Getting bytes to disk more quickly
Let’s face it: functional package managers like Guix provide unequaled support for reproducibility and transactional upgrades, but the price to pay is that users often spend a fair amount of time downloading (or building) packages. Download times are okay on day-to-day use but they’re a pain point when performing large upgrades or when installing Guix System for the first time.
With that in mind, it should come as no surprise that Michael Stapelberg’s excellent 2020 Arch Linux Conference talk and the installation speed achieved by distri were a great motivation boost. Michael proposes radical ideas to speed up package installation, such as downloading and mounting ready-to-use SquashFS images. Not everything can be transposed to Guix as-is, but it certainly got us thinking.
This article dives into improvements made over the last few months that
will be in the upcoming 1.2.1 release, and which are already one guix pull
away;
they all contribute to making substitute
download and
installation “faster”. This is an evolution of the existing mechanisms
rather than a revolution, but one that users will surely welcome.
Reducing latency
One of the first things we notice is latency between subsequent
substitute downloads. It may sound ridiculous, but guix-daemon would
spawn one helper process (running the internal guix substitute
command) for each substitute download. That means that not only would
it create a new process each time, it would also be unable to reuse
connections to the substitute servers. This is particularly noticeable
and wasteful when downloading many substitutes in a row, such as when
installing Guix System for the first time.
The latency in between subsequent substitute downloads was primarily
this: fork (creating a new process), TCP connection establishment and
TLS connection handshake. When running perf timechart record guix build … (what a wonderful tool perf timechart is!), we get this Gantt
diagram, which gives an idea of all the time wasted creating these
processes, waiting for them to initialize and connect to the substitute
server, and so on:

Why was it done this way? Because the daemon, written in C++ and inherited from Nix, would historically delegate substitution to helper programs, with a flexible but naive protocol between the daemon and those helper programs.
Back in December, we tackled this
issue
(followup): the daemon would now
launch a single guix substitute process and reuse it for subsequent
substitute downloads. In turn, guix substitute would cache
connections so we save time on connection establishment.
Another observation we made is that guix-daemon implemented
post-processing steps after each download that would contribute to
latency. Once guix substitute had completed a download and extracted
the archive to the store, the daemon would traverse this store item a
couple of times to reset file timestamps/permissions (“metadata
canonicalization”), to deduplicate files, and to verify the integrity
of the whole store item. This is I/O-intensive and particularly
wasteful for store items with many files. Our next step was to delegate
all this work to guix substitute, which allows it to pipeline archive
extraction, integrity checks, deduplication, and metadata
canonicalization. All this happens
as the bytes flow in and no extra traversal is needed.
The speedup offered by these optimizations depends on several factors, including the latency of your network, the speed of your CPU and that of your hard disk, and it grows with the number of substitutes fetched in a row. What we can say is that even in a “favorable” situation—low-latency network, fast CPU, fast storage device—it definitely feels snappier.
Increasing bandwidth
With the latency issue pretty much solved, the next step was to look at bandwidth. When we introduced lzip-compressed substitutes back in 2019, the assumption was that a much higher compression ratio (compared to gzip), would inevitably translate to faster downloads. That is true… but only for some bandwidth/CPU power configurations.
Specifically, it turns out that, for someone with a fast connection, such as fiber-to-the-home (FTTH), downloads of lzip-compressed substitutes are actually CPU-bound. In other words, the limiting factor is the processing time to decompress those lzip’d archives—not the available bandwidth. Lzip currently achieves the best compression ratios so far, and that’s great, but decompression is compute-intensive.
Ever-increasing bandwidth is what drove the design and implementation of newer compression methods, such as “Z standard”, colloquially known as “zstd”. The decompression speed of zstd is on the order of 3.5 higher than that of gzip and an order of magnitude higher than that of lzip; but unlike the venerable lzo, zstd achieves high compression ratios: at level 19, the compression ratio of zstd is lower than that of lzip but in the same ballpark. Guillaume Le Vaillant provided an insightful comparison of gzip, lzip, and zstd on a plot showing their decompression speed as a function of the compression ratio:
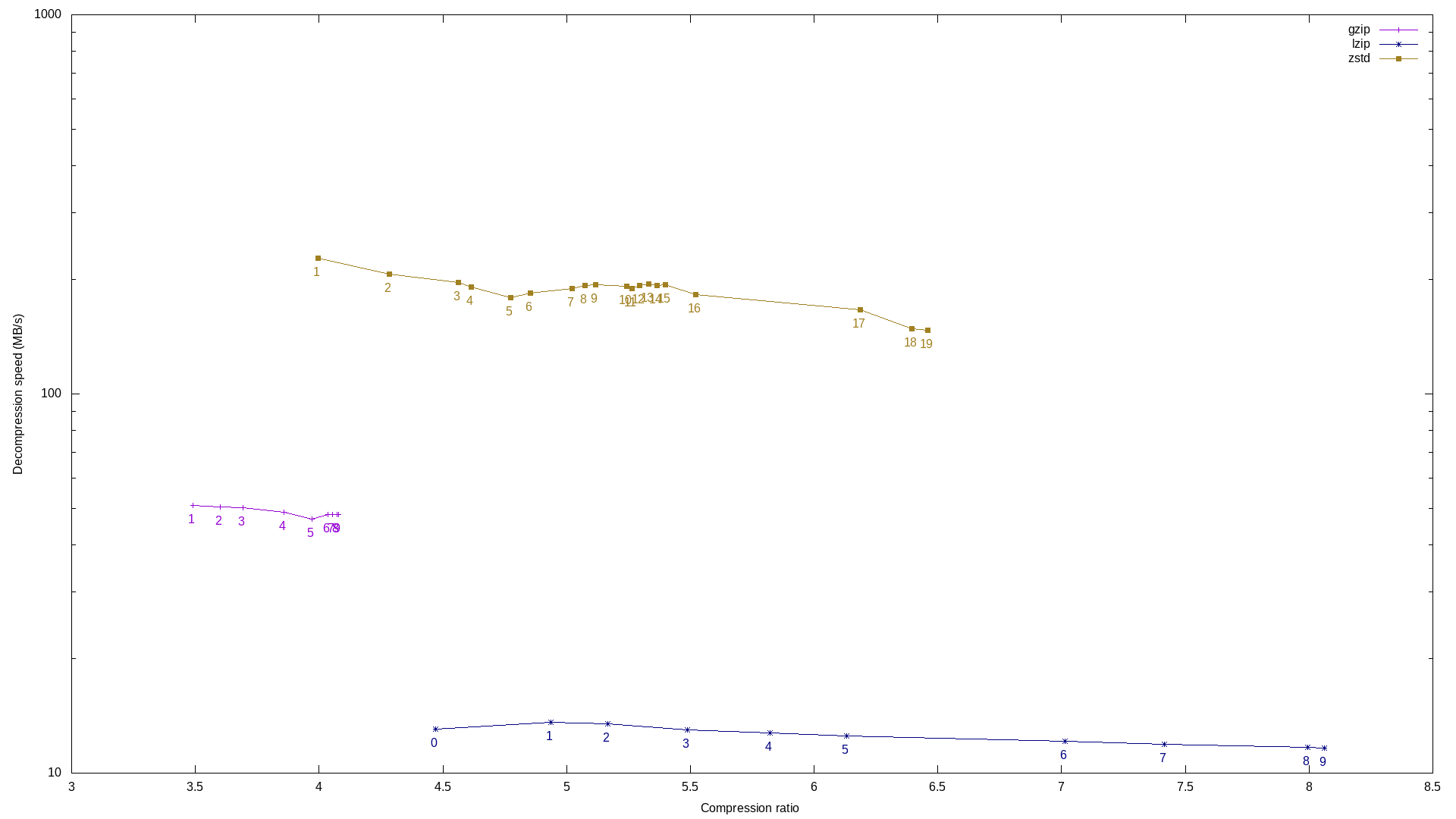
There are several takeaways. First, zstd decompression is always faster than the alternatives. Second, zstd compresses better than gzip starting from level 2, so gzip “loses” on both criteria. Last, zstd at level 19 achieves a compression ratio comparable to lzip level 5 or 6—lzip level 9 remains better in that regard.
With brand new Guile bindings to
zstd, we were able to add
zstd support to guix publish
and guix substitute. But what policy should be adopted for the
official substitute server at ci.guix.gnu.org?
Our goal is to maximize substitute download speed. In some configurations, for example on relatively slow connections, fetching lzip substitutes is not CPU-bound; in those cases, fetching lzip substitutes remains the fastest option. And of course, there are these other configurations where lzip decompression is the limiting factor, and where we’d rather fetch a slightly less compressed zstd substitute (or even a much less compressed gzip substitutes, sometimes).
The solution we came up with is a naive but efficient solution:
client-side adaptive compression
selection. When it fetches and
decompresses a substitute, guix substitute monitors its CPU usage as
reported by
times.
If the user time to wall-clock time ratio is close to one, that probably
means the substitute fetch and decompression process was CPU-bound; in
that case, choose a compression method that yields faster decompression
next time—assuming the substitute server offers several options.
Conversely, if CPU usage is close to zero, the process is probably
network-bound, so next time we’ll choose a better-compressed option.
The official server at ci.guix.gnu.org now provides zstd-compressed
substitutes in addition to lzip and gzip. An extra
complication
is that we cannot drop gzip compression just yet because pre-1.1.0 Guix
installations understand nothing but gzip. To ease transition, the
server will probably offer substitutes in all three compression formats
for one more year or so.
There’s a good reason to upgrade your daemon though: you’ll be able to benefit from those zstd substitutes and if you have high bandwidth, you’ll quickly see the difference!
Grabbing substitutes from your neighbors
When it comes to increasing download speeds, another option is to download from your neighbors rather than from a server far away. This is particularly useful at the workplace, where machines around you are likely to already have the store items you’re looking for, or, say, at Guix gatherings—at least when we can meet physically again…
The idea had been floating
around
for some time as a direct benefit of reproducible
builds and co-maintainer Mathieu
Othacehe recently implemented
it. As Mathieu
explains in his blog post, guix publish can now advertise itself on
the local network using the mDNS/DNS-SD protocol via
Avahi; when guix-daemon is passed the
--discover option, guix substitute automatically discovers local
substitute servers and adds them as the preferred download location.
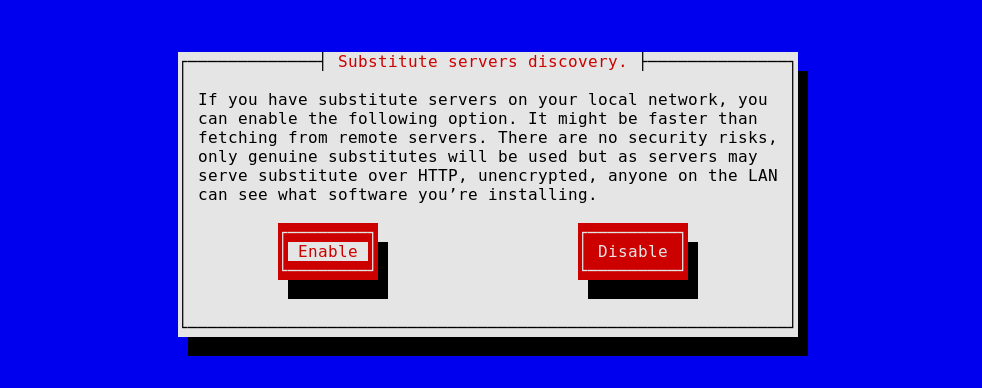
The Guix System installation image even allows you to enable it to speed
up the installation process:
Again, that only speeds things up if substitute servers use a compression method with fast decompression, and with either a cache or fast compression if they compress things on the fly. Zstd comes in handy for that: Guillaume’s measurements show that zstd compression is inexpensive at low compression levels, while achieving higher compression ratios than gzip.
{kind=link}
Going further
Put together, these changes have the potential to noticeably improve user experience. But as I wrote in the introduction, it’s not revolutionary either—users still have to download all these things.
The next big step might come from fetching substitutes over peer-to-peer, content-addressed networks such as IPFS or GNUnet. Their content-addressed nature could allow users to download less. The performance characteristics of these networks is less clear though.
There is still value in a plain HTTP-based substitute protocol like the one currently used that is easy to set up, though. In that spirit, an option would be to “upgrade” the existing substitute protocol to take advantage of content-addressability. After all, the daemon already performs file-level deduplication and there’s a fair amount of identical files between subsequent builds of the same package. So… what if we only downloaded those files not already available locally? This idea is appealing but we need to go beyond the prototyping phase to get a better idea of its viability.
For completeness, another option currently investigated by the Nix developers is that of “content-addressed derivations”. While currently store file names contain a hash of the inputs used to produce them, the idea of content-addressed derivations is to make it a content hash; that way, if an input change has no effect on the build result, the output is the same and nothing needs to be re-downloaded (this is what Eelco Dolstra described as the intensional model in Chapter 6 of his seminal PhD thesis). This option is appealing, also for other reasons, but it’s a fundamental change with what looks like a high implementation complexity and transition cost. We have yet to gauge the pros and cons of following this approach.
Until then, we hope Guix 1.2.1 will bring your faster substitutes and happiness!
About GNU Guix
GNU Guix is a transactional package manager and an advanced distribution of the GNU system that respects user freedom. Guix can be used on top of any system running the Hurd or the Linux kernel, or it can be used as a standalone operating system distribution for i686, x86_64, ARMv7, and AArch64 machines.
In addition to standard package management features, Guix supports transactional upgrades and roll-backs, unprivileged package management, per-user profiles, and garbage collection. When used as a standalone GNU/Linux distribution, Guix offers a declarative, stateless approach to operating system configuration management. Guix is highly customizable and hackable through Guile programming interfaces and extensions to the Scheme language.
Pokud není uvedeno jinak, příspěvky na blogu na těchto stránkách jsou chráněny autorskými právy příslušných autorů a zveřejněny za podmínek licence CC-BY-SA 4.0 a podmínek licence GNU Free Documentation License (verze 1.3 nebo novější, bez invariantních částí, bez textů na přední straně obálky a bez textů na zadní straně obálky).