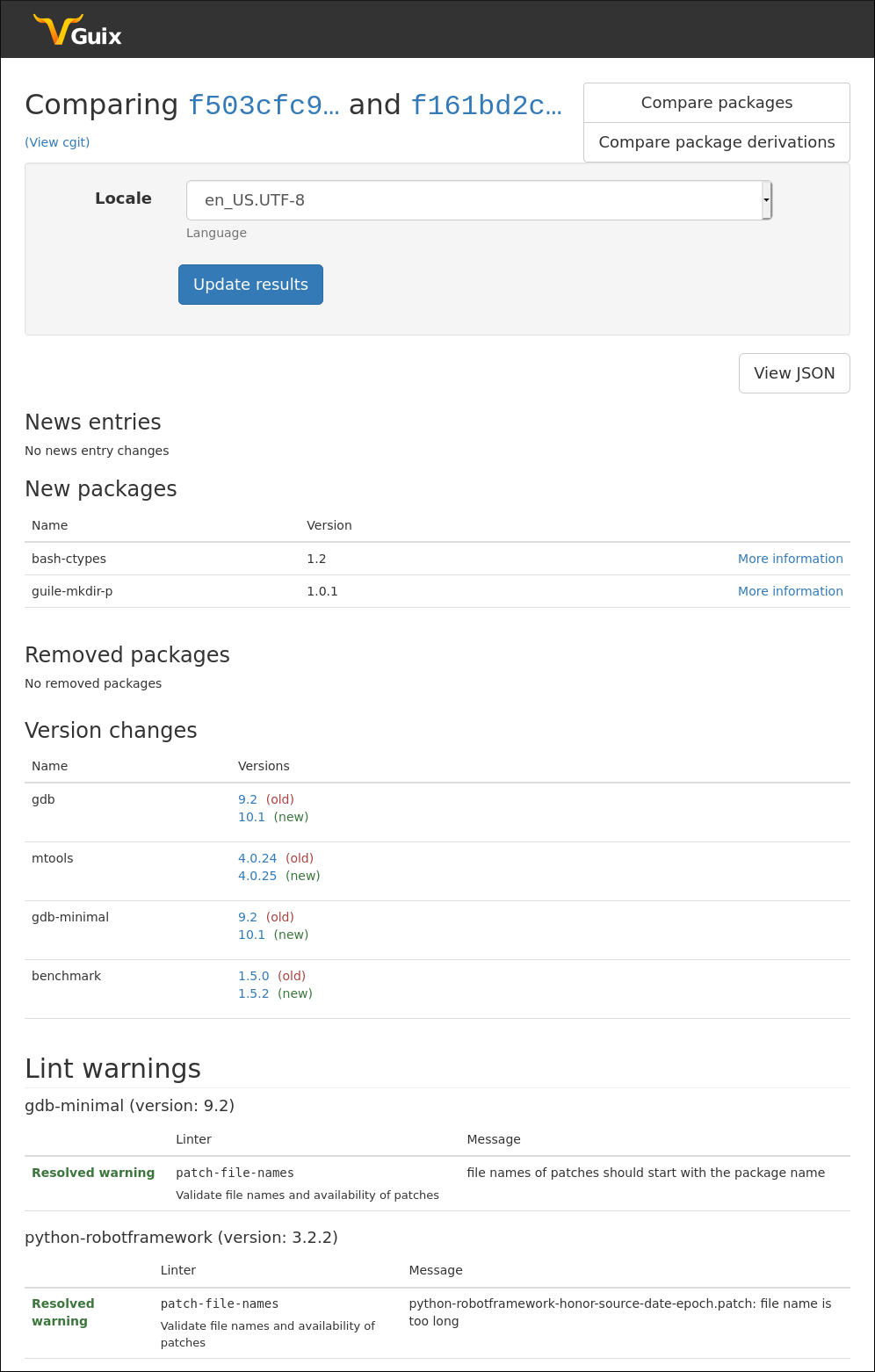
This approach of storing information about revisions has applications beyond reviewing patches, which is another reason why this approach was taken. While the Guix Data Service doesn't bring new knowledge to the world, it can make information that is out there more accessible, and that improved accessibility is a feature.
Applications
Say you want to know when the previous version of a package was available, and what that version was. You could look through the Git repository history, or inspect previous revisions to find out, but because the Guix Data Service can store the available package names and versions in a range of revisions, it can provide this information more quickly and with less effort.
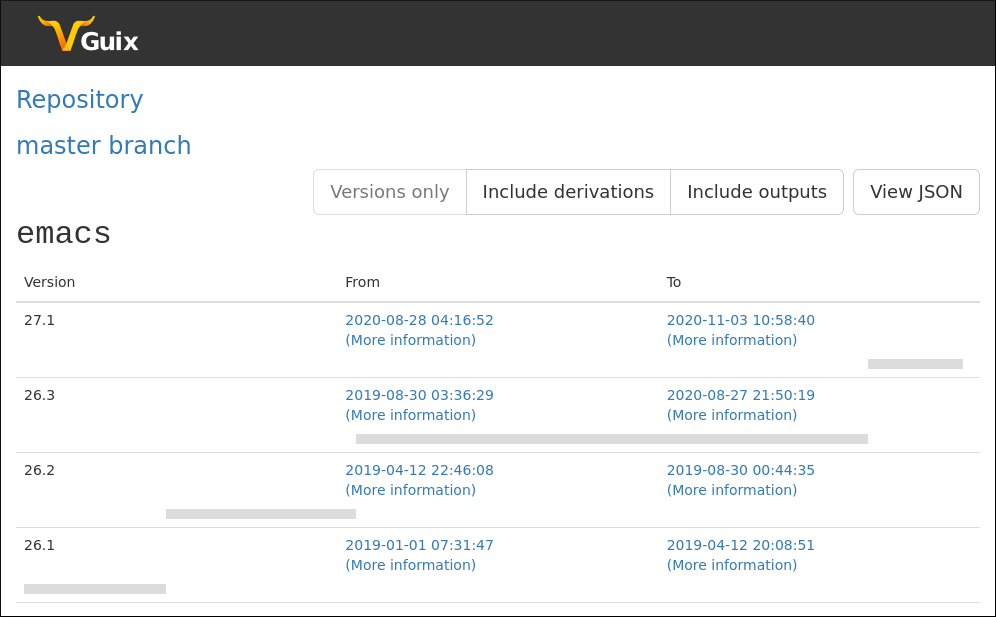
Now, questions about package versions is something a user of Guix might have. However, so far I haven't seen the Guix Data Service as something that users of Guix should necessarily use or be aware of. Instead, I think it has a place to provide information to enable things that users of Guix would directly use.
There are a few applications of data from the Guix Data Service in varying states of development. I've been attempting to automate parts of a weekly news publication about Guix through using the Guix Data Service, I've also been writing a service for building derivations, which I've been using in conjunction with the Guix Data Service to provide substitutes. As part of an Outreachy internship on improving internationalisation support in the Guix Data Service, Danjela worked on creating a package search page for the Guix website, which wrapped the package search functionality in the Guix Data Service.

While I'm cautious about having the Guix Data Service attempt to address individual user needs, there are some applications where it alone is sufficient. I've been using the Guix Data Service to gather up data about which packages in Guix don't build reproducibly. Hopefully the Guix Data Service is well positioned to help with technical questions like this.
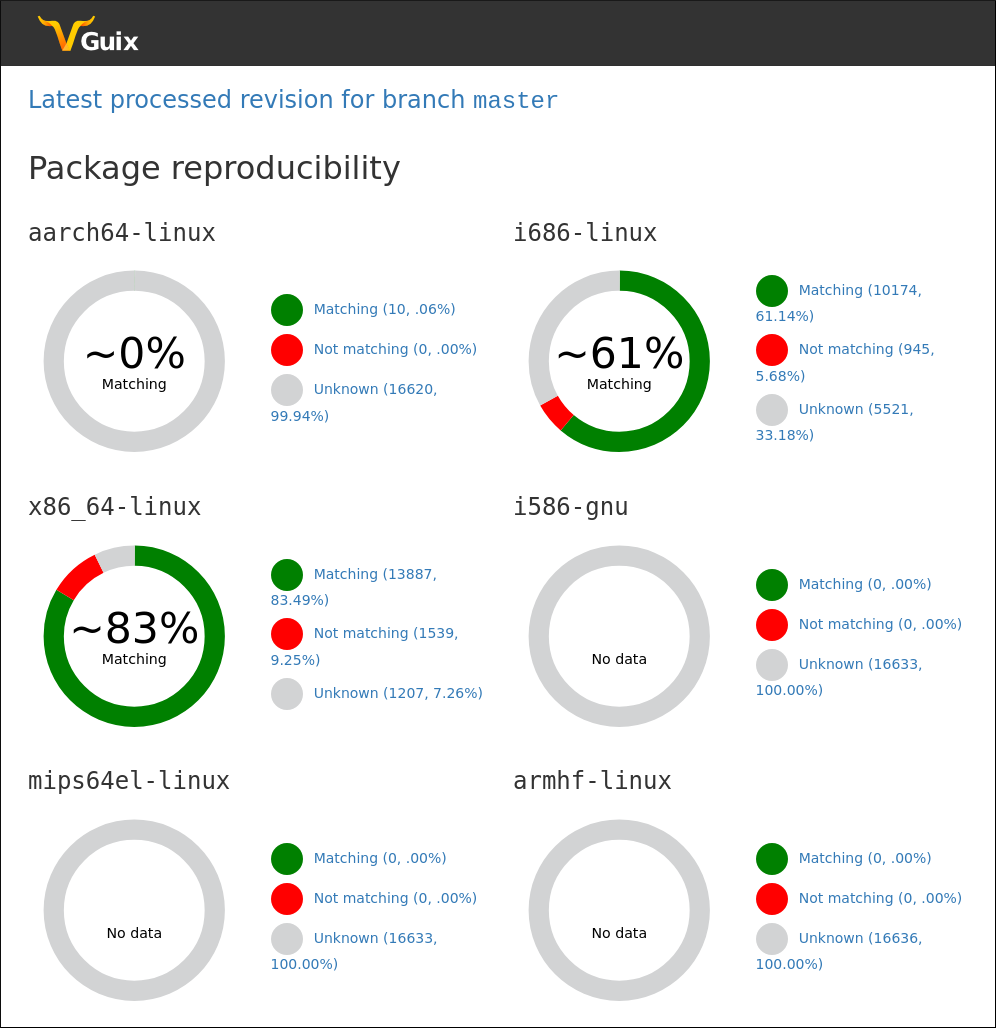
Architecture
The Guix Data Service is written in Guile, and uses PostgreSQL for the database. There's plenty of SQL queries in the code, including some quite long ones.
There are several scripts which act as entry points to different parts of the Guile codebase:
guix-data-service- Provides the web interface
guix-data-service-process-jobs- Polls the database for new jobs, and forks
guix-data-service-process-job
- Polls the database for new jobs, and forks
guix-data-service-process-job- Processes an individual job, loading data for a single revision
guix-data-service-process-branch-updated-emailProcesses an email to find out about new revisions
There's also other scripts which perform a range of functions, like backing up the database, generating a minimal database which is hopefully small in size and querying build/substitute servers for information.
When running on a Guix system, there's a service to help with deployment.
Getting information in
Rather than polling the Git repository to find out about new revisions, the methodology used so far has been to receive emails. In the case of the main Guix Git repository, this can work as follows:
- New commits are pushed to the Guix Git repository on Savannah
- A post-receive hook sends an email about the branch that's been updated, plus emails about each commit
- A dedicated email account is used to subscribe to guix-commits, and this receives the emails
getmailis running as a service on the machine running the Guix Data Service, it receives the emails and callsguix-data-service-process-branch-updated-emailpassing the contents in on stdin- The script reads the email and inserts the relevant data in about the branch that was updated, the time it was updated, and also inserts a new job, representing the new revision to be processed
Compared to polling the Git repository, this approach has a few advantages:
- The time the email was sent is a good proxy to when the branch was updated
- Receiving emails promptly, having
getmailuse IDLE for example helps with learning of changes quickly - The email account provides some reliability, so messages aren't missed if the Guix Data Serivce is down, they'll just be processed later
- The mbox files for the guix-commits mailing list can be processed to provide data for past revision, in years when the Guix Data Service wasn't running for example
When the guix-data-service-process-job script runs, it goes through
a long process to extract information about that revision of Guix, and
store it in the database.
The first part of this is to actually fetch and build the relevant
revision. The Guix Data Service uses channels
and inferiors, the same code used by guix pull and guix time-machine for communication with another revision
of Guix. It's through the inferior REPL that information from the
target revision is extracted.
In addition to receiving information about new revisions, the Guix Data Service can accept POST requests to receive information about builds. There's some support in Cuirass and the Guix Build Coordinator to send these requests.
Storing all that information
Following on from one of the initial motivations for the Guix Data Service, comparing two revisions to determine which packages have changed, the schema for the database is organised to facilitate fast comparisons between two arbitrary revisions. The compromise here is the storage space taken up.
Similar to version control systems, an alternative schema would have been to store the differences between revisions in a linked list or tree. This would avoid storing lots of information that generally doesn't often change between subsequent revisions, but at the expense of making both determining the entire state of individual revisions and comparing arbitrary revisions more complex and costly.
Even though all the information about each revision is associated with
that revision, there is some indirection, and deduplication involved.
For example, each revision is associated against entries in the
package_derivations table, which represents a package plus
derivation for a specific system and target. If this information
doesn't differ between two revisions, they'll just reference the same
entries in this table.
Making information available
Currently, the Guix Data Service provides a web interface. The HTML
pages and forms are designed to help potential users of the Guix Data
Service find and explore the available data. When using the Guix Data
Service, you'd probably want a more machine readable form for the
data, rather than HTML, and at the moment that's JSON. You should be
able to request JSON either through the HTTP Accept header, or by
using the .json extension on the URL path.
Deployments
There's not just one deployment of the Guix Data Service, currently I know of two. There's data.guix.gnu.org which just tracks the master branch of Guix, and has data going back to roughly the start of 2019 (with some gaps). There's also data.guix-patches.cbaines.net which isn't limited to just the master branch, and has additional branches constructed from patches that are submitted, but doesn't have much historical data.
Looking forward
There's still lots of areas where the Guix Data Service can be improved.
It would be convenient if getting data in to the Guix Data Service was faster, currently there's quite a delay between the Guix Data Service finding out about a new revision, and it completing processing it.
The processing could also be improved, there's some notable current omissions like the package graph (inputs, propagated-inputs and native-inputs) as well as package replacements (grafts). It would also be interesting to see if the Guix Data Service could be generalised to process other channels, instead or in addition to the main Guix channel.
In the future, I'd like to make the data available in formats other than JSON, like RDF. I'd also like for it to be possible to watch/subscribe to particular things that the Guix Data Service knows about, the Guix Data Service would then notify you via some means that there's be a change. This could enable all sorts of applications to respond to changes connected to Guix.
Additional reading
To provide some information, and to help get my own thoughts in order, I sent out semi-regular emails about the Guix Data Service over the last two years, I've linked to most of these below:
- 2020/06/03 - Build reproducibility metrics
- 2020/05/07 - April update on data.guix.gnu.org (Guix Data Service)
- 2020/03/30 - Patchwork + the Guix Data Service for assisting with patch review
- 2020/03/29 - March update on data.guix.gnu.org (Guix Data Service)
- 2020/02/17 - February update on data.guix.gnu.org and the Guix Data Service
- 2020/01/05 - Another update on the Guix Data Service
- 2019/09/30 - Anyone interested in getting involved with the Guix Data Service?
- 2019/09/08 - Guix Data Service - September update
- 2019/05/17 - More progress with the Guix Data Service
- 2019/05/06 - Linting, and how to get the information in to the Guix Data Serivce
- 2019/04/04 - Progress with the Guix Data Service
- 2019/02/08 - Tracking and inspecting how Guix changes over time
About GNU Guix
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, and AArch64 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Unless otherwise stated, blog posts on this site are copyrighted by their respective authors and published under the terms of the CC-BY-SA 4.0 license and those of the GNU Free Documentation License (version 1.3 or later, with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts).