Reproducible computations with Guix
This post is about reproducible computations, so let's start with a computation. A short, though rather uninteresting, C program is a good starting point. It computes π in three different ways:
#include <math.h>
#include <stdio.h>
int main()
{
printf( "M_PI : %.10lf\n", M_PI);
printf( "4 * atan(1.) : %.10lf\n", 4.*atan(1.));
printf( "Leibniz' formula (four terms): %.10lf\n", 4.*(1.-1./3.+1./5.-1./7.));
return 0;
}This program uses no random element, such as a random number generator or parallelism. It's strictly deterministic. It is reasonable to expect it to produce exactly the same output, on any computer and at any point in time. And yet, many programs whose results should be perfectly reproducible are in fact not. Programs using floating-point arithmetic, such as this short example, are particularly prone to seemingly inexplicable variations.
My goal is to explain why deterministic programs often fail to be reproducible, and what it takes to fix this. The short answer to that question is "use Guix", but even though Guix provides excellent support for reproducibility, you still have to use it correctly, and that requires some understanding of what's going on. The explanation I will give is rather detailed, to the point of discussing parts of the Guile API of Guix. You should be able to follow the reasoning without knowing Guile though, you will just have to believe me that the scripts I will show do what I claim they do. And in the end, I will provide a ready-to-run Guile script that will let you explore package dependencies right from the shell.
Dependencies: what it takes to run a program
One keyword in discussions of reproducibility is "dependencies". I will revisit the exact meaning of this term later, but to get started, I will define it loosely as "any software package required to run a program". Running the π computation shown above is normally done using something like
gcc pi.c -o pi
./piC programmers know that gcc is a C compiler, so that's one obvious
dependency for running our little program. But is a C compiler enough?
That question is surprisingly difficult to answer in practice. Your
computer is loaded with tons of software (otherwise it wouldn't be very
useful), and you don't really know what happens behind the scenes when
you run gcc or pi.
Containers are good
A major element of reproducibility support in Guix is the possibility to run programs in well-defined environments that contain exactly the software packages you request, and no more. So if your program runs in an environment that contains only a C compiler, you can be sure it has no other dependencies. Let's create such an environment:
guix environment --container --ad-hoc gcc-toolchainThe option --container ensures the best possible isolation from the
standard environment that your system installation and user account
provide for day-to-day work. This environment contains nothing but a C
compiler and a shell (which you need to type in commands), and has
access to no other files than those in the current directory.
If the term "container" makes you think of Docker, note that this is
something different. Note also that the option --container requires
support from the Linux kernel, which may not be present on your system,
or may be disabled by default. Finally, note that by default, a
containerized environment has no network access, which may be a problem.
If for whatever reason you cannot use --container, use --pure
instead. This yields a less isolated environment, but it is usually good
enough. For a more detailed discussion of these options, see the Guix
manual.
The above command leaves me in a shell inside my environment, where I can now compile and run my little program:
gcc pi.c -o pi
./piM_PI : 3.1415926536
4 * atan(1.) : 3.1415926536
Leibniz' formula (four terms): 2.8952380952It works! So now I can be sure that my program has a single dependency:
the Guix package gcc-toolchain. I'll leave that special-environment shell
by typing Ctrl-D, as otherwise the following examples won't work.
Perfectionists who want to exclude the possibility that my program requires a shell could run each step in a separate container:
guix environment --container --ad-hoc gcc-toolchain -- gcc pi.c -o pi
guix environment --container --ad-hoc gcc-toolchain -- ./piM_PI : 3.1415926536
4 * atan(1.) : 3.1415926536
Leibniz' formula (four terms): 2.8952380952Welcome to dependency hell!
Now that we know that our only dependency is gcc-toolchain, let's
look at it in more detail:
guix show gcc-toolchainname: gcc-toolchain
version: 9.2.0
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@9.2.0 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 8.3.0
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@8.3.0 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 7.4.0
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@7.4.0 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 6.5.0
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@6.5.0 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 5.5.0
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@5.5.0 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 4.9.4
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@4.9.4 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
name: gcc-toolchain
version: 4.8.5
outputs: out debug static
systems: x86_64-linux i686-linux
dependencies: binutils@2.32 gcc@4.8.5 glibc@2.29 ld-wrapper@0
location: gnu/packages/commencement.scm:2532:4
homepage: https://gcc.gnu.org/
license: GPL 3+
synopsis: Complete GCC tool chain for C/C++ development
description: This package provides a complete GCC tool chain for C/C++
+ development to be installed in user profiles. This includes GCC, as well as
+ libc (headers an d binaries, plus debugging symbols in the `debug' output),
+ and Binutils.
Guix actually knows about several versions of this toolchain. We didn't ask for a specific one, so what we got is the first one in this list, which is the one with the highest version number. Let's check that this is true:
guix environment --container --ad-hoc gcc-toolchain -- gcc --versiongcc (GCC) 9.2.0
Copyright (C) 2019 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
The output of guix show contains a line about dependencies. These are
the dependencies of our dependency, and you may already have guessed
that they will have dependencies as well. That's why reproducibility is
such a difficult job in practice! The dependencies of
gcc-toolchain@9.2.0 are:
guix show gcc-toolchain@9.2.0 | recsel -P dependenciesbinutils@2.32 gcc@9.2.0 glibc@2.29 ld-wrapper@0To dig deeper, we can try feeding these dependencies to guix show, one
by one, in order to learn more about them:
guix show binutils@2.32name: binutils
version: 2.32
outputs: out
systems: x86_64-linux i686-linux
dependencies:
location: gnu/packages/base.scm:415:2
homepage: https://www.gnu.org/software/binutils/
license: GPL 3+
synopsis: Binary utilities: bfd gas gprof ld
description: GNU Binutils is a collection of tools for working with binary
+ files. Perhaps the most notable are "ld", a linker, and "as", an assembler.
+ Other tools include programs to display binary profiling information, list the
+ strings in a binary file, and utilities for working with archives. The "bfd"
+ library for working with executable and object formats is also included.
guix show gcc@9.2.0guix show: error: gcc@9.2.0: package not foundThis looks a bit surprising. What's happening here is that gcc is
defined as a hidden package in Guix. The package is there, but it is
hidden from package queries. There is a good reason for this: gcc on
its own is rather useless, you need gcc-toolchain to actually use the
compiler. But if both gcc and gcc-toolchain showed up in a search,
that would be more confusing than helpful for most users. Hiding the
package is a way of saying "for experts only".
Let's take this as a sign that it's time to move on to the next level of Guix hacking: Guile scripts. Guile, an implementation of the Scheme language, is Guix' native language, so using Guile scripts, you get access to everything there is to know about Guix and its packages.
A note in passing: the emacs-guix package provides an intermediate level of Guix exploration for Emacs users. It lets you look at hidden packages, for example. But much of what I will show in the following really requires Guile scripts. Another nice tool for package exploration is guix graph, which creates a diagram showing dependency relations between packages. Unfortunately that diagram is legible only for a relatively small number of dependencies, and as we will see later, most packages end up having lots of them.
Anatomy of a Guix package
From the user's point of view, a package is a piece of software with a
name and a version number that can be installed using guix install.
The packager's point of view is quite a bit different. In fact, what
users consider a package is more precisely called the package's
output in Guix jargon. The package is a recipe for creating this
output.
To see how all these concepts fit together, let's look at an example of
a package definition: xmag. I have chosen this package not because I
care much about it, but because its definition is short while showcasing
all the features I want to explain. You can access it most easily by
typing guix edit xmag. Here is what you will see:
(package
(name "xmag")
(version "1.0.6")
(source
(origin
(method url-fetch)
(uri (string-append
"mirror://xorg/individual/app/" name "-" version ".tar.gz"))
(sha256
(base32
"19bsg5ykal458d52v0rvdx49v54vwxwqg8q36fdcsv9p2j8yri87"))))
(build-system gnu-build-system)
(arguments
`(#:configure-flags
(list (string-append "--with-appdefaultdir="
%output ,%app-defaults-dir))))
(inputs
`(("libxaw" ,libxaw)))
(native-inputs
`(("pkg-config" ,pkg-config)))
(home-page "https://www.x.org/wiki/")
(synopsis "Display or capture a magnified part of a X11 screen")
(description "Xmag displays and captures a magnified snapshot of a portion
of an X11 screen.")
(license license:x11))The package
definition
starts with the name and version information you expected. Next comes
source, which says how to obtain the source code and from where. It
also provides a hash that allows to check the integrity of the
downloaded files. The next four items, build-system, arguments,
inputs, and native-inputs supply the information required for
building the package, which is what creates its outputs. The remaining
items are documentation for human consumption, important for other
reasons but not for reproducibility, so I won't say any more about
them. (See this packaging
tutorial
if you want to define your own package.)
The example package definition has native-inputs in addition to
"plain" inputs. There's a third variant, propagated-inputs, but
xmag doesn't have any. The differences between these variants don't
matter for my topic, so I will just refer to "inputs" from now on.
Another omission I will make is the possibility to define several
outputs for a package. This is done for particularly big packages, in
order to reduce the footprint of installations, but for the purposes of
reproducibility, it's OK to treat all outputs of a package as a single
unit.
The following figure illustrates how the various pieces of information
from a package are used in the build process (done explicitly by
guix build, or implicitly when installing or otherwise using a
package): 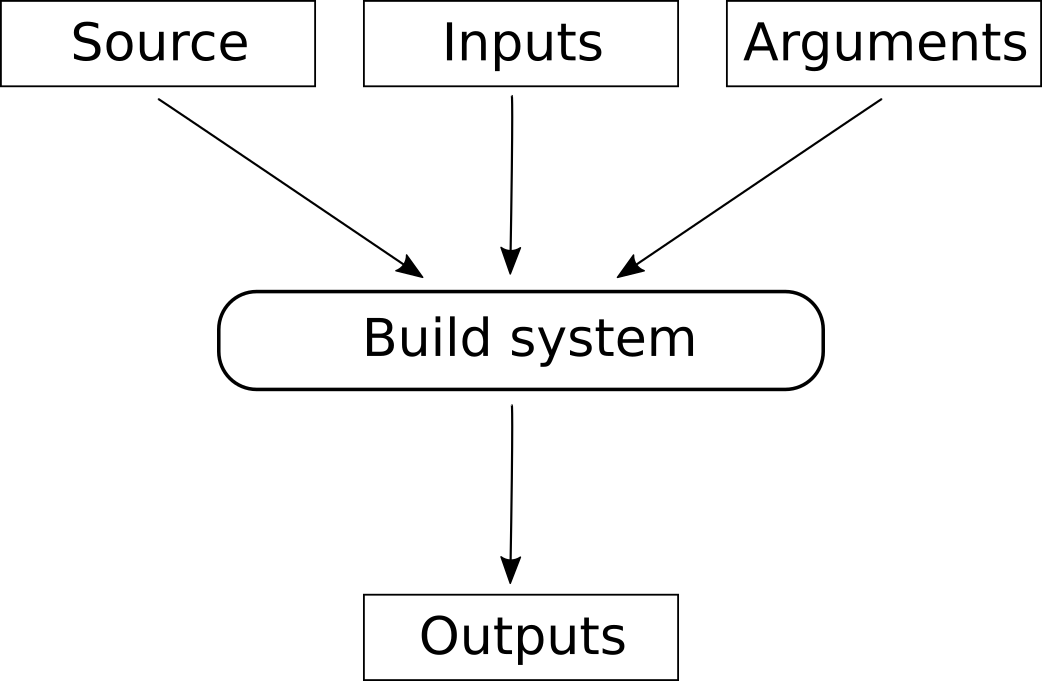
It may help to translate the Guix jargon to the vocabulary of C programming:
| Guix package | C program |
|--------------+------------------|
| source code | source code |
| inputs | libraries |
| arguments | compiler options |
| build system | compiler |
| output | executable |Building a package can be considered a generalization of compiling a
program. We could in fact create a "GCC build system" for Guix that
would simply run gcc. However, such a build system would be of little
practical use, since most real-life software consists of more than just
one C source code file, and requires additional pre- or post-processing
steps. The gnu-build-system used in the example is based on tools such
as make and autoconf, in addition to gcc.
Package exploration in Guile
Guile uses a record type called
<package>
to represent packages, which is defined in module (guix packages).
There is also a module
(gnu packages),
which contains the actual package definitions - be careful not to
confuse the two (as I always do). Here is a simple Guile script that
shows some package information, much like the guix show command that I
used earlier:
(use-modules (guix packages)
(gnu packages))
(define gcc-toolchain
(specification->package "gcc-toolchain"))
(format #t "Name : ~a\n" (package-name gcc-toolchain))
(format #t "Version: ~a\n" (package-version gcc-toolchain))
(format #t "Inputs : ~a\n" (package-direct-inputs gcc-toolchain))Name : gcc-toolchain
Version: 9.2.0
Inputs : ((gcc #<package gcc@9.2.0 gnu/packages/gcc.scm:524 7fc2d76af160>) (ld-wrapper #<package ld-wrapper@0 gnu/packages/base.scm:505 7fc2d306f580>) (binutils #<package binutils@2.32 gnu/packages/commencement.scm:2187 7fc2d306fdc0>) (libc #<package glibc@2.29 gnu/packages/commencement.scm:2145 7fc2d306fe70>) (libc-debug #<package glibc@2.29 gnu/packages/commencement.scm:2145 7fc2d306fe70> debug) (libc-static #<package glibc@2.29 gnu/packages/commencement.scm:2145 7fc2d306fe70> static))This script first calls specification->package to look up the package
using the same rules as the guix command line interface: pick the
latest available version if none is explicitly requested. Then it
extracts various information about the package. Note that
package-direct-inputs returns the combination of package-inputs,
package-native-inputs, and package-propagated-inputs. As I said
above, I don't care about the distinction here.
The inputs are not shown in a particularly nice form, so let's write two Guile functions to improve it:
(use-modules (guix packages)
(gnu packages)
(ice-9 match))
(define (package->specification package)
(format #f "~a@~a"
(package-name package)
(package-version package)))
(define (input->specification input)
(match input
((label (? package? package) . _)
(package->specification package))
(other-item
(format #f "~a" other-item))))
(define gcc-toolchain
(specification->package "gcc-toolchain"))
(format #t "Package: ~a\n"
(package->specification gcc-toolchain))
(format #t "Inputs : ~a\n"
(map input->specification (package-direct-inputs gcc-toolchain)))Package: gcc-toolchain@9.2.0
Inputs : (gcc@9.2.0 ld-wrapper@0 binutils@2.32 glibc@2.29 glibc@2.29 glibc@2.29)That looks much better. As you can see from the code, a list of inputs
is a bit more than a list of packages. It is in fact a list of labelled
package outputs. That also explains why we see glibc three times in
the input list: glibc defines three distinct outputs, all of which are
used in gcc-toolchain. For reproducibility, all we care about is the
package references. Later on, we will deal with much longer input lists,
so as a final cleanup step, let's show only unique package references
from the list of inputs:
(use-modules (guix packages)
(gnu packages)
(srfi srfi-1)
(ice-9 match))
(define (package->specification package)
(format #f "~a@~a"
(package-name package)
(package-version package)))
(define (input->specification input)
(match input
((label (? package? package) . _)
(package->specification package))
(other-item
(format #f "~a" other-item))))
(define (unique-inputs inputs)
(delete-duplicates
(map input->specification inputs)))
(define gcc-toolchain
(specification->package "gcc-toolchain"))
(format #t "Package: ~a\n"
(package->specification gcc-toolchain))
(format #t "Inputs : ~a\n"
(unique-inputs (package-direct-inputs gcc-toolchain)))Package: gcc-toolchain@9.2.0
Inputs : (gcc@9.2.0 ld-wrapper@0 binutils@2.32 glibc@2.29)Dependencies
You may have noticed the absence of the term "dependency" from the last two sections. There is a good reason for that: the term is used in somewhat different meanings, and that can create confusion. Guix jargon therefore avoids it.
The figure above shows three kinds of input to the build system: source,
inputs, and arguments. These categories reflect the packagers' point of
view: source is what the authors of the software supply, inputs are
other packages, and arguments is what the packagers themselves add to
the build procedure. It is important to understand that from a purely
technical point of view, there is no fundamental difference between the
three categories. You could, for example, define a package that contains
C source code in the build system arguments, but leaves source
empty. This would be inconvenient, and confusing for others, so I don't
recommend you actually do this. The three categories are important, but
for humans, not for computers. In fact, even the build system is not
fundamentally distinct from its inputs. You could define a
special-purpose build system for one package, and put all the source
code in there. At the level of the CPU and the computer's memory, a
build process (as in fact any computation) looks like
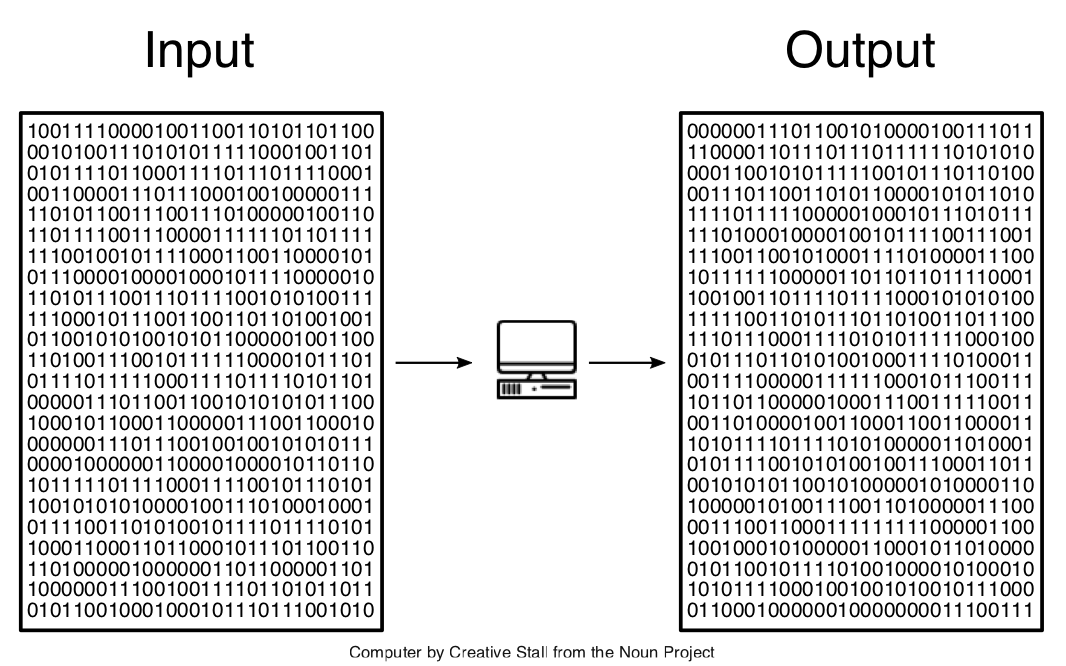 It is human interpretation that decomposes this
into
It is human interpretation that decomposes this
into 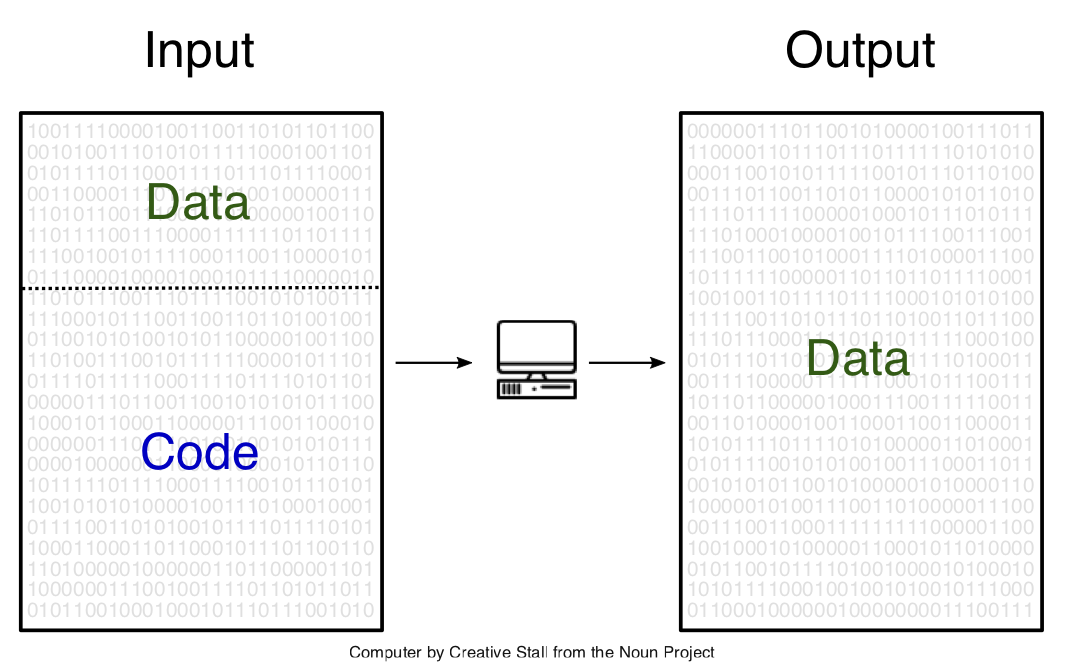 and in a next step into
and in a next step into
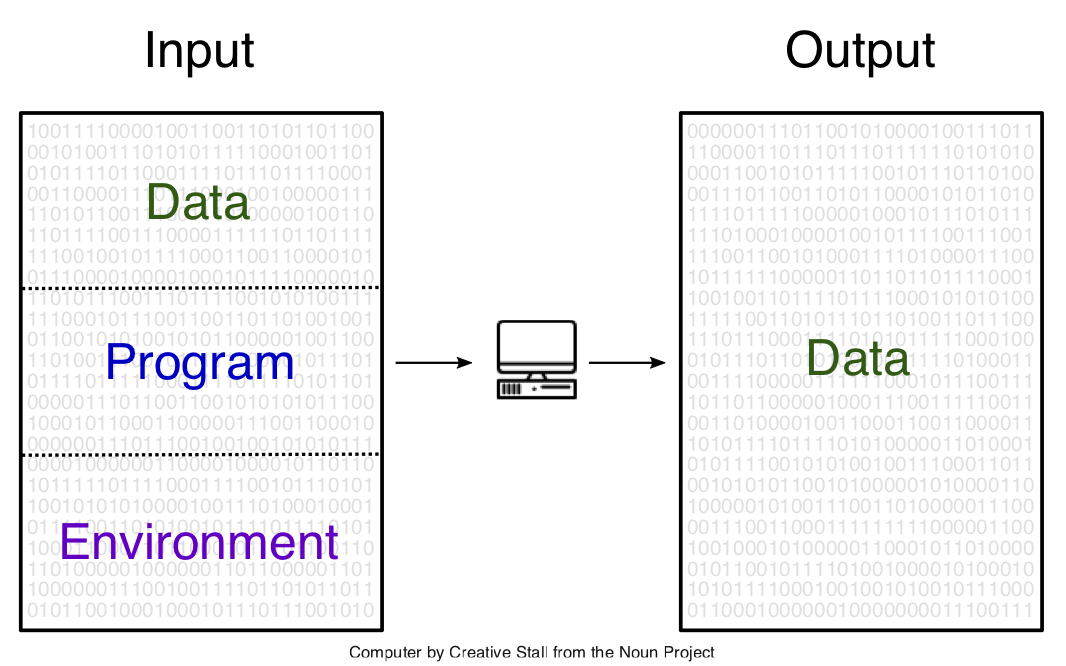 We can go on and divide the
environment into operating system, development tools, and application
software, for example, but the further we go in decomposing the input to
a computation, the more arbitrary it gets.
We can go on and divide the
environment into operating system, development tools, and application
software, for example, but the further we go in decomposing the input to
a computation, the more arbitrary it gets.
From this point of view, a software's dependencies consist of everything required to run it in addition to its source code. For a Guix package, the dependencies are thus,
- its inputs
- the build system arguments
- the build system itself
- Guix (which is a piece of software as well)
- the GNU/Linux operating system (kernel, file system, etc.).
In the following, I will not mention the last two items any more, because they are a common dependency of all Guix packages, but it's important not to forget about them. A change in Guix or in GNU/Linux can actually make a computation non-reproducible, although in practice that happens very rarely. Moreover, Guix is actually designed to run older versions of itself, as we will see later.
Build systems are (mostly) packages as well
I hope that by now you have a good idea of what a package is: a recipe for building outputs from source and inputs, with inputs being the outputs of other packages. The recipe involves a build system and arguments supplied to it. So... what exactly is a build system? I have introduced it as a generalization of a compiler, which describes its role. But where does a build system come from in Guix?
The ultimate answer is of course the source
code.
Build systems are pieces of Guile code that are part of Guix. But this
Guile code is only a shallow layer orchestrating invocations of other
software, such as gcc or make. And that software is defined by
packages. So in the end, from a reproducibility point of view, we can
replace the "build system" item in our list of dependencies by "a
bundle of packages". In other words: more inputs.
Before Guix can build a package, it must gather all the required
ingredients, and that includes replacing the build system by the
packages it represents. The resulting list of ingredients is called a
bag, and we can access it using a Guile script:
(use-modules (guix packages)
(gnu packages)
(srfi srfi-1)
(ice-9 match))
(define (package->specification package)
(format #f "~a@~a"
(package-name package)
(package-version package)))
(define (input->specification input)
(match input
((label (? package? package) . _)
(package->specification package))
((label (? origin? origin))
(format #f "[source code from ~a]"
(origin-uri origin)))
(other-input
(format #f "~a" other-input))))
(define (unique-inputs inputs)
(delete-duplicates
(map input->specification inputs)))
(define hello
(specification->package "hello"))
(format #t "Package : ~a\n"
(package->specification hello))
(format #t "Package inputs: ~a\n"
(unique-inputs (package-direct-inputs hello)))
(format #t "Build inputs : ~a\n"
(unique-inputs
(bag-direct-inputs
(package->bag hello))))Package : hello@2.10
Package inputs: ()
Build inputs : ([source code from mirror://gnu/hello/hello-2.10.tar.gz] tar@1.32 gzip@1.10 bzip2@1.0.6 xz@5.2.4 file@5.33 diffutils@3.7 patch@2.7.6 findutils@4.6.0 gawk@5.0.1 sed@4.7 grep@3.3 coreutils@8.31 make@4.2.1 bash-minimal@5.0.7 ld-wrapper@0 binutils@2.32 gcc@7.4.0 glibc@2.29 glibc-utf8-locales@2.29)I have used a different example,
hello,
because for gcc-toolchain, there is no difference between package
inputs and build inputs (check for yourself if you want!) My new
example, hello (a short demo
program printing "Hello, world" in the language of the system
installation), is interesting because it has no package inputs at all.
All the build inputs except for the source code have thus been
contributed by the build system.
If you compare this script to the previous one that printed only the
package inputs, you will notice two major new features. In
input->specification, there is an additional case for the source code
reference. And in the last statement, package->bag constructs a bag
from the package, before bag-direct-inputs is called to get that
bag's input list.
Inputs are outputs
I have mentioned before that one package's inputs are other packages' outputs, but that fact deserves a more in-depth discussion because of its crucial importance for reproducibility. A package is a recipe for building outputs from source and inputs. Since these inputs are outputs, they must have been built as well. Package building is therefore a process consisting of multiple steps. An immediate consequence is that any computation making use of packaged software is a multi-step computation as well.
Remember the short C program computing π from the beginning of this
post? Running that program is only the last step in a long series of
computations. Before you can run pi, you must compile pi.c. That
requires the package gcc-toolchain, which must first be built. And
before it can be built, its inputs must be built. And so on. If you want
the output of pi to be reproducible, the whole chain of computations
must be reproducible, because each step can have an impact on the
results produced by pi.
So... where does this chain start? Few people write machine code these days, so almost all software requires some compiler or interpreter. And that means that for every package, there are other packages that must be built first. The question of how to get this chain started is known as the bootstrapping problem. A rough summary of the solution is that the chain starts on somebody else's computer, which creates a bootstrap seed, an ideally small package that is downloaded in precompiled form. See this post by Jan Nieuwenhuizen for details of this procedure. The bootstrap seed is not the real start of the chain, but as long as we can retrieve an identical copy at a later time, that's good enough for reproducibility. In fact, the reason for requiring the bootstrap seed to be small is not reproducibility, but inspectability: it should be possible to audit the seed for bugs and malware, even in the absence of source code.
Reaching closure
Now we are finally ready for the ultimate step in dependency analysis:
identifying all packages on which a computation depends, right up to the
bootstrap seed. The starting point is the list of direct inputs of the
bag derived from a package, which we looked at in the previous script.
For each package in that list, we must apply this same procedure,
recursively. We don't have to write this code ourselves, because the
function package-closure in Guix does that job. These closures have
nothing to do with closures in Lisp, and even less with the Clojure
programming language. They are a case of what mathematicians call
transitive closures:
starting with a set of packages, you extend the set repeatedly by adding
the inputs of the packages that are already in the set, until there is
nothing more to add. If you have a basic knowledge of Scheme, you should
now be able to understand the
implementation
of this function. Let's add it to our dependency analysis code:
(use-modules (guix packages)
(gnu packages)
(srfi srfi-1)
(ice-9 match))
(define (package->specification package)
(format #f "~a@~a"
(package-name package)
(package-version package)))
(define (input->specification input)
(match input
((label (? package? package) . _)
(package->specification package))
((label (? origin? origin))
(format #f "[source code from ~a]"
(origin-uri origin)))
(other-input
(format #f "~a" other-input))))
(define (unique-inputs inputs)
(delete-duplicates
(map input->specification inputs)))
(define (length-and-list lists)
(list (length lists) lists))
(define hello
(specification->package "hello"))
(format #t "Package : ~a\n"
(package->specification hello))
(format #t "Package inputs : ~a\n"
(length-and-list (unique-inputs (package-direct-inputs hello))))
(format #t "Build inputs : ~a\n"
(length-and-list
(unique-inputs
(bag-direct-inputs
(package->bag hello)))))
(format #t "Package closure: ~a\n"
(length-and-list
(delete-duplicates
(map package->specification
(package-closure (list hello))))))Package : hello@2.10
Package inputs : (0 ())
Build inputs : (20 ([source code from mirror://gnu/hello/hello-2.10.tar.gz] tar@1.32 gzip@1.10 bzip2@1.0.6 xz@5.2.4 file@5.33 diffutils@3.7 patch@2.7.6 findutils@4.6.0 gawk@5.0.1 sed@4.7 grep@3.3 coreutils@8.31 make@4.2.1 bash-minimal@5.0.7 ld-wrapper@0 binutils@2.32 gcc@7.4.0 glibc@2.29 glibc-utf8-locales@2.29))
Package closure: (84 (m4@1.4.18 libatomic-ops@7.6.10 gmp@6.1.2 libgc@7.6.12 libltdl@2.4.6 libunistring@0.9.10 libffi@3.2.1 pkg-config@0.29.2 guile@2.2.6 libsigsegv@2.12 lzip@1.21 ed@1.15 perl@5.30.0 guile-bootstrap@2.0 zlib@1.2.11 xz@5.2.4 ncurses@6.1-20190609 libxml2@2.9.9 attr@2.4.48 gettext-minimal@0.20.1 gcc-cross-boot0-wrapped@7.4.0 libstdc++@7.4.0 ld-wrapper-boot3@0 bootstrap-binaries@0 ld-wrapper-boot0@0 flex@2.6.4 glibc-intermediate@2.29 libstdc++-boot0@4.9.4 expat@2.2.7 gcc-mesboot1-wrapper@4.7.4 mesboot-headers@0.19 gcc-core-mesboot@2.95.3 bootstrap-mes@0 bootstrap-mescc-tools@0.5.2 tcc-boot0@0.9.26-6.c004e9a mes-boot@0.19 tcc-boot@0.9.27 make-mesboot0@3.80 gcc-mesboot0@2.95.3 binutils-mesboot0@2.20.1a make-mesboot@3.82 diffutils-mesboot@2.7 gcc-mesboot1@4.7.4 glibc-headers-mesboot@2.16.0 glibc-mesboot0@2.2.5 binutils-mesboot@2.20.1a linux-libre-headers@4.19.56 linux-libre-headers-bootstrap@0 gcc-mesboot@4.9.4 glibc-mesboot@2.16.0 gcc-cross-boot0@7.4.0 bash-static@5.0.7 gettext-boot0@0.19.8.1 python-minimal@3.5.7 perl-boot0@5.30.0 texinfo@6.6 bison@3.4.1 gzip@1.10 libcap@2.27 acl@2.2.53 glibc-utf8-locales@2.29 gcc-mesboot-wrapper@4.9.4 file-boot0@5.33 findutils-boot0@4.6.0 diffutils-boot0@3.7 make-boot0@4.2.1 binutils-cross-boot0@2.32 glibc@2.29 gcc@7.4.0 binutils@2.32 ld-wrapper@0 bash-minimal@5.0.7 make@4.2.1 coreutils@8.31 grep@3.3 sed@4.7 gawk@5.0.1 findutils@4.6.0 patch@2.7.6 diffutils@3.7 file@5.33 bzip2@1.0.6 tar@1.32 hello@2.10))That's 84 packages, just for printing "Hello, world!". As promised,
it includes the bootstrap seed, called bootstrap-binaries. It may be
more surprising to see Perl and Python in the dependency list of what is
a pure C program. The explanation is that the build process of gcc and
glibc contains Perl and Python code. Considering that both Perl and
Python are written in C and use glibc, this hints at why bootstrapping
is a hard problem!
Get ready for your own analyses
As promised, here is a Guile script that you can download and run from the command line to do dependency analyses much like the ones I have shown. Just give the packages whose combined list of dependencies you want to analyze. For example:
./show-dependencies.scm helloPackages: 1
hello@2.10
Package inputs: 0 packages
Build inputs: 20 packages
[source code from mirror://gnu/hello/hello-2.10.tar.gz] bash-minimal@5.0.7 binutils@2.32 bzip2@1.0.6 coreutils@8.31 diffutils@3.7 file@5.33 findutils@4.6.0 gawk@5.0.1 gcc@7.4.0 glibc-utf8-locales@2.29 glibc@2.29 grep@3.3 gzip@1.10 ld-wrapper@0 make@4.2.1 patch@2.7.6 sed@4.7 tar@1.32 xz@5.2.4
Package closure: 84 packages
acl@2.2.53 attr@2.4.48 bash-minimal@5.0.7 bash-static@5.0.7 binutils-cross-boot0@2.32 binutils-mesboot0@2.20.1a binutils-mesboot@2.20.1a binutils@2.32 bison@3.4.1 bootstrap-binaries@0 bootstrap-mes@0 bootstrap-mescc-tools@0.5.2 bzip2@1.0.6 coreutils@8.31 diffutils-boot0@3.7 diffutils-mesboot@2.7 diffutils@3.7 ed@1.15 expat@2.2.7 file-boot0@5.33 file@5.33 findutils-boot0@4.6.0 findutils@4.6.0 flex@2.6.4 gawk@5.0.1 gcc-core-mesboot@2.95.3 gcc-cross-boot0-wrapped@7.4.0 gcc-cross-boot0@7.4.0 gcc-mesboot-wrapper@4.9.4 gcc-mesboot0@2.95.3 gcc-mesboot1-wrapper@4.7.4 gcc-mesboot1@4.7.4 gcc-mesboot@4.9.4 gcc@7.4.0 gettext-boot0@0.19.8.1 gettext-minimal@0.20.1 glibc-headers-mesboot@2.16.0 glibc-intermediate@2.29 glibc-mesboot0@2.2.5 glibc-mesboot@2.16.0 glibc-utf8-locales@2.29 glibc@2.29 gmp@6.1.2 grep@3.3 guile-bootstrap@2.0 guile@2.2.6 gzip@1.10 hello@2.10 ld-wrapper-boot0@0 ld-wrapper-boot3@0 ld-wrapper@0 libatomic-ops@7.6.10 libcap@2.27 libffi@3.2.1 libgc@7.6.12 libltdl@2.4.6 libsigsegv@2.12 libstdc++-boot0@4.9.4 libstdc++@7.4.0 libunistring@0.9.10 libxml2@2.9.9 linux-libre-headers-bootstrap@0 linux-libre-headers@4.19.56 lzip@1.21 m4@1.4.18 make-boot0@4.2.1 make-mesboot0@3.80 make-mesboot@3.82 make@4.2.1 mes-boot@0.19 mesboot-headers@0.19 ncurses@6.1-20190609 patch@2.7.6 perl-boot0@5.30.0 perl@5.30.0 pkg-config@0.29.2 python-minimal@3.5.7 sed@4.7 tar@1.32 tcc-boot0@0.9.26-6.c004e9a tcc-boot@0.9.27 texinfo@6.6 xz@5.2.4 zlib@1.2.11You can now easily experiment yourself, even if you are not at ease with Guile. For example, suppose you have a small Python script that plots some data using matplotlib. What are its dependencies? First you should check that it runs in a minimal environment:
guix environment --container --ad-hoc python python-matplotlib -- python my-script.pyNext, find its dependencies:
./show-dependencies.scm python python-matplotlibI won't show the output here because it is rather long - the package closure contains 499 packages!
OK, but... what are the real dependencies?
I have explained dependencies along these lines in a few seminars.
There's one question that someone in the audience is bound to ask: What
do the results of a computation really depend on? The output of
hello is "Hello, world!", no matter which version of gcc I use to
compile it, and no matter which version of python was used in building
glibc. The package closure is a worst-case estimate: it contains
everything that can potentially influence the results, though most of
it doesn't in practice. Unfortunately, there is no way to identify the
dependencies that matter automatically, because answering that question
in general (i.e. for arbitrary software) is equivalent to solving the
halting problem.
Most package managers, such as Debian's apt or the multi-platform
conda, take a different point of view. They define the dependencies of
a program as all packages that need to be loaded into memory in order to
run it. They thus exclude the software that is required to build the
program and its run-time dependencies, but can then be discarded.
Whereas Guix' definition errs on the safe side (its dependency list is
often longer than necessary but never too short), the run-time-only
definition is both too vast and too restrictive. Many run-time
dependencies don't have an impact on most programs' results, but some
build-time dependencies do.
One important case where build-time dependencies matter is floating-point computations. For historical reasons, they are surrounded by an aura of vagueness and imprecision, which goes back to its early days, when many details were poorly understood and implementations varied a lot. Today, all computers used for scientific computing respect the IEEE 754 standard that precisely defines how floating-point numbers are represented in memory and what the result of each arithmetic operation must be. Floating-point arithmetic is thus perfectly deterministic and even perfectly portable between machines, if expressed in terms of the operations defined by the standard. However, high-level languages such as C or Fortran do not allow programmers to do that. Their designers assume (probably correctly) that most programmers do not want to deal with the intricate details of rounding. Therefore they provide only a simplified interface to the arithmetic operations of IEEE 754, which incidentally also leaves more liberty for code optimization to compiler writers. The net result is that the complete specification of a program's results is its source code plus the compiler and the compilation options. You thus can get reproducible floating-point results if you include all compilation steps into the perimeter of your computation, at least for code running on a single processor. Parallel computing is a different story: it involves voluntarily giving up reproducibility in exchange for speed. Reproducibility then becomes a best-effort approach of limiting the collateral damage done by optimization through the clever design of algorithms.
Reproducing a reproducible computation
So far, I have explained the theory behind reproducible computations. The take-home message is that to be sure to get exactly the same results in the future, you have to use the exact same versions of all packages in the package closure of your immediate dependencies. I have also shown you how you can access that package closure. There is one missing piece: how do you actually run your program in the future, using the same environment?
The good news is that doing this is a lot simpler than understanding my lengthy explanations (which is why I leave this for the end!). The complex dependency graphs that I have analyzed up to here are encoded in the Guix source code, so all you need to re-create your environment is the exact same version of Guix! You get that version using
guix describeGeneration 15 Jan 06 2020 13:30:45 (current)
guix 769b96b
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: master
commit: 769b96b62e8c09b078f73adc09fb860505920f8fThe critical information here is the unpleasant looking string of hexadecimal digits after "commit". This is all it takes to uniquely identify a version of Guix. And to re-use it in the future, all you need is Guix' time machine:
guix time-machine --commit=769b96b62e8c09b078f73adc09fb860505920f8f -- environment --ad-hoc gcc-toolchainUpdating channel 'guix' from Git repository at 'https://git.savannah.gnu.org/git/guix.git'...gcc pi.c -o pi
./piM_PI : 3.1415926536
4 * atan(1.) : 3.1415926536
Leibniz' formula (four terms): 2.8952380952The time machine actually downloads the specified version of Guix and
passes it the rest of the command line. You are running the same code
again. Even bugs in Guix will be reproduced faithfully! As before,
guix environment leaves us in a special-environment shell which
needs to be terminated by Ctrl-D.
For many practical use cases, this technique is sufficient. But there are two variants you should know about for more complicated situations:
If you need an environment with many packages, you should use a manifest rather than list the packages on the command line. See the manual for details.
If you need packages from additional channels, i.e. packages that are not part of the official Guix distribution, you should store a complete channel description in a file using
guix describe -f channels > guix-version-for-reproduction.txtand feed that file to the time machine:
guix time-machine --channels=guix-version-for-reproduction.txt -- environment --ad-hoc gcc-toolchainUpdating channel 'guix' from Git repository at 'https://git.savannah.gnu.org/git/guix.git'...gcc pi.c -o pi
./piM_PI : 3.1415926536
4 * atan(1.) : 3.1415926536
Leibniz' formula (four terms): 2.8952380952Last, if your colleagues do not use Guix yet, you can pack your reproducible software for use on other systems: as a tarball, or as a Docker or Singularity container image. For example:
guix pack \
-f docker \
-C none \
-S /bin=bin \
-S /lib=lib \
-S /share=share \
-S /etc=etc \
gcc-toolchain/gnu/store/iqn9yyvi8im18g7y9f064lw9s9knxp0w-docker-pack.tarwill produce a Docker container image, and with the knowledge of the
Guix commit (or channel specification), you will be able in the future
to reproduce this container bit-to-bit using guix time-machine.
And now... congratulations for having survived to the end of this long journey! May all your computations be reproducible, with Guix.
About GNU Guix
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the kernel Linux, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, and AArch64 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Sauf indication contraire, les billets de blog de ce site sont la propriété de leurs auteurs respectifs et publiés sous les termes de la licence CC-BY-SA 4.0 et ceux de la GNU Free Documentation License (version 1.3 ou supérieur, sans section invariante, sans texte de préface ni de postface).