GNU Guix
В этом документе описывается GNU Guix версии 1.4.0 — менеджер пакетов, написанный для системы GNU.
This manual is also available in Simplified Chinese (see GNU Guix参考手册), French (see Manuel de référence de GNU Guix), German (see Referenzhandbuch zu GNU Guix), Spanish (see Manual de referencia de GNU Guix), Brazilian Portuguese (see Manual de referência do GNU Guix), and Russian (see Руководство GNU Guix). If you would like to translate it in your native language, consider joining Weblate (see Тестирование Guix.).
Table of Contents
- 1 Введение
- 2 Установка
- 3 Установка системы
- 4 System Troubleshooting Tips
- 5 Начиная
- 6 Управление пакетами
- 7 Каналы
- 7.1 Указание дополнительных каналов
- 7.2 Использование отдельного канала Guix
- 7.3 Копирование Guix
- 7.4 Аутентификация канала
- 7.5 Каналы с заменителями
- 7.6 Создание канала
- 7.7 Пакетные модули в поддиректории
- 7.8 Объявление зависимостей канала
- 7.9 Указание авторизаций канала
- 7.10 Основной URL
- 7.11 Написание новостей канала
- 8 Разработка
- 9 Программный интерфейс
- 10 Утилиты
- 10.1 Запуск
guix build - 10.2 Вызов
guix edit - 10.3 Вызов
guix download - 10.4 Вызов
guix hash - 10.5 Вызов
guix import - 10.6 Вызов
guix refresh - 10.7 Invoking
guix style - 10.8 Вызов
guix lint - 10.9 Вызов
guix size - 10.10 Вызов
guix graph - 10.11 Вызов
guix publish - 10.12 Вызов
guix challenge - 10.13 Вызов
guix copy - 10.14 Вызов
guix container - 10.15 Вызов
guix weather - 10.16 Вызов
guix processes
- 10.1 Запуск
- 11 Foreign Architectures
- 12 Конфигурирование системы
- 12.1 Использование системы конфигурации
- 12.2
operating-systemReference - 12.3 Файловые системы
- 12.4 Размеченные устройства
- 12.5 Swap Space
- 12.6 Учётные записи пользователей
- 12.7 Раскладка клавиатуры
- 12.8 Региональные настройки
- 12.9 Сервисы
- 12.9.1 Базовые службы
- 12.9.2 Запланированное исполнения задач
- 12.9.3 Ротация логов
- 12.9.4 Networking Setup
- 12.9.5 Сервисы сети
- 12.9.6 Автоматические обновления
- 12.9.7 Оконная система X
- 12.9.8 Сервисы печати
- 12.9.9 Сервисы рабочего стола
- 12.9.10 Звуковые сервисы
- 12.9.11 Сервисы баз данных
- 12.9.12 Почтовые сервисы
- 12.9.13 Сервисы сообщений
- 12.9.14 Сервисы телефонии
- 12.9.15 File-Sharing Services
- 12.9.16 Сервисы мониторинга
- 12.9.17 Сервисы Kerberos
- 12.9.18 LDAP Сервисы
- 12.9.19 Веб-сервисы
- 12.9.20 Сервисы сертификатов
- 12.9.21 Сервисы DNS
- 12.9.22 VNC Services
- 12.9.23 VPN-сервисы
- 12.9.24 Сетевые файловые системы
- 12.9.25 Samba Services
- 12.9.26 Длительная интеграция
- 12.9.27 Сервисы управления питанием
- 12.9.28 Сервисы аудио
- 12.9.29 Сервисы виртуализации
- 12.9.30 Сервисы упраления версиями
- 12.9.31 Игровые службы
- 12.9.32 Службы подключения PAM
- 12.9.33 Сервисы Guix
- 12.9.34 Службы Linux
- 12.9.35 Сервисы Hurd
- 12.9.36 Разнообразные службы
- 12.10 Программы setuid
- 12.11 Сертификаты X.509
- 12.12 Служба выбора имён
- 12.13 Начальный RAM-диск
- 12.14 Настройка загрузчика
- 12.15 Invoking
guix system - 12.16 Invoking
guix deploy - 12.17 Running Guix in a Virtual Machine
- 12.18 Создание служб
- 13 Home Configuration
- 14 Документация
- 15 Platforms
- 16 Creating System Images
- 17 Установка файлов отладки
- 18 Using TeX and LaTeX
- 19 Обновления безопасности
- 20 Начальная загрузка
- 21 Портирование на новую платформу
- 22 Содействие
- 22.1 Сборка из Git
- 22.2 Запуск Guix перед его установкой
- 22.3 Совершенная установка
- 22.4 Принципы опакечивания
- 22.5 Стиль кодирования
- 22.6 Отправка исправлений
- 22.7 Отслеживание ошибок и патчей
- 22.8 Доступ к коммитам
- 22.9 Обновление пакета Guix
- 22.10 Writing Documentation
- 22.11 Тестирование Guix.
- 23 Благодарности
- Appendix A Лицензия свободной документации GNU
- Термины и указатели
- Программный индекс
1 Введение
GNU Guix1 — это утилита для управления пакетами и дистрибутив системы GNU. Guix позволяет непривилегированным пользователям устанавливать, обновлять и удалять программные пакеты, откатываться до предыдущих наборов пакетов, собирать пакеты из исходников и обеспечивает создание и поддержку программного окружения в целом.
Вы можете установить GNU Guix поверх существующей системы GNU/Linux, и она дополнит функции системы новой утилитой, не внося помехи (see Установка). Или можно использовать отдельную операционную систему — Guix System2. See Дистрибутив GNU.
Next: Дистрибутив GNU, Up: Введение [Contents][Index]
1.1 Управление программным обеспечением Guix Way
Guix предоставляет интерфейс командной строки для управления пакетами (see Управление пакетами), инструменты, которые помогают в разработке программного обеспечения (see Разработка), более сложные утилиты командной строки (see Утилиты), а также программный интерфейс Scheme (see Программный интерфейс). Его демон сборки отвечает за сборку пакетов по запросам пользователей (see Настройка демона) и за скачивание компилированных бинарников из авторизованных ресурсов (see Подстановки).
Guix включает определения пакетов для множества проектов GNU и не-GNU, каждый из которых уважает свободу пользователя в работе за компьютером. Он расширяемый: пользователи могут писать свои собственные определения пакетов (see Описание пакетов) и делать их доступными как независимые пакетные модули (see Пакетные модули). Он также настраиваемый: пользователи могут получать специальные определения пакетов из существующих, в том числе через командную строку (see Параметры преобразования пакета).
Под капотом Guix работает как функциональный пакетный менеджер — принцип, впервые введённый Nix (see Благодарности). В Guix процесс сборки и установки пакета рассматривается как функция в математическом смысле. Эта функция принимает входные данные, как например, скрипты сборки, компилятор, её результат зависит только от входных данных, и он не может зависеть от программ или скриптов, которые не подаются на вход явным образом. Функция сборки всегда производит один результат, когда получает один и тот же набор входных данных. Она не может как-либо изменять окружение запущенной системы; например, она не может создавать, изменять или удалять файлы за пределами её директорий сборки и установки. Это достигается так: процесс сборки запускается в изолированном окружении (или контейнере), в котором видны только входные данные, заданные явно.
Результат работы функций сборки пакетов кешируется в файловой системе в специальной директории, называемой склад (see Хранилище).Каждый пакет устанавливается в собственную директорию склада, по умолчанию — под /gnu/store. Имя директории содержит хеш всех входных данных, используемых для сборки этого пакета, так что изменение входных данных порождает различные имена директорий.
Этот подход является принципиальным, на нём основаны ключевые особенностей Guix: поддержка транзакционного обновления пакета и откаты, установка для отдельного пользователя, сборка мусора от пакетов (see Особенности).
Previous: Управление программным обеспечением Guix Way, Up: Введение [Contents][Index]
1.2 Дистрибутив GNU
Guix поставляется с дистрибутивом системы GNU, полностью состоящим из свободного программного обеспечения 3. Дистрибутив можно установить отдельно (see Установка системы), но также можно установить Guix в качестве пакетного менеджера поверх установленной системы GNU/Linux (see Установка). Когда нам нужно провести различие между ними, мы называем самодостаточный дистрибутив Guix System.
Дистрибутив предоставляет основные пакеты GNU, такие как GNU libc, GCC и
Binutils, а также многие приложения GNU и не-GNU. Полный список доступных
пакетов можно просмотреть по
онлайн или запустив
guix package (see Вызов guix package):
guix package --list-available
Наша цель — предоставить состоящий на 100% из свободного программного обеспечения рабочий дистрибуив Linux или другие варианты GNU. Мы ориентируемся на продвижении и полноценной интеграции компонентов GNU и поддержке программ и утилит, которые помогают пользователям реализовать их свободы.
Пакеты в данные момент доступны для следующих платформ:
x86_64-linuxархитектура Intel/AMD
x86_64с ядром Linux-Libre.i686-linuxархитектура Intel 32-bit (IA32) с ядром Linux-Libre.
armhf-linuxАрхитектура ARMv7-A с hard float, Thumb-2 и NEON, используя двочиный интерфейс приложений EABI hard-float (ABI), с ядром Linux-Libre.
aarch64-linuxпроцессоры little-endian 64-bit ARMv8-A с ядром Linux-Libre.
i586-gnuGNU/Hurd на 32 битной архитектуре Intel (IA32).
Эта конфигурация является экспериментальной и находится в разработке. Самый простой способ попробовать - настроить экземпляр
hurd-vm-service-typeна вашем GNU/Linux компьютере (seehurd-vm-service-type). See Содействие, о том, как помочь!mips64el-linux (unsupported)64-разрядные little-endian процессоры MIPS порядком байтов, в частности серии Loongson, n32 ABI и ядро Linux-Libre. Эта конфигурация больше не поддерживается полностью; в частности, фермы сборки проекта больше не предоставляют замены этой архитектуре.
powerpc-linux (unsupported)big-endian 32-bit PowerPC processors, specifically the PowerPC G4 with AltiVec support, and Linux-Libre kernel. This configuration is not fully supported and there is no ongoing work to ensure this architecture works.
aarch64-linux64-битные процессоры Power ISA с прямым порядком байтов, ядро Linux-Libre. Сюда входят системы POWER9, такие какRYF Talos II mainboard. Эта платформа доступна как «предварительная версия»: хотя она и поддерживается, заменители еще не доступны (see Подстановки), а некоторые пакеты могут не собираться (see Отслеживание ошибок и патчей) . Тем не менее, сообщество Guix активно работает над улучшением этой поддержки, и сейчас отличное время, чтобы попробовать и принять участие!
riscv64-linuxlittle-endian 64-bit RISC-V processors, specifically RV64GC, and Linux-Libre kernel. This platform is available as a "technology preview": although it is supported, substitutes are not yet available from the build farm (see Подстановки), and some packages may fail to build (see Отслеживание ошибок и патчей). That said, the Guix community is actively working on improving this support, and now is a great time to try it and get involved!
Пользуясь системой Guix, вы объявляете все аспекты конфигурации системы, и Guix выполняет установку инстранции ОС транзакционным, повторяемым способом, не имеющей состояния (stateless) (see Конфигурирование системы). Система Guix использует ядро Linux-libre, систему инициализации Shepherd (see Introduction in The GNU Shepherd Manual), хорошо известные утилиты и тулчейны GNU, а также графическое окружение на выбор.
Guix System is available on all the above platforms except
mips64el-linux, powerpc-linux, powerpc64le-linux and
riscv64-linux.
Информация о портировании на другие архитектуры и ядра доступна в see Портирование на новую платформу.
Дистрибутив созаётся совместными усилиями, приглашаем вас! См. See Содействие, чтобы узнать о том, как вы можете помочь.
Next: Установка системы, Previous: Введение, Up: GNU Guix [Contents][Index]
2 Установка
Примечание: We recommend the use of this shell installer script to install Guix on top of a running GNU/Linux system, thereafter called a foreign distro.4 The script automates the download, installation, and initial configuration of Guix. It should be run as the root user.
При установке на чужой дистрибутив GNU Guix дополняет доступные утилиты без внесения помех. Его данные живут только в двух директориях — обычно /gnu/store и /var/guix; другие файлы вашей системы, как /etc, остаются нетронутыми.
Установленный Guix можно обновлять командой guix pull
(see Вызов guix pull).
Если вы предпочитаете выполнять шаги установки вручную или хотита подправить их, следующие параграфы будут полезны. В них описаны требования Guix к программному обеспечению, а также процесс ручной установки до запуска в работу.
- Бинарная установка
- Требования
- Запуск набора тестов
- Настройка демона
- Вызов
guix-daemon - Установка приложения
- Обновление Guix
Next: Требования, Up: Установка [Contents][Index]
2.1 Бинарная установка
Этот раздел описывает, как установить Guix на обычную систему из отдельного архива, который содержит бинарники Guix и все его зависимости. Это обычно быстрее установки из исходных кодов, которая описана в следующем разделе. Единственное требование - иметь GNU tar и Xz.
Примечание: We recommend the use of this shell installer script. The script automates the download, installation, and initial configuration steps described below. It should be run as the root user. As root, you can thus run this:
cd /tmp wget 'https://git.savannah.gnu.org/gitweb/?p=guix.git;a=blob_plain;f=etc/guix-install.sh;hb=HEAD' chmod +x guix-install.sh ./guix-install.shIf you’re running Debian or a derivative such as Ubuntu, you can instead install the package (it might be a version older than 1.4.0 but you can update it afterwards by running ‘guix pull’):
sudo apt install guixLikewise on openSUSE:
sudo zypper install guixКогда закончите, вам может понадобиться see Установка приложения для дополнительной настройки и Начиная!
Установка производится следующими образом:
-
Скачайте архив с бинарником из
‘
https://ftp.gnu.org/gnu/guix/guix-binary-1.4.0.system.tar.xz’, где system — этоx86_64-linuxдля машиныx86_64, на которой уже запущено ядро Linux, и так далее.Убедитесь в аутентичности архива, скачав файл .sig и запустив:
$ wget https://ftp.gnu.org/gnu/guix/guix-binary-1.4.0.x86_64-linux.tar.xz.sig $ gpg --verify guix-binary-1.4.0.x86_64-linux.tar.xz.sig
Если это завершается ошибкой, значит у вас нет необходимого публичного ключа, тогда запустите команду для импорта ключа:
$ wget 'https://sv.gnu.org/people/viewgpg.php?user_id=15145' \ -qO - | gpg --import -и запустите команду
gpg --verify.Обратите внимание, что предупреждение по типу «Этот ключ не сертифицирован с доверенной подписью!» является нормальным.
- Теперь вам необходимы привилегии пользователя
root. В зависимости от вашего дистрибутива, можно запуститьsu -илиsudo -i. Подrootзапустите:# cd /tmp # tar --warning=no-timestamp -xf \ /path/to/guix-binary-1.4.0.x86_64-linux.tar.xz # mv var/guix /var/ && mv gnu /Это создаёт /gnu/store (see Хранилище) и /var/guix. Последнее содержит готовый к использованию профиль для
root(подробнее в следующем шаге).Не распаковывайте архив в работающую систему Guix, так как это перезапишет её основные файлы.
Опция
--warning=no-timestampнеобходима, чтобы удостовериться, что GNU tar не вызывает ошибок об "устаревшей дате", подобные ошибки появлялись в GNU tar 1.26 и старше, в последних версиях всё в порядке). Они возникают из-за того, что архив имеет нулевую дату модификации (что соответствует 1 января 1970). Это сделано с той целью, чтобы удостовериться, что содержимое архива не засисит от даты его создания, что делает его воспроизводимым (повторяемым). - Сделайте профиль доступным по пути ~root/.config/guix/current, куда
guix pullбудет устанавливать обновления (see Вызовguix pull):# mkdir -p ~root/.config/guix # ln -sf /var/guix/profiles/per-user/root/current-guix \ ~root/.config/guix/currentДобавьте etc/profile в
PATHи другие уместные переменные окружения:# GUIX_PROFILE="`echo ~root`/.config/guix/current" ; \ source $GUIX_PROFILE/etc/profile
- Создайте группу и пользовательские учётные записи, как это обозначено в (see Установка окружения сборки).
- Запустите демон и сделайте добавьте его в автоззагрузку после старта.
Если ваш дистрибутив использует систему инициализации systemd, этого можно добиться следующими командами:
# cp ~root/.config/guix/current/lib/systemd/system/gnu-store.mount \ ~root/.config/guix/current/lib/systemd/system/guix-daemon.service \ /etc/systemd/system/ # systemctl enable --now gnu-store.mount guix-daemonYou may also want to arrange for
guix gcto run periodically:# cp ~root/.config/guix/current/lib/systemd/system/guix-gc.service \ ~root/.config/guix/current/lib/systemd/system/guix-gc.timer \ /etc/systemd/system/ # systemctl enable --now guix-gc.timerYou may want to edit guix-gc.service to adjust the command line options to fit your needs (see Вызов
guix gc).Если ваш дистрибутив использует систему инициализации Upstart:
# initctl reload-configuration # cp ~root/.config/guix/current/lib/upstart/system/guix-daemon.conf \ /etc/init/ # start guix-daemonИли можно запускать демон вручную так:
# ~root/.config/guix/current/bin/guix-daemon \ --build-users-group=guixbuild - Сделайте команду
guixдоступной для других пользователей машины, например, так:# mkdir -p /usr/local/bin # cd /usr/local/bin # ln -s /var/guix/profiles/per-user/root/current-guix/bin/guix
Хорошо также предоставить доступ к Info-версии руководства так:
# mkdir -p /usr/local/share/info # cd /usr/local/share/info # for i in /var/guix/profiles/per-user/root/current-guix/share/info/* ; do ln -s $i ; done
Таким образом, если предположить, что /usr/local/share/info находится в пути поиска, запуск
info guixоткроет это руководство (см., see Other Info Directories in GNU Texinfo). -
To use substitutes from
ci.guix.gnu.org,bordeaux.guix.gnu.orgor a mirror (see Подстановки), authorize them:# guix archive --authorize < \ ~root/.config/guix/current/share/guix/ci.guix.gnu.org.pub # guix archive --authorize < \ ~root/.config/guix/current/share/guix/bordeaux.guix.gnu.org.pubПримечание: If you do not enable substitutes, Guix will end up building everything from source on your machine, making each installation and upgrade very expensive. See Касательно проверенных бинарников, for a discussion of reasons why one might want do disable substitutes.
- Каждый пользователь, возможно, должен выполнить дополнительные шаги, чтобы сделать их окружение Guix готовым к использованию see Установка приложения.
Вуаля! Установка завершена!
Вы можете проверить, что Guix работает, установив тестовый пакет для профиля root:
# guix install hello
Архив для бинарной установки может быть воспроизведён (повторён) и проверен простым запуском следующей команды в дереве исходников Guix:
make guix-binary.system.tar.xz
..., что в свою очередь, выполнит:
guix pack -s system --localstatedir \ --profile-name=current-guix guix
See Вызов guix pack для подробной информации об этом полезном
инструменте.
Next: Запуск набора тестов, Previous: Бинарная установка, Up: Установка [Contents][Index]
2.2 Требования
Этот раздел содержит требования для сборки Guix из исходников. Пожалуйста, смотрите файлы README и INSTALL в дереве исходников Guix для подробной информации.
GNU Guix доступен для скачивания на сайте https://www.gnu.org/software/guix/.
GNU Guix зависит от следующих пакетов:
- GNU Guile, version 3.0.x, version 3.0.3 or later;
- Guile-Gcrypt версии 0.1.0 или более поздней;
- Guile-GnuTLS (see how to install the GnuTLS bindings for Guile in GnuTLS-Guile)5;
- Guile-SQLite3 версии 0.1.0 или новее;
- Guile-zlib, 0.1.0 или более поздней;
- Guile-lzlib;
- Guile-Avahi;
- Guile-Git, version 0.5.0 or later;
- Guile-JSON 4.3.0 или более поздней;
- GNU Make.
Следующие зависимости необязательны:
- Поддержка разгрузки сборки (see Использование функционала разгрузки) и
guix copy(see Вызовguix copy) зависят от Guile-SSH версии 0.10.2 или новее. - Guile-zstd, для zstd
сжатия и распаковки в
guix publishи для заменителей (see Вызовguix publish). - Guile-Semver для
crateимпортера (see Вызовguix import). - Guile-Semver для
crateимпортера (see Вызовguix import). - Если доступна libbz2,
guix-daemonможет использовать её для сжатия логов сборки.
Если строка --disable-daemon не использовалась в configure,
тогда необходимы также следующие пакеты:
- GNU libgcrypt;
- SQLite 3;
- GCC’s g++ с поддержкой стандарта C++11.
Если Guix развёртывается в системе, где уже был установлен Guix, необходимо
указать главный каталог предыдущей инсталляции, используя параметр
--localstatedir в скрипте configure (see localstatedir in GNU Coding Standards). Скрипт
configure защищает от ошибок в конфигурации localstatedir,
предотвращая непреднамеренное повреждение хранилища (see Хранилище).
Next: Настройка демона, Previous: Требования, Up: Установка [Contents][Index]
2.3 Запуск набора тестов
После успешного завершения configure и make хорошо бы
выполнить набор тестов. Это поможет выявить проблемы установки или в
окружении, как и баги самого Guix (на самом деле, отчёты об ошибках тестов
помогают улучшить ПО). Чтобы запустить тесты, напечатайте:
make check
Тесты можно выполнять параллельно при включении опции -j в
GNU make, так быстрее. Первый запуск может длиться несколько минут на
топовой машине, последующие запуски будут быстрее, так как склад, который
создаётся для тестов, уже закеширует различные вещи.
Также можно запустить отдельные наборы тестов, используя переменную
TESTS, как в примере:
make check TESTS="tests/store.scm tests/cpio.scm"
По умолчанию результаты тестов выводятся в файл. Чтобы просмотреть
результаты каждого отдельного теста, нужно задать переменную makifile
SCM_LOG_DRIVER_FLAGS, как в примере:
make check TESTS="tests/base64.scm" SCM_LOG_DRIVER_FLAGS="--brief=no"
Лежащий в основе кастомный SRFI 64 Automake тестовый драйвер, используемый для ’проверки’ набора тестов (расположенный в build-aux/test-driver.scm) также позволяет выбрать, какие тестовые случаи запускать на более высоком уровне, при помощи опций --select и --exclude. Вот пример для запуска всех тестовых случаев из файла tests/packages.scm, чьи имена начинаются с “transaction-upgrade-entry”:
export SCM_LOG_DRIVER_FLAGS="--select=^transaction-upgrade-entry" make check TESTS="tests/packages.scm"
Желающие проверить результаты неудачных тестов прямо из командной строки
могут добавить --errors-only=yes к makefile
переменнойSCM_LOG_DRIVER_FLAGS и задать Automake makefile переменную
VERBOSE, как в:
make check TESTS="tests/base64.scm" SCM_LOG_DRIVER_FLAGS="--brief=no"
Опция --show-duration=yes может быть использована чтобы отобразить продолжительность отдельных тестовых случаев, когда использована вместе с --brief=no:
make check TESTS="tests/base64.scm" SCM_LOG_DRIVER_FLAGS="--brief=no"
See Parallel Test Harness in GNU Automake для получения дополнительной информации о Automake Parallel Test Harness.
В случае ошибки, пожалуйста, отправьте сообщение на bug-guix@gnu.org и присоедините файл test-suite.log. Пожалуйста, обозначьте в сообщении используемую версию Guix, а также номера версий зависимостей (see Требования).
Guix также идёт с набором тестов для всей системы, который проверяет нстранцию системы Guix. Их можно запустить только в системах, где Guix уже установлен, так:
make check-system
или, опять же, задав TESTS, чтобы выбрать список тестов для запуска:
make check-system TESTS="basic mcron"
Тесты системы определены в модулях (gnu tests …). При работе
они запускают операционную систему под легковесным инструментарием в
виртуальной машине. Они могут выполнять тяжёлые вычисления или довольно
простые в зависимости от наличия подстановок их зависимостей
(see Подстановки). Некоторые из них требуют много места для работы с
образами виртуальной машины.
Конечно, в случае неудачных тестов, пожалуйста, направьте детали на bug-guix@gnu.org.
Next: Вызов guix-daemon, Previous: Запуск набора тестов, Up: Установка [Contents][Index]
2.4 Настройка демона
Такие операции, как сборка пакета или запуск сборщика мусора, выполняются
запуском специальных процесса — демона сборки — по запросам
клиентов. Только демон имеет доступ к складу и его базе данных. Так что
операции управления складом выполняются с помощью демона. Например,
инструменты командной строки, как guix package и guix
build, обычно взаимодействуют с демоном через удалённый вызов процедур
(RPC) и сообщают, что необходимо сделать.
Следующие разделы поясняют как настроить окружение демона сборки. Смотрите также Подстановки для подробной инсорации о том, как разрешить демону скачивать собранные бинарники.
Next: Использование функционала разгрузки, Up: Настройка демона [Contents][Index]
2.4.1 Установка окружения сборки
В случае стандартной многопользовательской установки Guix и его демон
(программа guix-daemon) установливаются системным администратором;
/gnu/store принадлежит root, и guix-daemon запущен
от root. Непривилегированные пользователи могут пользоваться
инструментами Guix, чтобы собирать пакеты или получить доступ к складу с
какой-либо целью, и демон выполнит это по их запросу, убедившись, что склад
находится в должном состоянии, и разрешив сборку пакетов и разделение их
между пользователями.
Когда guix-daemon запущен от root, возможно, из соображений
безопасности вы не примете того, что процессы сборки пакетов тоже
выполняются от root. Чтобы избежать этого, необходимо создать
специальных пользователей для сборки. Ими будет пользоваться процесс
сборки, запускаемый демоном. Эти пользователи сборки не должны иметь
оболочки и домашней директории — они просто будут использоваться, когда
демон сбрасывает привилегии root в процессе сборки. Наличие
нескольких таких пользователей позволит демону запускать отдельные процессы
сборки под отдельными UID, что гарантирует, что они не будут помехой друг
другу — важная особенность, учитывая, что сборка рассматривается как
чистая функция (see Введение).
В системе GNU/Linux набор пользователей для сборки может быть создан так
(используя синтаксис команды Bash shadow):
# groupadd --system guixbuild
# for i in `seq -w 1 10`;
do
useradd -g guixbuild -G guixbuild \
-d /var/empty -s `which nologin` \
-c "Guix build user $i" --system \
guixbuilder$i;
done
Число пользователей для сборки определяет, сколько задач сборки может быть
запущено параллельно. Это задаётся опцией --max-jobs
(see --max-jobs). Чтобы использовать
guix system vm и подобные, вам потребуется добавить пользователей
для сборки в группу kvm, так чтобы они имели доступ к
/dev/kvm, используя -G guixbuild,kvm вместо -G
guixbuild (see Invoking guix system).
The guix-daemon program may then be run as root with the
following command6:
# guix-daemon --build-users-group=guixbuild
Так демон стартует процессы сборки в chroot под одним из пользователей
группы guixbuilder. В GNU/Linux по умолчанию окружение chroot
содержит только следующее:
- минимальный состав директории
/dev, созданной максимально независимо от исходной/dev7; - директория
/proc; она показывает только процессы контейнера, так как используется отдельное пространство имён процессов PID; - /etc/passwd с записью о текущем пользователе и пользователе nobody;
- /etc/group с записью о группе пользователя;
- /etc/hosts с записью, которая адресует
localhostна127.0.0.1; - директория /tmp, доступная для записи.
The chroot does not contain a /home directory, and the HOME
environment variable is set to the non-existent /homeless-shelter.
This helps to highlight inappropriate uses of HOME in the build
scripts of packages.
Можно указать директорию, в которую демон сохраняет деревья сборки через
переменную окружения TMPDIR. Однако дерево сборки внутри chroot
всегда называется /tmp/guix-build-name.drv-0, где name -
это имя деривации, то есть, например, coreutils-8.24. Так значение
TMPDIR не проникает внутрь окружения сборки, что предотвращает
расхождения и случаях, когда процессы сборки имеют иные имена их деревьев
сборки.
Демон также уважаем переменную окружения http_proxy, когда выполняет
скачивание по HTTP как для дериваций с фиксированным результатом
(see Деривации), так и для подстановок (see Подстановки).
Если вы устанавливаете Guix как непривилегированный пользователь, всё ещё
возможно запустить guix-daemon с указанием
--disable-chroot. Однако процессы сборки не будут изолированы один от
другого, а также от остальной системы. Так процессы сборки смогут внести
помехи в работу друг друга, смогут получить доступ к программам, библиотекам
и другим файлам, доступным в системе, что конечно, делает затруднительным
рассмотрение сборки как чистой функции.
Next: Поддержка SELinux, Previous: Установка окружения сборки, Up: Настройка демона [Contents][Index]
2.4.2 Использование функционала разгрузки
При желании демон сборки может offload производные сборки на других
машинах, на которых запущен Guix, используя offload build
hook8. Когда
данная функция включена, список указанных пользователем машин для сборки
считывается из /etc/guix/machines.scm; каждый раз, когда
запрашивается сборка, например через guix build, демон пытается
выгрузить ее на одну из машин, удовлетворяющих ограничениям производной
сборки, в частности, ее системным типам—например, x86_64-linux. На
одной машине можеь быть несколько типов систем, либо потому, что архитектура
изначально поддерживает ее, либо через эмуляцию
(see Transparent Emulation with QEMU).
Отсутствующие необходимые условия для сборки копируются по SSH на целевой
компьютер, который затем продолжает сборку; в случает успеха выходные данные
копируются на исходную машину. Средство разгрузки поставляется с базовым
планировщиком, который пытается выбрать лучшую машину. Лучшая машина
выбирается среди доступных машин на основании такиз критериев как:
- Наличие слота для сборки. Машина для сборки может иметь столько слотов для
сборки (соединений), сколько указано в значении
parallel-buildsопределения объектаbuild-machine. - Ее относительная скорость, указанная через значение
speedопределения объектаbuild-machine. - Ее нагрузка. Нормализованная нагрузка на машину должна быть ниже порогового
значения, которое можно настроить с помощью поля
overload-thresholdобъектаbuild-machine. - Доступность дискового пространства. Должно быть доступно более 100 МБ.
Файл /etc/guix/machines.scm обычно выглядит так:
(list (build-machine
(name "eightysix.example.org")
(systems (list "x86_64-linux" "i686-linux"))
(host-key "ssh-ed25519 AAAAC3Nza…")
(user "bob")
(speed 2.)) ;incredibly fast!
(build-machine
(name "armeight.example.org")
(systems (list "aarch64-linux"))
(host-key "ssh-rsa AAAAB3Nza…")
(user "alice")
;; Remember 'guix offload' is spawned by
;; 'guix-daemon' as root.
(private-key "/root/.ssh/identity-for-guix")))
В примере выше мы обозначили список, состоящий из двух машин: одна — для
архитектуры x86_64, а другая — для архитектуры mips64el.
По факту, этот файл, что не удивительно, является файлом Scheme, и он имеет
значение, когда запускается хук разгрузки. Он возвращает объекты
класса build-machine. Приведённый пример показывает фиксированный
список машин для сборки, но можно представить, скажем, используя DNS-SD, он
может возвращать список потенциальных машин, обнаруженных в локальной сети
(see Guile-Avahi in Using Avahi in Guile Scheme
Programs). Тип данных build-machine описан ниже.
- Тип данных: build-machine
Этот тип данных представляет машины для сборки, на которые демон может разгружать сборки. Важные поля:
nameИмя хоста удалённой машины.
systemsТип системы удалённой машины, то есть
x86_64-linux.userАккаунт пользователя, используемый для соединения с удалённой машиной через SSH. Отметим, что ключ-пара SSH не должна быть защищена парольной фразой, чтобы разрешить не интерактивные авторизации.
host-keyЭто публичный ключ хоста в формает OpenSSH. Он используется при аутентификации машины, когда мы подсоединяемс к ней. Это длинная строка, которая выглядит примерно так:
ssh-ed25519 AAAAC3NzaC…mde+UhL hint@example.org
Если на машине запущен демон OpenSSH
sshd, ключ хоста может быть найден в файле под директорией /etc/ssh, например, /etc/ssh/ssh_host_ed25519_key.pub.Если на машине запущен демон SSH GNU lsh,
lshd, тогда ключ хоста расположен в /etc/lsh/host-key.pub или подобном файле. Его можно конвертировать в формат OpenSSH, используяlsh-export-key(see Converting keys in LSH Manual):$ lsh-export-key --openssh < /etc/lsh/host-key.pub ssh-rsa AAAAB3NzaC1yc2EAAAAEOp8FoQAAAQEAs1eB46LV…
Список необязательных полей:
port(default:22)Номер порта сервера SSH на машине.
private-key(default: ~root/.ssh/id_rsa)Файл приватного ключа в формате OpenSSH, используемого в соединении с машиной. Этот ключ не должен быть защищён парольной фразой.
Отметим, что значение по умолчанию — приватный ключ аккаунта root. Убедитесь, что он существует, если вы используете настройки по умолчанию.
compression(default:"zlib@openssh.com,zlib")compression-level(default:3)Методы компрессии уровня SSH и уровень компрессии.
Отметим, что разгрузка зависит от компрессии SSH, что уменьшает использование траффика при передаче файлов на и с машин для сборки.
daemon-socket(default:"/var/guix/daemon-socket/socket")Имя файла сокета Unix-домена, который слушает
guix-daemonна удалённой машине.overload-threshold(default:0.8)Порог нагрузки, выше которого потенциальная offload машина не учитывается offload планировщиком. Это значение примерно соответствует общему использованию процессора машиной сборки в диапазоне от 0,0 (0%) до 1,0 (100%). Это также можно отключить, установив
overload-thresholdв#f.parallel-builds(default:1)Число сборок, которые могут быть запущены на машине.
speed(default:1.0)Показатель скорости. Планировщик разгрузки предпримет попытку выбрать машину с наибольшим показателем скорости.
features(default:'())Набор строк, описывающий специфические функции, которые поддерживаются на машине. Например,
"kvm"для машин, которые имеют модули Linux KVM и соответствующую поддерку аппаратного обеспечения. Деривации могут запрашивать функции по имени, и тогда они будут запранированы на соответствующих машинах для сборки.
Команда guix должна быть в путях для поиска на машинах лоя
сборки. Можно проверить это, выполнив:
ssh build-machine guix repl --version
Есть ещё одна вещь, которую нужно выполнить после размещения
machines.scm. Выше описано, что при разгрузке файлы передаются вперёд
и назад между складами на машинах. Для этого необходимо сгенерировать
ключ-пару на кадой машине, чтобы позволить демону экспортировать подписанные
архивы файлов из склада (see Вызов guix archive):
# guix archive --generate-key
Каждая машина для сорки должна авторизовать ключ машины-инициатора, чтобы принимать элементы из склада, которые присылает инициатор:
# guix archive --authorize < master-public-key.txt
Точно так же машина-инициатор должна авторизовать ключ каждой машины для сборки.
Всё движение с ключами, описанное здесь, создаёт надёжную двустороннюю свзь между инициатором и машинами для сборки. А именно, когда машина-инициатор принимает файлы из машины для сборки (или наборот), её демон может удостоверить их подлинность и невмешательство других, а также то, что они подписаны авторизованным ключом.
Чтобы проверить работоспособность настроек, запустите следующую команду на инициирующем узле:
# guix offload test
Это выполнит попытку соединиться с каждой из машин для сборки, обозначенных в /etc/guix/machines.scm, проверит наличие модулей Guile и Guix на каждой машине, а также сделает попытку экспортировать и импортировать, а затем выведет отчёт об этом процессе.
Если нужно тестировать другой файл с описанием машин, просто приведите его в командной строке:
# guix offload test machines-qualif.scm
И последнее, можно тестировать набор машин, чьи имена соответствуют регулярному выражению, например:
# guix offload test machines.scm '\.gnu\.org$'
Чтобы отобразить текущую загрузку всех машин для сборки, запустите команду на инициирущем узле:
# guix offload status
Previous: Использование функционала разгрузки, Up: Настройка демона [Contents][Index]
2.4.3 Поддержка SELinux
Guix включает файл политик SELinnux etc/guix-daemon.cil, который может устанавливаться в систему, в которой включен SELinux, тогда файлы Guix будут помечены и настроены для соответствующего поведения демона. Так как система Guix не предоставляет политику SELinux, политика демона не может использоваться в системе Guix.
2.4.3.1 Установка политики SELinux
Чтобы установить политику, запустите следующую команду от root:
semodule -i etc/guix-daemon.cil
Затем измените метку файловой системы с restorecon или другим
механизмом, поставляемым вашей системой.
Когда политика установлена, изменена метка файловой системы и демон
перезапущен, она должна работать в контексте guix_daemon_t. Можно
проверить это следующей командой:
ps -Zax | grep guix-daemon
Наблюдайте файлы логов SELinux во время работы команды guix build
hello, чтобы удостовериться, что SELinux позволяет выполнение необходимых
операций.
2.4.3.2 Ограничения
Эта политика не совершенна. Тут есть ряд ограничений или причуд, который нужно учитывать при разворачивании политики SELinux для демона Guix.
-
guix_daemon_socket_tна самом деле не используется. Никакие операции с сокетом не выполняются. Ничего плохого в том, чтобы иметь эту неиспользуемую метку, но желательно определить правила сокета для этой метки. -
guix gcне может получить доступ к обычным ссылкам профилей. По задумке метка файла назначения символической ссылки не зависит от метки файла самой ссылки. Хотя все профили под $localstatedir помечены, ссылки на эти профили не наследуют метку директории, в которой они находятся. Для ссылок на домашние директории пользователей это будетuser_home_t. Но для ссылок из домашней директории root, а также /tmp или рабочей директории HTTP-сервера и т.п., это не работает.guix gcне будет допускаться к чтению и следованию по этим ссылкам. - Функция демона прослушивать соединения TCP может более не работать. Это может потребовать дополнительных правил, потому что SELinux относится к сетевым сокетам иначе, чем к файлам.
- В настоящее время всем файлам с именами, соответствующими регулярному
выражению
/gnu/store/.+-(guix-.+|profile)/bin/guix-daemon, присвоена меткаguix_daemon_exec_t; это означает, что любому файлу с таким именем в любом профиле разрешён запуск в доменеguix_daemon_t. Это не идеально. Атакующий может собрать пакет, который содержит исполняемый файл и убеить пользователя установить и запустить его, и таким образом он получит доступ к доменуguix_daemon_t. В этой связи SELinux мог бы не давать ему доступ к файлам, которые разрешены для процессов в этом домене.Вам нужно будет изменить метку (label) каталога хранилища после всех обновлений до guix-daemon, например, после запуска
guix pull. Предполагая, что хранилище в /gnu, вы можете это сделать сrestorecon -vR /gnu, или другими способами, предусмотренными вашей операционной системой.Мы можем создать политику с большими ограничениями во время установки, так чтобы только точное имя исполняемого файла установленного в данный момент
guix-daemonбыло помечено меткойguix_daemon_exec_tвместо того, чтобы использовать регулярное выражение, выбирающее большой ряд файлов. Проблемой в данном случае будет то, что root потребуется устанавливать или обновлять политику во время любой установки в случае, если обновлён исполняемый файлguix-daemon.
Next: Установка приложения, Previous: Настройка демона, Up: Установка [Contents][Index]
2.5 Вызов guix-daemon
Программа guix-daemon реализует весь функционал доступа к
складу. Это включает запуск процессов сборки, запуск сборщика мусора,
проверка доступности результата сборки и т.д. Он должен быть запущен от
root так:
# guix-daemon --build-users-group=guixbuild
This daemon can also be started following the systemd “socket activation”
protocol (see make-systemd-constructor in The GNU Shepherd Manual).
Для подробностей о том, как настроить его, смотрите see Настройка демона.
По умолчанию guix-daemon запускает процессы сборки под различными
UID, от пользователей из группы, обозначенной в
--build-users-group. В дополнение каждый процесс сборки запускается в
окружении chroot, которое содержит только набор элементов склада, от которых
зависит процесс сборки, как это обозначено в деривации (see derivation), а также набор специфичных системных директорий. По
умолчанию последнее включает /dev и /dev/pts. Более того, под
GNU/Linux окружение сборки — это контейнер: в дополнение к тому, что
он имеет собственное дерево файловой системы, он также имеет отдельное
пространство имён монтирования, своё собственное пространство имён процессов
PID, пространство сетевых имён и т.д. Это позволяет получить воспроизводимые
сборки (see Особенности).
Когда демон выполняет сборку по запросу пользователя, он создаёт директорию
под /tmp или под директорией, заданной его переменной окружения
TMPDIR. Эта директория разделяется с контейнером на время сборки,
хотя внутри контейнера дерево сборки всегда называется
/tmp/guix-build-name.drv-0.
Директория сборки автоматически удаляется по завершении, если конечно, сборка не завершилась с ошибкой, и клиент не обозначил --keep-failed (see --keep-failed).
Демон слушает соединения и порождает один под-процесс для каждой сессии,
запускаемой клиентом (одну из подкоманд guix). Команда
guix processes позволяет мониторить активность вашей системы,
предоставляя обзор каждой активной сессии и клиентов. Смотрите
See Вызов guix processes для подробной информации.
Поддерживаются следующие опции командной строки:
--build-users-group=groupИспользовать пользователей из группы group для запуска процессов сборки (see build users).
--no-substitutes¶Не использовать подстановки для сборок. Это означает — собирать элементы локально вместо того, чтобы скачивать собранные бинарники (see Подстановки).
Когда демон работает с
--no-substitutes, клиенты всё ещё могут явно включить подстановку с помощью удалённого вызова процедурset-build-options(see Хранилище).--substitute-urls=urlsИспользовать адреса urls, разделённые пробелом по умолчанию, как список источников подстановок. Когда эта опция пропущена, используется ‘
https://ci.guix.gnu.org https://bordeaux.guix.gnu.org’.Это означает, что подстановки могут скачиваться из адресов urls, если конечно они подписаны доверенной подписью (see Подстановки).
See Получение заменителей с других серверов, для получения дополнительной информации о том, как настроить демон для получения заменителей с других серверов.
--no-offloadНе использовать подстановки для сборок. Это означает — собирать элементы локально вместо того, чтобы скачивать собранные бинарники (see Подстановки).
--cache-failuresКешировать ошибки сборки. По умолчанию кешируются только успешные сборки.
При установке этой опции можно использовать
guix gc --list-failures, чтобы просматривать элементы склада, помеченные как ошибочные;guix gc --clear-failuresудаляет элементы склада из кеша ошибок. See Вызовguix gc.--cores=n-c nИспользовать n ядер процессора для сборки каждой деривации;
0означает использовать все доступные.Значение по умолчанию -
0, но оно может быть изменено клиентами, в частности, опцией--coresкомандыguix build(see Запускguix build).В результате устанавливается переменная окружения
NIX_BUILD_CORESдля процесса сборки, который затем может использовать её для применения внутреннего параллелизма, например, для запускаmake -j$NIX_BUILD_CORES.--max-jobs=n-M nРазрешить максимум n параллельных задач сборки. Значение по умолчанию -
1. Установка в0означает, чтоб сборки не будут выполняться локально, вместо этого, демон будет разгружать сборки (see Использование функционала разгрузки) или просто отчитается об ошибке.--max-silent-time=secondsКогда процесс сборки или подстановки молчит более seconds секунд, завершить его и отчитаться об ошибке сборки.
Значение по умолчанию -
0, что значит отключить таймаут.Значение, заданное здесь, может быть переопределено клиентами (see
--max-silent-time).--timeout=secondsТочно так же, когда процесс сборки или подстановки длится более seconds, завершить его и отчитаться об ошибке сборки.
Значение по умолчанию -
0, что значит отключить таймаут.Значение, заданное здесь, может быть переопределено клиентами (see
--timeout).--rounds=NСобирать каждую деривацию n раз подряд и вызывать ошибку, если результаты последовательных сборок не идентичны бит-к-биту. Отметим, что эта настройка может быть переопределена клиентами в команде, например,
guix build(see Запускguix build).При использовании вместе с --keep-failed различные результаты сохраняются на складе под /gnu/store/…-check. Это делает возможным просмотр различий между двумя результатами.
--debugВыводить отладочную информацию.
Это полезно для отладки проблем запуска демона, но затем это может быть переопределено клиентами, например, опцией --verbosity команды
guix build(see Запускguix build).--chroot-directory=dirДобавить директорию dir в chroot сборки.
Это может изменить результаты процессов сборки, например, если они используют необязательные (опциональные) зависимости, найденные в dir, если они доступны, но только так, а не иначе. Поэтому не рекомендуется делать так. Вместо этого, убедитесь, что каждая деривация объявляет все необходимые входные данные.
--disable-chrootОтключить chroot для сборки.
Использование этой опции не рекомендуется, так как опять же это позволит процессам сборки получить доступ к не объявленным зависимостям. Это важно, даже если
guix-daemonзапущен под аккаунтом непривилегированного пользователя.--log-compression=typeАрхивировать логи сборки методом type. Это один из:
gzip,bzip2илиnone.Unless --lose-logs is used, all the build logs are kept in the localstatedir. To save space, the daemon automatically compresses them with gzip by default.
--discover[=yes|no]Следует ли обнаруживать сервера с заменителями в локальной сети с помощью mDNS and DNS-SD.
Эта функция все еще экспериментальная. Однако есть несколько соображений.
- Это может быть быстрее/дешевле, чем загрузка (fetching) с удаленных серверов;
- Никаких угроз безопасности, будут использоваться только подлинные заменители (see Аутентификация подстановок);
- Объявление злоумышленника
guix publishв вашей локальной сети не могут предоставить вам вредоносные двоичные файлы, но они могут узнать, какое программное обеспечение вы устанавливаете; - Серверы могут предоставить заменители через HTTP в незашифрованном виде, поэтому любой в локальной сети может видеть, какое программное обеспечение вы устанавливаете.
Также можно включить или отключить обнаружение сервера с заменителями во время выполнения, запустив:
herd discover guix-daemon on herd discover guix-daemon off
--disable-deduplication¶Отключить автоматическую "дедупликацию" файлов на складе.
По умолчанию файлы, добавленные на склад, автоматически "дедуплицируются": если вновь добавленный файл идентичен другому, найденному на складе, демон делает новый файл жесткой ссылкой на другой файл. Это существенно сокращает использование места на диске за счёт небольшого увеличения запросов ввода/вывода в конце процесса сборки. Эта опция отключает такую оптимизацию.
--gc-keep-outputs[=yes|no]Сообщить, должен ли сборщик мусора (GC) сохранять выходные данные живой деривации.
При установке в "yes" (да), сборщик мусора (GC) будет сохранять результаты любой живой деривации, доступной на складе, — файлы
.drv. Значение по умолчанию - "no" (нет) - означает, что результаты дериваций хранятся только, если они доступны из корней сборщика мусора (GC roots). Смотрите See Вызовguix gcдля информации о корнях сборщика мусора.--gc-keep-derivations[=yes|no]Сообщить, должен ли сборщик мусора (GC) сохранять деривации, соответствующие живым результатам.
При указании "yes" (да), что является значением по умолчанию, сборщик мусора сохраняет деривации, то есть файлы
.drv, до тех пор, пока любой из их выходов остаётся живым. Это позволяет пользователям отслеживать исходники элементов на складе. Установка в "no" (нет) немного экономит место на диске.Таким образом, установка
--gc-keep-derivationsв "yes" (да) даётт возможность пройти от результатов до дериваций, а установка--gc-keep-outputsв "yes" (да), делает возможным пройти от дериваций до результатов. Если оба установлены в "yes", тогда это сохранит всё используемое для сборки (исходники, компилятор, библиотеки и другие инструменты сборки) живых объектов на складе, без учёта, доступны эти инструменты сборки из корней сборщика мусора или нет. Это удобно для разработчиков, так как это сокращает пересборки или скачивания.--impersonate-linux-2.6На системах, основанных на Linux, выдавать себя за Linux 2.6. Это означает, что системный вызов ядра
unameбудет выдавать 2.6 номером релиза.Это полезно для сборки программ, которые (обычно по ошибке) зависят от версии ядра.
--lose-logsНе сохранять логи сборки. По умолчанию они сохраняются под
localstatedir/guix/log.--system=systemСчитать system текущим типом системы. По умолчанию это пара архитектура/ядро, обнаруженная во время конфигурации, например,
x86_64-linux.--listen=endpointСлушать соединения с endpoint. endpoint интерпретируется как имя файла сокета Unix-домена, если начинается с
/(знак слеша). В противном случае endpoint интерпретируется как имя хоста или им хоста и порт для прослушивания. Вот несколько примеров:--listen=/gnu/var/daemonСлушать соединения с сокетом Unix-домена /gnu/var/daemon, который создаётся при необходимости.
--listen=localhost¶-
Слушать соединения TCP сетевого интерфейса, относящиеся к
localhost, на порту 44146. --listen=128.0.0.42:1234Слушать соединения TCP сетевого интерфейса, относящиеся к
128.0.0.42, на порту 1234.
Эта опция может повторяться много раз, в таком случае
guix-daemonпринимает соединения на всех обозначенных точках. Пользователи могут через клиентские команды сообщать, через какие точки соединяться, для этого нужно устанавливать переменную окруженияGUIX_DAEMON_SOCKET(seeGUIX_DAEMON_SOCKET).Примечание: Протокол демона неаутентичный и нешифрованный. Использование
--listen=hostподходит локальным сетям, как например, кластерам, где только доверенные узлы могут соединяться с демоном сборки. В других случаях, когда необходим удалённый доступ к демону рекомендуется использовать сокеты Unix-домена вместе с SSH.Когда
--listenпропущена,guix-daemonслушает соединения с сокетом Unix-домена, расположенным в localstatedir/guix/daemon-socket/socket.
Next: Обновление Guix, Previous: Вызов guix-daemon, Up: Установка [Contents][Index]
2.6 Установка приложения
При использовании дистрибутива GNU/Linux, отличного от системы, называемого также чужой дистрибутив, необходимо несколько дополнительных шагов, чтобы всё работало. Вот некоторые из них.
2.6.1 Региональные настройки
Пакеты, установленные с помощью Guix, не будут использовать данные
локали хост-системы. Вместо этого вы должны вначале установить один из
пакетов локали, доступных в Guix, а затем определить переменную окружения
GUIX_LOCPATH:
$ guix install glibc-locales $ export GUIX_LOCPATH=$HOME/.guix-profile/lib/locale
Note that the glibc-locales package contains data for all the locales
supported by the GNU libc and weighs in at around
930 MiB9. If
you only need a few locales, you can define your custom locales package via
the make-glibc-utf8-locales procedure from the (gnu packages
base) module. The following example defines a package containing the
various Canadian UTF-8 locales known to the GNU libc, that weighs
around 14 MiB:
(use-modules (gnu packages base)) (define my-glibc-locales (make-glibc-utf8-locales glibc #:locales (list "en_CA" "fr_CA" "ik_CA" "iu_CA" "shs_CA") #:name "glibc-canadian-utf8-locales"))
Переменная GUIX_LOCPATH играет ту же роль, что и LOCPATH
(see LOCPATH in The GNU C Library Reference
Manual). Но есть два существенных различия:
-
GUIX_LOCPATHучитывается только libc в Guix, но не учитывается libc, предоставляемым чужим дистрибутивом. Так что использованиеGUIX_LOCPATHпозволяет вам убедиться, что программы чужого дистрибутива не будут производить загрузку несовместимых данных локали. - libc добавляет суффиксы
/X.Yк каждому компонентуGUIX_LOCPATH, гдеX.Y- это версия libc, например,2.22. Это значит, что если ваш профиль Guix будет содержать смесь программ, связанных с дугой версией libc, каждая версия libc будет пытаться загружать только данные локали в правильном формате.
Это важно, потому что использование данных локали другой версией libc может быть неприемлемо.
2.6.2 Служба выбора имён
При использовании Guix на чужом дистрибутиве мы настойчиво
рекомендуем, чтобы система запускала демон кеша имён сервисов
библиотеки GNU C, nscd, который должен слушать сокет
/var/run/nscd/socket. Если это не сделано, приложения, установленные
Guix, могут некорректно адресовать имена хостов или аккаунты пользователей и
даже падать. Ниже объясняется почему.
Библиотека GNU C реализует выбор имён сервисов (NSS), который представляет собой расширяемый механизм для резолвинга имён в целом: резолвинг имён хостов, аккаунтов пользователей и другое (see Name Service Switch in The GNU C Library Reference Manual).
Будучи расширяемым, NSS поддерживает плагины, которые предоставляют
реализации разрешения новых имён: плагин nss-mdns резолвит имена
хостов .local, плагин nis адресует пользовательские аккаунты,
используя сервис сетевой информации (NIS) и т.д. Эти дополнительные сервисы
адресации настраиваются для всей системы в /etc/nsswitch.conf, и все
запущенные в системе программы учитывают эти настройки (see NSS
Configuration File in The GNU C Reference Manual).
Когда выполняется разрешение имён, например, вызовом функции C
getaddrinfo, приложения вначале делают попытку соединиться с nscd; в
случае успеха nscd выполняет разрешение имён по их запросу. Если nscd не
запущен, тогда они выполняют разрешение имён самостоятельно, загружая
сервисы разрешения имён в их собственные адресные пространства и запуская
их. Эти сервисы разрешения имён — файлы libnss_*.so — запускаются
dlopen, но они могут поставляться системной библиотекой C, а не
библиотекой C, с которой залинковано приложение (библиотека C из Guix).
Вот где кроется проблема — если ваше приложение залинковано с библиотекой
C Guix (скажем, glibc 2.24) и пытается загрузить плагины NSS из другой
библиотеки C (скажем, libnss_mdns.so для glibc 2.22), это вероятно
вызовет падение или резолвинг имени завершится с ошибкой.
Запуск nscd в системе, помимо преимуществ, также исключает эту
проблему несовместимости программ, потому что файлы libnss_*.so
загружены в процессе nscd, а не в самом приложении.
2.6.3 Шрифты X11
The majority of graphical applications use Fontconfig to locate and load
fonts and perform X11-client-side rendering. The fontconfig package
in Guix looks for fonts in $HOME/.guix-profile by default. Thus, to
allow graphical applications installed with Guix to display fonts, you have
to install fonts with Guix as well. Essential font packages include
font-ghostscript, font-dejavu, and font-gnu-freefont.
После того, как вы установили или удалили шрифты, или когда вы заметили приложение, которое не находит шрифты, вам может потребоваться установить Fontconfig и принудительно обновить кэш шрифтов, выполнив:
guix install fontconfig fc-cache -rv
Для отображения в графических приложениях текста на китайском, японском,
корейском нужно установить font-adobe-source-han-sans или
font-wqy-zenhei. Первый имеет множественный выход, один для языковой
семьи (see Пакеты со множественным выходом). Например, следующая команда
устанавливает шрифты для китайских языков:
guix install font-adobe-source-han-sans:cn
Старые программы, например, xterm, не используют Fontconfig, а
вместо этого вызывают рендеринг шрифтов на стороне сервера. Таким программам
необходимо указывать полное имя шрифта, используя XLFD (X Logical Font
Description), примерно так:
-*-dejavu sans-medium-r-normal-*-*-100-*-*-*-*-*-1
Чтобы иметь возможность использовать такие полные имена для шрифтов TrueType, установленных в вашем профиле Guix, вам нужно расширить пути шрифтов X-сервера:
xset +fp $(dirname $(readlink -f ~/.guix-profile/share/fonts/truetype/fonts.dir))
После этого можно запустить xlsfonts (из пакета xlsfonts),
чтобы убедиться, что ваши шрифты TrueType находятся там.
2.6.4 Сертификаты X.509
Пакет nss-certs предоставялет сертификаты X.509, которые позволяют
программам аутентифицировать веб-серверы и работать через HTTPS.
При использовании Guix на чужом дистрибутиве можно установить этот пакет и определить соответствующие переменные окружения, чтобы пакеты знали, где искать сертификаты. Смотрите See Сертификаты X.509 для подробной информации.
2.6.5 Пакеты Emacs
Когда вы устанавливаете пакеты Emacs с Guix, файлы пакетов помещаются в
каталог share/emacs/site-lisp/ того профиля, в котором они
установлены. Библиотеки Elisp доступны для Emacs через переменную среды
EMACSLOADPATH, которая устанавливается при установке самого Emacs.
По умолчанию Emacs (установленный Guix) "знает", куда размещаются эти
пакеты, так что вам не нужно выполнять конфигурацию. Если по каким-либо
причинам вы хотите отменить автозагрузку пакетов Emacs, установленных с
помощью Guix, вы можете это сделать, запустив Emacs с опцией
--no-site-file (see Init File in The GNU Emacs Manual).
Примечание: Emacs can now compile packages natively. Under the default configuration, this means that Emacs packages will now be just-in-time (JIT) compiled as you use them, and the results stored in a subdirectory of your
user-emacs-directory.Furthermore, the build system for Emacs packages transparently supports native compilation, but note, that
emacs-minimal—the default Emacs for building packages—has been configured without native compilation. To natively compile your emacs packages ahead of time, use a transformation like --with-input=emacs-minimal=emacs.
Previous: Установка приложения, Up: Установка [Contents][Index]
2.7 Обновление Guix
Чтобы обновить Guix, запустите:
guix pull
See Вызов guix pull для дополнительной информации.
В ином дистрибутиве вы можете обновить демон сборки, запустив:
sudo -i guix pull
затем (при условии, что ваш дистрибутив использует инструмент управления сервисами systemd):
systemctl restart guix-daemon.service
В системе Guix обновление демона достигается путем перенастройки системы
(see guix system reconfigure).
Next: System Troubleshooting Tips, Previous: Установка, Up: GNU Guix [Contents][Index]
3 Установка системы
Этот раздел объясняет, как установить систему Guix на компьютер. Guix, как пакетный менеджер, можно также установить на уже установленную систему GNU/Linux (see Установка).
- Ограничения
- По поводу железа
- Установочная флеш и DVD
- Подготовка к установке
- Графическая установка в GUI
- Ручная установка
- После установки системы
- Установка Guix на виртуальную машину (VM)
- Сборка установочного образа
- Сбрка и установка образа для плат ARM
Next: По поводу железа, Up: Установка системы [Contents][Index]
3.1 Ограничения
Мы полагаем, система Guix будет широко применяться для офисных и серверных решений. Гарантия надёжности основана на транзакционных обновлениях, откатах и воспроизводимости. Это наше прочное основание.
Тем не менее, перед началом установки, ознакомьтесь с важной информацией об ограничениях версии 1.4.0:
- Мы постоянно добавляем новые сервисы (see Сервисы), но некоторые могут отсутствовать.
- Доступные GNOME, Xfce, LXDE и Enlightenment (see Сервисы рабочего стола), а также ряд оконных менеджеров X11. Однако, KDE в настоящее время отсутствует.
Мы настойчиво призываем вас присылать отчёты о проблемах (или историиуспеха!). Присоединяйтесь к нам, если вы хотите улучшить Guix. Смотрите See Содействие, чтобы узнать больше.
Next: Установочная флеш и DVD, Previous: Ограничения, Up: Установка системы [Contents][Index]
3.2 По поводу железа
GNU Guix особенно заботится об уважении свободы пользователя при работе за компьютером. Она построена на ядре Linux-libre, что означает, что поддерживается только аппаратное обеспечение, которое имеет свободные драйверы и прошивки. Сегодня широкий список наличествующей аппаратуры поддерживается GNU/Linux-libre — от клавиатур и графических карт до сканеров и контроллеров Ethernet. К сожалению, всё ещё остаётся ряд производителей железа, которые запрещают пользователям управлять их устройствами, и такое аппаратное обеспечение не поддерживается системой Guix.
Основной областью, в которой отсутствуют свободные драйверы и прошивки,
являются устройства Wi-Fi. Работают устройства Wi-Fi, которые используют
платы Atheros (AR9271 и AR7010) и взаимодействуют с драйвером Linux-libre
ath9k, также использующие платы Broadcom/AirForce (BCM43xx with
Wireless-Core Revision 5), которые работают с драйвером Linux-libre
b43-open. Свободная прошивка существует для обоих и доступна в
системе Guix из коробки как часть %base-firmware
(see firmware).
The installer warns you early on if it detects devices that are known not to work due to the lack of free firmware or free drivers.
Фонд свободного программного обспечения FSF ведёт Уважение вашей свободы (RYF) — программу сертификации аппаратного обеспечения, которое уважает вашу свободу и вашу безопасность и утверждает, что вы имеете контроль над вашими устройствами. Мы побуждаем вас проверить список устройств, сертифицированных RYF.
Другой полезный ресурс — сайт H-Node. Он содержит каталог устройств с информацией об их поддержке в GNU/Linux.
Next: Подготовка к установке, Previous: По поводу железа, Up: Установка системы [Contents][Index]
3.3 Установочная флеш и DVD
Установочный образ ISO-9660 может быть записан на USB-флеш или DVD, скачать
его можно по адресу:
‘https://alpha.gnu.org/gnu/guix/guix-system-install-1.4.0.system.iso’,
где system одна из следующих:
x86_64-linuxдля системы GNU/Linux на 64-битных Intel/AMD-совместимых процессорах;
i686-linuxдля системы GNU/Linux на 32-битных Intel-совместимых процессорах.
Обязательно скачайте связанный файл подписи .sig и проверьте аутентичность образа так:
$ wget https://ftp.gnu.org/gnu/guix/guix-system-install-1.4.0.x86_64-linux.iso.sig $ gpg --verify guix-system-install-1.4.0.x86_64-linux.iso.sig
Если это завершается ошибкой, значит у вас нет необходимого публичного ключа, тогда запустите команду для импорта ключа:
$ wget https://sv.gnu.org/people/viewgpg.php?user_id=15145 \
-qO - | gpg --import -
и запустите команду gpg --verify.
Обратите внимание, что предупреждение по типу «Этот ключ не сертифицирован с доверенной подписью!» является нормальным.
Этот образ содержит инструменты, необходимые для установки. Он должен копироваться как есть на большую USB-флеш или DVD.
Запись на USB-флеш
Вставьте в компьютер USB-флеш объёмом 1 Гб или более и определите его имя. Учитывая имя (обычно соответствующее /dev/sdX) скопируйте образ на него:
dd if=guix-system-install-1.4.0.x86_64-linux.iso of=/dev/sdX status=progress sync
Доступ к /dev/sdX обычно требует привилегий root.
Запись на DVD
Вставьте чистый DVD в компьютер и определите имя устройства. Обычно DVD определяется как /dev/srX, скопируйте образ так:
growisofs -dvd-compat -Z /dev/srX=guix-system-install-1.4.0.x86_64-linux.iso
Доступ к /dev/srX обычно требует привилегий root.
Загрузка
Когда это сделано, вы должны перезагрузить систему и загрузиться с USB-флеш или DVD. Последнее обычно требует доступа к меню BIOS или UEFI, где можно выбрать загрузку с USB-флеш.
Смотрите See Установка Guix на виртуальную машину (VM), если вы хотите установить систему Guix на виртуальную машину (VM).
Next: Графическая установка в GUI, Previous: Установочная флеш и DVD, Up: Установка системы [Contents][Index]
3.4 Подготовка к установке
Когда вы загрузитесь, вы можете использовать графическую установку, которая намного проще для начала (see Графическая установка в GUI). Или если вы уже знакомы с GNU/Linux или вы хотите больший контроль, чем это предоставляет графическая установка, вы можете выбрать ручной процесс установки (see Ручная установка).
Графическа установка доступна в TTY1. Вы можете запустить оболочку root в TTY 3-6, нажимая ctrl-alt-f3, ctrl-alt-f4 и т.д. TTY2 отображает эту документацию, открыть его можно клавишами ctrl-alt-f2. Листать документацию можно командами просмотрщика Info (see Stand-alone GNU Info). Установка системы запускает демона мыши GPM, который позволяет вам выделять текст лековй кнопкой мыши и вставлять средней кнопкой.
Примечание: Установка требует доступа к Интернету, чтобы скачивать любые отсутствующие зависимости в вашей конфигурации системы. Смотрите раздел "Сеть" ниже.
Next: Ручная установка, Previous: Подготовка к установке, Up: Установка системы [Contents][Index]
3.5 Графическая установка в GUI
Графический установщик представляет собой текстовый интерфейс. Он взаимодействует через диалоговые блоки, проходя шаги установки системы GNU Guix.
Первый диалоговый блок позволяет вам установить систему в таком виде, как во время установки. Вы можете выбрать язык, раскладку клавиатуры, задать настройки сети для установки. На картинке ниже — диалог настройки сети.

Следующие шаги позволят вам разметить диск, как это показано на картинке ниже. Также можно выбрать шифрование вайловой системы (или без шифрования), ввести имя хоста и пароль root, создать дополнительную учётную запись и другие действия.
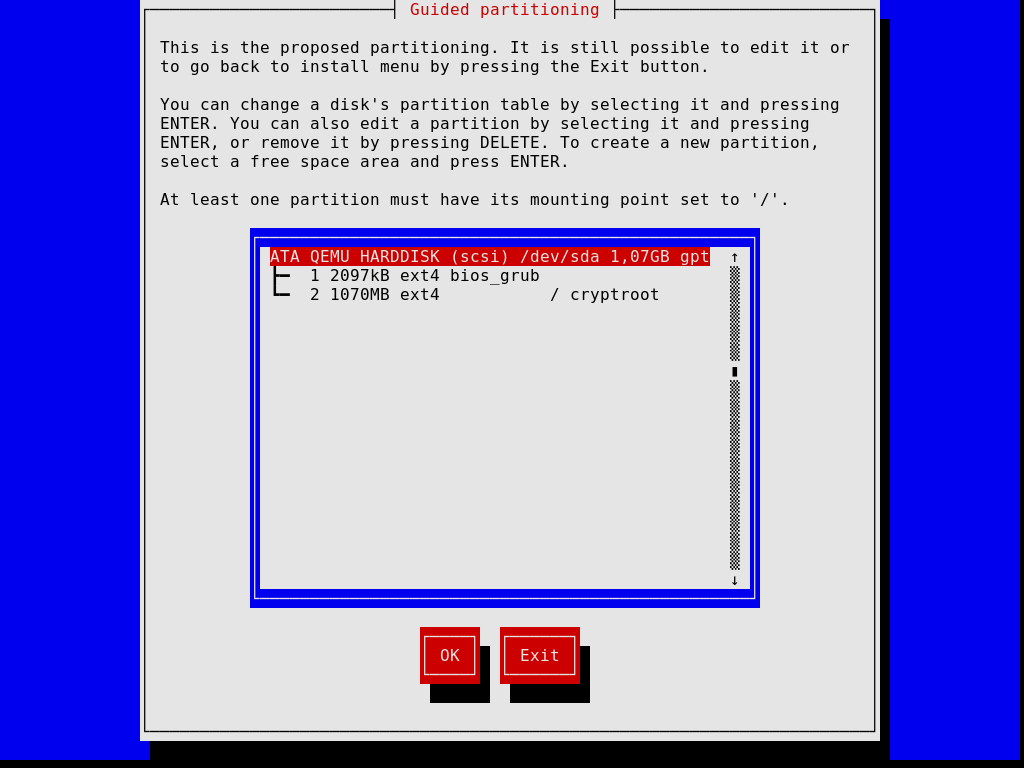
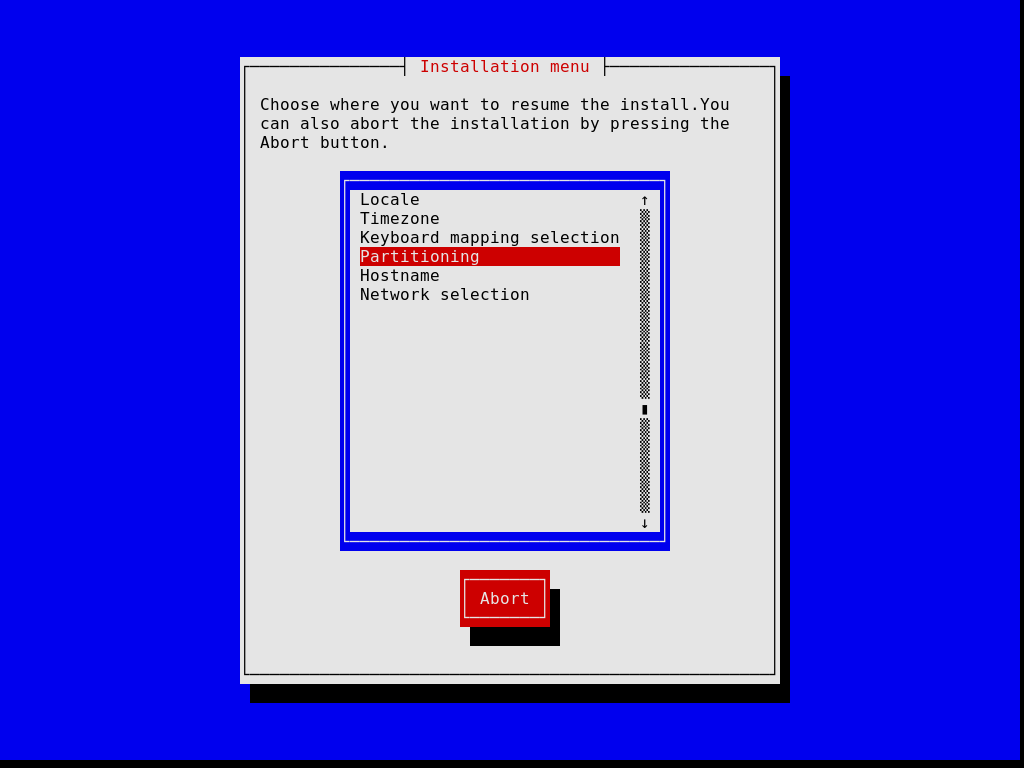
Отметим, что в любое время установщик позволяет вам отменить текущий шаг и вернуться к предыдущему шагу установки, как это показано на картинке ниже.
Когда настройки выполнены, установщик сгенерирует конфигурацию операционной системы и отобразит её (see Использование системы конфигурации). На этом этапе нажатие “OK” запустит установку. После успешнго завершения нужно перезагрузиться и использовать новую систему. Смотрите See После установки системы, чтобы узнать ещё больше!
Next: После установки системы, Previous: Графическая установка в GUI, Up: Установка системы [Contents][Index]
3.6 Ручная установка
Этот раздел описывает, как можно вручную установить систему GNU Guix на вашу машину. Это потребует знаний GNU/Linux, оболочки и инструментов администрирования. Если вы считаете, это не для вас, используйте вариант графической установки (see Графическая установка в GUI).
The installation system provides root shells on TTYs 3 to 6; press
ctrl-alt-f3, ctrl-alt-f4, and so on to reach them. It includes
many common tools needed to install the system, but is also a full-blown
Guix System. This means that you can install additional packages, should
you need it, using guix package (see Вызов guix package).
Next: В продолжении установки, Up: Ручная установка [Contents][Index]
3.6.1 Раскладка клавиатуры, Сеть, Разметка диска
Перед установкой системы вам может понадобиться смена раскладки клавиатуры, а также настройка сети и разметка целевого жёсткого диска. В этом разделе приведены соответствующие инструкции.
3.6.1.1 Раскладка клавиатуры
Установочный образ использует раскладку клавиатуры US qwerty. Если нужно
поменять её, можно пользоваться командой loadkeys. Например,
следующая команда выбирает раскладку клавиатуры Dvorak:
loadkeys dvorak
Смотрите файлы в /run/current-system/profile/share/keymaps, чтобы
найти список доступных раскладок. Запустите man loadkeys, чтобы
узнать больше.
3.6.1.2 Сеть
Запустите следующую команду, чтобы узнать имена сетевых интерфейсов:
ifconfig -a
… или используйте специальную команду GNU/Linux ip:
ip address
Проводные интерфейсы называются на букву ‘e’; например, интерфейс, соответствующий первому контроллеру Ethernet на материнской плате, называется ‘eno1’. Беспроводные интерфейсы имеют имена, начинающиеся с ‘w’, как ‘w1p2s0’.
- Проводное соединение
Чтобы настроить проводную сеть, запустите следующую команду, заменив interface именем проводного интерфейса, который вы хотите использовать.
ifconfig interface up
… или используйте специальную команду GNU/Linux
ip:ifconfig interface up
- Беспроводное соединение ¶
-
Чтобы настроить беспроводную сеть, можно создать конфигурционный файл для
wpa_supplicant(расположение файла неважно). Можно пользоваться любым доступным текстовым редактором, например,nano:nano wpa_supplicant.conf
Следующий пример настроек подойдёт для большинства беспроводных сетей. Нужно предоставить фактический SSID и парольную фразу для сети, к которой вы подключаетесь:
network={ ssid="my-ssid" key_mgmt=WPA-PSK psk="the network's secret passphrase" }Запустите сервис беспроводной сети в фоновом режиме следующей командой (замените interface именем сетевого интерфейса, который вы используете):
wpa_supplicant -c wpa_supplicant.conf -i interface -B
Запустите
man wpa_supplicant, чтобы узнать больше.
Теперь нужно получить IP-адрес. В случае сети, где IP-адреса автоматически распределяются с помощью DHCP, можно запустить:
dhclient -v interface
Попробуйте пинговать сервер, чтобы узнать, работает ли сеть:
ping -c 3 gnu.org
Настройка доступа к сети необходима почти всегда, потому что ораз может не иметь программное обеспечение и инструменты, которые могут понадобиться.
Если вам нужено настроить доступ HTTP и HTTPS прокси, выполните следующую команду:
herd set-http-proxy guix-daemon URL
где URL адрес прокси, например http://example.org:8118.
Если желаете, вы можете продолжить установку удалённо, запустив SSH-сервер:
herd start ssh-daemon
Не забудьте задать пароль командой passwd или настроить публичный
ключ OpenSSH для аутентификации, чтобы иметь возможность подключиться.
3.6.1.3 Разметка диска
Если это ещё не сделано, тогда нужно разделить диск, а затем отформатировать целевой(-ые) раздел(ы).
Установочный образ содержит несколько инструментов для разметки, включая
Parted (see Overview in GNU Parted User Manual), fdisk
и cfdisk. Запустите и настройте ваш диск, используя план разметки,
который нужен:
cfdisk
Если ваш диск использует формат GUID Partition Table (GPT), и вы планируете использовать GRUB, работающий с BIOS (что по умолчанию), убедитесь, что раздел BIOS Boot Partition доступен (see BIOS installation in GNU GRUB manual).
Если вместо этого вы хотите использовать GRUB, работающий с EFI, тогда
необходима разметка система EFI FAT32 (ESP). Такая разметка может,
например, монтироваться в /boot/efi и должна иметь флаг
esp. То есть в случае parted:
parted /dev/sda set 1 esp on
Примечание: Не уверенны, что выбрать: GRUB, взаимодействующий с EFI или BIOS? Если существует директория /sys/firmware/efi в установочом образе, тогда вам следует использовать установку EFI и
grub-efi-bootloader. В противном случае нужно использовать GRUB, работающий с BIOS, называемыйgrub-bootloader. Смотрите See Настройка загрузчика для большей информации о загрузчиках.
Когда разметка целевого диска выполнена, нужно создать файловую систему на соответствующем(-их) разделе(-ах)10. В случае ESP, если у вас раздел /dev/sda1, выполните:
mkfs.fat -F32 /dev/sda1
Для корневой файловой системы наиболее широко используется формат ext4. Другие файловые системы, такие как Btrfs, поддерживают сжатие, которое, как известно, прекрасно дополняет дедупликацию файлов, которую демон выполняет независимо от файловой системы (see deduplication).
Желательно добавить метки файловых систем, чтобы вы могли ссылаться на них
по именам в объявлениях file-system (see Файловые системы). Обычно
это можно сделать опцией -L в mkfs.ext4,
например. Допустим, раздел root располагается в /dev/sda2, можно
добавить метку my-root следующим образом:
mkfs.ext4 -L my-root /dev/sda2
If you are instead planning to encrypt the root partition, you can use the
Cryptsetup/LUKS utilities to do that (see man cryptsetup for more information).
Внимание: Note that GRUB can unlock LUKS2 devices since version 2.06, but only supports the PBKDF2 key derivation function, which is not the default for
cryptsetup luksFormat. You can check which key derivation function is being used by a device by runningcryptsetup luksDump device, and looking for the PBKDF field of your keyslots.
Assuming you want to store the root partition on /dev/sda2, the command sequence to format it as a LUKS2 partition would be along these lines:
cryptsetup luksFormat --type luks2 --pbkdf pbkdf2 /dev/sda2 cryptsetup open /dev/sda2 my-partition mkfs.ext4 -L my-root /dev/mapper/my-partition
Когда это сделано, монтируйте целевую файловую систему под /mnt
следующей командой (опять же полагая, что метка раздела root —
my-root):
mount LABEL=my-root /mnt
Также монтируйте любые другие файловые системы внутрь целевой файловой
системы. Если например, выбрана точка монтирования EFI /boot/efi,
монтируйте её в /mnt/boot/efi, так, чтобы она обнаруживалась после
запуска guix system init.
Finally, if you plan to use one or more swap partitions (see Swap Space), make sure to initialize them with mkswap. Assuming you
have one swap partition on /dev/sda3, you would run:
mkswap /dev/sda3 swapon /dev/sda3
Возможно, вместо этого вы используете swap-файл. Например, предположим, вы хотите использовать в новой системе swap-файл в /swapfile, тогда нужно выполнить11:
# This is 10 GiB of swap space. Adjust "count" to change the size. dd if=/dev/zero of=/mnt/swapfile bs=1MiB count=10240 # For security, make the file readable and writable only by root. chmod 600 /mnt/swapfile mkswap /mnt/swapfile swapon /mnt/swapfile
Заметим, что если вы шифруете раздел root и создаёте swap-файл в его файловой системе, как это описано выше, шифрование также будет защищать swap-файл, как и любой другой файл в этой файловой системе.
Previous: Раскладка клавиатуры, Сеть, Разметка диска, Up: Ручная установка [Contents][Index]
3.6.2 В продолжении установки
Когда целевые разделы готовы и раздел root монтирован под /mnt, всё готово для старта. Сначала запустите:
herd start cow-store /mnt
Это сделает /gnu/store копируемым при записи (copy-on-write), что
заставит систему записывать пакеты, добавляемые в систему на этапе
установки, на целевой диск под /mnt, а не держать их в памяти. Это
важно, потому что по команде guix system init (смотрите ниже)
будут скачиваться или собираться пакеты в /gnu/store, которая
изначально находится в файловой системе, загрузженной в память.
Next, you have to edit a file and provide the declaration of the operating
system to be installed. To that end, the installation system comes with
three text editors. We recommend GNU nano (see GNU nano
Manual), which supports syntax highlighting and parentheses matching; other
editors include mg (an Emacs clone), and nvi (a clone of the original BSD
vi editor). We strongly recommend storing that file on the target
root file system, say, as /mnt/etc/config.scm. Failing to do that,
you will have lost your configuration file once you have rebooted into the
newly-installed system.
Смотрите See Использование системы конфигурации для подробностей о конфигурационном файле. Конфигурационный файл для примера доступен под /etc/configuration установочного образа. Например, чтобы получить систему с графическим сервером (т.е. десктопную систему), можно это сделать примерно так:
# mkdir /mnt/etc # cp /etc/configuration/desktop.scm /mnt/etc/config.scm # nano /mnt/etc/config.scm
Нужно уделить внимание содержимому конфигурационного файла, в частности:
- Make sure the
bootloader-configurationform refers to the targets you want to install GRUB on. It should mentiongrub-bootloaderif you are installing GRUB in the legacy way, orgrub-efi-bootloaderfor newer UEFI systems. For legacy systems, thetargetsfield contain the names of the devices, like(list "/dev/sda"); for UEFI systems it names the paths to mounted EFI partitions, like(list "/boot/efi"); do make sure the paths are currently mounted and afile-systementry is specified in your configuration. - Убедитесь, чтобы в полях
deviceбыли указаны метки ваших файловых систем внутри конфигурацииfile-system, если конечно, конфигурацияfile-systemиспользует процедуруfile-system-labelв полеdevice. - При наличии шифрованных разделов RAID, обязательно добавьте поле
mapped-devices, чтобы описать их (see Размеченные устройства).
Когда вы подготовили конфигурационный файл, нужно инициализировать новую систему (помните, что целевой раздел root монтирован под /mnt):
guix system init /mnt/etc/config.scm /mnt
Это копирует все нужные файлы и устанавливает GRUB в /dev/sdX, если
конечно, вы не задали опцию --no-bootloader. Подробнее -
see Invoking guix system. Эта команда может вызывать скачивание или
сборку отсутствующих пакетов, что может занять время.
Когда эта команда завершена, надеемся, успешно, можно запустить
reboot и загрузиться в новую систему. Пароль root в новой
системе изначально пустой; пароли других пользователей должны быть заданы
командой passwd от root, если конечно, ваша конфиурация не
содержит указания (see user account
passwords). Смотрите See После установки системы, чтобы узнать, что
дальше!
Next: Установка Guix на виртуальную машину (VM), Previous: Ручная установка, Up: Установка системы [Contents][Index]
3.7 После установки системы
Замечательно! Теперь вы загрузились в систему Guix! Теперь можно обновить систему, когда у вас будет на это время, запустив, например:
guix pull sudo guix system reconfigure /etc/config.scm
Это соберёт поколение (generation) системы с последними пакетами и сервисами
(see Invoking guix system). Мы рекомендуем делать это регулярно, чтобы
ваша система содержала обновления безопасности (see Обновления безопасности).
Примечание: Отметим, что
sudo guixзапускает командуguixот вашего пользователя, но не от root, потому чтоsudoне меняетPATH. Чтобы вместо этого запуститьguixот root, напечатайтеsudo -i guix ….Разница важна, потому что
guix pullобновляет командуguixи определения пакетов только для пользователя, от имени которого она запускается. Это означает, что если вы решите использоватьguix system reconfigureот имени root, вам нужно будет запуститьguix pullотдельно.
Присоединяйтесь к нашему IRC-каналу #guix в сети Freenode или пишите
на guix-devel@gnu.org, чтобы поделиться опытом!
Next: Сборка установочного образа, Previous: После установки системы, Up: Установка системы [Contents][Index]
3.8 Установка Guix на виртуальную машину (VM)
Если вы хотите установить систему Guix на виртуальную машину (VM) или на виртуальный приватный сервер (VPS) вместо вашей любимой машины, этот раздел для вас.
Чтобы загрузить Guix в QEMU VM и установить образ, выполните шаги:
- Во-первых, найдите и распакуйте установочный образ системы Guix, как описано ранее (see Установочная флеш и DVD).
- Создайте образ диска, который будет содержать установленную систему. Чтобы
создать образ диска qcow2, используйте команду
qemu-img:qemu-img create -f qcow2 guixsd.img 50G
Результирующий файл будет намного меньше 50Гб (обычно менее 1Мб), но он будет увеличиваться с заполнение виртуального устройства.
- Загрузите установочный образ USB в VM:
qemu-system-x86_64 -m 1024 -smp 1 -enable-kvm \ -nic user,model=virtio-net-pci -boot menu=on,order=d \ -drive file=guix-system.img \ -drive media=cdrom,file=guix-system-install-1.4.0.system.iso
-enable-kvmопционален, но значительно улучшает производительность, see Running Guix in a Virtual Machine. - Теперь вы в корне VM, проделайте процесс установки See Подготовка к установке и последующие инструкции.
Когда установка завершена, можно загрузиться в систему, которая расположена в образе guixsd.img. Смотрите See Running Guix in a Virtual Machine, чтобы узнать, как это сделать.
Previous: Установка Guix на виртуальную машину (VM), Up: Установка системы [Contents][Index]
3.9 Сборка установочного образа
Установочный образ, описанный выше, собран командой guix system, а
именно:
guix system disk-image -t iso9660 gnu/system/install.scm
Нужно просмотреть gnu/system/install.scm в дереве исходников, а также
Invoking guix system, чтобы получить больше информации об установочном
образе.
3.10 Сбрка и установка образа для плат ARM
Многие платы ARM требуют специфический вариант загрузчика U-Boot.
Если вы собираете образ диска, а загрузчик не доступен (на другом устройстве загрузке и т.п.), советуем собрать образ, который включает загрузчик, то есть так:
guix system disk-image --system=armhf-linux -e '((@ (gnu system install) os-with-u-boot) (@ (gnu system install) installation-os) "A20-OLinuXino-Lime2")'
A20-OLinuXino-Lime2 — это имя материнской платы. Если вы обозначите
недействительную плату, будет выведен список возможных плат.
Next: Начиная, Previous: Установка системы, Up: GNU Guix [Contents][Index]
4 System Troubleshooting Tips
Guix System allows rebooting into a previous generation should the last one be malfunctioning, which makes it quite robust against being broken irreversibly. This feature depends on GRUB being correctly functioning though, which means that if for whatever reasons your GRUB installation becomes corrupted during a system reconfiguration, you may not be able to easily boot into a previous generation. A technique that can be used in this case is to chroot into your broken system and reconfigure it from there. Such technique is explained below.
4.1 Chrooting into an existing system
This section details how to chroot to an already installed Guix System with the aim of reconfiguring it, for example to fix a broken GRUB installation. The process is similar to how it would be done on other GNU/Linux systems, but there are some Guix System particularities such as the daemon and profiles that make it worthy of explaining here.
- Obtain a bootable image of Guix System. It is recommended the latest development snapshot so the kernel and the tools used are at least as as new as those of your installed system; it can be retrieved from the https://ci.guix.gnu.org URL. Follow the see Установочная флеш и DVD section for copying it to a bootable media.
- Boot the image, and proceed with the graphical text-based installer until your network is configured. Alternatively, you could configure the network manually by following the manual-installation-networking section. If you get the error ‘RTNETLINK answers: Operation not possible due to RF-kill’, try ‘rfkill list’ followed by ‘rfkill unblock 0’, where ‘0’ is your device identifier (ID).
- Switch to a virtual console (tty) if you haven’t already by pressing
simultaneously the Control + Alt + F4 keys. Mount your file system at
/mnt. Assuming your root partition is /dev/sda2, you would
do:
mount /dev/sda2 /mnt
- Mount special block devices and Linux-specific directories:
mount --bind /proc /mnt/proc mount --bind /sys /mnt/sys mount --bind /dev /mnt/dev
If your system is EFI-based, you must also mount the ESP partition. Assuming it is /dev/sda1, you can do so with:
mount /dev/sda1 /mnt/boot/efi
- Enter your system via chroot:
chroot /mnt /bin/sh
- Source the system profile as well as your user profile to setup the
environment, where user is the user name used for the Guix System you
are attempting to repair:
source /var/guix/profiles/system/profile/etc/profile source /home/user/.guix-profile/etc/profile
To ensure you are working with the Guix revision you normally would as your normal user, also source your current Guix profile:
source /home/user/.config/guix/current/etc/profile
- Start a minimal
guix-daemonin the background:guix-daemon --build-users-group=guixbuild --disable-chroot &
- Edit your Guix System configuration if needed, then reconfigure with:
guix system reconfigure your-config.scm
- Finally, you should be good to reboot the system to test your fix.
Next: Управление пакетами, Previous: System Troubleshooting Tips, Up: GNU Guix [Contents][Index]
5 Начиная
Предположительно, вы попали в этот раздел, потому что либо вы установили Guix поверх другого дистрибутива (see Установка), либо вы установили отдельную операционную систему Guix (see Установка системы). Пора вам начать использовать Guix, и этот раздел призван помочь вам в этом.
Guix занимается установкой программного обеспечения, поэтому, вероятно, первое, что вам нужно сделать, это поискать программное обеспечение. Допустим, вы ищете текстовый редактор, вы можете запустить:
guix search text editor
Эта команда показывает количество подходящих пакетов, каждый раз показывая имя пакета, версию, описание и дополнительную информацию. Как только вы определились с тем, какой пакет хотите использовать, скажем, Emacs (ха!), вы можете установить его следующей командой (запустите эту команду как обычный пользователь, root привилегии не нужны!):
guix install emacs
Вы установили свой первый пакет, поздравляю! В процессе вы, вероятно, заметили, что Guix загружает заранее собранные двоичные файлы; или, если вы явно решили не использовать предварительно созданные двоичные файлы, то, вероятно, Guix все еще собирает программное обеспечение (see Подстановки, для дополнительной информации).
Пока вы используете Guix System, guix install команда должна
выводить данную подсказку:
hint: Consider setting the necessary environment variables by running:
GUIX_PROFILE=\"$HOME/.guix-profile\"
. \"$GUIX_PROFILE/etc/profile\"
Или смотрите `guix package --search-paths -p "$HOME/.guix-profile"'.
Indeed, you must now tell your shell where emacs and other
programs installed with Guix are to be found. Pasting the two lines above
will do just that: it will add $HOME/.guix-profile/bin—which is
where the installed package is—to the PATH environment variable.
You can paste these two lines in your shell so they take effect right away,
but more importantly you should add them to ~/.bash_profile (or
equivalent file if you do not use Bash) so that environment variables are
set next time you spawn a shell. You only need to do this once and other
search paths environment variables will be taken care of similarly—e.g.,
if you eventually install python and Python libraries,
GUIX_PYTHONPATH will be defined.
Вы можете продолжать установку пакетов по своему желанию. Чтобы вывести список установленных пакетов, запустите:
guix package --list-installed
Для удаления пакета вы можете выполнить команду guix remove.
Отличительная черта - возможность откатить любую операцию, которую вы
сделали (установка, удаление, обновление):
guix package --roll-back
Каждая операция фактически является транзакцией, которая создает новое поколение. Эти поколения и разницу между ними можно отобразить, запустив:
guix package --list-generations
Теперь вы знаете основы управления пакетами!
Больше информации: See Управление пакетами, для получения дополнительной информации об управлении пакетами. Вам может понравиться декларативное управление пакетами с помощью
guix package --manifest, управление отдельными профилями с помощью --profile, удаление старых поколений, сбор мусора и другие полезные функции, которые помогут пригодится по мере того, как вы ближе познакомитесь с Guix. Если вы разработчик, see Разработка для получения дополнительных инструментов. И если вам интересно, see Особенности, чтобы заглянуть под капот.
После того, как вы установили набор пакетов, вам нужно будет периодически обновлять их до последней и самой лучшей версии. Для этого вы сначала загрузите последнюю версию Guix и его коллекцию пакетов:
guix pull
Конечным результатом является новая команда guix в
~/.config/guix/current/bin. Если вы не используете Guix System, при
первом запуске guix pull обязательно следуйте подсказке, которую
выводит команда, и, подобно тому, что мы видели выше, вставьте эти две
строки в свой терминал и .bash_profile:
GUIX_PROFILE="$HOME/.config/guix/current/etc/profile" . "$GUIX_PROFILE/etc/profile"
Вы также должны указать своей оболочке, чтобы она указывала на новую команду
guix:
hash guix
На данный момент вы используете новый Guix. Вы можете обновить все ранее установленные пакеты:
guix upgrade
Когда вы запустите эту команду, вы увидите, что загружены двоичные файлы (или, возможно, собраны некоторые пакеты), и в конечном итоге вы получите обновленные пакеты. Если один из этих обновленных пакетов вам не понравится, помните, что вы всегда можете выполнить откат!
Вы можете отобразить точную версию Guix, которую сейчас используете, запустив:
guix describe
Отображаемая информация - это все, что нужно для воспроизведения того же самого Guix, будь то в другой момент времени или на другой машине.
Больше информации: See Вызов
guix pull, для дополнительной информации. See Каналы, как указать дополнительные каналы для получения пакетов, как реплицировать Guix и т. д. Также командаtime-machineможет оказаться полезной (see Запускguix time-machine).
Если вы установили Guix System, первое, что вам нужно сделать, это обновить
вашу систему. После того, как вы запустите команду guix pull,
чтобы получить последнюю версию Guix, вы можете обновить систему следующим
образом:
sudo guix system reconfigure /etc/config.scm
По завершении в системе будут запущены последние версии пакетов. Когда вы перезагрузите машину, вы заметите подменю в загрузчике “Old system generations”: это то, что позволяет вам загружать старшее поколение вашей системы, если последнее поколение “сломано” или не соответствует вашим ожиданиям. Как и в случае с пакетами, вы всегда можете откатиться на предыдущее поколение всей системы:
sudo guix system roll-back
Есть много вещей, которые вы, вероятно, захотите настроить в своей системе: добавление новых учетных записей пользователей, добавление новых системных служб, изменение конфигурации этих служб и т.д. Конфигурация системы полностью определена в файле /etc/config.scm. See Использование системы конфигурации, узнать о настройке системы.
Теперь вы знаете достаточно, чтобы начать!
Ресурсы: Остальная часть этого руководства представляет собой справочник по всему, что связано с Guix. Вот несколько дополнительных ресурсов, которые могут вам пригодиться:
- See The GNU Guix Cookbook, статьи с готовыми решениями для различных ситуаций в стиле “how-to”.
- GNU Guix Reference Card шпаргалка с большинством команд и опций, которые вам когда-либо понадобятся.
- Веб-сайт содержит обучающие видеоролики по таким темам, как повседневное использование Guix, как получить помощь и как стать участником сообщества.
- See Документация, чтобы узнать, как получить доступ к документации на вашем компьютере.
Мы надеемся, что вам понравится Guix так же, как и сообществу нравится его создавать!
6 Управление пакетами
Целью GNU Guix является предоставление пользователям возможности легко устанавливать, обновлять и удалять пакеты программного обеспечения, без необходимости изучения процедур их сборки и без необходимости разрешения зависимостей. Также Guix имеет следующие обязательные особенности.
Этот раздел описывает основные особенности Guix и предоставляемые им
инструменты управления пакетами. Кроме интерфейса командной строки, который
описан ниже (see guix package), можно
также использовать интерфейс Emacs-Guix (see The
Emacs-Guix Reference Manual), если установить пакет emacs-guix
(выполните команду M-x guix-help, чтобы начать работу с ним):
guix install emacs-guix
- Особенности
- Вызов
guix package - Подстановки
- Пакеты со множественным выходом
- Вызов
guix gc - Вызов
guix pull - Запуск
guix time-machine - Младшие версии
- Вызов
guix describe - Вызов
guix archive
Next: Вызов guix package, Up: Управление пакетами [Contents][Index]
6.1 Особенности
Здесь мы предполагаем, что вы уже сделали свои первые шаги с Guix (see Начиная) и хотели бы получить обзор того, что происходит под капотом.
При использовании Guix каждый пакет после установки размещается в
package store, в собственной директории, например,
/gnu/store/xxx-package-1.2, где xxx - это строка base32.
Вместо того, чтобы ссылаться на эти директории, пользователям нужно
обращаться к их профилям, профиль указывает на пакеты, которые они
хотят использовать. Эти профили хранятся в домашней директории каждого
пользователя в $HOME/.guix-profile.
Например, alice устанавливает GCC 4.7.2. В результате
/home/alice/.guix-profile/bin/gcc указывает на
/gnu/store/…-gcc-4.7.2/bin/gcc. Допустим, на той же машине
bob установил GCC 4.8.0. Профиль пользователя bob просто
указывает на /gnu/store/…-gcc-4.8.0/bin/gcc. То есть обе версии
GCC присутствуют в одной системе без помех.
Команда guix package — главный инструмент для управления
пакетами (see Вызов guix package). Она работает с профилями
пользователей, которые имеют права обычных пользователей.
Команда предоставляет обязательные операции установки, удаления и
обновления. Каждый вызов представляет собой транзакцию, независимо от
того, выполнены успешно заданные операции, или ничего не произошло. Так,
если процесс guix package завершился во время транзакции, или
произошёл сбой питания во время транзакции, тогда профиль пользователя
остаётся в исходном состоянии, готовом к использованию.
В дополнение, каждую транзакцию, которая работает с пакетами, можно откатить. Так если, например, обновление устанавливает новую версию пакета, которая имеет серьёзный баг, пользователи могут откатиться до предыдущей инстанции своего профиля, который работал нормально. Точно так же, глобальные настройки системы Guix являются объектом транзакционных обновлений и откатов (see Использование системы конфигурации).
Все пакеты на складе могут быть собраны как мусор. Guix может
определить, какие пакеты всё ещё используются профилями пользователей, и
удалить те, которые однозначно больше не используются (see Вызов guix gc). Также пользователи могут явно удалить старые поколения (generations)
их профилей, поэтому пакеты, на которые ссылались старые профили, могут быть
удалены.
Guix реализует чисто функциональный подход к управлению пакетами, как описано во введении (see Введение). В /gnu/store имя директории каждого пакета содержит хеш всех входных данных, которые использовались при сборке пакета: компилятор, библиотеки, скрипты сборки и т.д. Это прямое соответствие позволяет пользователям убедиться, что данная установка пакета соответствует текущему состоянию дистрибутива. Также это помогает улучшить воспроизводимость сборки: благодаря изолированному окружению сборки, которая используется при установке пакета, результат сборки содержит точно такие же файлы на разных машинах (see container).
Эта концепция позволяет Guix поддерживать прозрачное внедрение
бинарников/исходников. Когда доступен элемент /gnu/store, собранный
заранее на внешнем источнике, то есть готова подстановка, Guix просто
скачивает и распаковывает его. В противном случае он собирает пакет из
исходников на локальной машине (see Подстановки). Так как результаты
сборки обычно воспроизводимы бит-к-биту, пользователи не должны доверять
серверам, которые поставляют подстановки — они могут целенаправленно
запросить локальную сборку и не пользоваться серверами подстановки
(see Вызов guix challenge).
Control over the build environment is a feature that is also useful for
developers. The guix shell command allows developers of a package
to quickly set up the right development environment for their package,
without having to manually install the dependencies of the package into
their profile (see Вызов guix shell).
Guix и его определения пакетов подчняются контролю версиями, и guix
pull позволяет "путешествовать во времени" по истории Guix (see Вызов guix pull). Это позволяет повторять инстанцию Guix на разных машинах или по
прошествию времени, что в свою очередь позволяет вам повторять
полностью программное окружение из достпуных трекеров источников
программного обеспечения.
Next: Подстановки, Previous: Особенности, Up: Управление пакетами [Contents][Index]
6.2 Вызов guix package
Команда guix package — инструмент, который позволяет
пользователям устанавливать, обновлять и удалять пакеты, а также
откатываться до предыдущих конфигураций (see Особенности). Его синтаксис:
guix package options
В первую очередь, options (опции) задают операции, которые нужно выполнить в транзакции. По завершении создаётся новый профиль, а предыдущие поколения (generations) профиля остаются доступными, если пользователь решит откатиться.
Например, чтобы удалить lua и устанвоить guile и
guile-cairo в одной транзакции, напечатайте:
guix package -r lua -i guile guile-cairo
Для вашего удобства мы также предоставляем следующие синонимы:
-
guix search- синонимguix package -s, -
guix install- синонимguix package -i, -
guix remove- синонимguix package -r, -
guix upgrade— это синонимguix package -u, - и
guix showпсевдоним (alias) дляguix package --show=.
Эти синонимы не такие мощные, как guix package, и предоставляют
меньше опций, так что в некоторых случаях вам скорее нужно пользоваться
непосредственно guix package.
guix package также поддерживает декларативный подход, с
помощью которого пользователь зааёт точный набор пакетов, которые должны
быть доступны, и передаёт его в опции --manifest
(see --manifest).
Для каждого пользователя автоматически создаётся символическая ссылка на
профиль по умолчанию, она располагается в файле
$HOME/.guix-profile. Эта ссылка всегда указывает на текущее поколение
пользовательского профиля по умолчанию. Так пользователи могут добавить
$HOME/.guix-profile/bin в свою переменную окружения PATH и
прочее.
Если вы не используете систему Guix, предполагается добавление следующих
строк в ваш ~/.bash_profile (see Bash Startup Files in The
GNU Bash Reference Manual), чтобы порождаемые оболочки получили все
необходимые определения переменных окружения:
GUIX_PROFILE="$HOME/.guix-profile" ; \ source "$GUIX_PROFILE/etc/profile"
В случае многопользовательской установки, профили пользователей сохраняются
в месте, которое зарегстрировано как garbage-collector root, которое
указывет на $HOME/.guix-profile (see Вызов guix gc). Эта
директория обычно ссылается на
localstatedir/guix/profiles/per-user/user, где
localstatedir — значение, переданное скрипту configure опцией
--localstatedir, а user — имя пользователя. Директория
per-user создаёся, когда запускается guix-daemon, а
поддиректория user создаётся guix package.
Опции options могут быть следующими:
--install=package …-i package …Установить заданный пакет.
Each package may specify a simple package name, such as
guile, optionally followed by an at-sign and version number, such asguile@3.0.7or simplyguile@3.0. In the latter case, the newest version prefixed by3.0is selected.If no version number is specified, the newest available version will be selected. In addition, such a package specification may contain a colon, followed by the name of one of the outputs of the package, as in
gcc:docorbinutils@2.22:lib(see Пакеты со множественным выходом).Packages with a corresponding name (and optionally version) are searched for among the GNU distribution modules (see Пакетные модули).
Alternatively, a package can directly specify a store file name such as /gnu/store/...-guile-3.0.7, as produced by, e.g.,
guix build.Иногда пакеты имеют распространённые входные данные (propagated inputs) — это зависимости, которые устанавливаются автоматически вместе с требуемыми пакетами (см. see
propagated-inputsinpackageobjects для подробной информации о распространяемых входных днных в определениях пакетов).Примером является библиотека GNU MPC: его файлы заголовков C ссылаются на файлы библиотеки GNU MPFR, которые в свою очередь, ссылаются на библиотеку GMP. Так при установке MPC, также в профиль будут устанволены библиотеки MPFR и GMP; удаление MPC также удалит MPFR и GMP, если конечно, они не были явно установлены пользователем.
Кроме того, пакеты иногда зависят от переменных окружения — от их путей поиска (смотрите разъяснение
--search-pathsниже). Любая отсутствующая или, возможно, некорректная переменная окружения вызывает сообщение отчета.--install-from-expression=exp-e expУстанавить пакет, соответствующий exp.
exp должно быть выражением Scheme, которое определяет объект
<package>. Эта опция полезна, чтобы указать однозначно пакет, который имеет схожие варианты имён, например, выражением(@ (gnu packages base) guile-final).Отметим, что эта опция устанавливает первое содержимое пакета, чего может быть недостаточно, если нужен специфичный выход пакета со множественным выходом.
--install-from-file=file-f fileУстанавить пакет, который определён в файле.
Например, file может содержать определение (see Описание пакетов):
(use-modules (guix) (guix build-system gnu) (guix licenses)) (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "http://www.gnu.org/software/hello/") (license gpl3+))
Developers may find it useful to include such a guix.scm file in the root of their project source tree that can be used to test development snapshots and create reproducible development environments (see Вызов
guix shell).file может также содержать JSON-представление одного или нескольких определений пакетов. Запуск
guix package -fна файле hello.json со следующим содержимым, установит пакетgreeterпосле сборкиmyhello:(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))--remove=package …-r package …Удалить обозначенный пакет.
Касаемо
--install, каждый пакет package может задавать номер версии и имя содержимого в добавлении к имени пакета. Например,-r glibc:debugудалит содержимоеdebugизglibc.--upgrade[=regexp …]¶-u [regexp …]Обновить все устанволенные пакеты. Если задано одно или более значений regexp, обновление затронет только пакеты, которые соответствуют regexp. Также смотрите опцию
--do-not-upgradeниже.Отметим, что это обновляет пакеты, которые установлены в системе, до последних версий, имеющихся в дистрибутиве. Чтобы обновить дистрибутив, нужно регулярно запускать
guix pull(see Вызовguix pull).При обновлении автоматически применяются преобразования пакета, которые были первоначально применены при создании профиля (see Параметры преобразования пакета). Например, предположим, что вы сначала установили Emacs из ветки разработки с помощью:
guix install emacs-next --with-branch=emacs-next=master
В следующий раз, когда вы запустите
guix upgrade, Guix снова посмотрит на ветку разработки Emacs и соберет новыйemacs-next.Обратите внимание, что параметры преобразования, такие как --with-branch и --with-source, зависят от внешнего состояния; вам решать, чтобы они работали должным образом. Вы также можете отменить преобразования, которые применяются к пакету, запустив:
guix install package
--do-not-upgrade[=regexp …]При совместном использовании с опцией
--upgradeне обновляет ни один пакет, чьё имя соответствует regexp. Например, обновить все пакеты в текущем профиле , кроме тех, которые содержат подстроку "emacs":$ guix package --upgrade . --do-not-upgrade emacs
--manifest=file¶-m file-
Создаёт новую версию профиля из объекта манифеста, возвращаемого кодом Scheme в file. Этот параметр можно указывать несколько раз. В результате манифесты будут объединены в один.
Это позволяет вам описать содержимое профиля вместо того, чтобы собирать его последовательностью команд
--installи других. Преимущество в том, что file может подчиняться контролю версиями, копироваться на другие машины, чтобы повторить такой же профиль и т.д.file должен возвращать объект manifest, который, грубо говоря, является списком пакетов:
(use-package-modules guile emacs) (packages->manifest (list emacs guile-2.0 ;; Use a specific package output. (list guile-2.0 "debug")))
See Writing Manifests, for information on how to write a manifest. See --export-manifest, to learn how to obtain a manifest file from an existing profile.
--roll-back¶-
Откатиться до предыдущего поколения профиля, то есть отменить последнюю транзакцию.
При сочетании с опциеями как
--install, откат выполняется до всех прочих действий.При откате от первого поколения, которое по факту содержит установленные пакеты, профиль будет указывать на нулевое поколение, которое не содержит файлы, кроме собственных метаданных.
После выполнения отката, установка, удаление или обновление пакетов по факту заменяет прежние будущие поколения. То есть история поколений в профиле всегда линейная.
--switch-generation=pattern¶-S patternПереключиться на определённое поколение, опрделённое pattern.
pattern может быть либо номером поколения или числом с префиксом "+" или "-". Последнее означает сменить вперёд/назад на обозначенное число поколений. Например, если вы хотите вернуться к последнему поколению после
--roll-back, используйте--switch-generation=+1.Разница между
--roll-backи--switch-generation=-1заключается в том, что--switch-generationне создаёт нулевое поколение, так что если заданное поколение не существует, текущее поколение не будет изменено.--search-paths[=kind]¶Вывести отчёт об определениях переменных окружения в синтаксисе Bash. Это может понадобиться для использования набора установленных пакетов. Эти переменные окружения используются некоторыми установленными пакетами для поиска файлов.
For example, GCC needs the
CPATHandLIBRARY_PATHenvironment variables to be defined so it can look for headers and libraries in the user’s profile (see Environment Variables in Using the GNU Compiler Collection (GCC)). If GCC and, say, the C library are installed in the profile, then --search-paths will suggest setting these variables to profile/include and profile/lib, respectively (see Search Paths, for info on search path specifications associated with packages.)Обычный способ определить эти переменные окружения в оболочке:
$ eval $(guix package --search-paths)
Вид kind может быть либо точный адрес
exact, либо префиксprefix, либо суффиксsuffix, то есть возвращаемые переменные окружения могут быть либо точными, либо префиксами и суффиксами текущего значения этих переменных. При пропуске вид kind по умолчанию выбирается точныйexact.Эта опция также может использоваться для вычисления комбинированных путей поиска нескольких профилей. Рассмотрим пример:
$ guix package -p foo -i guile $ guix package -p bar -i guile-json $ guix package -p foo -p bar --search-paths
Последняя команда выше составляет отчёт о переменной
GUILE_LOAD_PATH, даже если по отдельности ни foo, ни bar не предшествуют рекомендациям.--profile=profile-p profileИспользовать profile вместо пользовательского профиля по умолчанию.
profile должен быть именем файла, который будет создан по завершении. Конкретно profile будет простой символической ссылкой (“символическая ссылка”), указывающей на текущий профиль, в котором установлены пакеты:
$ guix install hello -p ~/code/my-profile … $ ~/code/my-profile/bin/hello Hello, world!
Чтобы избавиться от профиля, нужно удалить символическую ссылку и привязанные к ней элементы, которые указывают на конкретные поколения:
$ rm ~/code/my-profile ~/code/my-profile-*-link
--list-profilesПеречислить все профили пользователя:
$ guix package --list-profiles /home/charlie/.guix-profile /home/charlie/code/my-profile /home/charlie/code/devel-profile /home/charlie/tmp/test
При запуске от имени root будут перечислены все профили всех пользователей.
--allow-collisionsРазрешить соперничающие пакеты в новом профиле. Используйте на свой собственный страх и риск!
По умолчанию
guix packageделает отчёт о противоречиях collisions в профиле. Противоречия происходят, когда дви или более разных версии или варианта данного пакета присутсвуют в профиле.--bootstrapИспользовать бутстрап Guile для сборки профиля. Эта опция полезна только разработчикам дистрибутива.
В дополнение к этим действиям guix package поддерживает следующие
опции при обращении к текущему состоянию профиля или для проверки
доступности пакетов:
- --search=regexp
- -s regexp
-
Вывести список пакетов, чьи имена или описания содержат выражение regexp с учётом регистра, упорядоченные по соответствию. Печать всех метаданных соответствующих пакетов в формате
recutils(see GNU recutils databases in GNU recutils manual).Это позволяет извлекать заданые поля, используя команду
recsel, например:$ guix package -s malloc | recsel -p name,version,relevance name: jemalloc version: 4.5.0 relevance: 6 name: glibc version: 2.25 relevance: 1 name: libgc version: 7.6.0 relevance: 1
Также для отображения имён всех доступных пакетов под лицензией GNU LGPL версии 3:
$ guix package -s "" | recsel -p name -e 'license ~ "LGPL 3"' name: elfutils name: gmp …
Также можно уточнить поиск, используя несколько флагов
-sв командеguix packageили несколько аргументов вguix search. Например, следующая команда возвращает список настольных игр (используя синонимguix searchна этот раз):$ guix search '\<board\>' game | recsel -p name name: gnubg …
При пропуске
-s gameмы получим пакеты программного обеспечения, которые работают с печатными платами (boards); удалив угловые скобки рядом сboard, получим пакеты, которые также работают с клавиатурами (keyboards).А теперь более запутанный пример. Следующая команда ищет библиотеки криптографии, фильтрует библиотеки Haskel, Perl, Python и Ruby и печатает имена и краткие описания найденных пакетов:
$ guix search crypto library | \ recsel -e '! (name ~ "^(ghc|perl|python|ruby)")' -p name,synopsisСм. See Selection Expressions in GNU recutils manual для подробной информации о регуларяных выражениях selection expressions для
recsel -e. - --show=package
Показать детали пакета package из списка доступных пакетов в формате
recutils(see GNU recutils databases in GNU recutils manual).$ guix package --show=guile | recsel -p name,version name: guile version: 3.0.5 name: guile version: 3.0.2 name: guile version: 2.2.7 …
Можно также указать полное имя пакета, чтобы только получить детали его определённой версии (в этот раз, используя
guix showпсевдоним):$ guix show guile@3.0.5 | recsel -p name,version name: guile version: 3.0.5
- --list-installed[=regexp]
- -I [regexp]
Вывести текущий список установленных пакетов в заданном профиле, отобразив самый последний установленный пакет последним. Если задано regexp, будут выведены только пакеты, чьи имена содержат regexp.
Для каждого установленного пакета выводит следующие элементы, разделенные табуляцией (tab): имя пакета, строка версии, частью какого пакета является установленный пакет (например,
outвывода по умолчанию включаетincludeего заголовки т.д.), а также путь этого пакета на складе.- --list-available[=regexp]
- -A [regexp]
Вывести список пакетов, доступных на текущий момент в дистрибутиве данной системы (see Дистрибутив GNU). Если задано regexp, выводит только установленные пакеты, чьё имя содержит regexp.
Для каждого пакета выводит следующие элементы, разделённые табуляцией: его имя, строка версии, часть пакета (see Пакеты со множественным выходом), а также расположение его определения в исходниках.
- --list-generations[=pattern] ¶
- -l [pattern]
Вывести список поколений (generations) с датами их создания; для каждого поколения отобразить установленные пакеты, самый последний установленный пакет отобразать последним. Отметим, что нулевое поколение никогда не показывается.
Для каждого установленного пакета отображает следующие элементы, разделённые табуляцией: имя пакета, строка версии, частью какого пакета является установленный пакет (see Пакеты со множественным выходом), а также расположение пакета на складе.
Если используется pattern, команда выводит только соответствующие поколения. Правильные паттерны содержат:
- Числа и числа, разделённые запятыми. Оба паттерна обозначают
номера поколений. Например, --list-generations=1 возвращает первое.
Опция
--list-generations=1,8,2выводит три поколения в заданном пордке. Пробелы и запятые на конце запрещены. - Ranges. --list-generations=2..9 выводит
заданные поколения и все между ними. Отметим, что начало диапазона должно
быть меньше его конца.
Также можно пропустить конечную точку. Например,
--list-generations=2..возвращает все поколения, начиная со второго. - Сроки. Также можно задать последние N дней, недель
или месяцев, указав число и первую букву срока (d,w,m). Например,
--list-generations=20dотобразит список поколений старше 20 дней.
- Числа и числа, разделённые запятыми. Оба паттерна обозначают
номера поколений. Например, --list-generations=1 возвращает первое.
- --delete-generations[=pattern]
- -d [pattern]
Если pattern пропущен, удалит все поголения, кроме текущего.
Эта команда принимает такие же паттерны, как --list-generations. Если pattern задан, удалит соответствующие поколения. Если паттерн pattern задаёт срок, выбираются поколения старше срока. Например,
--delete-generations=1mудалит поколения, которые старше одного месяца.Если текущее поколение попадает под условия паттерна, оно не будет удалено. А также нулевое поокление никогда не удаляется.
Отметим, что удаление поколений делает невозможным откат к ним. Следовательно эта команда должна использоваться внимательно.
- --export-manifest
Напишите в стандартный вывод манифест, подходящий для --manifest, соответствующий выбранному профилю (-ам).
Эта опция предназначена для того, чтобы помочь вам перейти из “императивного” режима работы—запустив
guix install,guix upgradeи т.д.—в декларативный режим, который предлагает --manifest.Имейте в виду, что полученный манифест приблизительно соответствует тому, что на самом деле содержится в вашем профиле; например, в зависимости от того, как был создан ваш профиль, он может относиться к пакетам или версиям пакетов, которые не совсем то, что вы указали.
Имейте в виду, что манифест является чисто символическим: он содержит только имена пакетов и, возможно, версии, и их значение со временем меняется. Если вы хотите “привязать” каналы к ревизиям, которые использовались для создания профиля (ов), см. --export-channels ниже.
- %default-channels
Вывести на стандартный вывод список каналов, используемых выбранным профилем (-ями), в формате, подходящем для
guix pull --channelsилиguix time-machine --channels(see Каналы).Вместе с --export-manifest этот параметр предоставляет информацию, позволяющую копировать текущий профиль (see Копирование Guix).
Однако обратите внимание, что выходные данные этой команды приблизительно используются для создания этого профиля. В частности, один профиль мог быть построен из нескольких различных версий одного и того же канала. В этом случае --export-manifest выбирает последнюю версию и записывает список других ревизий в комментарий. Если вам действительно нужно выбрать пакеты из разных ревизий канала, вы можете использовать подчиненные элементы в своем манифесте для этого (see Младшие версии).
Если вы хотите перейти от “императивной” модели к полностью декларативной модели, состоящей из файла манифеста и файла каналов, закрепляющего точную желаемые версии каналов, то --export-manifest хорошая отправная точка.
Наконец, так как guix package может запускать процессы сборки, она
поддерживает все привычные опции сборки (see Стандартные параметры сборки). Она
также поддерживает опции трансформации пакетов, как --with-source
(see Параметры преобразования пакета). Однако, отметим, что трансформации
пакетов теряются после обновлений; чтобы сохранить трансформации при
обновлениях, нужно определить собственный вариант пакета в модуле Guile и
добавить его в GUIX_PACKAGE_PATH (see Описание пакетов).
Next: Пакеты со множественным выходом, Previous: Вызов guix package, Up: Управление пакетами [Contents][Index]
6.3 Подстановки
Guix поддерживает прозрачную развёртку исходников/бинарников, это означает возможность сборки пакетов локально или скачивания собранных элементов с сервера, или и то и другое. Мы называем собранные элементы подстановками (substitutes) — это подстановки результатов локальных сборок. Часто скасивание подстановки намного быстрее, чем сборка пакетов локально.
В качестве подстановок может выступать какой угодно результат сборки деривации (see Деривации). Конечно, обычно это собранные пакеты, но также архивы исходников, например, представляя собой результаты сборок дериваций, могут быть доступны в качестве подстановок.
- Official Substitute Servers
- Авторизация сервера подстановок
- Получение заменителей с других серверов
- Аутентификация подстановок
- Настройки proxy
- Ошибки при подстановке
- Касательно проверенных бинарников
Next: Авторизация сервера подстановок, Up: Подстановки [Contents][Index]
6.3.1 Official Substitute Servers
ci.guix.gnu.org and bordeaux.guix.gnu.org
are both front-ends to official build farms that build packages from Guix
continuously for some architectures, and make them available as
substitutes. These are the default source of substitutes; which can be
overridden by passing the --substitute-urls option either to
guix-daemon (see guix-daemon
--substitute-urls) or to client tools such as guix package
(see client --substitute-urls option).
URL подстановок могут быть либо HTTP, либо HTTPS. Рекомендуется HTTPS, так как такая связь шифруется; и наоборот, использование HTTP делает связь видимой для подслушивающих, и они могут использовать собранную информацию, чтобы определить, например, что ваша система не имеет патчей, покрывающих уязвимости безопасности.
Substitutes from the official build farms are enabled by default when using Guix System (see Дистрибутив GNU). However, they are disabled by default when using Guix on a foreign distribution, unless you have explicitly enabled them via one of the recommended installation steps (see Установка). The following paragraphs describe how to enable or disable substitutes for the official build farm; the same procedure can also be used to enable substitutes for any other substitute server.
Next: Получение заменителей с других серверов, Previous: Official Substitute Servers, Up: Подстановки [Contents][Index]
6.3.2 Авторизация сервера подстановок
To allow Guix to download substitutes from
ci.guix.gnu.org, bordeaux.guix.gnu.org or a
mirror, you must add the relevant public key to the access control list
(ACL) of archive imports, using the guix archive command
(see Вызов guix archive). Doing so implies that you trust the
substitute server to not be compromised and to serve genuine substitutes.
Примечание: If you are using Guix System, you can skip this section: Guix System authorizes substitutes from
ci.guix.gnu.organdbordeaux.guix.gnu.orgby default.
The public keys for each of the project maintained substitute servers are
installed along with Guix, in prefix/share/guix/, where
prefix is the installation prefix of Guix. If you installed Guix from
source, make sure you checked the GPG signature of
guix-1.4.0.tar.gz, which contains this public key file.
Then, you can run something like this:
# guix archive --authorize < prefix/share/guix/ci.guix.gnu.org.pub # guix archive --authorize < prefix/share/guix/bordeaux.guix.gnu.org.pub
Когда это сделано, вывод команды guix build должен измениться с
примерно такого:
$ guix build emacs --dry-run The following derivations would be built: /gnu/store/yr7bnx8xwcayd6j95r2clmkdl1qh688w-emacs-24.3.drv /gnu/store/x8qsh1hlhgjx6cwsjyvybnfv2i37z23w-dbus-1.6.4.tar.gz.drv /gnu/store/1ixwp12fl950d15h2cj11c73733jay0z-alsa-lib-1.0.27.1.tar.bz2.drv /gnu/store/nlma1pw0p603fpfiqy7kn4zm105r5dmw-util-linux-2.21.drv …
на примерно следующий:
$ guix build emacs --dry-run 112.3 MB would be downloaded: /gnu/store/pk3n22lbq6ydamyymqkkz7i69wiwjiwi-emacs-24.3 /gnu/store/2ygn4ncnhrpr61rssa6z0d9x22si0va3-libjpeg-8d /gnu/store/71yz6lgx4dazma9dwn2mcjxaah9w77jq-cairo-1.12.16 /gnu/store/7zdhgp0n1518lvfn8mb96sxqfmvqrl7v-libxrender-0.9.7 …
The text changed from “The following derivations would be built” to “112.3 MB would be downloaded”. This indicates that substitutes from the configured substitute servers are usable and will be downloaded, when possible, for future builds.
Механизм подстановок может быть отключен глобально путём запуска
guix-daemon с --no-substitutes (see Вызов guix-daemon). Также он может отключиться временно путём указания опции
--no-substitutes в guix package, guix build и
других инструментах командной строки.
Next: Аутентификация подстановок, Previous: Авторизация сервера подстановок, Up: Подстановки [Contents][Index]
6.3.3 Получение заменителей с других серверов
Guix может искать и получать заменители с нескольких серверов. Это полезно, когда вы используете пакеты из дополнительных каналов, для которых официальный сервер не имеет заменителей, но их предоставляет другой сервер. Еще одна ситуация, когда это полезно, если вы предпочитаете выполнять загрузку с замещающего сервера вашей организации, прибегая к официальному серверу только в качестве запасного варианта или полностью отклоняя его.
Вы можете дать Guix список URL-адресов серверов с заменителями, и он проверит их в указанном порядке. Вам также необходимо явно авторизовать открытые ключи серверов с заменителями, чтобы Guix принял заменители, которые они подписывают.
В системе Guix это достигается путем изменения конфигурации службы
guix. Поскольку служба guix является частью списков служб по
умолчанию, %base-services и %desktop-services, вы можете
использовать modify-services для изменения ее конфигурации и добавьте
нужные URL-адреса и заменить ключи (see modify-services).
В качестве примера предположим, что вы хотите получить заменители из
guix.example.org и авторизовать ключ этого сервера в дополнение к
ci.guix.gnu.org и bordeaux.guix.gnu.org.
Полученная конфигурация операционной системы будет выглядеть примерно так:
(operating-system
;; …
(services
;; Assume we're starting from '%desktop-services'. Replace it
;; with the list of services you're actually using.
(modify-services %desktop-services
(guix-service-type config =>
(guix-configuration
(inherit config)
(substitute-urls
(append (list "https://guix.example.org")
%default-substitute-urls))
(authorized-keys
(append (list (local-file "./key.pub"))
%default-authorized-guix-keys)))))))
Предполагается, что файл key.pub содержит ключ подписи
guix.example.org. После внесения этого изменения в файл конфигурации
вашей операционной системы (например, /etc/config.scm) вы можете
перенастроить и перезапустить службу guix-daemon или перезагрузиться,
чтобы изменения вступили в силу:
$ sudo guix system reconfigure /etc/config.scm $ sudo herd restart guix-daemon
Если вы используете Guix в качестве пакетного менеджера на другом дистрибутиве, вместо вышеописанного вы должны предпринять следующие шаги, чтобы получить заменители с дополнительных серверов:
- Отредактируйте файл конфигурации службы для
guix-daemon; когда исользуете systemd, это обычно /etc/systemd/system/guix-daemon.service. Добавьте параметр --substitute-urls командыguix-daemonпри вызове в командной строке и перечислите интересующие URL-адреса (seeguix-daemon --substitute-urls):… --substitute-urls='https://guix.example.org https://ci.guix.gnu.org https://bordeaux.guix.gnu.org'
- Перезапустите демон. Пример для systemd:
systemctl daemon-reload systemctl restart guix-daemon.service
- Авторизуйте ключ нового сервера (see Вызов
guix archive):# guix archive --authorize < master-public-key.txt
Опять же, это предполагает key.pub, содержащий открытый ключ, который
guix.example.orgиспользует для подписи замененителей.
Now you’re all set! Substitutes will be preferably taken from
https://guix.example.org, using ci.guix.gnu.org
then bordeaux.guix.gnu.org as fallback options. Of course you
can list as many substitute servers as you like, with the caveat that
substitute lookup can be slowed down if too many servers need to be
contacted.
Обратите внимание, что бывают также ситуации, когда можно добавить URL-адрес замещающего сервера без авторизации его ключа. See Аутентификация подстановок, чтобы понять этот тонкий момент.
Next: Настройки proxy, Previous: Получение заменителей с других серверов, Up: Подстановки [Contents][Index]
6.3.4 Аутентификация подстановок
Guix определяет и вызывает ошибку, если происходит попытка использовать поддельную подстановку. А также он игнорирует подстановки, которые не подписаны, или те, которые не подписаны ни одним ключом из списка ACL.
Но всё же есть одно исключение: если не авторизованный сервер предоставляет подстановки, которые являются идентичными бит-к-биту с теми, которые предоставляет авторизованный сервер, тогда неавторизованный сервер становится приемлемым для скачивания. Например, положим, мы выбрали два сервера подстановок такой опцией:
--substitute-urls="https://a.example.org https://b.example.org"
Если ACL содержит только ключ для b.example.org, и если вдруг
a.example.org предоставляет идентичные подстановки, тогда Guix
будет скачивать подстановки из a.example.org, потому что он идёт
первым в списке и может рассматриваться как зеркало b.example.org. На
практике независимые машины сборки обычно производят одинаковые бинарники
благодаря воспроизводимым сборкам (смотрите ниже).
При использовании HTTPS, сертификат X.509 сервера не проверяется (другими словами, сервер не проходит аутентификацию), супротив тому, что HTTPS-клиенты, как веб-браузеры, обычно делают это. Это потому, что Guix аутентифицирует саму информацию подстановки, как это описано выше, что собственно и представляет для нас интерес (в то время, как сертификаты X.509 относятся к аутентификации связок между доменными именами и публичными ключами).
Next: Ошибки при подстановке, Previous: Аутентификация подстановок, Up: Подстановки [Contents][Index]
6.3.5 Настройки proxy
Подстановки скачиваются через HTTP или HTTPS. Можно установить переменную
окружения http_proxy в окружении guix-daemon, чтобы она
учитывалась при скачивании. Отметим, что значение http_proxy в
окружении, в котором запускаются guix build, guix
package и другие клиентские команды совершенно не даёт эффекта.
Next: Касательно проверенных бинарников, Previous: Настройки proxy, Up: Подстановки [Contents][Index]
6.3.6 Ошибки при подстановке
Даже когда подстановка для деривации доступна, иногда попытка подстановки завершается неудачно. Это может происходить по разным причинам: сервер подстановок может быть отключен, подстановка могла быть недавно удалена, связь может прерываться и т.д.
Когда подстановки включены, и подстановка для деривации доступна, но попытка
подстановки завершается с ошибкой, Guix будет пытаться собрать деривацию
локально в зависимости от того, задана или нет опция --fallback
(see common build option --fallback). То есть,
если --fallback пропущена, тогда локальная сборка не будет
выполняться, а деривация будет рассматриваться как неудачная. Однако, если
--fallback задана, тогда Guix попытается собрать деривацию локально,
и успех или неудача деривации будет зависеть от успешной или неудачной
процедуры локальной сборки. Отметим, что когда подстановки отключены или нет
доступных подстановок для деривации, локальная сборка всегда будет
исполняться, вне зависимости от установки опции --fallback.
Чтобы узнать,. сколько подстановок доступны в данный момент, можно
попробовать запустить команду guix weather (see Вызов guix weather). Эта команда предоставляет статистику подстановок, предоставляемых
сервером.
Previous: Ошибки при подстановке, Up: Подстановки [Contents][Index]
6.3.7 Касательно проверенных бинарников
Today, each individual’s control over their own computing is at the mercy of
institutions, corporations, and groups with enough power and determination
to subvert the computing infrastructure and exploit its weaknesses. While
using substitutes can be convenient, we encourage users to also build on
their own, or even run their own build farm, such that the project run
substitute servers are less of an interesting target. One way to help is by
publishing the software you build using guix publish so that
others have one more choice of server to download substitutes from
(see Вызов guix publish).
Guix определяет цель максимизировать воспроизводимость сборок
(see Особенности). В большинстве случаев независимые сборки заданного
пакета или деривации должны давать результаты, идентичные до бита. То есть,
благодаря ряду независимых сборок пакета мы можем улучшить чистоту наших
систем. Команда guix challenge должна помочь пользователям оценить
серверы подстановок, а разработчикам - помочь выявить недетерминистические
сборки пакетов (see Вызов guix challenge). Подобным образом опция
--check команды guix build даёт возможность пользователям
проверить, яляются ли установленные ранее подстановки подлинными, выполнив
их локальную сборку (see guix build --check).
Мы хотим, чтобы Guix в будущем поддерживал публикации и запросы бинарников от/для пользователей в формате равноправного обмена (peer-to-peer). Если вы желаете обсудить этот проект, присоединяйтесь к нам guix-devel@gnu.org.
Next: Вызов guix gc, Previous: Подстановки, Up: Управление пакетами [Contents][Index]
6.4 Пакеты со множественным выходом
Часто пакеты, определённые в Guix, имеют один выход, это значит, что
исходный пакет даёт только одну директорию на складе. При запуске
guix package -i glibc это устанавливает результат по умолчанию;
результат по умолчанию называется выходом, но его имя может
пропускаться, как показано в этой команде. В этом частном случае результат
по умолчанию для glibc содержит все файлы заголовков C, разделяемые
библиотеки, статические библиотеки, документацию Info и другие поставляемые
файлы.
Часто более приемлемым будет разделить различные типы файлов, поставляемых
одним исходным пакетом, на отдельные выходы (результаты). Например,
библиотека GLib C, используемая GTK+ и связанными с ним пакетами,
устанавливает более 20Мб связанной документации в виде страниц HTML. Чтобы
экономить место, пользователи, которым это не нужно, документацию можно
выделить в отдельный выход, называемый doc. Чтобы установить основной
выход GLib, который содерит всё, кроме документации, можно запустить:
guix install glib
Команда для установки её документации:
guix install glib:doc
Некоторые пакеты устанавливают программы с различными “отпечатками
зависимостей”. Например, пакет WordNet устанавливает и инструменты
командной строки, и графический интерфейс (GUI). Первое зависит только от
библиотеки C, а последнее зависит от Tcl/Tk и библиотек X. В таком случае
мы оставляем инструменты командной строки в качестве результата по
умолчанию, в то время как GUI поставляется как отдельный выход. Это
экономит место для пользователей, которым не нужен GUI. Команда
guix size может помочь выявить такие ситуации (see Вызов guix size). guix graph также полезна (see Вызов guix graph).
Есть несколько таких пакетов со множественным выходом в дистрибутиве
GNU. Другие традиционные имена выходов включают lib - для библиотек и
иногда файлов заголовков, bin - для самих программ, debug -
для отладочной информации (see Установка файлов отладки). Выходы
пакетов представлены в третьей колонке вывода guix package
--list-available (see Вызов guix package).
Next: Вызов guix pull, Previous: Пакеты со множественным выходом, Up: Управление пакетами [Contents][Index]
6.5 Вызов guix gc
Пакеты, которые установлены, но не используются, могут быть очищены как
мусор (garbage-collected). Команда guix gc позволяет
пользователям непосредственно запустить сборщик мусора и восстановить место
в директории /gnu/store. Это единственный способ удалить файлы
из /gnu/store — удаление файлов вручную может поломать её
безвозвратно!
Сборщик мусора имеет набор известных корней (roots): любой файл в
/gnu/store, доступный из корня, рассматривается как живой
(live) и не может быть удалён; любой другой файл рассматривается как
мёртвый (dead) и может быть удалён. Набор корней сборщика мусора
(сокращённо "GC roots") содержит профили пользователей по умолчанию; по
умолчанию символические ссылки в /var/guix/gcroots представляют эти
корни сборщика мусора. Новые корни могут добавляться, например, командой
guix build --root (see Запуск guix build). Команда
guix gc --list-roots отображает их.
Перед запуском guix gc --collect-garbage для освобождения места часто
бывает полезно удалить старые поколения из пользовательских профилей; так
старые пакеты, относящиеся к этим поколениям, будут удалены. Это можно
сделать, запустив guix package --delete-generations (see Вызов guix package).
Мы рекомендуем запускать сборщик мусора периодически, или когда вы хотите освободить место на диске. Например, чтобы гарантировать, что по меньшей мере 5 Гб будет доступно на вашем диске, просто запустите:
guix gc -F 5G
Хорошо бы запускать это как неинтерактивную периодическую задачу
(see Запланированное исполнения задач, чтобы узнать, как добавить такую
задачу). Запуск guix gc без аргументов соберёт столько мусора,
сколько возможно, но это часто не удобно: можно обнаружить, что придётся
заново собирать или скачивать программы, "убитые" сборщиком мусора, хотя они
необходимы для сборки другого софта, например, это касается инструментов
компилятора.
Команда guix gc предоставляет три способа взаимодействия: может
использоваться для сборки мусора (garbage-collect) любых мёртвых файлов (по
умолчанию), для удаления конкретных файлов (опция --delete), для
вывода информации сборщика мусора, а также для более изощрённых
запросов. Опции сборщика мусора:
--collect-garbage[=min]-C [min]Собрать мусор, то есть недоступные файлы в /gnu/store и поддиректориях. Это операция по умолчанию, если не заданы опции.
Если задана min, остановиться, когда min байт собрано. min может быть числом байт или может содержать единицу измерения в суффиксе, как например,
MiBдля мебибайт иGBгигабайт (see size specifications in GNU Coreutils).Если min пропущено, собрать весь мусор.
--free-space=free-F freeСобирать мусор, пока не станет доступно free места в /gnu/store, если возможно; free описывает дисковое пространство, как
500MiB, как это описанов выше.Когда free или более места стало свободно в /gnu/store, ничего не делать и немедленно выйти.
--delete-generations[=duration]-d [duration]Before starting the garbage collection process, delete all the generations older than duration, for all the user profiles and home environment generations; when run as root, this applies to all the profiles of all the users.
Например, следующая команда удаляет все поколения всех ваших профилей, которые старше 2 месцев (кроме текущего поколения), а затем запускается процесс освобождения мместа, пока по меньшей мере 10 GiB не станет доступно:
guix gc -d 2m -F 10G
--delete-DПопытаться удалить все файлы и директории склада, приведённые в аргументах. Это завершается с ошибкой, если какие-либо файлы не присутствуют на складе, или если они ещё живы (live).
--list-failuresВывести список элементов склада, которые относятся к кешированным неудачным сборкам.
Это ничего не выводит, если демон не был запущен с опцией --cache-failures (see --cache-failures).
--list-rootsВывести список корней сборщика мусора (GC roots), которыми владеет пользователь; при запуске от root, выводит список всех корней сборщика мусора.
--list-busyСоставляет список элементов хранилица, исользуемых запущенными в данное время процессами. Эти элементы считаются корнями GC: они не могут быть удалены.
--clear-failuresУдалить заданные элементы склада из кеша неудачных сборок.
Опять же эта опция имеет смысл, если демон запущен с --cache-failures. В противном случае это не имеет эффекта.
--list-deadВывести список мёртвых файлов и директорий, которые по-прежнему присутствуют на складе, то есть файлы и директории, не доступные более из любого корня.
--list-liveВывести список живых файлов и директорий склада.
В дополнение можно запросить связи между существующими файлами на складе:
--references¶--referrersВывести список связанных (обязательно, ссылающихся) файлов на складе с указанными аргументами.
--requisites¶-RВывести всё необходимое для файлов на складе, указанных в аргументах. Всё необходимое включает сами файлы на складе, их связи и связи их связей рекурсивно. Другими словами, выводимый список — это непосредственный конвейер файлов на складе.
См. See Вызов
guix sizeдля информации об инструменте профилирования конвейера для элемента. См. See Вызовguix graphдля информации об инструменте визуализации графа связей.--derivers¶Вернуть деривацию(-ии), производящие данные элементы склада (see Деривации).
Например, эта команда:
guix gc --derivers `guix package -I ^emacs$ | cut -f4`
возвращает файл(ы) .drv, которые произвели пакет
emacs, установленный в вашем профиле.Отметим, что может быть не найдено ни одного файла .drv, например, потому что эти файлы были удалены сборщиком мусора. Также может быть более одного файла .drv из-за дериваций с фиксированным выходом.
Наконец, следующие опции позволяют проверить целостность склада и контролировать использование диска.
- --verify[=options] ¶
-
Проверить целостность склада.
По умолчанию убедиться, что все элементы склада, которые в базе данных демона помечены как действующие, на самом деле присутствуют в /gnu/store.
Опции options, если они указаны, должны представлять собой список, разделённый запятыми, содержащий одно или более значений
contentsиrepair.Если задано --verify=contents, демон вычисляет хеш содержимого каждого элемента склада и сравнивает с его хешем в базе данных. Несовпадения хеша отображаются в отчёте как повреждение данных. Так как она проходит все файлы склада, эта команда может занять много времени, особенно в системах с медленным диском.
Использование --verify=repair или --verify=contents,repair указывает демону предпринять попытку восстановить разрушенные элементы склада, выбирая подстановки для них (see Подстановки). Так как восстановление не атомарное, и поэтому потенциально опасно, оно доступно только системному администратору. Малозатратная альтернатива в случае, если вы знаете точно, какие элементы склада испорчены, — это
guix build --repair(see Запускguix build). - --optimize ¶
Оптимизировать склад с помощью жёстких ссылок на идентичные файлы — это дедупликация.
Демон выполняет дедупликацию после каждой успешной сборки или импорта архива, если конечно оно не было запущено с
--disable-deduplication(see--disable-deduplication). Так что эта опция особенно важна, если демон запущено с--disable-deduplication.- --vacuum-database ¶
Guix uses an sqlite database to keep track of the items in (see Хранилище). Over time it is possible that the database may grow to a large size and become fragmented. As a result, one may wish to clear the freed space and join the partially used pages in the database left behind from removed packages or after running the garbage collector. Running
sudo guix gc --vacuum-databasewill lock the database andVACUUMthe store, defragmenting the database and purging freed pages, unlocking the database when it finishes.
Next: Запуск guix time-machine, Previous: Вызов guix gc, Up: Управление пакетами [Contents][Index]
6.6 Вызов guix pull
Packages are installed or upgraded to the latest version available in the
distribution currently available on your local machine. To update that
distribution, along with the Guix tools, you must run guix pull:
the command downloads the latest Guix source code and package descriptions,
and deploys it. Source code is downloaded from a
Git repository, by default the official
GNU Guix repository, though this can be customized. guix
pull ensures that the code it downloads is authentic by verifying
that commits are signed by Guix developers.
В частности, guix pull загружает код из channel
(see Каналы), указанного одним из следующих способов, в следующем
порядке:
- опция --channels;
- пользовательский файл ~/.config/guix/channels.scm;
- общесистемный файл /etc/guix/channels.scm file;
- встроенные по умолчанию каналы определены в переменной
%default-channels.
После выполнения этой команды guix package будет использовать
пакеты и те их версии, которые имеются в только что полученной копии
Guix. Эта последняя версия будет источником также всех команд Guix, модулей
Scheme. Из этого обновления станет доступен набор команд guix.
Любой пользователь может обновить свою копию Guix, используя guix
pull, эффект коснётся только пользователя, который запустил guix
pull. Например, если пользователь root запускает guix
pull, это не имеет эффекта на версию Guix, которую видит alice sees,
и наоборот.
Результат запуска guix pull — это профиль profile,
доступный в ~/.config/guix/current, содержащий последний Guix. Так
что обязательно добавьте этот адрес первым в пути поиска, чтобы использовать
последнюю версию, а также для руководства Info (see Документация):
export PATH="$HOME/.config/guix/current/bin:$PATH" export INFOPATH="$HOME/.config/guix/current/share/info:$INFOPATH"
Опция --list-generations или -l выводит список последних
поколений, поставленных guix pull, вместе с деталями об их
происхождении:
$ guix pull -l
Generation 1 Jun 10 2018 00:18:18
guix 65956ad
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: origin/master
commit: 65956ad3526ba09e1f7a40722c96c6ef7c0936fe
Generation 2 Jun 11 2018 11:02:49
guix e0cc7f6
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: origin/master
commit: e0cc7f669bec22c37481dd03a7941c7d11a64f1d
Generation 3 Jun 13 2018 23:31:07 (current)
guix 844cc1c
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: origin/master
commit: 844cc1c8f394f03b404c5bb3aee086922373490c
Смотрите See guix describe, для
информации о других способах получить информацию о текущем статусе Guix.
Этот профиль ~/.config/guix/current работает, как любой другой
профиль, созданный guix package (see Вызов guix package). Так что можно вывести список поколений, откатиться до предыдущего
поколения, то есть до предыдущего Guix, и так далее:
$ guix package -p ~/.config/guix/current --roll-back switched from generation 3 to 2 $ guix package -p ~/.config/guix/current --delete-generations=1 deleting /var/guix/profiles/per-user/charlie/current-guix-1-link
Вы также можете использовать guix package (see Вызов guix package), чтобы управлять профилем, называя его явно:
$ guix package -p ~/.config/guix/current --roll-back switched from generation 3 to 2 $ guix package -p ~/.config/guix/current --delete-generations=1 deleting /var/guix/profiles/per-user/charlie/current-guix-1-link
Команда guix pull обычно вызывается без аргументов, но
поддерживает следующие опции:
--url=url--commit=commit--branch=branchDownload code for the
guixchannel from the specified url, at the given commit (a valid Git commit ID represented as a hexadecimal string or the name of a tag), or branch.Эти опции внедрены для удобства, но также можно задать конфигурационный файл ~/.config/guix/channels.scm или использовать опцию --channels (смотрите ниже).
--channels=file-C fileСчитать список каналов из файла file вместо ~/.config/guix/channels.scm. file должен содержать код Scheme, который определяет список объектов "канал". См. See Каналы для подробной информации.
--news-NDisplay news written by channel authors for their users for changes made since the previous generation (see Writing Channel News). When --details is passed, additionally display new and upgraded packages.
You can view that information for previous generations with
guix pull -l.--list-generations[=pattern]-l [pattern]Вывести список всех поколений ~/.config/guix/current или, если предоставлен паттерн pattern, подмножество поколений, которые соответствуют pattern. Синтаксис pattern — такой же, как у
guix package --list-generations(see Вызовguix package).By default, this prints information about the channels used in each revision as well as the corresponding news entries. If you pass --details, it will also print the list of packages added and upgraded in each generation compared to the previous one.
--detailsInstruct --list-generations or --news to display more information about the differences between subsequent generations—see above.
--roll-back¶-
Откатиться до предыдущего поколения профиля, то есть отменить последнюю транзакцию.
--switch-generation=pattern¶-S patternПереключиться на определённое поколение, опрделённое pattern.
pattern может быть либо номером поколения или числом с префиксом "+" или "-". Последнее означает сменить вперёд/назад на обозначенное число поколений. Например, если вы хотите вернуться к последнему поколению после
--roll-back, используйте--switch-generation=+1.--delete-generations[=pattern]-d [pattern]Если pattern пропущен, удалит все поголения, кроме текущего.
Эта команда принимает такие же паттерны, как --list-generations. Если pattern задан, удалит соответствующие поколения. Если паттерн pattern задаёт срок, выбираются поколения старше срока. Например,
--delete-generations=1mудалит поколения, которые старше одного месяца.Если текущее поколение попадает под условия паттерна, оно не будет удалено. А также нулевое поокление никогда не удаляется.
Отметим, что удаление поколений делает невозможным откат к ним. Следовательно эта команда должна использоваться внимательно.
См. See Вызов
guix describe, чтобы узнать, как вывести информацию только о текущем поколении.--profile=profile-p profileИспользовать профиль profile вместо ~/.config/guix/current.
--dry-run-nПоказать, какие коммиты будут использоваться, и что будет собрано или скачано в виде подстановок, но не выполнять эту работу.
--allow-downgradesРазрешить загружать более старые или несвязанные версии каналов, чем те, которые используются в настоящее время.
По умолчанию
guix pullзащищает от так называемых “атак на более раннюю версию”, когда репозиторий Git данного канала будет сброшен до более ранней или несвязанной версии, что может привести к установке более старых, известных уязвимых версий пакетов.Примечание: Прежде чем использовать --allow-downgrades, убедитесь, что вы понимаете его последствия для безопасности.
--disable-authenticationРазрешить загрузку канала без его аутентификации.
По умолчанию
guix pullаутентифицирует код, загруженный из каналов, проверяя, что его коммиты подписаны авторизованными разработчиками, и выдает ошибку, если это не так. Эта опция дает указание не выполнять такую проверку.Примечание: Прежде чем использовать --disable-authentication, убедитесь, что вы понимаете его последствия для безопасности.
--system=system-s systemПредпринять попытку собрать систему system, т.е.
i686-linux, вместо типа системы хоста сборки.--bootstrapИспользовать бутстрап Guile для сорки последнего Guix. Эта опция полезна только для разработчиков.
Механизм каналов channel позволяет указать guix pull, из
какого репозитория или ветки скачивать, а также какие дополнительные
репозитории должны использоваться для развёртки. См. See Каналы для
подробной информации.
В добавок guix pull поддерживает все стандартные опции сборки
(see Стандартные параметры сборки).
Next: Младшие версии, Previous: Вызов guix pull, Up: Управление пакетами [Contents][Index]
6.7 Запуск guix time-machine
Команда guix time-machine предоставляет доступ к другим версиям
Guix, например, для установки более старых версий пакетов или для
воспроизведения вычислений в идентичной среде. Версия используемого Guix
определяется коммитом или файлом описания канала, созданным guix
describe (see Вызов guix describe).
Let’s assume that you want to travel to those days of November 2020 when
version 1.2.0 of Guix was released and, once you’re there, run the
guile of that time:
guix time-machine --commit=v1.2.0 -- \ environment -C --ad-hoc guile -- guile
The command above fetches Guix 1.2.0 and runs its guix
environment command to spawn an environment in a container running
guile (guix environment has since been subsumed by
guix shell; see Вызов guix shell). It’s like driving a
DeLorean12! The first guix time-machine invocation can
be expensive: it may have to download or even build a large number of
packages; the result is cached though and subsequent commands targeting the
same commit are almost instantaneous.
Примечание: The history of Guix is immutable and
guix time-machineprovides the exact same software as they are in a specific Guix revision. Naturally, no security fixes are provided for old versions of Guix or its channels. A careless use ofguix time-machineopens the door to security vulnerabilities. See --allow-downgrades.
Основной синтаксис:
guix time-machine options… -- command arg…
где command и arg… передаются без изменений в команду
guix указанной ревизии. options, которые определяют эту
ревизию, такие же, как и для guix pull (see Вызов guix pull):
--url=url--commit=commit--branch=branchUse the
guixchannel from the specified url, at the given commit (a valid Git commit ID represented as a hexadecimal string or the name of a tag), or branch.--channels=file-C fileСчитать список каналов из файла file вместо ~/.config/guix/channels.scm. file должен содержать код Scheme, который определяет список объектов "канал". См. See Каналы для подробной информации.
Что касается guix pull, то отсутствие каких-либо опций означает,
что будет использоваться последний коммит в основной ветке. Команда
guix time-machine -- build hello
таким образом, мы соберем пакет hello, как определено в основной
ветке, которая, как правило, является более новой версией Guix, чем вы
установили. Путешествие во времени работает в обоих направлениях!
Если указанные пакеты ещё не собраны, guix archive автоматически
соберёт их. Процесс сборки может контролироваться обычными опциями сборки
(see Стандартные параметры сборки).
Next: Вызов guix describe, Previous: Запуск guix time-machine, Up: Управление пакетами [Contents][Index]
6.8 Младшие версии
Примечание: Функциональность, описанная здесь, — это обзор технологии версии 1.4.0. Интерфейс может меняться.
Иногда вам может понадобиться перемешивать пакеты из ревизии Guix, которая работает в настоящий момент, с пакетами, доступными в другой ревизии Guix. Основания Guix inferiors позволяют вам получить это, составляя различные ревизии Guix произвольным образом.
Технически работа с ранними версиями — это в целом отдельный процесс Guix,
связанный с главным процессом Guix через REPL (see Вызов guix repl). Модуль (guix inferior) позволяет запускать ранние версии и
взаимодействовать с ними. Он также предоставляет высокоуровневый интерфейс
для обзора и управления пакетами, которые поставляет ранняя версия —
ранние версии пакетов.
When combined with channels (see Каналы), inferiors provide a simple
way to interact with a separate revision of Guix. For example, let’s assume
you want to install in your profile the current guile package, along
with the guile-json as it existed in an older revision of
Guix—perhaps because the newer guile-json has an incompatible API
and you want to run your code against the old API. To do that, you could
write a manifest for use by guix package --manifest (see Writing Manifests); in that manifest, you would create an inferior for that old
Guix revision you care about, and you would look up the guile-json
package in the inferior:
(use-modules (guix inferior) (guix channels) (srfi srfi-1)) ;for 'first' (define channels ;; This is the old revision from which we want to ;; extract guile-json. (list (channel (name 'guix) (url "https://git.savannah.gnu.org/git/guix.git") (commit "65956ad3526ba09e1f7a40722c96c6ef7c0936fe")))) (define inferior ;; An inferior representing the above revision. (inferior-for-channels channels)) ;; Now create a manifest with the current "guile" package ;; and the old "guile-json" package. (packages->manifest (list (first (lookup-inferior-packages inferior "guile-json")) (specification->package "guile")))
Далее запуск guix package --manifest может вызвать сборку канала,
который вы обозначили ранее, и в результате это задействует раннюю
версию. Последовательные запуски будут быстрее, потому что ревизия Guix
будет кеширована.
Модуль (guix inferior) предоставляет следующие процедуры для работы с
ранними версиями:
- Процедура Scheme: inferior-for-channels channels [#:cache-directory] [#:ttl] Возвращает раннюю версию для списка каналов
channels. Использует кеш в cache-directory, где компоненты могут восстанавливаться через ttl секунд. Эта процедура открывает новое соединение с демоном сборки.
Как побочный эффект, эта процедура может собирать или скачивать подстановки бинарников для channels, что может занять время.
- Процедура Scheme: open-inferior directory [#:command "bin/guix"] Открывает раннюю версию Guix в directory,
запустив repl
directory/commandили эквивалент. Возвращает#f, если ранняя версия не может быть запущена.
Процедуры, приведённые ниже, обеспечивают работу и управление ранними версиями пакетов.
- Процедура Scheme: inferior-packages inferior
Возвращает список пакетов, относящихся к ранней версии inferior.
- Процедура Scheme: lookup-inferior-packages inferior name [version] Возвращает сортированный список пакетов ранней версии
inferior, содержащих имя name, поздняя версия - вначале. Если версия version задана, возвращает только пакеты с номером версии, начинающейся с version.
- Процедура Scheme: inferior-package? obj
Возвращает true, если объект obj — это пакет ранней версии.
- Процедура Scheme: inferior-package-name package
- Процедура Scheme: inferior-package-version package
- Процедура Scheme: inferior-package-synopsis package
- Процедура Scheme: inferior-package-description package
- Процедура Scheme: inferior-package-home-page package
- Процедура Scheme: inferior-package-location package
- Процедура Scheme: inferior-package-inputs package
- Процедура Scheme: inferior-package-native-inputs package
- Процедура Scheme: inferior-package-propagated-inputs package
- Процедура Scheme: inferior-package-transitive-propagated-inputs package
- Процедура Scheme: inferior-package-native-search-paths package
- Процедура Scheme: inferior-package-transitive-native-search-paths package
- Процедура Scheme: inferior-package-search-paths package
Эти процедуры являются двойниками метода доступа к записям пакетов (see
packageСсылка). Большинство из них работают с запросами для ранней версии, из которой происходит package, так что ранняя версия должна оставаться живой, когда вы вызываете эти процедуры.
Пакеты ранних версий могут использоваться прозрачно, как любой другой пакет
или объект типа файл в выражении G-expressions (see G-Expressions). Они
также прозрачно используются в процедуре packages->manifest, которая
обычно используется в манифестах (see the
--manifest option of guix package). Так можно вставлять
пакет ранней версии в принципе куда угодно, как если вставлять обычный
пакет: в манифесты, в поле packages вашего объявления
operating-system и т.д.
Next: Вызов guix archive, Previous: Младшие версии, Up: Управление пакетами [Contents][Index]
6.9 Вызов guix describe
Часто может возникать вопрос: "Какую ревизию Guix я использую?" - Или:
"Какие каналы я использую?" Это полезна информация во многих ситуациях: если
вы хотите повторить окружение на другой машине или в другом
пользовательском аккаунте, если вы хотите составить отчёт об ошибке, чтобы
определить, какие изменения в канале, который вы используете, вызвали
ошибку, или если вы хотите записать состояние вашей системы в целях
воспроизводимости. Команда guix describe отвечает на эти вопросы.
В случае запуска после guix pull команда guix describe
отображает канал(ы), из которых производилась сборка, включая URL и
репозиториев и ID коммитов (see Каналы):
$ guix describe
Generation 10 Sep 03 2018 17:32:44 (current)
guix e0fa68c
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: master
commit: e0fa68c7718fffd33d81af415279d6ddb518f727
Если вы знакомы с системой контроля версиями Git, эта команда по сути похожа
на git describe; выход тот же, что в guix pull
--list-generations, но ограничен текущим поколением (see the --list-generations option). Так как ID коммита Git выше
ссылается однозначно на снимок Guix, эта информация — всё, что нужно для
описания используемой ревизии Guix и повторения её.
Чтобы проще повторить Guix, guix describe также может вызываться
для вывода списка каналов вместо читаемого описания выше:
$ guix describe -f channels
(list (channel
(name 'guix)
(url "https://git.savannah.gnu.org/git/guix.git")
(commit
"e0fa68c7718fffd33d81af415279d6ddb518f727")))
(introduction
(make-channel-introduction
"9edb3f66fd807b096b48283debdcddccfea34bad"
(openpgp-fingerprint
"BBB0 2DDF 2CEA F6A8 0D1D E643 A2A0 6DF2 A33A 54FA")))))
Можно сохранить это в файл и подать на вход guix pull -C на любой
другой машине или через время, чтобы инициализировать эту конкретную
ревизию Guix (see the -C option). Теперь,
когда можно развернуть подобную ревизию Guix, вы можете также
полностью повторить программное окружение. Мы скромно полагаем, это
чудесно. Надеемся, вам это тоже понравится!
Подробнее об опциях, поддерживаемых guix describe:
--format=format-f formatПроизвести вывод в указанном формате format, одном из:
humanпроизвести вывод для чтения человеком;
каналыпроизвести список спецификаций каналов, который может использоваться в
guix pull -Cили вставлен в файл ~/.config/guix/channels.scm (see Вызовguix pull);channels-sans-introкак
channels, но без поляIntroduction; используйте его для создания спецификации канала, подходящей для Guix версии 1.1.0 или более ранней. ПолеIntroductionсвязано с аутентификацией канала (see Channel Authentication) и не поддерживается этими более ранними версиями;json¶произвести список спецификаций каналов в формате JSON;
recutilsпроизвести список спецификаций каналов в формате Recutils.
--list-rootsВывести доступные форматы для --format опции.
--profile=profile-p profileВывести информацию о профиле profile.
Previous: Вызов guix describe, Up: Управление пакетами [Contents][Index]
6.10 Вызов guix archive
Команда guix archive даёт возможность пользователям
экспортировать файлы со склада в простой архив и затем
импортировать их на машину с работающим Guix. В частности, это
позволяет передавать файлы склада одной машины на склад другой машины.
Примечание: Если вы ищете способ производить архивы в формате, который подходит для инструментов, отличных от Guix, смотрите see Вызов
guix pack.
Чтобы экспортировать файлы склада в архив в стандартный вывод, выполните:
guix archive --export options specifications...
Спецификации specifications могут быть либо именами файлов или
пакетами, как для команде guix package (see Вызов guix package). Например, следующая команда создаёт архив, содержащий выход
gui пакета git и главный выход emacs:
guix archive --export git:gui /gnu/store/...-emacs-24.3 > great.nar
Если указанные пакеты ещё не собраны, guix archive автоматически
соберёт их. Процесс сборки может контролироваться обычными опциями сборки
(see Стандартные параметры сборки).
Чтобы передать пакет emacs на машину, соединённую по SSH, нужно
следующее:
guix archive --export -r emacs | ssh the-machine guix archive --import
Точно также для передачи всего профиля пользователя из одной машины на другую, выполните:
guix archive --export -r $(readlink -f ~/.guix-profile) | \ ssh the-machine guix archive --import
Однако заметим, что в обоих примерах, передаются весь emacs и профиль
вместе с их зависимости (ввиду -r), не учитывая, что доступно на
складе целевой машины. Опция --missing помогает определить
отсутствующие элементы на целевом складе. Команда guix copy
упрощает и оптимизирует весь этот процесс, так что в данном случае она
решает проблему (see Вызов guix copy).
Каждый элемент храниища написан в normalized archive или nar
формате (описано ниже), и вывод guix archive --export (и ввод
guix archive --import) есть nar bundle.
Формат nar по духу сравним с tar, но с отличиями, которые делают его более
подходящим для наших целей. Во-первых, вместо записи всех метаданных Unix
для каждого файла, в формате nar упоминается только тип файла (обычный,
каталог или символическая ссылка); Разрешения Unix и владелец/группа
отклонены. Во-вторых, порядок, в котором хранятся записи каталога, всегда
следует порядку имен файлов в соответствии с порядком сопоставления C
локали. Это делает создание архивов полностью детерминированным.
Формат пакета nar - это, по сути, конкатенация нуля или более nars вместе с метаданными для каждого элемента store, который содержит: имя файла, ссылки, соответствующую derivation и цифровую подпись.
При экспортировании демон подписывает цифровой подписью содержимое архива, и эта цифровая подпись прикрепляется. При импорте демон проверяет подпись и отменяет импорт в случае недействительной подписи, или если ключ подписи не авторизован.
Основные опции:
--exportЭкспортировать указанные файлы хранилища или пакеты (смотрите ниже). Писать результирующий архив в стандартный вывод.
Зависимости не включаются в выход, если не задана опция --recursive.
-r--recursiveПри сочетании с
--exportэто указываетguix archiveвключать в архив зависимости обозначенных элементов. Так результирующий архив будет "сам в себе": содержит полный конвейер экспортированных элементов склада.--importЧитать архив из стандартного ввода и импортировать файлы, поставляемые им, на склад. Отклонить, если архив имеет недействительную цифровую подпись, или если он подписан публичным ключом, который не находится в списке авторизованных ключей (смотрите
--authorizeниже).--missingЧитать список имён файлов склада из стандартного ввода, одна линия - один файл, и писать в стандартный вывод подмножество этих файлов, отсутствующих на складе.
--generate-key[=parameters]¶Генерировать новую ключ-пару для демона. Это необходимо получить перед тем, как экспортировать архивы опцией
--export. Отметим, что эта операция обычно занимает время, так как необходимо собрать много энтропии для ключ-пары.Сгенерированная ключ-пара обычно сохраняется под /etc/guix, в файлы signing-key.pub (публичный ключ) и signing-key.sec (прватный ключ, который должен оставаться в секрете). Если параметры parameters пропущены, генерируется ключ ECDSA, используя кривую Ed25519, или для Libgcrypt версии ранее 1.6.0 — это 4096-битный ключ RSA. Альтернативно в параметрах parameters можно указать
genkey, соответствующие Libgcrypt (seegcry_pk_genkeyin The Libgcrypt Reference Manual).--authorize¶Авторизовать импорт, подписанный публичным ключом, поступивший на стандартный ввод. Публичный ключ должен быть в формате s-expression, то есть в таком же формате, как файл signing-key.pub.
Список авторизованных ключей хранится в файле /etc/guix/acl, доступном для редактирования человеком. Файл содержит s-expression расширенного формата, и он структурирован в виде списка контроля доступа в Simple Public-Key Infrastructure (SPKI).
--extract=directory-x directoryЧитать архив, представляющий один элемент, в качестве поставленного серверами подстановки (see Подстановки) и извлечь его в директорию directory. Это низкоуровневая операция, необходимая только в очень редких случаях, смотрите ниже.
Например, следующая команда распаковывает подстановку Emacs, поставленную
ci.guix.gnu.orgв /tmp/emacs:$ wget -O - \ https://ci.guix.gnu.org/nar/gzip/…-emacs-24.5 \ | gunzip | guix archive -x /tmp/emacs
Архивы, представляющие один элемент, отличаются от архивов, содержащих множество элементов, производимых
guix archive --export. Они содержат один элемент склада, но они не включают подпись. Так что эта операция не использует верификацию, и его выход должен рассматриваться как небезопасный.Основная цель этой операции — упростить просмотр содержимого архива, происходящего, возможно, из недоверенных серверов подстановок.
--list-tЧитать архив, представляющий один элемент, в качестве поставленного серверами подстановки (see Подстановки) и распечатайте список файлов, которые он содержит, как в этом примере:
$ wget -O - \ https://ci.guix.gnu.org/nar/lzip/…-emacs-26.3 \ | lzip -d | guix archive -t
Next: Разработка, Previous: Управление пакетами, Up: GNU Guix [Contents][Index]
7 Каналы
Guix и его коллекция пакетов можно обновить запуском guix pull
(see Вызов guix pull). По умолчанию guix pull скачивает и
разворачивает Guix из официального репозитория GNU Guix. Это может быть
изменено определением каналов channels в файле
~/.config/guix/channels.scm. Канал обозначает URL или ветку
репозитория Git для разворачивания. Также guix pull может быть
настроена для скачивания из одного или более каналов. Другими словами,
каналы могут использоваться для настройки и для расширения
Guix, как это будет показано ниже.
- Указание дополнительных каналов
- Использование отдельного канала Guix
- Копирование Guix
- Аутентификация канала
- Каналы с заменителями
- Создание канала
- Пакетные модули в поддиректории
- Объявление зависимостей канала
- Указание авторизаций канала
- Основной URL
- Написание новостей канала
Next: Использование отдельного канала Guix, Up: Каналы [Contents][Index]
7.1 Указание дополнительных каналов
Чтобы использовать канал, напишите ~/.config/guix/channels.scm, чтобы
обозначить guix pull скачивать оттуда в дополнение к
каналу(-ам) Guix по умолчанию:
;; Add my personal packages to those Guix provides. (cons (channel (name 'my-personal-packages) (url "https://example.org/personal-packages.git")) %default-channels)
Заметим, что сниппет выше (всегда!) код Scheme; мы используем cons
для добавления канала в список каналов, то есть в переменную
%default-channels (see cons and lists in GNU
Guile Reference Manual). Если этот файл написан, guix pull
производит сборку не только Guix, но и пакетных модулей из вашего
репозитория. В результате в ~/.config/guix/current содержится
объединение Guix и ваших собственных пакетных модулей:
$ guix describe
Generation 19 Aug 27 2018 16:20:48
guix d894ab8
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: master
commit: d894ab8e9bfabcefa6c49d9ba2e834dd5a73a300
variant-packages dd3df5e
repository URL: https://example.org/variant-packages.git
branch: master
commit: dd3df5e2c8818760a8fc0bd699e55d3b69fef2bb
The output of guix describe above shows that we’re now running
Generation 19 and that it includes both Guix and packages from the
variant-personal-packages channel (see Вызов guix describe).
Next: Копирование Guix, Previous: Указание дополнительных каналов, Up: Каналы [Contents][Index]
7.2 Использование отдельного канала Guix
Канал, названный guix, обозначает, откуда должен скачиваться сам Guix
(его инструменты командной строки и коллекция пакетов). Например,
предположим вы хотите обновиться из вашей собственной копии репозитория Guix
на example.org, а именно из ветки super-hacks, тогда можно
написать в ~/.config/guix/channels.scm следующую спецификацию:
;; Tell 'guix pull' to use my own repo. (list (channel (name 'guix) (url "https://example.org/my-guix.git") (branch "super-hacks")))
From there on, guix pull will fetch code from the
super-hacks branch of the repository at example.org. The
authentication concern is addressed below (see Аутентификация канала).
Next: Аутентификация канала, Previous: Использование отдельного канала Guix, Up: Каналы [Contents][Index]
7.3 Копирование Guix
The guix describe command shows precisely which commits were used
to build the instance of Guix we’re using (see Вызов guix describe).
We can replicate this instance on another machine or at a different point in
time by providing a channel specification “pinned” to these commits that
looks like this:
;; Deploy specific commits of my channels of interest. (list (channel (name 'guix) (url "https://git.savannah.gnu.org/git/guix.git") (commit "d894ab8e9bfabcefa6c49d9ba2e834dd5a73a300")) (channel (name 'my-personal-packages) (url "https://example.org/personal-packages.git") (branch "dd3df5e2c8818760a8fc0bd699e55d3b69fef2bb")))
To obtain this pinned channel specification, the easiest way is to run
guix describe and to save its output in the channels format
in a file, like so:
guix describe -f channels > channels.scm
The resulting channels.scm file can be passed to the -C
option of guix pull (see Вызов guix pull) or guix
time-machine (see Запуск guix time-machine), as in this example:
guix time-machine -C channels.scm -- shell python -- python3
Given the channels.scm file, the command above will always fetch the
exact same Guix instance, then use that instance to run the exact
same Python (see Вызов guix shell). On any machine, at any time, it
ends up running the exact same binaries, bit for bit.
Pinned channels address a problem similar to “lock files” as implemented by some deployment tools—they let you pin and reproduce a set of packages. In the case of Guix though, you are effectively pinning the entire package set as defined at the given channel commits; in fact, you are pinning all of Guix, including its core modules and command-line tools. You’re also getting strong guarantees that you are, indeed, obtaining the exact same software.
Это даёт вам супервозможности, позволяя вам отслеживать и управлять происхождением артефактов бинарников с точной детализацией, также повторять программные окружения — это воспроизводимость высокого уровня. Смотрите See Младшие версии, чтобы узнать другие преимущества таких супервозможностей.
Next: Каналы с заменителями, Previous: Копирование Guix, Up: Каналы [Contents][Index]
7.4 Аутентификация канала
guix pull и guix time-machine аутентифицируют код,
полученный из каналов: они гарантируют, что каждый полученный коммит
подписан авторизованным разработчиком. Цель состоит в том, чтобы защитить
канал от несанкционированных изменений, которые могут привести к запуску
вредоносного кода пользователями.
Как пользователь, вы должны предоставить channel introduction в вашем файле канала, чтобы Guix знал как авторизовать свой первый коммит. Спецификация канала, включая введения, выглядит как-то так:
(channel
(name 'some-channel)
(url "https://example.org/some-channel.git")
(introduction
(make-channel-introduction
"6f0d8cc0d88abb59c324b2990bfee2876016bb86"
(openpgp-fingerprint
"CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5"))))
В приведенной выше спецификации указано имя и URL-адрес канала. Вызов
make-channel-introduction выше указывает, что аутентификация этого
канала начинается с коммита 6f0d8cc…, который подписывается
ключом OpenPGP с отпечатком CABB A931….
Для основного канала, называемого guix, вы автоматически получаете
эту информацию из вашей установки Guix. Для других каналов, укажите
introduction для канала, предоставленное авторами канала, в ваш файл
channels.scm. Убедитесь, что вы получили introduction канала из
надежного источника, так как это основа вашего доверия.
Если вам любопытены механизмы авторизации, читайте дальше!
Next: Создание канала, Previous: Аутентификация канала, Up: Каналы [Contents][Index]
7.5 Каналы с заменителями
При запуске guix pull Guix сначала скомпилирует определения
каждого доступного пакета. Это тяжелая операция, для которой могут быть
доступны заменители (see Подстановки). Следующий фрагмент в
channels.scm гарантирует, что guix pull использует
последний коммит с доступными заменами для определений пакетов: это делается
путем запроса к серверу непрерывной интеграции по адресу https://ci.guix.gnu.org.
(use-package-modules guile emacs) (list (channel-with-substitutes-available %default-guix-channel "https://ci.guix.gnu.org"))
Учтите, что это не означает, что все пакеты, которые вы установите после
запуска guix pull, будут иметь доступные заменители. Это только
гарантирует, что guix pull не будет пытаться скомпилировать
определения пакетов. Это особенно полезно при использовании машин с
ограниченными ресурсами.
Next: Пакетные модули в поддиректории, Previous: Каналы с заменителями, Up: Каналы [Contents][Index]
7.6 Создание канала
Можно также задать дополнительные каналы для выборки оттуда. Ну, например, у вас ряд собственных вариантов пакетов или собственные пакеты, которые вы считаете не особо важным для отправки в проект Guix, но хотите, чтобы эти пакеты были доступны вам в командной строке прозрачно, без дополнительных действий. Вначале можно написать модули, содержащие определения этих пакетов (see Пакетные модули), затем разместить их в репозитории Git, и тогда вы или кто-либо ещё сможете использовать их в качестве дополнтельного канала для получения пакетов. Красиво, да?
Внимание: Прежде чем вы крикнете Ух-ты, это круто! и опубликуете собственный канал, необходимо учесть некоторые предостережения:
- Перед публикацией канала, пожалуйста, рассмотрите возможность поделиться вашими определениями пакетов со сборником Guix (see Содействие). Guix, как проект, открыт свободному программному обеспечению любого назначения, и пакеты в сборнике Guix готовы и доступны для использования всеми пользователями Guix и прошли проверку качества.
- Когда вы выгружаете определение пакета вне Guix, мы, разработчики Guix, полагаем, что вопрос совместимости ложится на вас. Учтите, что пакетные модули и определения пакетов — это код Scheme, который используют различные программные интерфейсы (API). Мы хотим оставить возможность для себя изменять эти API, чтобы продолжить улучшать Guix. И это может привести к поломке вашего канала. Мы никогда не меняем API необоснованно, но всё же мы не будем обновлять устаревшие, замороженные API.
- Вывод: если вы используете внешний канал, и этот канал ломается, пожалуйста, заявите об этой проблеме авторам каналв, но не в проект Guix.
Вы предупреждены! Обозначив это, мы верим, что внешние каналы — это способ для вас проявлять свою свободу и вместе с тем расширять коллекцию пакетов Guix и делиться улучшениями, что является основными догматами свободного программного обеспечения. Пожалуйста, свяжитесь с нами по e-mail guix-devel@gnu.org, если вы хотите обсудить это.
Чтобы создать канал, создайте репозиторий Git, содержащий ваши собственные
пакетные модули, и сделайте его доступным. Репозиторий может содержать
что-либо, но полезный канал будет содержать модули Guile, экспортирующие
пакеты. Когда вы начали использовать канал, Guix будет работать, как будто
корневая директория репозитория Git этого канала добавлена в путь загрузки
Guile (see Load Paths in GNU Guile Reference Manual). Например,
если ваш канал содержит файл my-packages/my-tools.scm, который
определяет модуль Guile, тогда модуль будет доступен под именем
(my-packages my-tools), и вы сможете использовать его, как любой
другой модуль (see Modules in GNU Guile Reference Manual).
Как автор канала, рассмотрите возможность объединения материалов для аутентификации с вашим каналом, чтобы пользователи могли его аутентифицировать. See Аутентификация канала и Указание авторизаций канала для получения информации о том, как это сделать.
Next: Объявление зависимостей канала, Previous: Создание канала, Up: Каналы [Contents][Index]
7.7 Пакетные модули в поддиректории
Как автор канала, вы можете хранить модули канала в подкаталоге. Если ваши модули находятся в подкаталоге guix, вы должны добавить файл метаданных .guix-channel, который содержит:
(channel
(version 0)
(directory "guix"))
Next: Указание авторизаций канала, Previous: Пакетные модули в поддиректории, Up: Каналы [Contents][Index]
7.8 Объявление зависимостей канала
Авторы канала могут решить расширить коллекцию пакетов пакетами, которые поставляются другими каналами. Они могут объявить, что их канал зависит от других каналов, в файле метаданных .guix-channel, который нужно разместить в корне репозитория канала.
Файл метаданных должен содержать простое выражение S-expression как это:
(channel
(version 0)
(dependencies
(channel
(name 'some-collection)
(url "https://example.org/first-collection.git")
;; The 'introduction' bit below is optional: you would
;; provide it for dependencies that can be authenticated.
(introduction
(channel-introduction
(version 0)
(commit "a8883b58dc82e167c96506cf05095f37c2c2c6cd")
(signer "CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5"))))
(channel
(name 'some-other-collection)
(url "https://example.org/second-collection.git")
(branch "testing"))))
В примере выше объявлен канал, который зависит от двух других каналов, из которых оба будут скачаны автоматически. Модули, предоставляемые каналом, будут скомпилированы в окружении, в котором доступны модули всех этих каналов.
В целях воспроизводимости и сопровождения вы должны избегать зависимостей от каналов, которые вы не контролируете, и вы должны стремиться минимизировать число зависимостей.
Next: Основной URL, Previous: Объявление зависимостей канала, Up: Каналы [Contents][Index]
7.9 Указание авторизаций канала
Как мы видели выше, Guix гарантирует, что исходный код, который он получает из каналов, поступает от авторизованных разработчиков. Как автор канала, вам необходимо указать список авторизованных разработчиков в файле .guix-authorizations в репозитории Git канала. Правило аутентификации простое: каждый коммит должен быть подписан ключом, указанным в файле .guix-authorizations его родительского коммита(ов) 13 файл .guix-authorizations выглядит так:
;; Пример '.guix-authorizations' файла. (authorizations (version 0) ;current file format version (("AD17 A21E F8AE D8F1 CC02 DBD9 F8AE D8F1 765C 61E3" (name "alice")) ("2A39 3FFF 68F4 EF7A 3D29 12AF 68F4 EF7A 22FB B2D5" (name "bob")) ("CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5" (name "charlie"))))
За каждым отпечатком следуют необязательные пары ключ/значение, как в примере выше. В настоящее время эти пары ключ/значение игнорируются.
Это правило аутентификации создает проблему с курицей и яйцом: как мы аутентифицируем первый коммит? В связи с этим: как нам поступать с каналами, история репозитория которых содержит неподписанные коммиты и не имеет .guix-authorizations? И как нам разветвлять существующие каналы?
Channel introductions answer these questions by describing the first commit
of a channel that should be authenticated. The first time a channel is
fetched with guix pull or guix time-machine, the command
looks up the introductory commit and verifies that it is signed by the
specified OpenPGP key. From then on, it authenticates commits according to
the rule above. Authentication fails if the target commit is neither a
descendant nor an ancestor of the introductory commit.
Кроме того, ваш канал должен предоставлять все ключи OpenPGP, которые
когда-либо упоминались в .guix-authorizations, хранящиеся как файлы
.key, которые могут быть либо двоичными, либо “ASCII-armored”. По
умолчанию эти файлы .key ищутся в ветке с именем keyring, но
вы можете указать другое имя ветки в .guix-channel следующим образом:
(channel
(version 0)
(keyring-reference "my-keyring-branch"))
Подытоживая, как автор канала, вы должны сделать три вещи, чтобы позволить другим пользователям авторизовать ваш код:
- Экспортируйте ключи OpenPGP прошлых и нынешних коммиттеров с помощью
gpg --exportи сохраните их в файлах .key, по умолчанию в ветке с именемkeyring(мы рекомендуем сделать это в orphan branch). - Добавьте .guix-authorizations в репозиторий канала. Сделайте это в подписанном коммите (see Доступ к коммитам, чтобы узнать, как подписывать коммиты Git)
- Рекламируйте channel introduction, например, на веб-странице вашего канала. Channel introduction, как мы видели выше, - это пара коммит/ключ, то есть коммит, который представляет .guix-authorizations, и отпечаток OpenPGP, использованный для его подписи.
Перед отправкой в ваш общедоступный репозиторий Git вы можете запустить
guix git-authenticate, чтобы убедиться, что вы подписали все
коммиты, которые собираетесь отправить, авторизованным ключом:
guix git authenticate commit signer
где commit и signer являются вашим channel introduction.
See Вызов guix package, подробнее.
Публикация подписанного канала требует дисциплины: любая ошибка, такая как неподписанная фиксация или фиксация, подписанная неавторизованным ключом, не позволит пользователям pull’ить с вашего канала - в этом весь смысл аутентификации! Обратите внимание на merge, в частности: merge коммиты считаются аутентичными, если и только если они подписаны ключом, присутствующим в файле .guix-authorizations обоих веток.
Next: Написание новостей канала, Previous: Указание авторизаций канала, Up: Каналы [Contents][Index]
7.10 Основной URL
Авторы каналов могут указать основной URL-адрес репозитория Git своего канала в файле .guix-channel, например:
(channel
(version 0)
(url "https://example.org/guix.git"))
Это позволяет guix pull определять, pull’ит ли он код из зеркала
канала; в этом случае он предупреждает пользователя о том, что зеркало может
быть устаревшим, и отображает основной URL-адрес. Таким образом,
пользователей нельзя обмануть, заставив их получить код с устаревшего
зеркала, которое не получает обновлений безопасности.
Эта функция имеет смысл только для аутентифицированных репозиториев, таких
как официальный канал guix, для которого guix pull
гарантирует, что полученный код аутентичен.
Previous: Основной URL, Up: Каналы [Contents][Index]
7.11 Написание новостей канала
Авторы канала могут захотеть сообщить своим пользователям информацию о важных изменениях в канале. Вы можете отправить им письмо по электронной почте, но это не удобно.
Вместо этого каналы могут предоставлять файл новостей; когда
пользователи канала запускают guix pull, этот файл новостей
автоматически читается, и guix pull --news может отображать
объявления, которые соответствуют новым зафиксированным коммитам, если
таковые имеются.
Для этого авторы каналов должны сначала объявить имя файла новостей в своем файле .guix-channel:
(channel
(version 0)
(news-file "etc/news.txt"))
Сам файл новостей, etc/news.txt в этом примере, должен выглядеть примерно так:
(channel-news
(version 0)
(entry (tag "the-bug-fix")
(title (en "Fixed terrible bug")
(fr "Oh la la"))
(body (en "@emph{Good news}! It's fixed!")
(eo "Certe ĝi pli bone funkcias nun!")))
(entry (commit "bdcabe815cd28144a2d2b4bc3c5057b051fa9906")
(title (en "Added a great package")
(ca "Què vol dir guix?"))
(body (en "Don't miss the @code{hello} package!"))))
В то время как файл новостей использует синтаксис Scheme, избегайте называть его расширением .scm, иначе он будет выбран при построении канала и выдаст ошибку, поскольку это недопустимый модуль. Кроме того, вы можете переместить модуль канала в подкаталог и сохранить файл новостей в другом каталоге.
Файл состоит из списка news entries. Каждая запись связана с коммитом или тегом: она описывает изменения, сделанные в этом коммите, возможно, также и в предыдущих коммитах. Пользователи видят записи только при первом получении коммита, на который ссылается запись.
Поле title должно быть однострочным, а body может быть
произвольно длинным, и оба могут содержать Texinfo разметку
(see Overview in GNU Texinfo). И заголовок, и тело являются
списком языковых тегов/кортежей сообщений, что позволяет комманде
guix pull отображать новости на языке, соответствующем языку
пользователя.
Если вы хотите перевести новости, используя рабочий процесс на основе
gettext, вы можете извлечь переводимые строки с помощью xgettext
(see xgettext Invocation in GNU Gettext Utilities). Например,
если вы сначала пишете новости на английском языке, команда ниже создает
PO-файл, содержащий строки для перевода:
xgettext -o news.po -l scheme -ken etc/news.txt
Подводя итог, да, вы можете использовать свой канал в качестве блога. Но будьте осторожны, это не совсем то, что могут ожидать ваши пользователи.
Next: Программный интерфейс, Previous: Каналы, Up: GNU Guix [Contents][Index]
8 Разработка
Если вы являетесь разработчиком программного обеспечения, Guix предоставляет инструменты, которые вы можете найти полезными, независимо от языка разработки. Об этом данный раздел.
The guix shell command provides a convenient way to set up one-off
software environments, be it for development purposes or to run a command
without installing it in your profile. The guix pack command
allows you to create application bundles that can be easily
distributed to users who do not run Guix.
Next: Вызов guix environment, Up: Разработка [Contents][Index]
8.1 Вызов guix shell
The purpose of guix shell is to make it easy to create one-off
software environments, without changing one’s profile. It is typically used
to create development environments; it is also a convenient way to run
applications without “polluting” your profile.
Примечание: The
guix shellcommand was recently introduced to supersedeguix environment(see Вызовguix environment). If you are familiar withguix environment, you will notice that it is similar but also—we hope!—more convenient.
Основной синтаксис:
guix shell [options] [package…]
The following example creates an environment containing Python and NumPy,
building or downloading any missing package, and runs the python3
command in that environment:
guix shell python python-numpy -- python3
Development environments can be created as in the example below, which spawns an interactive shell containing all the dependencies and environment variables needed to work on Inkscape:
guix shell --development inkscape
Exiting the shell places the user back in the original environment before
guix shell was invoked. The next garbage collection
(see Вызов guix gc) may clean up packages that were installed in the
environment and that are no longer used outside of it.
As an added convenience, guix shell will try to do what you mean
when it is invoked interactively without any other arguments as in:
guix shell
If it finds a manifest.scm in the current working directory or any of
its parents, it uses this manifest as though it was given via
--manifest. Likewise, if it finds a guix.scm in the same
directories, it uses it to build a development profile as though both
--development and --file were present. In either case, the
file will only be loaded if the directory it resides in is listed in
~/.config/guix/shell-authorized-directories. This provides an easy
way to define, share, and enter development environments.
By default, the shell session or command runs in an augmented
environment, where the new packages are added to search path environment
variables such as PATH. You can, instead, choose to create an
isolated environment containing nothing but the packages you asked
for. Passing the --pure option clears environment variable
definitions found in the parent environment14; passing --container goes one step further by
spawning a container isolated from the rest of the system:
guix shell --container emacs gcc-toolchain
The command above spawns an interactive shell in a container where nothing
but emacs, gcc-toolchain, and their dependencies is
available. The container lacks network access and shares no files other
than the current working directory with the surrounding environment. This
is useful to prevent access to system-wide resources such as /usr/bin
on foreign distros.
This --container option can also prove useful if you wish to run a
security-sensitive application, such as a web browser, in an isolated
environment. For example, the command below launches Ungoogled-Chromium in
an isolated environment, this time sharing network access with the host and
preserving its DISPLAY environment variable, but without even sharing
the current directory:
guix shell --container --network --no-cwd ungoogled-chromium \ --preserve='^DISPLAY$' -- chromium
guix shell определяет переменную GUIX_ENVIRONMENT в
оболочке, которую создаёт; её значением является имя файла профиля этого
окружения. Это позволяет пользователям, скажем, определить специфичные
значения окружений разработки в .bashrc (see Bash Startup Files in The GNU Bash Reference Manual):
if [ -n "$GUIX_ENVIRONMENT" ]
then
export PS1="\u@\h \w [dev]\$ "
fi
... или просмотеть профиль:
$ ls "$GUIX_ENVIRONMENT/bin"
Доступные опции резюмированы ниже.
--checkSet up the environment and check whether the shell would clobber environment variables. It’s a good idea to use this option the first time you run
guix shellfor an interactive session to make sure your setup is correct.For example, if the shell modifies the
PATHenvironment variable, report it since you would get a different environment than what you asked for.Such problems usually indicate that the shell startup files are unexpectedly modifying those environment variables. For example, if you are using Bash, make sure that environment variables are set or modified in ~/.bash_profile and not in ~/.bashrc—the former is sourced only by log-in shells. See Bash Startup Files in The GNU Bash Reference Manual, for details on Bash start-up files.
--development-DCause
guix shellto include in the environment the dependencies of the following package rather than the package itself. This can be combined with other packages. For instance, the command below starts an interactive shell containing the build-time dependencies of GNU Guile, plus Autoconf, Automake, and Libtool:guix shell -D guile autoconf automake libtool
--expression=expr-e exprСоздать окружение для пакета или списка пакетов, которые соответствуют выражению expr.
Например, запуск:
guix shell -D -e '(@ (gnu packages maths) petsc-openmpi)'
запускает оболочку с окружением для этого специфического варианта пакета PETSc.
Запуск:
guix shell -e '(@ (gnu) %base-packages)'
стартует оболочку со всеми доступными базовыми пакетами.
Команды выше используют только выход по умолчанию обозначенных пакетов. Чтобы выбрать другие выходы, можно указать два элемента кортежей:
guix shell -e '(list (@ (gnu packages bash) bash) "include")'
See
package->development-manifest, for information on how to write a manifest for the development environment of a package.--file=file-f fileCreate an environment containing the package or list of packages that the code within file evaluates to.
Например, file может содержать определение (see Описание пакетов):
(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))With the file above, you can enter a development environment for GDB by running:
guix shell -D -f gdb-devel.scm
--manifest=file-m fileСоздать окружение для пакетов, содержащихся в объекте манифеста, возвращаемого кодом Scheme в файле file.
Это то же, что опция с таким же именем в
guix package(see --manifest) и использует такие же файлы манифестов.See Writing Manifests, for information on how to write a manifest. See --export-manifest below on how to obtain a first manifest.
--export-manifestWrite to standard output a manifest suitable for --manifest corresponding to given command-line options.
This is a way to “convert” command-line arguments into a manifest. For example, imagine you are tired of typing long lines and would like to get a manifest equivalent to this command line:
guix shell -D guile git emacs emacs-geiser emacs-geiser-guile
Just add --export-manifest to the command line above:
guix shell --export-manifest \ -D guile git emacs emacs-geiser emacs-geiser-guile
... and you get a manifest along these lines:
(concatenate-manifests (list (specifications->manifest (list "git" "emacs" "emacs-geiser" "emacs-geiser-guile")) (package->development-manifest (specification->package "guile"))))You can store it into a file, say manifest.scm, and from there pass it to
guix shellor indeed pretty much anyguixcommand:guix shell -m manifest.scm
Voilà, you’ve converted a long command line into a manifest! That conversion process honors package transformation options (see Параметры преобразования пакета) so it should be lossless.
--profile=profile-p profileCreate an environment containing the packages installed in profile. Use
guix package(see Вызовguix package) to create and manage profiles.--pureСброс существующих переменных окружения при сборке нового окружения, кроме обозначенных в опции --preserve (смотрите ниже). Эффект этой опции — создание окружения, в котором пути поиска содержат только входные данные пакета.
--preserve=regexp-E regexpПри использовании вместе с --pure, оставить содержимое переменных окружения, соответствующих выражению regexp — другими словами, включить их в "белый список" переменных окружения, которые не должны обнуляться. Эту опцию можно повторять несколько раз.
guix shell --pure --preserve=^SLURM openmpi … \ -- mpirun …
Этот пример запускает
mpirunв контексте, в котором определены только следующие переменные окружения:PATH, переменные окружения, чьи имена начинаются с ‘SLURM’, а также обычные "дорогие" переменные (HOME,USER, и т.д.).--search-pathsОтобразить определения переменных окружения, которые составляют окружение.
--system=system-s systemПопытаться собрать систему system, то есть
i686-linux.--container¶-CЗапустить command в изолированном контейнере. Текущая рабочая директория за пределами контейнера отображается внутри контейнера. В дополнение, если это не переопределено опцией
--user, тогда настраивается фиктивная домашняя директория, которая совпадает с домашней директорией текущего пользователя, а также соответствующий файл /etc/passwd.Порождаемый процесс снаружи предстаёт как запущенный от текущего пользователя. Внутри контейнера он имеет такие же UID и GID, что и текущий пользователь, если не обозначена --user (смотрите ниже).
--network-NРазделять пространство сетевых имён контейнера с хостящей системой. Контейнеры, созданные без этого флага, могут только иметь доступ к петлевому устройству.
--link-profile-PСвязать профиль окружения контейнера с ~/.guix-profile внутри контейнера. Это эквивалент запуска команды
ln -s $GUIX_ENVIRONMENT ~/.guix-profileвнутри контейнера. Связывание завершится ошибкой и отменит создание окружения, если директория уже существует, что, конечно, будет происходить, еслиguix shellвызвана в домашней директории пользователя.Определённые пакеты сконфигурированы, чтобы смотреть конфигурационные файлы и данные в
~/.guix-profile;15--link-profileпозволяет этим программам вести себя ожидаемо внутри окружения.--user=user-u userИспользовать в контейнере имя пользователя user вместо текущего пользователя. Созданная внутри контейнера запись /etc/passwd будет содержать имя user, домашняя директория будет /home/user, но не будут копированы пользовательские данные GECOS. Более того, внутри контейнера UID и GID будут 1000. user не обязательно должен существовать в системе.
В дополнение, любой разделяемый или расширяемый путь (смотрите
--shareи--exposeсоответственно), чьи цели находятся в домашней директории пользователя, будут отображены соответственно в /home/USER; это включает автоматическое отображение текущей рабочей директории.# will expose paths as /home/foo/wd, /home/foo/test, and /home/foo/target cd $HOME/wd guix shell --container --user=foo \ --expose=$HOME/test \ --expose=/tmp/target=$HOME/targetЭто ограничит утечку данных идентификации пользователя через домашние пути и каждое из полей пользователя. Это один единственный компонент расширенного решения приватности/анонимности — ничто не войдёт, ничто не выйдет.
--no-cwdДля контейнеров стандартным поведением является разделение текущего рабочего каталога с изолированным контейнером и немедленное переключение на этот каталог в контейнере. Если это нежелательно,
--no-cwdприведет к автоматическому доступу к текущему рабочему каталогу not, который изменится на домашний каталог пользователя в контейнере. Смотрите также--user.--expose=source[=target]--share=source[=target]Расширить файловую систему контейнера источником source из хостящей системы в качестве файловой системы только для чтения с целью target внутри контейнера. Если цель target не задана, источник source используется как целевая точка монтирования в контейнере.
Пример ниже порождает Guile REPL в контейнере, в котором домашняя директория пользователя доступна только для чтения через директорию /exchange:
guix shell --container --expose=$HOME=/exchange guile -- guile
--symlink=spec-S specFor containers, create the symbolic links specified by spec, as documented in pack-symlink-option.
--emulate-fhs-FWhen used with --container, emulate a Filesystem Hierarchy Standard (FHS) configuration within the container, providing /bin, /lib, and other directories and files specified by the FHS.
As Guix deviates from the FHS specification, this option sets up the container to more closely mimic that of other GNU/Linux distributions. This is useful for reproducing other development environments, testing, and using programs which expect the FHS specification to be followed. With this option, the container will include a version of glibc that will read /etc/ld.so.cache within the container for the shared library cache (contrary to glibc in regular Guix usage) and set up the expected FHS directories: /bin, /etc, /lib, and /usr from the container’s profile.
--rebuild-cache¶-
In most cases,
guix shellcaches the environment so that subsequent uses are instantaneous. Least-recently used cache entries are periodically removed. The cache is also invalidated, when using --file or --manifest, anytime the corresponding file is modified.The --rebuild-cache forces the cached environment to be refreshed. This is useful when using --file or --manifest and the
guix.scmormanifest.scmfile has external dependencies, or if its behavior depends, say, on environment variables. --root=file¶-r file-
Создать символическую ссылку file на профиль этого окружения и зарегистрировать её как корень сборщика мусора.
Это полезно, если вы хотите защитить своё окружение от сборщика мусора, сделать его "постоянным".
When this option is omitted,
guix shellcaches profiles so that subsequent uses of the same environment are instantaneous—this is comparable to using --root except thatguix shelltakes care of periodically removing the least-recently used garbage collector roots.In some cases,
guix shelldoes not cache profiles—e.g., if transformation options such as --with-latest are used. In those cases, the environment is protected from garbage collection only for the duration of theguix shellsession. This means that next time you recreate the same environment, you could have to rebuild or re-download packages.See Вызов
guix gc, for more on GC roots.
guix shell также поддерживает все обычные опции сборки, которые
поддерживает команда guix build (see Стандартные параметры сборки), а
также опции трансформации пакета (see Параметры преобразования пакета).
Next: Вызов guix pack, Previous: Вызов guix shell, Up: Разработка [Contents][Index]
8.2 Вызов guix environment
The purpose of guix environment is to assist in creating
development environments.
Deprecation warning: The
guix environmentcommand is deprecated in favor ofguix shell, which performs similar functions but is more convenient to use. See Вызовguix shell.Being deprecated,
guix environmentis slated for eventual removal, but the Guix project is committed to keeping it until May 1st, 2023. Please get in touch with us at guix-devel@gnu.org if you would like to discuss it.
Основной синтаксис:
guix environment options package…
Следующий пример порождает новую оболочку, установленную для разработки GNU Guile:
guix environment guile
Если необходимые зависимости еще не собраны, guix environment
автоматически построит их. Среда новой оболочки - это расширенная версия
среды, в которой была запущена guix environment. Она содержит
необходимые пути поиска для сборки данного пакета, добавленные к
существующим переменным среды. Чтобы создать “чистую” среду, в которой
исходные переменные среды не были установлены, используйте параметр
--pure 16.
Выход из окружения Guix аналогичен выходу из оболочки и возвращает
пользователя в старое окружение до вызова guix environment.
Следующая сборка мусора (see Вызов guix gc) очистит пакеты, которые
были установлены в окружении и больше не используются за ее пределами.
guix environment определяет переменную GUIX_ENVIRONMENT в
оболочке, которую создаёт; её значением является имя файла профиля этого
окружения. Это позволяет пользователям, скажем, определить специфичные
значения окружений разработки в .bashrc (see Bash Startup Files in The GNU Bash Reference Manual):
if [ -n "$GUIX_ENVIRONMENT" ]
then
export PS1="\u@\h \w [dev]\$ "
fi
... или просмотеть профиль:
$ ls "$GUIX_ENVIRONMENT/bin"
Дополним, что может быть указано более одного пакета, в таком случае используется объединённые входные данные для указанных пакетов. Например, команда ниже порождает оболочку, в котором доступны все зависимости, как Guile, так и Emacs:
guix environment guile emacs
Иногда интерактивная сессия оболочки не нужна. Можно вызвать произвольную
команду при указании токена --, который отделяет команду от остальных
аргументов:
guix environment guile -- make -j4
In other situations, it is more convenient to specify the list of packages
needed in the environment. For example, the following command runs
python from an environment containing Python 3 and NumPy:
guix environment --ad-hoc python-numpy python -- python3
Более того, возможно, вам потребуются зависимости пакета, а также некоторые
дополнительные пакеты, которые не являются зависимостями процесса сборки или
процесса исполнения (работы), но важны при разработке. Для этого и указан
флаш --ad-hoc. Пакеты, обозначенные до --ad-hoc
интерпретируются как пакеты, чьи зависимости будут добавлены в
окружение. Пакеты, которые обозначены после --ad-hoc,
интерпретируются как пакеты, которые будут добавлены в окружение
непосредственно. Например, следующая команда создаёт окружение разработки
Guix, которая в дополнение включает Git и strace:
guix environment guix --ad-hoc git strace
Иногда возникает необходимость изолировать окружение настолько, насколькоо возможно, для максимальной чистоты и воспроизводимости. В частности, при использовании Guix на дистрибутиве, отличном от системы Guix, желательно предотвращать доступ из окружения разработки к /usr/bin и другим ресурсам системы. Например, следующая команда порождает Guile REPL в "контейнере", в котором монтированы только склад и текущая рабочая директория:
guix environment --ad-hoc --container guile -- guile
Примечание: Опция
--containerтребует Linux-libre 3.19 или новее.
Другой типичный вариант использования контейнеров - запуск приложений,
чувствительных к безопасности, таких как веб-браузер. Чтобы запустить
Eolie, мы должны предоставить доступ к некоторым файлам и каталогам; мы
используем nss-certs и предоставляем /etc /ssl /certs/ для
аутентификации HTTPS; наконец, мы сохраняем переменную среды DISPLAY,
поскольку контейнерные графические приложения не будут отображаться без нее.
guix environment --preserve='^DISPLAY$' --container --network \ --expose=/etc/machine-id \ --expose=/etc/ssl/certs/ \ --share=$HOME/.local/share/eolie/=$HOME/.local/share/eolie/ \ --ad-hoc eolie nss-certs dbus -- eolie
Доступные опции резюмированы ниже.
--checkSet up the environment and check whether the shell would clobber environment variables. See --check, for more info.
--root=file¶-r file-
Создать символическую ссылку file на профиль этого окружения и зарегистрировать её как корень сборщика мусора.
Это полезно, если вы хотите защитить своё окружение от сборщика мусора, сделать его "постоянным".
Если эта опция пропущена, окружеие защищено от сборщика мусора только на время сессии
guix environment. Это означает, что в следующий раз, когда вы создадите такое же окружение, вам потребуется пересобирать и скачивать пакеты заново. See Вызовguix gc, for more on GC roots. --expression=expr-e exprСоздать окружение для пакета или списка пакетов, которые соответствуют выражению expr.
Например, запуск:
guix environment -e '(@ (gnu packages maths) petsc-openmpi)'
запускает оболочку с окружением для этого специфического варианта пакета PETSc.
Запуск:
guix environment --ad-hoc -e '(@ (gnu) %base-packages)'
стартует оболочку со всеми доступными базовыми пакетами.
Команды выше используют только выход по умолчанию обозначенных пакетов. Чтобы выбрать другие выходы, можно указать два элемента кортежей:
guix environment --ad-hoc -e '(list (@ (gnu packages bash) bash) "include")'
--load=file-l fileСоздать окружение для пакета или списка пакетов, код которых задан в файле file.
Например, file может содержать определение (see Описание пакетов):
(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))--manifest=file-m fileСоздать окружение для пакетов, содержащихся в объекте манифеста, возвращаемого кодом Scheme в файле file.
Это то же, что опция с таким же именем в
guix package(see --manifest) и использует такие же файлы манифестов.See
guix shell --export-manifest, for information on how to “convert” command-line options into a manifest.--ad-hocВключить все указанные пакеты в результирующее окружение, если бы целевой (лат. ad hoc) пакет имел бы их как входные данные. Эта опция полезна для быстрого создания окружения без необходимости писать выражение типа пакет, содержащее желаемые входные данные.
Например, команда:
guix environment --ad-hoc guile guile-sdl -- guile
запускает
guileв окружении, в котором доступны Guile и Guile-SDL.Отметим, что этот пример явно запрашивает выходы
guileиguile-sdlпо умолчанию, но возможно запросить специфичный выход, то естьglib:binзапрашивает выходbinизglib(see Пакеты со множественным выходом).Эта опция может сочетаться с поведением по умолчанию
guix environment. Пакеты, которые появляются до--ad-hocинтерпретируются как пакеты, чьи зависимости будут добавлены в окружение (поведение по умолчанию). Пакеты, которые появляются после этой опции, интерпретируются как пакеты, которые будут добавлены в окружение непосредственно.--profile=profile-p profileCreate an environment containing the packages installed in profile. Use
guix package(see Вызовguix package) to create and manage profiles.--pureСброс существующих переменных окружения при сборке нового окружения, кроме обозначенных в опции --preserve (смотрите ниже). Эффект этой опции — создание окружения, в котором пути поиска содержат только входные данные пакета.
--preserve=regexp-E regexpПри использовании вместе с --pure, оставить содержимое переменных окружения, соответствующих выражению regexp — другими словами, включить их в "белый список" переменных окружения, которые не должны обнуляться. Эту опцию можно повторять несколько раз.
guix environment --pure --preserve=^SLURM --ad-hoc openmpi … \ -- mpirun …
Этот пример запускает
mpirunв контексте, в котором определены только следующие переменные окружения:PATH, переменные окружения, чьи имена начинаются с ‘SLURM’, а также обычные "дорогие" переменные (HOME,USER, и т.д.).--search-pathsОтобразить определения переменных окружения, которые составляют окружение.
--system=system-s systemПопытаться собрать систему system, то есть
i686-linux.--container¶-CЗапустить command в изолированном контейнере. Текущая рабочая директория за пределами контейнера отображается внутри контейнера. В дополнение, если это не переопределено опцией
--user, тогда настраивается фиктивная домашняя директория, которая совпадает с домашней директорией текущего пользователя, а также соответствующий файл /etc/passwd.Порождаемый процесс снаружи предстаёт как запущенный от текущего пользователя. Внутри контейнера он имеет такие же UID и GID, что и текущий пользователь, если не обозначена --user (смотрите ниже).
--network-NРазделять пространство сетевых имён контейнера с хостящей системой. Контейнеры, созданные без этого флага, могут только иметь доступ к петлевому устройству.
--link-profile-PСвязать профиль окружения контейнера с ~/.guix-profile внутри контейнера. Это эквивалент запуска команды
ln -s $GUIX_ENVIRONMENT ~/.guix-profileвнутри контейнера. Связывание завершится ошибкой и отменит создание окружения, если директория уже существует, что, конечно, будет происходить, еслиguix environmentвызвана в домашней директории пользователя.Определённые пакеты сконфигурированы, чтобы смотреть конфигурационные файлы и данные в
~/.guix-profile;17--link-profileпозволяет этим программам вести себя ожидаемо внутри окружения.--user=user-u userИспользовать в контейнере имя пользователя user вместо текущего пользователя. Созданная внутри контейнера запись /etc/passwd будет содержать имя user, домашняя директория будет /home/user, но не будут копированы пользовательские данные GECOS. Более того, внутри контейнера UID и GID будут 1000. user не обязательно должен существовать в системе.
В дополнение, любой разделяемый или расширяемый путь (смотрите
--shareи--exposeсоответственно), чьи цели находятся в домашней директории пользователя, будут отображены соответственно в /home/USER; это включает автоматическое отображение текущей рабочей директории.# will expose paths as /home/foo/wd, /home/foo/test, and /home/foo/target cd $HOME/wd guix environment --container --user=foo \ --expose=$HOME/test \ --expose=/tmp/target=$HOME/targetЭто ограничит утечку данных идентификации пользователя через домашние пути и каждое из полей пользователя. Это один единственный компонент расширенного решения приватности/анонимности — ничто не войдёт, ничто не выйдет.
--no-cwdДля контейнеров стандартным поведением является разделение текущего рабочего каталога с изолированным контейнером и немедленное переключение на этот каталог в контейнере. Если это нежелательно,
--no-cwdприведет к автоматическому доступу к текущему рабочему каталогу not, который изменится на домашний каталог пользователя в контейнере. Смотрите также--user.--expose=source[=target]--share=source[=target]Расширить файловую систему контейнера источником source из хостящей системы в качестве файловой системы только для чтения с целью target внутри контейнера. Если цель target не задана, источник source используется как целевая точка монтирования в контейнере.
Пример ниже порождает Guile REPL в контейнере, в котором домашняя директория пользователя доступна только для чтения через директорию /exchange:
guix environment --container --expose=$HOME=/exchange --ad-hoc guile -- guile
--emulate-fhs-FFor containers, emulate a Filesystem Hierarchy Standard (FHS) configuration within the container, see the official specification. As Guix deviates from the FHS specification, this option sets up the container to more closely mimic that of other GNU/Linux distributions. This is useful for reproducing other development environments, testing, and using programs which expect the FHS specification to be followed. With this option, the container will include a version of
glibcwhich will read/etc/ld.so.cachewithin the container for the shared library cache (contrary toglibcin regular Guix usage) and set up the expected FHS directories:/bin,/etc,/lib, and/usrfrom the container’s profile.
guix environment также поддерживает все обычные опции сборки,
которые поддерживает команда guix build (see Стандартные параметры сборки), а также опции трансформации пакета (see Параметры преобразования пакета).
Next: Тулчейн GCC, Previous: Вызов guix environment, Up: Разработка [Contents][Index]
8.3 Вызов guix pack
Иногда бывает необходимо передать программу людям, которые (ещё!) не
являются счастливыми обладателями Guix. Вы могли бы им рекомендовать
заустить guix package -i something, но в данном случае это
не подхлдит. Тогда guix pack решает вопрос.
Примечание: Если вы ищете способ обмена бинарниками между машинами, работающими с Guix, see Вызов
guix copy, Вызовguix publishи Вызовguix archive.
Команда guix pack создаёт обёрнутый набор или
программный набор: она создаёт архив tarball или другой архив,
содержащий исполняемые файлы программного обеспечения, которое вас
интересует, а также все его зависимости. Результирующий архив может
использоваться на любой машине, которая не имеет Guix, а люди могут
запустить совершенно такие же бинарники, как у вас в Guix. Набор создаётся
со свойством воспроизводимости до бита, так что любой может проверить, что
он действительно содержит результаты сборок, которые вы поставляете.
Например, чтобы создать набор, содержащий Guile, Emacs, Geiser и все их зависимости, можно запустить:
$ guix pack guile emacs geiser … /gnu/store/…-pack.tar.gz
Результатом будет архив tarball, содержащий директорию /gnu/store со
всеми соответствующими пакетами. Результирующий архив содержат профиль
с тремя запрошенными пакетами; профиль представляет то же самое, что можно
создать командой guix package -i. Это механизм, который
используется, собственно, для создания автономного (standalone) бинарного
архива Guix (see Бинарная установка).
Пользователи этого пакета должны запускать /gnu/store/…-profile/bin/guile для запуска Guile, что может быть не удобно. Чтобы исправить это, можно создать, например, символическую ссылку /opt/gnu/bin на профиль:
guix pack -S /opt/gnu/bin=bin guile emacs geiser
Так пользователи смогут благополучно напечатать /opt/gnu/bin/guile, и всё хорошо.
Что если получатель вашего пакета не имеет привилегий root на своей машине,
и поэтому не может распаковать его в корне файловой системы? В таком случае
вам стоит использовать опцию --relocatable (смотрите ниже). Эта опция
производит перемещаемые бинарники, в том плане, что они могут
размещаться где угодно в иерархии файловой системы: в примере выше
пользователи могут распаковать ваш архив в свои домашние директории и
напрямую запустить ./opt/gnu/bin/guile.
В качестве альтернативы можно производить пакет в формате образа Docker, используя следующую команду:
guix pack -f docker guile emacs geiser
Результатом будет архив, который можно передать команде docker
load, followed by docker run:
docker load < file docker run -ti guile-guile-readline /bin/guile
Результатом будет архив, который можно передать команде docker
load. Смотрите
документацию Docker для подробной информации.
Ещё одна опция производит образ SquashFS следующей командой:
guix pack -f squashfs guile emacs geiser
Результатом будет образ файловой системы SquashFS, который может
непосредственно монтироваться как образ, содержащий контейнер файловой
системы, с помощью контейнерного
окружения Singularity, используя команды типа singularity shell
или singularity exec.
Несколько опций командной строки позволяют вам переделывать ваш пакет:
--format=format-f formatПроизвести пакет в указанном формате format.
Возможные форматы:
tarballЭто формат по умолчанию. Он производит архив tarball, содержащий все заданные бинарники и символические ссылки.
dockerЭто производит архив, соответствующий спецификации образа Docker.
squashfsЭто создает образ SquashFS, содержащий все указанные двоичные файлы и символические ссылки, а также пустые точки монтирования для виртуальных файловых систем, таких как procfs.
Примечание: Singularity требует, чтобы вы указали /bin /sh в образе. По этой причине
guix pack -f squashfsвсегда подразумевает-S /bin=bin. Таким образом, вызовguix packвсегда должен начинаться с чего-то вроде:guix pack -f squashfs guile emacs geiser
Если вы забудете пакет
bash(или аналогичный),singularity runиsingularity execвыдаст бесполезное сообщение “нет такого файла или каталога”.debThis produces a Debian archive (a package with the ‘.deb’ file extension) containing all the specified binaries and symbolic links, that can be installed on top of any dpkg-based GNU(/Linux) distribution. Advanced options can be revealed via the --help-deb-format option. They allow embedding control files for more fine-grained control, such as activating specific triggers or providing a maintainer configure script to run arbitrary setup code upon installation.
guix pack -f deb -C xz -S /usr/bin/hello=bin/hello hello
Примечание: Because archives produced with
guix packcontain a collection of store items and because eachdpkgpackage must not have conflicting files, in practice that means you likely won’t be able to install more than one such archive on a given system.Внимание:
dpkgwill assume ownership of any files contained in the pack that it does not know about. It is unwise to install Guix-produced ‘.deb’ files on a system where /gnu/store is shared by other software, such as a Guix installation or other, non-deb packs.
--relocatable-RСоздавать relocatable binaries — то есть двоичные файлы, которые можно разместить в любом месте иерархии файловой системы и запускать оттуда.
Когда эта опция передается один раз, конечные двоичные файлы требуют поддержки user namespaces в ядре Linux; при передаче дважды18, Relocatable двоичные файлы возвращаются к другим методам, если пользовательские пространства имен недоступны, и по существу работают где угодно - см. ниже что под этим подразумевается.
Например, если вы создаете пакет, содержащий Bash, с помощью:
guix pack -RR -S /mybin=bin bash
... вы можете скопировать этот пакет на машину, на которой отсутствует Guix, и из своего домашнего каталога как обычный пользователь запустите:
tar xf pack.tar.gz ./mybin/sh
В этой оболочке, если вы наберете
ls /gnu/store, вы заметите, что отобразятся /gnu/store и содержатся все зависимостиbash, даже если на машине нет /gnu/store! Это, вероятно, самый простой способ установить программное обеспечение, созданное с помощью Guix, на машине, отличной от Guix.Примечание: По умолчанию relocatable двоичные файлы полагаются на функцию user namespace ядра Linux, которая позволяет непривилегированным пользователям монтировать или изменять root. Старые версии Linux не поддерживали его, а некоторые дистрибутивы GNU/Linux его отключили.
Чтобы создать relocatable двоичные файлы, которые работают даже при отсутствии пользовательских пространств имен, передайте --relocatable или -R дважды. В этом случае двоичные файлы будут пытаться использовать пространство имен пользователей и возвращаться к другому механизму выполнения, если пространства имен пользователей не поддерживаются. Поддерживаются следующие механизмы выполнения:
по умолчаниюПопробовать использовать пространства имен пользователей и вернуться к PRoot, если пространства имен пользователей не поддерживаются (см. ниже).
форматирование кодаПопробовать использовать пространства имен пользователей и вернуться к Fakechroot, если пространства имен пользователей не поддерживаются (см. ниже).
userЗапустить программу через пользовательские пространства имен и прервать, если они не поддерживаются.
chrootЗапустить PRoot. Программа PRoot обеспечивает необходимую поддержку виртуализации файловой системы. Это достигается с помощью системного вызова
ptraceв запущенной программе. Преимущество этого подхода заключается в том, что это не требует специальной поддержки ядра, но это требует дополнительных затрат времени выполнения каждый раз, когда выполняется системный вызов.chrootЗапустить Fakechroot. Fakechroot виртуализирует доступ к файловой системе путем перехвата вызовов функций библиотеки C, таких как
open,stat,execи т.п. В отличие от PRoot, накладных расходов очень мало. Однако это не всегда работает: например, некоторые обращения к файловой системе, сделанные из библиотеки C, не перехватываются, а обращения к файловой системе, сделанные через прямые системные вызовы, также не перехватываются, что приводит к нестабильному поведению.
При запуске обернутой программы вы можете явно запросить один из механизмов выполнения, перечисленных выше, установив соответствующую переменную среды
GUIX_EXECUTION_ENGINE.--commit=commitИспользуйте command в качестве точки входа конечного пакета, если формат пакета поддерживает это — в настоящее время
dockerиsquashfs(Singularity) поддерживают это. command должна относиться к профилю, содержащемуся в пакете.Точка входа указывает команду, которую по умолчанию автоматически запускают такие инструменты, как
docker runилиsingularity run. Например, вы можете сделать:guix pack -f docker guile emacs geiser
Полученный пакет может быть легко импортирован, и запущен через
docker runбез дополнительных аргументов, пораждаяbin/guile:docker load -i pack.tar.gz docker run image-id
--expression=expr-e exprПроцедура, при выполнении которой возвращается пакет.
Это то же, что опция с таким же именем в
guix package(see --manifest) и использует такие же файлы манифестов.--manifest=file-m fileИспользовать пакеты, содержащиеся в объекте манифеста, возвращенном кодом Scheme в file. Эта опция может быть указана несколько раз, и в этом случае манифесты объединяются.
Она служит для того же, что и одноименная опция в
guix package(see --manifest) и использует те же файлы манифеста. Она позволяет вам один раз определить набор пакетов и использовать его как для создания профилей, так и для создания архивов для использования на машинах, на которых не установлен Guix. Обратите внимание, что вы можете указать либо файл манифеста либо список пакетов, но не то и другое вместе.See Writing Manifests, for information on how to write a manifest. See
guix shell --export-manifest, for information on how to “convert” command-line options into a manifest.--system=system-s systemПредпринять попытку собрать систему system, т.е.
i686-linux, вместо типа системы хоста сборки.--target=triplet¶Cross-сборка для triplet, который должен быть допустимым GNU triplet, например
\ "aarch64-linux-gnu\"(see GNU configuration triplets in Autoconf).--compression=tool-C toolАрхивировать логи сборки методом type. Это один из:
gzip,bzip2илиnone.--symlink=spec-S specДобавить в пакет символические ссылки, указанные в spec. Эта опция может быть указана несколько раз.
spec имеет вид
source=target, где source - это символическая ссылка, которая будет создана, а target - это цель символьной ссылки.Например,
-S /opt/gnu/bin=binсоздает символическую ссылку /opt/gnu/bin, указывающую на подкаталог bin профиля.--save-provenanceСохранить информацию о происхождении пакетов, переданных в командной строке. Информация о происхождении включает в себя URL и фиксацию используемых каналов (see Каналы).
Информация о происхождении сохраняется в файле /gnu/store/…-profile/manifest в пакете вместе с обычными метаданными пакета - названием и версией каждого пакета, их propagated inputs и т.п. Это полезная информация для получателя pack, который исходя из нее знает, как (предположительно) был собран pack.
Этот параметр не включен по умолчанию, поскольку, как и временные метки, информация о происхождении не влияет на процесс сборки. Другими словами, существует бесконечное количество URL-адресов каналов и ID коммитов, которые могут привести к одному и тому же pack. Таким образом, запись таких “тихих” метаданных в output потенциально нарушает свойство побитовой воспроизводимости.
--root=file¶-r fileСоздать символическую ссылку file на профиль этого окружения и зарегистрировать её как корень сборщика мусора.
--localstatedir--profile-name=nameВключите в конечный пакет “локальный каталог состояния”, /var/guix и, в частности, профиль /var/guix/profiles/per-user/root/name — по умолчанию name - это
guix-profile, что соответствует ~root/.guix-profile./var/guix содержит базу данных store (see Хранилище), а также корни сборщика мусора (see Вызов
guix gc). Предоставление ее в pack означает, что store является “полным” и управляемым Guix; отсутствие в pack означает, что store “мертв”: пакеты нельзя добавить в него или удалить из него после извлечения pack.Одним из вариантов использования является включающий себя двоичный архив Guix (see Бинарная установка).
--derivation-dВыведите имя derivation, которая создает pack.
--bootstrapИспользовать bootstrap бинарники для сборки пакета. Эта опция полезна только разработчикам Guix.
Кроме того, guix pack поддерживает все стандартные параметры
сборки (see Стандартные параметры сборки) и все параметры преобразования пакетов
(see Параметры преобразования пакета).
Next: Вызов guix package, Previous: Вызов guix pack, Up: Разработка [Contents][Index]
8.4 Тулчейн GCC
Guix предлагает индивидуальные пакеты компиляторов, как например,
gcc. Но если вам необходим полный набор инструментов (тулчейн) для
компиляции и линковки исходного кода, тогда то, что вам действительно нужно,
— это пакет gcc-toolchain. Этот пакет предоставляет полный тулчейн
GCC для разработки C/C++, включая сам GCC, библиотеку GNU C (заголовки и
бинарники, а также отладочные символы в выходе debug), Binutils и
набор линковщика.
Цель оболочки — проверять опции -L и -l, направленные
линковщику, и соответствующие аргументы -rpath, и вызывать
соответствующий линковщик с этим новым набором аргументов. Вы можете указать
оболочке отклонять линковку с библиотеками, находящимися не на складе,
установив переменную окружения GUIX_LD_WRAPPER_ALLOW_IMPURITIES в
значение no.
Пакет gfortran-toolchain предоставляет полный набор инструментов GCC
для разработки Fortran. Для других языков используйте ‘guix search gcc
toolchain’ (see Invoking guix package).
Previous: Тулчейн GCC, Up: Разработка [Contents][Index]
8.5 Вызов guix package
Команда guix git Authenticate аутентифицирует проверку Git по тому
же правилу, что и для каналов (see channel
authentication). То есть, начиная с данного коммита, он гарантирует, что
все последующие коммиты подписаны ключом OpenPGP, отпечаток которого указан
в файле .guix-authorizations его родительского коммита(ов).
Вы найдете эту команду полезной, если будете поддерживать канал. Но на самом деле этот механизм аутентификации полезен в более широком контексте, поэтому вы можете использовать его для репозиториев Git, которые не имеют ничего общего с Guix.
Основной синтаксис:
guix environment options package…
По умолчанию эта команда аутентифицирует проверку Git в текущем каталоге; она ничего не выводит и завершает работу с нулевым кодом в случае успеха и ненулевым в случае неудачи. commit выше обозначает первый коммит, в котором происходит аутентификация, а signer - это отпечаток открытого ключа OpenPGP, используемый для подписи commit. Вместе они образуют “channel introduction” (see channel introduction). Указанные ниже параметры позволяют вам точно настроить процесс.
--extract=directory-x directoryОткрыть репозиторий Git в directory вместо текущего каталога.
--expression=expr-F freeЗагрузить связку ключей OpenPGP из reference, ссылки на branch, например
origin/keyringилиmy-keyring. branch должна содержать открытые ключи OpenPGP в файлах .key либо в двоичной форме, либо в “ASCII-armored” виде. По умолчанию связка ключей загружается из branch с именемkeyring.--statsОтобразить статистику подписания commit’ов по завершению.
--search=regexpРанее аутентифицированные коммиты кэшируются в файле под ~/.cache/guix/authentication. Эта опция заставляет хранить кеш в файле key в этом каталоге.
--install-from-file=fileПо умолчанию любой коммит, родительский коммит которого не содержит файла .guix-authorizations, считается недостоверным. Напротив, эта опция учитывает авторизацию в file для любого коммита, в котором отсутствует .guix-authorizations. Формат file такой же, как у .guix-authorizations (see .guix-authorizations format).
Next: Утилиты, Previous: Разработка, Up: GNU Guix [Contents][Index]
9 Программный интерфейс
GNU Guix предоставляет несколько Scheme программных интерфейсов (API) для определения, сборки и запроса пакетов. Первый интерфейс позволяет пользователям писать высокоуровневые определения пакетов. Эти определения относятся к знакомым концепциям упаковки, таким как имя и версия пакета, его система сборки и зависимости. Затем эти определения можно превратить в конкретные действия по сборке.
Действия по сборке выполняются демоном Guix от имени пользователей. В стандартной настройке демон имеет доступ на запись в хранилище—каталог /gnu/store—, в то время как пользователи не имеют. Рекомендуемая установка также предусматривает, что демон выполняет сборки в chroot, под определенными пользователями сборки, чтобы минимизировать влияние на остальную систему.
Доступны API нижнего уровня для взаимодействия с демоном и хранилищем. Чтобы дать демону команду выполнить действие сборки, пользователи фактически предоставляют ему derivation. Derivation - это низкоуровневое представление действий сборки, которые должны быть предприняты, и среды, в которой они должны происходить - derivation’ы относятся к определениям пакетов, как сборка для программ на C. Термин “derivation” происходит от того факта, что результаты сборки производные от них.
В этой главе описываются все эти API по очереди, начиная с определений пакетов высокого уровня.
- Пакетные модули
- Описание пакетов
- Defining Package Variants
- Writing Manifests
- Системы сборки
- Фазы сборки
- Build Utilities
- Search Paths
- Хранилище
- Деривации
- Устройство склада
- G-Expressions
- Вызов
guix repl - Using Guix Interactively
Next: Описание пакетов, Up: Программный интерфейс [Contents][Index]
9.1 Пакетные модули
С точки зрения программирования, определения пакетов дистрибутива GNU
предоставляются модулями Guile в пространстве имен (gnu packages
…) 19 (see Guile modules in GNU Guile
Reference Manual)). Например, модуль (gnu packages emacs)
экспортирует переменную с именем emacs, которая привязана к
<package> объекту (see Описание пакетов).
Пространство имен модуля (gnu packages …) автоматически
сканируется на наличие пакетов с помощью инструментов командной строки.
Например, при запуске guix install emacs все модули (gnu
packages …) сканируются до тех пор, пока не будет найден тот, который
экспортирует объект пакета с именем emacs. Это средство поиска
пакетов реализовано в модуле (gnu packages).
Пользователи могут хранить определения пакетов в модулях с разными именами -
например, (my-packages emacs) 20. Есть два способа сделать эти
определения пакетов видимыми для пользовательских интерфейсов:
- Добавить каталог, содержащий модули вашего пакета, в пути поиска с помощью
флага
-Lкомандыguix packageи другие команды (see Стандартные параметры сборки) или указать переменную окруженияGUIX_PACKAGE_PATH, описанную ниже. - Определить канал и настроить
guix pullтак, чтобы он учитывал его. Канал - это, по сути, репозиторий Git, содержащий модули пакетов. See Каналы, чтобы узнать больше о том, как определять и использовать каналы.
GUIX_PACKAGE_PATH работает аналогично другим переменным пути поиска:
- Environment Variable: GUIX_PACKAGE_PATH
Это список каталогов, разделенных двоеточиями, для поиска дополнительных модулей пакета. Каталоги, перечисленные в этой переменной, имеют приоритет над собственными модулями дистрибутива.
Дистрибутив полностью bootstrapped и самодостаточный: каждый
пакет построен исключительно на основе других пакетов в дистрибутиве.
Корнем этого графа зависимостей является небольшой набор bootstrap
бинарный файлы, предоставляемых модулем (gnu packages bootstrap).
Для получения дополнительной информации о начальной загрузке
see Начальная загрузка.
Next: Defining Package Variants, Previous: Пакетные модули, Up: Программный интерфейс [Contents][Index]
9.2 Описание пакетов
Интерфейс высокого уровня к определениям пакетов реализован в модулях
(guix packages) и (guix build-system). Например, определение
пакета или рецепта для пакета GNU Hello выглядит так:
(define-module (gnu packages hello) #:use-module (guix packages) #:use-module (guix download) #:use-module (guix build-system gnu) #:use-module (guix licenses) #:use-module (gnu packages gawk)) (define-public hello (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (arguments '(#:configure-flags '("--enable-silent-rules"))) (inputs (list gawk)) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "https://www.gnu.org/software/hello/") (license gpl3+)))
Не будучи Scheme экспертом, вы можете догадаться о значении различных
полей. Это выражение связывает переменную hello с объектом
<package>, который по сути является record (see Scheme
records in GNU Guile Reference Manual). Этот объект пакета можно
проверить с помощью процедур из модуля (guix packages); например,
(package-name hello) возвращает—сюрприз!—"hello".
Если повезет, вы сможете импортировать часть или все определение
интересующего вас пакета из другого репозитория с помощью команды guix
import (see Вызов guix import).
В приведенном выше примере hello определен в собственном модуле
(gnu packages hello). Технически в этом нет строгой необходимости,
но это удобно: все пакеты, определенные в модулях под (gnu packages
…), автоматически становятся известны инструментам командной строки
(see Пакетные модули).
В приведенном выше определении пакета стоит отметить несколько моментов:
- Поле
sourceпакета представляет собой объект<origin>(seeoriginСправка, for the complete reference). Здесь используется методurl-fetchиз(guix download), что означает, что источником является файл, который нужно загрузить через FTP или HTTP.Префикс
mirror://gnuуказываетurl-fetchиспользовать одно из зеркал GNU, определенных в(guix download).Поле
sha256указывает ожидаемый хэш SHA256 загружаемого файла. Это обязательно и позволяет Guix проверять целостность файла. Форма(base32 …)указывает представление хеша в формате base32. Вы можете получить эту информацию с помощьюguix download(see Вызовguix download)guix hash(see Вызовguix hash).При необходимости форма
originможет также иметь полеpatchesсо списком исправлений, которые необходимо применить, и полеsnippet, содержащее Scheme выражение для изменения исходного кода. -
Поле
build-systemуказывает процедуру сборки пакета (see Системы сборки). Здесьgnu-build-systemпредставляет знакомую систему сборки GNU, в которой пакеты могут быть настроены, собраны и установлены с помощью обычной последовательности команд./configure && make && make check && make install.Когда вы начинаете упаковывать нетривиальное программное обеспечение, вам могут потребоваться инструменты для управления этими этапами сборки, управления файлами и т.д. See Build Utilities, чтобы узнать об этом подробнее.
- Поле
argumentsопределяет параметры для системы сборки (see Системы сборки). В примере это интерпретируетсяgnu-build-systemкак запуск запроса configure с флагом --enable-silent-rules.What about these quote (
') characters? They are Scheme syntax to introduce a literal list;'is synonymous withquote. Sometimes you’ll also see`(a backquote, synonymous withquasiquote) and,(a comma, synonymous withunquote). See quoting in GNU Guile Reference Manual, for details. Here the value of theargumentsfield is a list of arguments passed to the build system down the road, as withapply(seeapplyin GNU Guile Reference Manual).Последовательность хэш-двоеточие (
#:) определяет Scheme ключевое слово (see Keywords in GNU Guile Reference Manual), а#:configure-flags- это ключевое слово, используемое для передачи аргумента ключевого слова системе сборки (see Coding With Keywords in GNU Guile Reference Manual). - The
inputsfield specifies inputs to the build process—i.e., build-time or run-time dependencies of the package. Here, we add an input, a reference to thegawkvariable;gawkis itself bound to a<package>object.Обратите внимание, что GCC, Coreutils, Bash и другие важные инструменты не нужно указывать здесь в качестве inputs. Вместо этого
gnu-build-systemпозаботится об их наличии (see Системы сборки).Однако любые другие зависимости необходимо указать в поле
inputs. Любая не указанная здесь зависимость будет просто недоступна для процесса сборки, что может привести к сбою сборки.
See package Ссылка, для полного описания возможных полей.
Больше информации: Intimidated by the Scheme language or curious about it? The Cookbook has a short section to get started that recaps some of the things shown above and explains the fundamentals. See A Scheme Crash Course in GNU Guix Cookbook, for more information.
После того, как определение пакета введено, пакет может быть фактически
собран с помощью инструмента командной строки guix build
(see Запуск guix build), устраняя любые возникающие ошибки сборки
(see Отладка ошибок сборки). Вы можете легко вернуться к определению
пакета с помощью команды guix edit (see Вызов guix edit).
See Принципы опакечивания для получения дополнительной информации о том,
как тестировать определения пакетов, и Вызов guix lint для
получения информации о том, как проверить определение на соответствие стилю.
Наконец, see Каналы, чтобы узнать, как расширить дистрибутив, добавив
собственные определения пакетов в “канал”.
Наконец, обновление определения пакета до новой исходной версии можно
частично автоматизировать с помощью команды guix refresh
(see Вызов guix refresh).
За кулисами derivation, соответствующая объекту <package>, сначала
вычисляется с помощью процедуры package-diveration. Этот вывод
хранится в файле .drv в каталоге /gnu/store. Действия сборки,
которые он предписывает, затем могут быть реализованы с помощью процедуры
build-derivations (see Хранилище).
- Процедура Scheme: package-derivation store package [system]
Возвращает the
<derivation>объект package для system (see Деривации).package должен быть допустимым объектом
<package>, а system должен быть строкой, обозначающей тип системы—например,"x86_64-linux"для системы GNU на базе x86_64 Linux. store должен быть подключен к демону, который работает с хранилищем (see Хранилище).
Точно так же можно вычислить derivation, которая cross собирает пакет для некоторой другой системы:
- Процедура Scheme: package-cross-derivation store package target [system] Возвращает
<derivation> объект package cross-собранный из system в target.
target должен быть допустимым GNU triplet’ом, обозначающим желамое оборудование и операционную систему, например
"aarch64-linux-gnu"(see Specifying Target Triplets in Autoconf).
Когда у вас есть определения пакетов, вы можете легко определить варианты этих пакетов. См. See Defining Package Variants, чтобы узнать об этом подробнее.
Next: origin Справка, Up: Описание пакетов [Contents][Index]
9.2.1 package Ссылка
В этом разделе перечислены все параметры, доступные в объявлениях
package (see Описание пакетов).
- Тип данных: package
Это тип данных, представляющий рецепт пакета.
nameНазвание пакета в виде строки.
версияThe version of the package, as a string. See Номера версий, for guidelines.
источникОбъект, указывающий, как должен быть получен исходный код пакета. В большинстве случаев это объект
origin, который обозначает файл, полученный из Интернета (seeoriginСправка). Это также может быть любой другой объект, подобный файлу, напримерlocal-file, который представляет собой файл из локальной файловой системы (seelocal-file).система сборкиСистема сборки, которую следует использовать для сборки пакета (see Системы сборки).
arguments(default:'())The arguments that should be passed to the build system (see Системы сборки). This is a list, typically containing sequential keyword-value pairs, as in this example:
(package (name "example") ;; several fields omitted (arguments (list #:tests? #f ;skip tests #:make-flags #~'("VERBOSE=1") ;pass flags to 'make' #:configure-flags #~'("--enable-frobbing"))))The exact set of supported keywords depends on the build system (see Системы сборки), but you will find that almost all of them honor
#:configure-flags,#:make-flags,#:tests?, and#:phases. The#:phaseskeyword in particular lets you modify the set of build phases for your package (see Фазы сборки).inputs(default:'()) ¶native-inputs(default:'())propagated-inputs(default:'())These fields list dependencies of the package. Each element of these lists is either a package, origin, or other “file-like object” (see G-Expressions); to specify the output of that file-like object that should be used, pass a two-element list where the second element is the output (see Пакеты со множественным выходом, for more on package outputs). For example, the list below specifies three inputs:
(list libffi libunistring `(,glib "bin")) ;the "bin" output of GLib
In the example above, the
"out"output oflibffiandlibunistringis used.Compatibility Note: Until version 1.3.0, input lists were a list of tuples, where each tuple has a label for the input (a string) as its first element, a package, origin, or derivation as its second element, and optionally the name of the output thereof that should be used, which defaults to
"out". For example, the list below is equivalent to the one above, but using the old input style:;; Old input style (deprecated). `(("libffi" ,libffi) ("libunistring" ,libunistring) ("glib:bin" ,glib "bin")) ;the "bin" output of GLib
This style is now deprecated; it is still supported but support will be removed in a future version. It should not be used for new package definitions. See Invoking
guix style, on how to migrate to the new style.Различие между
native-inputsиinputsнеобходимо при рассмотрении кросс-компиляции. При кросс-компиляции зависимости, перечисленные вinput, создаются для архитектуры target; и наоборот, зависимости, перечисленные вnative-inputs, созданы для архитектуры машины, выполняющей сборку.native-inputsобычно используется для перечисления инструментов, необходимых во время сборки, но не во время выполнения, таких как Autoconf, Automake, pkg-config, Gettext или Bison.guix lintможет сообщить о вероятных ошибках в этой области (see Вызовguix lint).Наконец,
propagated-inputsпохоже наinputs, но указанные пакеты будут автоматически установлены в профили (see the role of profiles in Guix) вместе с пакетом, которому они принадлежат (seeguix package, for information on howguix packagedeals with propagated inputs).Например, это необходимо при упаковке библиотеки C/C++, которой для компиляции требуются заголовки другой библиотеки, или когда файл pkg-config ссылается на другое поле через его
Requires.Другой пример использования
propagated-inputs- это языки, в которых отсутствует возможность записывать путь поиска во время выполнения, аналогичныйRUNPATHфайлов ELF; сюда входят Guile, Python, Perl и другие. При упаковке библиотек, написанных на этих языках, убедитесь, что они могут найти код библиотеки, от которого они зависят, во время выполнения, указав зависимости времени выполнения вpropagated-inputs, а не вinputs.outputs(default:'("out"))Список выходных имен пакета. See Пакеты со множественным выходом, для типичного использования дополнительных выходов.
native-search-paths(default:'())search-paths(по умолчанию:'())A list of
search-path-specificationobjects describing search-path environment variables honored by the package. See Search Paths, for more on search path specifications.As for inputs, the distinction between
native-search-pathsandsearch-pathsonly matters when cross-compiling. In a cross-compilation context,native-search-pathsapplies exclusively to native inputs whereassearch-pathsapplies only to host inputs.Packages such as cross-compilers care about target inputs—for instance, our (modified) GCC cross-compiler has
CROSS_C_INCLUDE_PATHinsearch-paths, which allows it to pick .h files for the target system and not those of native inputs. For the majority of packages though, onlynative-search-pathsmakes sense.replacement(по умолчанию:#f)Это должен быть либо
#f, либо объект пакета, который будет использоваться как замена для этого пакета. See grafts, чтобы узнать подробности.синопсисОписание пакета в одну строку.
описаниеA more elaborate description of the package, as a string in Texinfo syntax.
лицензия¶Лицензия пакета; значение из
(guix licenses)или список таких значений.главная страницаURL-адрес домашней страницы пакета в виде строки.
port(default:22)Список систем, поддерживаемых пакетом, в виде строк вида
architecture-kernel, например"x86_64-linux".location(по умолчанию: исходное местоположение формыpackage)Исходное расположение пакета. Это полезно переопределить при наследовании от другого пакета, и в этом случае это поле не корректируется автоматически.
- Scheme Syntax: this-package
При использовании в lexical scope определения поля пакета этот идентификатор преобразуется в определяемый пакет.
В приведенном ниже примере показано, как добавить пакет в качестве собственного ввода при кросс-компиляции:
(package (name "guile") ;; ... ;; When cross-compiled, Guile, for example, depends on ;; a native version of itself. Add it here. (native-inputs (if (%current-target-system) (list this-package) '())))Ссылка на
this-packageвне определения пакета является ошибкой.
The following helper procedures are provided to help deal with package inputs.
- Scheme Procedure: lookup-package-input package name
- Scheme Procedure: lookup-package-native-input package name
- Scheme Procedure: lookup-package-propagated-input package name
- Scheme Procedure: lookup-package-direct-input package name
Look up name among package’s inputs (or native, propagated, or direct inputs). Return it if found,
#fotherwise.name is the name of a package depended on. Here’s how you might use it:
(use-modules (guix packages) (gnu packages base)) (lookup-package-direct-input coreutils "gmp") ⇒ #<package gmp@6.2.1 …>
In this example we obtain the
gmppackage that is among the direct inputs ofcoreutils.
Sometimes you will want to obtain the list of inputs needed to
develop a package—all the inputs that are visible when the package
is compiled. This is what the package-development-inputs procedure
returns.
- Scheme Procedure: package-development-inputs package [system] [#:target #f] Return the list of inputs required by
package for development purposes on system. When target is true, return the inputs needed to cross-compile package from system to target, where target is a triplet such as
"aarch64-linux-gnu".Note that the result includes both explicit inputs and implicit inputs—inputs automatically added by the build system (see Системы сборки). Let us take the
hellopackage to illustrate that:(use-modules (gnu packages base) (guix packages)) hello ⇒ #<package hello@2.10 gnu/packages/base.scm:79 7f585d4f6790> (package-direct-inputs hello) ⇒ () (package-development-inputs hello) ⇒ (("source" …) ("tar" #<package tar@1.32 …>) …)
In this example,
package-direct-inputsreturns the empty list, becausehellohas zero explicit dependencies. Conversely,package-development-inputsincludes inputs implicitly added bygnu-build-systemthat are required to buildhello: tar, gzip, GCC, libc, Bash, and more. To visualize it,guix graph hellowould show you explicit inputs, whereasguix graph -t bag hellowould include implicit inputs (see Вызовguix graph).
Поскольку пакеты являются обычными Scheme объектами, которые захватывают полный граф зависимостей и связанные процедуры сборки, часто бывает полезно написать процедуры, которые принимают пакет и возвращают его измененную версию в соответствии с некоторыми параметрами. Ниже приведены несколько примеров.
- Процедура Scheme: inferior-package-location package
Вернуть вариант package, в котором используется toolchain вместо стандартного набора инструментов GNU C/C++. toolchain должен быть списком входов (кортежи меток/пакетов), обеспечивающих эквивалентную функциональность, например, пакет
gcc-toolchain.Пример ниже возвращает вариант пакета
hello, созданный с помощью GCC 10.x и остальной части GNU утилит (Binutils и библиотеки GNU C) вместо цепочки инструментов по умолчанию:(let ((toolchain (specification->package "gcc-toolchain@10"))) (package-with-c-toolchain hello `(("toolchain" ,toolchain))))Инструменты сборки являются частью неявных входных данных пакетов - обычно они не указываются как часть различных полей “входных данных”, а вместо этого извлекается системой сборки. Следовательно, эта процедура работает путем изменения системы сборки package, так что она использует toolchain вместо значений по умолчанию. Системы сборки, чтобы узнать больше о системах сборки.
Previous: package Ссылка, Up: Описание пакетов [Contents][Index]
9.2.2 origin Справка
Этот раздел документирует origins. Объявление origin
определяет данные, которые должны быть “произведены”—обычно
загружены—и чей хэш содержимого известен заранее. Origins в основном
используются для представления исходного кода пакетов (see Описание пакетов). По этой причине форма origin позволяет вам объявлять
исправления для применения к исходному коду, а также фрагменты кода для его
изменения.
- Тип данных: origin
Это тип данных, представляющий источник исходного кода.
uriОбъект, содержащий URI источника. Тип объекта зависит от
method(см. ниже). Например, при использовании метода url-fetch для(guix download)допустимые значенияuri: URL, представленный в виде строки, или их список.методМонадическая процедура, обрабатывающая данный URI. Процедура должна принимать по крайней мере три аргумента: значение поля
uri, а также алгоритм хеширования и значение хеш-функции, указанные в полеhash. Она должна возвращать элемент store или derivation в store монаде (see Устройство склада); большинство методов возвращают derivation с фиксированным выводом (see Деривации).Обычно используемые методы включают
url-fetch, который извлекает данные из URL-адреса, иgit-fetch, который извлекает данные из репозитория Git (см. ниже).sha256Байт-вектор, содержащий хэш SHA-256 источника. Это эквивалент предоставлению объекта SHA256
content-hashв полеhash, описанном ниже.hashОбъект
content-hashисточника—см. ниже, как использоватьcontent-hash.Вы можете получить эту информацию, используя
guix download(see Вызовguix download) илиguix hash(see Вызовguix hash).file-name(по умолчанию:#f)Имя файла, под которым должен быть сохранен исходный код. Когда это
#f, в большинстве случаев будет использоваться разумное значение по умолчанию. В случае, если источник извлекается из URL-адреса, будет использоваться имя файла из URL-адреса. Для проверок контроля версий рекомендуется явно указывать имя файла, поскольку значение по умолчанию не очень информативно.patches(по умолчанию:'())Список имен файлов, источников или объектов подобных файлами (see file-like objects), указывающих на исправления, которые будут применены к источнику.
Данный список исправлений должен быть безвариативным. В частности, он не может зависеть от значения
%current-systemили%current-target-system.snippet(по умолчанию:#f)G-выражение (see G-Expressions) или S-выражение, которое будет выполнено в исходном каталоге. Это удобный способ изменить исходный код, иногда более удобный, чем патч.
patch-flags(по умолчанию:'("-p1"))Список флагов командной строки, которые следует передать команде
patch.patch-inputs(по умолчанию:#f)"Входные пакеты или derivation’ы для процесса исправления. Когда это
#f, предоставляется обычный набор входных данных, необходимых для исправления, например GNU Patch.modules(по умолчанию:'())Список модулей Guile, которые должны быть загружены в процессе установки исправлений и при выполнении кода, в поле
snippet.patch-guile(по умолчанию:#f)Пакет Guile, который следует использовать в процессе установки исправлений. Когда это
#f, используется разумное значение по умолчанию.
- Тип данных: content-hash value [algorithm]
Создать объект хэша содержимого для заданного algorithm и с value в качестве его хеш-значения. Если algorithm опущен, предполагается, что это
sha256.value может быть буквальной строкой, и в этом случае она декодируется с помощью base32, или может быть байтовым вектором.
Следующие зависимости необязательны:
(content-hash "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj") (content-hash "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj" sha256) (content-hash (base32 "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj")) (content-hash (base64 "kkb+RPaP7uyMZmu4eXPVkM4BN8yhRd8BTHLslb6f/Rc=") sha256)
Технически
content-hashв настоящее время реализован как макрос. Он выполняет проверки работоспособности во время раскрытия макроса, когда это возможно, например, гарантирует, что value имеет правильный размер для algorithm.
Как мы видели выше, то, как именно извлекаются данные, на которые ссылается
источник, определяется его полем method. Модуль (guix
download) предоставляет наиболее распространенный метод url-fetch,
описанный ниже.
- Scheme Procedure: lookup-inferior-packages inferior name [name] [#:executable? #f] Возвращает derivation с фиксированным выводом,
которая извлекает данные из url (строка или список строк, обозначающих альтернативные URL-адреса), который, как ожидается, будет иметь хэш hash типа hash-algo (символ). По умолчанию имя файла - это базовое имя URL-адреса; при желании name может указывать другое имя файла. Если executable? истинно, загруженный файл будет исполняемым.
Когда один из URL-адресов начинается с
mirror://, тогда его хост-часть интерпретируется как имя схемы зеркала, взятой из %mirror-file.В качестве альтернативного варианта, если URL-адрес начинается с
file://, вернуть соответствующее имя файла в store.
Аналогичным образом, модуль (guix git-download) определяет метод
источника git-download, который извлекает данные из репозитория
управления версиями Git, и тип данных git-reference для описания
репозиторий и ревизия для загрузки.
- Scheme Procedure: mixed-text-file name text …
Вернуть derivation с фиксированным выводом, которая выбирает объект ref,
<git-reference>. Ожидается, что на выходе будет рекурсивный хеш hash типа hash-algo (символ). Использовать name в качестве имени файла или общее имя, если#f.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
urlURL-адрес репозитория Git для клонирования.
commitThis string denotes either the commit to fetch (a hexadecimal string), or the tag to fetch. You can also use a “short” commit ID or a
git describestyle identifier such asv1.0.1-10-g58d7909c97.features(default:'())Это логическое значение (boolean) указывает, нужно ли рекурсивно получать подмодули Git.
Пример ниже обозначает тег
v2.10репозитория GNU Hello:(git-reference (url "https://git.savannah.gnu.org/git/hello.git") (commit "v2.10"))Это эквивалентно приведенной ниже ссылке, которая явно называет коммит:
(git-reference (url "https://git.savannah.gnu.org/git/hello.git") (commit "dc7dc56a00e48fe6f231a58f6537139fe2908fb9"))
Для репозиториев Mercurial, модуль (guix hg-download) определяет
метод hg-fetch и тип данных hg-reference для поддержки системы
контроля версий Mercurial.
- Scheme Procedure: mixed-text-file name text …
Вернуть derivation с фиксированным выводом, которая выбирает объект ref,
<git-reference>. Ожидается, что на выходе будет рекурсивный хеш hash типа hash-algo (символ). Использовать name в качестве имени файла или общее имя, если#f.
Next: Writing Manifests, Previous: Описание пакетов, Up: Программный интерфейс [Contents][Index]
9.3 Defining Package Variants
One of the nice things with Guix is that, given a package definition, you can easily derive variants of that package—for a different upstream version, with different dependencies, different compilation options, and so on. Some of these custom packages can be defined straight from the command line (see Параметры преобразования пакета). This section describes how to define package variants in code. This can be useful in “manifests” (see Writing Manifests) and in your own package collection (see Создание канала), among others!
Как обсуждалось ранее, пакеты—это объекты первого класса на языке Scheme.
Модуль (guix packages) предоставляет конструкцию package для
определения новых объектов пакета (see package Ссылка). Самый
простой способ определить вариант пакета—использовать ключевое слово
inherit вместе с package. Это позволяет вам наследовать от
определения пакета, переопределяя нужные поля.
Например, учитывая переменную hello, которая содержит определение для
текущей версии GNU Hello, вот как вы могли бы определить вариант для
версии 2.2 (выпущенной в 2006 году, это винтаж!):
(use-modules (gnu packages guile)) ;for 'guile-json' (define hello-2.2 (package (inherit hello) (version "2.2") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0lappv4slgb5spyqbh6yl5r013zv72yqg2pcl30mginf3wdqd8k9"))))))
Приведенный выше пример соответствует тому, что делает опция преобразования
пакета --with-source. По сути, hello-2.2 сохраняет все поля
hello, кроме version и source, которые
переопределяется. Обратите внимание, что исходная переменная hello
все еще присутствует в модуле (gnu packages base) без изменений.
Когда вы определяете собственный пакет таким образом, вы на самом деле
добавляете новое определение пакета; оригинал остается доступным.
Вы также можете определить варианты с другим набором зависимостей, чем
исходный пакет. Например, пакет gdb по умолчанию зависит от
guile, но поскольку это необязательная зависимость, вы можете
определить вариант, который удаляет эту зависимость следующим образом:
(use-modules (gnu packages gdb)) ;for 'gdb' (define gdb-sans-guile (package (inherit gdb) (inputs (modify-inputs (package-inputs gdb) (delete "guile")))))
The modify-inputs form above removes the "guile" package from
the inputs field of gdb. The modify-inputs macro is a
helper that can prove useful anytime you want to remove, add, or replace
package inputs.
- Scheme Syntax: modify-inputs inputs clauses
Modify the given package inputs, as returned by
package-inputs& co., according to the given clauses. Each clause must have one of the following forms:(delete name…)Delete from the inputs packages with the given names (strings).
(prepend package…)Add packages to the front of the input list.
(append package…)Add packages to the end of the input list.
The example below removes the GMP and ACL inputs of Coreutils and adds libcap to the front of the input list:
(modify-inputs (package-inputs coreutils) (delete "gmp" "acl") (prepend libcap))The example below replaces the
guilepackage from the inputs ofguile-rediswithguile-2.2:(modify-inputs (package-inputs guile-redis) (replace "guile" guile-2.2))The last type of clause is
append, to add inputs at the back of the list.
В некоторых случаях вам может быть полезно написать функции (“процедуры”
Scheme), которые возвращают пакет на основе некоторых параметров. Например,
рассмотрим библиотеку luasocket для языка программирования Lua. Мы
хотим создать пакеты luasocket для основных версий Lua. Один из
способов сделать это—определить процедуру, которая принимает пакет Lua и
возвращает зависящий от него пакет luasocket:
(define (make-lua-socket name lua) ;; Return a luasocket package built with LUA. (package (name name) (version "3.0") ;; several fields omitted (inputs (list lua)) (synopsis "Socket library for Lua"))) (define-public lua5.1-socket (make-lua-socket "lua5.1-socket" lua-5.1)) (define-public lua5.2-socket (make-lua-socket "lua5.2-socket" lua-5.2))
Здесь мы определили пакеты lua5.1-socket и lua5.2-socket,
вызвав make-lua-socket с разными аргументами.
См. See Procedures in GNU Guile Reference Manual, для получения
дополнительной информации о процедурах. Наличие общедоступных определений
верхнего уровня для этих двух пакетов означает, что на них можно ссылаться
из командной строки (see Пакетные модули).
Это довольно простые варианты пакета. Для удобства модуль (guix
transformations) предоставляет высокоуровневый интерфейс, который напрямую
сопоставляется с более сложными параметрами преобразования пакетов
(see Параметры преобразования пакета):
- Процедура Scheme: open-inferior directory Возвращает процедуру, которая при передаче объекта для сборки (пакета,
производной и т. д.), применяет преобразования, указанные в opts, и возвращает результирующие объекты. opts должен быть списком пар символ/строка, например:
((with-branch . "guile-gcrypt=master") (without-tests . "libgcrypt"))Каждый символ именует преобразование, а соответствующая строка (string) является аргументом этого преобразования.
Например, команда:
guix build guix \ --with-branch=guile-gcrypt=master \ --with-debug-info=zlib
Вывод должен быть таким:
(use-package-modules guile emacs) (define transform ;; The package transformation procedure. (options->transformation '((with-branch . "guile-gcrypt=master") (with-debug-info . "zlib")))) (packages->manifest (list (transform (specification->package "guix"))))
Процедура options-> transformation удобна, но, возможно, не так
гибка, как вам хотелось бы. Как это реализовано? Проницательный читатель,
вероятно, заметил, что большинство вариантов преобразования пакетов выходят
за рамки поверхностных изменений, показанных в первых примерах этого
раздела: они включают перезапись входных данных, в результате чего
граф зависимостей пакета переписывается путем замены определенных входных
данных другими.
Перезапись графа зависимостей для замены пакетов в графе реализуется
процедурой package-input-rewriting в (guix packages).
- Процедура Scheme: package-input-rewriting replacements [rewrite-name] [#:deep? #t] Возвращает процедуру, которая при передаче
пакета заменяет его прямые и косвенные зависимости, включая неявные входы, когда deep? истинна, согласно replacements. replacements - это список пар пакетов; первый элемент каждой пары - это заменяемый пакет, а второй - заменяющий.
При необходимости, rewrite-name - это процедура с одним аргументом, которая принимает имя пакета и возвращает его новое имя после перезаписи.
Рассмотрим пример:
(define libressl-instead-of-openssl ;; This is a procedure to replace OPENSSL by LIBRESSL, ;; recursively. (package-input-rewriting `((,openssl . ,libressl)))) (define git-with-libressl (libressl-instead-of-openssl git))
Здесь мы сначала определяем процедуру перезаписи, которая заменяет openssl на libressl. Затем мы используем это, чтобы определить вариант пакета git, который использует libressl вместо openssl. Это именно то, что делает параметр командной строки --with-input (see --with-input).
Следующий вариант package-input-rewriting может сопоставлять пакеты,
подлежащие замене, по имени, а не по идентификатору.
- Процедура Scheme: inferior-package-inputs package
Возвращает процедуру, которая для данного пакета применяет заданные replacements ко всему графу пакета, включая неявные входные данные, если deep? не ложно. replacements - это список пары спецификация/процедуры; каждая спецификация - это спецификация пакета, такая как
"gcc"или"guile@2", и каждая процедура берет соответствующий пакет и возвращает замену для этого пакета.
Приведенный выше пример можно переписать так:
(define libressl-instead-of-openssl
;; Replace all the packages called "openssl" with LibreSSL.
(package-input-rewriting/spec `(("openssl" . ,(const libressl)))))
Ключевое отличие здесь в том, что на этот раз пакеты сопоставляются по
спецификации, а не по идентичности. Другими словами, любой пакет в графе,
который называется openssl, будет заменен.
Более общая процедура для перезаписи графа зависимостей пакетов - это
package-mapping: она поддерживает произвольные изменения узлов в
графе.
- Процедура Scheme: inferior-package-location package
Вернуть процедуру, которая для данного пакета применяет proc ко всем зависимым пакетам и возвращает полученный пакет. Процедура останавливает рекурсию, когда cut? возвращает истину для данного пакета. Когда deep? истинно, proc также применяется к неявным входным данным.
Next: Системы сборки, Previous: Defining Package Variants, Up: Программный интерфейс [Contents][Index]
9.4 Writing Manifests
guix commands let you specify package lists on the command line.
This is convenient, but as the command line becomes longer and less trivial,
it quickly becomes more convenient to have that package list in what we call
a manifest. A manifest is some sort of a “bill of materials” that
defines a package set. You would typically come up with a code snippet that
builds the manifest, store it in a file, say manifest.scm, and then
pass that file to the -m (or --manifest) option that many
guix commands support. For example, here’s what a manifest for a
simple package set might look like:
;; Manifest for three packages. (specifications->manifest '("gcc-toolchain" "make" "git"))
Once you have that manifest, you can pass it, for example, to guix
package to install just those three packages to your profile
(see -m option of guix package):
guix package -m manifest.scm
... or you can pass it to guix shell (see -m option of guix shell) to spawn an ephemeral
environment:
guix shell -m manifest.scm
... or you can pass it to guix pack in pretty much the same way
(see -m option of guix pack). You can
store the manifest under version control, share it with others so they can
easily get set up, etc.
But how do you write your first manifest? To get started, maybe you’ll want
to write a manifest that mirrors what you already have in a profile. Rather
than start from a blank page, guix package can generate a manifest
for you (see guix package --export-manifest):
# Write to 'manifest.scm' a manifest corresponding to the # default profile, ~/.guix-profile. guix package --export-manifest > manifest.scm
Or maybe you’ll want to “translate” command-line arguments into a
manifest. In that case, guix shell can help
(see guix shell --export-manifest):
# Write a manifest for the packages specified on the command line. guix shell --export-manifest gcc-toolchain make git > manifest.scm
In both cases, the --export-manifest option tries hard to generate a faithful manifest; in particular, it takes package transformation options into account (see Параметры преобразования пакета).
Примечание: Manifests are symbolic: they refer to packages of the channels currently in use (see Каналы). In the example above,
gcc-toolchainmight refer to version 11 today, but it might refer to version 13 two years from now.If you want to “pin” your software environment to specific package versions and variants, you need an additional piece of information: the list of channel revisions in use, as returned by
guix describe. See Копирование Guix, for more information.
Once you’ve obtained your first manifest, perhaps you’ll want to customize it. Since your manifest is code, you now have access to all the Guix programming interfaces!
Let’s assume you want a manifest to deploy a custom variant of GDB, the GNU Debugger, that does not depend on Guile, together with another package. Building on the example seen in the previous section (see Defining Package Variants), you can write a manifest along these lines:
(use-modules (guix packages) (gnu packages gdb) ;for 'gdb' (gnu packages version-control)) ;for 'git' ;; Define a variant of GDB without a dependency on Guile. (define gdb-sans-guile (package (inherit gdb) (inputs (modify-inputs (package-inputs gdb) (delete "guile"))))) ;; Return a manifest containing that one package plus Git. (packages->manifest (list gdb-sans-guile git))
Note that in this example, the manifest directly refers to the gdb
and git variables, which are bound to a package object
(see package Ссылка), instead of calling
specifications->manifest to look up packages by name as we did
before. The use-modules form at the top lets us access the core
package interface (see Описание пакетов) and the modules that define
gdb and git (see Пакетные модули). Seamlessly, we’re
weaving all this together—the possibilities are endless, unleash your
creativity!
The data type for manifests as well as supporting procedures are defined in
the (guix profiles) module, which is automatically available to code
passed to -m. The reference follows.
- Data Type: manifest
Data type representing a manifest.
It currently has one field:
entriesThis must be a list of
manifest-entryrecords—see below.
- Data Type: manifest-entry
Data type representing a manifest entry. A manifest entry contains essential metadata: a name and version string, the object (usually a package) for that entry, the desired output (see Пакеты со множественным выходом), and a number of optional pieces of information detailed below.
Most of the time, you won’t build a manifest entry directly; instead, you will pass a package to
package->manifest-entry, described below. In some unusual cases though, you might want to create manifest entries for things that are not packages, as in this example:;; Manually build a single manifest entry for a non-package object. (let ((hello (program-file "hello" #~(display "Hi!")))) (manifest-entry (name "foo") (version "42") (item (computed-file "hello-directory" #~(let ((bin (string-append #$output "/bin"))) (mkdir #$output) (mkdir bin) (symlink #$hello (string-append bin "/hello")))))))
The available fields are the following:
nameверсияName and version string for this entry.
itemA package or other file-like object (see file-like objects).
output(default:"out")Output of
itemto use, in caseitemhas multiple outputs (see Пакеты со множественным выходом).dependencies(default:'())List of manifest entries this entry depends on. When building a profile, dependencies are added to the profile.
Typically, the propagated inputs of a package (see
propagated-inputs) end up having a corresponding manifest entry in among the dependencies of the package’s own manifest entry.search-paths(по умолчанию:'())The list of search path specifications honored by this entry (see Search Paths).
properties(default:'())List of symbol/value pairs. When building a profile, those properties get serialized.
This can be used to piggyback additional metadata—e.g., the transformations applied to a package (see Параметры преобразования пакета).
parent(default:(delay #f))A promise pointing to the “parent” manifest entry.
This is used as a hint to provide context when reporting an error related to a manifest entry coming from a
dependenciesfield.
- Scheme Procedure: concatenate-manifests lst
Concatenate the manifests listed in lst and return the resulting manifest.
- Scheme Procedure: package->manifest-entry package [output] [#:properties] Return a manifest entry for the output
of package package, where output defaults to
"out", and with the given properties. By default properties is the empty list or, if one or more package transformations were applied to package, it is an association list representing those transformations, suitable as an argument tooptions->transformation(seeoptions->transformation).The code snippet below builds a manifest with an entry for the default output and the
send-emailoutput of thegitpackage:(use-modules (gnu packages version-control)) (manifest (list (package->manifest-entry git) (package->manifest-entry git "send-email")))
- Scheme Procedure: packages->manifest packages
Return a list of manifest entries, one for each item listed in packages. Elements of packages can be either package objects or package/string tuples denoting a specific output of a package.
Using this procedure, the manifest above may be rewritten more concisely:
(use-modules (gnu packages version-control)) (packages->manifest (list git `(,git "send-email")))
- Scheme Procedure: package->development-manifest package [system] [#:target] Return a manifest for the development inputs
of package for system, optionally when cross-compiling to target. Development inputs include both explicit and implicit inputs of package.
Like the -D option of
guix shell(seeguix shell -D), the resulting manifest describes the environment in which one can develop package. For example, suppose you’re willing to set up a development environment for Inkscape, with the addition of Git for version control; you can describe that “bill of materials” with the following manifest:(use-modules (gnu packages inkscape) ;for 'inkscape' (gnu packages version-control)) ;for 'git' (concatenate-manifests (list (package->development-manifest inkscape) (packages->manifest (list git))))
In this example, the development manifest that
package->development-manifestreturns includes the compiler (GCC), the many supporting libraries (Boost, GLib, GTK, etc.), and a couple of additional development tools—these are the dependenciesguix show inkscapelists.
Last, the (gnu packages) module provides higher-level facilities to
build manifests. In particular, it lets you look up packages by name—see
below.
- Scheme Procedure: specifications->manifest specs
Given specs, a list of specifications such as
"emacs@25.2"or"guile:debug", return a manifest. Specs have the format that command-line tools such asguix installandguix packageunderstand (see Вызовguix package).As an example, it lets you rewrite the Git manifest that we saw earlier like this:
(specifications->manifest '("git" "git:send-email"))Notice that we do not need to worry about
use-modules, importing the right set of modules, and referring to the right variables. Instead, we directly refer to packages in the same way as on the command line, which can often be more convenient.
Next: Фазы сборки, Previous: Writing Manifests, Up: Программный интерфейс [Contents][Index]
9.5 Системы сборки
В каждом определении пакета указывается система сборки и аргументы для
этой системы сборки (see Описание пакетов). Это поле
build-system представляет процедуру сборки пакета, а также неявные
зависимости этой процедуры сборки.
Системы сборки - это объекты <build-system>. Интерфейс для их
создания и управления ими предоставляется модулем (guix
build-system), а фактические системы сборки экспортируются определенными
модулями.
Под капотом системы сборки сначала компилируют объекты пакета в bag.
bag похож на пакет, но с меньшим количеством украшений—другими
словами, bag - это представление пакета нижнего уровня, которое включает в
себя все входные данные этого пакета, включая те, которые были неявно
добавлены система сборки. Это промежуточное представление затем
компилируется в derivation (see Деривации).
package-with-c-toolchain - это пример способа изменить неявные
входные данные, которые использует система сборки пакета (see package-with-c-toolchain).
Системы сборки принимают необязательный список из arguments. В
определениях пакетов они передаются через поле arguments
(see Описание пакетов). Обычно это аргументы ключевого слова
(see keyword arguments in Guile in GNU Guile
Reference Manual). Значение этих аргументов обычно оценивается в
build stratum—то есть процессом Guile, запущенным демоном
(see Деривации).
Основная система сборки - это gnu-build-system, которая реализует
стандартную процедуру сборки для GNU и многих других пакетов. Она
предоставляется модулем (guix build-system gnu).
- Scheme Variable: gnu-build-system
gnu-build-systemпредставляет систему сборки GNU и ее варианты (see configuration and makefile conventions in GNU Coding Standards).Вкратце, пакеты, использующие его, настраиваются, собираются и устанавливаются с помощью обычной последовательности команд
./ configure && make && make check && make install. На практике часто требуется несколько дополнительных шагов. Все эти шаги разбиты на отдельные фазы. See Фазы сборки, чтобы узнать больше о фазах сборки и способах их настройки.Кроме того, эта система сборки гарантирует, что доступна “стандартная” среда для пакетов GNU. Сюда входят такие инструменты, как GCC, libc, Coreutils, Bash, Make, Diffutils, grep и sed (полный список см. в модуле
(guix build-system gnu)). Мы называем их неявными входами пакета, потому что в определениях пакетов они не упоминаются.Эта система сборки поддерживает ряд ключевых аргументов, которые можно передать через поле
argumentsпакета. Вот некоторые из основных параметров:build phasesСчитать список каналов из файла file вместо ~/.config/guix/channels.scm. file должен содержать код Scheme, который определяет список объектов "канал". См. See Каналы для подробной информации.
Конфигурирование системыЭто список флагов (строк), переданных в сценарий (script)
configure. См. See Описание пакетов.#:make-flagsЭтот список строк содержит флаги, передаваемые в качестве аргументов для вызовов
makeна этапахbuild,checkиinstall.#:out-of-source?Это логическое значение,
#fпо умолчанию, указывает, следует ли запускать сборки в каталоге сборки отдельно от исходников.Когда это значение истинно, на этапе
configureсоздается отдельный каталог сборки, происходит переход в этот каталог и оттуда запускается сценарийconfigure. Это полезно для пакетов, которым это необходимо, таких какglibc.#:tests?This Boolean,
#tby default, indicates whether thecheckphase should run the package’s test suite.#:test-targetThis string,
"check"by default, gives the name of the makefile target used by thecheckphase.#:parallel-build?#:parallel-tests?These Boolean values specify whether to build, respectively run the test suite, in parallel, with the
-jflag ofmake. When they are true,makeis passed-jn, where n is the number specified as the --cores option ofguix-daemonor that of theguixclient command (see --cores).#:validate-runpath?This Boolean,
#tby default, determines whether to “validate” theRUNPATHof ELF binaries (.soshared libraries as well as executables) previously installed by theinstallphase. See thevalidate-runpathphase, for details.#:substitutable?This Boolean,
#tby default, tells whether the package outputs should be substitutable—i.e., whether users should be able to obtain substitutes for them instead of building locally (see Подстановки).--references--referencesWhen true, these arguments must be a list of dependencies that must not appear among the references of the build results. If, upon build completion, some of these references are retained, the build process fails.
This is useful to ensure that a package does not erroneously keep a reference to some of it build-time inputs, in cases where doing so would, for example, unnecessarily increase its size (see Вызов
guix size).
Most other build systems support these keyword arguments.
Другие объекты <build-system> определены для поддержки других
соглашений и инструментов, используемых пакетами свободного программного
обеспечения. Они наследуют большую часть gnu-build-system и
различаются в основном набором входных данных, неявно добавляемых в процесс
сборки, и списком выполняемых фаз. Некоторые из этих систем сборки
перечислены ниже.
- Scheme Variable: ant-build-system
Эта переменная экспортируется
(guix build-system ant). Она реализует процедуру сборки пакетов Java, которые можно собрать с помощью Ant build tool.Она добавляет к набору входных данных как
ant, так и Java Development Kit (JDK), предоставленные пакетомicedtea. Различные пакеты можно указать с помощью параметров#:antи#:jdkсоответственно.Когда исходный пакет не предоставляет подходящий файл сборки Ant, параметр
#:jar-nameможно использовать для создания минимального файла сборки Ant build.xml с задачами для создания указанного архива jar. В этом случае параметр#:source-dirможно использовать для указания подкаталога источника, по умолчанию - src.Параметр
#:main-classможно использовать с минимальным файлом сборки ant для указания основного класса результирующего jar-файла. Это делает файл jar исполняемым. Параметр#:test-includeможно использовать для указания списка запускаемых тестов junit. По умолчанию это(list "**/*Test.java").#:test-excludeможно использовать для отключения некоторых тестов. По умолчанию это(list "**/Abstract*.java"), потому что абстрактные классы не могут быть запущены как тесты.Параметр
#:build-targetможно использовать для указания задачи Ant, которая должна выполняться на этапеbuild. По умолчанию будет запущена задача jar.
- Scheme Variable: android-ndk-build-system
-
Эта переменная экспортируется
(guix build-system android-ndk). Она реализует процедуру сборки пакетов Android NDK (собственный комплект разработки) с использованием процесса сборки, специфичного для Guix.Система сборки предполагает, что пакеты устанавливают свои файлы общедоступного интерфейса (заголовки) в подкаталог include вывода
out, а их библиотеки - в подкаталог lib выводаout.Также предполагается, что объединение всех зависимостей пакета не имеет конфликтующих файлов.
В настоящее время кросс-компиляция не поддерживается, поэтому сейчас предполагается, что библиотеки и файлы заголовков являются хост-инструментами.
- Scheme Variable: asdf-build-system/source
- Scheme Variable: asdf-build-system/sbcl
- Scheme Variable: asdf-build-system/ecl
-
Эти переменные, экспортированные
(guix build-system asdf), реализуют процедуры сборки для пакетов Common Lisp с использованием “ASDF”. ASDF - это средство определения системы для программ и библиотек Common Lisp.Система
asdf-build-system/sourceустанавливает пакеты в исходной форме и может быть загружена с использованием любой распространенной реализации Lisp через ASDF. Другие, такие какasdf-build-system/sbcl, устанавливают двоичные системы в формате, понятном конкретной реализации. Эти системы сборки также могут использоваться для создания исполняемых программ или образов lisp, которые содержат набор предварительно загруженных пакетов.В системе сборки используются соглашения об именах. Для бинарных пакетов перед именем пакета должен стоять префикс реализации lisp, например
sbcl-дляasdf-build-system/sbcl.Кроме того, соответствующий исходный пакет должен быть помечен с использованием того же соглашения, что и пакеты python (см. Модули Python), с использованием префикса
cl-.Для создания исполняемых программ и образов можно использовать процедуры сборки
build-programиbuild-image. Их следует вызывать в фазе сборки после фазыcreate-symlinks, чтобы только что созданную систему можно было использовать в полученном образе.build-programтребует, чтобы список выражений Common Lisp был передан в качестве аргумента#:entry-program.Если система не определена в собственном файле .asd с тем же именем, тогда следует использовать параметр
#:asd-file, чтобы указать, в каком файле определена система. Кроме того, если пакет определяет систему для своих тестов в отдельном файле, он будет загружен перед запуском тестов, если он указан параметром#:test-asd-file. Если он не установлен, будут попробованы файлы<system>-tests.asd,<system>-test.asd,tests.asdиtest.asd, если они есть.Если по какой-то причине пакет должен быть назван иначе, чем это предлагается в соглашениях об именах, можно использовать параметр
#:asd-system-nameдля указания имени системы.
- Scheme Variable: cargo-build-system
-
Эта переменная экспортируется
(guix build-system cargo). Она поддерживает сборку пакетов с использованием Cargo, инструмента сборки языка программирования Rust.Она добавляет
rustcиcargoк набору входных данных. Другой пакет Rust можно указать с помощью параметра#:rust.Обычные cargo зависимости должны быть добавлены к определению пакета через параметр
#:cargo-inputsв виде списка пар имени и спецификации, где спецификацией может быть определение пакета или источника. Обратите внимание, что в спецификации должен быть указан путь к сжатому архиву, который содержит файлCargo.tomlв своем корне, иначе он будет проигнорирован. Точно так же dev-зависимости cargo должны быть добавлены в определение пакета с помощью параметра#:cargo-development-inputs.На этапе
configureэта система сборки собирет любые исходные данные, указанные в параметрах#:cargo-inputsи#:cargo-development-inputs, доступными для cargo. Она также удалит файлCargo.lock, который будет воссозданcargoна этапеbuild. На этапеinstallустанавливаются двоичные файлы, определенные crate.
- Scheme переменная: cmake-build-system
This variable is exported by
(guix build-system chicken). It builds CHICKEN Scheme modules, also called “eggs” or “extensions”. CHICKEN generates C source code, which then gets compiled by a C compiler, in this case GCC.Эта система сборки добавляет
chickenк входным данным (inputs) пакета, а также к пакетамgnu-build-system.The build system can’t (yet) deduce the egg’s name automatically, so just like with
go-build-systemand its#:import-path, you should define#:egg-namein the package’sargumentsfield.Например, если вы создаете пакет, содержащий Bash, с помощью:
(arguments '(#:egg-name "srfi-1"))Egg dependencies must be defined in
propagated-inputs, notinputsbecause CHICKEN doesn’t embed absolute references in compiled eggs. Test dependencies should go tonative-inputs, as usual.
- Scheme Variable: copy-build-system
Эта переменная экспортируется в
(guix build-system copy). Она поддерживает сборку простых пакетов, которые не требуют большой компиляции, в основном просто перемещения файлов.Она добавляет большую часть пакетов
gnu-build-systemв набор входных данных. По этой причинеcopy-build-systemне требуется весь шаблонный код, часто необходимый дляtrivial-build-system.Чтобы еще больше упростить процесс установки файла, предоставляется аргумент
#:install-plan, позволяющий упаковщику указывать, какие файлы куда установить. План установки представляет собой список(source target [filters]). filters необязательны.- Когда source соответствует файл или каталог без косой черты, установить его в target.
- Если target имеет косую черту в конце, установить source basename ниже target.
- В противном случае установите source как target.
- Когда source - это каталог с косой чертой в конце или когда используются filters,
завершающая косая черта target подразумевается с тем же значением, что
и выше.
- Без filter установить содержимое source в target.
- С filters среди
#:include,#:include-regexp,#:exclude,#:exclude-regexp, установить только избранные файлы в зависимости от фильтров. Каждый фильтр определяется списком строк.- С помощью
#:includeустановите все файлы, суффикс пути которых соответствует хотя бы одному из элементов в данном списке. - С помощью
#:include-regexустановить все файлы, подкаталоги которых соответствуют хотя бы одному из регулярных выражений в данном списке. - Фильтры
#:excludeи#:exclude-regexpявляются дополнением к своим аналогам включения. Без флагов#:includeустановить все файлы, кроме тех, которые соответствуют фильтрам исключения. Если указаны и включения, и исключения, то исключения выполняются поверх включений.
- С помощью
В любом случае пути, относительные к source, сохраняются в target.
Примеры:
-
("foo/bar" "share/my-app/"): Установить bar в share/my-app/bar. -
("foo/bar" "share/my-app/baz"): Установить bar в share/my-app/baz. -
("foo/" "share/my-app"): Установить содержимое foo в share/my-app, например, установить foo/sub/file в share/my-app/sub/file. -
("foo/" "share/my-app" #:include ("sub/file")): Установить только foo/sub/file в share/my-app/sub/file. -
("foo/sub" "share/my-app" #:include ("file")): Установить foo/sub/file в share/my-app/file.
- Когда source соответствует файл или каталог без косой черты, установить его в target.
- Scheme Variable: clojure-build-system
Эта переменная экспортируется
(guix build-system clojure). Она реализует простую процедуру сборки пакетов Clojure с использованием простого старогоcompileв Clojure. Кросс-компиляция пока не поддерживается.Она добавляет
clojure,icedteaиzipк набору входных данных. Различные пакеты можно указать с помощью параметров#:clojure,#:jdkи#:zipсоответственно.Список исходных каталогов, тестовых каталогов и имен jar-файлов можно указать с помощью параметров
#:source-dirs,#:test-dirsи#:jar-namesсоответственно. Каталог компиляции и основной класс можно указать с помощью параметров#:compile-dirи#:main-classсоответственно. Остальные параметры описаны ниже.Эта система сборки является расширением
ant-build-system, но со следующими изменениями:buildНа этом этапе вызывается
compileв Clojure для компиляции исходных файлов и запускаетсяjarдля создания jar-файлов как из исходных файлов, так и из скомпилированных файлов в соответствии со списком включения и списком исключений, указанным в#:aot-includeи#:aot-excludeсоответственно. Список исключений имеет приоритет над списком включения. Эти списки состоят из символов, представляющих библиотеки Clojure, или специального ключевого слова#:all, представляющего все библиотеки Clojure, находящиеся в исходных каталогах. Параметр#:omit-source?определяет, следует ли включать исходники в jar-файлы.checkНа этом этапе выполняются тесты в соответствии со списком включения и списком исключений, указанными в
#:test-includeи#:test-excludeсоответственно. Их значения аналогичны значениям#:aot-includeи#:aot-exclude, за исключением того, что специальное ключевое слово#:allтеперь обозначает все библиотеки Clojure, находящиеся в каталогах test. Параметр#:tests?определяет, нужно ли запускать тесты.установкаНа этом этапе устанавливаются все созданные ранее jars.
Помимо вышесказанного, эта система сборки также содержит дополнительную фазу:
install-docНа этом этапе устанавливаются все файлы верхнего уровня с базовым именем, совпадающим с
%doc-regex. Другое регулярное выражение можно указать с помощью параметра#:doc-regex. Все файлы (рекурсивно) в каталогах документации, указанные в#:doc-dirs, также устанавливаются.
- Scheme переменная: cmake-build-system
Эта переменная экспортируется
(guix build-system cmake). Она реализует процедуру сборки пакетов с использованием инструмента сборки CMake.Она автоматически добавляет пакет
cmakeв набор входных данных. Какой пакет используется, можно указать с помощью параметра#:cmake.Параметр
#:configure-flagsиспользуется как список флагов, переданных командеcmake. Параметр#:build-typeабстрактно определяет флаги, передаваемые компилятору; по умолчанию используется"RelWithDebInfo"(сокращение от “release mode с отладочной информацией”), что примерно означает, что код компилируется с помощью-O2 -g, как в случае пакетов на основе Autoconf по умолчанию.
- Scheme переменная: dune-build-system
Эта переменная экспортируется в
(guix build-system dune). Она поддерживает сборку пакетов с использованием Dune, инструмента сборки для языка программирования OCaml. Она реализована как расширениеocaml-build-system, описанную ниже. Таким образом, в эту систему сборки можно передать параметры#:ocamlи#:findlib.Она автоматически добавляет пакет
duneв набор входных данных. Какой пакет используется, можно указать с помощью параметра#:dune.Фаза
configureотсутствует, потому что dune пакеты обычно не нужно настраивать. Параметр#:build-flagsиспользуется как список флагов, переданных командеduneво время сборки.Параметр
#:jbuild?можно передать для использования командыjbuildвместо более новой командыduneпри сборке пакета. Его значение по умолчанию -#f.Параметр
#:packageможет быть передан для указания имени пакета, что полезно, когда пакет содержит несколько пакетов, и вы хотите создать только один из них. Это эквивалентно передаче аргумента-pвdune.
- Scheme variable: elm-build-system
This variable is exported by
(guix build-system elm). It implements a build procedure for Elm packages similar to ‘elm install’.The build system adds an Elm compiler package to the set of inputs. The default compiler package (currently
elm-sans-reactor) can be overridden using the#:elmargument. Additionally, Elm packages needed by the build system itself are added as implicit inputs if they are not already present: to suppress this behavior, use the#:implicit-elm-package-inputs?argument, which is primarily useful for bootstrapping.The
"dependencies"and"test-dependencies"in an Elm package’s elm.json file correspond topropagated-inputsandinputs, respectively.Elm requires a particular structure for package names: see Elm Packages for more details, including utilities provided by
(guix build-system elm).There are currently a few noteworthy limitations to
elm-build-system:- The build system is focused on packages in the Elm sense of the word:
Elm projects which declare
{ "type": "package" }in their elm.json files. Usingelm-build-systemto build Elm applications (which declare{ "type": "application" }) is possible, but requires ad-hoc modifications to the build phases. For examples, see the definitions of theelm-todomvcexample application and theelmpackage itself (because the front-end for the ‘elm reactor’ command is an Elm application). - Elm supports multiple versions of a package coexisting simultaneously under
ELM_HOME, but this does not yet work well withelm-build-system. This limitation primarily affects Elm applications, because they specify exact versions for their dependencies, whereas Elm packages specify supported version ranges. As a workaround, the example applications mentioned above use thepatch-application-dependenciesprocedure provided by(guix build elm-build-system)to rewrite their elm.json files to refer to the package versions actually present in the build environment. Alternatively, Guix package transformations (see Defining Package Variants) could be used to rewrite an application’s entire dependency graph. - We are not yet able to run tests for Elm projects because neither
elm-test-rsnor the Node.js-basedelm-testrunner has been packaged for Guix yet.
- The build system is focused on packages in the Elm sense of the word:
Elm projects which declare
- Scheme переменная: go-build-system
Эта переменная экспортируется
(guix build-system go). Онf реализует процедуру сборки пакетов Go с использованием стандартного механизмов сборки Go.Ожидается, что пользователь предоставит значение для ключа
#:import-pathи, в некоторых случаях,#:unpack-path. import path соответствует пути к файловой системе, ожидаемому сценариями сборки пакета и любыми ссылочными пакетами, и обеспечивает уникальный способ ссылки на Go пакет. Обычно он основан на комбинации удаленного URI исходного кода пакета и иерархической структуры файловой системы. В некоторых случаях вам нужно будет распаковать исходный код пакета в другую структуру каталогов, отличную от той, которая указана в пути импорта, и в таких случаях следует использовать#:unpack-path.Пакеты, которые предоставляют библиотеки Go, должны устанавливать свой исходный код во встроенные выходные данные. Ключ
#:install-source?, который по умолчанию равен#t, определяет, установливается ли исходный код. Для пакетов, которые предоставляют только исполняемые файлы, может быть установлено значение#f.Packages can be cross-built, and if a specific architecture or operating system is desired then the keywords
#:goarchand#:gooscan be used to force the package to be built for that architecture and operating system. The combinations known to Go can be found in their documentation.
- Scheme переменная: glib-or-gtk-build-system
Эта переменная экспортируется в
(guix build-system glib-or-gtk). Она предназначена для использования с пакетами, использующими GLib или GTK+.Эта система сборки добавляет следующие две фазы к тем, которые определены в
gnu-build-system:glib-or-gtk-wrapФаза
glib-or-gtk-wrapгарантирует, что программы в bin/ смогут найти GLib “schemas” и модули GTK+. Это достигается путем включения программ в сценарии запуска, которые соответствующим образом устанавливают переменные средыXDG_DATA_DIRSиGTK_PATH.Можно исключить определенные выходные данные пакета из этого процесса упаковки, указав их имена в параметре
#:glib-or-gtk-wrap-excluded-output. Это полезно, когда известно, что выходной файл не содержит двоичных файлов GLib или GTK+, и где wrapping может произвольно добавить зависимость этого вывода от GLib и GTK+.glib-or-gtk-compile-schemasФаза
glib-or-gtk-compile-schemasгарантирует, что все GSettings schemas в GLib скомпилированы. Компиляция выполняется программойglib-compile-schemas. Она предоставляется пакетомglib:bin, который автоматически импортируется системой сборки. Пакетglib, предоставляющийglib-compile-schemas, можно указать с помощью параметра#:glib.
Обе фазы выполняются после фазы
install.
- Scheme переменная: guile-build-system
Эта система сборки предназначена для пакетов Guile, которые состоят исключительно из кода Scheme и настолько скудны, что у них даже нет make-файла, не говоря уже о сценарии configure. Она компилирует Scheme код с помощью
guild compile(see Compilation in GNU Guile Reference Manual) и устанавливает файлы .scm и .go в нужное место. Она также устанавливает документацию.Эта система сборки поддерживает кросс-компиляцию с использованием параметра --target в ‘guild compile’.
Пакеты, созданные с помощью
guile-build-system, должны содержать пакет Guile в полеnative-inputs.
- Scheme переменная: julia-build-system
Эта переменная экспортируется в
(guix build-system julia). Она реализует процедуру сборки, используемую пакетами julia, которая по сути аналогична запуску ‘julia -e 'используя Pkg; Pkg.add(package)'’ в среде, гдеJULIA_LOAD_PATHсодержит пути ко всем входным данным пакета Julia. Тесты запускаются сPkg.test.The Julia package name and uuid is read from the file Project.toml. These values can be overridden by passing the argument
#:julia-package-name(which must be correctly capitalized) or#:julia-package-uuid.Julia packages usually manage their binary dependencies via
JLLWrappers.jl, a Julia package that creates a module (named after the wrapped library followed by_jll.jl.To add the binary path
_jll.jlpackages, you need to patch the files under src/wrappers/, replacing the call to the macroJLLWrappers.@generate_wrapper_header, adding as a second argument containing the store path the binary.As an example, in the MbedTLS Julia package, we add a build phase (see Фазы сборки) to insert the absolute file name of the wrapped MbedTLS package:
(add-after 'unpack 'override-binary-path (lambda* (#:key inputs #:allow-other-keys) (for-each (lambda (wrapper) (substitute* wrapper (("generate_wrapper_header.*") (string-append "generate_wrapper_header(\"MbedTLS\", \"" (assoc-ref inputs "mbedtls-apache") "\")\n")))) ;; There's a Julia file for each platform, override them all. (find-files "src/wrappers/" "\\.jl$"))))Some older packages that aren’t using Project.toml yet, will require this file to be created, too. It is internally done if the arguments
#:julia-package-nameand#:julia-package-uuidare provided.
- Scheme Variable: ant-build-system
Эта переменная экспортируется в
(guix build-system maven). Она реализует процедуру сборки пакетов Maven. Maven - это инструмент для управления зависимостями и жизненным циклом Java. Пользователь Maven указывает зависимости и плагины в файле pom.xml, который читает Maven. Когда Maven не имеет одной из зависимостей или плагинов в своем репозитории, он загружает их и использует для сборки пакета.Система сборки maven гарантирует, что maven не будет пытаться загрузить какие-либо зависимости, работая в offline режиме. Maven завершится ошибкой, если зависимость отсутствует. Перед запуском Maven pom.xml (и подпроекты) модифицируются, чтобы указать версию зависимостей и плагинов, которые соответствуют версиям, доступным в среде сборки guix. Зависимости и плагины должны быть установлены в поддельном репозитории maven по адресу lib/m2 и перед запуском maven привязаны к соответствующему репозиторию. Maven получает указание использовать этот репозиторий для сборки и устанавливает туда созданные артефакты. Измененные файлы копируются в каталог lib/m2 выходных данных пакета.
Вы можете указать файл pom.xml с аргументом
#:pom-fileили позволить системе сборки использовать файл pom.xml по умолчанию в источниках.Если вам нужно указать версию зависимости вручную, вы можете использовать аргумент
#:local-packages. Он принимает список ассоциаций, где ключ - это groupId пакета, а его значение - это список ассоциаций, где ключ - это artifactId пакета, а его значение - это версия, которую вы хотите переопределить в pom.xml.Некоторые пакеты используют зависимости или плагины, которые не используются ни во время выполнения, ни во время сборки в Guix. Вы можете изменить файл pom.xml, чтобы удалить их, используя аргумент
#:exclude. Его значение - это список ассоциаций, где ключ - это groupId плагина или зависимости, которые вы хотите удалить, а значение - это список artifactId, которые вы хотите удалить.Вы можете переопределить пакеты по умолчанию
jdkиmavenс помощью соответствующего аргумента,#:jdkи#:maven.Аргумент
#:maven-plugins- это список подключаемых модулей maven, используемых во время сборки, в том же формате, что и поляinputsв объявлении пакета. Его значение по умолчанию -(default-maven-plugins), которое также экспортируется.
- Scheme переменная: minetest-mod-build-system
This variable is exported by
(guix build-system minetest). It implements a build procedure for Minetest mods, which consists of copying Lua code, images and other resources to the location Minetest searches for mods. The build system also minimises PNG images and verifies that Minetest can load the mod without errors.
- Scheme переменная: minify-build-system
Эта переменная экспортируется в
(guix build-system minify). Она реализует процедуру минификации для простых пакетов JavaScript.Он добавляет
uglify-jsк набору входных данных и использует его для сжатия всех файлов JavaScript в каталоге src. Другой minifier пакет можно указать с помощью параметра#:uglify-js, но ожидается, что этот пакет запишет минимизированный код в стандартный вывод.Когда не все входные файлы JavaScript находятся в каталоге src, можно использовать параметр
#:javascript-files, чтобы указать список имен файлов для передачи в minifier.
- Scheme переменная: ocaml-build-system
Эта переменная экспортируется в
(guix build-system ocaml). Она реализует процедуру сборки пакетов OCaml, которая заключается в выборе правильного набора команд для запуска для каждого пакета. Пакеты OCaml могут ожидать выполнения множества различных команд. Эта система сборки попробует некоторые из них.Если в пакете есть файл setup.ml на верхнем уровне, он будет запускать
ocaml setup.ml -configure,ocaml setup.ml -buildиocaml setup.ml -install. Система сборки предполагает, что этот файл был сгенерирован OASIS, и позаботится об установке префикса и включении тестов, если они не отключены. Вы можете передать флаги конфигурации и сборки с помощью#:configure-flagsи#:build-flags. Ключ#:test-flagsможет быть передан для изменения набора флагов, используемых для включения тестов. Ключ#:use-make?можно использовать для обхода этой системы на этапах сборки и установки.Когда в пакете есть файл configure, предполагается, что это созданный вручную скрипт настройки, для которого требуется другой формат аргументов, чем в
gnu-build-system. Вы можете добавить дополнительные флаги с помощью клавиши#:configure-flags.Когда в пакете есть файл Makefile (или
#:use-make?- это#t), он будет использоваться, и дополнительные флаги могут быть переданы на этапы сборки и установки с#:make-flagsключом.Наконец, некоторые пакеты не имеют этих файлов и используют стандартное расположение для своей системы сборки. В этом случае система сборки запустит
ocaml pkg/pkg.mlилиocaml pkg/build.mlи позаботится о предоставлении пути к необходимому модулю findlib. Дополнительные флаги можно передать с помощью ключа#:build-flags. Об установке позаботитсяopam-installer. В этом случае пакетopamнеобходимо добавить в полеnative-inputsв определении пакета.Обратите внимание, что большинство пакетов OCaml предполагают, что они будут установлены в том же каталоге, что и OCaml, что не является тем, что мы хотим в guix. В частности, они устанавливают файлы .so в каталог своего модуля, что обычно нормально, потому что он находится в каталоге компилятора OCaml. Однако в guix эти библиотеки нельзя найти, и мы используем
CAML_LD_LIBRARY_PATH. Эта переменная указывает на lib/ocaml/site-lib/stubslibs, и именно здесь должны быть установлены библиотеки .so.
- Scheme переменная: python-build-system
Эта переменная экспортируется в
(guix build-system python). Она реализует более или менее стандартную процедуру сборки, используемую пакетами Python, которая заключается в запускеpython setup.py build, а затемpython setup.py install --prefix=/gnu/store/….For packages that install stand-alone Python programs under
bin/, it takes care of wrapping these programs so that theirGUIX_PYTHONPATHenvironment variable points to all the Python libraries they depend on.Какой пакет Python используется для сборки, можно указать с помощью параметра
#:python. Это полезный способ принудительно создать пакет для определенной версии интерпретатора Python, что может потребоваться, если пакет совместим только с одной версией интерпретатора.По умолчанию guix вызывает
setup.pyпод управлениемsetuptools, как иpip. Некоторые пакеты несовместимы с setuptools (и pip), поэтому вы можете отключить это, установив для параметра#:use-setuptools?значение#f.If a
"python"output is available, the package is installed into it instead of the default"out"output. This is useful for packages that include a Python package as only a part of the software, and thus want to combine the phases ofpython-build-systemwith another build system. Python bindings are a common usecase.
- Scheme Variable: pyproject-build-system
This is a variable exported by
guix build-system pyproject. It is based on python-build-system, and adds support for pyproject.toml and PEP 517. It also supports a variety of build backends and test frameworks.The API is slightly different from python-build-system:
-
#:use-setuptools?and#:test-targetis removed. -
#:build-backendis added. It defaults to#falseand will try to guess the appropriate backend based on pyproject.toml. -
#:test-backendis added. It defaults to#falseand will guess an appropriate test backend based on what is available in package inputs. -
#:test-flagsis added. The default is'(). These flags are passed as arguments to the test command. Note that flags for verbose output is always enabled on supported backends.
It is considered “experimental” in that the implementation details are not set in stone yet, however users are encouraged to try it for new Python projects (even those using setup.py). The API is subject to change, but any breaking changes in the Guix channel will be dealt with.
Eventually this build system will be deprecated and merged back into python-build-system, probably some time in 2024.
-
- Scheme Variable: perl-build-system
Эта переменная экспортируется в
(guix build-system perl). Она реализует стандартную процедуру сборки для пакетов Perl, которая заключается либо в запускеperl Build.PL --prefix=/gnu/store/…, за которым следуютBuildиBuild install; или при запускеperl Makefile.PL PREFIX=/gnu/store/…, за которым следуютmakeиmake install, в зависимости от того, какой изBuild.PLилиMakefile.PLприсутствует в дистрибутиве пакета. Предпочтение отдается первому, если в дистрибутиве пакета есть иBuild.PL, иMakefile.PL. Это предпочтение можно отменить, указав#tдля параметра#:make-maker?.Первоначальный вызов
perl Makefile.PLилиperl Build.PLпередает флаги, указанные в параметре#:make-maker-flagsили#:module-build-flags, соответственно.Какой пакет Perl используется, можно указать с помощью
#:perl.
- Scheme Variable: r-build-system
Эта переменная экспортируется в
(guix build-system python). Она реализует более или менее стандартную процедуру сборки, используемую пакетами Python, которая заключается в запускеpython setup.py build, а затемpython setup.py install --prefix=/gnu/store/….It further creates a wrapper script in
bin/and a desktop entry inshare/applications, both of which can be used to launch the game.Which Ren’py package is used can be specified with
#:renpy. Games can also be installed in outputs other than “out” by using#:output.
- Scheme переменная: qt-build-system
Эта переменная экспортируется в
(guix build-system qt). Она предназначена для использования с приложениями, использующими Qt или KDE.Эта система сборки добавляет следующие две фазы к тем, которые определены в
cmake-build-system:check-setupФаза
check-setupподготавливает среду к запуску проверок, которые обычно используются тестовыми программами Qt. Пока это устанавливает только некоторые переменные среды:QT_QPA_PLATFORM=offscreen,DBUS_FATAL_WARNINGS=0иCTEST_OUTPUT_ON_FAILURE=1.Этот этап добавляется перед этапом
check. Это отдельный этап для облегчения настройки.qt-wrapФаза
qt-wrapищет пути к плагинам Qt5, пути QML и некоторый XDG во входных и выходных данных. Если путь найден, все программы в выходных каталогах bin/, sbin/, libexec/ и lib/libexec/ заключены в сценарии, определяющие необходимые environment переменные.Можно исключить определенные выходные данные пакета из этого процесса упаковки, указав их имена в параметре
#:qt-wrap-excluded-output. Это полезно, когда известно, что вывод не содержит никаких двоичных файлов Qt, и когда обертка может произвольно добавить зависимость этого вывода от Qt, KDE и т.п.Эта фаза добавляется после фазы
install.
- Scheme Variable: r-build-system
Эта переменная экспортируется в
(guix build-system r). Она реализует процедуру сборки, используемую пакетами R, которая, по сути, немного больше, чем запуск ‘R CMD INSTALL --library=/gnu/store/…’ в среде, гдеR_LIBS_SITEсодержит пути ко всем входам пакета R. Тесты запускаются после установки с использованием R-функцииtools::testInstalledPackage.
- Scheme переменная: rakudo-build-system
Эта переменная экспортируется
(guix build-system rakudo). Которая реализует систем сборки, используемую Rakudo для Perl6 пакетов. Она устанавливает: пакет в/gnu/store/…/NAME-VERSION/share/perl6; двоичные файлы, библиотеки и ресурсы; помещает файлы вbin/. Тесты можно пропустить, передав#fпараметруtests?.Какой пакет rakudo используется, можно указать с помощью
rakudo. Какой пакет perl6-tap-harness, используемый для тестов, можно указать с помощью#:verify6или удалить, передав#fв параметрwith-verify6?. Какой пакет perl6-zef, используемый для тестирования и установки, можно указать с помощью#:zefили удалить, передав#fв параметрwith-zef?.
- Scheme Variable: rebar-build-system
This variable is exported by
(guix build-system rebar). It implements a build procedure around rebar3, a build system for programs written in the Erlang language.It adds both
rebar3and theerlangto the set of inputs. Different packages can be specified with the#:rebarand#:erlangparameters, respectively.This build system is based on
gnu-build-system, but with the following phases changed:unpackThis phase, after unpacking the source like the
gnu-build-systemdoes, checks for a filecontents.tar.gzat the top-level of the source. If this file exists, it will be unpacked, too. This eases handling of package hosted at https://hex.pm/, the Erlang and Elixir package repository.bootstrapconfigureThere are no
bootstrapandconfigurephase because erlang packages typically don’t need to be configured.buildThis phase runs
rebar3 compilewith the flags listed in#:rebar-flags.checkUnless
#:tests? #fis passed, this phase runsrebar3 eunit, or some other target specified with#:test-target, with the flags listed in#:rebar-flags,установкаThis installs the files created in the default profile, or some other profile specified with
#:install-profile.
- Scheme переменная: texlive-build-system
Эта переменная экспортируется в
(guix build-system texlive). Она используется для сборки пакетов TeX в batch режиме с указанным движком. Система сборки устанавливает переменнуюTEXINPUTSдля поиска всех исходных файлов TeX во входных данных.По умолчанию она запускает
luatexдля всех файлов, заканчивающихся наins. Другой механизм и формат можно указать с помощью аргумента#:tex-format. Различные цели сборки могут быть указаны с помощью аргумента#:build-target, который ожидает список имен файлов. Система сборки добавляет к входам толькоtexlive-binиtexlive-latex-base(оба из(gnu packages tex). Оба могут быть переопределены с помощью аргументов#:texlive-binи#:texlive-latex-baseсоответственно.Параметр
#:tex-directoryсообщает системе сборки, где установить созданные файлы в дереве texmf.
- Scheme переменная: ruby-build-system
Эта переменная экспортируется в
(guix build-system ruby). Она реализует процедуру сборки RubyGems, используемую пакетами Ruby, которая включает запускgem build, за которым следуетgem install.Поле
sourceпакета, использующего эту систему сборки, обычно ссылается на gem архив, поскольку это формат, который разработчики Ruby используют при выпуске своего программного обеспечения. Система сборки распаковывает gem архив, потенциально исправляет исходный код, запускает набор тестов, переупаковывает gem и устанавливает его. Кроме того, на каталоги и архивы можно ссылаться, чтобы можно было создавать unreleased gem’ы из Git или традиционного архива с исходным кодом.Какой пакет Ruby используется, можно указать с помощью параметра
#:ruby. Список дополнительных флагов, передаваемых командеgem, можно указать с помощью параметра#:gem-flags.
- Scheme переменная: waf-build-system
Эта переменная экспортируется в
(guix build-system waf). Она реализует процедуру сборки вокруг сценарияwaf. Общие этапы—configure,buildиinstall—реализуются путем передачи их имен в качестве аргументов сценариюwaf.Скрипт
wafвыполняется интерпретатором Python. Какой пакет Python используется для запуска сценария, можно указать с помощью параметра#:python.
- Scheme переменная: scons-build-system
Эта переменная экспортируется в
(guix build-system scons). Она реализует процедуру сборки, используемую инструментом сборки программного обеспечения SCons. Эта система сборки запускаетsconsдля сборки пакета,scons testдля запуска тестов и затемscons installдля установки пакета.Дополнительные флаги, передаваемые в
scons, можно указать с помощью параметра#:scons-flags. Цели сборки и установки по умолчанию могут быть переопределены с помощью#:build-targetи#:install-targetсоответственно. Версия Python, используемая для запуска SCons, может быть указана путем выбора соответствующего пакета SCons с параметром#:scons.
- Scheme переменная: haskell-build-system
Эта переменная экспортируется в
(guix build-system haskell). Она реализует процедуру сборки Cabal, используемую пакетами Haskell, которая включает запускrunhaskell Setup.hs configure --prefix=/gnu/store/…иrunhaskell Setup.hs build. Вместо установки пакета путем запускаrunhaskell Setup.hs install, чтобы избежать попыток регистрации библиотек в каталоге хранилища компилятора только для чтения, система сборки используетrunhaskell Setup.hs copy, за которым следуетrunhaskell Setup.hs register. Кроме того, система сборки генерирует документацию по пакету, запускаяrunhaskell Setup.hs haddock, если только#:haddock? #fпройден. Дополнительные параметры можно передать с помощью параметра#:haddock-flags. Если файлSetup.hsне найден, система сборки вместо этого ищетSetup.lhs.Какой компилятор Haskell используется, можно указать с помощью параметра
#:haskell, который по умолчанию равенghc.
- Scheme переменная: dub-build-system
Эта переменная экспортируется в
(guix build-system dub). Она реализует процедуру сборки Dub, используемую пакетами D, которая включает запускdub buildиdub run. Установка осуществляется путем копирования файлов вручную.Какой компилятор D используется, можно указать с помощью параметра
#:ldc, который по умолчанию равенldc.
- Scheme переменная: emacs-build-system
Эта переменная экспортируется в
(guix build-system emacs). Она реализует процедуру установки, аналогичную системе упаковки самого Emacs (see Packages in The GNU Emacs Manual).Сначала она создает файл
package-autoloads.el
- Scheme переменная: font-build-system
Эта переменная экспортируется в
(guix build-system font). Она реализует процедуру установки для пакетов шрифтов, в которой upstream предоставляет предварительно скомпилированные файлы TrueType, OpenType и т.д. файлы шрифтов, которые необходимо просто скопировать на место. Она копирует файлы шрифтов в стандартные места выходного каталога.
- Scheme переменная: meson-build-system
Эта переменная экспортируется в
(guix build-system meson). Она реализует процедуру сборки для пакетов, которые используют Meson в качестве своей системы сборки.It adds both Meson and Ninja to the set of inputs, and they can be changed with the parameters
#:mesonand#:ninjaif needed.Эта система сборки является расширением
gnu-build-system, но со следующими фазами, измененными на некоторые специфичные для Meson:configureНа этапе выполняется
mesonс флагами, указанными в#:configure-flags. Флаг --buildtype всегда установлен наdebugoptimized, если что-то еще не указано в#:build-type.buildНа этапе выполняется
ninjaдля параллельной сборки пакета по умолчанию, но это можно изменить с помощью#:parallel-build?.checkThe phase runs ‘meson test’ with a base set of options that cannot be overridden. This base set of options can be extended via the
#:test-optionsargument, for example to select or skip a specific test suite.установкаФаза выполняется
ninja installи не может быть изменен.
Помимо этого, система сборки также добавляет следующие фазы:
fix-runpathThis phase ensures that all binaries can find the libraries they need. It searches for required libraries in subdirectories of the package being built, and adds those to
RUNPATHwhere needed. It also removes references to libraries left over from the build phase bymeson, such as test dependencies, that aren’t actually required for the program to run.glib-or-gtk-wrapЭта фаза предоставляется
glib-or-gtk-build-systemи по умолчанию не включена. Ее можно включить с помощью#:glib-or-gtk?.glib-or-gtk-compile-schemasЭта фаза предоставляется
glib-or-gtk-build-systemи по умолчанию не включена. Ее можно включить с помощью#:glib-or-gtk?.
- Scheme переменная: linux-module-build-system
linux-module-build-systemпозволяет создавать модули ядра Linux.Эта система сборки является расширением
gnu-build-system, но со следующими изменениями:configureНа этой фазе среда настраивается таким образом, чтобы Makefile ядра Linux можно было использовать для сборки внешнего модуля ядра.
buildНа этой фазе используется Makefile ядра Linux для сборки внешнего модуля ядра.
установкаНа этой фазе используется Makefile ядра Linux для установки внешнего модуля ядра.
Возможно и полезно указать ядро Linux, которое будет использоваться для сборки модуля (в форме
argumentsпакета с использованиемlinux-module-build-systemиспользуйте ключ#:linux, чтобы указать это).
- Scheme переменная: node-build-system
Эта переменная экспортируется в
(guix build-system node). Она реализует процедуру сборки, используемую Node.js, которая реализует аппроксимацию командыnpm install, за которой следует командаnpm test.Какой пакет Node.js используется для интерпретации команд
npm, можно указать с помощью параметра#:node, который по умолчанию равенnode.
Наконец, для пакетов, которым не нужно ничего столь же сложного, предоставляется “trivial” система сборки. Она тривиальна в том смысле, что она практически не оказывает поддержки при сборке: она не извлекает никаких неявных входных данных и не имеет понятия о этапах сборки.
- Scheme переменная: trivial-build-system
Эта переменная экспортируется
(guix build-system trivial).Эта система сборки требует аргумента
#:builder. Этот аргумент должен быть Scheme выражением, которое строит выходные данные пакета—как сbuild-expression->derivation(seebuild-expression->derivation).
- Scheme Variable: channel-build-system
This variable is exported by
(guix build-system channel).This build system is meant primarily for internal use. A package using this build system must have a channel specification as its
sourcefield (see Каналы); alternatively, its source can be a directory name, in which case an additional#:commitargument must be supplied to specify the commit being built (a hexadecimal string).The resulting package is a Guix instance of the given channel, similar to how
guix time-machinewould build it.
Next: Build Utilities, Previous: Системы сборки, Up: Программный интерфейс [Contents][Index]
9.6 Фазы сборки
Почти все системы сборки пакетов реализуют понятие фазы сборки:
последовательность действий, которые система сборки выполняет при сборке
пакета, что приводит к установке побочных продуктов в store. Заметным
исключением является “bare-bones” trivial-build-system
(see Системы сборки).
As discussed in the previous section, those build systems provide a standard
list of phases. For gnu-build-system, the main build phases are the
following:
set-pathsDefine search path environment variables for all the input packages, including
PATH(see Search Paths).unpackРаспаковать архив исходных текстов и измените текущий каталог на извлеченное дерево исходных текстов. Если источник на самом деле является каталогом, скопировать его в дерево сборки и войдите в этот каталог.
patch-source-shebangsИзменить shebang, встречающиеся в исходных файлах, чтобы они ссылались на правильные имена файлов хранилища. Например, это изменяет
#!/bin/shна#!/gnu/store/…-bash-4.3/bin/sh.configureЗапустить сценарий configure с несколькими параметрами по умолчанию, такими как --prefix=/gnu/store/…, а также параметрами, указанными в
#:configure-flagsаргументе.buildЗапустить
makeсо списком флагов, указанным с помощью#:make-flags. Если аргумент#:parallel-build?истинен (по умолчанию), выполнить сборку сmake -j.checkЗапустить
make checkили другой target, указанный с помощью#:test-target, если только#:tests? #fпройден. Если аргумент#:parallel-tests?истинен (по умолчанию), запуститьmake check -j.установкаЗапустить
make installс флагами, перечисленными в#:make-flags.patch-shebangsИзменить shebangs на установленные исполняемые файлы.
stripУдалить символы отладки из файлов ELF (если
#:strip-binaries?не является ложным), скопировав их в выходные данныеdebug, если они доступны (see Установка файлов отладки).validate-runpathValidate the
RUNPATHof ELF binaries, unless#:validate-runpath?is false (see Системы сборки).This validation step consists in making sure that all the shared libraries needed by an ELF binary, which are listed as
DT_NEEDEDentries in itsPT_DYNAMICsegment, appear in theDT_RUNPATHentry of that binary. In other words, it ensures that running or using those binaries will not result in a “file not found” error at run time. See -rpath in The GNU Linker, for more information onRUNPATH.
Как обсуждалось в предыдущем разделе, эти системы сборки предоставляют
стандартный список фаз. Для gnu-build-system стандартные фазы
включают фазу unpack для распаковки архива исходного кода, фазу
configure для запуска ./configure, build фаза для
запуска make и (среди прочего) фазу install для запуска
make install; see Системы сборки, чтобы получить более
подробное представление об этих фазах. Точно так же
cmake-build-system наследует эти фазы, но его фаза configure
запускает cmake вместо ./configure. Другие системы
сборки, такие как python-build-system, имеют совершенно другой список
стандартных фаз. Весь этот код выполняется на build side: он
выполняется, когда вы фактически собираете пакет, в отдельном процессе
сборки, порожденном демоном сборки (see Вызов guix-daemon).
Этапы сборки представлены в виде ассоциативных списков или “alists” (see Association Lists in GNU Guile Reference Manual), где каждый ключ является символом имени фазы, а соответствующее значение - процедурой, которая принимает произвольное количество аргументов. По соглашению эти процедуры получают информацию о сборке в виде ключевых параметров, которые они могут использовать или игнорировать.
Например, вот как (guix build gnu-build-system) определяет
%standard-phase, переменную, содержащую список фаз сборки
21:
;; The build phases of 'gnu-build-system'. (define* (unpack #:key source #:allow-other-keys) ;; Extract the source tarball. (invoke "tar" "xvf" source)) (define* (configure #:key outputs #:allow-other-keys) ;; Run the 'configure' script. Install to output "out". (let ((out (assoc-ref outputs "out"))) (invoke "./configure" (string-append "--prefix=" out)))) (define* (build #:allow-other-keys) ;; Compile. (invoke "make")) (define* (check #:key (test-target "check") (tests? #true) #:allow-other-keys) ;; Run the test suite. (if tests? (invoke "make" test-target) (display "test suite not run\n"))) (define* (install #:allow-other-keys) ;; Install files to the prefix 'configure' specified. (invoke "make" "install")) (define %standard-phases ;; The list of standard phases (quite a few are omitted ;; for brevity). Each element is a symbol/procedure pair. (list (cons 'unpack unpack) (cons 'configure configure) (cons 'build build) (cons 'check check) (cons 'install install)))
Это показывает, как %standard-phase определяется как список пар
символ/процедура (see Pairs in GNU Guile Reference Manual).
Первая пара связывает процедуру unpack с символом
unpack—именем; вторая пара аналогичным образом определяет фазу
configure и так далее. При сборке пакета, который использует
gnu-build-system со списком фаз по умолчанию, эти фазы выполняются
последовательно. Вы можете увидеть название каждой фазы, запущенной и
завершенной, в журнале сборки пакетов, которые вы собираете.
Теперь посмотрим на сами процедуры. Каждая из них определяется с помощью
define*: #:key перечисляет параметры ключевого слова, которые
принимает процедура, возможно, со значением по умолчанию, а
#:allow-other-keys указывает, что другие параметры ключевого слова
являются игнорируется (see Optional Arguments in GNU Guile
Reference Manual).
Процедура unpack учитывает параметр source, который система
сборки использует для передачи имени файла исходного архива (или checkout
контроля версий), и игнорирует другие параметры. Фаза configure
касается только параметра output, списка имен выходных пакетов,
отображающих имена файлов хранилища (see Пакеты со множественным выходом). Она извлекает имя файла для out, вывода по умолчанию, и
передает его ./configure в качестве префикса установки, что
означает, что make install в конечном итоге скопирует все файлы в
этом каталоге (see configuration and makefile
conventions in GNU Coding Standards). build и
install игнорируют все свои аргументы. check учитывает
аргумент test-target, который указывает имя цели Makefile для запуска
тестов; она печатает сообщение и пропускает тесты, если tests? ложно.
Список фаз, используемых для конкретного пакета, можно изменить с помощью
параметра #:phase системы сборки. Изменение набора фаз сборки
сводится к созданию нового списка фаз на основе списка
%standard-phase, описанного выше. Это можно сделать с помощью
стандартных процедур списков, таких как alist-delete (see SRFI-1
Association Lists in GNU Guile Reference Manual); однако это удобнее
делать с помощью modify-phase (see modify-phases).
Вот пример определения пакета, который удаляет фазу configure из
%standard-phase и вставляет новую фазу перед фазой build,
которая называется set-prefix-in- makefile:
(define-public example
(package
(name "example")
;; other fields omitted
(build-system gnu-build-system)
(arguments
'(#:phases (modify-phases %standard-phases
(delete 'configure)
(add-before 'build 'set-prefix-in-makefile
(lambda* (#:key outputs #:allow-other-keys)
;; Modify the makefile so that its
;; 'PREFIX' variable points to "out".
(let ((out (assoc-ref outputs "out")))
(substitute* "Makefile"
(("PREFIX =.*")
(string-append "PREFIX = "
out "\n")))))))))))
Новая вставляемая фаза записывается как анонимная процедура, представленная
с помощью lambda*; она учитывает параметр output, который мы
видели ранее. See Build Utilities, чтобы узнать больше о помощниках,
используемых в этой фазе, и получить больше примеров modify-phase.
Имейте в виду, что фазы сборки - это код, выполняемый во время фактической
сборки пакета. Это объясняет, почему приведенное выше выражение
modify-phase целиком (оно идет после ' или апострофа): это
staged для последующего выполнения. See G-Expressions для
объяснения staging кода и задействованных code strata.
Next: Search Paths, Previous: Фазы сборки, Up: Программный интерфейс [Contents][Index]
9.7 Build Utilities
Как только вы начнете писать нетривиальные определения пакетов
(see Описание пакетов) или другие действия сборки
(see G-Expressions), вы, скорее всего, начнете искать помощников для
действий, подобных оболочке—создание каталогов, рекурсивное копирование и
удаление файлов, управление этапами сборки и т.д. Модуль (guix build
utils) предоставляет такие служебные процедуры.
Большинство систем сборки загружают (guix build utils) (see Системы сборки). Таким образом, при написании настраиваемых фаз сборки для
определений пакетов вы обычно можете предположить, что эти процедуры входят
в область действия.
При написании G-выражений вы можете импортировать (guix build utils)
на “стороне сборки”, используя with-import-modules, а затем
поместить его в область видимости с помощью формы use-modules
(see Using Guile Modules in GNU Guile Reference Manual):
(with-imported-modules '((guix build utils)) ;import it
(computed-file "empty-tree"
#~(begin
;; Put it in scope.
(use-modules (guix build utils))
;; Happily use its 'mkdir-p' procedure.
(mkdir-p (string-append #$output "/a/b/c")))))
Оставшаяся часть этого раздела является справочником по большинству
служебных процедур, предоставляемых (guix build utils).
- Работа с именами файлов в store
- Файловые системы
- Управление файлами
- Файловые системы
- Program Invocation
- Фазы сборки
- Wrappers
9.7.1 Работа с именами файлов в store
В этом разделе описаны процедуры, относящиеся к именам файлов в store.
- Процедура Scheme: sane-service-type
Проверить целостность склада.
- Scheme Procedure: file-union name files
Возвращает true, если объект obj — это пакет ранней версии.
- Scheme Procedure: file-union name files
Удалиnm /gnu/store и хэш из file, имени файла в store. Результатом обычно является строка
"package-version".
- Процедура Scheme: inferior-package-version package
Учитывая name, имя пакета, такое как
"foo-0.9.1b", возвращает два значения:"foo"и"0.9.1b". Если часть версии недоступна, возвращаются name и#f. Считается, что первый дефис, за которым следует цифра, обозначает часть версии.
9.7.2 Файловые системы
Процедуры, приведённые ниже, обеспечивают работу и управление ранними версиями пакетов.
- Scheme Procedure: directory-union name things
Вернуть
#t, если dir существует и является каталогом.
- Scheme Procedure: file-union name files
Вернуть
#t, если file существует и исполняемый файл.
- Scheme Procedure: file-union name files
Вернуть
#t, если file является символической ссылкой (также известной как “символическая ссылка”).
- Scheme Procedure: file-union name files
- Scheme Procedure: file-union name files
- Scheme Procedure: file-union name files
Вернуть
#t, если file является, соответственно, файлом ELF, архивомar(например, статической библиотекой .a) или файлом gzip.
- Процедура Scheme: inferior-package-inputs package
Если file является файлом gzip, сбросить его timestamp (как в случае
gzip --no-name) и вернуть истину. В противном случае вернуть#f. Когда keep-mtime? истинна, сохранить время модификации file.
9.7.3 Управление файлами
Следующие процедуры и макросы помогают создавать, изменять и удалять файлы.
Они обеспечивают функциональность, сопоставимую с такими обычными утилитами
оболочки, как mkdir -p, cp -r, rm -r и
sed. Они дополняют обширный, но низкоуровневый интерфейс файловой
системы Guile (see POSIX in GNU Guile Reference Manual).
- Scheme Syntax: let-system system body…
Запустить body с directory в качестве текущего каталога процесса.
По сути, этот макрос изменяет текущий каталог на directory перед вычислением body, используя
chdir(see Processes in GNU Guile Reference Manual). Она возвращается в исходный каталог, когда остается динамический extent body, будь то через возврат нормальной процедуры или через нелокальный выход, такой как исключение.
- Процедура Scheme: inferior-packages inferior
Создать каталог dir и всех его предков.
- Процедура Scheme: open-inferior directory Создать каталог, если он не существует, и скопировать туда file
под тем же именем.
- Scheme Procedure: file-union name files
Сделать file доступным для записи его владельцу.
- Scheme Procedure: lookup-inferior-packages inferior name [#:log (current-output-port)] [#:follow-symlinks? #f] [#:copy-file
copy-file] [#:keep-mtime? #f] [#:keep-permissions? #t] Copy source directory to destination. Follow symlinks if follow-symlinks? is true; otherwise, just preserve them. Call copy-file to copy regular files. When keep-mtime? is true, keep the modification time of the files in source on those of destination. When keep-permissions? is true, preserve file permissions. Write verbose output to the log port.
- Процедура Scheme: open-inferior directory [#:follow-mounts? #f] dir рекурсивно, как
rm -rf, без использования символических ссылок. Также не следовать точкам монтирования, если follow-mounts? не истинна. Сообщать об ошибках, но игнорировать их.
- Scheme Syntax: let-system system body…
((regexp match-var…) body…) … Заменить regexp в file строкой, возвращаемой body. body вычисляется с каждой привязкой match-var к соответствующему подвыражению позиционного регулярного выражения. Например:
(substitute* file (("hello") "good morning\n") (("foo([a-z]+)bar(.*)$" all letters end) (string-append "baz" letters end)))Здесь, когда строка file содержит
hello, она заменяется наgood morning. Каждый раз, когда строка file соответствует второму регулярному выражению,allпривязывается к полному совпадению,lettersпривязано к первому подвыражению, аendпривязано к последнему.Когда одно из match-var -
_, никакая переменная не связана с соответствующей подстрокой соответствия.В качестве альтернативы file может быть списком имен файлов, и в этом случае все они могут быть заменены.
В качестве альтернативы file может быть списком имен файлов, и в этом случае все они могут быть заменены.
9.7.4 Файловые системы
В этом разделе описаны процедуры поиска и фильтрации файлов.
- Процедура Scheme: inferior-package? obj
Вернуть предикат, который возвращает истину при передаче имени файла, базовое имя которого совпадает с regexp.
- Процедура Scheme: lookup-inferior-packages inferior name [#:stat lstat] [#:directories? #f] [#:fail-on-error? #f] Возвращает
лексикографически отсортированный список файлов в dir, для которых pred возвращает истину. pred передается два аргумента: абсолютное имя файла и его буфер статистики; предикат по умолчанию всегда возвращает истину. pred также может быть регулярным выражением, в этом случае оно эквивалентно
(file-name-predicate pred). stat используется для получения информации о файле; использованиеlstatозначает, что символические ссылки не соблюдаются. Если directories? истина, то каталоги также будут включены. Если fail-on-error? истина, генерировать исключение при ошибке.
Вот несколько примеров, в которых мы предполагаем, что текущий каталог является корнем дерева исходников Guix:
;; List all the regular files in the current directory. (find-files ".") ⇒ ("./.dir-locals.el" "./.gitignore" …) ;; List all the .scm files under gnu/services. (find-files "gnu/services" "\\.scm$") ⇒ ("gnu/services/admin.scm" "gnu/services/audio.scm" …) ;; List ar files in the current directory. (find-files "." (lambda (file stat) (ar-file? file))) ⇒ ("./libformat.a" "./libstore.a" …)
- Процедура Scheme: inferior-packages inferior
Вернуть полное имя файла для program, как в
$PATH, или#f, если program не найдена.
- Scheme Procedure: search-input-file inputs name
- Scheme Procedure: search-input-directory inputs name
Return the complete file name for name as found in inputs;
search-input-filesearches for a regular file andsearch-input-directorysearches for a directory. If name could not be found, an exception is raised.Here, inputs must be an association list like
inputsandnative-inputsas available to build phases (see Фазы сборки).
Here is a (simplified) example of how search-input-file is used in a
build phase of the wireguard-tools package:
(add-after 'install 'wrap-wg-quick
(lambda* (#:key inputs outputs #:allow-other-keys)
(let ((coreutils (string-append (assoc-ref inputs "coreutils")
"/bin")))
(wrap-program (search-input-file outputs "bin/wg-quick")
#:sh (search-input-file inputs "bin/bash")
`("PATH" ":" prefix ,(list coreutils))))))
9.7.5 Program Invocation
You’ll find handy procedures to spawn processes in this module, essentially
convenient wrappers around Guile’s system* (see system* in GNU Guile Reference Manual).
- Scheme Procedure: invoke program args…
Invoke program with the given args. Raise an
&invoke-errorexception if the exit code is non-zero; otherwise return#t.The advantage compared to
system*is that you do not need to check the return value. This reduces boilerplate in shell-script-like snippets for instance in package build phases.
- Scheme Procedure: invoke-error? c
Return true if c is an
&invoke-errorcondition.
- Scheme Procedure: invoke-error-program c
- Scheme Procedure: invoke-error-arguments c
- Scheme Procedure: invoke-error-exit-status c
- Scheme Procedure: invoke-error-term-signal c
- Scheme Procedure: invoke-error-stop-signal c
Access specific fields of c, an
&invoke-errorcondition.
- Scheme Procedure: report-invoke-error c [port]
Report to port (by default the current error port) about c, an
&invoke-errorcondition, in a human-friendly way.Typical usage would look like this:
(use-modules (srfi srfi-34) ;for 'guard' (guix build utils)) (guard (c ((invoke-error? c) (report-invoke-error c))) (invoke "date" "--imaginary-option")) -| command "date" "--imaginary-option" failed with status 1
- Scheme Procedure: invoke/quiet program args…
Invoke program with args and capture program’s standard output and standard error. If program succeeds, print nothing and return the unspecified value; otherwise, raise a
&messageerror condition that includes the status code and the output of program.Here’s an example:
(use-modules (srfi srfi-34) ;for 'guard' (srfi srfi-35) ;for 'message-condition?' (guix build utils)) (guard (c ((message-condition? c) (display (condition-message c)))) (invoke/quiet "date") ;all is fine (invoke/quiet "date" "--imaginary-option")) -| 'date --imaginary-option' exited with status 1; output follows: date: unrecognized option '--imaginary-option' Try 'date --help' for more information.
9.7.6 Фазы сборки
(guix build utils) также содержит инструменты для управления фазами
сборки, которые используются системами сборки (see Системы сборки). Фазы
сборки представлены в виде ассоциативных списков или “alists”
(see Association Lists in GNU Guile Reference Manual), где каждый
ключ представляет собой символ, обозначающий фазу, а связанное значение
представляет собой процедуру (see Фазы сборки).
Ядро Guile и модуль (srfi srfi-1) предоставляют инструменты для
управления списками. Модуль (guix build utils) дополняет их
инструментами, написанными с учетом фаз сборки.
- Scheme Syntax: let-system system body…
Изменить phases последовательно в соответствии с каждым clause, которое может иметь одну из следующих форм:
(delete old-phase-name) (replace old-phase-name new-phase) (add-before old-phase-name new-phase-name new-phase) (add-after old-phase-name new-phase-name new-phase)
Где каждая phase-name выше - это выражение, преобразующееся в символ, а new-phase - выражение, преобразующееся в процедуру.
Пример ниже взят из определения пакета grep. Он добавляет фазу для
запуска после фазы install, которая называется
fix-egrep-and-fgrep. Эта фаза представляет собой процедуру
(lambda* обозначает анонимную процедуру), которая принимает аргумент
ключевого слова #:output и игнорирует дополнительные аргументы
ключевого слова (see Optional Arguments in GNU Guile Reference
Manual, for more on lambda* and optional and keyword arguments.) В
фазе используется substitute* для изменения установленных сценариев
egrep и fgrep, чтобы они ссылались на grep по
абсолютному имени файла:
(modify-phases %standard-phases
(add-after 'install 'fix-egrep-and-fgrep
;; Patch 'egrep' and 'fgrep' to execute 'grep' via its
;; absolute file name instead of searching for it in $PATH.
(lambda* (#:key outputs #:allow-other-keys)
(let* ((out (assoc-ref outputs "out"))
(bin (string-append out "/bin")))
(substitute* (list (string-append bin "/egrep")
(string-append bin "/fgrep"))
(("^exec grep")
(string-append "exec " bin "/grep")))))))
В приведенном ниже примере фазы изменяются двумя способами: стандартная фаза
configure удаляется, предположительно потому, что в пакете нет
сценария configure или чего-то подобного, и фаза install по
умолчанию заменяется файлом, который вручную копирует устанавливаемые
исполняемые файлы:
(modify-phases %standard-phases
(delete 'configure) ;no 'configure' script
(replace 'install
(lambda* (#:key outputs #:allow-other-keys)
;; The package's Makefile doesn't provide an "install"
;; rule so do it by ourselves.
(let ((bin (string-append (assoc-ref outputs "out")
"/bin")))
(install-file "footswitch" bin)
(install-file "scythe" bin)))))
9.7.7 Wrappers
It is not unusual for a command to require certain environment variables to be set for proper functioning, typically search paths (see Search Paths). Failing to do that, the command might fail to find files or other commands it relies on, or it might pick the “wrong” ones—depending on the environment in which it runs. Examples include:
- a shell script that assumes all the commands it uses are in
PATH; - a Guile program that assumes all its modules are in
GUILE_LOAD_PATHandGUILE_LOAD_COMPILED_PATH; - a Qt application that expects to find certain plugins in
QT_PLUGIN_PATH.
For a package writer, the goal is to make sure commands always work the same
rather than depend on some external settings. One way to achieve that is to
wrap commands in a thin script that sets those environment variables,
thereby ensuring that those run-time dependencies are always found. The
wrapper would be used to set PATH, GUILE_LOAD_PATH, or
QT_PLUGIN_PATH in the examples above.
To ease that task, the (guix build utils) module provides a couple of
helpers to wrap commands.
- Scheme Procedure: wrap-program program [#:sh sh] [#:rest variables] Make a wrapper for program.
variables should look like this:
'(variable delimiter position list-of-directories)
where delimiter is optional.
:will be used if delimiter is not given.For example, this call:
(wrap-program "foo" '("PATH" ":" = ("/gnu/.../bar/bin")) '("CERT_PATH" suffix ("/gnu/.../baz/certs" "/qux/certs")))will copy foo to .foo-real and create the file foo with the following contents:
#!location/of/bin/bash export PATH="/gnu/.../bar/bin" export CERT_PATH="$CERT_PATH${CERT_PATH:+:}/gnu/.../baz/certs:/qux/certs" exec -a $0 location/of/.foo-real "$@"If program has previously been wrapped by
wrap-program, the wrapper is extended with definitions for variables. If it is not, sh will be used as the interpreter.
- Scheme Procedure: wrap-script program [#:guile guile] [#:rest variables] Wrap the script program
such that variables are set first. The format of variables is the same as in the
wrap-programprocedure. This procedure differs fromwrap-programin that it does not create a separate shell script. Instead, program is modified directly by prepending a Guile script, which is interpreted as a comment in the script’s language.Special encoding comments as supported by Python are recreated on the second line.
Note that this procedure can only be used once per file as Guile scripts are not supported.
Next: Хранилище, Previous: Build Utilities, Up: Программный интерфейс [Contents][Index]
9.8 Search Paths
Many programs and libraries look for input data in a search path, a list of directories: shells like Bash look for executables in the command search path, a C compiler looks for .h files in its header search path, the Python interpreter looks for .py files in its search path, the spell checker has a search path for dictionaries, and so on.
Search paths can usually be defined or overridden via environment
variables (see Environment Variables in The GNU C Library Reference
Manual). For example, the search paths mentioned above can be changed by
defining the PATH, C_INCLUDE_PATH, PYTHONPATH (or
GUIX_PYTHONPATH), and DICPATH environment variables—you know,
all these something-PATH variables that you need to get right or things
“won’t be found”.
You may have noticed from the command line that Guix “knows” which search
path environment variables should be defined, and how. When you install
packages in your default profile, the file
~/.guix-profile/etc/profile is created, which you can “source” from
the shell to set those variables. Likewise, if you ask guix shell
to create an environment containing Python and NumPy, a Python library, and
if you pass it the --search-paths option, it will tell you about
PATH and GUIX_PYTHONPATH (see Вызов guix shell):
$ guix shell python python-numpy --pure --search-paths export PATH="/gnu/store/…-profile/bin" export GUIX_PYTHONPATH="/gnu/store/…-profile/lib/python3.9/site-packages"
When you omit --search-paths, it defines these environment variables right away, such that Python can readily find NumPy:
$ guix shell python python-numpy -- python3 Python 3.9.6 (default, Jan 1 1970, 00:00:01) [GCC 10.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import numpy >>> numpy.version.version '1.20.3'
For this to work, the definition of the python package
declares the search path it cares about and its associated
environment variable, GUIX_PYTHONPATH. It looks like this:
(package
(name "python")
(version "3.9.9")
;; some fields omitted...
(native-search-paths
(list (search-path-specification
(variable "GUIX_PYTHONPATH")
(files (list "lib/python/3.9/site-packages"))))))
What this native-search-paths field says is that, when the
python package is used, the GUIX_PYTHONPATH environment
variable must be defined to include all the
lib/python/3.9/site-packages sub-directories encountered in its
environment. (The native- bit means that, if we are in a
cross-compilation environment, only native inputs may be added to the search
path; see search-paths.) In the NumPy example
above, the profile where python appears contains exactly one such
sub-directory, and GUIX_PYTHONPATH is set to that. When there are
several lib/python/3.9/site-packages—this is the case in package
build environments—they are all added to GUIX_PYTHONPATH, separated
by colons (:).
Примечание: Notice that
GUIX_PYTHONPATHis specified as part of the definition of thepythonpackage, and not as part of that ofpython-numpy. This is because this environment variable “belongs” to Python, not NumPy: Python actually reads the value of that variable and honors it.Corollary: if you create a profile that does not contain
python,GUIX_PYTHONPATHwill not be defined, even if it contains packages that provide .py files:$ guix shell python-numpy --search-paths --pure export PATH="/gnu/store/…-profile/bin"This makes a lot of sense if we look at this profile in isolation: no software in this profile would read
GUIX_PYTHONPATH.
Of course, there are many variations on that theme: some packages honor more
than one search path, some use separators other than colon, some accumulate
several directories in their search path, and so on. A more complex example
is the search path of libxml2: the value of the XML_CATALOG_FILES
environment variable is space-separated, it must contain a list of
catalog.xml files (not directories), which are to be found in
xml sub-directories—nothing less. The search path specification
looks like this:
(package
(name "libxml2")
;; some fields omitted
(native-search-paths
(list (search-path-specification
(variable "XML_CATALOG_FILES")
(separator " ")
(files '("xml"))
(file-pattern "^catalog\\.xml$")
(file-type 'regular)))))
Worry not, search path specifications are usually not this tricky.
The (guix search-paths) module defines the data type of search path
specifications and a number of helper procedures. Below is the reference of
search path specifications.
- Data Type: search-path-specification
The data type for search path specifications.
variableThe name of the environment variable for this search path (a string).
filesThe list of sub-directories (strings) that should be added to the search path.
separator(default:":")The string used to separate search path components.
As a special case, a
separatorvalue of#fspecifies a “single-component search path”—in other words, a search path that cannot contain more than one element. This is useful in some cases, such as theSSL_CERT_DIRvariable (honored by OpenSSL, cURL, and a few other packages) or theASPELL_DICT_DIRvariable (honored by the GNU Aspell spell checker), both of which must point to a single directory.file-type(default:'directory)The type of file being matched—
'directoryor'regular, though it can be any symbol returned bystat:type(seestatin GNU Guile Reference Manual).In the libxml2 example above, we would match regular files; in the Python example, we would match directories.
file-pattern(default:#f)This must be either
#for a regular expression specifying files to be matched within the sub-directories specified by thefilesfield.Again, the libxml2 example shows a situation where this is needed.
Some search paths are not tied by a single package but to many packages. To
reduce duplications, some of them are pre-defined in (guix
search-paths).
- Scheme Variable: $SSL_CERT_DIR
- Scheme Variable: $SSL_CERT_FILE
These two search paths indicate where X.509 certificates can be found (see Сертификаты X.509).
These pre-defined search paths can be used as in the following example:
(package
(name "curl")
;; some fields omitted ...
(native-search-paths (list $SSL_CERT_DIR $SSL_CERT_FILE)))
How do you turn search path specifications on one hand and a bunch of
directories on the other hand in a set of environment variable definitions?
That’s the job of evaluate-search-paths.
- Scheme Procedure: evaluate-search-paths search-paths directories [getenv] Evaluate search-paths, a list of
search-path specifications, for directories, a list of directory names, and return a list of specification/value pairs. Use getenv to determine the current settings and report only settings not already effective.
The (guix profiles) provides a higher-level helper procedure,
load-profile, that sets the environment variables of a profile.
Next: Деривации, Previous: Search Paths, Up: Программный интерфейс [Contents][Index]
9.9 Хранилище
Концептуально store - это место, где хранятся успешно построенные derivation’ы - по умолчанию /gnu/store. Подкаталоги в store называются store items или иногда store paths. У store есть связанная база данных, которая содержит такую информацию, как store paths, на которые ссылается каждый store path, и список валидных store item’ов—результаты успешных сборок. Эта база данных находится в localstatedir/guix/db, где localstatedir - это каталог состояний, указанный через --localstatedir во время configure, обычно /var.
Демон всегда обращается к store от имени своих клиентов
(see Вызов guix-daemon). Чтобы управлять store, клиенты подключаются
к демону через сокет домена Unix, отправляют ему запросы и читают результат
- это вызовы удаленных процедур или RPC.
Примечание: Пользователи должны никогда напрямую изменять файлы в /gnu/store. Это приведет к несоответствиям и нарушит предположения о неизменности функциональной модели Guix (see Введение).
See
guix gc --verify, для получения информации о том, как проверить целостность store и попытаться восстановить его после случайных изменений.
Модуль (guix store) предоставляет процедуры для подключения к демону
и выполнения RPC. Они описаны ниже. По умолчанию open-connection и,
следовательно, все команды guix подключаются к локальному демону
или к URI, указанному в переменной среды GUIX_DAEMON_SOCKET.
- Environment Variable: GUIX_DAEMON_SOCKET
Если установлено, значение этой переменной должно быть именем файла или URI, обозначающим конечную точку демона. Когда это имя файла, оно обозначает сокет домена Unix, к которому нужно подключиться. Помимо имен файлов, поддерживаются следующие схемы URI:
fileunixЭто для сокетов домена Unix.
file:///var/guix/daemon-socket/socketэквивалентен /var/guix/daemon-socket/socket.guix¶-
Эти URI обозначают соединения через TCP/IP без шифрования и аутентификации удаленного хоста. В URI необходимо указать имя хоста и, возможно, номер порта (по умолчанию используется порт 44146):
guix://master.guix.example.org:1234
Эта настройка подходит для локальных сетей, таких как кластеры, где только доверенные узлы могут подключаться к демону сборки по адресу
master.guix.example.org.Параметр --listen команды
guix-daemonможно использовать для указания ему прослушивать TCP-соединения (see --listen). ssh¶Эти URI позволяют подключаться к удаленному демону через SSH. Для этой функции требуется Guile-SSH (see Требования) и рабочий
guilebinary файл вPATHна конечном компьютере. Он поддерживает открытый ключ и аутентификацию GSSAPI. Типичный URL-адрес может выглядеть так:ssh://charlie@guix.example.org:22
Что касается
guix copy, учитываются обычные файлы конфигурации клиента OpenSSH (see Вызовguix copy).
В будущем могут поддерживаться дополнительные схемы URI.
Примечание: Возможность подключения к демонам удаленной сборки считается экспериментальной с 1.4.0. Пожалуйста, свяжитесь с нами, чтобы поделиться любыми проблемами или предложениями, которые могут у вас возникнуть (see Содействие).
- Scheme Procedure: open-connection [uri] [#:reserve-space? #t]
Подключится к демону через сокет домена Unix по адресу uri (строка). Когда reserve-space? истинна, указать ему, чтобы он зарезервировал немного дополнительного места в файловой системе, чтобы сборщик мусора мог работать, если диск заполнится. Вернуть объект сервера.
file по умолчанию -
%default-socket-path, что является обычным расположением с учетом параметров, переданных вconfigure.
- Scheme Procedure: close-connection server
Закрыть соединение с server.
- Scheme Variable: current-build-output-port
Эта переменная привязана к параметру SRFI-39, который относится к порту, на который должны быть записаны журналы сборки и ошибок, отправляемые демоном.
Процедуры, которые заставляют все RPC принимать объект сервера в качестве своего первого аргумента.
- Scheme Procedure: valid-path? server path
-
Возвращать
#t, когда path обозначает допустимый элемент хранилища, и#fв противном случае (недопустимый элемент может существовать на диске, но по-прежнему быть недопустимым, например, потому что он является результатом прерывания или неудачной сборки).Условие
&store-protocol-errorвозникает, если path не имеет префикса в каталоге store (/gnu/store).
- Scheme Procedure: add-text-to-store server name text [references]
Добавить text в файл name в store и вернуть его store path. references - это список store path’ы, на которые ссылается конечный store path.
- Scheme Procedure: lookup-inferior-packages inferior name [mode] Собрать derivations, список объектов
<derivation>, имен файлов .drv или пар derivation/output, используя указанный mode—
(build-mode normal)по умолчанию.
Обратите внимание, что модуль (guix monads) предоставляет как монаду,
так и монадические версии вышеупомянутых процедур с целью сделать более
удобной работу с кодом, который обращается к store (see Устройство склада).
Этот раздел в настоящее время не завершен.
Next: Устройство склада, Previous: Хранилище, Up: Программный интерфейс [Contents][Index]
9.10 Деривации
Действия низкоуровневой сборки и среда, в которой они выполняются, представлены через derivations. Derivation содержит следующую информацию:
- The outputs of the derivation—derivations создают по крайней мере один файл или каталог в store, но могут создавать и больше.
- Входные данные производных—то есть его build-time зависимости - которые могут быть другими derivation’ами или простыми файлами в store (патчи, скрипты сборки и т.д.).
- Тип системы, на который нацелена derivation - например,
x86_64-linux. - Имя файла скрипта сборки в store вместе с передаваемыми аргументами.
- Список переменных среды, которые необходимо определить.
Derivation’ы позволяют клиентам демона передавать действия сборки в store.
Они существуют в двух формах: как представление в памяти, как на стороне
клиента, так и на стороне демона, и в виде файлов в хранилище, имена которых
заканчиваются на .drv - эти файлы называются derivation paths.
Derivation paths могут быть переданы в процедуру build-derivations
для выполнения действий сборки, которые они предписывают (see Хранилище).
Такие операции, как загрузка файлов и проверка версий, для которых заранее известен ожидаемый хэш содержимого, моделируются как fixed-output derivations. В отличие от обычных дериваций, выходные данные деривации с фиксированным выходом не зависят от его входных данных - например, загрузка исходного кода дает тот же результат независимо от метода загрузки и используемых инструментов.
Outputs of derivations—то есть результаты сборки—имеют множество
references, в соответствии с указаниями RPC references или
команды guix gc --references (see Вызов guix gc).
References - это набор run-time зависимостей результатов сборки. References
- это подмножество входных данных derivation; это подмножество автоматически
вычисляется демоном сборки путем сканирования всех файлов в выходных данных.
Модуль (guix diverations) предоставляет представление derivation’ов в
виде Scheme объектов, а также процедуры для создания derivation’ов и других
манипуляций с ними. Самым низкоуровневым примитивом для создания
derivation’а является процедура derivation:
- Scheme Procedure: derivation store name builder args [#:outputs '(\"out\")] [#:hash #f] [#:hash-algo #f] [#:recursive? #f] [#:inputs '()] [#:env-vars '()] [#:system
(%current-system)] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:leaked-env-vars #f] [#:local-build? #f] [#:substitutable? #t] [#:properties ’()] Собрать производную с заданными аргументами и вернуть полученный объект
<derivation>.Когда заданы hash и hash-algo, создается fixed-output derivation - то есть результат, который известен заранее, например, загрузка файла. Кроме того, если recursive? истинна, то этот фиксированный вывод может быть исполняемым файлом или каталогом, а hash должен быть хешем архива, содержащего этот вывод.
Когда links-graphs истинна, данная переменная должна быть списком из пар имя файла и путь к store. В этом случае граф ссылок каждого store path экспортируется в среду сборки в соответствующий файл в простом текстовом формате.
Когда allowed-links истинна, данная переменная должна быть списком store item’ов или выходных данных, на которые может ссылаться выход derivation’а. Аналогично, disallowed-links, если она истинна, данная переменная должна быть списком сущностей, на которые не могут ссылаться выходные данные.
Когда leaked-env-vars истинна, данная переменная должна быть списком строк, обозначающих переменные среды, которым разрешено “просачиваться” из среды демона в среду сборки. Это применимо только к fixed-output derivation’ам, т.е. когда hash истинна. Основное использование - разрешить передачу таких переменных, как
http_proxy, derivation’ам, которые загружают файлы.Когда local-build? истинна, объявить, что производная не является хорошим кандидатом для offload и должна быть собрана локально (see Использование функционала разгрузки). Это справедливо для небольших derivation’ов, когда затраты на передачу данных перевешивают выгоды.
Когда substitutable? ложно, объявить, что substitutes derivation’ов не должны использоваться (see Подстановки). Это полезно, например, при создании пакетов, которые фиксируют подробности набора команд центрального процессора.
properties должна быть списком ассоциаций, описывающих “свойства” derivation’а. При выводе они сохраняются как есть, без интерпретации.
Вот пример со shell скриптом в качестве его builder’а, предполагая, что store является открытым соединением с демоном, а bash указывает на исполняемый файл Bash в store:
(use-modules (guix utils) (guix store) (guix derivations)) (let ((builder ; add the Bash script to the store (add-text-to-store store "my-builder.sh" "echo hello world > $out\n" '()))) (derivation store "foo" bash `("-e" ,builder) #:inputs `((,bash) (,builder)) #:env-vars '(("HOME" . "/homeless")))) ⇒ #<derivation /gnu/store/…-foo.drv => /gnu/store/…-foo>
Как можно догадаться, этот примитив неудобно использовать напрямую.
Конечно, лучший подход - писать скрипты сборки на Scheme! Лучше всего для
этого написать код сборки как “G-выражение” и передать его в
gexp->derivation. Для получения дополнительной информации,
see G-Expressions.
Когда-то давно gexp->derivation не существовала, и построение
derivation’ов с помощью кода сборки, написанного на Scheme, достигалось с
помощью build-expression->derivation, описанной ниже. Эта процедура
теперь устарела и заменена более приятным gexp->derivation.
- Scheme Procedure: build-expression->derivation store name exp [#:system (%current-system)] [#:inputs '()] [#:outputs '(\"out\")] [#:hash #f] [#:hash-algo #f] [#:recursive? #f]
[#:env-vars ’()] [#:modules ’()] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:local-build? #f] [#:substitutable? #t] [#:guile-for-build #f] Возвращает derivation, которая исполняет Scheme выражение exp как builder для derivation’а name. inputs должна быть списком кортежей
(name drv-path sub-drv); когда sub-drv опущена, предполагается"out". modules - это список имен модулей Guile из текущего пути поиска, которые будут скопированы в store, скомпилированы и станут доступными в пути загрузки во время выполнения exp—например,((guix build utils) (guix build gnu-build-system)).exp выполняется в среде, где
%outputпривязан к списку пар output/path, а где%build-inputsпривязан к списку пар строка/output-path сделаными из input. Необязательно, env-vars - это список пар строк, определяющих имя и значение переменных среды, видимых builder’у. Builder завершает работу, передавая результат exp вexit; таким образом, когда exp возвращает#f, сборка считается неудачной.exp собирается с использованием guile-for-build (derivation). Когда guile-for-build опущена или равна
#f, вместо этого используется значение fluid’а%guile-for-build.См. в процедуре
derivationзначение references-graphs, allowed-references, disallowed-references, local-build? и substitutable?.
Вот пример single-output derivation’а, которая создает каталог, содержащий один файл:
(let ((builder '(let ((out (assoc-ref %outputs "out"))) (mkdir out) ; create /gnu/store/…-goo (call-with-output-file (string-append out "/test") (lambda (p) (display '(hello guix) p)))))) (build-expression->derivation store "goo" builder)) ⇒ #<derivation /gnu/store/…-goo.drv => …>
Next: G-Expressions, Previous: Деривации, Up: Программный интерфейс [Contents][Index]
9.11 Устройство склада
Все процедуры, которые работают с store, описанные в предыдущих разделах, принимают открытое соединение с демоном сборки в качестве первого аргумента. Хотя основная модель является функциональной, они либо имеют побочные эффекты, либо зависят от текущего состояния store.
Первое неудобно: соединение с демоном сборки должно поддерживаться во всех этих функциях, что делает невозможным составление функций, которые не принимают этот параметр, с функциями, которые его принимают. Последнее может быть проблематичным: поскольку операции store имеют побочные эффекты и/или зависят от внешнего состояния, они должны быть правильно упорядочены.
Здесь на помощь приходит модуль (guix monads). Этот модуль
предоставляет основу для работы с monads и особенно полезную монаду
для наших целей - store monad. Монады - это конструкции, которая
позволяют две вещи: связывать “контекст” со значениями (в нашем случае
контекст - это store) и строить последовательности вычислений (здесь
вычисления включают доступ к store). Значения в монаде—значения, которые
несут этот дополнительный контекст—называются монадическими
значениями; процедуры, возвращающие такие значения, называются
монадическими процедурами.
Рассмотрим эту “нормальную” процедуру:
(define (sh-symlink store)
;; Return a derivation that symlinks the 'bash' executable.
(let* ((drv (package-derivation store bash))
(out (derivation->output-path drv))
(sh (string-append out "/bin/bash")))
(build-expression->derivation store "sh"
`(symlink ,sh %output))))
Используя (guix monads) и (guix gexp), ее можно переписать как
монадическую функцию:
(define (sh-symlink)
;; Same, but return a monadic value.
(mlet %store-monad ((drv (package->derivation bash)))
(gexp->derivation "sh"
#~(symlink (string-append #$drv "/bin/bash")
#$output))))
Во второй версии следует отметить несколько моментов: параметр store
теперь является неявным и является “threaded” в вызовах
package->derivation и gexp->derivation монадические процедуры,
а монадическим значением, возвращаемым package->derivation, является
bound с использованием mlet вместо простого let.
Оказывается, вызов package->derivation можно даже опустить, поскольку
она будет выполняться неявно, как мы увидим позже (see G-Expressions):
(define (sh-symlink)
(gexp->derivation "sh"
#~(symlink (string-append #$bash "/bin/bash")
#$output)))
Вызов монадического sh-symlink ни на что не влияет. Как кто-то
однажды сказал: “Вы выходите из монады, как вы выходите из горящего здания:
by running”. Итак, чтобы выйти из монады и получить желаемый эффект, нужно
использовать run-with-store:
(run-with-store (open-connection) (sh-symlink)) ⇒ /gnu/store/...-sh-symlink
Note that the (guix monad-repl) module extends the Guile REPL with
new “commands” to make it easier to deal with monadic procedures:
run-in-store, and enter-store-monad (see Using Guix Interactively). The former is used to “run” a single monadic value
through the store:
scheme@(guile-user)> ,run-in-store (package->derivation hello) $1 = #<derivation /gnu/store/…-hello-2.9.drv => …>
Последний входит в рекурсивный REPL, где все возвращаемые значения автоматически проходят через хранилище:
scheme@(guile-user)> ,enter-store-monad store-monad@(guile-user) [1]> (package->derivation hello) $2 = #<derivation /gnu/store/…-hello-2.9.drv => …> store-monad@(guile-user) [1]> (text-file "foo" "Hello!") $3 = "/gnu/store/…-foo" store-monad@(guile-user) [1]> ,q scheme@(guile-user)>
Обратите внимание, что немонадические значения не могут быть возвращены в
REPL store-monad.
Other meta-commands are available at the REPL, such as ,build to
build a file-like object (see Using Guix Interactively).
Основные синтаксические формы для работы с монадами в целом предоставляются
модулем (guix monads) и описаны ниже.
- Scheme Syntax: with-monad monad body ...
Evaluate any
>>=orreturnforms in body as being in monad.
- Scheme Syntax: return val
Возвращает монадическое значение, инкапсулирующее val.
- Scheme Syntax: >>= mval mproc ...
Bind monadic value mval, passing its “contents” to monadic procedures mproc…22. There can be one mproc or several of them, as in this example:
(run-with-state (with-monad %state-monad (>>= (return 1) (lambda (x) (return (+ 1 x))) (lambda (x) (return (* 2 x))))) 'some-state) ⇒ 4 ⇒ some-state
- Scheme Syntax: mlet monad ((var mval) ...) body ...
- Scheme Syntax: mlet* monad ((var mval) ...) body ... Bind the variables var to the monadic values
mval in body, which is a sequence of expressions. As with the bind operator, this can be thought of as “unpacking” the raw, non-monadic value “contained” in mval and making var refer to that raw, non-monadic value within the scope of the body. The form (var -> val) binds var to the “normal” value val, as per
let. The binding operations occur in sequence from left to right. The last expression of body must be a monadic expression, and its result will become the result of themletormlet*when run in the monad.mlet*is tomletwhatlet*is tolet(see Local Bindings in GNU Guile Reference Manual).
- Scheme System: mbegin monad mexp ...
Bind mexp and the following monadic expressions in sequence, returning the result of the last expression. Every expression in the sequence must be a monadic expression.
This is akin to
mlet, except that the return values of the monadic expressions are ignored. In that sense, it is analogous tobegin, but applied to monadic expressions.
- Scheme System: mwhen condition mexp0 mexp* ...
When condition is true, evaluate the sequence of monadic expressions mexp0..mexp* as in an
mbegin. When condition is false, return*unspecified*in the current monad. Every expression in the sequence must be a monadic expression.
- Scheme System: munless condition mexp0 mexp* ...
When condition is false, evaluate the sequence of monadic expressions mexp0..mexp* as in an
mbegin. When condition is true, return*unspecified*in the current monad. Every expression in the sequence must be a monadic expression.
The (guix monads) module provides the state monad, which allows
an additional value—the state—to be threaded through monadic
procedure calls.
- Scheme Variable: %state-monad
The state monad. Procedures in the state monad can access and change the state that is threaded.
Consider the example below. The
squareprocedure returns a value in the state monad. It returns the square of its argument, but also increments the current state value:(define (square x) (mlet %state-monad ((count (current-state))) (mbegin %state-monad (set-current-state (+ 1 count)) (return (* x x))))) (run-with-state (sequence %state-monad (map square (iota 3))) 0) ⇒ (0 1 4) ⇒ 3
When “run” through
%state-monad, we obtain that additional state value, which is the number ofsquarecalls.
- Monadic Procedure: current-state
Вернуть текущее состояние в виде монадического значения.
- Monadic Procedure: set-current-state value
Set the current state to value and return the previous state as a monadic value.
- Monadic Procedure: state-push value
Push value to the current state, which is assumed to be a list, and return the previous state as a monadic value.
- Monadic Procedure: state-pop
Pop a value from the current state and return it as a monadic value. The state is assumed to be a list.
- Scheme Procedure: run-with-state mval [state]
Run monadic value mval starting with state as the initial state. Return two values: the resulting value, and the resulting state.
The main interface to the store monad, provided by the (guix store)
module, is as follows.
- Scheme Variable: %store-monad
The store monad—an alias for
%state-monad.Values in the store monad encapsulate accesses to the store. When its effect is needed, a value of the store monad must be “evaluated” by passing it to the
run-with-storeprocedure (see below).
- Scheme Procedure: run-with-store store mval [#:guile-for-build] [#:system (%current-system)]
Run mval, a monadic value in the store monad, in store, an open store connection.
- Monadic Procedure: text-file name text [references]
Return as a monadic value the absolute file name in the store of the file containing text, a string. references is a list of store items that the resulting text file refers to; it defaults to the empty list.
- Monadic Procedure: binary-file name data [references]
Return as a monadic value the absolute file name in the store of the file containing data, a bytevector. references is a list of store items that the resulting binary file refers to; it defaults to the empty list.
- Monadic Procedure: interned-file file [name] [#:recursive? #t] [#:select? (const #t)] Return the name of file once
interned in the store. Use name as its store name, or the basename of file if name is omitted.
When recursive? is true, the contents of file are added recursively; if file designates a flat file and recursive? is true, its contents are added, and its permission bits are kept.
When recursive? is true, call
(select? file stat)for each directory entry, where file is the entry’s absolute file name and stat is the result oflstat; exclude entries for which select? does not return true.The example below adds a file to the store, under two different names:
(run-with-store (open-connection) (mlet %store-monad ((a (interned-file "README")) (b (interned-file "README" "LEGU-MIN"))) (return (list a b)))) ⇒ ("/gnu/store/rwm…-README" "/gnu/store/44i…-LEGU-MIN")
The (guix packages) module exports the following package-related
monadic procedures:
- Monadic Procedure: package-file package [file] [#:system (%current-system)] [#:target #f] [#:output "out"] Return as a
monadic value in the absolute file name of file within the output directory of package. When file is omitted, return the name of the output directory of package. When target is true, use it as a cross-compilation target triplet.
Note that this procedure does not build package. Thus, the result might or might not designate an existing file. We recommend not using this procedure unless you know what you are doing.
- Monadic Procedure: package->derivation package [system]
- Monadic Procedure: package->cross-derivation package target [system] Monadic version of
package-derivationand package-cross-derivation(see Описание пакетов).
Next: Вызов guix repl, Previous: Устройство склада, Up: Программный интерфейс [Contents][Index]
9.12 G-Expressions
So we have “derivations”, which represent a sequence of build actions to
be performed to produce an item in the store (see Деривации). These
build actions are performed when asking the daemon to actually build the
derivations; they are run by the daemon in a container (see Вызов guix-daemon).
It should come as no surprise that we like to write these build actions in
Scheme. When we do that, we end up with two strata of Scheme
code23: the
“host code”—code that defines packages, talks to the daemon, etc.—and
the “build code”—code that actually performs build actions, such as
making directories, invoking make, and so on (see Фазы сборки).
To describe a derivation and its build actions, one typically needs to embed
build code inside host code. It boils down to manipulating build code as
data, and the homoiconicity of Scheme—code has a direct representation as
data—comes in handy for that. But we need more than the normal
quasiquote mechanism in Scheme to construct build expressions.
The (guix gexp) module implements G-expressions, a form of
S-expressions adapted to build expressions. G-expressions, or gexps,
consist essentially of three syntactic forms: gexp, ungexp,
and ungexp-splicing (or simply: #~, #$, and
#$@), which are comparable to quasiquote, unquote, and
unquote-splicing, respectively (see quasiquote in GNU Guile Reference Manual). However, there are
major differences:
- Gexps are meant to be written to a file and run or manipulated by other processes.
- When a high-level object such as a package or derivation is unquoted inside a gexp, the result is as if its output file name had been introduced.
- Gexps carry information about the packages or derivations they refer to, and these dependencies are automatically added as inputs to the build processes that use them.
This mechanism is not limited to package and derivation objects:
compilers able to “lower” other high-level objects to derivations or
files in the store can be defined, such that these objects can also be
inserted into gexps. For example, a useful type of high-level objects that
can be inserted in a gexp is “file-like objects”, which make it easy to
add files to the store and to refer to them in derivations and such (see
local-file and plain-file below).
To illustrate the idea, here is an example of a gexp:
(define build-exp
#~(begin
(mkdir #$output)
(chdir #$output)
(symlink (string-append #$coreutils "/bin/ls")
"list-files")))
This gexp can be passed to gexp->derivation; we obtain a derivation
that builds a directory containing exactly one symlink to
/gnu/store/…-coreutils-8.22/bin/ls:
(gexp->derivation "the-thing" build-exp)
As one would expect, the "/gnu/store/…-coreutils-8.22" string
is substituted to the reference to the coreutils package in the actual
build code, and coreutils is automatically made an input to the
derivation. Likewise, #$output (equivalent to (ungexp
output)) is replaced by a string containing the directory name of the
output of the derivation.
In a cross-compilation context, it is useful to distinguish between
references to the native build of a package—that can run on the
host—versus references to cross builds of a package. To that end, the
#+ plays the same role as #$, but is a reference to a native
package build:
(gexp->derivation "vi"
#~(begin
(mkdir #$output)
(mkdir (string-append #$output "/bin"))
(system* (string-append #+coreutils "/bin/ln")
"-s"
(string-append #$emacs "/bin/emacs")
(string-append #$output "/bin/vi")))
#:target "aarch64-linux-gnu")
In the example above, the native build of coreutils is used, so that
ln can actually run on the host; but then the cross-compiled build
of emacs is referenced.
Another gexp feature is imported modules: sometimes you want to be
able to use certain Guile modules from the “host environment” in the gexp,
so those modules should be imported in the “build environment”. The
with-imported-modules form allows you to express that:
(let ((build (with-imported-modules '((guix build utils))
#~(begin
(use-modules (guix build utils))
(mkdir-p (string-append #$output "/bin"))))))
(gexp->derivation "empty-dir"
#~(begin
#$build
(display "success!\n")
#t)))
In this example, the (guix build utils) module is automatically
pulled into the isolated build environment of our gexp, such that
(use-modules (guix build utils)) works as expected.
Usually you want the closure of the module to be imported—i.e., the
module itself and all the modules it depends on—rather than just the
module; failing to do that, attempts to use the module will fail because of
missing dependent modules. The source-module-closure procedure
computes the closure of a module by looking at its source file headers,
which comes in handy in this case:
(use-modules (guix modules)) ;for 'source-module-closure' (with-imported-modules (source-module-closure '((guix build utils) (gnu build image))) (gexp->derivation "something-with-vms" #~(begin (use-modules (guix build utils) (gnu build image)) …)))
In the same vein, sometimes you want to import not just pure-Scheme modules,
but also “extensions” such as Guile bindings to C libraries or other
“full-blown” packages. Say you need the guile-json package
available on the build side, here’s how you would do it:
(use-modules (gnu packages guile)) ;for 'guile-json' (with-extensions (list guile-json) (gexp->derivation "something-with-json" #~(begin (use-modules (json)) …)))
The syntactic form to construct gexps is summarized below.
- Scheme Syntax: #~exp ¶
- Scheme Syntax: (gexp exp)
Return a G-expression containing exp. exp may contain one or more of the following forms:
#$obj(ungexp obj)Introduce a reference to obj. obj may have one of the supported types, for example a package or a derivation, in which case the
ungexpform is replaced by its output file name—e.g.,"/gnu/store/…-coreutils-8.22.If obj is a list, it is traversed and references to supported objects are substituted similarly.
If obj is another gexp, its contents are inserted and its dependencies are added to those of the containing gexp.
If obj is another kind of object, it is inserted as is.
#$obj:output(ungexp obj output)This is like the form above, but referring explicitly to the output of obj—this is useful when obj produces multiple outputs (see Пакеты со множественным выходом).
#+obj#+obj:output(ungexp-native obj)(ungexp-native obj output)Same as
ungexp, but produces a reference to the native build of obj when used in a cross compilation context.#$output[:output](ungexp output [output])Insert a reference to derivation output output, or to the main output when output is omitted.
This only makes sense for gexps passed to
gexp->derivation.#$@lst(ungexp-splicing lst)Like the above, but splices the contents of lst inside the containing list.
#+@lst(ungexp-native-splicing lst)Like the above, but refers to native builds of the objects listed in lst.
G-expressions created by
gexpor#~are run-time objects of thegexp?type (see below).
- Scheme Syntax: with-imported-modules modules body…
Mark the gexps defined in body… as requiring modules in their execution environment.
Each item in modules can be the name of a module, such as
(guix build utils), or it can be a module name, followed by an arrow, followed by a file-like object:`((guix build utils) (guix gcrypt) ((guix config) => ,(scheme-file "config.scm" #~(define-module …))))
In the example above, the first two modules are taken from the search path, and the last one is created from the given file-like object.
This form has lexical scope: it has an effect on the gexps directly defined in body…, but not on those defined, say, in procedures called from body….
- Scheme Syntax: with-extensions extensions body…
Mark the gexps defined in body… as requiring extensions in their build and execution environment. extensions is typically a list of package objects such as those defined in the
(gnu packages guile)module.Concretely, the packages listed in extensions are added to the load path while compiling imported modules in body…; they are also added to the load path of the gexp returned by body….
- Scheme Procedure: gexp? obj
Return
#tif obj is a G-expression.
G-expressions are meant to be written to disk, either as code building some derivation, or as plain files in the store. The monadic procedures below allow you to do that (see Устройство склада, for more information about monads).
- Monadic Procedure: gexp->derivation name exp [#:system (%current-system)] [#:target #f] [#:graft? #t] [#:hash #f]
[#:hash-algo #f] [#:recursive? #f] [#:env-vars ’()] [#:modules ’()] [#:module-path
%load-path] [#:effective-version "2.2"] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:leaked-env-vars #f] [#:script-name (string-append name "-builder")] [#:deprecation-warnings #f] [#:local-build? #f] [#:substitutable? #t] [#:properties ’()] [#:guile-for-build #f] Return a derivation name that runs exp (a gexp) with guile-for-build (a derivation) on system; exp is stored in a file called script-name. When target is true, it is used as the cross-compilation target triplet for packages referred to by exp.modules is deprecated in favor of
with-imported-modules. Its meaning is to make modules available in the evaluation context of exp; modules is a list of names of Guile modules searched in module-path to be copied in the store, compiled, and made available in the load path during the execution of exp—e.g.,((guix build utils) (guix build gnu-build-system)).effective-version determines the string to use when adding extensions of exp (see
with-extensions) to the search path—e.g.,"2.2".graft? determines whether packages referred to by exp should be grafted when applicable.
When references-graphs is true, it must be a list of tuples of one of the following forms:
(file-name package) (file-name package output) (file-name derivation) (file-name derivation output) (file-name store-item)
The right-hand-side of each element of references-graphs is automatically made an input of the build process of exp. In the build environment, each file-name contains the reference graph of the corresponding item, in a simple text format.
allowed-references must be either
#for a list of output names and packages. In the latter case, the list denotes store items that the result is allowed to refer to. Any reference to another store item will lead to a build error. Similarly for disallowed-references, which can list items that must not be referenced by the outputs.deprecation-warnings determines whether to show deprecation warnings while compiling modules. It can be
#f,#t, or'detailed.The other arguments are as for
derivation(see Деривации).
The local-file, plain-file, computed-file,
program-file, and scheme-file procedures below return
file-like objects. That is, when unquoted in a G-expression, these
objects lead to a file in the store. Consider this G-expression:
#~(system* #$(file-append glibc "/sbin/nscd") "-f" #$(local-file "/tmp/my-nscd.conf"))
The effect here is to “intern” /tmp/my-nscd.conf by copying it to
the store. Once expanded, for instance via gexp->derivation, the
G-expression refers to that copy under /gnu/store; thus, modifying or
removing the file in /tmp does not have any effect on what the
G-expression does. plain-file can be used similarly; it differs in
that the file content is directly passed as a string.
- Scheme Procedure: local-file file [name] [#:recursive? #f] [#:select? (const #t)] Return an object representing local
file file to add to the store; this object can be used in a gexp. If file is a literal string denoting a relative file name, it is looked up relative to the source file where it appears; if file is not a literal string, it is looked up relative to the current working directory at run time. file will be added to the store under name–by default the base name of file.
When recursive? is true, the contents of file are added recursively; if file designates a flat file and recursive? is true, its contents are added, and its permission bits are kept.
When recursive? is true, call
(select? file stat)for each directory entry, where file is the entry’s absolute file name and stat is the result oflstat; exclude entries for which select? does not return true.This is the declarative counterpart of the
interned-filemonadic procedure (seeinterned-file).
- Scheme Procedure: plain-file name content
Return an object representing a text file called name with the given content (a string or a bytevector) to be added to the store.
This is the declarative counterpart of
text-file.
- Scheme Procedure: computed-file name gexp [#:local-build? #t] [#:options '()] Return an object representing the store
item name, a file or directory computed by gexp. When local-build? is true (the default), the derivation is built locally. options is a list of additional arguments to pass to
gexp->derivation.This is the declarative counterpart of
gexp->derivation.
- Monadic Procedure: gexp->script name exp [#:guile (default-guile)] [#:module-path %load-path] [#:system
(%current-system)] [#:target #f] Return an executable script name that runs exp using guile, with exp’s imported modules in its search path. Look up exp’s modules in module-path.
The example below builds a script that simply invokes the
lscommand:(use-modules (guix gexp) (gnu packages base)) (gexp->script "list-files" #~(execl #$(file-append coreutils "/bin/ls") "ls"))
When “running” it through the store (see
run-with-store), we obtain a derivation that produces an executable file /gnu/store/…-list-files along these lines:#!/gnu/store/…-guile-2.0.11/bin/guile -ds !# (execl "/gnu/store/…-coreutils-8.22"/bin/ls" "ls")
- Scheme Procedure: program-file name exp [#:guile #f] [#:module-path %load-path] Return an object representing the
executable store item name that runs gexp. guile is the Guile package used to execute that script. Imported modules of gexp are looked up in module-path.
This is the declarative counterpart of
gexp->script.
- Monadic Procedure: gexp->file name exp [#:set-load-path? #t] [#:module-path %load-path] [#:splice? #f] [#:guile
(default-guile)] Return a derivation that builds a file name containing exp. When splice? is true, exp is considered to be a list of expressions that will be spliced in the resulting file.
When set-load-path? is true, emit code in the resulting file to set
%load-pathand%load-compiled-pathto honor exp’s imported modules. Look up exp’s modules in module-path.The resulting file holds references to all the dependencies of exp or a subset thereof.
- Scheme Procedure: scheme-file name exp [#:splice? #f] [#:set-load-path? #t] Возвращает объект, представляющий
Scheme файл file name содержащий exp.
This is the declarative counterpart of
gexp->file.
- Monadic Procedure: text-file* name text …
Return as a monadic value a derivation that builds a text file containing all of text. text may list, in addition to strings, objects of any type that can be used in a gexp: packages, derivations, local file objects, etc. The resulting store file holds references to all these.
This variant should be preferred over
text-fileanytime the file to create will reference items from the store. This is typically the case when building a configuration file that embeds store file names, like this:(define (profile.sh) ;; Return the name of a shell script in the store that ;; initializes the 'PATH' environment variable. (text-file* "profile.sh" "export PATH=" coreutils "/bin:" grep "/bin:" sed "/bin\n"))In this example, the resulting /gnu/store/…-profile.sh file will reference coreutils, grep, and sed, thereby preventing them from being garbage-collected during its lifetime.
- Scheme Procedure: mixed-text-file name text …
Return an object representing store file name containing text. text is a sequence of strings and file-like objects, as in:
(mixed-text-file "profile" "export PATH=" coreutils "/bin:" grep "/bin")Это декларативный аналог
text-file*.
- Scheme Procedure: file-union name files
Return a
<computed-file>that builds a directory containing all of files. Each item in files must be a two-element list where the first element is the file name to use in the new directory, and the second element is a gexp denoting the target file. Here’s an example:(file-union "etc" `(("hosts" ,(plain-file "hosts" "127.0.0.1 localhost")) (\"bashrc\" ,(plain-file "bashrc" "alias ls='ls --color=auto'"))))This yields an
etcdirectory containing these two files.
- Scheme Procedure: directory-union name things
Return a directory that is the union of things, where things is a list of file-like objects denoting directories. For example:
(directory-union "guile+emacs" (list guile emacs))yields a directory that is the union of the
guileandemacspackages.
- Scheme Procedure: file-append obj suffix …
Return a file-like object that expands to the concatenation of obj and suffix, where obj is a lowerable object and each suffix is a string.
В качестве примера рассмотрим этот gexp:
(gexp->script "run-uname" #~(system* #$(file-append coreutils "/bin/uname")))Такого же эффекта можно добиться с помощью:
(gexp->script "run-uname" #~(system* (string-append #$coreutils "/bin/uname")))There is one difference though: in the
file-appendcase, the resulting script contains the absolute file name as a string, whereas in the second case, the resulting script contains a(string-append …)expression to construct the file name at run time.
- Scheme Syntax: let-system system body…
- Scheme Syntax: let-system (system target) body…
Привязать system к текущей целевой системе—например,
\"x86_64-linux\"—в body.In the second case, additionally bind target to the current cross-compilation target—a GNU triplet such as
"arm-linux-gnueabihf"—or#fif we are not cross-compiling.let-systemis useful in the occasional case where the object spliced into the gexp depends on the target system, as in this example:#~(system* #+(let-system system (cond ((string-prefix? "armhf-" system) (file-append qemu "/bin/qemu-system-arm")) ((string-prefix? "x86_64-" system) (file-append qemu "/bin/qemu-system-x86_64")) (else (error "dunno!")))) "-net" "user" #$image)
- Scheme Syntax: with-parameters ((parameter value) …) exp
This macro is similar to the
parameterizeform for dynamically-bound parameters (see Parameters in GNU Guile Reference Manual). The key difference is that it takes effect when the file-like object returned by exp is lowered to a derivation or store item.A typical use of
with-parametersis to force the system in effect for a given object:(with-parameters ((%current-system "i686-linux")) coreutils)The example above returns an object that corresponds to the i686 build of Coreutils, regardless of the current value of
%current-system.
Of course, in addition to gexps embedded in “host” code, there are also
modules containing build tools. To make it clear that they are meant to be
used in the build stratum, these modules are kept in the (guix build
…) name space.
Internally, high-level objects are lowered, using their compiler, to
either derivations or store items. For instance, lowering a package yields
a derivation, and lowering a plain-file yields a store item. This is
achieved using the lower-object monadic procedure.
- Monadic Procedure: lower-object obj [system] [#:target #f] Return as a value in
%store-monadthe derivation or store item corresponding to obj for system, cross-compiling for target if target is true. obj must be an object that has an associated gexp compiler, such as a
<package>.
- Procedure: gexp->approximate-sexp gexp
Sometimes, it may be useful to convert a G-exp into a S-exp. For example, some linters (see Вызов
guix lint) peek into the build phases of a package to detect potential problems. This conversion can be achieved with this procedure. However, some information can be lost in the process. More specifically, lowerable objects will be silently replaced with some arbitrary object – currently the list(*approximate*), but this may change.
Next: Using Guix Interactively, Previous: G-Expressions, Up: Программный интерфейс [Contents][Index]
9.13 Вызов guix repl
The guix repl command makes it easier to program Guix in Guile by
launching a Guile read-eval-print loop (REPL) for interactive
programming (see Using Guile Interactively in GNU Guile Reference
Manual), or by running Guile scripts (see Running Guile Scripts in GNU Guile Reference Manual). Compared to just launching the
guile command, guix repl guarantees that all the Guix
modules and all its dependencies are available in the search path.
Основной синтаксис:
guix repl options [file args]
When a file argument is provided, file is executed as a Guile scripts:
guix repl my-script.scm
To pass arguments to the script, use -- to prevent them from being
interpreted as arguments to guix repl itself:
guix repl -- my-script.scm --input=foo.txt
To make a script executable directly from the shell, using the guix executable that is on the user’s search path, add the following two lines at the top of the script:
#!/usr/bin/env -S guix repl --!#
Without a file name argument, a Guile REPL is started, allowing for interactive use (see Using Guix Interactively):
$ guix repl scheme@(guile-user)> ,use (gnu packages base) scheme@(guile-user)> coreutils $1 = #<package coreutils@8.29 gnu/packages/base.scm:327 3e28300>
In addition, guix repl implements a simple machine-readable REPL
protocol for use by (guix inferior), a facility to interact with
inferiors, separate processes running a potentially different revision
of Guix.
The available options are as follows:
--type=type-t typeStart a REPL of the given TYPE, which can be one of the following:
guileThis is default, and it spawns a standard full-featured Guile REPL.
компьютерSpawn a REPL that uses the machine-readable protocol. This is the protocol that the
(guix inferior)module speaks.
--listen=endpointBy default,
guix replreads from standard input and writes to standard output. When this option is passed, it will instead listen for connections on endpoint. Here are examples of valid options:--listen=tcp:37146Accept connections on localhost on port 37146.
--listen=unix:/tmp/socketAccept connections on the Unix-domain socket /tmp/socket.
--load-path=directory-L directoryAdd directory to the front of the package module search path (see Пакетные модули).
This allows users to define their own packages and make them visible to the script or REPL.
-qInhibit loading of the ~/.guile file. By default, that configuration file is loaded when spawning a
guileREPL.
Previous: Вызов guix repl, Up: Программный интерфейс [Contents][Index]
9.14 Using Guix Interactively
The guix repl command gives you access to a warm and friendly
read-eval-print loop (REPL) (see Вызов guix repl). If you’re
getting into Guix programming—defining your own packages, writing
manifests, defining services for Guix System or Guix Home, etc.—you will
surely find it convenient to toy with ideas at the REPL.
If you use Emacs, the most convenient way to do that is with Geiser
(see Совершенная установка), but you do not have to use Emacs to enjoy the
REPL. When using guix repl or guile in the terminal,
we recommend using Readline for completion and Colorized to get colorful
output. To do that, you can run:
guix install guile guile-readline guile-colorized
... and then create a .guile file in your home directory containing this:
(use-modules (ice-9 readline) (ice-9 colorized)) (activate-readline) (activate-colorized)
The REPL lets you evaluate Scheme code; you type a Scheme expression at the prompt, and the REPL prints what it evaluates to:
$ guix repl scheme@(guix-user)> (+ 2 3) $1 = 5 scheme@(guix-user)> (string-append "a" "b") $2 = "ab"
It becomes interesting when you start fiddling with Guix at the REPL. The
first thing you’ll want to do is to “import” the (guix) module,
which gives access to the main part of the programming interface, and
perhaps a bunch of useful Guix modules. You could type (use-modules
(guix)), which is valid Scheme code to import a module (see Using Guile
Modules in GNU Guile Reference Manual), but the REPL provides the
use command as a shorthand notation (see REPL Commands in GNU Guile Reference Manual):
scheme@(guix-user)> ,use (guix) scheme@(guix-user)> ,use (gnu packages base)
Notice that REPL commands are introduced by a leading comma. A REPL command
like use is not valid Scheme code; it’s interpreted specially by the
REPL.
Guix extends the Guile REPL with additional commands for convenience. Among
those, the build command comes in handy: it ensures that the given
file-like object is built, building it if needed, and returns its output
file name(s). In the example below, we build the coreutils and
grep packages, as well as a “computed file” (see computed-file), and we use the scandir procedure to list the
files in Grep’s /bin directory:
scheme@(guix-user)> ,build coreutils
$1 = "/gnu/store/…-coreutils-8.32-debug"
$2 = "/gnu/store/…-coreutils-8.32"
scheme@(guix-user)> ,build grep
$3 = "/gnu/store/…-grep-3.6"
scheme@(guix-user)> ,build (computed-file "x" #~(mkdir #$output))
building /gnu/store/…-x.drv...
$4 = "/gnu/store/…-x"
scheme@(guix-user)> ,use(ice-9 ftw)
scheme@(guix-user)> (scandir (string-append $3 "/bin"))
$5 = ("." ".." "egrep" "fgrep" "grep")
At a lower-level, a useful command is lower: it takes a file-like
object and “lowers” it into a derivation (see Деривации) or a store
file:
scheme@(guix-user)> ,lower grep $6 = #<derivation /gnu/store/…-grep-3.6.drv => /gnu/store/…-grep-3.6 7f0e639115f0> scheme@(guix-user)> ,lower (plain-file "x" "Hello!") $7 = "/gnu/store/…-x"
The full list of REPL commands can be seen by typing ,help guix and
is given below for reference.
- REPL command: build object
Lower object and build it if it’s not already built, returning its output file name(s).
- REPL command: lower object
Lower object into a derivation or store file name and return it.
- REPL command: verbosity level
Change build verbosity to level.
This is similar to the --verbosity command-line option (see Стандартные параметры сборки): level 0 means total silence, level 1 shows build events only, and higher levels print build logs.
- REPL command: run-in-store exp
Run exp, a monadic expresssion, through the store monad. See Устройство склада, for more information.
- REPL command: enter-store-monad
Enter a new REPL to evaluate monadic expressions (see Устройство склада). You can quit this “inner” REPL by typing
,q.
Next: Foreign Architectures, Previous: Программный интерфейс, Up: GNU Guix [Contents][Index]
10 Утилиты
В этом разделе описаны утилиты командной строки Guix. Некоторые из них в первую очередь нацелены на разработчиков и пользователей, которые пишут новые определения пакетов, в то время как другие полезны в целом. Они удобно дополняют программный интерфейс Scheme в Guix.
- Запуск
guix build - Вызов
guix edit - Вызов
guix download - Вызов
guix hash - Вызов
guix import - Вызов
guix refresh - Invoking
guix style - Вызов
guix lint - Вызов
guix size - Вызов
guix graph - Вызов
guix publish - Вызов
guix challenge - Вызов
guix copy - Вызов
guix container - Вызов
guix weather - Вызов
guix processes
Next: Вызов guix edit, Up: Утилиты [Contents][Index]
10.1 Запуск guix build
Команда guix build собирает пакеты или производные и их
зависимости и выводит полученные пути в хранилище (store paths). Обратите
внимание, что она не изменяет профиль пользователя—это задача команды
guix package (see Вызов guix package). Таким образом, это в
основном полезно для разработчиков дистрибутива.
Основной синтаксис:
guix build options package-or-derivation…
В качестве примера следующая команда собирает последние версии Emacs и Guile, отображает их логи и, наконец, отображает полученные директории:
guix build emacs guile
Аналогичным образом следующая команда собирает все доступные пакеты:
guix build --quiet --keep-going \
$(guix package -A | awk '{ print $1 "@" $2 }')
package-or-derivation может быть именем пакета, найденного в
дистрибутиве программного обеспечения, например coreutils или
coreutils@8.20, или производным, например
/gnu/store/…-coreutils-8.19.drv. В первом случае пакет с
соответствующим именем (и, возможно, версией) ищется среди модулей
дистрибутива GNU (see Пакетные модули).
В качестве альтернативы можно использовать параметр --expression, чтобы указать выражение на языке Scheme, оценивающее пакет; это полезно, когда требуется устранение неоднозначности между несколькими пакетами с одинаковыми именами или вариантами пакетов.
Может быть ноль или больше options. Доступные параметры описаны в подразделах ниже.
- Стандартные параметры сборки
- Параметры преобразования пакета
- Дополнительные параметры сборки
- Отладка ошибок сборки
Next: Параметры преобразования пакета, Up: Запуск guix build [Contents][Index]
10.1.1 Стандартные параметры сборки
Ряд параметров, управляющих процессом сборки, является общим для
guix build и других команд, которые могут порождать сборки,
например guix package или guix archive. Это следующие:
--load-path=directory-L directoryAdd directory to the front of the package module search path (see Пакетные модули).
Это позволяет пользователям определять свои собственные пакеты и делать их видимыми для инструментов командной строки.
--keep-failed-KСохраните дерево сборки неудачных попыток сборки. Таким образом, в случае сбоя сборки ее дерево сборки сохраняется в /tmp, в каталоге, имя которого отображается в конце журнала сборки. Это полезно при отладке проблем сборки. See Отладка ошибок сборки, советы и рекомендации по отладке проблем сборки.
Этот параметр предполагает --no-offload и не действует при подключении к удалённому демону с URI
guix://(see theGUIX_DAEMON_SOCKET.--keep-going-kПродолжайте, когда некоторые из производных не удается построить; возвращайтесь только после того, как все сборки будут завершены или не пройдены.
Поведение по умолчанию—остановка, как только одна из указанных производных не удалась.
--dry-run-nНе собирайте производные.
--fallbackЕсли замена предварительно созданного двоичного файла не удалась, процесс возвращается к сборке пакетов локально (see Ошибки при подстановке).
--substitute-urls=urlsРассмотрим urls разделенный пробелами список URL-адресов источников замещений, заменяющий список URL-адресов по умолчанию
guix-daemon(seeguix-daemonURLs).Это означает, что заменители могут быть загружены с urls, при условии, что они подписаны ключом, авторизованным системным администратором (see Подстановки).
Когда urls является пустой строкой—замены фактически отключены.
--no-substitutesНе использовать подстановки для сборок. Это означает — собирать элементы локально вместо того, чтобы скачивать собранные бинарники (see Подстановки).
--no-graftsНе “прививайте” (graft) пакеты. На практике это означает, что обновления пакетов, доступные в виде прививок, не применяются. Ознакомьтесь с See Обновления безопасности, чтобы узнать больше о прививках (grafts).
--rounds=nСоберите каждое производное n раз подряд и вызовите появление ошибки, если последовательные результаты построения не будут побитно идентичны.
Это полезный способ обнаружения недетерминированных процессов сборки. Недетерминированные процессы сборки представляют собой проблему, потому что они делают практически невозможным для пользователей verify подлинность сторонних двоичных файлов. Обратитесь к See Вызов
guix challenge, чтобы узнать больше.При использовании вместе с --keep-failed различные результаты сохраняются на складе под /gnu/store/…-check. Это делает возможным просмотр различий между двумя результатами.
--no-offloadНе использовать подстановки для сборок. Это означает — собирать элементы локально вместо того, чтобы скачивать собранные бинарники (see Подстановки).
--max-silent-time=secondsКогда процесс сборки или подстановки молчит более seconds секунд, завершить его и отчитаться об ошибке сборки.
По умолчанию настройки демона соблюдаются (see --max-silent-time).
--timeout=secondsТочно так же, когда процесс сборки или подстановки длится более seconds, завершить его и отчитаться об ошибке сборки.
Это ничего не выводит, если демон не был запущен с опцией --cache-failures (see --cache-failures).
-v level--verbosity=levelИспользуйте заданную степень многословия level (целое число). Выбор 0 означает, что вывод не производится, 1 - для тихого вывода, а 2 показывает весь вывод журнала сборки при стандартной ошибке.
--cores=n-c nРазрешить использование до n ядер ЦП для сборки. Специальное значение
0означает использование максимально доступного количества ядер ЦП.--max-jobs=n-M nРазрешить не более n сборок параллельно. Обратитесь к See --max-jobs для получения подробной информации об этой опции и аналогичной опции
guix-daemon.--debug=levelСоздавать отладочные данные, поступающие от демона сборки. level должен быть целым числом от 0 до 5; чем выше, тем подробнее вывод. Уровнь 4 или выше может быть полезен при отладке проблемы с установкой демона сборки.
За кулисами guix build, по сути, является интерфейсом к процедуре
package-diveration модуля (guix packages) и к процедуре
build-diverations модуля (guix derivations) модуль.
Помимо параметров, явно переданных в командной строке, guix build
и другие команды guix, поддерживающие сборку, учитывают переменную
среды GUIX_BUILD_OPTIONS.
- Environment Variable: GUIX_BUILD_OPTIONS
Пользователи могут определить эту переменную для списка параметров командной строки, которые будут автоматически использоваться
guix buildи другими командамиguix, которые могут выполнять сборки, как в примере ниже:$ export GUIX_BUILD_OPTIONS="--no-substitutes -c 2 -L /foo/bar"
Эти параметры анализируются независимо, а результат добавляется к проанализированным параметрам командной строки.
Next: Дополнительные параметры сборки, Previous: Стандартные параметры сборки, Up: Запуск guix build [Contents][Index]
10.1.2 Параметры преобразования пакета
Другой набор параметров командной строки, поддерживаемых guix
build и guix package это package transformation
options. Это параметры, которые позволяют определять package
variants—например, пакеты, созданные из другого исходного кода. Это
удобный способ создавать индивидуальные пакеты на лету без необходимости
вводить определения вариантов пакета (see Описание пакетов).
Параметры преобразования пакета сохраняются при обновлении: guix
upgrade пытается применить параметры преобразования, которые изначально
использовались при создании профиля, к обновленным пакетам.
Доступные варианты перечислены ниже. Большинство команд поддерживают их, а также поддерживают параметр --help-transform, в котором перечислены все доступные параметры и их крткое описание (эти параметры не показаны в выводе --help для краткости).
--tune[=cpu]Use versions of the packages marked as “tunable” optimized for cpu. When cpu is
native, or when it is omitted, tune for the CPU on which theguixcommand is running.Valid cpu names are those recognized by the underlying compiler, by default the GNU Compiler Collection. On x86_64 processors, this includes CPU names such as
nehalem,haswell, andskylake(see-marchin Using the GNU Compiler Collection (GCC)).As new generations of CPUs come out, they augment the standard instruction set architecture (ISA) with additional instructions, in particular instructions for single-instruction/multiple-data (SIMD) parallel processing. For example, while Core2 and Skylake CPUs both implement the x86_64 ISA, only the latter supports AVX2 SIMD instructions.
The primary gain one can expect from --tune is for programs that can make use of those SIMD capabilities and that do not already have a mechanism to select the right optimized code at run time. Packages that have the
tunable?property set are considered tunable packages by the --tune option; a package definition with the property set looks like this:(package (name "hello-simd") ;; ... ;; This package may benefit from SIMD extensions so ;; mark it as "tunable". (properties '((tunable? . #t))))Other packages are not considered tunable. This allows Guix to use generic binaries in the cases where tuning for a specific CPU is unlikely to provide any gain.
Tuned packages are built with
-march=CPU; under the hood, the -march option is passed to the actual wrapper by a compiler wrapper. Since the build machine may not be able to run code for the target CPU micro-architecture, the test suite is not run when building a tuned package.To reduce rebuilds to the minimum, tuned packages are grafted onto packages that depend on them (see grafts). Thus, using --no-grafts cancels the effect of --tune.
We call this technique package multi-versioning: several variants of tunable packages may be built, one for each CPU variant. It is the coarse-grain counterpart of function multi-versioning as implemented by the GNU tool chain (see Function Multiversioning in Using the GNU Compiler Collection (GCC)).
--with-source=source--with-source=package=source--with-source=package@version=sourceИспользуйте source в качестве источника package и version в качестве номера версии. source должен быть именем файла или URL-адресом, как для
guix download(see Вызовguix download).When package is omitted, it is taken to be the package name specified on the command line that matches the base of source—e.g., if source is
/src/guile-2.0.10.tar.gz, the corresponding package isguile.Likewise, when version is omitted, the version string is inferred from source; in the previous example, it is
2.0.10.This option allows users to try out versions of packages other than the one provided by the distribution. The example below downloads ed-1.7.tar.gz from a GNU mirror and uses that as the source for the
edpackage:guix build ed --with-source=mirror://gnu/ed/ed-1.4.tar.gz
As a developer, --with-source makes it easy to test release candidates, and even to test their impact on packages that depend on them:
guix build elogind --with-source=…/shepherd-0.9.0rc1.tar.gz
… or to build from a checkout in a pristine environment:
$ git clone git://git.sv.gnu.org/guix.git $ guix build guix --with-source=guix@1.0=./guix
--with-input=package=replacementReplace dependency on package by a dependency on replacement. package must be a package name, and replacement must be a package specification such as
guileorguile@1.8.For instance, the following command builds Guix, but replaces its dependency on the current stable version of Guile with a dependency on the legacy version of Guile,
guile@2.0:guix build --with-input=guile=guile@2.0 guix
This is a recursive, deep replacement. So in this example, both
guixand its dependencyguile-json(which also depends onguile) get rebuilt againstguile@2.0.This is implemented using the
package-input-rewritingScheme procedure (seepackage-input-rewriting).--with-graft=package=replacementThis is similar to --with-input but with an important difference: instead of rebuilding the whole dependency chain, replacement is built and then grafted onto the binaries that were initially referring to package. See Обновления безопасности, for more information on grafts.
For example, the command below grafts version 3.5.4 of GnuTLS onto Wget and all its dependencies, replacing references to the version of GnuTLS they currently refer to:
guix build --with-graft=gnutls=gnutls@3.5.4 wget
This has the advantage of being much faster than rebuilding everything. But there is a caveat: it works if and only if package and replacement are strictly compatible—for example, if they provide a library, the application binary interface (ABI) of those libraries must be compatible. If replacement is somehow incompatible with package, then the resulting package may be unusable. Use with care!
--without-tests=packageBuild package in a way that preserves its debugging info and graft it onto packages that depend on it. This is useful if package does not already provide debugging info as a
debugoutput (see Установка файлов отладки).For example, suppose you’re experiencing a crash in Inkscape and would like to see what’s up in GLib, a library deep down in Inkscape’s dependency graph. GLib lacks a
debugoutput, so debugging is tough. Fortunately, you rebuild GLib with debugging info and tack it on Inkscape:guix install inkscape --with-debug-info=glib
Only GLib needs to be recompiled so this takes a reasonable amount of time. See Установка файлов отладки, for more info.
Примечание: Under the hood, this option works by passing the ‘#:strip-binaries? #f’ to the build system of the package of interest (see Системы сборки). Most build systems support that option but some do not. In that case, an error is raised.
Likewise, if a C/C++ package is built without
-g(which is rarely the case), debugging info will remain unavailable even when#:strip-binaries?is false.--with-commit=package=commitThis option changes the compilation of package and everything that depends on it so that they get built with toolchain instead of the default GNU tool chain for C/C++.
Рассмотрим пример:
guix build octave-cli \ --with-c-toolchain=fftw=gcc-toolchain@10 \ --with-c-toolchain=fftwf=gcc-toolchain@10
The command above builds a variant of the
fftwandfftwfpackages using version 10 ofgcc-toolchaininstead of the default tool chain, and then builds a variant of the GNU Octave command-line interface using them. GNU Octave itself is also built withgcc-toolchain@10.This other example builds the Hardware Locality (
hwloc) library and its dependents up tointel-mpi-benchmarkswith the Clang C compiler:guix build --with-c-toolchain=hwloc=clang-toolchain \ intel-mpi-benchmarksПримечание: There can be application binary interface (ABI) incompatibilities among tool chains. This is particularly true of the C++ standard library and run-time support libraries such as that of OpenMP. By rebuilding all dependents with the same tool chain, --with-c-toolchain minimizes the risks of incompatibility but cannot entirely eliminate them. Choose package wisely.
--with-git-url=package=url¶-
Build package from the latest commit of the
masterbranch of the Git repository at url. Git sub-modules of the repository are fetched, recursively.For example, the following command builds the NumPy Python library against the latest commit of the master branch of Python itself:
guix build python-numpy \ --with-git-url=python=https://github.com/python/cpython
This option can also be combined with --with-branch or --with-commit (see below).
Obviously, since it uses the latest commit of the given branch, the result of such a command varies over time. Nevertheless it is a convenient way to rebuild entire software stacks against the latest commit of one or more packages. This is particularly useful in the context of continuous integration (CI).
Checkouts are kept in a cache under ~/.cache/guix/checkouts to speed up consecutive accesses to the same repository. You may want to clean it up once in a while to save disk space.
--with-branch=package=branchBuild package from the latest commit of branch. If the
sourcefield of package is an origin with thegit-fetchmethod (seeoriginСправка) or agit-checkoutobject, the repository URL is taken from thatsource. Otherwise you have to use --with-git-url to specify the URL of the Git repository.For instance, the following command builds
guile-sqlite3from the latest commit of itsmasterbranch, and then buildsguix(which depends on it) andcuirass(which depends onguix) against this specificguile-sqlite3build:guix build --with-branch=guile-sqlite3=master cuirass
--with-commit=package=commitThis is similar to --with-branch, except that it builds from commit rather than the tip of a branch. commit must be a valid Git commit SHA1 identifier, a tag, or a
git describestyle identifier such as1.0-3-gabc123.--with-branch=package=branchAdd file to the list of patches applied to package, where package is a spec such as
python@3.8orglibc. file must contain a patch; it is applied with the flags specified in theoriginof package (seeoriginСправка), which by default includes-p1(see patch Directories in Comparing and Merging Files).As an example, the command below rebuilds Coreutils with the GNU C Library (glibc) patched with the given patch:
guix build coreutils --with-patch=glibc=./glibc-frob.patch
In this example, glibc itself as well as everything that leads to Coreutils in the dependency graph is rebuilt.
--without-tests=packageSo you like living on the bleeding edge? This option is for you! It replaces occurrences of package in the dependency graph with its latest upstream version, as reported by
guix refresh(see Вызовguix refresh).It does so by determining the latest upstream release of package (if possible), downloading it, and authenticating it if it comes with an OpenPGP signature.
As an example, the command below builds Guix against the latest version of Guile-JSON:
guix build --with-input=guile=guile@2.0 guix
There are limitations. First, in cases where the tool cannot or does not know how to authenticate source code, you are at risk of running malicious code; a warning is emitted in this case. Second, this option simply changes the source used in the existing package definitions, which is not always sufficient: there might be additional dependencies that need to be added, patches to apply, and more generally the quality assurance work that Guix developers normally do will be missing.
You’ve been warned! In all the other cases, it’s a snappy way to stay on top. We encourage you to submit patches updating the actual package definitions once you have successfully tested an upgrade (see Содействие).
--without-tests=packageBuild package without running its tests. This can be useful in situations where you want to skip the lengthy test suite of a intermediate package, or if a package’s test suite fails in a non-deterministic fashion. It should be used with care because running the test suite is a good way to ensure a package is working as intended.
Turning off tests leads to a different store item. Consequently, when using this option, anything that depends on package must be rebuilt, as in this example:
guix install --without-tests=python python-notebook
The command above installs
python-notebookon top ofpythonbuilt without running its test suite. To do so, it also rebuilds everything that depends onpython, includingpython-notebookitself.Internally, --without-tests relies on changing the
#:tests?option of a package’scheckphase (see Системы сборки). Note that some packages use a customizedcheckphase that does not respect a#:tests? #fsetting. Therefore, --without-tests has no effect on these packages.
Wondering how to achieve the same effect using Scheme code, for example in your manifest, or how to write your own package transformation? See Defining Package Variants, for an overview of the programming interfaces available.
Next: Отладка ошибок сборки, Previous: Параметры преобразования пакета, Up: Запуск guix build [Contents][Index]
10.1.3 Дополнительные параметры сборки
Параметры командной строки, представленные ниже, относятся к guix
build.
--quiet-qBuild quietly, without displaying the build log; this is equivalent to --verbosity=0. Upon completion, the build log is kept in /var (or similar) and can always be retrieved using the --log-file option.
--file=file-f fileBuild the package, derivation, or other file-like object that the code within file evaluates to (see file-like objects).
As an example, file might contain a package definition like this (see Описание пакетов):
(use-modules (guix) (guix build-system gnu) (guix licenses)) (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "http://www.gnu.org/software/hello/") (license gpl3+))
The file may also contain a JSON representation of one or more package definitions. Running
guix build -fon hello.json with the following contents would result in building the packagesmyhelloandgreeter:(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))--manifest=file-m fileBuild all packages listed in the given manifest (see --manifest).
--expression=expr-e exprBuild the package or derivation expr evaluates to.
For example, expr may be
(@ (gnu packages guile) guile-1.8), which unambiguously designates this specific variant of version 1.8 of Guile.Alternatively, expr may be a G-expression, in which case it is used as a build program passed to
gexp->derivation(see G-Expressions).Lastly, expr may refer to a zero-argument monadic procedure (see Устройство склада). The procedure must return a derivation as a monadic value, which is then passed through
run-with-store.--source-SBuild the source derivations of the packages, rather than the packages themselves.
For instance,
guix build -S gccreturns something like /gnu/store/…-gcc-4.7.2.tar.bz2, which is the GCC source tarball.The returned source tarball is the result of applying any patches and code snippets specified in the package
origin(see Описание пакетов).As with other derivations, the result of building a source derivation can be verified using the --check option (see build-check). This is useful to validate that a (potentially already built or substituted, thus cached) package source matches against its declared hash.
Note that
guix build -Scompiles the sources only of the specified packages. They do not include the sources of statically linked dependencies and by themselves are insufficient for reproducing the packages.--sourcesFetch and return the source of package-or-derivation and all their dependencies, recursively. This is a handy way to obtain a local copy of all the source code needed to build packages, allowing you to eventually build them even without network access. It is an extension of the --source option and can accept one of the following optional argument values:
packageThis value causes the --sources option to behave in the same way as the --source option.
allBuild the source derivations of all packages, including any source that might be listed as
inputs. This is the default value.$ guix build --sources tzdata The following derivations will be built: /gnu/store/…-tzdata2015b.tar.gz.drv /gnu/store/…-tzcode2015b.tar.gz.drv
transitiveBuild the source derivations of all packages, as well of all transitive inputs to the packages. This can be used e.g. to prefetch package source for later offline building.
$ guix build --sources=transitive tzdata The following derivations will be built: /gnu/store/…-tzcode2015b.tar.gz.drv /gnu/store/…-findutils-4.4.2.tar.xz.drv /gnu/store/…-grep-2.21.tar.xz.drv /gnu/store/…-coreutils-8.23.tar.xz.drv /gnu/store/…-make-4.1.tar.xz.drv /gnu/store/…-bash-4.3.tar.xz.drv …
--system=system-s systemAttempt to build for system—e.g.,
i686-linux—instead of the system type of the build host. Theguix buildcommand allows you to repeat this option several times, in which case it builds for all the specified systems; other commands ignore extraneous -s options.Примечание: The --system flag is for native compilation and must not be confused with cross-compilation. See --target below for information on cross-compilation.
An example use of this is on Linux-based systems, which can emulate different personalities. For instance, passing --system=i686-linux on an
x86_64-linuxsystem or --system=armhf-linux on anaarch64-linuxsystem allows you to build packages in a complete 32-bit environment.Примечание: Building for an
armhf-linuxsystem is unconditionally enabled onaarch64-linuxmachines, although certain aarch64 chipsets do not allow for this functionality, notably the ThunderX.Similarly, when transparent emulation with QEMU and
binfmt_miscis enabled (seeqemu-binfmt-service-type), you can build for any system for which a QEMUbinfmt_mischandler is installed.Builds for a system other than that of the machine you are using can also be offloaded to a remote machine of the right architecture. See Использование функционала разгрузки, for more information on offloading.
--target=triplet¶Cross-build for triplet, which must be a valid GNU triplet, such as
"aarch64-linux-gnu"(see GNU configuration triplets in Autoconf).--list-systemsList all the supported systems, that can be passed as an argument to --system.
--list-targetsList all the supported targets, that can be passed as an argument to --target.
--check¶-
Rebuild package-or-derivation, which are already available in the store, and raise an error if the build results are not bit-for-bit identical.
This mechanism allows you to check whether previously installed substitutes are genuine (see Подстановки), or whether the build result of a package is deterministic. See Вызов
guix challenge, for more background information and tools.При использовании вместе с --keep-failed различные результаты сохраняются на складе под /gnu/store/…-check. Это делает возможным просмотр различий между двумя результатами.
--repair¶-
Attempt to repair the specified store items, if they are corrupt, by re-downloading or rebuilding them.
This operation is not atomic and thus restricted to
root. --derivations-dReturn the derivation paths, not the output paths, of the given packages.
--root=file¶-r file-
Make file a symlink to the result, and register it as a garbage collector root.
Consequently, the results of this
guix buildinvocation are protected from garbage collection until file is removed. When that option is omitted, build results are eligible for garbage collection as soon as the build completes. See Вызовguix gc, for more on GC roots. --log-file¶Return the build log file names or URLs for the given package-or-derivation, or raise an error if build logs are missing.
This works regardless of how packages or derivations are specified. For instance, the following invocations are equivalent:
guix build --log-file $(guix build -d guile) guix build --log-file $(guix build guile) guix build --log-file guile guix build --log-file -e '(@ (gnu packages guile) guile-2.0)'
If a log is unavailable locally, and unless --no-substitutes is passed, the command looks for a corresponding log on one of the substitute servers (as specified with --substitute-urls).
So for instance, imagine you want to see the build log of GDB on
aarch64, but you are actually on anx86_64machine:$ guix build --log-file gdb -s aarch64-linux https://ci.guix.gnu.org/log/…-gdb-7.10
You can freely access a huge library of build logs!
Previous: Дополнительные параметры сборки, Up: Запуск guix build [Contents][Index]
10.1.4 Отладка ошибок сборки
When defining a new package (see Описание пакетов), you will probably find yourself spending some time debugging and tweaking the build until it succeeds. To do that, you need to operate the build commands yourself in an environment as close as possible to the one the build daemon uses.
To that end, the first thing to do is to use the --keep-failed or
-K option of guix build, which will keep the failed build
tree in /tmp or whatever directory you specified as TMPDIR
(see --keep-failed).
From there on, you can cd to the failed build tree and source the
environment-variables file, which contains all the environment
variable definitions that were in place when the build failed. So let’s say
you’re debugging a build failure in package foo; a typical session
would look like this:
$ guix build foo -K … build fails $ cd /tmp/guix-build-foo.drv-0 $ source ./environment-variables $ cd foo-1.2
Now, you can invoke commands as if you were the daemon (almost) and troubleshoot your build process.
Sometimes it happens that, for example, a package’s tests pass when you run them manually but they fail when the daemon runs them. This can happen because the daemon runs builds in containers where, unlike in our environment above, network access is missing, /bin/sh does not exist, etc. (see Установка окружения сборки).
In such cases, you may need to run inspect the build process from within a container similar to the one the build daemon creates:
$ guix build -K foo … $ cd /tmp/guix-build-foo.drv-0 $ guix shell --no-grafts -C -D foo strace gdb [env]# source ./environment-variables [env]# cd foo-1.2
Here, guix shell -C creates a container and spawns a new shell in
it (see Вызов guix shell). The strace gdb part adds the
strace and gdb commands to the container, which you may
find handy while debugging. The --no-grafts option makes sure we
get the exact same environment, with ungrafted packages (see Обновления безопасности, for more info on grafts).
To get closer to a container like that used by the build daemon, we can remove /bin/sh:
[env]# rm /bin/sh
(Don’t worry, this is harmless: this is all happening in the throw-away
container created by guix shell.)
The strace command is probably not in the search path, but we can
run:
[env]# $GUIX_ENVIRONMENT/bin/strace -f -o log make check
In this way, not only you will have reproduced the environment variables the daemon uses, you will also be running the build process in a container similar to the one the daemon uses.
Next: Вызов guix download, Previous: Запуск guix build, Up: Утилиты [Contents][Index]
10.2 Вызов guix edit
So many packages, so many source files! The guix edit command
facilitates the life of users and packagers by pointing their editor at the
source file containing the definition of the specified packages. For
instance:
guix edit gcc@4.9 vim
launches the program specified in the VISUAL or in the EDITOR
environment variable to view the recipe of GCC 4.9.3 and that of Vim.
If you are using a Guix Git checkout (see Сборка из Git), or have
created your own packages on GUIX_PACKAGE_PATH (see Пакетные модули), you will be able to edit the package recipes. In other cases,
you will be able to examine the read-only recipes for packages currently in
the store.
Instead of GUIX_PACKAGE_PATH, the command-line option
--load-path=directory (or in short -L
directory) allows you to add directory to the front of the
package module search path and so make your own packages visible.
Next: Вызов guix hash, Previous: Вызов guix edit, Up: Утилиты [Contents][Index]
10.3 Вызов guix download
When writing a package definition, developers typically need to download a
source tarball, compute its SHA256 hash, and write that hash in the package
definition (see Описание пакетов). The guix download tool
helps with this task: it downloads a file from the given URI, adds it to the
store, and prints both its file name in the store and its SHA256 hash.
The fact that the downloaded file is added to the store saves bandwidth:
when the developer eventually tries to build the newly defined package with
guix build, the source tarball will not have to be downloaded
again because it is already in the store. It is also a convenient way to
temporarily stash files, which may be deleted eventually (see Вызов guix gc).
The guix download command supports the same URIs as used in
package definitions. In particular, it supports mirror:// URIs.
https URIs (HTTP over TLS) are supported provided the Guile
bindings for GnuTLS are available in the user’s environment; when they are
not available, an error is raised. See how to install
the GnuTLS bindings for Guile in GnuTLS-Guile, for more
information.
guix download verifies HTTPS server certificates by loading the
certificates of X.509 authorities from the directory pointed to by the
SSL_CERT_DIR environment variable (see Сертификаты X.509), unless
--no-check-certificate is used.
The following options are available:
--show=package-f formatCompute a hash using the specified algorithm. See Вызов
guix hash, for more information.--format=fmt-f fmtWrite the hash in the format specified by fmt. For more information on the valid values for fmt, see Вызов
guix hash.--no-check-certificateDo not validate the X.509 certificates of HTTPS servers.
When using this option, you have absolutely no guarantee that you are communicating with the authentic server responsible for the given URL, which makes you vulnerable to “man-in-the-middle” attacks.
--output=file-o fileSave the downloaded file to file instead of adding it to the store.
Next: Вызов guix import, Previous: Вызов guix download, Up: Утилиты [Contents][Index]
10.4 Вызов guix hash
The guix hash command computes the hash of a file. It is
primarily a convenience tool for anyone contributing to the distribution: it
computes the cryptographic hash of one or more files, which can be used in
the definition of a package (see Описание пакетов).
Основной синтаксис:
guix hash option file ...
When file is - (a hyphen), guix hash computes the
hash of data read from standard input. guix hash has the
following options:
--show=package-f formatCompute a hash using the specified algorithm,
sha256by default.algorithm must be the name of a cryptographic hash algorithm supported by Libgcrypt via Guile-Gcrypt—e.g.,
sha512orsha3-256(see Hash Functions in Guile-Gcrypt Reference Manual).--format=fmt-f fmtWrite the hash in the format specified by fmt.
Supported formats:
base64,nix-base32,base32,base16(hexandhexadecimalcan be used as well).If the --format option is not specified,
guix hashwill output the hash innix-base32. This representation is used in the definitions of packages.--recursive-rThe --recursive option is deprecated in favor of --serializer=nar (see below); -r remains accepted as a convenient shorthand.
--serializer=type-S typeCompute the hash on file using type serialization.
type may be one of the following:
noneThis is the default: it computes the hash of a file’s contents.
narCompute the hash of a “normalized archive” (or “nar”) containing file, including its children if it is a directory. Some of the metadata of file is part of the archive; for instance, when file is a regular file, the hash is different depending on whether file is executable or not. Metadata such as time stamps have no impact on the hash (see Вызов
guix archive, for more info on the nar format).gitCompute the hash of the file or directory as a Git “tree”, following the same method as the Git version control system.
--exclude-vcs-xWhen combined with --recursive, exclude version control system directories (.bzr, .git, .hg, etc.).
As an example, here is how you would compute the hash of a Git checkout, which is useful when using the
git-fetchmethod (seeoriginСправка):$ git clone http://example.org/foo.git $ cd foo $ guix hash -x --serializer=nar .
Next: Вызов guix refresh, Previous: Вызов guix hash, Up: Утилиты [Contents][Index]
10.5 Вызов guix import
The guix import command is useful for people who would like to add
a package to the distribution with as little work as possible—a legitimate
demand. The command knows of a few repositories from which it can
“import” package metadata. The result is a package definition, or a
template thereof, in the format we know (see Описание пакетов).
Основной синтаксис:
guix import importer options…
importer specifies the source from which to import package metadata, and options specifies a package identifier and other options specific to importer.
Some of the importers rely on the ability to run the gpgv
command. For these, GnuPG must be installed and in $PATH; run
guix install gnupg if needed.
Возможные форматы:
gnuImport metadata for the given GNU package. This provides a template for the latest version of that GNU package, including the hash of its source tarball, and its canonical synopsis and description.
Additional information such as the package dependencies and its license needs to be figured out manually.
For example, the following command returns a package definition for GNU Hello:
guix import gnu hello
Specific command-line options are:
--key-download=policyAs for
guix refresh, specify the policy to handle missing OpenPGP keys when verifying the package signature. See --key-download.
pypi¶Import metadata from the Python Package Index. Information is taken from the JSON-formatted description available at
pypi.python.organd usually includes all the relevant information, including package dependencies. For maximum efficiency, it is recommended to install theunziputility, so that the importer can unzip Python wheels and gather data from them.The command below imports metadata for the latest version of the
itsdangerousPython package:guix import pypi itsdangerous
You can also ask for a specific version:
guix import pypi itsdangerous@1.1.0
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
gem¶Import metadata from RubyGems. Information is taken from the JSON-formatted description available at
rubygems.organd includes most relevant information, including runtime dependencies. There are some caveats, however. The metadata doesn’t distinguish between synopses and descriptions, so the same string is used for both fields. Additionally, the details of non-Ruby dependencies required to build native extensions is unavailable and left as an exercise to the packager.The command below imports metadata for the
railsRuby package:guix import gem rails
You can also ask for a specific version:
guix import gem rails@7.0.4
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
minetest¶-
Import metadata from ContentDB. Information is taken from the JSON-formatted metadata provided through ContentDB’s API and includes most relevant information, including dependencies. There are some caveats, however. The license information is often incomplete. The commit hash is sometimes missing. The descriptions are in the Markdown format, but Guix uses Texinfo instead. Texture packs and subgames are unsupported.
The command below imports metadata for the Mesecons mod by Jeija:
guix import minetest Jeija/mesecons
The author name can also be left out:
guix import minetest mesecons
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
cpan¶Import metadata from MetaCPAN. Information is taken from the JSON-formatted metadata provided through MetaCPAN’s API and includes most relevant information, such as module dependencies. License information should be checked closely. If Perl is available in the store, then the
corelistutility will be used to filter core modules out of the list of dependencies.The command command below imports metadata for the Acme::Boolean Perl module:
guix import cpan Acme::Boolean
cran¶-
Import metadata from CRAN, the central repository for the GNU R statistical and graphical environment.
Information is extracted from the DESCRIPTION file of the package.
The command command below imports metadata for the Cairo R package:
guix import cran Cairo
You can also ask for a specific version:
guix import cran rasterVis@0.50.3
When --recursive is added, the importer will traverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
When --style=specification is added, the importer will generate package definitions whose inputs are package specifications instead of references to package variables. This is useful when generated package definitions are to be appended to existing user modules, as the list of used package modules need not be changed. The default is --style=variable.
When --archive=bioconductor is added, metadata is imported from Bioconductor, a repository of R packages for the analysis and comprehension of high-throughput genomic data in bioinformatics.
Information is extracted from the DESCRIPTION file contained in the package archive.
The command below imports metadata for the GenomicRanges R package:
guix import cran --archive=bioconductor GenomicRanges
Finally, you can also import R packages that have not yet been published on CRAN or Bioconductor as long as they are in a git repository. Use --archive=git followed by the URL of the git repository:
guix import cran --archive=git https://github.com/immunogenomics/harmony
texlive¶-
Import TeX package information from the TeX Live package database for TeX packages that are part of the TeX Live distribution.
Information about the package is obtained from the TeX Live package database, a plain text file that is included in the
texlive-binpackage. The source code is downloaded from possibly multiple locations in the SVN repository of the Tex Live project.The command command below imports metadata for the
fontspecTeX package:guix import texlive fontspec
json¶Import package metadata from a local JSON file. Consider the following example package definition in JSON format:
{ "name": "hello", "version": "2.10", "source": "mirror://gnu/hello/hello-2.10.tar.gz", "build-system": "gnu", "home-page": "https://www.gnu.org/software/hello/", "synopsis": "Hello, GNU world: An example GNU package", "description": "GNU Hello prints a greeting.", "license": "GPL-3.0+", "native-inputs": ["gettext"] }The field names are the same as for the
<package>record (See Описание пакетов). References to other packages are provided as JSON lists of quoted package specification strings such asguileorguile@2.0.The importer also supports a more explicit source definition using the common fields for
<origin>records:{ … "source": { "method": "url-fetch", "uri": "mirror://gnu/hello/hello-2.10.tar.gz", "sha256": { "base32": "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i" } } … }The command below reads metadata from the JSON file
hello.jsonand outputs a package expression:guix import json hello.json
hackage¶Import metadata from the Haskell community’s central package archive Hackage. Information is taken from Cabal files and includes all the relevant information, including package dependencies.
Specific command-line options are:
--stdin-sRead a Cabal file from standard input.
--no-test-dependencies-tDo not include dependencies required only by the test suites.
--cabal-environment=alist-e alistalist is a Scheme alist defining the environment in which the Cabal conditionals are evaluated. The accepted keys are:
os,arch,impland a string representing the name of a flag. The value associated with a flag has to be either the symboltrueorfalse. The value associated with other keys has to conform to the Cabal file format definition. The default value associated with the keysos,archandimplis ‘linux’, ‘x86_64’ and ‘ghc’, respectively.--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
The command below imports metadata for the latest version of the HTTP Haskell package without including test dependencies and specifying the value of the flag ‘network-uri’ as
false:guix import hackage -t -e "'((\"network-uri\" . false))" HTTP
A specific package version may optionally be specified by following the package name by an at-sign and a version number as in the following example:
guix import hackage mtl@2.1.3.1
stackage¶The
stackageimporter is a wrapper around thehackageone. It takes a package name, looks up the package version included in a long-term support (LTS) Stackage release and uses thehackageimporter to retrieve its metadata. Note that it is up to you to select an LTS release compatible with the GHC compiler used by Guix.Specific command-line options are:
--no-test-dependencies-tDo not include dependencies required only by the test suites.
--lts-version=version-l versionversion is the desired LTS release version. If omitted the latest release is used.
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
The command below imports metadata for the HTTP Haskell package included in the LTS Stackage release version 7.18:
guix import stackage --lts-version=7.18 HTTP
elpa¶Import metadata from an Emacs Lisp Package Archive (ELPA) package repository (see Packages in The GNU Emacs Manual).
Specific command-line options are:
--archive=repo-a reporepo identifies the archive repository from which to retrieve the information. Currently the supported repositories and their identifiers are:
- - GNU, selected by the
gnuidentifier. This is the default.Packages from
elpa.gnu.orgare signed with one of the keys contained in the GnuPG keyring at share/emacs/25.1/etc/package-keyring.gpg (or similar) in theemacspackage (see ELPA package signatures in The GNU Emacs Manual). - - NonGNU, selected by the
nongnuidentifier. - - MELPA-Stable, selected by the
melpa-stableidentifier. - - MELPA, selected by the
melpaidentifier.
- - GNU, selected by the
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
crate¶Import metadata from the crates.io Rust package repository crates.io, as in this example:
guix import crate blake2-rfc
The crate importer also allows you to specify a version string:
guix import crate constant-time-eq@0.1.0
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
elm¶Import metadata from the Elm package repository package.elm-lang.org, as in this example:
guix import elm elm-explorations/webgl
The Elm importer also allows you to specify a version string:
guix import elm elm-explorations/webgl@1.1.3
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
opam¶-
Import metadata from the OPAM package repository used by the OCaml community.
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
--repoBy default, packages are searched in the official OPAM repository. This option, which can be used more than once, lets you add other repositories which will be searched for packages. It accepts as valid arguments:
- the name of a known repository - can be one of
opam,coq(equivalent tocoq-released),coq-core-dev,coq-extra-devorgrew. - the URL of a repository as expected by the
opam repository addcommand (for instance, the URL equivalent of the aboveopamname would be https://opam.ocaml.org). - the path to a local copy of a repository (a directory containing a packages/ sub-directory).
Repositories are assumed to be passed to this option by order of preference. The additional repositories will not replace the default
opamrepository, which is always kept as a fallback.Also, please note that versions are not compared across repositories. The first repository (from left to right) that has at least one version of a given package will prevail over any others, and the version imported will be the latest one found in this repository only.
- the name of a known repository - can be one of
go¶Import metadata for a Go module using proxy.golang.org.
guix import go gopkg.in/yaml.v2
It is possible to use a package specification with a
@VERSIONsuffix to import a specific version.Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
версияWhen using this option, the importer preserves the exact versions of the Go modules dependencies instead of using their latest available versions. This can be useful when attempting to import packages that recursively depend on former versions of themselves to build. When using this mode, the symbol of the package is made by appending the version to its name, so that multiple versions of the same package can coexist.
egg¶Import metadata for CHICKEN eggs. The information is taken from PACKAGE.egg files found in the eggs-5-all Git repository. However, it does not provide all the information that we need, there is no “description” field, and the licenses used are not always precise (BSD is often used instead of BSD-N).
guix import egg sourcehut
You can also ask for a specific version:
guix import egg arrays@1.0
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
hexpm¶Import metadata from the hex.pm Erlang and Elixir package repository hex.pm, as in this example:
guix import hexpm stun
The importer tries to determine the build system used by the package.
The hexpm importer also allows you to specify a version string:
guix import hexpm cf@0.3.0
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
The structure of the guix import code is modular. It would be
useful to have more importers for other package formats, and your help is
welcome here (see Содействие).
Next: Invoking guix style, Previous: Вызов guix import, Up: Утилиты [Contents][Index]
10.6 Вызов guix refresh
The primary audience of the guix refresh command is packagers. As
a user, you may be interested in the --with-latest option, which
can bring you package update superpowers built upon guix refresh
(see --with-latest). By
default, guix refresh reports any packages provided by the
distribution that are outdated compared to the latest upstream version, like
this:
$ guix refresh gnu/packages/gettext.scm:29:13: gettext would be upgraded from 0.18.1.1 to 0.18.2.1 gnu/packages/glib.scm:77:12: glib would be upgraded from 2.34.3 to 2.37.0
Alternatively, one can specify packages to consider, in which case a warning is emitted for packages that lack an updater:
$ guix refresh coreutils guile guile-ssh gnu/packages/ssh.scm:205:2: warning: no updater for guile-ssh gnu/packages/guile.scm:136:12: guile would be upgraded from 2.0.12 to 2.0.13
guix refresh browses the upstream repository of each package and
determines the highest version number of the releases therein. The command
knows how to update specific types of packages: GNU packages, ELPA packages,
etc.—see the documentation for --type below. There are many
packages, though, for which it lacks a method to determine whether a new
upstream release is available. However, the mechanism is extensible, so
feel free to get in touch with us to add a new method!
--recursiveConsider the packages specified, and all the packages upon which they depend.
$ guix refresh --recursive coreutils gnu/packages/acl.scm:35:2: warning: no updater for acl gnu/packages/m4.scm:30:12: info: 1.4.18 is already the latest version of m4 gnu/packages/xml.scm:68:2: warning: no updater for expat gnu/packages/multiprecision.scm:40:12: info: 6.1.2 is already the latest version of gmp …
Sometimes the upstream name differs from the package name used in Guix, and
guix refresh needs a little help. Most updaters honor the
upstream-name property in package definitions, which can be used to
that effect:
(define-public network-manager
(package
(name "network-manager")
;; …
(properties '((upstream-name . "NetworkManager")))))
When passed --update, it modifies distribution source files to
update the version numbers and source tarball hashes of those package
recipes (see Описание пакетов). This is achieved by downloading each
package’s latest source tarball and its associated OpenPGP signature,
authenticating the downloaded tarball against its signature using
gpgv, and finally computing its hash—note that GnuPG must be
installed and in $PATH; run guix install gnupg if needed.
When the public key used to sign the tarball is missing from the user’s
keyring, an attempt is made to automatically retrieve it from a public key
server; when this is successful, the key is added to the user’s keyring;
otherwise, guix refresh reports an error.
Поддерживаются следующие варианты:
--expression=expr-e exprПроцедура, при выполнении которой возвращается пакет.
This is useful to precisely refer to a package, as in this example:
guix refresh -l -e '(@@ (gnu packages commencement) glibc-final)'
This command lists the dependents of the “final” libc (essentially all the packages).
--update-uUpdate distribution source files (package recipes) in place. This is usually run from a checkout of the Guix source tree (see Запуск Guix перед его установкой):
$ ./pre-inst-env guix refresh -s non-core -u
See Описание пакетов, for more information on package definitions.
--select=[subset]-s subsetSelect all the packages in subset, one of
coreornon-core.The
coresubset refers to all the packages at the core of the distribution—i.e., packages that are used to build “everything else”. This includes GCC, libc, Binutils, Bash, etc. Usually, changing one of these packages in the distribution entails a rebuild of all the others. Thus, such updates are an inconvenience to users in terms of build time or bandwidth used to achieve the upgrade.The
non-coresubset refers to the remaining packages. It is typically useful in cases where an update of the core packages would be inconvenient.--manifest=file-m fileSelect all the packages from the manifest in file. This is useful to check if any packages of the user manifest can be updated.
--type=updater-t updaterSelect only packages handled by updater (may be a comma-separated list of updaters). Currently, updater may be one of:
gnuсредство обновления пакетов GNU;
savannahthe updater for packages hosted at Savannah;
источниксредство обновления пакетов, размещенных на kernel.org;
gnomeсредство обновления пакетов GNOME;
kdeсредство обновления пакетов KDE;
xorgсредство обновления пакетов X.org;
kernel.orgсредство обновления пакетов, размещенных на kernel.org;
eggthe updater for Egg packages;
elpathe updater for ELPA packages;
cranthe updater for CRAN packages;
bioconductorthe updater for Bioconductor R packages;
cpanthe updater for CPAN packages;
pypithe updater for PyPI packages.
gemthe updater for RubyGems packages.
githubсредство обновления пакетов GitHub.
hackagethe updater for Hackage packages.
stackagethe updater for Stackage packages.
cratethe updater for Crates packages.
launchpadthe updater for Launchpad packages.
generic-htmla generic updater that crawls the HTML page where the source tarball of the package is hosted, when applicable.
generic-gita generic updater for packages hosted on Git repositories. It tries to be smart about parsing Git tag names, but if it is not able to parse the tag name and compare tags correctly, users can define the following properties for a package.
-
release-tag-prefix: a regular expression for matching a prefix of the tag name. -
release-tag-suffix: a regular expression for matching a suffix of the tag name. -
release-tag-version-delimiter: a string used as the delimiter in the tag name for separating the numbers of the version. -
accept-pre-releases: by default, the updater will ignore pre-releases; to make it also look for pre-releases, set the this property to#t.
(package (name "foo") ;; ... (properties '((release-tag-prefix . "^release0-") (release-tag-suffix . "[a-z]?$") (release-tag-version-delimiter . ":"))))-
For instance, the following command only checks for updates of Emacs packages hosted at
elpa.gnu.organd for updates of CRAN packages:$ guix refresh --type=elpa,cran gnu/packages/statistics.scm:819:13: r-testthat would be upgraded from 0.10.0 to 0.11.0 gnu/packages/emacs.scm:856:13: emacs-auctex would be upgraded from 11.88.6 to 11.88.9
--list-updatersList available updaters and exit (see --type above).
For each updater, display the fraction of packages it covers; at the end, display the fraction of packages covered by all these updaters.
In addition, guix refresh can be passed one or more package names,
as in this example:
$ ./pre-inst-env guix refresh -u emacs idutils gcc@4.8
The command above specifically updates the emacs and idutils
packages. The --select option would have no effect in this case.
You might also want to update definitions that correspond to the packages
installed in your profile:
$ ./pre-inst-env guix refresh -u \
$(guix package --list-installed | cut -f1)
When considering whether to upgrade a package, it is sometimes convenient to
know which packages would be affected by the upgrade and should be checked
for compatibility. For this the following option may be used when passing
guix refresh one or more package names:
--list-dependent-lList top-level dependent packages that would need to be rebuilt as a result of upgrading one or more packages.
See the
reverse-packagetype ofguix graph, for information on how to visualize the list of dependents of a package.
Be aware that the --list-dependent option only approximates the rebuilds that would be required as a result of an upgrade. More rebuilds might be required under some circumstances.
$ guix refresh --list-dependent flex Building the following 120 packages would ensure 213 dependent packages are rebuilt: hop@2.4.0 emacs-geiser@0.13 notmuch@0.18 mu@0.9.9.5 cflow@1.4 idutils@4.6 …
The command above lists a set of packages that could be built to check for
compatibility with an upgraded flex package.
--list-transitiveList all the packages which one or more packages depend upon.
$ guix refresh --list-transitive flex flex@2.6.4 depends on the following 25 packages: perl@5.28.0 help2man@1.47.6 bison@3.0.5 indent@2.2.10 tar@1.30 gzip@1.9 bzip2@1.0.6 xz@5.2.4 file@5.33 …
The command above lists a set of packages which, when changed, would cause
flex to be rebuilt.
The following options can be used to customize GnuPG operation:
--gpg=commandUse command as the GnuPG 2.x command. command is searched for in
$PATH.--keyring=fileUse file as the keyring for upstream keys. file must be in the keybox format. Keybox files usually have a name ending in .kbx and the GNU Privacy Guard (GPG) can manipulate these files (see
kbxutilin Using the GNU Privacy Guard, for information on a tool to manipulate keybox files).When this option is omitted,
guix refreshuses ~/.config/guix/upstream/trustedkeys.kbx as the keyring for upstream signing keys. OpenPGP signatures are checked against keys from this keyring; missing keys are downloaded to this keyring as well (see --key-download below).You can export keys from your default GPG keyring into a keybox file using commands like this one:
gpg --export rms@gnu.org | kbxutil --import-openpgp >> mykeyring.kbx
Likewise, you can fetch keys to a specific keybox file like this:
gpg --no-default-keyring --keyring mykeyring.kbx \ --recv-keys 3CE464558A84FDC69DB40CFB090B11993D9AEBB5
See --keyring in Using the GNU Privacy Guard, for more information on GPG’s --keyring option.
--key-download=policyHandle missing OpenPGP keys according to policy, which may be one of:
всегдаAlways download missing OpenPGP keys from the key server, and add them to the user’s GnuPG keyring.
никогдаNever try to download missing OpenPGP keys. Instead just bail out.
interactiveWhen a package signed with an unknown OpenPGP key is encountered, ask the user whether to download it or not. This is the default behavior.
--key-server=hostUse host as the OpenPGP key server when importing a public key.
--load-path=directory-L directoryAdd directory to the front of the package module search path (see Пакетные модули).
Это позволяет пользователям определять свои собственные пакеты и делать их видимыми для инструментов командной строки.
The github updater uses the GitHub API to query for new releases. When used repeatedly e.g. when
refreshing all packages, GitHub will eventually refuse to answer any further
API requests. By default 60 API requests per hour are allowed, and a full
refresh on all GitHub packages in Guix requires more than this.
Authentication with GitHub through the use of an API token alleviates these
limits. To use an API token, set the environment variable
GUIX_GITHUB_TOKEN to a token procured from
https://github.com/settings/tokens or otherwise.
Next: Вызов guix lint, Previous: Вызов guix refresh, Up: Утилиты [Contents][Index]
10.7 Invoking guix style
The guix style command helps users and packagers alike style their
package definitions and configuration files according to the latest
fashionable trends. It can either reformat whole files, with the
--whole-file option, or apply specific styling rules to
individual package definitions. The command currently provides the
following styling rules:
- formatting package definitions according to the project’s conventions (see Форматирование кода);
- rewriting package inputs to the “new style”, as explained below.
The way package inputs are written is going through a transition
(see package Ссылка, for more on package inputs). Until version
1.3.0, package inputs were written using the “old style”, where each input
was given an explicit label, most of the time the package name:
(package
;; …
;; The "old style" (deprecated).
(inputs `(("libunistring" ,libunistring)
("libffi" ,libffi))))
Today, the old style is deprecated and the preferred style looks like this:
Likewise, uses of alist-delete and friends to manipulate inputs is
now deprecated in favor of modify-inputs (see Defining Package Variants, for more info on modify-inputs).
In the vast majority of cases, this is a purely mechanical change on the
surface syntax that does not even incur a package rebuild. Running
guix style -S inputs can do that for you, whether you’re working
on packages in Guix proper or in an external channel.
Основной синтаксис:
guix style [options] package…
This causes guix style to analyze and rewrite the definition of
package… or, when package is omitted, of all the
packages. The --styling or -S option allows you to select
the style rule, the default rule being format—see below.
To reformat entire source files, the syntax is:
guix style --whole-file file…
Доступные опции резюмированы ниже.
--dry-run-nShow source file locations that would be edited but do not modify them.
--whole-file-fReformat the given files in their entirety. In that case, subsequent arguments are interpreted as file names (rather than package names), and the --styling option has no effect.
As an example, here is how you might reformat your operating system configuration (you need write permissions for the file):
guix style -f /etc/config.scm
--styling=rule-S ruleApply rule, one of the following styling rules:
formatFormat the given package definition(s)—this is the default styling rule. For example, a packager running Guix on a checkout (see Запуск Guix перед его установкой) might want to reformat the definition of the Coreutils package like so:
./pre-inst-env guix style coreutils
inputsRewrite package inputs to the “new style”, as described above. This is how you would rewrite inputs of package
whatnotin your own channel:guix style -L ~/my/channel -S inputs whatnot
Rewriting is done in a conservative way: preserving comments and bailing out if it cannot make sense of the code that appears in an inputs field. The --input-simplification option described below provides fine-grain control over when inputs should be simplified.
--list-stylings-lList and describe the available styling rules and exit.
--load-path=directory-L directoryAdd directory to the front of the package module search path (see Пакетные модули).
--expression=expr-e exprStyle the package expr evaluates to.
Например, запуск:
guix style -e '(@ (gnu packages gcc) gcc-5)'
styles the
gcc-5package definition.--input-simplification=policyWhen using the
inputsstyling rule, with ‘-S inputs’, this option specifies the package input simplification policy for cases where an input label does not match the corresponding package name. policy may be one of the following:silentSimplify inputs only when the change is “silent”, meaning that the package does not need to be rebuilt (its derivation is unchanged).
safeSimplify inputs only when that is “safe” to do: the package might need to be rebuilt, but the change is known to have no observable effect.
всегдаSimplify inputs even when input labels do not match package names, and even if that might have an observable effect.
The default is
silent, meaning that input simplifications do not trigger any package rebuild.
Next: Вызов guix size, Previous: Invoking guix style, Up: Утилиты [Contents][Index]
10.8 Вызов guix lint
The guix lint command is meant to help package developers avoid
common errors and use a consistent style. It runs a number of checks on a
given set of packages in order to find common mistakes in their
definitions. Available checkers include (see --list-checkers
for a complete list):
синопсисописаниеValidate certain typographical and stylistic rules about package descriptions and synopses.
inputs-should-be-nativeIdentify inputs that should most likely be native inputs.
источникглавная страницаmirror-urlgithub-urlsource-file-nameProbe
home-pageandsourceURLs and report those that are invalid. Suggest amirror://URL when applicable. If thesourceURL redirects to a GitHub URL, recommend usage of the GitHub URL. Check that the source file name is meaningful, e.g. is not just a version number or “git-checkout”, without a declaredfile-name(seeoriginСправка).source-unstable-tarballParse the
sourceURL to determine if a tarball from GitHub is autogenerated or if it is a release tarball. Unfortunately GitHub’s autogenerated tarballs are sometimes regenerated.деривацияВернуть деривацию(-ии), производящие данные элементы склада (see Деривации).
противоречеия профиляCheck whether installing the given packages in a profile would lead to collisions. Collisions occur when several packages with the same name but a different version or a different store file name are propagated. See
propagated-inputs, for more information on propagated inputs.архивирование¶-
Checks whether the package’s source code is archived at Software Heritage.
When the source code that is not archived comes from a version-control system (VCS)—e.g., it’s obtained with
git-fetch, send Software Heritage a “save” request so that it eventually archives it. This ensures that the source will remain available in the long term, and that Guix can fall back to Software Heritage should the source code disappear from its original host. The status of recent “save” requests can be viewed on-line.When source code is a tarball obtained with
url-fetch, simply print a message when it is not archived. As of this writing, Software Heritage does not allow requests to save arbitrary tarballs; we are working on ways to ensure that non-VCS source code is also archived.Software Heritage limits the request rate per IP address. When the limit is reached,
guix lintprints a message and thearchivalchecker stops doing anything until that limit has been reset. cve¶-
Report known vulnerabilities found in the Common Vulnerabilities and Exposures (CVE) databases of the current and past year published by the US NIST.
To view information about a particular vulnerability, visit pages such as:
- ‘
https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-YYYY-ABCD’ - ‘
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-YYYY-ABCD’
where
CVE-YYYY-ABCDis the CVE identifier—e.g.,CVE-2015-7554.Package developers can specify in package recipes the Common Platform Enumeration (CPE) name and version of the package when they differ from the name or version that Guix uses, as in this example:
(package (name "grub") ;; … ;; CPE calls this package "grub2". (properties '((cpe-name . "grub2") (cpe-version . "2.3"))))Some entries in the CVE database do not specify which version of a package they apply to, and would thus “stick around” forever. Package developers who found CVE alerts and verified they can be ignored can declare them as in this example:
(package (name "t1lib") ;; … ;; These CVEs no longer apply and can be safely ignored. (properties `((lint-hidden-cve . ("CVE-2011-0433" "CVE-2011-1553" "CVE-2011-1554" "CVE-2011-5244"))))) - ‘
formattingWarn about obvious source code formatting issues: trailing white space, use of tabulations, etc.
input-labelsReport old-style input labels that do not match the name of the corresponding package. This aims to help migrate from the “old input style”. See
packageСсылка, for more information on package inputs and input styles. See Invokingguix style, on how to migrate to the new style.
Основной синтаксис:
guix lint options package…
If no package is given on the command line, then all packages are checked. The options may be zero or more of the following:
--list-checkers-lList and describe all the available checkers that will be run on packages and exit.
--checkers-cOnly enable the checkers specified in a comma-separated list using the names returned by --list-checkers.
--exclude-xOnly disable the checkers specified in a comma-separated list using the names returned by --list-checkers.
--expression=expr-e exprПроцедура, при выполнении которой возвращается пакет.
This is useful to unambiguously designate packages, as in this example:
guix lint -c archival -e '(@ (gnu packages guile) guile-3.0)'
--network-nOnly enable the checkers that do not depend on Internet access.
--load-path=directory-L directoryAdd directory to the front of the package module search path (see Пакетные модули).
Это позволяет пользователям определять свои собственные пакеты и делать их видимыми для инструментов командной строки.
Next: Вызов guix graph, Previous: Вызов guix lint, Up: Утилиты [Contents][Index]
10.9 Вызов guix size
The guix size command helps package developers profile the disk
usage of packages. It is easy to overlook the impact of an additional
dependency added to a package, or the impact of using a single output for a
package that could easily be split (see Пакеты со множественным выходом). Such are the typical issues that guix size can
highlight.
The command can be passed one or more package specifications such as
gcc@4.8 or guile:debug, or a file name in the store.
Consider this example:
$ guix size coreutils store item total self /gnu/store/…-gcc-5.5.0-lib 60.4 30.1 38.1% /gnu/store/…-glibc-2.27 30.3 28.8 36.6% /gnu/store/…-coreutils-8.28 78.9 15.0 19.0% /gnu/store/…-gmp-6.1.2 63.1 2.7 3.4% /gnu/store/…-bash-static-4.4.12 1.5 1.5 1.9% /gnu/store/…-acl-2.2.52 61.1 0.4 0.5% /gnu/store/…-attr-2.4.47 60.6 0.2 0.3% /gnu/store/…-libcap-2.25 60.5 0.2 0.2% total: 78.9 MiB
The store items listed here constitute the transitive closure of Coreutils—i.e., Coreutils and all its dependencies, recursively—as would be returned by:
$ guix gc -R /gnu/store/…-coreutils-8.23
Here the output shows three columns next to store items. The first column, labeled “total”, shows the size in mebibytes (MiB) of the closure of the store item—that is, its own size plus the size of all its dependencies. The next column, labeled “self”, shows the size of the item itself. The last column shows the ratio of the size of the item itself to the space occupied by all the items listed here.
In this example, we see that the closure of Coreutils weighs in at 79 MiB, most of which is taken by libc and GCC’s run-time support libraries. (That libc and GCC’s libraries represent a large fraction of the closure is not a problem per se because they are always available on the system anyway.)
Since the command also accepts store file names, assessing the size of a build result is straightforward:
guix size $(guix system build config.scm)
When the package(s) passed to guix size are available in the
store24, guix size queries the daemon to determine its
dependencies, and measures its size in the store, similar to du -ms
--apparent-size (see du invocation in GNU Coreutils).
When the given packages are not in the store, guix size
reports information based on the available substitutes
(see Подстановки). This makes it possible it to profile disk usage of
store items that are not even on disk, only available remotely.
You can also specify several package names:
$ guix size coreutils grep sed bash store item total self /gnu/store/…-coreutils-8.24 77.8 13.8 13.4% /gnu/store/…-grep-2.22 73.1 0.8 0.8% /gnu/store/…-bash-4.3.42 72.3 4.7 4.6% /gnu/store/…-readline-6.3 67.6 1.2 1.2% … total: 102.3 MiB
In this example we see that the combination of the four packages takes 102.3 MiB in total, which is much less than the sum of each closure since they have a lot of dependencies in common.
When looking at the profile returned by guix size, you may find
yourself wondering why a given package shows up in the profile at all. To
understand it, you can use guix graph --path -t references to
display the shortest path between the two packages (see Вызов guix graph).
Доступные опции:
- --substitute-urls=urls
Use substitute information from urls. See the same option for
guix build.- --sort=key
Sort lines according to key, one of the following options:
selfthe size of each item (the default);
конвейерthe total size of the item’s closure.
- --map-file=file
Write a graphical map of disk usage in PNG format to file.
For the example above, the map looks like this:

This option requires that Guile-Charting be installed and visible in Guile’s module search path. When that is not the case,
guix sizefails as it tries to load it.- --system=system
- -s system
Consider packages for system—e.g.,
x86_64-linux.- --load-path=directory
- -L directory
Add directory to the front of the package module search path (see Пакетные модули).
Это позволяет пользователям определять свои собственные пакеты и делать их видимыми для инструментов командной строки.
Next: Вызов guix publish, Previous: Вызов guix size, Up: Утилиты [Contents][Index]
10.10 Вызов guix graph
Packages and their dependencies form a graph, specifically a directed
acyclic graph (DAG). It can quickly become difficult to have a mental model
of the package DAG, so the guix graph command provides a visual
representation of the DAG. By default, guix graph emits a DAG
representation in the input format of Graphviz, so its output can be passed directly to the dot command
of Graphviz. It can also emit an HTML page with embedded JavaScript code to
display a “chord diagram” in a Web browser, using the
d3.js library, or emit Cypher queries to construct
a graph in a graph database supporting the
openCypher query language. With
--path, it simply displays the shortest path between two packages.
The general syntax is:
guix graph options package…
For example, the following command generates a PDF file representing the package DAG for the GNU Core Utilities, showing its build-time dependencies:
guix graph coreutils | dot -Tpdf > dag.pdf
Вывод должен быть таким:

Неплохой граф, не так ли?
You may find it more pleasant to navigate the graph interactively with
xdot (from the xdot package):
guix graph coreutils | xdot -
But there is more than one graph! The one above is concise: it is the graph
of package objects, omitting implicit inputs such as GCC, libc, grep, etc.
It is often useful to have such a concise graph, but sometimes one may want
to see more details. guix graph supports several types of graphs,
allowing you to choose the level of detail:
packageThis is the default type used in the example above. It shows the DAG of package objects, excluding implicit dependencies. It is concise, but filters out many details.
reverse-packageThis shows the reverse DAG of packages. For example:
guix graph --type=reverse-package ocaml
... yields the graph of packages that explicitly depend on OCaml (if you are also interested in cases where OCaml is an implicit dependency, see
reverse-bagbelow).Note that for core packages this can yield huge graphs. If all you want is to know the number of packages that depend on a given package, use
guix refresh --list-dependent(see --list-dependent).bag-emergedThis is the package DAG, including implicit inputs.
For instance, the following command:
guix graph --type=bag-emerged coreutils
... yields this bigger graph:

At the bottom of the graph, we see all the implicit inputs of gnu-build-system (see
gnu-build-system).Now, note that the dependencies of these implicit inputs—that is, the bootstrap dependencies (see Начальная загрузка)—are not shown here, for conciseness.
bagSimilar to
bag-emerged, but this time including all the bootstrap dependencies.bag-with-originsSimilar to
bag, but also showing origins and their dependencies.reverse-bagThis shows the reverse DAG of packages. Unlike
reverse-package, it also takes implicit dependencies into account. For example:guix graph -t reverse-bag dune
... yields the graph of all packages that depend on Dune, directly or indirectly. Since Dune is an implicit dependency of many packages via
dune-build-system, this shows a large number of packages, whereasreverse-packagewould show very few if any.деривацияThis is the most detailed representation: It shows the DAG of derivations (see Деривации) and plain store items. Compared to the above representation, many additional nodes are visible, including build scripts, patches, Guile modules, etc.
For this type of graph, it is also possible to pass a .drv file name instead of a package name, as in:
guix graph -t derivation `guix system build -d my-config.scm`
модульThis is the graph of package modules (see Пакетные модули). For example, the following command shows the graph for the package module that defines the
guilepackage:guix graph -t module guile | xdot -
All the types above correspond to build-time dependencies. The following graph type represents the run-time dependencies:
referencesThis is the graph of references of a package output, as returned by
guix gc --references(see Вызовguix gc).If the given package output is not available in the store,
guix graphattempts to obtain dependency information from substitutes.Here you can also pass a store file name instead of a package name. For example, the command below produces the reference graph of your profile (which can be big!):
guix graph -t references `readlink -f ~/.guix-profile`
referrersThis is the graph of the referrers of a store item, as returned by
guix gc --referrers(see Вызовguix gc).This relies exclusively on local information from your store. For instance, let us suppose that the current Inkscape is available in 10 profiles on your machine;
guix graph -t referrers inkscapewill show a graph rooted at Inkscape and with those 10 profiles linked to it.It can help determine what is preventing a store item from being garbage collected.
Often, the graph of the package you are interested in does not fit on your
screen, and anyway all you want to know is why that package actually
depends on some seemingly unrelated package. The --path option
instructs guix graph to display the shortest path between two
packages (or derivations, or store items, etc.):
$ guix graph --path emacs libunistring emacs@26.3 mailutils@3.9 libunistring@0.9.10 $ guix graph --path -t derivation emacs libunistring /gnu/store/…-emacs-26.3.drv /gnu/store/…-mailutils-3.9.drv /gnu/store/…-libunistring-0.9.10.drv $ guix graph --path -t references emacs libunistring /gnu/store/…-emacs-26.3 /gnu/store/…-libidn2-2.2.0 /gnu/store/…-libunistring-0.9.10
Sometimes you still want to visualize the graph but would like to trim it so
it can actually be displayed. One way to do it is via the
--max-depth (or -M) option, which lets you specify the
maximum depth of the graph. In the example below, we visualize only
libreoffice and the nodes whose distance to libreoffice is at
most 2:
guix graph -M 2 libreoffice | xdot -f fdp -
Mind you, that’s still a big ball of spaghetti, but at least dot
can render it quickly and it can be browsed somewhat.
The available options are the following:
- --type=type
- -t type
Produce a graph output of type, where type must be one of the values listed above.
- --list-types
List the supported graph types.
- --backend=backend
- -b backend
Produce a graph using the selected backend.
- --list-backends
List the supported graph backends.
Currently, the available backends are Graphviz and d3.js.
- --paths
Display the shortest path between two nodes of the type specified by --type. The example below shows the shortest path between
libreofficeandllvmaccording to the references oflibreoffice:$ guix graph --path -t references libreoffice llvm /gnu/store/…-libreoffice-6.4.2.2 /gnu/store/…-libepoxy-1.5.4 /gnu/store/…-mesa-19.3.4 /gnu/store/…-llvm-9.0.1
- --expression=expr
- -e expr
Процедура, при выполнении которой возвращается пакет.
This is useful to precisely refer to a package, as in this example:
guix graph -e '(@@ (gnu packages commencement) gnu-make-final)'
- --system=system
- -s system
Вывести граф для system—например,
i686-linux.The package dependency graph is largely architecture-independent, but there are some architecture-dependent bits that this option allows you to visualize.
- --load-path=directory
- -L directory
Add directory to the front of the package module search path (see Пакетные модули).
Это позволяет пользователям определять свои собственные пакеты и делать их видимыми для инструментов командной строки.
On top of that, guix graph supports all the usual package
transformation options (see Параметры преобразования пакета). This makes
it easy to view the effect of a graph-rewriting transformation such as
--with-input. For example, the command below outputs the graph of
git once openssl has been replaced by libressl
everywhere in the graph:
guix graph git --with-input=openssl=libressl
So many possibilities, so much fun!
Next: Вызов guix challenge, Previous: Вызов guix graph, Up: Утилиты [Contents][Index]
10.11 Вызов guix publish
The purpose of guix publish is to enable users to easily share
their store with others, who can then use it as a substitute server
(see Подстановки).
When guix publish runs, it spawns an HTTP server which allows
anyone with network access to obtain substitutes from it. This means that
any machine running Guix can also act as if it were a build farm, since the
HTTP interface is compatible with Cuirass, the software behind the
ci.guix.gnu.org build farm.
For security, each substitute is signed, allowing recipients to check their
authenticity and integrity (see Подстановки). Because guix
publish uses the signing key of the system, which is only readable by the
system administrator, it must be started as root; the --user option
makes it drop root privileges early on.
The signing key pair must be generated before guix publish is
launched, using guix archive --generate-key (see Вызов guix archive).
When the --advertise option is passed, the server advertises its availability on the local network using multicast DNS (mDNS) and DNS service discovery (DNS-SD), currently via Guile-Avahi (see Using Avahi in Guile Scheme Programs).
Основной синтаксис:
guix publish options…
Running guix publish without any additional arguments will spawn
an HTTP server on port 8080:
guix publish
guix publish can also be started following the systemd “socket
activation” protocol (see make-systemd-constructor in The GNU Shepherd Manual).
Once a publishing server has been authorized, the daemon may download substitutes from it. See Получение заменителей с других серверов.
By default, guix publish compresses archives on the fly as it
serves them. This “on-the-fly” mode is convenient in that it requires no
setup and is immediately available. However, when serving lots of clients,
we recommend using the --cache option, which enables caching of the
archives before they are sent to clients—see below for details. The
guix weather command provides a handy way to check what a server
provides (see Вызов guix weather).
As a bonus, guix publish also serves as a content-addressed mirror
for source files referenced in origin records (see origin Справка). For instance, assuming guix publish is running on
example.org, the following URL returns the raw
hello-2.10.tar.gz file with the given SHA256 hash (represented in
nix-base32 format, see Вызов guix hash):
http://example.org/file/hello-2.10.tar.gz/sha256/0ssi1…ndq1i
Obviously, these URLs only work for files that are in the store; in other cases, they return 404 (“Not Found”).
Build logs are available from /log URLs like:
http://example.org/log/gwspk…-guile-2.2.3
When guix-daemon is configured to save compressed build logs, as
is the case by default (see Вызов guix-daemon), /log URLs
return the compressed log as-is, with an appropriate Content-Type
and/or Content-Encoding header. We recommend running
guix-daemon with --log-compression=gzip since Web
browsers can automatically decompress it, which is not the case with Bzip2
compression.
The following options are available:
--port=port-p portListen for HTTP requests on port.
--listen=hostListen on the network interface for host. The default is to accept connections from any interface.
--user=user-u userChange privileges to user as soon as possible—i.e., once the server socket is open and the signing key has been read.
--log-compression=type-C [method[:level]]Compress data using the given method and level. method is one of
lzip,zstd, andgzip; when method is omitted,gzipis used.When level is zero, disable compression. The range 1 to 9 corresponds to different compression levels: 1 is the fastest, and 9 is the best (CPU-intensive). The default is 3.
Usually,
lzipcompresses noticeably better thangzipfor a small increase in CPU usage; see benchmarks on the lzip Web page. However,lzipachieves low decompression throughput (on the order of 50 MiB/s on modern hardware), which can be a bottleneck for someone who downloads over a fast network connection.The compression ratio of
zstdis between that oflzipand that ofgzip; its main advantage is a high decompression speed.Unless --cache is used, compression occurs on the fly and the compressed streams are not cached. Thus, to reduce load on the machine that runs
guix publish, it may be a good idea to choose a low compression level, to runguix publishbehind a caching proxy, or to use --cache. Using --cache has the advantage that it allowsguix publishto addContent-LengthHTTP header to its responses.This option can be repeated, in which case every substitute gets compressed using all the selected methods, and all of them are advertised. This is useful when users may not support all the compression methods: they can select the one they support.
--cache=directory-c directoryCache archives and meta-data (
.narinfoURLs) to directory and only serve archives that are in cache.When this option is omitted, archives and meta-data are created on-the-fly. This can reduce the available bandwidth, especially when compression is enabled, since this may become CPU-bound. Another drawback of the default mode is that the length of archives is not known in advance, so
guix publishdoes not add aContent-LengthHTTP header to its responses, which in turn prevents clients from knowing the amount of data being downloaded.Conversely, when --cache is used, the first request for a store item (via a
.narinfoURL) triggers a background process to bake the archive—computing its.narinfoand compressing the archive, if needed. Once the archive is cached in directory, subsequent requests succeed and are served directly from the cache, which guarantees that clients get the best possible bandwidth.That first
.narinforequest nonetheless returns 200, provided the requested store item is “small enough”, below the cache bypass threshold—see --cache-bypass-threshold below. That way, clients do not have to wait until the archive is baked. For larger store items, the first.narinforequest returns 404, meaning that clients have to wait until the archive is baked.The “baking” process is performed by worker threads. By default, one thread per CPU core is created, but this can be customized. See --workers below.
When --ttl is used, cached entries are automatically deleted when they have expired.
--workers=NWhen --cache is used, request the allocation of N worker threads to “bake” archives.
--ttl=ttlProduce
Cache-ControlHTTP headers that advertise a time-to-live (TTL) of ttl. ttl must denote a duration:5dmeans 5 days,1mmeans 1 month, and so on.This allows the user’s Guix to keep substitute information in cache for ttl. However, note that
guix publishdoes not itself guarantee that the store items it provides will indeed remain available for as long as ttl.Additionally, when --cache is used, cached entries that have not been accessed for ttl and that no longer have a corresponding item in the store, may be deleted.
--manifest=fileSimilarly produce
Cache-ControlHTTP headers to advertise the time-to-live (TTL) of negative lookups—missing store items, for which the HTTP 404 code is returned. By default, no negative TTL is advertised.This parameter can help adjust server load and substitute latency by instructing cooperating clients to be more or less patient when a store item is missing.
--search-paths[=kind]When used in conjunction with --cache, store items smaller than size are immediately available, even when they are not yet in cache. size is a size in bytes, or it can be suffixed by
Mfor megabytes and so on. The default is10M.“Cache bypass” allows you to reduce the publication delay for clients at the expense of possibly additional I/O and CPU use on the server side: depending on the client access patterns, those store items can end up being baked several times until a copy is available in cache.
Increasing the threshold may be useful for sites that have few users, or to guarantee that users get substitutes even for store items that are not popular.
--nar-path=pathUse path as the prefix for the URLs of “nar” files (see normalized archives).
By default, nars are served at a URL such as
/nar/gzip/…-coreutils-8.25. This option allows you to change the/narpart to path.--public-key=file--private-key=fileUse the specific files as the public/private key pair used to sign the store items being published.
The files must correspond to the same key pair (the private key is used for signing and the public key is merely advertised in the signature metadata). They must contain keys in the canonical s-expression format as produced by
guix archive --generate-key(see Вызовguix archive). By default, /etc/guix/signing-key.pub and /etc/guix/signing-key.sec are used.--repl[=port]-r [port]Spawn a Guile REPL server (see REPL Servers in GNU Guile Reference Manual) on port (37146 by default). This is used primarily for debugging a running
guix publishserver.
Enabling guix publish on Guix System is a one-liner: just
instantiate a guix-publish-service-type service in the
services field of the operating-system declaration
(see guix-publish-service-type).
If you are instead running Guix on a “foreign distro”, follow these instructions:
- If your host distro uses the systemd init system:
# ln -s ~root/.guix-profile/lib/systemd/system/guix-publish.service \ /etc/systemd/system/ # systemctl start guix-publish && systemctl enable guix-publish - Если ваш дистрибутив использует систему инициализации Upstart:
# ln -s ~root/.guix-profile/lib/upstart/system/guix-publish.conf /etc/init/ # start guix-publish
- Otherwise, proceed similarly with your distro’s init system.
Next: Вызов guix copy, Previous: Вызов guix publish, Up: Утилиты [Contents][Index]
10.12 Вызов guix challenge
Do the binaries provided by this server really correspond to the source code
it claims to build? Is a package build process deterministic? These are the
questions the guix challenge command attempts to answer.
The former is obviously an important question: Before using a substitute server (see Подстановки), one had better verify that it provides the right binaries, and thus challenge it. The latter is what enables the former: If package builds are deterministic, then independent builds of the package should yield the exact same result, bit for bit; if a server provides a binary different from the one obtained locally, it may be either corrupt or malicious.
We know that the hash that shows up in /gnu/store file names is the
hash of all the inputs of the process that built the file or
directory—compilers, libraries, build scripts,
etc. (see Введение). Assuming deterministic build processes, one
store file name should map to exactly one build output. guix
challenge checks whether there is, indeed, a single mapping by comparing
the build outputs of several independent builds of any given store item.
The command output looks like this:
$ guix challenge \
--substitute-urls="https://ci.guix.gnu.org https://guix.example.org" \
openssl git pius coreutils grep
updating substitutes from 'https://ci.guix.gnu.org'... 100.0%
updating substitutes from 'https://guix.example.org'... 100.0%
/gnu/store/…-openssl-1.0.2d contents differ:
local hash: 0725l22r5jnzazaacncwsvp9kgf42266ayyp814v7djxs7nk963q
https://ci.guix.gnu.org/nar/…-openssl-1.0.2d: 0725l22r5jnzazaacncwsvp9kgf42266ayyp814v7djxs7nk963q
https://guix.example.org/nar/…-openssl-1.0.2d: 1zy4fmaaqcnjrzzajkdn3f5gmjk754b43qkq47llbyak9z0qjyim
differing files:
/lib/libcrypto.so.1.1
/lib/libssl.so.1.1
/gnu/store/…-git-2.5.0 contents differ:
local hash: 00p3bmryhjxrhpn2gxs2fy0a15lnip05l97205pgbk5ra395hyha
https://ci.guix.gnu.org/nar/…-git-2.5.0: 069nb85bv4d4a6slrwjdy8v1cn4cwspm3kdbmyb81d6zckj3nq9f
https://guix.example.org/nar/…-git-2.5.0: 0mdqa9w1p6cmli6976v4wi0sw9r4p5prkj7lzfd1877wk11c9c73
differing file:
/libexec/git-core/git-fsck
/gnu/store/…-pius-2.1.1 contents differ:
local hash: 0k4v3m9z1zp8xzzizb7d8kjj72f9172xv078sq4wl73vnq9ig3ax
https://ci.guix.gnu.org/nar/…-pius-2.1.1: 0k4v3m9z1zp8xzzizb7d8kjj72f9172xv078sq4wl73vnq9ig3ax
https://guix.example.org/nar/…-pius-2.1.1: 1cy25x1a4fzq5rk0pmvc8xhwyffnqz95h2bpvqsz2mpvlbccy0gs
differing file:
/share/man/man1/pius.1.gz
…
5 store items were analyzed:
- 2 (40.0%) were identical
- 3 (60.0%) differed
- 0 (0.0%) were inconclusive
In this example, guix challenge queries all the substitute servers
for each of the fives packages specified on the command line. It then
reports those store items for which the servers obtained a result different
from the local build (if it exists) and/or different from one another; here,
the ‘local hash’ lines indicate that a local build result was available
for each of these packages and shows its hash.
As an example, guix.example.org always gets a different answer.
Conversely, ci.guix.gnu.org agrees with local builds,
except in the case of Git. This might indicate that the build process of
Git is non-deterministic, meaning that its output varies as a function of
various things that Guix does not fully control, in spite of building
packages in isolated environments (see Особенности). Most common sources
of non-determinism include the addition of timestamps in build results, the
inclusion of random numbers, and directory listings sorted by inode number.
See https://reproducible-builds.org/docs/, for more information.
To find out what is wrong with this Git binary, the easiest approach is to run:
guix challenge git \ --diff=diffoscope \ --substitute-urls="https://ci.guix.gnu.org https://guix.example.org"
This automatically invokes diffoscope, which displays detailed
information about files that differ.
Alternatively, we can do something along these lines (see Вызов guix archive):
$ wget -q -O - https://ci.guix.gnu.org/nar/lzip/…-git-2.5.0 \ | lzip -d | guix archive -x /tmp/git $ diff -ur --no-dereference /gnu/store/…-git.2.5.0 /tmp/git
This command shows the difference between the files resulting from the local
build, and the files resulting from the build on
ci.guix.gnu.org (see Comparing and Merging
Files in Comparing and Merging Files). The diff
command works great for text files. When binary files differ, a better
option is Diffoscope, a tool that helps
visualize differences for all kinds of files.
Once you have done that work, you can tell whether the differences are due
to a non-deterministic build process or to a malicious server. We try hard
to remove sources of non-determinism in packages to make it easier to verify
substitutes, but of course, this is a process that involves not just Guix,
but a large part of the free software community. In the meantime,
guix challenge is one tool to help address the problem.
If you are writing packages for Guix, you are encouraged to check whether
ci.guix.gnu.org and other substitute servers obtain the
same build result as you did with:
guix challenge package
Основной синтаксис:
guix challenge options argument…
where argument is a package specification such as guile@2.0 or
glibc:debug or, alternatively, a store file name as returned, for
example, by guix build or guix gc --list-live.
When a difference is found between the hash of a locally-built item and that of a server-provided substitute, or among substitutes provided by different servers, the command displays it as in the example above and its exit code is 2 (other non-zero exit codes denote other kinds of errors).
The one option that matters is:
--substitute-urls=urlsConsider urls the whitespace-separated list of substitute source URLs to compare to.
--load=fileUpon mismatches, show differences according to mode, one of:
speed(default:1.0)Вывести список живых файлов и директорий склада.
diffoscope- command
Invoke Diffoscope, passing it two directories whose contents do not match.
When command is an absolute file name, run command instead of Diffoscope.
noneDo not show further details about the differences.
Thus, unless --diff=none is passed,
guix challengedownloads the store items from the given substitute servers so that it can compare them.--verbose-vShow details about matches (identical contents) in addition to information about mismatches.
Next: Вызов guix container, Previous: Вызов guix challenge, Up: Утилиты [Contents][Index]
10.13 Вызов guix copy
The guix copy command copies items from the store of one machine
to that of another machine over a secure shell (SSH)
connection25. For example, the following
command copies the coreutils package, the user’s profile, and all
their dependencies over to host, logged in as user:
guix graph -t references `readlink -f ~/.guix-profile`
If some of the items to be copied are already present on host, they are not actually sent.
The command below retrieves libreoffice and gimp from
host, assuming they are available there:
guix copy --from=host libreoffice gimp
The SSH connection is established using the Guile-SSH client, which is compatible with OpenSSH: it honors ~/.ssh/known_hosts and ~/.ssh/config, and uses the SSH agent for authentication.
The key used to sign items that are sent must be accepted by the remote
machine. Likewise, the key used by the remote machine to sign items you are
retrieving must be in /etc/guix/acl so it is accepted by your own
daemon. See Вызов guix archive, for more information about store item
authentication.
Основной синтаксис:
guix copy [--to=spec|--from=spec] items…
You must always specify one of the following options:
--to=spec--from=specSpecify the host to send to or receive from. spec must be an SSH spec such as
example.org,charlie@example.org, orcharlie@example.org:2222.
The items can be either package names, such as gimp, or store
items, such as /gnu/store/…-idutils-4.6.
When specifying the name of a package to send, it is first built if needed, unless --dry-run was specified. Common build options are supported (see Стандартные параметры сборки).
Next: Вызов guix weather, Previous: Вызов guix copy, Up: Утилиты [Contents][Index]
10.14 Вызов guix container
Примечание: As of version 1.4.0, this tool is experimental. The interface is subject to radical change in the future.
The purpose of guix container is to manipulate processes running
within an isolated environment, commonly known as a “container”, typically
created by the guix shell (see Вызов guix shell) and
guix system container (see Invoking guix system) commands.
Основной синтаксис:
guix container action options…
action specifies the operation to perform with a container, and options specifies the context-specific arguments for the action.
The following actions are available:
execExecute a command within the context of a running container.
The syntax is:
guix container exec pid program arguments…
pid specifies the process ID of the running container. program specifies an executable file name within the root file system of the container. arguments are the additional options that will be passed to program.
The following command launches an interactive login shell inside a Guix system container, started by
guix system container, and whose process ID is 9001:guix container exec 9001 /run/current-system/profile/bin/bash --login
Note that the pid cannot be the parent process of a container. It must be PID 1 of the container or one of its child processes.
Next: Вызов guix processes, Previous: Вызов guix container, Up: Утилиты [Contents][Index]
10.15 Вызов guix weather
Occasionally you’re grumpy because substitutes are lacking and you end up
building packages by yourself (see Подстановки). The guix
weather command reports on substitute availability on the specified servers
so you can have an idea of whether you’ll be grumpy today. It can sometimes
be useful info as a user, but it is primarily useful to people running
guix publish (see Вызов guix publish).
Here’s a sample run:
$ guix weather --substitute-urls=https://guix.example.org
computing 5,872 package derivations for x86_64-linux...
looking for 6,128 store items on https://guix.example.org..
updating substitutes from 'https://guix.example.org'... 100.0%
https://guix.example.org
43.4% substitutes available (2,658 out of 6,128)
7,032.5 MiB of nars (compressed)
19,824.2 MiB on disk (uncompressed)
0.030 seconds per request (182.9 seconds in total)
33.5 requests per second
9.8% (342 out of 3,470) of the missing items are queued
867 queued builds
x86_64-linux: 518 (59.7%)
i686-linux: 221 (25.5%)
aarch64-linux: 128 (14.8%)
build rate: 23.41 builds per hour
x86_64-linux: 11.16 builds per hour
i686-linux: 6.03 builds per hour
aarch64-linux: 6.41 builds per hour
As you can see, it reports the fraction of all the packages for which
substitutes are available on the server—regardless of whether substitutes
are enabled, and regardless of whether this server’s signing key is
authorized. It also reports the size of the compressed archives (“nars”)
provided by the server, the size the corresponding store items occupy in the
store (assuming deduplication is turned off), and the server’s throughput.
The second part gives continuous integration (CI) statistics, if the server
supports it. In addition, using the --coverage option,
guix weather can list “important” package substitutes missing on
the server (see below).
To achieve that, guix weather queries over HTTP(S) meta-data
(narinfos) for all the relevant store items. Like guix
challenge, it ignores signatures on those substitutes, which is innocuous
since the command only gathers statistics and cannot install those
substitutes.
Основной синтаксис:
guix environment options package…
When packages is omitted, guix weather checks the
availability of substitutes for all the packages, or for those
specified with --manifest; otherwise it only considers the
specified packages. It is also possible to query specific system types with
--system. guix weather exits with a non-zero code when
the fraction of available substitutes is below 100%.
Доступные опции резюмированы ниже.
--substitute-urls=urlsurls is the space-separated list of substitute server URLs to query. When this option is omitted, the default set of substitute servers is queried.
--system=system-s systemQuery substitutes for system—e.g.,
aarch64-linux. This option can be repeated, in which caseguix weatherwill query substitutes for several system types.--manifest=fileInstead of querying substitutes for all the packages, only ask for those specified in file. file must contain a manifest, as with the
-moption ofguix package(see Вызовguix package).Создать окружение для пакетов, содержащихся в объекте манифеста, возвращаемого кодом Scheme в файле file.
--coverage[=count]-c [count]Report on substitute coverage for packages: list packages with at least count dependents (zero by default) for which substitutes are unavailable. Dependent packages themselves are not listed: if b depends on a and a has no substitutes, only a is listed, even though b usually lacks substitutes as well. The result looks like this:
$ guix weather --substitute-urls=https://ci.guix.gnu.org https://bordeaux.guix.gnu.org -c 10 computing 8,983 package derivations for x86_64-linux... looking for 9,343 store items on https://ci.guix.gnu.org https://bordeaux.guix.gnu.org... updating substitutes from 'https://ci.guix.gnu.org https://bordeaux.guix.gnu.org'... 100.0% https://ci.guix.gnu.org https://bordeaux.guix.gnu.org 64.7% substitutes available (6,047 out of 9,343) … 2502 packages are missing from 'https://ci.guix.gnu.org https://bordeaux.guix.gnu.org' for 'x86_64-linux', among which: 58 kcoreaddons@5.49.0 /gnu/store/…-kcoreaddons-5.49.0 46 qgpgme@1.11.1 /gnu/store/…-qgpgme-1.11.1 37 perl-http-cookiejar@0.008 /gnu/store/…-perl-http-cookiejar-0.008 …What this example shows is that
kcoreaddonsand presumably the 58 packages that depend on it have no substitutes atci.guix.gnu.org; likewise forqgpgmeand the 46 packages that depend on it.If you are a Guix developer, or if you are taking care of this build farm, you’ll probably want to have a closer look at these packages: they may simply fail to build.
--missingDisplay the list of store items for which substitutes are missing.
Previous: Вызов guix weather, Up: Утилиты [Contents][Index]
10.16 Вызов guix processes
The guix processes command can be useful to developers and system
administrators, especially on multi-user machines and on build farms: it
lists the current sessions (connections to the daemon), as well as
information about the processes involved26. Here’s an example of the information it
returns:
$ sudo guix processes SessionPID: 19002 ClientPID: 19090 ClientCommand: guix shell python SessionPID: 19402 ClientPID: 19367 ClientCommand: guix publish -u guix-publish -p 3000 -C 9 … SessionPID: 19444 ClientPID: 19419 ClientCommand: cuirass --cache-directory /var/cache/cuirass … LockHeld: /gnu/store/…-perl-ipc-cmd-0.96.lock LockHeld: /gnu/store/…-python-six-bootstrap-1.11.0.lock LockHeld: /gnu/store/…-libjpeg-turbo-2.0.0.lock ChildPID: 20495 ChildCommand: guix offload x86_64-linux 7200 1 28800 ChildPID: 27733 ChildCommand: guix offload x86_64-linux 7200 1 28800 ChildPID: 27793 ChildCommand: guix offload x86_64-linux 7200 1 28800
In this example we see that guix-daemon has three clients:
guix environment, guix publish, and the Cuirass
continuous integration tool; their process identifier (PID) is given by the
ClientPID field. The SessionPID field gives the PID of the
guix-daemon sub-process of this particular session.
The LockHeld fields show which store items are currently locked by
this session, which corresponds to store items being built or substituted
(the LockHeld field is not displayed when guix processes is
not running as root). Last, by looking at the ChildPID and
ChildCommand fields, we understand that these three builds are being
offloaded (see Использование функционала разгрузки).
The output is in Recutils format so we can use the handy recsel
command to select sessions of interest (see Selection Expressions in GNU recutils manual). As an example, the command shows the
command line and PID of the client that triggered the build of a Perl
package:
$ sudo guix processes | \
recsel -p ClientPID,ClientCommand -e 'LockHeld ~ "perl"'
ClientPID: 19419
ClientCommand: cuirass --cache-directory /var/cache/cuirass …
Доступные опции резюмированы ниже.
--format=format-f formatПроизвести вывод в указанном формате format, одном из:
recutilsThe default option. It outputs a set of Session recutils records that include each
ChildProcessas a field.normalizedNormalize the output records into record sets (see Record Sets in GNU recutils manual). Normalizing into record sets allows joins across record types. The example below lists the PID of each
ChildProcessand the associated PID forSessionthat spawned theChildProcesswhere theSessionwas started usingguix build.$ guix processes --format=normalized | \ recsel \ -j Session \ -t ChildProcess \ -p Session.PID,PID \ -e 'Session.ClientCommand ~ "guix build"' PID: 4435 Session_PID: 4278 PID: 4554 Session_PID: 4278 PID: 4646 Session_PID: 4278
Next: Конфигурирование системы, Previous: Утилиты, Up: GNU Guix [Contents][Index]
11 Foreign Architectures
You can target computers of different CPU architectures when producing
packages (see Вызов guix package), packs (see Вызов guix pack)
or full systems (see Invoking guix system).
GNU Guix supports two distinct mechanisms to target foreign architectures:
- The traditional cross-compilation mechanism.
- The native building mechanism which consists in building using the CPU instruction set of the foreign system you are targeting. It often requires emulation, using the QEMU program for instance.
Next: Native Builds, Up: Foreign Architectures [Contents][Index]
11.1 Cross-Compilation
The commands supporting cross-compilation are proposing the --list-targets and --target options.
The --list-targets option lists all the supported targets that can be passed as an argument to --target.
$ guix build --list-targets The available targets are: - aarch64-linux-gnu - arm-linux-gnueabihf - i586-pc-gnu - i686-linux-gnu - i686-w64-mingw32 - mips64el-linux-gnu - powerpc-linux-gnu - powerpc64le-linux-gnu - riscv64-linux-gnu - x86_64-linux-gnu - x86_64-w64-mingw32
Targets are specified as GNU triplets (see GNU configuration triplets in Autoconf).
Those triplets are passed to GCC and the other underlying compilers possibly involved when building a package, a system image or any other GNU Guix output.
$ guix build --target=aarch64-linux-gnu hello /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12 $ file /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12/bin/hello /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12/bin/hello: ELF 64-bit LSB executable, ARM aarch64 …
The major benefit of cross-compilation is that there are no performance penaly compared to emulation using QEMU. There are however higher risks that some packages fail to cross-compile because few users are using this mechanism extensively.
Previous: Cross-Compilation, Up: Foreign Architectures [Contents][Index]
11.2 Native Builds
The commands that support impersonating a specific system have the --list-systems and --system options.
The --list-systems option lists all the supported systems that can be passed as an argument to --system.
$ guix build --list-systems The available systems are: - x86_64-linux [current] - aarch64-linux - armhf-linux - i586-gnu - i686-linux - mips64el-linux - powerpc-linux - powerpc64le-linux - riscv64-linux $ guix build --system=i686-linux hello /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12 $ file /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12/bin/hello /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12/bin/hello: ELF 32-bit LSB executable, Intel 80386 …
In the above example, the current system is x86_64-linux. The hello package is however built for the i686-linux system.
This is possible because the i686 CPU instruction set is a subset of the x86_64, hence i686 targeting binaries can be run on x86_64.
Still in the context of the previous example, if picking the
aarch64-linux system and the guix build
--system=aarch64-linux hello has to build some derivations, an extra step
might be needed.
The aarch64-linux targeting binaries cannot directly be run on a x86_64-linux system. An emulation layer is requested. The GNU Guix daemon can take advantage of the Linux kernel binfmt_misc mechanism for that. In short, the Linux kernel can defer the execution of a binary targeting a foreign platform, here aarch64-linux, to a userspace program, usually an emulator.
There is a service that registers QEMU as a backend for the
binfmt_misc mechanism (see qemu-binfmt-service-type). On Debian based foreign distributions,
the alternative would be the qemu-user-static package.
If the binfmt_misc mechanism is not setup correctly, the building
will fail this way:
$ guix build --system=armhf-linux hello --check … unsupported-platform /gnu/store/jjn969pijv7hff62025yxpfmc8zy0aq0-hello-2.12.drv aarch64-linux while setting up the build environment: a `aarch64-linux' is required to build `/gnu/store/jjn969pijv7hff62025yxpfmc8zy0aq0-hello-2.12.drv', but I am a `x86_64-linux'…
whereas, with the binfmt_misc mechanism correctly linked with QEMU,
one can expect to see:
$ guix build --system=armhf-linux hello --check /gnu/store/13xz4nghg39wpymivlwghy08yzj97hlj-hello-2.12
The main advantage of native building compared to cross-compiling, is that more packages are likely to build correctly. However it comes at a price: compilation backed by QEMU is way slower than cross-compilation, because every instruction needs to be emulated.
The availability of substitutes for the architecture targeted by the
--system option can mitigate this problem. An other way to work
around it is to install GNU Guix on a machine whose CPU supports the
targeted instruction set, and set it up as an offload machine (see Использование функционала разгрузки).
Next: Home Configuration, Previous: Foreign Architectures, Up: GNU Guix [Contents][Index]
12 Конфигурирование системы
Guix System supports a consistent whole-system configuration mechanism. By that we mean that all aspects of the global system configuration—such as the available system services, timezone and locale settings, user accounts—are declared in a single place. Such a system configuration can be instantiated—i.e., effected.
One of the advantages of putting all the system configuration under the control of Guix is that it supports transactional system upgrades, and makes it possible to roll back to a previous system instantiation, should something go wrong with the new one (see Особенности). Another advantage is that it makes it easy to replicate the exact same configuration across different machines, or at different points in time, without having to resort to additional administration tools layered on top of the own tools of the system.
This section describes this mechanism. First we focus on the system administrator’s viewpoint—explaining how the system is configured and instantiated. Then we show how this mechanism can be extended, for instance to support new system services.
- Использование системы конфигурации
operating-systemReference- Файловые системы
- Размеченные устройства
- Swap Space
- Учётные записи пользователей
- Раскладка клавиатуры
- Региональные настройки
- Сервисы
- Программы setuid
- Сертификаты X.509
- Служба выбора имён
- Начальный RAM-диск
- Настройка загрузчика
- Invoking
guix system - Invoking
guix deploy - Running Guix in a Virtual Machine
- Создание служб
Next: operating-system Reference, Up: Конфигурирование системы [Contents][Index]
12.1 Использование системы конфигурации
The operating system is configured by providing an operating-system
declaration in a file that can then be passed to the guix system
command (see Invoking guix system). A simple setup, with the default
system services, the default Linux-Libre kernel, initial RAM disk, and boot
loader looks like this:
;; This is an operating system configuration template ;; for a "bare bones" setup, with no X11 display server. (use-modules (gnu)) (use-service-modules networking ssh) (use-package-modules screen ssh) (operating-system (host-name "komputilo") (timezone "Europe/Berlin") (locale "en_US.utf8") ;; Boot in "legacy" BIOS mode, assuming /dev/sdX is the ;; target hard disk, and "my-root" is the label of the target ;; root file system. (bootloader (bootloader-configuration (bootloader grub-bootloader) (targets '("/dev/sdX")))) ;; It's fitting to support the equally bare bones ‘-nographic’ ;; QEMU option, which also nicely sidesteps forcing QWERTY. (kernel-arguments (list "console=ttyS0,115200")) (file-systems (cons (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4")) %base-file-systems)) ;; This is where user accounts are specified. The "root" ;; account is implicit, and is initially created with the ;; empty password. (users (cons (user-account (name "alice") (comment "Bob's sister") (group "users") ;; Adding the account to the "wheel" group ;; makes it a sudoer. Adding it to "audio" ;; and "video" allows the user to play sound ;; and access the webcam. (supplementary-groups '("wheel" "audio" "video"))) %base-user-accounts)) ;; Globally-installed packages. (packages (cons screen %base-packages)) ;; Add services to the baseline: a DHCP client and ;; an SSH server. (services (append (list (service dhcp-client-service-type) (service openssh-service-type (openssh-configuration (openssh openssh-sans-x) (port-number 2222)))) %base-services)))
This example should be self-describing. Some of the fields defined above,
such as host-name and bootloader, are mandatory. Others, such
as packages and services, can be omitted, in which case they
get a default value.
Below we discuss the effect of some of the most important fields
(see operating-system Reference, for details about all the available
fields), and how to instantiate the operating system using
guix system.
- Bootloader
- Globally-Visible Packages
- System Services
- Instantiating the System
- The Programming Interface
Bootloader
The bootloader field describes the method that will be used to boot
your system. Machines based on Intel processors can boot in “legacy” BIOS
mode, as in the example above. However, more recent machines rely instead
on the Unified Extensible Firmware Interface (UEFI) to boot. In that
case, the bootloader field should contain something along these
lines:
(bootloader-configuration
(bootloader grub-efi-bootloader)
(targets '("/boot/efi")))
See Настройка загрузчика, for more information on the available configuration options.
Globally-Visible Packages
The packages field lists packages that will be globally visible on
the system, for all user accounts—i.e., in every user’s PATH
environment variable—in addition to the per-user profiles (see Вызов guix package). The %base-packages variable provides all the tools
one would expect for basic user and administrator tasks—including the GNU
Core Utilities, the GNU Networking Utilities, the mg lightweight
text editor, find, grep, etc. The example above adds
GNU Screen to those, taken from the (gnu packages screen) module
(see Пакетные модули). The (list package output) syntax can be
used to add a specific output of a package:
(use-modules (gnu packages)) (use-modules (gnu packages dns)) (operating-system ;; ... (packages (cons (list isc-bind "utils") %base-packages)))
Referring to packages by variable name, like isc-bind above, has the
advantage of being unambiguous; it also allows typos and such to be
diagnosed right away as “unbound variables”. The downside is that one
needs to know which module defines which package, and to augment the
use-package-modules line accordingly. To avoid that, one can use the
specification->package procedure of the (gnu packages) module,
which returns the best package for a given name or name and version:
(use-modules (gnu packages)) (operating-system ;; ... (packages (append (map specification->package '("tcpdump" "htop" "gnupg@2.0")) %base-packages)))
System Services
The services field lists system services to be made available
when the system starts (see Сервисы). The operating-system
declaration above specifies that, in addition to the basic services, we want
the OpenSSH secure shell daemon listening on port 2222 (see openssh-service-type). Under the hood,
openssh-service-type arranges so that sshd is started with
the right command-line options, possibly with supporting configuration files
generated as needed (see Создание служб).
Occasionally, instead of using the base services as is, you will want to
customize them. To do this, use modify-services (see modify-services) to modify the list.
For example, suppose you want to modify guix-daemon and Mingetty (the
console log-in) in the %base-services list (see %base-services). To do that, you can write the following in your
operating system declaration:
(define %my-services ;; My very own list of services. (modify-services %base-services (guix-service-type config => (guix-configuration (inherit config) ;; Fetch substitutes from example.org. (substitute-urls (list "https://example.org/guix" "https://ci.guix.gnu.org")))) (mingetty-service-type config => (mingetty-configuration (inherit config) ;; Automatically log in as "guest". (auto-login "guest"))))) (operating-system ;; … (services %my-services))
This changes the configuration—i.e., the service parameters—of the
guix-service-type instance, and that of all the
mingetty-service-type instances in the %base-services list
(see see the cookbook for how to auto-login
one user to a specific TTY in GNU Guix Cookbook)). Observe
how this is accomplished: first, we arrange for the original configuration
to be bound to the identifier config in the body, and then we
write the body so that it evaluates to the desired configuration. In
particular, notice how we use inherit to create a new configuration
which has the same values as the old configuration, but with a few
modifications.
The configuration for a typical “desktop” usage, with an encrypted root partition, a swap file on the root partition, the X11 display server, GNOME and Xfce (users can choose which of these desktop environments to use at the log-in screen by pressing F1), network management, power management, and more, would look like this:
;; This is an operating system configuration template ;; for a "desktop" setup with GNOME and Xfce where the ;; root partition is encrypted with LUKS, and a swap file. (use-modules (gnu) (gnu system nss) (guix utils)) (use-service-modules desktop sddm xorg) (use-package-modules certs gnome) (operating-system (host-name "antelope") (timezone "Europe/Paris") (locale "en_US.utf8") ;; Choose US English keyboard layout. The "altgr-intl" ;; variant provides dead keys for accented characters. (keyboard-layout (keyboard-layout "us" "altgr-intl")) ;; Use the UEFI variant of GRUB with the EFI System ;; Partition mounted on /boot/efi. (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")) (keyboard-layout keyboard-layout))) ;; Specify a mapped device for the encrypted root partition. ;; The UUID is that returned by 'cryptsetup luksUUID'. (mapped-devices (list (mapped-device (source (uuid "12345678-1234-1234-1234-123456789abc")) (target "my-root") (type luks-device-mapping)))) (file-systems (append (list (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4") (dependencies mapped-devices)) (file-system (device (uuid "1234-ABCD" 'fat)) (mount-point "/boot/efi") (type "vfat"))) %base-file-systems)) ;; Specify a swap file for the system, which resides on the ;; root file system. (swap-devices (list (swap-space (target "/swapfile")))) ;; Create user `bob' with `alice' as its initial password. (users (cons (user-account (name "bob") (comment "Alice's brother") (password (crypt "alice" "$6$abc")) (group "students") (supplementary-groups '("wheel" "netdev" "audio" "video"))) %base-user-accounts)) ;; Add the `students' group (groups (cons* (user-group (name "students")) %base-groups)) ;; This is where we specify system-wide packages. (packages (append (list ;; for HTTPS access nss-certs ;; for user mounts gvfs) %base-packages)) ;; Add GNOME and Xfce---we can choose at the log-in screen ;; by clicking the gear. Use the "desktop" services, which ;; include the X11 log-in service, networking with ;; NetworkManager, and more. (services (if (target-x86-64?) (append (list (service gnome-desktop-service-type) (service xfce-desktop-service-type) (set-xorg-configuration (xorg-configuration (keyboard-layout keyboard-layout)))) %desktop-services) ;; FIXME: Since GDM depends on Rust (gdm -> gnome-shell -> gjs ;; -> mozjs -> rust) and Rust is currently unavailable on ;; non-x86_64 platforms, we use SDDM and Mate here instead of ;; GNOME and GDM. (append (list (service mate-desktop-service-type) (service xfce-desktop-service-type) (set-xorg-configuration (xorg-configuration (keyboard-layout keyboard-layout)) sddm-service-type)) %desktop-services))) ;; Allow resolution of '.local' host names with mDNS. (name-service-switch %mdns-host-lookup-nss))
A graphical system with a choice of lightweight window managers instead of full-blown desktop environments would look like this:
;; This is an operating system configuration template ;; for a "desktop" setup without full-blown desktop ;; environments. (use-modules (gnu) (gnu system nss)) (use-service-modules desktop) (use-package-modules bootloaders certs emacs emacs-xyz ratpoison suckless wm xorg) (operating-system (host-name "antelope") (timezone "Europe/Paris") (locale "en_US.utf8") ;; Use the UEFI variant of GRUB with the EFI System ;; Partition mounted on /boot/efi. (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")))) ;; Assume the target root file system is labelled "my-root", ;; and the EFI System Partition has UUID 1234-ABCD. (file-systems (append (list (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4")) (file-system (device (uuid "1234-ABCD" 'fat)) (mount-point "/boot/efi") (type "vfat"))) %base-file-systems)) (users (cons (user-account (name "alice") (comment "Bob's sister") (group "users") (supplementary-groups '("wheel" "netdev" "audio" "video"))) %base-user-accounts)) ;; Add a bunch of window managers; we can choose one at ;; the log-in screen with F1. (packages (append (list ;; window managers ratpoison i3-wm i3status dmenu emacs emacs-exwm emacs-desktop-environment ;; terminal emulator xterm ;; for HTTPS access nss-certs) %base-packages)) ;; Use the "desktop" services, which include the X11 ;; log-in service, networking with NetworkManager, and more. (services %desktop-services) ;; Allow resolution of '.local' host names with mDNS. (name-service-switch %mdns-host-lookup-nss))
This example refers to the /boot/efi file system by its UUID,
1234-ABCD. Replace this UUID with the right UUID on your system, as
returned by the blkid command.
See Сервисы рабочего стола, for the exact list of services provided by
%desktop-services. See Сертификаты X.509, for background
information about the nss-certs package that is used here.
Again, %desktop-services is just a list of service objects. If you
want to remove services from there, you can do so using the procedures for
list filtering (see SRFI-1 Filtering and Partitioning in GNU Guile
Reference Manual). For instance, the following expression returns a list
that contains all the services in %desktop-services minus the Avahi
service:
(remove (lambda (service)
(eq? (service-kind service) avahi-service-type))
%desktop-services)
Alternatively, the modify-services macro can be used:
Instantiating the System
Assuming the operating-system declaration is stored in the
my-system-config.scm file, the guix system reconfigure
my-system-config.scm command instantiates that configuration, and makes it
the default GRUB boot entry (see Invoking guix system).
Примечание: We recommend that you keep this my-system-config.scm file safe and under version control to easily track changes to your configuration.
The normal way to change the system configuration is by updating this file
and re-running guix system reconfigure. One should never have to
touch files in /etc or to run commands that modify the system state
such as useradd or grub-install. In fact, you must
avoid that since that would not only void your warranty but also prevent you
from rolling back to previous versions of your system, should you ever need
to.
Speaking of roll-back, each time you run guix system reconfigure,
a new generation of the system is created—without modifying or
deleting previous generations. Old system generations get an entry in the
bootloader boot menu, allowing you to boot them in case something went wrong
with the latest generation. Reassuring, no? The guix system
list-generations command lists the system generations available on disk.
It is also possible to roll back the system via the commands guix
system roll-back and guix system switch-generation.
Although the guix system reconfigure command will not modify
previous generations, you must take care when the current generation is not
the latest (e.g., after invoking guix system roll-back), since the
operation might overwrite a later generation (see Invoking guix system).
The Programming Interface
At the Scheme level, the bulk of an operating-system declaration is
instantiated with the following monadic procedure (see Устройство склада):
- Monadic Procedure: operating-system-derivation os
Return a derivation that builds os, an
operating-systemobject (see Деривации).The output of the derivation is a single directory that refers to all the packages, configuration files, and other supporting files needed to instantiate os.
This procedure is provided by the (gnu system) module. Along with
(gnu services) (see Сервисы), this module contains the guts of
Guix System. Make sure to visit it!
Next: Файловые системы, Previous: Использование системы конфигурации, Up: Конфигурирование системы [Contents][Index]
12.2 operating-system Reference
This section summarizes all the options available in operating-system
declarations (see Использование системы конфигурации).
- Data Type: operating-system
This is the data type representing an operating system configuration. By that, we mean all the global system configuration, not per-user configuration (see Использование системы конфигурации).
port(default:22)The package object of the operating system kernel to use27.
speed(default:1.0)The package object of the Hurd to be started by the kernel. When this field is set, produce a GNU/Hurd operating system. In that case,
kernelmust also be set to thegnumachpackage—the microkernel the Hurd runs on.Внимание: This feature is experimental and only supported for disk images.
features(default:'())A list of objects (usually packages) to collect loadable kernel modules from–e.g.
(list ddcci-driver-linux).features(default:'())List of strings or gexps representing additional arguments to pass on the command-line of the kernel—e.g.,
("console=ttyS0").bootloaderThe system bootloader configuration object. See Настройка загрузчика.
labelThis is the label (a string) as it appears in the bootloader’s menu entry. The default label includes the kernel name and version.
keyboard-layout(default:#f)This field specifies the keyboard layout to use in the console. It can be either
#f, in which case the default keyboard layout is used (usually US English), or a<keyboard-layout>record. See Раскладка клавиатуры, for more information.This keyboard layout is in effect as soon as the kernel has booted. For instance, it is the keyboard layout in effect when you type a passphrase if your root file system is on a
luks-device-mappingmapped device (see Размеченные устройства).Примечание: This does not specify the keyboard layout used by the bootloader, nor that used by the graphical display server. See Настройка загрузчика, for information on how to specify the bootloader’s keyboard layout. See Оконная система X, for information on how to specify the keyboard layout used by the X Window System.
initrd-modules(default:%base-initrd-modules) ¶-
The list of Linux kernel modules that need to be available in the initial RAM disk. See Начальный RAM-диск.
initrd(default:base-initrd)A procedure that returns an initial RAM disk for the Linux kernel. This field is provided to support low-level customization and should rarely be needed for casual use. See Начальный RAM-диск.
port(default:22) ¶List of firmware packages loadable by the operating system kernel.
The default includes firmware needed for Atheros- and Broadcom-based WiFi devices (Linux-libre modules
ath9kandb43-open, respectively). See По поводу железа, for more info on supported hardware.host-nameThe host name.
hosts-file¶A file-like object (see file-like objects) for use as /etc/hosts (see Host Names in The GNU C Library Reference Manual). The default is a file with entries for
localhostand host-name.mapped-devices(default:'())A list of mapped devices. See Размеченные устройства.
file-systemsA list of file systems. See Файловые системы.
swap-devices(default:'()) ¶A list of swap spaces. See Swap Space.
users(default:%base-user-accounts)port(default:22)List of user accounts and groups. See Учётные записи пользователей.
If the
userslist lacks a user account with UID 0, a “root” account with UID 0 is automatically added.skeletons(default:(default-skeletons))A list of target file name/file-like object tuples (see file-like objects). These are the skeleton files that will be added to the home directory of newly-created user accounts.
For instance, a valid value may look like this:
`((".bashrc" ,(plain-file "bashrc" "echo Hello\n")) (".guile" ,(plain-file "guile" "(use-modules (ice-9 readline)) (activate-readline)")))
port(default:22)A string denoting the contents of the /etc/issue file, which is displayed when users log in on a text console.
speed(default:1.0)A list of packages to be installed in the global profile, which is accessible at /run/current-system/profile. Each element is either a package variable or a package/output tuple. Here’s a simple example of both:
(cons* git ; the default "out" output (list git "send-email") ; another output of git %base-packages) ; the default set
The default set includes core utilities and it is good practice to install non-core utilities in user profiles (see Вызов
guix package).timezone(default:"Etc/UTC")A timezone identifying string—e.g.,
"Europe/Paris".You can run the
tzselectcommand to find out which timezone string corresponds to your region. Choosing an invalid timezone name causesguix systemto fail.locale(default:"en_US.utf8")The name of the default locale (see Locale Names in The GNU C Library Reference Manual). See Региональные настройки, for more information.
features(default:'())The list of locale definitions to be compiled and that may be used at run time. See Региональные настройки.
locale-libcs(default:(list glibc))The list of GNU libc packages whose locale data and tools are used to build the locale definitions. See Региональные настройки, for compatibility considerations that justify this option.
port(default:22)Configuration of the libc name service switch (NSS)—a
<name-service-switch>object. See Служба выбора имён, for details.speed(default:1.0)A list of service objects denoting system services. See Сервисы.
essential-services(default: ...)The list of “essential services”—i.e., things like instances of
system-service-typeandhost-name-service-type(see Интерфейс сервиса), which are derived from the operating system definition itself. As a user you should never need to touch this field.pam-services(default:(base-pam-services)) ¶-
Linux pluggable authentication module (PAM) services.
port(default:22)List of
<setuid-program>. See Программы setuid, for more information.speed(default:1.0) ¶The contents of the /etc/sudoers file as a file-like object (see
local-fileandplain-file).This file specifies which users can use the
sudocommand, what they are allowed to do, and what privileges they may gain. The default is that onlyrootand members of thewheelgroup may usesudo.
- Scheme Syntax: this-operating-system
When used in the lexical scope of an operating system field definition, this identifier resolves to the operating system being defined.
The example below shows how to refer to the operating system being defined in the definition of the
labelfield:(use-modules (gnu) (guix)) (operating-system ;; ... (label (package-full-name (operating-system-kernel this-operating-system))))
It is an error to refer to
this-operating-systemoutside an operating system definition.
Next: Размеченные устройства, Previous: operating-system Reference, Up: Конфигурирование системы [Contents][Index]
12.3 Файловые системы
The list of file systems to be mounted is specified in the
file-systems field of the operating system declaration (see Использование системы конфигурации). Each file system is declared using the
file-system form, like this:
(file-system
(mount-point "/home")
(device "/dev/sda3")
(type "ext4"))
As usual, some of the fields are mandatory—those shown in the example above—while others can be omitted. These are described below.
- Data Type: file-system
Objects of this type represent file systems to be mounted. They contain the following members:
typeThis is a string specifying the type of the file system—e.g.,
"ext4".mount-pointThis designates the place where the file system is to be mounted.
deviceThis names the “source” of the file system. It can be one of three things: a file system label, a file system UUID, or the name of a /dev node. Labels and UUIDs offer a way to refer to file systems without having to hard-code their actual device name28.
File system labels are created using the
file-system-labelprocedure, UUIDs are created usinguuid, and /dev node are plain strings. Here’s an example of a file system referred to by its label, as shown by thee2labelcommand:(file-system (mount-point "/home") (type "ext4") (device (file-system-label "my-home")))UUIDs are converted from their string representation (as shown by the
tune2fs -lcommand) using theuuidform29, like this:(file-system (mount-point "/home") (type "ext4") (device (uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb")))When the source of a file system is a mapped device (see Размеченные устройства), its
devicefield must refer to the mapped device name—e.g., "/dev/mapper/root-partition". This is required so that the system knows that mounting the file system depends on having the corresponding device mapping established.flags(default:'())This is a list of symbols denoting mount flags. Recognized flags include
read-only,bind-mount,no-dev(disallow access to special files),no-suid(ignore setuid and setgid bits),no-atime(do not update file access times),no-diratime(likewise for directories only),strict-atime(update file access time),lazy-time(only update time on the in-memory version of the file inode),no-exec(disallow program execution), andshared(make the mount shared). See Mount-Unmount-Remount in The GNU C Library Reference Manual, for more information on these flags.options(default:#f)This is either
#f, or a string denoting mount options passed to the file system driver. See Mount-Unmount-Remount in The GNU C Library Reference Manual, for details.Run
man 8 mountfor options for various file systems, but beware that what it lists as file-system-independent “mount options” are in fact flags, and belong in theflagsfield described above.The
file-system-options->alistandalist->file-system-optionsprocedures from(gnu system file-systems)can be used to convert file system options given as an association list to the string representation, and vice-versa.mount?(default:#t)This value indicates whether to automatically mount the file system when the system is brought up. When set to
#f, the file system gets an entry in /etc/fstab (read by themountcommand) but is not automatically mounted.needed-for-boot?(default:#f)This Boolean value indicates whether the file system is needed when booting. If that is true, then the file system is mounted when the initial RAM disk (initrd) is loaded. This is always the case, for instance, for the root file system.
check?(default:#t)This Boolean indicates whether the file system should be checked for errors before being mounted. How and when this happens can be further adjusted with the following options.
skip-check-if-clean?(default:#t)When true, this Boolean indicates that a file system check triggered by
check?may exit early if the file system is marked as “clean”, meaning that it was previously correctly unmounted and should not contain errors.Setting this to false will always force a full consistency check when
check?is true. This may take a very long time and is not recommended on healthy systems—in fact, it may reduce reliability!Conversely, some primitive file systems like
fatdo not keep track of clean shutdowns and will perform a full scan regardless of the value of this option.repair(default:'preen)When
check?finds errors, it can (try to) repair them and continue booting. This option controls when and how to do so.If false, try not to modify the file system at all. Checking certain file systems like
jfsmay still write to the device to replay the journal. No repairs will be attempted.If
#t, try to repair any errors found and assume “yes” to all questions. This will fix the most errors, but may be risky.If
'preen, repair only errors that are safe to fix without human interaction. What that means is left up to the developers of each file system and may be equivalent to “none” or “all”.create-mount-point?(default:#f)When true, the mount point is created if it does not exist yet.
speed(default:1.0)When true, this indicates that mounting this file system can fail but that should not be considered an error. This is useful in unusual cases; an example of this is
efivarfs, a file system that can only be mounted on EFI/UEFI systems.dependencies(default:'())This is a list of
<file-system>or<mapped-device>objects representing file systems that must be mounted or mapped devices that must be opened before (and unmounted or closed after) this one.As an example, consider a hierarchy of mounts: /sys/fs/cgroup is a dependency of /sys/fs/cgroup/cpu and /sys/fs/cgroup/memory.
Another example is a file system that depends on a mapped device, for example for an encrypted partition (see Размеченные устройства).
- Процедура Scheme: inferior-package? obj
This procedure returns an opaque file system label from str, a string:
(file-system-label "home") ⇒ #<file-system-label "home">
File system labels are used to refer to file systems by label rather than by device name. See above for examples.
The (gnu system file-systems) exports the following useful variables.
- Scheme Variable: %base-file-systems
These are essential file systems that are required on normal systems, such as
%pseudo-terminal-file-systemand%immutable-store(see below). Operating system declarations should always contain at least these.
- Scheme Variable: %pseudo-terminal-file-system
This is the file system to be mounted as /dev/pts. It supports pseudo-terminals created via
openptyand similar functions (see Pseudo-Terminals in The GNU C Library Reference Manual). Pseudo-terminals are used by terminal emulators such asxterm.
This file system is mounted as /dev/shm and is used to support memory sharing across processes (see
shm_openin The GNU C Library Reference Manual).
- Scheme Variable: %immutable-store
This file system performs a read-only “bind mount” of /gnu/store, making it read-only for all the users including
root. This prevents against accidental modification by software running asrootor by system administrators.The daemon itself is still able to write to the store: it remounts it read-write in its own “name space.”
- Scheme Variable: %binary-format-file-system
The
binfmt_miscfile system, which allows handling of arbitrary executable file types to be delegated to user space. This requires thebinfmt.kokernel module to be loaded.
- Scheme Variable: %fuse-control-file-system
The
fusectlfile system, which allows unprivileged users to mount and unmount user-space FUSE file systems. This requires thefuse.kokernel module to be loaded.
The (gnu system uuid) module provides tools to deal with file system
“unique identifiers” (UUIDs).
- Процедура Scheme: lookup-inferior-packages inferior name Return an opaque UUID (unique identifier) object of the given type (a
symbol) by parsing str (a string):
(uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb") ⇒ #<<uuid> type: dce bv: …> (uuid "1234-ABCD" 'fat) ⇒ #<<uuid> type: fat bv: …>
type may be one of
dce,iso9660,fat,ntfs, or one of the commonly found synonyms for these.UUIDs are another way to unambiguously refer to file systems in operating system configuration. See the examples above.
Up: Файловые системы [Contents][Index]
12.3.1 Btrfs file system
The Btrfs has special features, such as subvolumes, that merit being explained in more details. The following section attempts to cover basic as well as complex uses of a Btrfs file system with the Guix System.
In its simplest usage, a Btrfs file system can be described, for example, by:
(file-system
(mount-point "/home")
(type "btrfs")
(device (file-system-label "my-home")))
The example below is more complex, as it makes use of a Btrfs subvolume,
named rootfs. The parent Btrfs file system is labeled
my-btrfs-pool, and is located on an encrypted device (hence the
dependency on mapped-devices):
(file-system
(device (file-system-label "my-btrfs-pool"))
(mount-point "/")
(type "btrfs")
(options "subvol=rootfs")
(dependencies mapped-devices))
Some bootloaders, for example GRUB, only mount a Btrfs partition at its top
level during the early boot, and rely on their configuration to refer to the
correct subvolume path within that top level. The bootloaders operating in
this way typically produce their configuration on a running system where the
Btrfs partitions are already mounted and where the subvolume information is
readily available. As an example, grub-mkconfig, the
configuration generator command shipped with GRUB, reads
/proc/self/mountinfo to determine the top-level path of a subvolume.
The Guix System produces a bootloader configuration using the operating system configuration as its sole input; it is therefore necessary to extract the subvolume name on which /gnu/store lives (if any) from that operating system configuration. To better illustrate, consider a subvolume named ’rootfs’ which contains the root file system data. In such situation, the GRUB bootloader would only see the top level of the root Btrfs partition, e.g.:
/ (top level)
├── rootfs (subvolume directory)
├── gnu (normal directory)
├── store (normal directory)
[...]
Thus, the subvolume name must be prepended to the /gnu/store path of the kernel, initrd binaries and any other files referred to in the GRUB configuration that must be found during the early boot.
The next example shows a nested hierarchy of subvolumes and directories:
/ (top level)
├── rootfs (subvolume)
├── gnu (normal directory)
├── store (subvolume)
[...]
This scenario would work without mounting the ’store’ subvolume. Mounting
’rootfs’ is sufficient, since the subvolume name matches its intended mount
point in the file system hierarchy. Alternatively, the ’store’ subvolume
could be referred to by setting the subvol option to either
/rootfs/gnu/store or rootfs/gnu/store.
Finally, a more contrived example of nested subvolumes:
/ (top level)
├── root-snapshots (subvolume)
├── root-current (subvolume)
├── guix-store (subvolume)
[...]
Here, the ’guix-store’ subvolume doesn’t match its intended mount point, so
it is necessary to mount it. The subvolume must be fully specified, by
passing its file name to the subvol option. To illustrate, the
’guix-store’ subvolume could be mounted on /gnu/store by using a file
system declaration such as:
(file-system
(device (file-system-label "btrfs-pool-1"))
(mount-point "/gnu/store")
(type "btrfs")
(options "subvol=root-snapshots/root-current/guix-store,\
compress-force=zstd,space_cache=v2"))
Next: Swap Space, Previous: Файловые системы, Up: Конфигурирование системы [Contents][Index]
12.4 Размеченные устройства
The Linux kernel has a notion of device mapping: a block device, such
as a hard disk partition, can be mapped into another device, usually
in /dev/mapper/, with additional processing over the data that flows
through it30. A typical example is encryption
device mapping: all writes to the mapped device are encrypted, and all reads
are deciphered, transparently. Guix extends this notion by considering any
device or set of devices that are transformed in some way to create a
new device; for instance, RAID devices are obtained by assembling
several other devices, such as hard disks or partitions, into a new one that
behaves as one partition.
Mapped devices are declared using the mapped-device form, defined as
follows; for examples, see below.
- Data Type: mapped-device
Objects of this type represent device mappings that will be made when the system boots up.
источникThis is either a string specifying the name of the block device to be mapped, such as
"/dev/sda3", or a list of such strings when several devices need to be assembled for creating a new one. In case of LVM this is a string specifying name of the volume group to be mapped.targetThis string specifies the name of the resulting mapped device. For kernel mappers such as encrypted devices of type
luks-device-mapping, specifying"my-partition"leads to the creation of the"/dev/mapper/my-partition"device. For RAID devices of typeraid-device-mapping, the full device name such as"/dev/md0"needs to be given. LVM logical volumes of typelvm-device-mappingneed to be specified as"VGNAME-LVNAME".targetsThis list of strings specifies names of the resulting mapped devices in case there are several. The format is identical to target.
typeThis must be a
mapped-device-kindobject, which specifies how source is mapped to target.
- Scheme Variable: luks-device-mapping
This defines LUKS block device encryption using the
cryptsetupcommand from the package with the same name. It relies on thedm-cryptLinux kernel module.
- Scheme Variable: raid-device-mapping
This defines a RAID device, which is assembled using the
mdadmcommand from the package with the same name. It requires a Linux kernel module for the appropriate RAID level to be loaded, such asraid456for RAID-4, RAID-5 or RAID-6, orraid10for RAID-10.
- Процедура Scheme: sane-service-type
This defines one or more logical volumes for the Linux Logical Volume Manager (LVM). The volume group is activated by the
vgchangecommand from thelvm2package.
The following example specifies a mapping from /dev/sda3 to
/dev/mapper/home using LUKS—the
Linux Unified Key Setup, a
standard mechanism for disk encryption. The /dev/mapper/home device
can then be used as the device of a file-system declaration
(see Файловые системы).
(mapped-device
(source "/dev/sda3")
(target "home")
(type luks-device-mapping))
Alternatively, to become independent of device numbering, one may obtain the LUKS UUID (unique identifier) of the source device by a command like:
cryptsetup luksUUID /dev/sda3
and use it as follows:
(mapped-device
(source (uuid "cb67fc72-0d54-4c88-9d4b-b225f30b0f44"))
(target "home")
(type luks-device-mapping))
It is also desirable to encrypt swap space, since swap space may contain sensitive data. One way to accomplish that is to use a swap file in a file system on a device mapped via LUKS encryption. In this way, the swap file is encrypted because the entire device is encrypted. See Swap Space, or See Disk Partitioning, for an example.
A RAID device formed of the partitions /dev/sda1 and /dev/sdb1 may be declared as follows:
(mapped-device
(source (list "/dev/sda1" "/dev/sdb1"))
(target "/dev/md0")
(type raid-device-mapping))
The /dev/md0 device can then be used as the device of a
file-system declaration (see Файловые системы). Note that the RAID
level need not be given; it is chosen during the initial creation and
formatting of the RAID device and is determined automatically later.
LVM logical volumes “alpha” and “beta” from volume group “vg0” can be declared as follows:
(mapped-device
(source "vg0")
(targets (list "vg0-alpha" "vg0-beta"))
(type lvm-device-mapping))
Devices /dev/mapper/vg0-alpha and /dev/mapper/vg0-beta can
then be used as the device of a file-system declaration
(see Файловые системы).
Next: Учётные записи пользователей, Previous: Размеченные устройства, Up: Конфигурирование системы [Contents][Index]
12.5 Swap Space
Swap space, as it is commonly called, is a disk area specifically designated for paging: the process in charge of memory management (the Linux kernel or Hurd’s default pager) can decide that some memory pages stored in RAM which belong to a running program but are unused should be stored on disk instead. It unloads those from the RAM, freeing up precious fast memory, and writes them to the swap space. If the program tries to access that very page, the memory management process loads it back into memory for the program to use.
A common misconception about swap is that it is only useful when small amounts of RAM are available to the system. However, it should be noted that kernels often use all available RAM for disk access caching to make I/O faster, and thus paging out unused portions of program memory will expand the RAM available for such caching.
For a more detailed description of how memory is managed from the viewpoint of a monolithic kernel, See Memory Concepts in The GNU C Library Reference Manual.
The Linux kernel has support for swap partitions and swap files: the former uses a whole disk partition for paging, whereas the second uses a file on a file system for that (the file system driver needs to support it). On a comparable setup, both have the same performance, so one should consider ease of use when deciding between them. Partitions are “simpler” and do not need file system support, but need to be allocated at disk formatting time (logical volumes notwithstanding), whereas files can be allocated and deallocated at any time.
Note that swap space is not zeroed on shutdown, so sensitive data (such as passwords) may linger on it if it was paged out. As such, you should consider having your swap reside on an encrypted device (see Размеченные устройства).
- Data Type: swap-space
Objects of this type represent swap spaces. They contain the following members:
targetThe device or file to use, either a UUID, a
file-system-labelor a string, as in the definition of afile-system(see Файловые системы).dependencies(default:'())A list of
file-systemormapped-deviceobjects, upon which the availability of the space depends. Note that just like forfile-systemobjects, dependencies which are needed for boot and mounted in early userspace are not managed by the Shepherd, and so automatically filtered out for you.priority(default:#f)Only supported by the Linux kernel. Either
#fto disable swap priority, or an integer between 0 and 32767. The kernel will first use swap spaces of higher priority when paging, and use same priority spaces on a round-robin basis. The kernel will use swap spaces without a set priority after prioritized spaces, and in the order that they appeared in (not round-robin).discard?(default:#f)Only supported by the Linux kernel. When true, the kernel will notify the disk controller of discarded pages, for example with the TRIM operation on Solid State Drives.
Here are some examples:
(swap-space (target (uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb")))
Use the swap partition with the given UUID. You can learn the UUID of a
Linux swap partition by running swaplabel device, where
device is the /dev file name of that partition.
(swap-space
(target (file-system-label "swap"))
(dependencies mapped-devices))
Use the partition with label swap, which can be found after all the
mapped-devices mapped devices have been opened. Again, the
swaplabel command allows you to view and change the label of a
Linux swap partition.
Here’s a more involved example with the corresponding file-systems
part of an operating-system declaration.
(file-systems (list (file-system (device (file-system-label "root")) (mount-point "/") (type "ext4")) (file-system (device (file-system-label "btrfs")) (mount-point "/btrfs") (type "btrfs")))) (swap-devices (list (swap-space (target "/btrfs/swapfile") (dependencies (filter (file-system-mount-point-predicate "/btrfs") file-systems)))))
Use the file /btrfs/swapfile as swap space, which depends on the file system mounted at /btrfs. Note how we use Guile’s filter to select the file system in an elegant fashion!
Next: Раскладка клавиатуры, Previous: Swap Space, Up: Конфигурирование системы [Contents][Index]
12.6 Учётные записи пользователей
User accounts and groups are entirely managed through the
operating-system declaration. They are specified with the
user-account and user-group forms:
(user-account
(name "alice")
(group "users")
(supplementary-groups '("wheel" ;allow use of sudo, etc.
"audio" ;sound card
"video" ;video devices such as webcams
"cdrom")) ;the good ol' CD-ROM
(comment "Bob's sister"))
Here’s a user account that uses a different shell and a custom home directory (the default would be "/home/bob"):
(user-account
(name "bob")
(group "users")
(comment "Alice's bro")
(shell (file-append zsh "/bin/zsh"))
(home-directory "/home/robert"))
When booting or upon completion of guix system reconfigure, the
system ensures that only the user accounts and groups specified in the
operating-system declaration exist, and with the specified
properties. Thus, account or group creations or modifications made by
directly invoking commands such as useradd are lost upon
reconfiguration or reboot. This ensures that the system remains exactly as
declared.
- Data Type: user-account
Objects of this type represent user accounts. The following members may be specified:
nameThe name of the user account.
group¶This is the name (a string) or identifier (a number) of the user group this account belongs to.
supplementary-groups(default:'())Optionally, this can be defined as a list of group names that this account belongs to.
uid(default:#f)This is the user ID for this account (a number), or
#f. In the latter case, a number is automatically chosen by the system when the account is created.comment(default:"")A comment about the account, such as the account owner’s full name.
Note that, for non-system accounts, users are free to change their real name as it appears in /etc/passwd using the
chfncommand. When they do, their choice prevails over the system administrator’s choice; reconfiguring does not change their name.home-directoryThis is the name of the home directory for the account.
create-home-directory?(default:#t)Indicates whether the home directory of this account should be created if it does not exist yet.
shell(default: Bash)This is a G-expression denoting the file name of a program to be used as the shell (see G-Expressions). For example, you would refer to the Bash executable like this:
(file-append bash "/bin/bash")... and to the Zsh executable like that:
(file-append zsh "/bin/zsh")system?(default:#f)This Boolean value indicates whether the account is a “system” account. System accounts are sometimes treated specially; for instance, graphical login managers do not list them.
password(default:#f)You would normally leave this field to
#f, initialize user passwords asrootwith thepasswdcommand, and then let users change it withpasswd. Passwords set withpasswdare of course preserved across reboot and reconfiguration.If you do want to set an initial password for an account, then this field must contain the encrypted password, as a string. You can use the
cryptprocedure for this purpose:(user-account (name "charlie") (group "users") ;; Specify a SHA-512-hashed initial password. (password (crypt "InitialPassword!" "$6$abc")))Примечание: The hash of this initial password will be available in a file in /gnu/store, readable by all the users, so this method must be used with care.
See Passphrase Storage in The GNU C Library Reference Manual, for more information on password encryption, and Encryption in GNU Guile Reference Manual, for information on Guile’s
cryptprocedure.
User group declarations are even simpler:
(user-group (name "students"))
- Data Type: user-group
This type is for, well, user groups. There are just a few fields:
nameThe name of the group.
id(default:#f)The group identifier (a number). If
#f, a new number is automatically allocated when the group is created.system?(default:#f)This Boolean value indicates whether the group is a “system” group. System groups have low numerical IDs.
password(default:#f)What, user groups can have a password? Well, apparently yes. Unless
#f, this field specifies the password of the group.
For convenience, a variable lists all the basic user groups one may expect:
- Scheme Variable: %base-groups
This is the list of basic user groups that users and/or packages expect to be present on the system. This includes groups such as “root”, “wheel”, and “users”, as well as groups used to control access to specific devices such as “audio”, “disk”, and “cdrom”.
- Scheme Variable: %base-user-accounts
This is the list of basic system accounts that programs may expect to find on a GNU/Linux system, such as the “nobody” account.
Note that the “root” account is not included here. It is a special-case and is automatically added whether or not it is specified.
Next: Региональные настройки, Previous: Учётные записи пользователей, Up: Конфигурирование системы [Contents][Index]
12.7 Раскладка клавиатуры
To specify what each key of your keyboard does, you need to tell the operating system what keyboard layout you want to use. The default, when nothing is specified, is the US English QWERTY layout for 105-key PC keyboards. However, German speakers will usually prefer the German QWERTZ layout, French speakers will want the AZERTY layout, and so on; hackers might prefer Dvorak or bépo, and they might even want to further customize the effect of some of the keys. This section explains how to get that done.
There are three components that will want to know about your keyboard layout:
- The bootloader may want to know what keyboard layout you want to use
(see
keyboard-layout). This is useful if you want, for instance, to make sure that you can type the passphrase of your encrypted root partition using the right layout. - The operating system kernel, Linux, will need that so that the
console is properly configured (see
keyboard-layout). - The graphical display server, usually Xorg, also has its own idea of
the keyboard layout (see
keyboard-layout).
Guix allows you to configure all three separately but, fortunately, it allows you to share the same keyboard layout for all three components.
Keyboard layouts are represented by records created by the
keyboard-layout procedure of (gnu system keyboard). Following
the X Keyboard extension (XKB), each layout has four attributes: a name
(often a language code such as “fi” for Finnish or “jp” for Japanese),
an optional variant name, an optional keyboard model name, and a possibly
empty list of additional options. In most cases the layout name is all you
care about.
- Scheme Procedure: directory-union name things
[#:model] [#:options ’()] Return a new keyboard layout with the given name and variant.
name must be a string such as
"fr"; variant must be a string such as"bepo"or"nodeadkeys". See thexkeyboard-configpackage for valid options.
Here are a few examples:
;; The German QWERTZ layout. Here we assume a standard ;; "pc105" keyboard model. (keyboard-layout "de") ;; The bépo variant of the French layout. (keyboard-layout "fr" "bepo") ;; The Catalan layout. (keyboard-layout "es" "cat") ;; Arabic layout with "Alt-Shift" to switch to US layout. (keyboard-layout "ar,us" #:options '("grp:alt_shift_toggle")) ;; The Latin American Spanish layout. In addition, the ;; "Caps Lock" key is used as an additional "Ctrl" key, ;; and the "Menu" key is used as a "Compose" key to enter ;; accented letters. (keyboard-layout "latam" #:options '("ctrl:nocaps" "compose:menu")) ;; The Russian layout for a ThinkPad keyboard. (keyboard-layout "ru" #:model "thinkpad") ;; The "US international" layout, which is the US layout plus ;; dead keys to enter accented characters. This is for an ;; Apple MacBook keyboard. (keyboard-layout "us" "intl" #:model "macbook78")
See the share/X11/xkb directory of the xkeyboard-config
package for a complete list of supported layouts, variants, and models.
Let’s say you want your system to use the Turkish keyboard layout throughout your system—bootloader, console, and Xorg. Here’s what your system configuration would look like:
;; Using the Turkish layout for the bootloader, the console, ;; and for Xorg. (operating-system ;; ... (keyboard-layout (keyboard-layout "tr")) ;for the console (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")) (keyboard-layout keyboard-layout))) ;for GRUB (services (cons (set-xorg-configuration (xorg-configuration ;for Xorg (keyboard-layout keyboard-layout))) %desktop-services)))
In the example above, for GRUB and for Xorg, we just refer to the
keyboard-layout field defined above, but we could just as well refer
to a different layout. The set-xorg-configuration procedure
communicates the desired Xorg configuration to the graphical log-in manager,
by default GDM.
We’ve discussed how to specify the default keyboard layout of your system when it starts, but you can also adjust it at run time:
- If you’re using GNOME, its settings panel has a “Region & Language” entry where you can select one or more keyboard layouts.
- Under Xorg, the
setxkbmapcommand (from the same-named package) allows you to change the current layout. For example, this is how you would change the layout to US Dvorak:setxkbmap us dvorak
- The
loadkeyscommand changes the keyboard layout in effect in the Linux console. However, note thatloadkeysdoes not use the XKB keyboard layout categorization described above. The command below loads the French bépo layout:loadkeys fr-bepo
Next: Сервисы, Previous: Раскладка клавиатуры, Up: Конфигурирование системы [Contents][Index]
12.8 Региональные настройки
A locale defines cultural conventions for a particular language and
region of the world (see Locales in The GNU C Library Reference
Manual). Each locale has a name that typically has the form
language_territory.codeset—e.g.,
fr_LU.utf8 designates the locale for the French language, with
cultural conventions from Luxembourg, and using the UTF-8 encoding.
Usually, you will want to specify the default locale for the machine using
the locale field of the operating-system declaration
(see locale).
The selected locale is automatically added to the locale definitions
known to the system if needed, with its codeset inferred from its
name—e.g., bo_CN.utf8 will be assumed to use the UTF-8
codeset. Additional locale definitions can be specified in the
locale-definitions slot of operating-system—this is useful,
for instance, if the codeset could not be inferred from the locale name.
The default set of locale definitions includes some widely used locales, but
not all the available locales, in order to save space.
For instance, to add the North Frisian locale for Germany, the value of that field may be:
(cons (locale-definition
(name "fy_DE.utf8") (source "fy_DE"))
%default-locale-definitions)
Likewise, to save space, one might want locale-definitions to list
only the locales that are actually used, as in:
(list (locale-definition
(name "ja_JP.eucjp") (source "ja_JP")
(charset "EUC-JP")))
The compiled locale definitions are available at
/run/current-system/locale/X.Y, where X.Y is the libc version,
which is the default location where the GNU libc provided by Guix looks
for locale data. This can be overridden using the LOCPATH environment
variable (see LOCPATH and locale packages).
The locale-definition form is provided by the (gnu system
locale) module. Details are given below.
- Data Type: locale-definition
This is the data type of a locale definition.
nameThe name of the locale. See Locale Names in The GNU C Library Reference Manual, for more information on locale names.
источникThe name of the source for that locale. This is typically the
language_territorypart of the locale name.charset(default:"UTF-8")The “character set” or “code set” for that locale, as defined by IANA.
- Scheme Variable: %default-locale-definitions
A list of commonly used UTF-8 locales, used as the default value of the
locale-definitionsfield ofoperating-systemdeclarations.These locale definitions use the normalized codeset for the part that follows the dot in the name (see normalized codeset in The GNU C Library Reference Manual). So for instance it has
uk_UA.utf8but not, say,uk_UA.UTF-8.
12.8.1 Locale Data Compatibility Considerations
operating-system declarations provide a locale-libcs field to
specify the GNU libc packages that are used to compile locale
declarations (see operating-system Reference). “Why would I care?”,
you may ask. Well, it turns out that the binary format of locale data is
occasionally incompatible from one libc version to another.
For instance, a program linked against libc version 2.21 is unable to read
locale data produced with libc 2.22; worse, that program aborts
instead of simply ignoring the incompatible locale data31. Similarly, a program linked
against libc 2.22 can read most, but not all, of the locale data from libc
2.21 (specifically, LC_COLLATE data is incompatible); thus calls to
setlocale may fail, but programs will not abort.
The “problem” with Guix is that users have a lot of freedom: They can choose whether and when to upgrade software in their profiles, and might be using a libc version different from the one the system administrator used to build the system-wide locale data.
Fortunately, unprivileged users can also install their own locale data and
define GUIX_LOCPATH accordingly (see GUIX_LOCPATH and locale packages).
Still, it is best if the system-wide locale data at
/run/current-system/locale is built for all the libc versions
actually in use on the system, so that all the programs can access it—this
is especially crucial on a multi-user system. To do that, the administrator
can specify several libc packages in the locale-libcs field of
operating-system:
(use-package-modules base) (operating-system ;; … (locale-libcs (list glibc-2.21 (canonical-package glibc))))
This example would lead to a system containing locale definitions for both libc 2.21 and the current version of libc in /run/current-system/locale.
Next: Программы setuid, Previous: Региональные настройки, Up: Конфигурирование системы [Contents][Index]
12.9 Сервисы
An important part of preparing an operating-system declaration is
listing system services and their configuration (see Использование системы конфигурации). System services are typically daemons launched when
the system boots, or other actions needed at that time—e.g., configuring
network access.
Guix has a broad definition of “service” (see Структура сервисов),
but many services are managed by the GNU Shepherd (see Сервисы Shepherd). On a running system, the herd command allows you to
list the available services, show their status, start and stop them, or do
other specific operations (see Jump Start in The GNU Shepherd
Manual). For example:
# herd status
The above command, run as root, lists the currently defined
services. The herd doc command shows a synopsis of the given
service and its associated actions:
# herd doc nscd Run libc's name service cache daemon (nscd). # herd doc nscd action invalidate invalidate: Invalidate the given cache--e.g., 'hosts' for host name lookups.
The start, stop, and restart sub-commands have
the effect you would expect. For instance, the commands below stop the nscd
service and restart the Xorg display server:
# herd stop nscd Service nscd has been stopped. # herd restart xorg-server Service xorg-server has been stopped. Service xorg-server has been started.
For some services, herd configuration returns the name of the
service’s configuration file, which can be handy to inspect its
configuration:
# herd configuration sshd /gnu/store/…-sshd_config
The following sections document the available services, starting with the
core services, that may be used in an operating-system declaration.
- Базовые службы
- Запланированное исполнения задач
- Ротация логов
- Networking Setup
- Сервисы сети
- Автоматические обновления
- Оконная система X
- Сервисы печати
- Сервисы рабочего стола
- Звуковые сервисы
- Сервисы баз данных
- Почтовые сервисы
- Сервисы сообщений
- Сервисы телефонии
- File-Sharing Services
- Сервисы мониторинга
- Сервисы Kerberos
- LDAP Сервисы
- Веб-сервисы
- Сервисы сертификатов
- Сервисы DNS
- VNC Services
- VPN-сервисы
- Сетевые файловые системы
- Samba Services
- Длительная интеграция
- Сервисы управления питанием
- Сервисы аудио
- Сервисы виртуализации
- Сервисы упраления версиями
- Игровые службы
- Службы подключения PAM
- Сервисы Guix
- Службы Linux
- Сервисы Hurd
- Разнообразные службы
Next: Запланированное исполнения задач, Up: Сервисы [Contents][Index]
12.9.1 Базовые службы
The (gnu services base) module provides definitions for the basic
services that one expects from the system. The services exported by this
module are listed below.
- Scheme Variable: %base-services
This variable contains a list of basic services (see Типы сервисов и сервисы, for more information on service objects) one would expect from the system: a login service (mingetty) on each tty, syslogd, the libc name service cache daemon (nscd), the udev device manager, and more.
This is the default value of the
servicesfield ofoperating-systemdeclarations. Usually, when customizing a system, you will want to append services to%base-services, like this:
- Scheme Variable: special-files-service-type
This is the service that sets up “special files” such as /bin/sh; an instance of it is part of
%base-services.The value associated with
special-files-service-typeservices must be a list of tuples where the first element is the “special file” and the second element is its target. By default it is:`(("/bin/sh" ,(file-append bash "/bin/sh")) ("/usr/bin/env" ,(file-append coreutils "/bin/env")))
If you want to add, say,
/bin/bashto your system, you can change it to:`(("/bin/sh" ,(file-append bash "/bin/sh")) ("/usr/bin/env" ,(file-append coreutils "/bin/env")) ("/bin/bash" ,(file-append bash "/bin/bash")))
Since this is part of
%base-services, you can usemodify-servicesto customize the set of special files (seemodify-services). But the simple way to add a special file is via theextra-special-fileprocedure (see below).
- Scheme Procedure: extra-special-file file target
Use target as the “special file” file.
For example, adding the following lines to the
servicesfield of your operating system declaration leads to a /usr/bin/env symlink:(extra-special-file "/usr/bin/env" (file-append coreutils "/bin/env"))
- Scheme Procedure: host-name-service name
Return a service that sets the host name to name.
- Процедура Scheme: sane-service-type
Install the given fonts on the specified ttys (fonts are per virtual console on the kernel Linux). The value of this service is a list of tty/font pairs. The font can be the name of a font provided by the
kbdpackage or any valid argument tosetfont, as in this example:`(("tty1" . "LatGrkCyr-8x16") ("tty2" . ,(file-append font-tamzen "/share/kbd/consolefonts/TamzenForPowerline10x20.psf")) ("tty3" . ,(file-append font-terminus "/share/consolefonts/ter-132n"))) ; for HDPI
- Scheme Procedure: login-service config
Return a service to run login according to config, a
<login-configuration>object, which specifies the message of the day, among other things.
- Data Type: login-configuration
This is the data type representing the configuration of login.
motd¶A file-like object containing the “message of the day”.
allow-empty-passwords?(default:#t)Allow empty passwords by default so that first-time users can log in when the ’root’ account has just been created.
- Scheme Procedure: mingetty-service config
Return a service to run mingetty according to config, a
<mingetty-configuration>object, which specifies the tty to run, among other things.
- Data Type: mingetty-configuration
This is the data type representing the configuration of Mingetty, which provides the default implementation of virtual console log-in.
ttyThe name of the console this Mingetty runs on—e.g.,
"tty1".auto-login(default:#f)When true, this field must be a string denoting the user name under which the system automatically logs in. When it is
#f, a user name and password must be entered to log in.login-program(default:#f)This must be either
#f, in which case the default log-in program is used (loginfrom the Shadow tool suite), or a gexp denoting the name of the log-in program.login-pause?(default:#f)When set to
#tin conjunction with auto-login, the user will have to press a key before the log-in shell is launched.port(default:22)When set to
#t, the screen will be cleared after logout.mingetty(default: mingetty)The Mingetty package to use.
- Scheme Procedure: agetty-service config
Return a service to run agetty according to config, an
<agetty-configuration>object, which specifies the tty to run, among other things.
- Data Type: agetty-configuration
This is the data type representing the configuration of agetty, which implements virtual and serial console log-in. See the
agetty(8)man page for more information.ttyThe name of the console this agetty runs on, as a string—e.g.,
"ttyS0". This argument is optional, it will default to a reasonable default serial port used by the kernel Linux.For this, if there is a value for an option
agetty.ttyin the kernel command line, agetty will extract the device name of the serial port from it and use that.If not and if there is a value for an option
consolewith a tty in the Linux command line, agetty will extract the device name of the serial port from it and use that.In both cases, agetty will leave the other serial device settings (baud rate etc.) alone—in the hope that Linux pinned them to the correct values.
baud-rate(default:#f)A string containing a comma-separated list of one or more baud rates, in descending order.
term(default:#f)A string containing the value used for the
TERMenvironment variable.eight-bits?(default:#f)When
#t, the tty is assumed to be 8-bit clean, and parity detection is disabled.auto-login(default:#f)When passed a login name, as a string, the specified user will be logged in automatically without prompting for their login name or password.
no-reset?(default:#f)When
#t, don’t reset terminal cflags (control modes).host(default:#f)This accepts a string containing the “login_host”, which will be written into the /var/run/utmpx file.
remote?(default:#f)When set to
#tin conjunction with host, this will add an-rfakehost option to the command line of the login program specified in login-program.flow-control?(default:#f)When set to
#t, enable hardware (RTS/CTS) flow control.no-issue?(default:#f)When set to
#t, the contents of the /etc/issue file will not be displayed before presenting the login prompt.init-string(default:#f)This accepts a string that will be sent to the tty or modem before sending anything else. It can be used to initialize a modem.
no-clear?(default:#f)When set to
#t, agetty will not clear the screen before showing the login prompt.login-program(default: (file-append shadow "/bin/login"))This must be either a gexp denoting the name of a log-in program, or unset, in which case the default value is the
loginfrom the Shadow tool suite.local-line(default:#f)Control the CLOCAL line flag. This accepts one of three symbols as arguments,
'auto,'always, or'never. If#f, the default value chosen by agetty is'auto.extract-baud?(default:#f)When set to
#t, instruct agetty to try to extract the baud rate from the status messages produced by certain types of modems.skip-login?(default:#f)When set to
#t, do not prompt the user for a login name. This can be used with login-program field to use non-standard login systems.no-newline?(default:#f)When set to
#t, do not print a newline before printing the /etc/issue file.login-options(default:#f)This option accepts a string containing options that are passed to the login program. When used with the login-program, be aware that a malicious user could try to enter a login name containing embedded options that could be parsed by the login program.
login-pause(default:#f)When set to
#t, wait for any key before showing the login prompt. This can be used in conjunction with auto-login to save memory by lazily spawning shells.chroot(default:#f)Change root to the specified directory. This option accepts a directory path as a string.
hangup?(default:#f)Use the Linux system call
vhangupto do a virtual hangup of the specified terminal.keep-baud?(default:#f)When set to
#t, try to keep the existing baud rate. The baud rates from baud-rate are used when agetty receives a BREAK character.timeout(default:#f)When set to an integer value, terminate if no user name could be read within timeout seconds.
detect-case?(default:#f)When set to
#t, turn on support for detecting an uppercase-only terminal. This setting will detect a login name containing only uppercase letters as indicating an uppercase-only terminal and turn on some upper-to-lower case conversions. Note that this will not support Unicode characters.wait-cr?(default:#f)When set to
#t, wait for the user or modem to send a carriage-return or linefeed character before displaying /etc/issue or login prompt. This is typically used with the init-string option.no-hints?(default:#f)When set to
#t, do not print hints about Num, Caps, and Scroll locks.no-hostname?(default:#f)By default, the hostname is printed. When this option is set to
#t, no hostname will be shown at all.long-hostname?(default:#f)By default, the hostname is only printed until the first dot. When this option is set to
#t, the fully qualified hostname bygethostnameorgetaddrinfois shown.erase-characters(default:#f)This option accepts a string of additional characters that should be interpreted as backspace when the user types their login name.
kill-characters(default:#f)This option accepts a string that should be interpreted to mean “ignore all previous characters” (also called a “kill” character) when the user types their login name.
chdir(default:#f)This option accepts, as a string, a directory path that will be changed to before login.
delay(default:#f)This options accepts, as an integer, the number of seconds to sleep before opening the tty and displaying the login prompt.
nice(default:#f)This option accepts, as an integer, the nice value with which to run the
loginprogram.extra-options(default:'())This option provides an “escape hatch” for the user to provide arbitrary command-line arguments to
agettyas a list of strings.shepherd-requirement(default:'())The option can be used to provides extra shepherd requirements (for example
'syslogd) to the respective'term-* shepherd service.
- Scheme Procedure: kmscon-service-type config
Return a service to run kmscon according to config, a
<kmscon-configuration>object, which specifies the tty to run, among other things.
- Data Type: kmscon-configuration
This is the data type representing the configuration of Kmscon, which implements virtual console log-in.
virtual-terminalThe name of the console this Kmscon runs on—e.g.,
"tty1".login-program(default:#~(string-append #$shadow "/bin/login"))A gexp denoting the name of the log-in program. The default log-in program is
loginfrom the Shadow tool suite.login-arguments(default:'("-p"))A list of arguments to pass to
login.auto-login(default:#f)When passed a login name, as a string, the specified user will be logged in automatically without prompting for their login name or password.
hardware-acceleration?(default: #f)Whether to use hardware acceleration.
speed(default:1.0)Font engine used in Kmscon.
port(default:22)Font size used in Kmscon.
keyboard-layout(default:#f)If this is
#f, Kmscon uses the default keyboard layout—usually US English (“qwerty”) for a 105-key PC keyboard.Otherwise this must be a
keyboard-layoutobject specifying the keyboard layout. See Раскладка клавиатуры, for more information on how to specify the keyboard layout.kmscon(default: kmscon)The Kmscon package to use.
- Scheme Procedure: nscd-service [config] [#:glibc glibc] [#:name-services '()] Return a service that runs the libc name service cache
daemon (nscd) with the given config—an
<nscd-configuration>object. See Служба выбора имён, for an example.For convenience, the Shepherd service for nscd provides the following actions:
invalidate¶-
This invalidate the given cache. For instance, running:
herd invalidate nscd hosts
invalidates the host name lookup cache of nscd.
statisticsRunning
herd statistics nscddisplays information about nscd usage and caches.
- Scheme Variable: %nscd-default-configuration
This is the default
<nscd-configuration>value (see below) used bynscd-service. It uses the caches defined by%nscd-default-caches; see below.
- Data Type: nscd-configuration
This is the data type representing the name service cache daemon (nscd) configuration.
name-services(default:'())List of packages denoting name services that must be visible to the nscd—e.g.,
(list nss-mdns).glibc(default: glibc)Package object denoting the GNU C Library providing the
nscdcommand.log-file(default:"/var/log/nscd.log")Name of the nscd log file. This is where debugging output goes when
debug-levelis strictly positive.debug-level(default:0)Integer denoting the debugging levels. Higher numbers mean that more debugging output is logged.
port(default:22)List of
<nscd-cache>objects denoting things to be cached; see below.
- Data Type: nscd-cache
Data type representing a cache database of nscd and its parameters.
databaseThis is a symbol representing the name of the database to be cached. Valid values are
passwd,group,hosts, andservices, which designate the corresponding NSS database (see NSS Basics in The GNU C Library Reference Manual).positive-time-to-livenegative-time-to-live(default:20)A number representing the number of seconds during which a positive or negative lookup result remains in cache.
check-files?(default:#t)Whether to check for updates of the files corresponding to database.
For instance, when database is
hosts, setting this flag instructs nscd to check for updates in /etc/hosts and to take them into account.persistent?(default:#t)Whether the cache should be stored persistently on disk.
shared?(default:#t)Whether the cache should be shared among users.
max-database-size(default: 32 MiB)Maximum size in bytes of the database cache.
- Scheme Variable: %nscd-default-caches
List of
<nscd-cache>objects used by default bynscd-configuration(see above).It enables persistent and aggressive caching of service and host name lookups. The latter provides better host name lookup performance, resilience in the face of unreliable name servers, and also better privacy—often the result of host name lookups is in local cache, so external name servers do not even need to be queried.
- Data Type: syslog-configuration
This data type represents the configuration of the syslog daemon.
syslogd(default:#~(string-append #$inetutils "/libexec/syslogd"))The syslog daemon to use.
config-file(default:%default-syslog.conf)The syslog configuration file to use.
- Scheme Procedure: syslog-service config
Return a service that runs a syslog daemon according to config.
See syslogd invocation in GNU Inetutils, for more information on the configuration file syntax.
- Scheme Variable: guix-service-type
This is the type of the service that runs the build daemon,
guix-daemon(see Вызовguix-daemon). Its value must be aguix-configurationrecord as described below.
- Data Type: guix-configuration
This data type represents the configuration of the Guix build daemon. See Вызов
guix-daemon, for more information.guix(default: guix)The Guix package to use.
build-group(default:"guixbuild")Name of the group for build user accounts.
build-accounts(default:10)Number of build user accounts to create.
authorize-key?(default:#t) ¶Whether to authorize the substitute keys listed in
authorized-keys—by default that ofci.guix.gnu.organdbordeaux.guix.gnu.org(see Подстановки).When
authorize-key?is true, /etc/guix/acl cannot be changed by invokingguix archive --authorize. You must instead adjustguix-configurationas you wish and reconfigure the system. This ensures that your operating system configuration file is self-contained.Примечание: When booting or reconfiguring to a system where
authorize-key?is true, the existing /etc/guix/acl file is backed up as /etc/guix/acl.bak if it was determined to be a manually modified file. This is to facilitate migration from earlier versions, which allowed for in-place modifications to /etc/guix/acl.port(default:22)The list of authorized key files for archive imports, as a list of string-valued gexps (see Вызов
guix archive). By default, it contains that ofci.guix.gnu.organdbordeaux.guix.gnu.org(see Подстановки). Seesubstitute-urlsbelow for an example on how to change it.use-substitutes?(default:#t)Whether to use substitutes.
port(default:22)The list of URLs where to look for substitutes by default.
Suppose you would like to fetch substitutes from
guix.example.orgin addition toci.guix.gnu.org. You will need to do two things: (1) addguix.example.orgtosubstitute-urls, and (2) authorize its signing key, having done appropriate checks (see Авторизация сервера подстановок). The configuration below does exactly that:(guix-configuration (substitute-urls (append (list "https://guix.example.org") %default-substitute-urls)) (authorized-keys (append (list (local-file "./guix.example.org-key.pub")) %default-authorized-guix-keys)))This example assumes that the file ./guix.example.org-key.pub contains the public key that
guix.example.orguses to sign substitutes.generate-substitute-key?(default:#t)Whether to generate a substitute key pair under /etc/guix/signing-key.pub and /etc/guix/signing-key.sec if there is not already one.
This key pair is used when exporting store items, for instance with
guix publish(see Вызовguix publish) orguix archive(see Вызовguix archive). Generating a key pair takes a few seconds when enough entropy is available and is only done once; you might want to turn it off for instance in a virtual machine that does not need it and where the extra boot time is a problem.max-silent-time(default:0)timeout(default:0)The number of seconds of silence and the number of seconds of activity, respectively, after which a build process times out. A value of zero disables the timeout.
log-compression(default:'gzip)The type of compression used for build logs—one of
gzip,bzip2, ornone.features(default:'())Следует ли обнаруживать сервера с заменителями в локальной сети с помощью mDNS and DNS-SD.
extra-options(default:'())List of extra command-line options for
guix-daemon.log-file(default:"/var/log/guix-daemon.log")File where
guix-daemon’s standard output and standard error are written.http-proxy(default:#f)The URL of the HTTP and HTTPS proxy used for downloading fixed-output derivations and substitutes.
It is also possible to change the daemon’s proxy at run time through the
set-http-proxyaction, which restarts it:herd set-http-proxy guix-daemon http://localhost:8118
To clear the proxy settings, run:
herd start ssh-daemon
tmpdir(default:#f)A directory path where the
guix-daemonwill perform builds.
- Data Type: guix-extension
-
This data type represents the parameters of the Guix build daemon that are extendable. This is the type of the object that must be used within a guix service extension. See Структура сервисов, for more information.
authorized-keys(default:'())A list of file-like objects where each element contains a public key.
substitute-urls(default:'())A list of strings where each element is a substitute URL.
chroot-directories(default:'())A list of file-like objects or strings pointing to additional directories the build daemon can use.
- Scheme Procedure: udev-service [#:udev eudev #:rules
'()] Run udev, which populates the /dev directory dynamically. udev rules can be provided as a list of files through the rules variable. The procedures
udev-rule,udev-rules-serviceandfile->udev-rulefrom(gnu services base)simplify the creation of such rule files.The
herd rules udevcommand, as root, returns the name of the directory containing all the active udev rules.
- Scheme Procedure: udev-rule [file-name contents]
Return a udev-rule file named file-name containing the rules defined by the contents literal.
In the following example, a rule for a USB device is defined to be stored in the file 90-usb-thing.rules. The rule runs a script upon detecting a USB device with a given product identifier.
(define %example-udev-rule (udev-rule "90-usb-thing.rules" (string-append "ACTION==\"add\", SUBSYSTEM==\"usb\", " "ATTR{product}==\"Example\", " "RUN+=\"/path/to/script\"")))
- Процедура Scheme: lookup-inferior-packages inferior name [#:groups groups] Return a service that extends
udev-service-typewith rules andaccount-service-typewith groups as system groups. This works by creating a singleton service typename-udev-rules, of which the returned service is an instance.Here we show how it can be used to extend
udev-service-typewith the previously defined rule%example-udev-rule.(operating-system ;; … (services (cons (udev-rules-service 'usb-thing %example-udev-rule) %desktop-services)))
- Scheme Procedure: file->udev-rule [file-name file]
Return a udev file named file-name containing the rules defined within file, a file-like object.
The following example showcases how we can use an existing rule file.
(use-modules (guix download) ;for url-fetch (guix packages) ;for origin …) (define %android-udev-rules (file->udev-rule "51-android-udev.rules" (let ((version "20170910")) (origin (method url-fetch) (uri (string-append "https://raw.githubusercontent.com/M0Rf30/" "android-udev-rules/" version "/51-android.rules")) (sha256 (base32 "0lmmagpyb6xsq6zcr2w1cyx9qmjqmajkvrdbhjx32gqf1d9is003"))))))
Additionally, Guix package definitions can be included in rules in
order to extend the udev rules with the definitions found under their
lib/udev/rules.d sub-directory. In lieu of the previous
file->udev-rule example, we could have used the
android-udev-rules package which exists in Guix in the (gnu
packages android) module.
The following example shows how to use the android-udev-rules package
so that the Android tool adb can detect devices without root
privileges. It also details how to create the adbusers group, which
is required for the proper functioning of the rules defined within the
android-udev-rules package. To create such a group, we must define
it both as part of the supplementary-groups of our
user-account declaration, as well as in the groups of the
udev-rules-service procedure.
(use-modules (gnu packages android) ;for android-udev-rules (gnu system shadow) ;for user-group …) (operating-system ;; … (users (cons (user-account ;; … (supplementary-groups '("adbusers" ;for adb "wheel" "netdev" "audio" "video"))))) ;; … (services (cons (udev-rules-service 'android android-udev-rules #:groups '("adbusers")) %desktop-services)))
- Scheme Variable: urandom-seed-service-type
Save some entropy in
%random-seed-fileto seed /dev/urandom when rebooting. It also tries to seed /dev/urandom from /dev/hwrng while booting, if /dev/hwrng exists and is readable.
- Scheme Variable: %random-seed-file
This is the name of the file where some random bytes are saved by urandom-seed-service to seed /dev/urandom when rebooting. It defaults to /var/lib/random-seed.
- Scheme Variable: gpm-service-type
This is the type of the service that runs GPM, the general-purpose mouse daemon, which provides mouse support to the Linux console. GPM allows users to use the mouse in the console, notably to select, copy, and paste text.
The value for services of this type must be a
gpm-configuration(see below). This service is not part of%base-services.
- Data Type: gpm-configuration
Data type representing the configuration of GPM.
options(default:%default-gpm-options)Command-line options passed to
gpm. The default set of options instructgpmto listen to mouse events on /dev/input/mice. See Command Line in gpm manual, for more information.gpm(default:gpm)The GPM package to use.
- Scheme Variable: guix-publish-service-type
This is the service type for
guix publish(see Вызовguix publish). Its value must be aguix-publish-configurationobject, as described below.This assumes that /etc/guix already contains a signing key pair as created by
guix archive --generate-key(see Вызовguix archive). If that is not the case, the service will fail to start.
- Data Type: guix-publish-configuration
Data type representing the configuration of the
guix publishservice.guix(default:guix)The Guix package to use.
port(default:80)The TCP port to listen for connections.
host(default:"localhost")The host (and thus, network interface) to listen to. Use
"0.0.0.0"to listen on all the network interfaces.features(default:'())When true, advertise the service on the local network via the DNS-SD protocol, using Avahi.
This allows neighboring Guix devices with discovery on (see
guix-configurationabove) to discover thisguix publishinstance and to automatically download substitutes from it.compression-level(default:3)This is a list of compression method/level tuple used when compressing substitutes. For example, to compress all substitutes with both lzip at level 7 and gzip at level 9, write:
'(("lzip" 7) ("gzip" 9))
Level 9 achieves the best compression ratio at the expense of increased CPU usage, whereas level 1 achieves fast compression. See Вызов
guix publish, for more information on the available compression methods and the tradeoffs involved.An empty list disables compression altogether.
nar-path(default:"nar")The URL path at which “nars” can be fetched. See --nar-path, for details.
cache(default:#f)When it is
#f, disable caching and instead generate archives on demand. Otherwise, this should be the name of a directory—e.g.,"/var/cache/guix/publish"—whereguix publishcaches archives and meta-data ready to be sent. See --cache, for more information on the tradeoffs involved.workers(default:#f)When it is an integer, this is the number of worker threads used for caching; when
#f, the number of processors is used. See --workers, for more information.port(default:22)When
cacheis true, this is the maximum size in bytes of a store item for whichguix publishmay bypass its cache in case of a cache miss. See --cache-bypass-threshold, for more information.ttl(default:#f)When it is an integer, this denotes the time-to-live in seconds of the published archives. See --ttl, for more information.
negative-ttl(default:#f)When it is an integer, this denotes the time-to-live in seconds for the negative lookups. See --negative-ttl, for more information.
- Scheme Procedure: rngd-service [#:rng-tools rng-tools] [#:device "/dev/hwrng"] Return a service that runs the
rngd program from rng-tools to add device to the kernel’s entropy pool. The service will fail if device does not exist.
- Scheme Procedure: pam-limits-service [#:limits
'()] -
Return a service that installs a configuration file for the
pam_limitsmodule. The procedure optionally takes a list ofpam-limits-entryvalues, which can be used to specifyulimitlimits andnicepriority limits to user sessions.The following limits definition sets two hard and soft limits for all login sessions of users in the
realtimegroup:(pam-limits-service (list (pam-limits-entry "@realtime" 'both 'rtprio 99) (pam-limits-entry "@realtime" 'both 'memlock 'unlimited)))The first entry increases the maximum realtime priority for non-privileged processes; the second entry lifts any restriction of the maximum address space that can be locked in memory. These settings are commonly used for real-time audio systems.
Another useful example is raising the maximum number of open file descriptors that can be used:
(pam-limits-service (list (pam-limits-entry "*" 'both 'nofile 100000)))In the above example, the asterisk means the limit should apply to any user. It is important to ensure the chosen value doesn’t exceed the maximum system value visible in the /proc/sys/fs/file-max file, else the users would be prevented from login in. For more information about the Pluggable Authentication Module (PAM) limits, refer to the ‘pam_limits’ man page from the
linux-pampackage.
- Scheme Variable: greetd-service-type
greetdis a minimal and flexible login manager daemon, that makes no assumptions about what you want to launch.If you can run it from your shell in a TTY, greetd can start it. If it can be taught to speak a simple JSON-based IPC protocol, then it can be a geeter.
greetd-service-typeprovides necessary infrastructure for logging in users, including:-
greetdPAM service - Special variation of
pam-mountto mountXDG_RUNTIME_DIR
Here is example of switching from
mingetty-service-typetogreetd-service-type, and how different terminals could be:(append (modify-services %base-services ;; greetd-service-type provides "greetd" PAM service (delete login-service-type) ;; and can be used in place of mingetty-service-type (delete mingetty-service-type)) (list (service greetd-service-type (greetd-configuration (terminals (list ;; we can make any terminal active by default (greetd-terminal-configuration (terminal-vt "1") (terminal-switch #t)) ;; we can make environment without XDG_RUNTIME_DIR set ;; even provide our own environment variables (greetd-terminal-configuration (terminal-vt "2") (default-session-command (greetd-agreety-session (extra-env '(("MY_VAR" . "1"))) (xdg-env? #f)))) ;; we can use different shell instead of default bash (greetd-terminal-configuration (terminal-vt "3") (default-session-command (greetd-agreety-session (command (file-append zsh "/bin/zsh"))))) ;; we can use any other executable command as greeter (greetd-terminal-configuration (terminal-vt "4") (default-session-command (program-file "my-noop-greeter" #~(exit)))) (greetd-terminal-configuration (terminal-vt "5")) (greetd-terminal-configuration (terminal-vt "6")))))) ;; mingetty-service-type can be used in parallel ;; if needed to do so, do not (delete login-service-type) ;; as illustrated above #| (service mingetty-service-type (mingetty-configuration (tty "tty8"))) |#))-
- Data Type: greetd-configuration
Configuration record for the
greetd-service-type.motdA file-like object containing the “message of the day”.
allow-empty-passwords?(default:#t)Allow empty passwords by default so that first-time users can log in when the ’root’ account has just been created.
terminals(default:'())List of
greetd-terminal-configurationper terminal for whichgreetdshould be started.greeter-supplementary-groups(default:'())List of groups which should be added to
greeteruser. For instance:(greeter-supplementary-groups '("seat" "video"))Note that this example will fail if
seatgroup does not exist.
- Data Type: greetd-terminal-configuration
Configuration record for per terminal greetd daemon service.
greetd(default:greetd)The greetd package to use.
config-file-nameConfiguration file name to use for greetd daemon. Generally, autogenerated derivation based on
terminal-vtvalue.log-file-nameLog file name to use for greetd daemon. Generally, autogenerated name based on
terminal-vtvalue.terminal-vt(default: ‘"7"’)The VT to run on. Use of a specific VT with appropriate conflict avoidance is recommended.
terminal-switch(default:#f)Make this terminal active on start of
greetd.default-session-user(default: ‘"greeter"’)The user to use for running the greeter.
default-session-command(default:(greetd-agreety-session))Can be either instance of
greetd-agreety-sessionconfiguration orgexp->scriptlike object to use as greeter.
- Data Type: greetd-agreety-session
Configuration record for the agreety greetd greeter.
agreety(default:greetd)The package with
/bin/agreetycommand.command(default:(file-append bash "/bin/bash"))Command to be started by
/bin/agreetyon successful login.command-args(default:'("-l"))Command arguments to pass to command.
extra-env(default:'())Extra environment variables to set on login.
xdg-env?(default:#t)If true
XDG_RUNTIME_DIRandXDG_SESSION_TYPEwill be set before starting command. One should note that,extra-envvariables are set right after mentioned variables, so that they can be overriden.
- Data Type: greetd-wlgreet-session
Generic configuration record for the wlgreet greetd greeter.
wlgreet(default:wlgreet)The package with the
/bin/wlgreetcommand.command(default:(file-append sway "/bin/sway"))Command to be started by
/bin/wlgreeton successful login.command-args(default:'())Command arguments to pass to command.
output-mode(default:"all")Option to use for
outputModein the TOML configuration file.scale(default:1)Option to use for
scalein the TOML configuration file.background(default:'(0 0 0 0.9))RGBA list to use as the background colour of the login prompt.
headline(default:'(1 1 1 1))RGBA list to use as the headline colour of the UI popup.
prompt(default:'(1 1 1 1))RGBA list to use as the prompt colour of the UI popup.
prompt-error(default:'(1 1 1 1))RGBA list to use as the error colour of the UI popup.
border(default:'(1 1 1 1))RGBA list to use as the border colour of the UI popup.
extra-env(default:'())Extra environment variables to set on login.
- Data Type: greetd-wlgreet-sway-session
Sway-specific configuration record for the wlgreet greetd greeter.
wlgreet-session(default:(greetd-wlgreet-session))A
greetd-wlgreet-sessionrecord for generic wlgreet configuration, on top of the Sway-specificgreetd-wlgreet-sway-session.sway(default:sway)The package providing the
/bin/swaycommand.sway-configuration(default: #f)File-like object providing an additional Sway configuration file to be prepended to the mandatory part of the configuration.
Here is an example of a greetd configuration that uses wlgreet and Sway:
(greetd-configuration ;; We need to give the greeter user these permissions, otherwise ;; Sway will crash on launch. (greeter-supplementary-groups (list "video" "input" "seat")) (terminals (list (greetd-terminal-configuration (terminal-vt "1") (terminal-switch #t) (default-session-command (greetd-wlgreet-sway-session (sway-configuration (local-file "sway-greetd.conf"))))))))
Next: Ротация логов, Previous: Базовые службы, Up: Сервисы [Contents][Index]
12.9.2 Запланированное исполнения задач
The (gnu services mcron) module provides an interface to
GNU mcron, a daemon to run jobs at scheduled times (see GNU mcron). GNU mcron is similar to the traditional Unix
cron daemon; the main difference is that it is implemented in
Guile Scheme, which provides a lot of flexibility when specifying the
scheduling of jobs and their actions.
The example below defines an operating system that runs the
updatedb (see Invoking updatedb in Finding Files) and
the guix gc commands (see Вызов guix gc) daily, as well as
the mkid command on behalf of an unprivileged user (see mkid
invocation in ID Database Utilities). It uses gexps to introduce
job definitions that are passed to mcron (see G-Expressions).
(use-modules (guix) (gnu) (gnu services mcron)) (use-package-modules base idutils) (define updatedb-job ;; Run 'updatedb' at 3AM every day. Here we write the ;; job's action as a Scheme procedure. #~(job '(next-hour '(3)) (lambda () (execl (string-append #$findutils "/bin/updatedb") "updatedb" "--prunepaths=/tmp /var/tmp /gnu/store")) "updatedb")) (define garbage-collector-job ;; Collect garbage 5 minutes after midnight every day. ;; The job's action is a shell command. #~(job "5 0 * * *" ;Vixie cron syntax "guix gc -F 1G")) (define idutils-job ;; Update the index database as user "charlie" at 12:15PM ;; and 19:15PM. This runs from the user's home directory. #~(job '(next-minute-from (next-hour '(12 19)) '(15)) (string-append #$idutils "/bin/mkid src") #:user "charlie")) (operating-system ;; … ;; %BASE-SERVICES already includes an instance of ;; 'mcron-service-type', which we extend with additional ;; jobs using 'simple-service'. (services (cons (simple-service 'my-cron-jobs mcron-service-type (list garbage-collector-job updatedb-job idutils-job)) %base-services)))
Tip: When providing the action of a job specification as a procedure, you should provide an explicit name for the job via the optional 3rd argument as done in the
updatedb-jobexample above. Otherwise, the job would appear as “Lambda function” in the output ofherd schedule mcron, which is not nearly descriptive enough!
For more complex jobs defined in Scheme where you need control over the top
level, for instance to introduce a use-modules form, you can move
your code to a separate program using the program-file procedure of
the (guix gexp) module (see G-Expressions). The example below
illustrates that.
(define %battery-alert-job
;; Beep when the battery percentage falls below %MIN-LEVEL.
#~(job
'(next-minute (range 0 60 1))
#$(program-file
"battery-alert.scm"
(with-imported-modules (source-module-closure
'((guix build utils)))
#~(begin
(use-modules (guix build utils)
(ice-9 popen)
(ice-9 regex)
(ice-9 textual-ports)
(srfi srfi-2))
(define %min-level 20)
(setenv "LC_ALL" "C") ;ensure English output
(and-let* ((input-pipe (open-pipe*
OPEN_READ
#$(file-append acpi "/bin/acpi")))
(output (get-string-all input-pipe))
(m (string-match "Discharging, ([0-9]+)%" output))
(level (string->number (match:substring m 1)))
((< level %min-level)))
(format #t "warning: Battery level is low (~a%)~%" level)
(invoke #$(file-append beep "/bin/beep") "-r5")))))))
See mcron job specifications in GNU mcron, for more information on mcron job specifications. Below is the reference of the mcron service.
On a running system, you can use the schedule action of the service
to visualize the mcron jobs that will be executed next:
# herd schedule mcron
The example above lists the next five tasks that will be executed, but you can also specify the number of tasks to display:
# herd schedule mcron 10
- Scheme Variable: mcron-service-type
This is the type of the
mcronservice, whose value is anmcron-configurationobject.This service type can be the target of a service extension that provides additional job specifications (see Структура сервисов). In other words, it is possible to define services that provide additional mcron jobs to run.
- Data Type: mcron-configuration
Available
mcron-configurationfields are:mcron(default:mcron) (type: file-like)The mcron package to use.
jobs(default:()) (type: list-of-gexps)This is a list of gexps (see G-Expressions), where each gexp corresponds to an mcron job specification (see mcron job specifications in GNU mcron).
log?(default:#t) (type: boolean)Log messages to standard output.
log-format(default:"~1@*~a ~a: ~a~%") (type: string)(ice-9 format)format string for log messages. The default value produces messages like "‘pid name: message"’ (see Invoking in GNU mcron). Each message is also prefixed by a timestamp by GNU Shepherd.
Next: Networking Setup, Previous: Запланированное исполнения задач, Up: Сервисы [Contents][Index]
12.9.3 Ротация логов
Log files such as those found in /var/log tend to grow endlessly, so
it’s a good idea to rotate them once in a while—i.e., archive their
contents in separate files, possibly compressed. The (gnu services
admin) module provides an interface to GNU Rot[t]log, a log rotation
tool (see GNU Rot[t]log Manual).
This service is part of %base-services, and thus enabled by default,
with the default settings, for commonly encountered log files. The example
below shows how to extend it with an additional rotation, should you
need to do that (usually, services that produce log files already take care
of that):
(use-modules (guix) (gnu)) (use-service-modules admin) (define my-log-files ;; Log files that I want to rotate. '("/var/log/something.log" "/var/log/another.log")) (operating-system ;; … (services (cons (simple-service 'rotate-my-stuff rottlog-service-type (list (log-rotation (frequency 'daily) (files my-log-files)))) %base-services)))
- Scheme Variable: rottlog-service-type
This is the type of the Rottlog service, whose value is a
rottlog-configurationobject.Other services can extend this one with new
log-rotationobjects (see below), thereby augmenting the set of files to be rotated.This service type can define mcron jobs (see Запланированное исполнения задач) to run the rottlog service.
- Data Type: rottlog-configuration
Data type representing the configuration of rottlog.
rottlog(default:rottlog)The Rottlog package to use.
rc-file(default:(file-append rottlog "/etc/rc"))The Rottlog configuration file to use (see Mandatory RC Variables in GNU Rot[t]log Manual).
rotations(default:%default-rotations)A list of
log-rotationobjects as defined below.jobsThis is a list of gexps where each gexp corresponds to an mcron job specification (see Запланированное исполнения задач).
- Data Type: log-rotation
Data type representing the rotation of a group of log files.
Taking an example from the Rottlog manual (see Period Related File Examples in GNU Rot[t]log Manual), a log rotation might be defined like this:
(log-rotation (frequency 'daily) (files '("/var/log/apache/*")) (options '("storedir apache-archives" "rotate 6" "notifempty" "nocompress")))The list of fields is as follows:
frequency(default:'weekly)The log rotation frequency, a symbol.
filesThe list of files or file glob patterns to rotate.
options(default:%default-log-rotation-options)The list of rottlog options for this rotation (see Configuration parameters in GNU Rot[t]log Manual).
post-rotate(default:#f)Either
#for a gexp to execute once the rotation has completed.
- Scheme Variable: %default-rotations
Specifies weekly rotation of
%rotated-filesand of /var/log/guix-daemon.log.
- Scheme Variable: %rotated-files
The list of syslog-controlled files to be rotated. By default it is:
'("/var/log/messages" "/var/log/secure" "/var/log/debug" \ "/var/log/maillog").
Some log files just need to be deleted periodically once they are old,
without any other criterion and without any archival step. This is the case
of build logs stored by guix-daemon under
/var/log/guix/drvs (see Вызов guix-daemon). The
log-cleanup service addresses this use case. For example,
%base-services (see Базовые службы) includes the following:
;; Periodically delete old build logs. (service log-cleanup-service-type (log-cleanup-configuration (directory "/var/log/guix/drvs")))
That ensures build logs do not accumulate endlessly.
- Scheme Variable: log-cleanup-service-type
This is the type of the service to delete old logs. Its value must be a
log-cleanup-configurationrecord as described below.
- Data Type: log-cleanup-configuration
Data type representing the log cleanup configuration
directoryName of the directory containing log files.
expiry(default:(* 6 30 24 3600))Age in seconds after which a file is subject to deletion (six months by default).
schedule(default:"30 12 01,08,15,22 * *")String or gexp denoting the corresponding mcron job schedule (see Запланированное исполнения задач).
Anonip Service
Anonip is a privacy filter that removes IP address from web server logs. This service creates a FIFO and filters any written lines with anonip before writing the filtered log to a target file.
The following example sets up the FIFO /var/run/anonip/https.access.log and writes the filtered log file /var/log/anonip/https.access.log.
(service anonip-service-type
(anonip-configuration
(input "/var/run/anonip/https.access.log")
(output "/var/log/anonip/https.access.log")))
Configure your web server to write its logs to the FIFO at /var/run/anonip/https.access.log and collect the anonymized log file at /var/web-logs/https.access.log.
- Data Type: anonip-configuration
This data type represents the configuration of anonip. It has the following parameters:
anonip(default:anonip)The anonip package to use.
inputThe file name of the input log file to process. The service creates a FIFO of this name. The web server should write its logs to this FIFO.
outputThe file name of the processed log file.
The following optional settings may be provided:
skip-private?When
#truedo not mask addresses in private ranges.columnA 1-based indexed column number. Assume IP address is in the specified column (default is 1).
replacementReplacement string in case address parsing fails, e.g.
"0.0.0.0".ipv4maskNumber of bits to mask in IPv4 addresses.
ipv6maskNumber of bits to mask in IPv6 addresses.
incrementIncrement the IP address by the given number. By default this is zero.
delimiterLog delimiter string.
regexRegular expression for detecting IP addresses. Use this instead of
column.
Next: Сервисы сети, Previous: Ротация логов, Up: Сервисы [Contents][Index]
12.9.4 Networking Setup
The (gnu services networking) module provides services to configure
network interfaces and set up networking on your machine. Those services
provide different ways for you to set up your machine: by declaring a static
network configuration, by running a Dynamic Host Configuration Protocol
(DHCP) client, or by running daemons such as NetworkManager and Connman that
automate the whole process, automatically adapt to connectivity changes, and
provide a high-level user interface.
On a laptop, NetworkManager and Connman are by far the most convenient
options, which is why the default desktop services include NetworkManager
(see %desktop-services). For a server, or for
a virtual machine or a container, static network configuration or a simple
DHCP client are often more appropriate.
This section describes the various network setup services available, starting with static network configuration.
- Scheme Variable: static-networking-service-type
This is the type for statically-configured network interfaces. Its value must be a list of
static-networkingrecords. Each of them declares a set of addresses, routes, and links, as shown below.Here is the simplest configuration, with only one network interface controller (NIC) and only IPv4 connectivity:
;; Static networking for one NIC, IPv4-only. (service static-networking-service-type (list (static-networking (addresses (list (network-address (device "eno1") (value "10.0.2.15/24")))) (routes (list (network-route (destination "default") (gateway "10.0.2.2")))) (name-servers '("10.0.2.3")))))
The snippet above can be added to the
servicesfield of your operating system configuration (see Использование системы конфигурации). It will configure your machine to have 10.0.2.15 as its IP address, with a 24-bit netmask for the local network—meaning that any 10.0.2.x address is on the local area network (LAN). Traffic to addresses outside the local network is routed via 10.0.2.2. Host names are resolved by sending domain name system (DNS) queries to 10.0.2.3.
- Data Type: static-networking
This is the data type representing a static network configuration.
As an example, here is how you would declare the configuration of a machine with a single network interface controller (NIC) available as
eno1, and with one IPv4 and one IPv6 address:;; Network configuration for one NIC, IPv4 + IPv6. (static-networking (addresses (list (network-address (device "eno1") (value "10.0.2.15/24")) (network-address (device "eno1") (value "2001:123:4567:101::1/64")))) (routes (list (network-route (destination "default") (gateway "10.0.2.2")) (network-route (destination "default") (gateway "2020:321:4567:42::1")))) (name-servers '("10.0.2.3")))
If you are familiar with the
ipcommand of theiproute2package found on Linux-based systems, the declaration above is equivalent to typing:ip address add 10.0.2.15/24 dev eno1 ip address add 2001:123:4567:101::1/64 dev eno1 ip route add default via inet 10.0.2.2 ip route add default via inet6 2020:321:4567:42::1
Run
man 8 ipfor more info. Venerable GNU/Linux users will certainly know how to do it withifconfigandroute, but we’ll spare you that.The available fields of this data type are as follows:
addresseslinks(default:'())routes(default:'())The list of
network-address,network-link, andnetwork-routerecords for this network (see below).name-servers(default:'())The list of IP addresses (strings) of domain name servers. These IP addresses go to /etc/resolv.conf.
provision(default:'(networking))If true, this should be a list of symbols for the Shepherd service corresponding to this network configuration.
requirement(default'())The list of Shepherd services depended on.
- Data Type: network-address
This is the data type representing the IP address of a network interface.
deviceThe name of the network interface for this address—e.g.,
"eno1".valueThe actual IP address and network mask, in CIDR (Classless Inter-Domain Routing) notation, as a string.
For example,
"10.0.2.15/24"denotes IPv4 address 10.0.2.15 on a 24-bit sub-network—all 10.0.2.x addresses are on the same local network.ipv6?Whether
valuedenotes an IPv6 address. By default this is automatically determined.
- Data Type: network-route
This is the data type representing a network route.
destinationThe route destination (a string), either an IP address and network mask or
"default"to denote the default route.source(default:#f)The route source.
device(default:#f)The device used for this route—e.g.,
"eno2".ipv6?(default: auto)Whether this is an IPv6 route. By default this is automatically determined based on
destinationorgateway.gateway(default:#f)IP address (a string) through which traffic is routed.
- Data Type: network-link
Data type for a network link (see Link in Guile-Netlink Manual).
nameThe name of the link—e.g.,
"v0p0".typeA symbol denoting the type of the link—e.g.,
'veth.argumentsList of arguments for this type of link.
- Scheme Variable: %loopback-static-networking
This is the
static-networkingrecord representing the “loopback device”,lo, for IP addresses 127.0.0.1 and ::1, and providing theloopbackShepherd service.
- Scheme Variable: %qemu-static-networking
This is the
static-networkingrecord representing network setup when using QEMU’s user-mode network stack oneth0(see Using the user mode network stack in QEMU Documentation).
- Scheme Variable: dhcp-client-service-type
This is the type of services that run dhcp, a Dynamic Host Configuration Protocol (DHCP) client.
- Data Type: dhcp-client-configuration
Data type representing the configuration of the DHCP client service.
package(default:isc-dhcp)DHCP client package to use.
interfaces(default:'all)Either
'allor the list of interface names that the DHCP client should listen on—e.g.,'("eno1").When set to
'all, the DHCP client listens on all the available non-loopback interfaces that can be activated. Otherwise the DHCP client listens only on the specified interfaces.
- Scheme Variable: network-manager-service-type
This is the service type for the NetworkManager service. The value for this service type is a
network-manager-configurationrecord.This service is part of
%desktop-services(see Сервисы рабочего стола).
- Data Type: network-manager-configuration
Data type representing the configuration of NetworkManager.
network-manager(default:network-manager)The NetworkManager package to use.
dns(default:"default")Processing mode for DNS, which affects how NetworkManager uses the
resolv.confconfiguration file.- ‘по умолчанию’
NetworkManager will update
resolv.confto reflect the nameservers provided by currently active connections.- ‘dnsmasq’
NetworkManager will run
dnsmasqas a local caching nameserver, using a conditional forwarding configuration if you are connected to a VPN, and then updateresolv.confto point to the local nameserver.With this setting, you can share your network connection. For example when you want to share your network connection to another laptop via an Ethernet cable, you can open
nm-connection-editorand configure the Wired connection’s method for IPv4 and IPv6 to be “Shared to other computers” and reestablish the connection (or reboot).You can also set up a host-to-guest connection to QEMU VMs (see Установка Guix на виртуальную машину (VM)). With a host-to-guest connection, you can e.g. access a Web server running on the VM (see Веб-сервисы) from a Web browser on your host system, or connect to the VM via SSH (see
openssh-service-type). To set up a host-to-guest connection, run this command once:nmcli connection add type tun \ connection.interface-name tap0 \ tun.mode tap tun.owner $(id -u) \ ipv4.method shared \ ipv4.addresses 172.28.112.1/24
Then each time you launch your QEMU VM (see Running Guix in a Virtual Machine), pass -nic tap,ifname=tap0,script=no,downscript=no to
qemu-system-....- ‘none’
NetworkManager will not modify
resolv.conf.
vpn-plugins(default:'())This is the list of available plugins for virtual private networks (VPNs). An example of this is the
network-manager-openvpnpackage, which allows NetworkManager to manage VPNs via OpenVPN.
- Scheme Variable: connman-service-type
This is the service type to run Connman, a network connection manager.
Its value must be an
connman-configurationrecord as in this example:(service connman-service-type (connman-configuration (disable-vpn? #t)))See below for details about
connman-configuration.
- Data Type: connman-configuration
Data Type representing the configuration of connman.
connman(default: connman)The connman package to use.
disable-vpn?(default:#f)When true, disable connman’s vpn plugin.
- Scheme Variable: wpa-supplicant-service-type
This is the service type to run WPA supplicant, an authentication daemon required to authenticate against encrypted WiFi or ethernet networks.
- Data Type: wpa-supplicant-configuration
Data type representing the configuration of WPA Supplicant.
It takes the following parameters:
wpa-supplicant(default:wpa-supplicant)The WPA Supplicant package to use.
features(default:'())List of services that should be started before WPA Supplicant starts.
dbus?(default:#t)Whether to listen for requests on D-Bus.
pid-file(default:"/var/run/wpa_supplicant.pid")Where to store the PID file.
interface(default:#f)If this is set, it must specify the name of a network interface that WPA supplicant will control.
config-file(default:#f)Optional configuration file to use.
extra-options(default:'())List of additional command-line arguments to pass to the daemon.
Some networking devices such as modems require special care, and this is what the services below focus on.
- Scheme Variable: modem-manager-service-type
This is the service type for the ModemManager service. The value for this service type is a
modem-manager-configurationrecord.This service is part of
%desktop-services(see Сервисы рабочего стола).
- Data Type: modem-manager-configuration
Data type representing the configuration of ModemManager.
modem-manager(default:modem-manager)The ModemManager package to use.
- Scheme Variable: usb-modeswitch-service-type
This is the service type for the USB_ModeSwitch service. The value for this service type is a
usb-modeswitch-configurationrecord.When plugged in, some USB modems (and other USB devices) initially present themselves as a read-only storage medium and not as a modem. They need to be modeswitched before they are usable. The USB_ModeSwitch service type installs udev rules to automatically modeswitch these devices when they are plugged in.
This service is part of
%desktop-services(see Сервисы рабочего стола).
- Data Type: usb-modeswitch-configuration
Data type representing the configuration of USB_ModeSwitch.
port(default:22)The USB_ModeSwitch package providing the binaries for modeswitching.
port(default:22)The package providing the device data and udev rules file used by USB_ModeSwitch.
config-file(default:#~(string-append #$usb-modeswitch:dispatcher "/etc/usb_modeswitch.conf"))Which config file to use for the USB_ModeSwitch dispatcher. By default the config file shipped with USB_ModeSwitch is used which disables logging to /var/log among other default settings. If set to
#f, no config file is used.
Next: Автоматические обновления, Previous: Networking Setup, Up: Сервисы [Contents][Index]
12.9.5 Сервисы сети
The (gnu services networking) module discussed in the previous
section provides services for more advanced setups: providing a DHCP service
for others to use, filtering packets with iptables or nftables, running a
WiFi access point with hostapd, running the inetd
“superdaemon”, and more. This section describes those.
- Scheme Procedure: dhcpd-service-type
This type defines a service that runs a DHCP daemon. To create a service of this type, you must supply a
<dhcpd-configuration>. For example:(service dhcpd-service-type (dhcpd-configuration (config-file (local-file "my-dhcpd.conf")) (interfaces '("enp0s25"))))
- Data Type: dhcpd-configuration
package(default:isc-dhcp)The package that provides the DHCP daemon. This package is expected to provide the daemon at sbin/dhcpd relative to its output directory. The default package is the ISC’s DHCP server.
config-file(default:#f)The configuration file to use. This is required. It will be passed to
dhcpdvia its-cfoption. This may be any “file-like” object (see file-like objects). Seeman dhcpd.conffor details on the configuration file syntax.version(default:"4")The DHCP version to use. The ISC DHCP server supports the values “4”, “6”, and “4o6”. These correspond to the
dhcpdprogram options-4,-6, and-4o6. Seeman dhcpdfor details.run-directory(default:"/run/dhcpd")The run directory to use. At service activation time, this directory will be created if it does not exist.
pid-file(default:"/run/dhcpd/dhcpd.pid")The PID file to use. This corresponds to the
-pfoption ofdhcpd. Seeman dhcpdfor details.interfaces(default:'())The names of the network interfaces on which dhcpd should listen for broadcasts. If this list is not empty, then its elements (which must be strings) will be appended to the
dhcpdinvocation when starting the daemon. It may not be necessary to explicitly specify any interfaces here; seeman dhcpdfor details.
- Процедура Scheme: sane-service-type
This is the service type to run the hostapd daemon to set up WiFi (IEEE 802.11) access points and authentication servers. Its associated value must be a
hostapd-configurationas shown below:;; Use wlan1 to run the access point for "My Network". (service hostapd-service-type (hostapd-configuration (interface "wlan1") (ssid "My Network") (channel 12)))
- Конфигурирование: системы
Этот тип данных представляет машины для сборки, на которые демон может разгружать сборки. Важные поля:
speed(default:1.0)Используемый пакет hostapd.
port(default:22)The network interface to run the WiFi access point.
ssidThe SSID (service set identifier), a string that identifies this network.
port(default:22)Whether to broadcast this SSID.
speed(default:1.0)Используемый канал Wi-Fi.
speed(default:1.0)The driver interface type.
"nl80211"is used with all Linux mac80211 drivers. Use"none"if building hostapd as a standalone RADIUS server that does # not control any wireless/wired driver.extra-settings(default:"")Extra settings to append as-is to the hostapd configuration file. See https://w1.fi/cgit/hostap/plain/hostapd/hostapd.conf for the configuration file reference.
- Процедура Scheme: sane-service-type
This is the type of a service to simulate WiFi networking, which can be useful in virtual machines for testing purposes. The service loads the Linux kernel
mac80211_hwsimmodule and starts hostapd to create a pseudo WiFi network that can be seen onwlan0, by default.The service’s value is a
hostapd-configurationrecord.
- Scheme Variable: iptables-service-type
This is the service type to set up an iptables configuration. iptables is a packet filtering framework supported by the Linux kernel. This service supports configuring iptables for both IPv4 and IPv6. A simple example configuration rejecting all incoming connections except those to the ssh port 22 is shown below.
(service iptables-service-type (iptables-configuration (ipv4-rules (plain-file "iptables.rules" "*filter :INPUT ACCEPT :FORWARD ACCEPT :OUTPUT ACCEPT -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT -A INPUT -p tcp --dport 22 -j ACCEPT -A INPUT -j REJECT --reject-with icmp-port-unreachable COMMIT ")) (ipv6-rules (plain-file "ip6tables.rules" "*filter :INPUT ACCEPT :FORWARD ACCEPT :OUTPUT ACCEPT -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT -A INPUT -p tcp --dport 22 -j ACCEPT -A INPUT -j REJECT --reject-with icmp6-port-unreachable COMMIT "))))
- Data Type: iptables-configuration
The data type representing the configuration of iptables.
iptables(default:iptables)The iptables package that provides
iptables-restoreandip6tables-restore.ipv4-rules(default:%iptables-accept-all-rules)The iptables rules to use. It will be passed to
iptables-restore. This may be any “file-like” object (see file-like objects).ipv6-rules(default:%iptables-accept-all-rules)The ip6tables rules to use. It will be passed to
ip6tables-restore. This may be any “file-like” object (see file-like objects).
- Scheme Variable: nftables-service-type
This is the service type to set up a nftables configuration. nftables is a netfilter project that aims to replace the existing iptables, ip6tables, arptables and ebtables framework. It provides a new packet filtering framework, a new user-space utility
nft, and a compatibility layer for iptables. This service comes with a default ruleset%default-nftables-rulesetthat rejecting all incoming connections except those to the ssh port 22. To use it, simply write:
- Тип данных: build-machine
Управление конфигурацией операционной системы.
speed(default:1.0)The nftables package that provides
nft.features(default:'())The nftables ruleset to use. This may be any “file-like” object (see file-like objects).
- Scheme Variable: ntp-service-type
This is the type of the service running the Network Time Protocol (NTP) daemon,
ntpd. The daemon will keep the system clock synchronized with that of the specified NTP servers.The value of this service is an
ntpd-configurationobject, as described below.
- Data Type: ntp-configuration
This is the data type for the NTP service configuration.
servers(default:%ntp-servers)This is the list of servers (
<ntp-server>records) with whichntpdwill be synchronized. See thentp-serverdata type definition below.parallel-builds(default:1)This determines whether
ntpdis allowed to make an initial adjustment of more than 1,000 seconds.ntp(default:ntp)The NTP package to use.
- Scheme Variable: %ntp-servers
List of host names used as the default NTP servers. These are servers of the NTP Pool Project.
- Data Type: ntp-server
The data type representing the configuration of a NTP server.
port(default:22)The type of the NTP server, given as a symbol. One of
'pool,'server,'peer,'broadcastor'manycastclient.addressПорядок следования устройств имеет значение.
optionsNTPD options to use with that specific server, given as a list of option names and/or of option names and values tuples. The following example define a server to use with the options iburst and prefer, as well as version 3 and a maxpoll time of 16 seconds.
(ntp-server (type 'server) (address "some.ntp.server.org") (options `(iburst (version 3) (maxpoll 16) prefer))))
- Scheme Procedure: openntpd-service-type
Run the
ntpd, the Network Time Protocol (NTP) daemon, as implemented by OpenNTPD. The daemon will keep the system clock synchronized with that of the given servers.(service openntpd-service-type (openntpd-configuration (listen-on '("127.0.0.1" "::1")) (sensor '("udcf0 correction 70000")) (constraint-from '("www.gnu.org")) (constraints-from '("https://www.google.com/"))))
- Scheme Variable: %openntpd-servers
This variable is a list of the server addresses defined in
%ntp-servers.
- Data Type: openntpd-configuration
openntpd(default:(file-append openntpd "/sbin/ntpd"))The openntpd executable to use.
listen-on(default:'("127.0.0.1" "::1"))A list of local IP addresses or hostnames the ntpd daemon should listen on.
query-from(default:'())A list of local IP address the ntpd daemon should use for outgoing queries.
sensor(default:'())Specify a list of timedelta sensor devices ntpd should use.
ntpdwill listen to each sensor that actually exists and ignore non-existent ones. See upstream documentation for more information.features(default:'())Specify a list of IP addresses or hostnames of NTP servers to synchronize to.
features(default:'())Specify a list of IP addresses or hostnames of NTP pools to synchronize to.
constraint-from(default:'())ntpdcan be configured to query the ‘Date’ from trusted HTTPS servers via TLS. This time information is not used for precision but acts as an authenticated constraint, thereby reducing the impact of unauthenticated NTP man-in-the-middle attacks. Specify a list of URLs, IP addresses or hostnames of HTTPS servers to provide a constraint.constraints-from(default:'())As with constraint from, specify a list of URLs, IP addresses or hostnames of HTTPS servers to provide a constraint. Should the hostname resolve to multiple IP addresses,
ntpdwill calculate a median constraint from all of them.
- Scheme variable: inetd-service-type
This service runs the
inetd(see inetd invocation in GNU Inetutils) daemon.inetdlistens for connections on internet sockets, and lazily starts the specified server program when a connection is made on one of these sockets.The value of this service is an
inetd-configurationobject. The following example configures theinetddaemon to provide the built-inechoservice, as well as an smtp service which forwards smtp traffic over ssh to a serversmtp-serverbehind a gatewayhostname:(service inetd-service-type (inetd-configuration (entries (list (inetd-entry (name "echo") (socket-type 'stream) (protocol "tcp") (wait? #f) (user "root")) (inetd-entry (node "127.0.0.1") (name "smtp") (socket-type 'stream) (protocol "tcp") (wait? #f) (user "root") (program (file-append openssh "/bin/ssh")) (arguments '("ssh" "-qT" "-i" "/path/to/ssh_key" "-W" "smtp-server:25" "user@hostname")))))))See below for more details about
inetd-configuration.
- Data Type: inetd-configuration
Data type representing the configuration of
inetd.program(default:(file-append inetutils "/libexec/inetd"))The
inetdexecutable to use.entries(default:'())A list of
inetdservice entries. Each entry should be created by theinetd-entryconstructor.
- Data Type: inetd-entry
Data type representing an entry in the
inetdconfiguration. Each entry corresponds to a socket whereinetdwill listen for requests.node(default:#f)Optional string, a comma-separated list of local addresses
inetdshould use when listening for this service. See Configuration file in GNU Inetutils for a complete description of all options.nameA string, the name must correspond to an entry in
/etc/services.socket-typeOne of
'stream,'dgram,'raw,'rdmor'seqpacket.protocolA string, must correspond to an entry in
/etc/protocols.wait?(default:#t)Whether
inetdshould wait for the server to exit before listening to new service requests.userA string containing the user (and, optionally, group) name of the user as whom the server should run. The group name can be specified in a suffix, separated by a colon or period, i.e.
"user","user:group"or"user.group".program(default:"internal")The server program which will serve the requests, or
"internal"ifinetdshould use a built-in service.arguments(default:'())A list strings or file-like objects, which are the server program’s arguments, starting with the zeroth argument, i.e. the name of the program itself. For
inetd’s internal services, this entry must be'()or'("internal").
See Configuration file in GNU Inetutils for a more detailed discussion of each configuration field.
- Scheme Variable: etc-service-type
This is the type of the service running a OpenDHT node,
dhtnode. The daemon can be used to host your own proxy service to the distributed hash table (DHT), for example to connect to with Jami, among other applications.Важно: When using the OpenDHT proxy server, the IP addresses it “sees” from the clients should be addresses reachable from other peers. In practice this means that a publicly reachable address is best suited for a proxy server, outside of your private network. For example, hosting the proxy server on a IPv4 private local network and exposing it via port forwarding could work for external peers, but peers local to the proxy would have their private addresses shared with the external peers, leading to connectivity problems.
The value of this service is a
opendht-configurationobject, as described below.
- Конфигурирование: системы
Available
opendht-configurationfields are:opendht(default:opendht) (type: file-like)Используемый пакет
webssh.peer-discovery?(default:#f) (type: boolean)Whether to enable the multicast local peer discovery mechanism.
enable-logging?(default:#f) (type: boolean)Whether to enable logging messages to syslog. It is disabled by default as it is rather verbose.
debug?(default:#f) (type: boolean)Whether to enable debug-level logging messages. This has no effect if logging is disabled.
bootstrap-host(default:"bootstrap.jami.net:4222") (type: maybe-string)The node host name that is used to make the first connection to the network. A specific port value can be provided by appending the
:PORTsuffix. By default, it uses the Jami bootstrap nodes, but any host can be specified here. It’s also possible to disable bootstrapping by explicitly setting this field to the%unset-valuevalue.port(default:4222) (type: maybe-number)The UDP port to bind to. When left unspecified, an available port is automatically selected.
proxy-server-port(type: maybe-number)Spawn a proxy server listening on the specified port.
proxy-server-port-tls(type: maybe-number)Spawn a proxy server listening to TLS connections on the specified port.
- Scheme Variable: tor-service-type
This is the type for a service that runs the Tor anonymous networking daemon. The service is configured using a
<tor-configuration>record. By default, the Tor daemon runs as thetorunprivileged user, which is a member of thetorgroup.
- Data Type: tor-configuration
tor(default:tor)The package that provides the Tor daemon. This package is expected to provide the daemon at bin/tor relative to its output directory. The default package is the Tor Project’s implementation.
config-file(default:(plain-file "empty" ""))The configuration file to use. It will be appended to a default configuration file, and the final configuration file will be passed to
torvia its-foption. This may be any “file-like” object (see file-like objects). Seeman torfor details on the configuration file syntax.hidden-services(default:'())The list of
<hidden-service>records to use. For any hidden service you include in this list, appropriate configuration to enable the hidden service will be automatically added to the default configuration file. You may conveniently create<hidden-service>records using thetor-hidden-serviceprocedure described below.socks-socket-type(default:'tcp)The default socket type that Tor should use for its SOCKS socket. This must be either
'tcpor'unix. If it is'tcp, then by default Tor will listen on TCP port 9050 on the loopback interface (i.e., localhost). If it is'unix, then Tor will listen on the UNIX domain socket /var/run/tor/socks-sock, which will be made writable by members of thetorgroup.If you want to customize the SOCKS socket in more detail, leave
socks-socket-typeat its default value of'tcpand useconfig-fileto override the default by providing your ownSocksPortoption.port(default:22)Whether or not to provide a “control socket” by which Tor can be controlled to, for instance, dynamically instantiate tor onion services. If
#t, Tor will listen for control commands on the UNIX domain socket /var/run/tor/control-sock, which will be made writable by members of thetorgroup.
Define a new Tor hidden service called name and implementing mapping. mapping is a list of port/host tuples, such as:
'((22 "127.0.0.1:22") (80 "127.0.0.1:8080"))
In this example, port 22 of the hidden service is mapped to local port 22, and port 80 is mapped to local port 8080.
This creates a /var/lib/tor/hidden-services/name directory, where the hostname file contains the
.onionhost name for the hidden service.See the Tor project’s documentation for more information.
The (gnu services rsync) module provides the following services:
You might want an rsync daemon if you have files that you want available so anyone (or just yourself) can download existing files or upload new files.
- Scheme Variable: rsync-service-type
This is the service type for the rsync daemon, The value for this service type is a
rsync-configurationrecord as in this example:;; Export two directories over rsync. By default rsync listens on ;; all the network interfaces. (service rsync-service-type (rsync-configuration (modules (list (rsync-module (name "music") (file-name "/srv/zik") (read-only? #f)) (rsync-module (name "movies") (file-name "/home/charlie/movies"))))))
See below for details about
rsync-configuration.
- Data Type: rsync-configuration
Data type representing the configuration for
rsync-service.package(default: rsync)rsyncpackage to use.features(default:'())IP address on which
rsynclistens for incoming connections. If unspecified, it defaults to listening on all available addresses.port-number(default:873)TCP port on which
rsynclistens for incoming connections. If port is less than1024rsyncneeds to be started as therootuser and group.pid-file(default:"/var/run/rsyncd/rsyncd.pid")Name of the file where
rsyncwrites its PID.lock-file(default:"/var/run/rsyncd/rsyncd.lock")Name of the file where
rsyncwrites its lock file.log-file(default:"/var/log/rsyncd.log")Name of the file where
rsyncwrites its log file.port(default:22)Owner of the
rsyncprocess.group(default:"root")Group of the
rsyncprocess.uid(default:"rsyncd")User name or user ID that file transfers to and from that module should take place as when the daemon was run as
root.gid(default:"rsyncd")Group name or group ID that will be used when accessing the module.
modules(default:%default-modules)List of “modules”—i.e., directories exported over rsync. Each element must be a
rsync-modulerecord, as described below.
- Data Type: rsync-module
This is the data type for rsync “modules”. A module is a directory exported over the rsync protocol. The available fields are as follows:
nameThe module name. This is the name that shows up in URLs. For example, if the module is called
music, the corresponding URL will bersync://host.example.org/music.file-nameName of the directory being exported.
comment(default:"")Comment associated with the module. Client user interfaces may display it when they obtain the list of available modules.
read-only?(default:#t)Whether or not client will be able to upload files. If this is false, the uploads will be authorized if permissions on the daemon side permit it.
chroot?(default:#t)When this is true, the rsync daemon changes root to the module’s directory before starting file transfers with the client. This improves security, but requires rsync to run as root.
timeout(default:300)Idle time in seconds after which the daemon closes a connection with the client.
Модуль (guix inferior) предоставляет следующие процедуры для работы с
ранними версиями:
You might want a syncthing daemon if you have files between two or more computers and want to sync them in real time, safely protected from prying eyes.
- Процедура Scheme: sane-service-type
This is the service type for the syncthing daemon, The value for this service type is a
syncthing-configurationrecord as in this example:See below for details about
syncthing-configuration.- Конфигурирование: системы
Управление конфигурацией операционной системы.
features(default:'())пакет
syncthingдля использования.arguments(default:'())Список флагов командной строки, которые следует передать команде
patch.features(default:'())Sum of logging flags, see Syncthing documentation logflags.
features(default:'())The user as which the Syncthing service is to be run. This assumes that the specified user exists.
port(default:22)The group as which the Syncthing service is to be run. This assumes that the specified group exists.
speed(default:1.0)Common configuration and data directory. The default configuration directory is $HOME of the specified Syncthing
user.
Furthermore, (gnu services ssh) provides the following services.
- Scheme Procedure: lsh-service [#:host-key "/etc/lsh/host-key"] [#:daemonic? #t] [#:interfaces '()] [#:port-number 22] [#:allow-empty-passwords? #f] [#:root-login? #f] [#:syslog-output? #t]
[#:x11-forwarding? #t] [#:tcp/ip-forwarding? #t] [#:password-authentication? #t] [#:public-key-authentication? #t] [#:initialize? #t] Run the
lshdprogram from lsh to listen on port port-number. host-key must designate a file containing the host key, and readable only by root.When daemonic? is true,
lshdwill detach from the controlling terminal and log its output to syslogd, unless one sets syslog-output? to false. Obviously, it also makes lsh-service depend on existence of syslogd service. When pid-file? is true,lshdwrites its PID to the file called pid-file.When initialize? is true, automatically create the seed and host key upon service activation if they do not exist yet. This may take long and require interaction.
When initialize? is false, it is up to the user to initialize the randomness generator (see lsh-make-seed in LSH Manual), and to create a key pair with the private key stored in file host-key (see lshd basics in LSH Manual).
When interfaces is empty, lshd listens for connections on all the network interfaces; otherwise, interfaces must be a list of host names or addresses.
allow-empty-passwords? specifies whether to accept log-ins with empty passwords, and root-login? specifies whether to accept log-ins as root.
The other options should be self-descriptive.
- Scheme Variable: openssh-service-type
This is the type for the OpenSSH secure shell daemon,
sshd. Its value must be anopenssh-configurationrecord as in this example:(service openssh-service-type (openssh-configuration (x11-forwarding? #t) (permit-root-login 'prohibit-password) (authorized-keys `(("alice" ,(local-file "alice.pub")) ("bob" ,(local-file "bob.pub"))))))See below for details about
openssh-configuration.This service can be extended with extra authorized keys, as in this example:
(service-extension openssh-service-type (const `(("charlie" ,(local-file "charlie.pub")))))
- Data Type: openssh-configuration
This is the configuration record for OpenSSH’s
sshd.port(default:22)The OpenSSH package to use.
pid-file(default:"/var/run/sshd.pid")Name of the file where
sshdwrites its PID.port-number(default:22)TCP port on which
sshdlistens for incoming connections.max-connections(default:200)Hard limit on the maximum number of simultaneous client connections, enforced by the inetd-style Shepherd service (see
make-inetd-constructorin The GNU Shepherd Manual).permit-root-login(default:#f)This field determines whether and when to allow logins as root. If
#f, root logins are disallowed; if#t, they are allowed. If it’s the symbol'prohibit-password, then root logins are permitted but not with password-based authentication.allow-empty-passwords?(default:#f)When true, users with empty passwords may log in. When false, they may not.
password-authentication?(default:#t)When true, users may log in with their password. When false, they have other authentication methods.
public-key-authentication?(default:#t)When true, users may log in using public key authentication. When false, users have to use other authentication method.
Authorized public keys are stored in ~/.ssh/authorized_keys. This is used only by protocol version 2.
x11-forwarding?(default:#f)When true, forwarding of X11 graphical client connections is enabled—in other words,
sshoptions -X and -Y will work.allow-agent-forwarding?(default:#t)Whether to allow agent forwarding.
allow-tcp-forwarding?(default:#t)Whether to allow TCP forwarding.
gateway-ports?(default:#f)Whether to allow gateway ports.
challenge-response-authentication?(default:#f)Specifies whether challenge response authentication is allowed (e.g. via PAM).
use-pam?(default:#t)Enables the Pluggable Authentication Module interface. If set to
#t, this will enable PAM authentication usingchallenge-response-authentication?andpassword-authentication?, in addition to PAM account and session module processing for all authentication types.Because PAM challenge response authentication usually serves an equivalent role to password authentication, you should disable either
challenge-response-authentication?orpassword-authentication?.print-last-log?(default:#t)Specifies whether
sshdshould print the date and time of the last user login when a user logs in interactively.subsystems(default:'(("sftp" "internal-sftp")))Configures external subsystems (e.g. file transfer daemon).
This is a list of two-element lists, each of which containing the subsystem name and a command (with optional arguments) to execute upon subsystem request.
The command
internal-sftpimplements an in-process SFTP server. Alternatively, one can specify thesftp-servercommand:(service openssh-service-type (openssh-configuration (subsystems `(("sftp" ,(file-append openssh "/libexec/sftp-server"))))))accepted-environment(default:'())List of strings describing which environment variables may be exported.
Each string gets on its own line. See the
AcceptEnvoption inman sshd_config.This example allows ssh-clients to export the
COLORTERMvariable. It is set by terminal emulators, which support colors. You can use it in your shell’s resource file to enable colors for the prompt and commands if this variable is set.(service openssh-service-type (openssh-configuration (accepted-environment '("COLORTERM"))))-
This is the list of authorized keys. Each element of the list is a user name followed by one or more file-like objects that represent SSH public keys. For example:
(openssh-configuration (authorized-keys `(("rekado" ,(local-file "rekado.pub")) ("chris" ,(local-file "chris.pub")) ("root" ,(local-file "rekado.pub") ,(local-file "chris.pub")))))registers the specified public keys for user accounts
rekado,chris, androot.Additional authorized keys can be specified via
service-extension.Note that this does not interfere with the use of ~/.ssh/authorized_keys.
generate-host-keys?(default:#t)Whether to generate host key pairs with
ssh-keygen -Aunder /etc/ssh if there are none.Generating key pairs takes a few seconds when enough entropy is available and is only done once. You might want to turn it off for instance in a virtual machine that does not need it because host keys are provided in some other way, and where the extra boot time is a problem.
log-level(default:'info)This is a symbol specifying the logging level:
quiet,fatal,error,info,verbose,debug, etc. See the man page for sshd_config for the full list of level names.extra-content(default:"")This field can be used to append arbitrary text to the configuration file. It is especially useful for elaborate configurations that cannot be expressed otherwise. This configuration, for example, would generally disable root logins, but permit them from one specific IP address:
(openssh-configuration (extra-content "\ Match Address 192.168.0.1 PermitRootLogin yes"))
- Scheme Procedure: dropbear-service [config]
Run the Dropbear SSH daemon with the given config, a
<dropbear-configuration>object.For example, to specify a Dropbear service listening on port 1234, add this call to the operating system’s
servicesfield:(dropbear-service (dropbear-configuration (port-number 1234)))
- Data Type: dropbear-configuration
This data type represents the configuration of a Dropbear SSH daemon.
dropbear(default: dropbear)The Dropbear package to use.
port-number(default: 22)The TCP port where the daemon waits for incoming connections.
syslog-output?(default:#t)Whether to enable syslog output.
pid-file(default:"/var/run/dropbear.pid")File name of the daemon’s PID file.
root-login?(default:#f)Whether to allow
rootlogins.allow-empty-passwords?(default:#f)Whether to allow empty passwords.
password-authentication?(default:#t)Whether to enable password-based authentication.
- Процедура Scheme: sane-service-type
This is the type for the AutoSSH program that runs a copy of
sshand monitors it, restarting it as necessary should it die or stop passing traffic. AutoSSH can be run manually from the command-line by passing arguments to the binaryautosshfrom the packageautossh, but it can also be run as a Guix service. This latter use case is documented here.AutoSSH can be used to forward local traffic to a remote machine using an SSH tunnel, and it respects the ~/.ssh/config of the user it is run as.
For example, to specify a service running autossh as the user
pinoand forwarding all local connections to port8081toremote:8081using an SSH tunnel, add this call to the operating system’sservicesfield:
- Тип данных: build-machine
Управление конфигурацией операционной системы.
port(default:22)The user as which the AutoSSH service is to be run. This assumes that the specified user exists.
port(default:22)Specifies the connection poll time in seconds.
port(default:22)Specifies how many seconds AutoSSH waits before the first connection test. After this first test, polling is resumed at the pace defined in
poll. When set to#f, the first poll is not treated specially and will also use the connection poll specified inpoll.port(default:22)Specifies how many seconds an SSH connection must be active before it is considered successful.
speed(default:1.0)The log level, corresponding to the levels used by syslog—so
0is the most silent while7is the chattiest.port(default:22)The maximum number of times SSH may be (re)started before AutoSSH exits. When set to
#f, no maximum is configured and AutoSSH may restart indefinitely.port(default:22)The message to append to the echo message sent when testing connections.
port(default:22)The ports used for monitoring the connection. When set to
"0", monitoring is disabled. When set to"n"where n is a positive integer, ports n and n+1 are used for monitoring the connection, such that port n is the base monitoring port andn+1is the echo port. When set to"n:m"where n and m are positive integers, the ports n and m are used for monitoring the connection, such that port n is the base monitoring port and m is the echo port.features(default:'())The list of command-line arguments to pass to
sshwhen it is run. Options -f and -M are reserved for AutoSSH and may cause undefined behaviour.
- Процедура Scheme: sane-service-type
This is the type for the WebSSH program that runs a web SSH client. WebSSH can be run manually from the command-line by passing arguments to the binary
wsshfrom the packagewebssh, but it can also be run as a Guix service. This latter use case is documented here.For example, to specify a service running WebSSH on loopback interface on port
8888with reject policy with a list of allowed to connection hosts, and NGINX as a reverse-proxy to this service listening for HTTPS connection, add this call to the operating system’sservicesfield:(service webssh-service-type (webssh-configuration (address "127.0.0.1") (port 8888) (policy 'reject) (known-hosts '("localhost ecdsa-sha2-nistp256 AAAA…" "127.0.0.1 ecdsa-sha2-nistp256 AAAA…")))) (service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (inherit %webssh-configuration-nginx) (server-name '("webssh.example.com")) (listen '("443 ssl")) (ssl-certificate (letsencrypt-certificate "webssh.example.com")) (ssl-certificate-key (letsencrypt-key "webssh.example.com")) (locations (cons (nginx-location-configuration (uri "/.well-known") (body '("root /var/www;"))) (nginx-server-configuration-locations %webssh-configuration-nginx))))))))
- Конфигурирование: системы
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет
webssh.port(default:22)User name or user ID that file transfers to and from that module should take place.
port(default:22)Group name or group ID that will be used when accessing the module.
features(default:'())IP address on which
websshlistens for incoming connections.port(default:22)TCP port on which
websshlistens for incoming connections.speed(default:1.0)Connection policy. reject policy requires to specify known-hosts.
inputs(default:'())List of hosts which allowed for SSH connection from
webssh.daemon-socket(default:"/var/guix/daemon-socket/socket")Name of the file where
websshwrites its log file.features(default:'())Logging level.
- Scheme Variable: %facebook-host-aliases
This variable contains a string for use in /etc/hosts (see Host Names in The GNU C Library Reference Manual). Each line contains a entry that maps a known server name of the Facebook on-line service—e.g.,
www.facebook.com—to the local host—127.0.0.1or its IPv6 equivalent,::1.This variable is typically used in the
hosts-filefield of anoperating-systemdeclaration (see /etc/hosts):(use-modules (gnu) (guix)) (operating-system (host-name "mymachine") ;; ... (hosts-file ;; Create a /etc/hosts file with aliases for "localhost" ;; and "mymachine", as well as for Facebook servers. (plain-file "hosts" (string-append (local-host-aliases host-name) %facebook-host-aliases))))
This mechanism can prevent programs running locally, such as Web browsers, from accessing Facebook.
The (gnu services avahi) provides the following definition.
- Scheme Variable: avahi-service-type
This is the service that runs
avahi-daemon, a system-wide mDNS/DNS-SD responder that allows for service discovery and “zero-configuration” host name lookups (see https://avahi.org/). Its value must be anavahi-configurationrecord—see below.This service extends the name service cache daemon (nscd) so that it can resolve
.localhost names using nss-mdns. See Служба выбора имён, for information on host name resolution.Additionally, add the avahi package to the system profile so that commands such as
avahi-browseare directly usable.
- Data Type: avahi-configuration
Data type representation the configuration for Avahi.
host-name(default:#f)If different from
#f, use that as the host name to publish for this machine; otherwise, use the machine’s actual host name.publish?(default:#t)When true, allow host names and services to be published (broadcast) over the network.
publish-workstation?(default:#t)When true,
avahi-daemonpublishes the machine’s host name and IP address via mDNS on the local network. To view the host names published on your local network, you can run:avahi-browse _workstation._tcp
wide-area?(default:#f)When true, DNS-SD over unicast DNS is enabled.
ipv4?(default:#t)ipv6?(default:#t)These fields determine whether to use IPv4/IPv6 sockets.
domains-to-browse(default:'())This is a list of domains to browse.
- Scheme Variable: openvswitch-service-type
This is the type of the Open vSwitch service, whose value should be an
openvswitch-configurationobject.
- Data Type: openvswitch-configuration
Data type representing the configuration of Open vSwitch, a multilayer virtual switch which is designed to enable massive network automation through programmatic extension.
package(default: openvswitch)Package object of the Open vSwitch.
- Scheme Variable: pagekite-service-type
This is the service type for the PageKite service, a tunneling solution for making localhost servers publicly visible, even from behind restrictive firewalls or NAT without forwarded ports. The value for this service type is a
pagekite-configurationrecord.Here’s an example exposing the local HTTP and SSH daemons:
(service pagekite-service-type (pagekite-configuration (kites '("http:@kitename:localhost:80:@kitesecret" "raw/22:@kitename:localhost:22:@kitesecret")) (extra-file "/etc/pagekite.rc")))
- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
port(default:22)Package object of PageKite.
port(default:22)PageKite name for authenticating to the frontend server.
speed(default:1.0)Shared secret for authenticating to the frontend server. You should probably put this inside
extra-fileinstead.speed(default:1.0)Connect to the named PageKite frontend server instead of the pagekite.net service.
kites(default:'("http:@kitename:localhost:80:@kitesecret"))List of service kites to use. Exposes HTTP on port 80 by default. The format is
proto:kitename:host:port:secret.speed(default:1.0)Extra configuration file to read, which you are expected to create manually. Use this to add additional options and manage shared secrets out-of-band.
- Процедура Scheme: sane-service-type
The service type for connecting to the Yggdrasil network, an early-stage implementation of a fully end-to-end encrypted IPv6 network.
Yggdrasil provides name-independent routing with cryptographically generated addresses. Static addressing means you can keep the same address as long as you want, even if you move to a new location, or generate a new address (by generating new keys) whenever you want. https://yggdrasil-network.github.io/2018/07/28/addressing.html
Pass it a value of
yggdrasil-configurationto connect it to public peers and/or local peers.Here is an example using public peers and a static address. The static signing and encryption keys are defined in /etc/yggdrasil-private.conf (the default value for
config-file).;; part of the operating-system declaration (service yggdrasil-service-type (yggdrasil-configuration (autoconf? #f) ;; use only the public peers (json-config ;; choose one from ;; https://github.com/yggdrasil-network/public-peers '((peers . #("tcp://1.2.3.4:1337")))) ;; /etc/yggdrasil-private.conf is the default value for config-file ))
# sample content for /etc/yggdrasil-private.conf { # Your public key. Your peers may ask you for this to put # into their AllowedPublicKeys configuration. PublicKey: 64277... # Your private key. DO NOT share this with anyone! PrivateKey: 5c750... }
- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Package object of Yggdrasil.
inputs(default:'())Contents of /etc/yggdrasil.conf. Will be merged with /etc/yggdrasil-private.conf. Note that these settings are stored in the Guix store, which is readable to all users. Do not store your private keys in it. See the output of
yggdrasil -genconffor a quick overview of valid keys and their default values.features(default:'())Whether to use automatic mode. Enabling it makes Yggdrasil use adynamic IP and peer with IPv6 neighbors.
log-level(default:'info)How much detail to include in logs. Use
'debugfor more detail.outputs(default:'("out"))Where to send logs. By default, the service logs standard output to /var/log/yggdrasil.log. The alternative is
'syslog, which sends output to the running syslog service.features(default:'())What HJSON file to load sensitive data from. This is where private keys should be stored, which are necessary to specify if you don’t want a randomized address after each restart. Use
#fto disable. Options defined in this file take precedence overjson-config. Use the output ofyggdrasil -genconfas a starting point. To configure a static address, delete everything except these options:-
EncryptionPublicKey -
EncryptionPrivateKey -
SigningPublicKey -
SigningPrivateKey
-
- Процедура Scheme: sane-service-type
The service type for connecting to the IPFS network, a global, versioned, peer-to-peer file system. Pass it a
ipfs-configurationto change the ports used for the gateway and API.Here’s an example configuration, using some non-standard ports:
(service guix-service-type (guix-configuration (build-accounts 5) (use-substitutes? #f)))
- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Package object of IPFS.
speed(default:1.0)Address of the gateway, in ‘multiaddress’ format.
speed(default:1.0)Address of the API endpoint, in ‘multiaddress’ format.
- Scheme Variable: profile-service-type
This is the type for the Keepalived routing software,
keepalived. Its value must be ankeepalived-configurationrecord as in this example for master machine:(service keepalived-service-type (keepalived-configuration (config-file (local-file "keepalived-master.conf"))))where keepalived-master.conf:
vrrp_instance my-group { state MASTER interface enp9s0 virtual_router_id 100 priority 100 unicast_peer { 10.0.0.2 } virtual_ipaddress { 10.0.0.4/24 } }and for backup machine:
(service keepalived-service-type (keepalived-configuration (config-file (local-file "keepalived-backup.conf"))))where keepalived-backup.conf:
vrrp_instance my-group { state BACKUP interface enp9s0 virtual_router_id 100 priority 99 unicast_peer { 10.0.0.3 } virtual_ipaddress { 10.0.0.4/24 } }
Next: Оконная система X, Previous: Сервисы сети, Up: Сервисы [Contents][Index]
12.9.6 Автоматические обновления
Guix provides a service to perform unattended upgrades: periodically, the system automatically reconfigures itself from the latest Guix. Guix System has several properties that make unattended upgrades safe:
- upgrades are transactional (either the upgrade succeeds or it fails, but you cannot end up with an “in-between” system state);
- the upgrade log is kept—you can view it with
guix system list-generations—and you can roll back to any previous generation, should the upgraded system fail to behave as intended; - channel code is authenticated so you know you can only run genuine code (see Каналы);
-
guix system reconfigureprevents downgrades, which makes it immune to downgrade attacks.
To set up unattended upgrades, add an instance of
unattended-upgrade-service-type like the one below to the list of
your operating system services:
(service unattended-upgrade-service-type)
The defaults above set up weekly upgrades: every Sunday at midnight. You do not need to provide the operating system configuration file: it uses /run/current-system/configuration.scm, which ensures it always uses your latest configuration—see provenance-service-type, for more information about this file.
There are several things that can be configured, in particular the
periodicity and services (daemons) to be restarted upon completion. When
the upgrade is successful, the service takes care of deleting system
generations older that some threshold, as per guix system
delete-generations. See the reference below for details.
To ensure that upgrades are actually happening, you can run guix
system describe. To investigate upgrade failures, visit the unattended
upgrade log file (see below).
- Процедура Scheme: sane-service-type
This is the service type for unattended upgrades. It sets up an mcron job (see Запланированное исполнения задач) that runs
guix system reconfigurefrom the latest version of the specified channels.Its value must be a
unattended-upgrade-configurationrecord (see below).
- Тип данных: build-machine
Этот тип данных представляет машины для сборки, на которые демон может разгружать сборки. Важные поля:
speed(default:1.0)This is the schedule of upgrades, expressed as a gexp containing an mcron job schedule (see mcron job specifications in GNU mcron).
port(default:22)This gexp specifies the channels to use for the upgrade (see Каналы). By default, the tip of the official
guixchannel is used.daemon-socket(default:"/var/guix/daemon-socket/socket")This field specifies the operating system configuration file to use. The default is to reuse the config file of the current configuration.
There are cases, though, where referring to /run/current-system/configuration.scm is not enough, for instance because that file refers to extra files (SSH public keys, extra configuration files, etc.) via
local-fileand similar constructs. For those cases, we recommend something along these lines:(unattended-upgrade-configuration (operating-system-file (file-append (local-file "." "config-dir" #:recursive? #t) "/config.scm")))The effect here is to import all of the current directory into the store, and to refer to config.scm within that directory. Therefore, uses of
local-filewithin config.scm will work as expected. See G-Expressions, for information aboutlocal-fileandfile-append.features(default:'())This field specifies the Shepherd services to restart when the upgrade completes.
Those services are restarted right away upon completion, as with
herd restart, which ensures that the latest version is running—remember that by defaultguix system reconfigureonly restarts services that are not currently running, which is conservative: it minimizes disruption but leaves outdated services running.Use
herd statusto find out candidates for restarting. See Сервисы, for general information about services. Common services to restart would includentpdandssh-daemon.By default, the
mcronservice is restarted. This ensures that the latest version of the unattended upgrade job will be used next time.features(default:'())This is the expiration time in seconds for system generations. System generations older that this amount of time are deleted with
guix system delete-generationswhen an upgrade completes.Примечание: The unattended upgrade service does not run the garbage collector. You will probably want to set up your own mcron job to run
guix gcperiodically.port(default:22)Maximum duration in seconds for the upgrade; past that time, the upgrade aborts.
This is primarily useful to ensure the upgrade does not end up rebuilding or re-downloading “the world”.
daemon-socket(default:"/var/guix/daemon-socket/socket")File where unattended upgrades are logged.
Next: Сервисы печати, Previous: Автоматические обновления, Up: Сервисы [Contents][Index]
12.9.7 Оконная система X
Support for the X Window graphical display system—specifically Xorg—is
provided by the (gnu services xorg) module. Note that there is no
xorg-service procedure. Instead, the X server is started by the
login manager, by default the GNOME Display Manager (GDM).
GDM of course allows users to log in into window managers and desktop environments other than GNOME; for those using GNOME, GDM is required for features such as automatic screen locking.
To use X11, you must install at least one window manager—for example
the windowmaker or openbox packages—preferably by adding it
to the packages field of your operating system definition
(see system-wide packages).
GDM also supports Wayland: it can itself use Wayland instead of X11 for its
user interface, and it can also start Wayland sessions. The former is
required for the latter, to enable, set wayland? to #t in
gdm-configuration.
- Scheme Variable: gdm-service-type
This is the type for the GNOME Desktop Manager (GDM), a program that manages graphical display servers and handles graphical user logins. Its value must be a
gdm-configuration(see below).GDM looks for session types described by the .desktop files in /run/current-system/profile/share/xsessions (for X11 sessions) and /run/current-system/profile/share/wayland-sessions (for Wayland sessions) and allows users to choose a session from the log-in screen. Packages such as
gnome,xfce,i3andswayprovide .desktop files; adding them to the system-wide set of packages automatically makes them available at the log-in screen.In addition, ~/.xsession files are honored. When available, ~/.xsession must be an executable that starts a window manager and/or other X clients.
- Data Type: gdm-configuration
auto-login?(default:#f)default-user(default:#f)When
auto-login?is false, GDM presents a log-in screen.When
auto-login?is true, GDM logs in directly asdefault-user.auto-suspend?(default#t)When true, GDM will automatically suspend to RAM when nobody is physically connected. When a machine is used via remote desktop or SSH, this should be set to false to avoid GDM interrupting remote sessions or rendering the machine unavailable.
debug?(default:#f)When true, GDM writes debug messages to its log.
gnome-shell-assets(default: ...)List of GNOME Shell assets needed by GDM: icon theme, fonts, etc.
xorg-configuration(default:(xorg-configuration))Configuration of the Xorg graphical server.
x-session(default:(xinitrc))Script to run before starting a X session.
xdmcp?(default:#f)When true, enable the X Display Manager Control Protocol (XDMCP). This should only be enabled in trusted environments, as the protocol is not secure. When enabled, GDM listens for XDMCP queries on the UDP port 177.
dbus-daemon(default:dbus-daemon-wrapper)File name of the
dbus-daemonexecutable.gdm(default:gdm)The GDM package to use.
wayland?(default:#f)When true, enables Wayland in GDM, necessary to use Wayland sessions.
wayland-session(default:gdm-wayland-session-wrapper)The Wayland session wrapper to use, needed to setup the environment.
- Scheme Variable: slim-service-type
This is the type for the SLiM graphical login manager for X11.
Like GDM, SLiM looks for session types described by .desktop files and allows users to choose a session from the log-in screen using F1. It also honors ~/.xsession files.
Unlike GDM, SLiM does not spawn the user session on a different VT after logging in, which means that you can only start one graphical session. If you want to be able to run multiple graphical sessions at the same time you have to add multiple SLiM services to your system services. The following example shows how to replace the default GDM service with two SLiM services on tty7 and tty8.
(use-modules (gnu services) (gnu services desktop) (gnu services xorg)) (operating-system ;; ... (services (cons* (service slim-service-type (slim-configuration (display ":0") (vt "vt7"))) (service slim-service-type (slim-configuration (display ":1") (vt "vt8"))) (modify-services %desktop-services (delete gdm-service-type)))))
- Data Type: slim-configuration
Data type representing the configuration of
slim-service-type.allow-empty-passwords?(default:#t)Whether to allow logins with empty passwords.
gnupg?(default:#f)If enabled,
pam-gnupgwill attempt to automatically unlock the user’s GPG keys with the login password viagpg-agent. The keygrips of all keys to be unlocked should be written to ~/.pam-gnupg, and can be queried withgpg -K --with-keygrip. Presetting passphrases must be enabled by addingallow-preset-passphrasein ~/.gnupg/gpg-agent.conf.auto-login?(default:#f)default-user(default:"")When
auto-login?is false, SLiM presents a log-in screen.When
auto-login?is true, SLiM logs in directly asdefault-user.theme(default:%default-slim-theme)theme-name(default:%default-slim-theme-name)The graphical theme to use and its name.
auto-login-session(default:#f)If true, this must be the name of the executable to start as the default session—e.g.,
(file-append windowmaker "/bin/windowmaker").If false, a session described by one of the available .desktop files in
/run/current-system/profileand~/.guix-profilewill be used.Примечание: You must install at least one window manager in the system profile or in your user profile. Failing to do that, if
auto-login-sessionis false, you will be unable to log in.xorg-configuration(default(xorg-configuration))Configuration of the Xorg graphical server.
speed(default:1.0)The display on which to start the Xorg graphical server.
port(default:22)The VT on which to start the Xorg graphical server.
xauth(default:xauth)The XAuth package to use.
shepherd(default:shepherd)The Shepherd package used when invoking
haltandreboot.sessreg(default:sessreg)The sessreg package used in order to register the session.
slim(default:slim)The SLiM package to use.
- Scheme Variable: %default-theme
- Scheme Variable: %default-theme-name
The default SLiM theme and its name.
- Scheme Variable: sddm-service-type
This is the type of the service to run the SDDM display manager. Its value must be a
sddm-configurationrecord (see below).Here’s an example use:
(service sddm-service-type (sddm-configuration (auto-login-user "alice") (auto-login-session "xfce.desktop")))
- Data Type: sddm-configuration
Этот тип данных представляет машины для сборки, на которые демон может разгружать сборки. Важные поля:
speed(default:1.0)Используемый пакет SDDM.
display-server(default: "x11")Select display server to use for the greeter. Valid values are ‘"x11"’ or ‘"wayland"’.
numlock(default: "on")Valid values are ‘"on"’, ‘"off"’ or ‘"none"’.
halt-command(default#~(string-append #$shepherd "/sbin/halt"))Command to run when halting.
reboot-command(default#~(string-append #$shepherd "/sbin/reboot"))Command to run when rebooting.
theme(default "maldives")Theme to use. Default themes provided by SDDM are ‘"elarun"’, ‘"maldives"’ or ‘"maya"’.
themes-directory(default "/run/current-system/profile/share/sddm/themes")Directory to look for themes.
faces-directory(default "/run/current-system/profile/share/sddm/faces")Directory to look for faces.
default-path(default "/run/current-system/profile/bin")Default PATH to use.
speed(default:1.0)Minimum UID displayed in SDDM and allowed for log-in.
parallel-builds(default:1)Maximum UID to display in SDDM.
remember-last-user?(default #t)Remember last user.
remember-last-session?(default #t)Remember last session.
hide-users(default "")Usernames to hide from SDDM greeter.
hide-shells(default#~(string-append #$shadow "/sbin/nologin"))Users with shells listed will be hidden from the SDDM greeter.
session-command(default#~(string-append #$sddm "/share/sddm/scripts/wayland-session"))Script to run before starting a wayland session.
sessions-directory(default "/run/current-system/profile/share/wayland-sessions")Directory to look for desktop files starting wayland sessions.
xorg-configuration(default(xorg-configuration))Configuration of the Xorg graphical server.
xauth-path(default#~(string-append #$xauth "/bin/xauth"))Path to xauth.
xephyr-path(default#~(string-append #$xorg-server "/bin/Xephyr"))Path to Xephyr.
xdisplay-start(default#~(string-append #$sddm "/share/sddm/scripts/Xsetup"))Script to run after starting xorg-server.
xdisplay-stop(default#~(string-append #$sddm "/share/sddm/scripts/Xstop"))Script to run before stopping xorg-server.
xsession-command(default:xinitrc)Script to run before starting a X session.
xsessions-directory(default: "/run/current-system/profile/share/xsessions")Directory to look for desktop files starting X sessions.
minimum-vt(default: 7)Minimum VT to use.
auto-login-user(default "")User account that will be automatically logged in. Setting this to the empty string disables auto-login.
auto-login-session(default "")The .desktop file name to use as the auto-login session, or the empty string.
relogin?(default #f)Relogin after logout.
- Scheme Variable: lightdm-service-type
This is the type of the service to run the LightDM display manager. Its value must be a
lightdm-configurationrecord, which is documented below. Among its distinguishing features are TigerVNC integration for easily remoting your desktop as well as support for the XDMCP protocol, which can be used by remote clients to start a session from the login manager.In its most basic form, it can be used simply as:
A more elaborate example making use of the VNC capabilities and enabling more features and verbose logs could look like:
(service lightdm-service-type (lightdm-configuration (allow-empty-passwords? #t) (xdmcp? #t) (vnc-server? #t) (vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -SecurityTypes None")) (seats (list (lightdm-seat-configuration (name "*") (user-session "ratpoison"))))))
- Data Type: lightdm-configuration
Available
lightdm-configurationfields are:lightdm(default:lightdm) (type: file-like)The lightdm package to use.
allow-empty-passwords?(default:#f) (type: boolean)Whether users not having a password set can login.
debug?(default:#f) (type: boolean)Enable verbose output.
xorg-configuration(type: xorg-configuration)The default Xorg server configuration to use to generate the Xorg server start script. It can be refined per seat via the
xserver-commandof the<lightdm-seat-configuration>record, if desired.greeters(type: list-of-greeter-configurations)The LightDM greeter configurations specifying the greeters to use.
seats(type: list-of-seat-configurations)The seat configurations to use. A LightDM seat is akin to a user.
xdmcp?(default:#f) (type: boolean)Whether a XDMCP server should listen on port UDP 177.
xdmcp-listen-address(type: maybe-string)The host or IP address the XDMCP server listens for incoming connections. When unspecified, listen on for any hosts/IP addresses.
vnc-server?(default:#f) (type: boolean)Whether a VNC server is started.
vnc-server-command(type: file-like)The Xvnc command to use for the VNC server, it’s possible to provide extra options not otherwise exposed along the command, for example to disable security:
(vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -SecurityTypes None" ))Or to set a PasswordFile for the classic (unsecure) VncAuth mecanism:
(vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -PasswordFile /var/lib/lightdm/.vnc/passwd"))The password file should be manually created using the
vncpasswdcommand. Note that LightDM will create new sessions for VNC users, which means they need to authenticate in the same way as local users would.vnc-server-listen-address(type: maybe-string)The host or IP address the VNC server listens for incoming connections. When unspecified, listen for any hosts/IP addresses.
vnc-server-port(default:5900) (type: number)The TCP port the VNC server should listen to.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the LightDM configuration file.
- Data Type: lightdm-gtk-greeter-configuration
Available
lightdm-gtk-greeter-configurationfields are:lightdm-gtk-greeter(default:lightdm-gtk-greeter) (type: file-like)The lightdm-gtk-greeter package to use.
assets(default:
(adwaita-icon-theme gnome-themes-extrahicolor-icon-theme)) (type: list-of-file-likes) The list of packages complementing the greeter, such as package providing icon themes.theme-name(default:"Adwaita") (type: string)The name of the theme to use.
icon-theme-name(default:"Adwaita") (type: string)The name of the icon theme to use.
cursor-theme-name(default:"Adwaita") (type: string)The name of the cursor theme to use.
cursor-theme-size(default:16) (type: number)The size to use for the cursor theme.
allow-debugging?(type: maybe-boolean)Set to #t to enable debug log level.
background(type: file-like)The background image to use.
at-spi-enabled?(default:#f) (type: boolean)Enable accessibility support through the Assistive Technology Service Provider Interface (AT-SPI).
a11y-states(default:
(contrast font keyboard reader)) (type: list-of-a11y-states) The accessibility features to enable, given as list of symbols.reader(type: maybe-file-like)The command to use to launch a screen reader.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the LightDM GTK Greeter configuration file.
- Data Type: lightdm-seat-configuration
Available
lightdm-seat-configurationfields are:name(type: seat-name)The name of the seat. An asterisk (*) can be used in the name to apply the seat configuration to all the seat names it matches.
user-session(type: maybe-string)The session to use by default. The session name must be provided as a lowercase string, such as
"gnome","ratpoison", etc.type(default:local) (type: seat-type)The type of the seat, either the
localorxremotesymbol.autologin-user(type: maybe-string)The username to automatically log in with by default.
greeter-session(default:
lightdm-gtk-greeter) (type: greeter-session) The greeter session to use, specified as a symbol. Currently, onlylightdm-gtk-greeteris supported.xserver-command(type: maybe-file-like)The Xorg server command to run.
session-wrapper(type: file-like)The xinitrc session wrapper to use.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the seat configuration section.
- Data Type: xorg-configuration
This data type represents the configuration of the Xorg graphical display server. Note that there is no Xorg service; instead, the X server is started by a “display manager” such as GDM, SDDM, LightDM or SLiM. Thus, the configuration of these display managers aggregates an
xorg-configurationrecord.modules(default:%default-xorg-modules)This is a list of module packages loaded by the Xorg server—e.g.,
xf86-video-vesa,xf86-input-keyboard, and so on.fonts(default:%default-xorg-fonts)This is a list of font directories to add to the server’s font path.
drivers(default:'())This must be either the empty list, in which case Xorg chooses a graphics driver automatically, or a list of driver names that will be tried in this order—e.g.,
("modesetting" "vesa").resolutions(default:'())When
resolutionsis the empty list, Xorg chooses an appropriate screen resolution. Otherwise, it must be a list of resolutions—e.g.,((1024 768) (640 480)).keyboard-layout(default:#f)If this is
#f, Xorg uses the default keyboard layout—usually US English (“qwerty”) for a 105-key PC keyboard.Otherwise this must be a
keyboard-layoutobject specifying the keyboard layout in use when Xorg is running. See Раскладка клавиатуры, for more information on how to specify the keyboard layout.extra-config(default:'())This is a list of strings or objects appended to the configuration file. It is used to pass extra text to be added verbatim to the configuration file.
server(default:xorg-server)This is the package providing the Xorg server.
server-arguments(default:%default-xorg-server-arguments)This is the list of command-line arguments to pass to the X server. The default is
-nolisten tcp.
- Scheme Procedure: set-xorg-configuration config [login-manager-service-type] Tell the log-in manager (of type
login-manager-service-type) to use config, an
<xorg-configuration>record.Since the Xorg configuration is embedded in the log-in manager’s configuration—e.g.,
gdm-configuration—this procedure provides a shorthand to set the Xorg configuration.
- Scheme Procedure: xorg-start-command [config]
Return a
startxscript in which the modules, fonts, etc. specified in config, are available. The result should be used in place ofstartx.Usually the X server is started by a login manager.
- Scheme Procedure: screen-locker-service package [program]
Add package, a package for a screen locker or screen saver whose command is program, to the set of setuid programs and add a PAM entry for it. For example:
(screen-locker-service xlockmore "xlock")makes the good ol’ XlockMore usable.
Next: Сервисы рабочего стола, Previous: Оконная система X, Up: Сервисы [Contents][Index]
12.9.8 Сервисы печати
The (gnu services cups) module provides a Guix service definition for
the CUPS printing service. To add printer support to a Guix system, add a
cups-service to the operating system definition:
- Scheme Variable: cups-service-type
The service type for the CUPS print server. Its value should be a valid CUPS configuration (see below). To use the default settings, simply write:
The CUPS configuration controls the basic things about your CUPS installation: what interfaces it listens on, what to do if a print job fails, how much logging to do, and so on. To actually add a printer, you have to visit the http://localhost:631 URL, or use a tool such as GNOME’s printer configuration services. By default, configuring a CUPS service will generate a self-signed certificate if needed, for secure connections to the print server.
Suppose you want to enable the Web interface of CUPS and also add support
for Epson printers via the epson-inkjet-printer-escpr package and
for HP printers via the hplip-minimal package. You can do that
directly, like this (you need to use the (gnu packages cups) module):
(service cups-service-type
(cups-configuration
(web-interface? #t)
(extensions
(list cups-filters epson-inkjet-printer-escpr hplip-minimal))))
Примечание: If you wish to use the Qt5 based GUI which comes with the hplip package then it is suggested that you install the
hplippackage, either in your OS configuration file or as your user.
The available configuration parameters follow. Each parameter definition is
preceded by its type; for example, ‘string-list foo’ indicates that the
foo parameter should be specified as a list of strings. There is
also a way to specify the configuration as a string, if you have an old
cupsd.conf file that you want to port over from some other system;
see the end for more details.
Available cups-configuration fields are:
cups-configurationparameter: package cups ¶The CUPS package.
cups-configurationparameter: package-list extensions (default:(list brlaser cups-filters epson-inkjet-printer-escpr foomatic-filters hplip-minimal splix)) ¶Drivers and other extensions to the CUPS package.
cups-configurationparameter: files-configuration files-configuration ¶Configuration of where to write logs, what directories to use for print spools, and related privileged configuration parameters.
Available
files-configurationfields are:files-configurationparameter: log-location access-log ¶Defines the access log filename. Specifying a blank filename disables access log generation. The value
stderrcauses log entries to be sent to the standard error file when the scheduler is running in the foreground, or to the system log daemon when run in the background. The valuesyslogcauses log entries to be sent to the system log daemon. The server name may be included in filenames using the string%s, as in/var/log/cups/%s-access_log.Defaults to ‘"/var/log/cups/access_log"’.
files-configurationparameter: file-name cache-dir ¶Where CUPS should cache data.
Defaults to ‘"/var/cache/cups"’.
files-configurationparameter: string config-file-perm ¶Specifies the permissions for all configuration files that the scheduler writes.
Note that the permissions for the printers.conf file are currently masked to only allow access from the scheduler user (typically root). This is done because printer device URIs sometimes contain sensitive authentication information that should not be generally known on the system. There is no way to disable this security feature.
Defaults to ‘"0640"’.
files-configurationparameter: log-location error-log ¶Defines the error log filename. Specifying a blank filename disables error log generation. The value
stderrcauses log entries to be sent to the standard error file when the scheduler is running in the foreground, or to the system log daemon when run in the background. The valuesyslogcauses log entries to be sent to the system log daemon. The server name may be included in filenames using the string%s, as in/var/log/cups/%s-error_log.Defaults to ‘"/var/log/cups/error_log"’.
files-configurationparameter: string fatal-errors ¶Specifies which errors are fatal, causing the scheduler to exit. The kind strings are:
noneNo errors are fatal.
allAll of the errors below are fatal.
browseBrowsing initialization errors are fatal, for example failed connections to the DNS-SD daemon.
configConfiguration file syntax errors are fatal.
listenListen or Port errors are fatal, except for IPv6 failures on the loopback or
anyaddresses.logLog file creation or write errors are fatal.
permissionsBad startup file permissions are fatal, for example shared TLS certificate and key files with world-read permissions.
Defaults to ‘"all -browse"’.
files-configurationparameter: boolean file-device? ¶Specifies whether the file pseudo-device can be used for new printer queues. The URI file:///dev/null is always allowed.
Defaults to ‘#f’.
files-configurationparameter: string group ¶Specifies the group name or ID that will be used when executing external programs.
Defaults to ‘"lp"’.
files-configurationparameter: string log-file-group ¶Specifies the group name or ID that will be used for log files.
Defaults to ‘"lpadmin"’.
files-configurationparameter: string log-file-perm ¶Specifies the permissions for all log files that the scheduler writes.
Defaults to ‘"0644"’.
files-configurationparameter: log-location page-log ¶Defines the page log filename. Specifying a blank filename disables page log generation. The value
stderrcauses log entries to be sent to the standard error file when the scheduler is running in the foreground, or to the system log daemon when run in the background. The valuesyslogcauses log entries to be sent to the system log daemon. The server name may be included in filenames using the string%s, as in/var/log/cups/%s-page_log.Defaults to ‘"/var/log/cups/page_log"’.
files-configurationparameter: string remote-root ¶Specifies the username that is associated with unauthenticated accesses by clients claiming to be the root user. The default is
remroot.Defaults to ‘"remroot"’.
files-configurationparameter: file-name request-root ¶Specifies the directory that contains print jobs and other HTTP request data.
Defaults to ‘"/var/spool/cups"’.
files-configurationparameter: sandboxing sandboxing ¶Specifies the level of security sandboxing that is applied to print filters, backends, and other child processes of the scheduler; either
relaxedorstrict. This directive is currently only used/supported on macOS.Defaults to ‘strict’.
files-configurationparameter: file-name server-keychain ¶Specifies the location of TLS certificates and private keys. CUPS will look for public and private keys in this directory: .crt files for PEM-encoded certificates and corresponding .key files for PEM-encoded private keys.
Defaults to ‘"/etc/cups/ssl"’.
files-configurationparameter: file-name server-root ¶Specifies the directory containing the server configuration files.
Defaults to ‘"/etc/cups"’.
files-configurationparameter: boolean sync-on-close? ¶Specifies whether the scheduler calls fsync(2) after writing configuration or state files.
Defaults to ‘#f’.
files-configurationparameter: space-separated-string-list system-group ¶Specifies the group(s) to use for
@SYSTEMgroup authentication.
files-configurationparameter: file-name temp-dir ¶Specifies the directory where temporary files are stored.
Defaults to ‘"/var/spool/cups/tmp"’.
files-configurationparameter: string user ¶Specifies the user name or ID that is used when running external programs.
Defaults to ‘"lp"’.
files-configurationparameter: string set-env ¶Set the specified environment variable to be passed to child processes.
Defaults to ‘"variable value"’.
cups-configurationparameter: access-log-level access-log-level ¶Specifies the logging level for the AccessLog file. The
configlevel logs when printers and classes are added, deleted, or modified and when configuration files are accessed or updated. Theactionslevel logs when print jobs are submitted, held, released, modified, or canceled, and any of the conditions forconfig. Thealllevel logs all requests.Defaults to ‘actions’.
cups-configurationparameter: boolean auto-purge-jobs? ¶Specifies whether to purge job history data automatically when it is no longer required for quotas.
Defaults to ‘#f’.
cups-configurationparameter: comma-separated-string-list browse-dns-sd-sub-types ¶Specifies a list of DNS-SD sub-types to advertise for each shared printer. For example, ‘"_cups" "_print"’ will tell network clients that both CUPS sharing and IPP Everywhere are supported.
Defaults to ‘"_cups"’.
cups-configurationparameter: browse-local-protocols browse-local-protocols ¶Specifies which protocols to use for local printer sharing.
Defaults to ‘dnssd’.
cups-configurationparameter: boolean browse-web-if? ¶Specifies whether the CUPS web interface is advertised.
Defaults to ‘#f’.
cups-configurationparameter: boolean browsing? ¶Specifies whether shared printers are advertised.
Defaults to ‘#f’.
cups-configurationparameter: string classification ¶Specifies the security classification of the server. Any valid banner name can be used, including ‘"classified"’, ‘"confidential"’, ‘"secret"’, ‘"topsecret"’, and ‘"unclassified"’, or the banner can be omitted to disable secure printing functions.
Defaults to ‘""’.
cups-configurationparameter: boolean classify-override? ¶Specifies whether users may override the classification (cover page) of individual print jobs using the
job-sheetsoption.Defaults to ‘#f’.
cups-configurationparameter: default-auth-type default-auth-type ¶Specifies the default type of authentication to use.
Defaults to ‘Basic’.
cups-configurationparameter: default-encryption default-encryption ¶Specifies whether encryption will be used for authenticated requests.
Defaults to ‘Required’.
cups-configurationparameter: string default-language ¶Specifies the default language to use for text and web content.
Defaults to ‘"en"’.
cups-configurationparameter: string default-paper-size ¶Specifies the default paper size for new print queues. ‘"Auto"’ uses a locale-specific default, while ‘"None"’ specifies there is no default paper size. Specific size names are typically ‘"Letter"’ or ‘"A4"’.
Defaults to ‘"Auto"’.
cups-configurationparameter: string default-policy ¶Specifies the default access policy to use.
Defaults to ‘"default"’.
Specifies whether local printers are shared by default.
Defaults to ‘#t’.
cups-configurationparameter: non-negative-integer dirty-clean-interval ¶Specifies the delay for updating of configuration and state files, in seconds. A value of 0 causes the update to happen as soon as possible, typically within a few milliseconds.
Defaults to ‘30’.
cups-configurationparameter: error-policy error-policy ¶Specifies what to do when an error occurs. Possible values are
abort-job, which will discard the failed print job;retry-job, which will retry the job at a later time;retry-current-job, which retries the failed job immediately; andstop-printer, which stops the printer.Defaults to ‘stop-printer’.
cups-configurationparameter: non-negative-integer filter-limit ¶Specifies the maximum cost of filters that are run concurrently, which can be used to minimize disk, memory, and CPU resource problems. A limit of 0 disables filter limiting. An average print to a non-PostScript printer needs a filter limit of about 200. A PostScript printer needs about half that (100). Setting the limit below these thresholds will effectively limit the scheduler to printing a single job at any time.
Defaults to ‘0’.
cups-configurationparameter: non-negative-integer filter-nice ¶Specifies the scheduling priority of filters that are run to print a job. The nice value ranges from 0, the highest priority, to 19, the lowest priority.
Defaults to ‘0’.
cups-configurationparameter: host-name-lookups host-name-lookups ¶Specifies whether to do reverse lookups on connecting clients. The
doublesetting causescupsdto verify that the hostname resolved from the address matches one of the addresses returned for that hostname. Double lookups also prevent clients with unregistered addresses from connecting to your server. Only set this option to#tordoubleif absolutely required.Defaults to ‘#f’.
cups-configurationparameter: non-negative-integer job-kill-delay ¶Specifies the number of seconds to wait before killing the filters and backend associated with a canceled or held job.
Defaults to ‘30’.
cups-configurationparameter: non-negative-integer job-retry-interval ¶Specifies the interval between retries of jobs in seconds. This is typically used for fax queues but can also be used with normal print queues whose error policy is
retry-joborretry-current-job.Defaults to ‘30’.
cups-configurationparameter: non-negative-integer job-retry-limit ¶Specifies the number of retries that are done for jobs. This is typically used for fax queues but can also be used with normal print queues whose error policy is
retry-joborretry-current-job.Defaults to ‘5’.
cups-configurationparameter: boolean keep-alive? ¶Specifies whether to support HTTP keep-alive connections.
Defaults to ‘#t’.
cups-configurationparameter: non-negative-integer limit-request-body ¶Specifies the maximum size of print files, IPP requests, and HTML form data. A limit of 0 disables the limit check.
Defaults to ‘0’.
cups-configurationparameter: multiline-string-list listen ¶Listens on the specified interfaces for connections. Valid values are of the form address:port, where address is either an IPv6 address enclosed in brackets, an IPv4 address, or
*to indicate all addresses. Values can also be file names of local UNIX domain sockets. The Listen directive is similar to the Port directive but allows you to restrict access to specific interfaces or networks.
cups-configurationparameter: non-negative-integer listen-back-log ¶Specifies the number of pending connections that will be allowed. This normally only affects very busy servers that have reached the MaxClients limit, but can also be triggered by large numbers of simultaneous connections. When the limit is reached, the operating system will refuse additional connections until the scheduler can accept the pending ones.
Defaults to ‘128’.
cups-configurationparameter: location-access-control-list location-access-controls ¶Specifies a set of additional access controls.
Available
location-access-controlsfields are:location-access-controlsparameter: file-name path ¶Specifies the URI path to which the access control applies.
location-access-controlsparameter: access-control-list access-controls ¶Access controls for all access to this path, in the same format as the
access-controlsofoperation-access-control.Defaults to ‘()’.
location-access-controlsparameter: method-access-control-list method-access-controls ¶Access controls for method-specific access to this path.
Defaults to ‘()’.
Available
method-access-controlsfields are:method-access-controlsparameter: boolean reverse? ¶If
#t, apply access controls to all methods except the listed methods. Otherwise apply to only the listed methods.Defaults to ‘#f’.
method-access-controlsparameter: method-list methods ¶Methods to which this access control applies.
Defaults to ‘()’.
method-access-controlsparameter: access-control-list access-controls ¶Access control directives, as a list of strings. Each string should be one directive, such as ‘"Order allow,deny"’.
Defaults to ‘()’.
cups-configurationparameter: non-negative-integer log-debug-history ¶Specifies the number of debugging messages that are retained for logging if an error occurs in a print job. Debug messages are logged regardless of the LogLevel setting.
Defaults to ‘100’.
cups-configurationparameter: log-level log-level ¶Specifies the level of logging for the ErrorLog file. The value
nonestops all logging whiledebug2logs everything.Defaults to ‘info’.
cups-configurationparameter: log-time-format log-time-format ¶Specifies the format of the date and time in the log files. The value
standardlogs whole seconds whileusecslogs microseconds.Defaults to ‘standard’.
cups-configurationparameter: non-negative-integer max-clients ¶Specifies the maximum number of simultaneous clients that are allowed by the scheduler.
Defaults to ‘100’.
cups-configurationparameter: non-negative-integer max-clients-per-host ¶Specifies the maximum number of simultaneous clients that are allowed from a single address.
Defaults to ‘100’.
cups-configurationparameter: non-negative-integer max-copies ¶Specifies the maximum number of copies that a user can print of each job.
Defaults to ‘9999’.
cups-configurationparameter: non-negative-integer max-hold-time ¶Specifies the maximum time a job may remain in the
indefinitehold state before it is canceled. A value of 0 disables cancellation of held jobs.Defaults to ‘0’.
cups-configurationparameter: non-negative-integer max-jobs ¶Specifies the maximum number of simultaneous jobs that are allowed. Set to 0 to allow an unlimited number of jobs.
Defaults to ‘500’.
cups-configurationparameter: non-negative-integer max-jobs-per-printer ¶Specifies the maximum number of simultaneous jobs that are allowed per printer. A value of 0 allows up to MaxJobs jobs per printer.
Defaults to ‘0’.
cups-configurationparameter: non-negative-integer max-jobs-per-user ¶Specifies the maximum number of simultaneous jobs that are allowed per user. A value of 0 allows up to MaxJobs jobs per user.
Defaults to ‘0’.
cups-configurationparameter: non-negative-integer max-job-time ¶Specifies the maximum time a job may take to print before it is canceled, in seconds. Set to 0 to disable cancellation of “stuck” jobs.
Defaults to ‘10800’.
cups-configurationparameter: non-negative-integer max-log-size ¶Specifies the maximum size of the log files before they are rotated, in bytes. The value 0 disables log rotation.
Defaults to ‘1048576’.
cups-configurationparameter: non-negative-integer multiple-operation-timeout ¶Specifies the maximum amount of time to allow between files in a multiple file print job, in seconds.
Defaults to ‘900’.
cups-configurationparameter: string page-log-format ¶Specifies the format of PageLog lines. Sequences beginning with percent (‘%’) characters are replaced with the corresponding information, while all other characters are copied literally. The following percent sequences are recognized:
- ‘%%’
insert a single percent character
- ‘%{name}’
insert the value of the specified IPP attribute
- ‘%C’
insert the number of copies for the current page
- ‘%P’
insert the current page number
- ‘%T’
insert the current date and time in common log format
- ‘%j’
insert the job ID
- ‘%p’
insert the printer name
- ‘%u’
insert the username
A value of the empty string disables page logging. The string
%p %u %j %T %P %C %{job-billing} %{job-originating-host-name} %{job-name} %{media} %{sides}creates a page log with the standard items.Defaults to ‘""’.
cups-configurationparameter: environment-variables environment-variables ¶Passes the specified environment variable(s) to child processes; a list of strings.
Defaults to ‘()’.
cups-configurationparameter: policy-configuration-list policies ¶Specifies named access control policies.
Available
policy-configurationfields are:policy-configurationparameter: string name ¶Name of the policy.
policy-configurationparameter: string job-private-access ¶Specifies an access list for a job’s private values.
@ACLmaps to the printer’s requesting-user-name-allowed or requesting-user-name-denied values.@OWNERmaps to the job’s owner.@SYSTEMmaps to the groups listed for thesystem-groupfield of thefiles-configuration, which is reified into thecups-files.conf(5)file. Other possible elements of the access list include specific user names, and@groupto indicate members of a specific group. The access list may also be simplyallordefault.Defaults to ‘"@OWNER @SYSTEM"’.
policy-configurationparameter: string job-private-values ¶Specifies the list of job values to make private, or
all,default, ornone.Defaults to ‘"job-name job-originating-host-name job-originating-user-name phone"’.
policy-configurationparameter: string subscription-private-access ¶Specifies an access list for a subscription’s private values.
@ACLmaps to the printer’s requesting-user-name-allowed or requesting-user-name-denied values.@OWNERmaps to the job’s owner.@SYSTEMmaps to the groups listed for thesystem-groupfield of thefiles-configuration, which is reified into thecups-files.conf(5)file. Other possible elements of the access list include specific user names, and@groupto indicate members of a specific group. The access list may also be simplyallordefault.Defaults to ‘"@OWNER @SYSTEM"’.
policy-configurationparameter: string subscription-private-values ¶Specifies the list of job values to make private, or
all,default, ornone.Defaults to ‘"notify-events notify-pull-method notify-recipient-uri notify-subscriber-user-name notify-user-data"’.
policy-configurationparameter: operation-access-control-list access-controls ¶Access control by IPP operation.
Defaults to ‘()’.
cups-configurationparameter: boolean-or-non-negative-integer preserve-job-files ¶Specifies whether job files (documents) are preserved after a job is printed. If a numeric value is specified, job files are preserved for the indicated number of seconds after printing. Otherwise a boolean value applies indefinitely.
Defaults to ‘86400’.
cups-configurationparameter: boolean-or-non-negative-integer preserve-job-history ¶Specifies whether the job history is preserved after a job is printed. If a numeric value is specified, the job history is preserved for the indicated number of seconds after printing. If
#t, the job history is preserved until the MaxJobs limit is reached.Defaults to ‘#t’.
cups-configurationparameter: non-negative-integer reload-timeout ¶Specifies the amount of time to wait for job completion before restarting the scheduler.
Defaults to ‘30’.
cups-configurationparameter: string rip-cache ¶Specifies the maximum amount of memory to use when converting documents into bitmaps for a printer.
Defaults to ‘"128m"’.
cups-configurationparameter: string server-admin ¶Specifies the email address of the server administrator.
Defaults to ‘"root@localhost.localdomain"’.
cups-configurationparameter: host-name-list-or-* server-alias ¶The ServerAlias directive is used for HTTP Host header validation when clients connect to the scheduler from external interfaces. Using the special name
*can expose your system to known browser-based DNS rebinding attacks, even when accessing sites through a firewall. If the auto-discovery of alternate names does not work, we recommend listing each alternate name with a ServerAlias directive instead of using*.Defaults to ‘*’.
cups-configurationparameter: string server-name ¶Specifies the fully-qualified host name of the server.
Defaults to ‘"localhost"’.
cups-configurationparameter: server-tokens server-tokens ¶Specifies what information is included in the Server header of HTTP responses.
Nonedisables the Server header.ProductOnlyreportsCUPS.MajorreportsCUPS 2.MinorreportsCUPS 2.0.MinimalreportsCUPS 2.0.0.OSreportsCUPS 2.0.0 (uname)where uname is the output of theunamecommand.FullreportsCUPS 2.0.0 (uname) IPP/2.0.Defaults to ‘Minimal’.
cups-configurationparameter: multiline-string-list ssl-listen ¶Listens on the specified interfaces for encrypted connections. Valid values are of the form address:port, where address is either an IPv6 address enclosed in brackets, an IPv4 address, or
*to indicate all addresses.Defaults to ‘()’.
cups-configurationparameter: ssl-options ssl-options ¶Sets encryption options. By default, CUPS only supports encryption using TLS v1.0 or higher using known secure cipher suites. Security is reduced when
Allowoptions are used, and enhanced whenDenyoptions are used. TheAllowRC4option enables the 128-bit RC4 cipher suites, which are required for some older clients. TheAllowSSL3option enables SSL v3.0, which is required for some older clients that do not support TLS v1.0. TheDenyCBCoption disables all CBC cipher suites. TheDenyTLS1.0option disables TLS v1.0 support - this sets the minimum protocol version to TLS v1.1.Defaults to ‘()’.
cups-configurationparameter: boolean strict-conformance? ¶Specifies whether the scheduler requires clients to strictly adhere to the IPP specifications.
Defaults to ‘#f’.
cups-configurationparameter: non-negative-integer timeout ¶Specifies the HTTP request timeout, in seconds.
Defaults to ‘900’.
cups-configurationparameter: boolean web-interface? ¶Specifies whether the web interface is enabled.
Defaults to ‘#f’.
At this point you’re probably thinking “oh dear, Guix manual, I like you
but you can stop already with the configuration options”. Indeed.
However, one more point: it could be that you have an existing
cupsd.conf that you want to use. In that case, you can pass an
opaque-cups-configuration as the configuration of a
cups-service-type.
Available opaque-cups-configuration fields are:
opaque-cups-configurationparameter: package cups ¶The CUPS package.
opaque-cups-configurationparameter: string cupsd.conf ¶The contents of the
cupsd.conf, as a string.
opaque-cups-configurationparameter: string cups-files.conf ¶The contents of the
cups-files.conffile, as a string.
For example, if your cupsd.conf and cups-files.conf are in
strings of the same name, you could instantiate a CUPS service like this:
(service cups-service-type
(opaque-cups-configuration
(cupsd.conf cupsd.conf)
(cups-files.conf cups-files.conf)))
Next: Звуковые сервисы, Previous: Сервисы печати, Up: Сервисы [Contents][Index]
12.9.9 Сервисы рабочего стола
The (gnu services desktop) module provides services that are usually
useful in the context of a “desktop” setup—that is, on a machine running
a graphical display server, possibly with graphical user interfaces, etc.
It also defines services that provide specific desktop environments like
GNOME, Xfce or MATE.
To simplify things, the module defines a variable containing the set of services that users typically expect on a machine with a graphical environment and networking:
- Scheme Variable: %desktop-services
This is a list of services that builds upon
%base-servicesand adds or adjusts services for a typical “desktop” setup.In particular, it adds a graphical login manager (see
gdm-service-type), screen lockers, a network management tool (seenetwork-manager-service-type) with modem support (seemodem-manager-service-type), energy and color management services, theelogindlogin and seat manager, the Polkit privilege service, the GeoClue location service, the AccountsService daemon that allows authorized users change system passwords, an NTP client (see Сервисы сети), the Avahi daemon, and has the name service switch service configured to be able to usenss-mdns(see mDNS).
The %desktop-services variable can be used as the services
field of an operating-system declaration (see services).
Additionally, the gnome-desktop-service-type,
xfce-desktop-service, mate-desktop-service-type,
lxqt-desktop-service-type and
enlightenment-desktop-service-type procedures can add GNOME, Xfce,
MATE and/or Enlightenment to a system. To “add GNOME” means that
system-level services like the backlight adjustment helpers and the power
management utilities are added to the system, extending polkit and
dbus appropriately, allowing GNOME to operate with elevated
privileges on a limited number of special-purpose system interfaces.
Additionally, adding a service made by gnome-desktop-service-type
adds the GNOME metapackage to the system profile. Likewise, adding the Xfce
service not only adds the xfce metapackage to the system profile, but
it also gives the Thunar file manager the ability to open a “root-mode”
file management window, if the user authenticates using the administrator’s
password via the standard polkit graphical interface. To “add MATE” means
that polkit and dbus are extended appropriately, allowing MATE
to operate with elevated privileges on a limited number of special-purpose
system interfaces. Additionally, adding a service of type
mate-desktop-service-type adds the MATE metapackage to the system
profile. “Adding Enlightenment” means that dbus is extended
appropriately, and several of Enlightenment’s binaries are set as setuid,
allowing Enlightenment’s screen locker and other functionality to work as
expected.
The desktop environments in Guix use the Xorg display server by default. If
you’d like to use the newer display server protocol called Wayland, you need
to enable Wayland support in GDM (see wayland-gdm). Another solution is
to use the sddm-service instead of GDM as the graphical login
manager. You should then select the “GNOME (Wayland)” session in SDDM.
Alternatively you can also try starting GNOME on Wayland manually from a TTY
with the command “XDG_SESSION_TYPE=wayland exec dbus-run-session
gnome-session“. Currently only GNOME has support for Wayland.
- Scheme Variable: gnome-desktop-service-type
This is the type of the service that adds the GNOME desktop environment. Its value is a
gnome-desktop-configurationobject (see below).This service adds the
gnomepackage to the system profile, and extends polkit with the actions fromgnome-settings-daemon.
- Data Type: gnome-desktop-configuration
Configuration record for the GNOME desktop environment.
port(default:22)The GNOME package to use.
- Scheme Variable: xfce-desktop-service-type
This is the type of a service to run the https://xfce.org/ desktop environment. Its value is an
xfce-desktop-configurationobject (see below).This service adds the
xfcepackage to the system profile, and extends polkit with the ability forthunarto manipulate the file system as root from within a user session, after the user has authenticated with the administrator’s password.Note that
xfce4-paneland its plugin packages should be installed in the same profile to ensure compatibility. When using this service, you should add extra plugins (xfce4-whiskermenu-plugin,xfce4-weather-plugin, etc.) to thepackagesfield of youroperating-system.
- Data Type: xfce-desktop-configuration
Configuration record for the Xfce desktop environment.
speed(default:1.0)The Xfce package to use.
- Scheme Variable: mate-desktop-service-type
This is the type of the service that runs the MATE desktop environment. Its value is a
mate-desktop-configurationobject (see below).This service adds the
matepackage to the system profile, and extends polkit with the actions frommate-settings-daemon.
- Data Type: mate-desktop-configuration
Configuration record for the MATE desktop environment.
port(default:22)The MATE package to use.
- Scheme Variable: etc-service-type
This is the type of the service that runs the LXQt desktop environment. Its value is a
lxqt-desktop-configurationobject (see below).This service adds the
lxqtpackage to the system profile.
- Конфигурирование: системы
Конфигурации для среды рабочего стола LXQt.
port(default:22)Используемый пакет LXQT.
- Scheme Variable: enlightenment-desktop-service-type
Return a service that adds the
enlightenmentpackage to the system profile, and extends dbus with actions fromefl.
- Data Type: enlightenment-desktop-service-configuration
features(default:'())The enlightenment package to use.
Because the GNOME, Xfce and MATE desktop services pull in so many packages,
the default %desktop-services variable doesn’t include any of them by
default. To add GNOME, Xfce or MATE, just cons them onto
%desktop-services in the services field of your
operating-system:
(use-modules (gnu)) (use-service-modules desktop) (operating-system ... ;; cons* adds items to the list given as its last argument. (services (cons* (service gnome-desktop-service-type) (service xfce-desktop-service) %desktop-services)) ...)
These desktop environments will then be available as options in the graphical login window.
The actual service definitions included in %desktop-services and
provided by (gnu services dbus) and (gnu services desktop) are
described below.
- Scheme Procedure: dbus-service [#:dbus dbus] [#:services '()] [#:verbose?] Return a service that runs the ``system bus'', using
dbus, with support for services. When verbose? is true, it causes the ‘DBUS_VERBOSE’ environment variable to be set to ‘1’; a verbose-enabled D-Bus package such as
dbus-verboseshould be provided as dbus in this scenario. The verbose output is logged to /var/log/dbus-daemon.log.D-Bus is an inter-process communication facility. Its system bus is used to allow system services to communicate and to be notified of system-wide events.
services must be a list of packages that provide an etc/dbus-1/system.d directory containing additional D-Bus configuration and policy files. For example, to allow avahi-daemon to use the system bus, services must be equal to
(list avahi).
- Scheme Procedure: elogind-service [#:config config]
Return a service that runs the
elogindlogin and seat management daemon. Elogind exposes a D-Bus interface that can be used to know which users are logged in, know what kind of sessions they have open, suspend the system, inhibit system suspend, reboot the system, and other tasks.Elogind handles most system-level power events for a computer, for example suspending the system when a lid is closed, or shutting it down when the power button is pressed.
The config keyword argument specifies the configuration for elogind, and should be the result of an
(elogind-configuration (parameter value)...)invocation. Available parameters and their default values are:kill-user-processes?#fkill-only-users()kill-exclude-users("root")inhibit-delay-max-seconds5handle-power-keypoweroffhandle-suspend-keysuspendhandle-hibernate-keyhibernatehandle-lid-switchsuspendhandle-lid-switch-dockedignorehandle-lid-switch-external-power*unspecified*power-key-ignore-inhibited?#fsuspend-key-ignore-inhibited?#fhibernate-key-ignore-inhibited?#flid-switch-ignore-inhibited?#tholdoff-timeout-seconds30idle-actionignoreidle-action-seconds(* 30 60)runtime-directory-size-percent10runtime-directory-size#fremove-ipc?#tsuspend-state("mem" "standby" "freeze")suspend-mode()hibernate-state("disk")hibernate-mode("platform" "shutdown")hybrid-sleep-state("disk")hybrid-sleep-mode("suspend" "platform" "shutdown")
- Scheme Procedure: accountsservice-service [#:accountsservice accountsservice] Return a service that runs
AccountsService, a system service that can list available accounts, change their passwords, and so on. AccountsService integrates with PolicyKit to enable unprivileged users to acquire the capability to modify their system configuration. the accountsservice web site for more information.
The accountsservice keyword argument is the
accountsservicepackage to expose as a service.
- Scheme Procedure: polkit-service [#:polkit polkit] Return a service that runs the
Polkit privilege management service, which allows system administrators to grant access to privileged operations in a structured way. By querying the Polkit service, a privileged system component can know when it should grant additional capabilities to ordinary users. For example, an ordinary user can be granted the capability to suspend the system if the user is logged in locally.
- Scheme Variable: polkit-wheel-service
Service that adds the
wheelgroup as admins to the Polkit service. This makes it so that users in thewheelgroup are queried for their own passwords when performing administrative actions instead ofroot’s, similar to the behaviour used bysudo.
- Scheme Variable: upower-service-type
Service that runs
upowerd, a system-wide monitor for power consumption and battery levels, with the given configuration settings.It implements the
org.freedesktop.UPowerD-Bus interface, and is notably used by GNOME.
- Data Type: upower-configuration
Data type representation the configuration for UPower.
upower(default: upower)Package to use for
upower.watts-up-pro?(default:#f)Enable the Watts Up Pro device.
poll-batteries?(default:#t)Enable polling the kernel for battery level changes.
ignore-lid?(default:#f)Ignore the lid state, this can be useful if it’s incorrect on a device.
use-percentage-for-policy?(default:#t)Whether to use a policy based on battery percentage rather than on estimated time left. A policy based on battery percentage is usually more reliable.
percentage-low(default:20)When
use-percentage-for-policy?is#t, this sets the percentage at which the battery is considered low.percentage-critical(default:5)When
use-percentage-for-policy?is#t, this sets the percentage at which the battery is considered critical.percentage-action(default:2)When
use-percentage-for-policy?is#t, this sets the percentage at which action will be taken.time-low(default:1200)When
use-time-for-policy?is#f, this sets the time remaining in seconds at which the battery is considered low.time-critical(default:300)When
use-time-for-policy?is#f, this sets the time remaining in seconds at which the battery is considered critical.time-action(default:120)When
use-time-for-policy?is#f, this sets the time remaining in seconds at which action will be taken.critical-power-action(default:'hybrid-sleep)The action taken when
percentage-actionortime-actionis reached (depending on the configuration ofuse-percentage-for-policy?).Possible values are:
-
'power-off -
'hibernate -
'hybrid-sleep.
-
- Scheme Procedure: udisks-service [#:udisks udisks]
Return a service for UDisks, a disk management daemon that provides user interfaces with notifications and ways to mount/unmount disks. Programs that talk to UDisks include the
udisksctlcommand, part of UDisks, and GNOME Disks. Note that Udisks relies on themountcommand, so it will only be able to use the file-system utilities installed in the system profile. For example if you want to be able to mount NTFS file-systems in read and write fashion, you’ll need to haventfs-3ginstalled system-wide.
- Scheme Variable: colord-service-type
This is the type of the service that runs
colord, a system service with a D-Bus interface to manage the color profiles of input and output devices such as screens and scanners. It is notably used by the GNOME Color Manager graphical tool. See the colord web site for more information.
- Процедура Scheme: sane-service-type
This service provides access to scanners via SANE by installing the necessary udev rules. It is included in
%desktop-services(see Сервисы рабочего стола) and relies by default onsane-backends-minimalpackage (see below) for hardware support.
- Scheme Variable: ant-build-system
The default package which the
sane-service-typeinstalls. It supports many recent scanners.
- Scheme Variable: ant-build-system
This package includes support for all scanners that
sane-backends-minimalsupports, plus older Hewlett-Packard scanners supported byhplippackage. In order to use this on a system which relies on%desktop-services, you may usemodify-services(seemodify-services) as illustrated below:(use-modules (gnu)) (use-service-modules … desktop) (use-package-modules … scanner) (define %my-desktop-services ;; List of desktop services that supports a broader range of scanners. (modify-services %desktop-services (sane-service-type _ => sane-backends))) (operating-system … (services %my-desktop-services))
- Scheme Procedure: geoclue-application name [#:allowed? #t] [#:system? #f] [#:users '()]
Return a configuration allowing an application to access GeoClue location data. name is the Desktop ID of the application, without the
.desktoppart. If allowed? is true, the application will have access to location information by default. The boolean system? value indicates whether an application is a system component or not. Finally users is a list of UIDs of all users for which this application is allowed location info access. An empty users list means that all users are allowed.
- Scheme Variable: %standard-geoclue-applications
The standard list of well-known GeoClue application configurations, granting authority to the GNOME date-and-time utility to ask for the current location in order to set the time zone, and allowing the IceCat and Epiphany web browsers to request location information. IceCat and Epiphany both query the user before allowing a web page to know the user’s location.
- Scheme Procedure: geoclue-service [#:colord colord] [#:whitelist '()] [#:wifi-geolocation-url
"https://location.services.mozilla.com/v1/geolocate?key=geoclue"] [#:submit-data? #f] [#:wifi-submission-url "https://location.services.mozilla.com/v1/submit?key=geoclue"] [#:submission-nick "geoclue"] [#:applications %standard-geoclue-applications] Return a service that runs the GeoClue location service. This service provides a D-Bus interface to allow applications to request access to a user’s physical location, and optionally to add information to online location databases. See the GeoClue web site for more information.
- Scheme Procedure: bluetooth-service [#:bluez bluez] [#:auto-enable? #f] Return a service that runs the
bluetoothd daemon, which manages all the Bluetooth devices and provides a number of D-Bus interfaces. When AUTO-ENABLE? is true, the bluetooth controller is powered automatically at boot, which can be useful when using a bluetooth keyboard or mouse.
Users need to be in the
lpgroup to access the D-Bus service.
- Scheme Variable: bluetooth-service-type
This is the type for the Linux Bluetooth Protocol Stack (BlueZ) system, which generates the /etc/bluetooth/main.conf configuration file. The value for this type is a
bluetooth-configurationrecord as in this example:See below for details about
bluetooth-configuration.
- Data Type: bluetooth-configuration
Data type representing the configuration for
bluetooth-service.bluez(default:bluez)bluezpackage to use.name(default:"BlueZ")Default adapter name.
class(default:#x000000)Default device class. Only the major and minor device class bits are considered.
discoverable-timeout(default:180)How long to stay in discoverable mode before going back to non-discoverable. The value is in seconds.
always-pairable?(default:#f)Always allow pairing even if there are no agents registered.
pairable-timeout(default:0)How long to stay in pairable mode before going back to non-discoverable. The value is in seconds.
device-id(default:#f)Use vendor id source (assigner), vendor, product and version information for DID profile support. The values are separated by ":" and assigner, VID, PID and version.
Possible values are:
-
#fto disable it, -
"assigner:1234:5678:abcd", where assigner is eitherusb(default) orbluetooth.
-
reverse-service-discovery?(default:#t)Do reverse service discovery for previously unknown devices that connect to us. For BR/EDR this option is really only needed for qualification since the BITE tester doesn’t like us doing reverse SDP for some test cases, for LE this disables the GATT client functionally so it can be used in system which can only operate as peripheral.
name-resolving?(default:#t)Enable name resolving after inquiry. Set it to
#fif you don’t need remote devices name and want shorter discovery cycle.debug-keys?(default:#f)Enable runtime persistency of debug link keys. Default is false which makes debug link keys valid only for the duration of the connection that they were created for.
controller-mode(default:'dual)Restricts all controllers to the specified transport.
'dualmeans both BR/EDR and LE are enabled (if supported by the hardware).Possible values are:
-
'dual -
'bredr -
'le
-
multi-profile(default:'off)Enables Multi Profile Specification support. This allows to specify if system supports only Multiple Profiles Single Device (MPSD) configuration or both Multiple Profiles Single Device (MPSD) and Multiple Profiles Multiple Devices (MPMD) configurations.
Possible values are:
-
'off -
'single -
'multiple
-
fast-connectable?(default:#f)Permanently enables the Fast Connectable setting for adapters that support it. When enabled other devices can connect faster to us, however the tradeoff is increased power consumptions. This feature will fully work only on kernel version 4.1 and newer.
privacy(default:'off)Default privacy settings.
-
'off: Disable local privacy -
'network/on: A device will only accept advertising packets from peer devices that contain private addresses. It may not be compatible with some legacy devices since it requires the use of RPA(s) all the time -
'device: A device in device privacy mode is only concerned about the privacy of the device and will accept advertising packets from peer devices that contain their Identity Address as well as ones that contain a private address, even if the peer device has distributed its IRK in the past
and additionally, if controller-mode is set to
'dual:-
'limited-network: Apply Limited Discoverable Mode to advertising, which follows the same policy as to BR/EDR that publishes the identity address when discoverable, and Network Privacy Mode for scanning -
'limited-device: Apply Limited Discoverable Mode to advertising, which follows the same policy as to BR/EDR that publishes the identity address when discoverable, and Device Privacy Mode for scanning.
-
just-works-repairing(default:'never)Specify the policy to the JUST-WORKS repairing initiated by peer.
Possible values:
-
'never -
'confirm -
'always
-
temporary-timeout(default:30)How long to keep temporary devices around. The value is in seconds.
0disables the timer completely.refresh-discovery?(default:#t)Enables the device to issue an SDP request to update known services when profile is connected.
experimental(default:#f)Enables experimental features and interfaces, alternatively a list of UUIDs can be given.
Possible values:
-
#t -
#f -
(list (uuid <uuid-1>) (uuid <uuid-2>) ...).
List of possible UUIDs:
-
d4992530-b9ec-469f-ab01-6c481c47da1c: BlueZ Experimental Debug, -
671b10b5-42c0-4696-9227-eb28d1b049d6: BlueZ Experimental Simultaneous Central and Peripheral, -
"15c0a148-c273-11ea-b3de-0242ac130004: BlueZ Experimental LL privacy, -
330859bc-7506-492d-9370-9a6f0614037f: BlueZ Experimental Bluetooth Quality Report, -
a6695ace-ee7f-4fb9-881a-5fac66c629af: BlueZ Experimental Offload Codecs.
-
remote-name-request-retry-delay(default:300)The duration to avoid retrying to resolve a peer’s name, if the previous try failed.
page-scan-type(default:#f)BR/EDR Page scan activity type.
page-scan-interval(default:#f)BR/EDR Page scan activity interval.
page-scan-window(default:#f)BR/EDR Page scan activity window.
inquiry-scan-type(default:#f)BR/EDR Inquiry scan activity type.
inquiry-scan-interval(default:#f)BR/EDR Inquiry scan activity interval.
inquiry-scan-window(default:#f)BR/EDR Inquiry scan activity window.
link-supervision-timeout(default:#f)BR/EDR Link supervision timeout.
page-timeout(default:#f)BR/EDR Page timeout.
min-sniff-interval(default:#f)BR/EDR minimum sniff interval.
max-sniff-interval(default:#f)BR/EDR maximum sniff interval.
min-advertisement-interval(default:#f)LE minimum advertisement interval (used for legacy advertisement only).
max-advertisement-interval(default:#f)LE maximum advertisement interval (used for legacy advertisement only).
multi-advertisement-rotation-interval(default:#f)LE multiple advertisement rotation interval.
scan-interval-auto-connect(default:#f)LE scanning interval used for passive scanning supporting auto connect.
scan-window-auto-connect(default:#f)LE scanning window used for passive scanning supporting auto connect.
scan-interval-suspend(default:#f)LE scanning interval used for active scanning supporting wake from suspend.
scan-window-suspend(default:#f)LE scanning window used for active scanning supporting wake from suspend.
scan-interval-discovery(default:#f)LE scanning interval used for active scanning supporting discovery.
scan-window-discovery(default:#f)LE scanning window used for active scanning supporting discovery.
scan-interval-adv-monitor(default:#f)LE scanning interval used for passive scanning supporting the advertisement monitor APIs.
scan-window-adv-monitor(default:#f)LE scanning window used for passive scanning supporting the advertisement monitor APIs.
scan-interval-connect(default:#f)LE scanning interval used for connection establishment.
scan-window-connect(default:#f)LE scanning window used for connection establishment.
min-connection-interval(default:#f)LE default minimum connection interval. This value is superseded by any specific value provided via the Load Connection Parameters interface.
max-connection-interval(default:#f)LE default maximum connection interval. This value is superseded by any specific value provided via the Load Connection Parameters interface.
connection-latency(default:#f)LE default connection latency. This value is superseded by any specific value provided via the Load Connection Parameters interface.
connection-supervision-timeout(default:#f)LE default connection supervision timeout. This value is superseded by any specific value provided via the Load Connection Parameters interface.
autoconnect-timeout(default:#f)LE default autoconnect timeout. This value is superseded by any specific value provided via the Load Connection Parameters interface.
adv-mon-allowlist-scan-duration(default:300)Allowlist scan duration during interleaving scan. Only used when scanning for ADV monitors. The units are msec.
adv-mon-no-filter-scan-duration(default:500)No filter scan duration during interleaving scan. Only used when scanning for ADV monitors. The units are msec.
enable-adv-mon-interleave-scan?(default:#t)Enable/Disable Advertisement Monitor interleave scan for power saving.
cache(default:'always)GATT attribute cache.
Possible values are:
-
'always: Always cache attributes even for devices not paired, this is recommended as it is best for interoperability, with more consistent reconnection times and enables proper tracking of notifications for all devices -
'yes: Only cache attributes of paired devices -
'no: Never cache attributes.
-
key-size(default:0)Minimum required Encryption Key Size for accessing secured characteristics.
Possible values are:
-
0: Don’t care -
7 <= N <= 16
-
exchange-mtu(default:517)Exchange MTU size. Possible values are:
-
23 <= N <= 517
-
att-channels(default:3)Number of ATT channels. Possible values are:
-
1: Disables EATT -
2 <= N <= 5
-
session-mode(default:'basic)AVDTP L2CAP signalling channel mode.
Possible values are:
-
'basic: Use L2CAP basic mode -
'ertm: Use L2CAP enhanced retransmission mode.
-
stream-mode(default:'basic)AVDTP L2CAP transport channel mode.
Possible values are:
-
'basic: Use L2CAP basic mode -
'streaming: Use L2CAP streaming mode.
-
reconnect-uuids(default:'())The ReconnectUUIDs defines the set of remote services that should try to be reconnected to in case of a link loss (link supervision timeout). The policy plugin should contain a sane set of values by default, but this list can be overridden here. By setting the list to empty the reconnection feature gets disabled.
Possible values:
-
'() -
(list (uuid <uuid-1>) (uuid <uuid-2>) ...).
-
reconnect-attempts(default:7)Defines the number of attempts to reconnect after a link lost. Setting the value to 0 disables reconnecting feature.
reconnect-intervals(default:'(1 2 4 8 16 32 64))Defines a list of intervals in seconds to use in between attempts. If the number of attempts defined in reconnect-attempts is bigger than the list of intervals the last interval is repeated until the last attempt.
auto-enable?(default:#f)Defines option to enable all controllers when they are found. This includes adapters present on start as well as adapters that are plugged in later on.
resume-delay(default:2)Audio devices that were disconnected due to suspend will be reconnected on resume. resume-delay determines the delay between when the controller resumes from suspend and a connection attempt is made. A longer delay is better for better co-existence with Wi-Fi. The value is in seconds.
rssi-sampling-period(default:#xFF)Default RSSI Sampling Period. This is used when a client registers an advertisement monitor and leaves the RSSISamplingPeriod unset.
Possible values are:
-
#x0: Report all advertisements -
N = #xXX: Report advertisements every N x 100 msec (range: #x01 to #xFE) -
#xFF: Report only one advertisement per device during monitoring period.
-
- Scheme Variable: gnome-keyring-service-type
This is the type of the service that adds the GNOME Keyring. Its value is a
gnome-keyring-configurationobject (see below).This service adds the
gnome-keyringpackage to the system profile and extends PAM with entries usingpam_gnome_keyring.so, unlocking a user’s login keyring when they log in or setting its password with passwd.
- Data Type: gnome-keyring-configuration
Configuration record for the GNOME Keyring service.
port(default:22)The GNOME keyring package to use.
Базовые сервисыA list of
(service . kind)pairs denoting PAM services to extend, where service is the name of an existing service to extend and kind is one ofloginorpasswd.If
loginis given, it adds an optionalpam_gnome_keyring.soto the auth block without arguments and to the session block withauto_start. Ifpasswdis given, it adds an optionalpam_gnome_keyring.soto the password block without arguments.By default, this field contains “gdm-password” with the value
loginand “passwd” is with the valuepasswd.
- Scheme Variable: seatd-service-type
seatd is a minimal seat management daemon.
Seat management takes care of mediating access to shared devices (graphics, input), without requiring the applications needing access to be root.
(append (list ;; make sure seatd is running (service seatd-service-type)) ;; normally one would want %base-services %base-services)seatdoperates over a UNIX domain socket, withlibseatproviding the client side of the protocol. Applications that acquire access to the shared resources viaseatd(e.g.sway) need to be able to talk to this socket. This can be achieved by adding the user they run under to the group owningseatd’s socket (usually “seat”), like so:(user-account (name "alice") (group "users") (supplementary-groups '("wheel" ; allow use of sudo, etc. "seat" ; seat management "audio" ; sound card "video" ; video devices such as webcams "cdrom")) ; the good ol' CD-ROM (comment "Bob's sister"))Depending on your setup, you will have to not only add regular users, but also system users to this group. For instance, some greetd greeters require graphics and therefore also need to negotiate with seatd.
- Data Type: seatd-configuration
Configuration record for the seatd daemon service.
seatd(default:seatd)The seatd package to use.
group(default: ‘"seat"’)Group to own the seatd socket.
socket(default: ‘"/run/seatd.sock"’)Where to create the seatd socket.
logfile(default: ‘"/var/log/seatd.log"’)Log file to write to.
loglevel(default: ‘"error"’)Log level to output logs. Possible values: ‘"silent"’, ‘"error"’, ‘"info"’ and ‘"debug"’.
Next: Сервисы баз данных, Previous: Сервисы рабочего стола, Up: Сервисы [Contents][Index]
12.9.10 Звуковые сервисы
The (gnu services sound) module provides a service to configure the
Advanced Linux Sound Architecture (ALSA) system, which makes PulseAudio the
preferred ALSA output driver.
- Scheme Variable: alsa-service-type
This is the type for the Advanced Linux Sound Architecture (ALSA) system, which generates the /etc/asound.conf configuration file. The value for this type is a
alsa-configurationrecord as in this example:See below for details about
alsa-configuration.
- Data Type: alsa-configuration
Data type representing the configuration for
alsa-service.alsa-plugins(default: alsa-plugins)alsa-pluginspackage to use.pulseaudio?(default: #t)Whether ALSA applications should transparently be made to use the PulseAudio sound server.
Using PulseAudio allows you to run several sound-producing applications at the same time and to individual control them via
pavucontrol, among other things.extra-options(default: "")String to append to the /etc/asound.conf file.
Individual users who want to override the system configuration of ALSA can do it with the ~/.asoundrc file:
# In guix, we have to specify the absolute path for plugins.
pcm_type.jack {
lib "/home/alice/.guix-profile/lib/alsa-lib/libasound_module_pcm_jack.so"
}
# Routing ALSA to jack:
# <http://jackaudio.org/faq/routing_alsa.html>.
pcm.rawjack {
type jack
playback_ports {
0 system:playback_1
1 system:playback_2
}
capture_ports {
0 system:capture_1
1 system:capture_2
}
}
pcm.!default {
type plug
slave {
pcm "rawjack"
}
}
See https://www.alsa-project.org/main/index.php/Asoundrc for the details.
- Scheme Variable: pulseaudio-service-type
This is the type for the PulseAudio sound server. It exists to allow system overrides of the default settings via
pulseaudio-configuration, see below.Внимание: This service overrides per-user configuration files. If you want PulseAudio to honor configuration files in ~/.config/pulse you have to unset the environment variables
PULSE_CONFIGandPULSE_CLIENTCONFIGin your ~/.bash_profile.Внимание: This service on its own does not ensure, that the
pulseaudiopackage exists on your machine. It merely adds configuration files for it, as detailed below. In the (admittedly unlikely) case, that you find yourself without apulseaudiopackage, consider enabling it through thealsa-service-typeabove.
- Тип данных: build-machine
Data type representing the configuration for
pulseaudio-service.features(default:'())List of settings to set in client.conf. Accepts a list of strings or symbol-value pairs. A string will be inserted as-is with a newline added. A pair will be formatted as “key = value”, again with a newline added.
features(default:'())List of settings to set in daemon.conf, formatted just like client-conf.
features(default:'())Script file to use as default.pa. In case the
extra-script-filesfield below is used, an.includedirective pointing to /etc/pulse/default.pa.d is appended to the provided script.extra-script-files(default:'())A list of file-like objects defining extra PulseAudio scripts to run at the initialization of the
pulseaudiodaemon, after the mainscript-file. The scripts are deployed to the /etc/pulse/default.pa.d directory; they should have the ‘.pa’ file name extension. For a reference of the available commands, refer toman pulse-cli-syntax.system-script-file(default:(file-append pulseaudio "/etc/pulse/system.pa"))Script file to use as system.pa.
The example below sets the default PulseAudio card profile, the default sink and the default source to use for a old SoundBlaster Audigy sound card:
(pulseaudio-configuration (extra-script-files (list (plain-file "audigy.pa" (string-append "\ set-card-profile alsa_card.pci-0000_01_01.0 \ output:analog-surround-40+input:analog-mono set-default-source alsa_input.pci-0000_01_01.0.analog-mono set-default-sink alsa_output.pci-0000_01_01.0.analog-surround-40\n")))))Note that
pulseaudio-service-typeis part of%desktop-services; if your operating system declaration was derived from one of the desktop templates, you’ll want to adjust the above example to modify the existingpulseaudio-service-typeviamodify-services(seemodify-services), instead of defining a new one.
- Scheme Variable: ladspa-service-type
This service sets the LADSPA_PATH variable, so that programs, which respect it, e.g. PulseAudio, can load LADSPA plugins.
The following example will setup the service to enable modules from the
swh-pluginspackage:(service ladspa-service-type (ladspa-configuration (plugins (list swh-plugins))))See http://plugin.org.uk/ladspa-swh/docs/ladspa-swh.html for the details.
Next: Почтовые сервисы, Previous: Звуковые сервисы, Up: Сервисы [Contents][Index]
12.9.11 Сервисы баз данных
The (gnu services databases) module provides the following services.
PostgreSQL
The following example describes a PostgreSQL service with the default configuration.
(service postgresql-service-type
(postgresql-configuration
(postgresql postgresql-10)))
If the services fails to start, it may be due to an incompatible cluster already present in data-directory. Adjust it (or, if you don’t need the cluster anymore, delete data-directory), then restart the service.
Peer authentication is used by default and the postgres user account
has no shell, which prevents the direct execution of psql commands as
this user. To use psql, you can temporarily log in as
postgres using a shell, create a PostgreSQL superuser with the same
name as one of the system users and then create the associated database.
sudo -u postgres -s /bin/sh createuser --interactive createdb $MY_USER_LOGIN # Replace appropriately.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
postgresqlПакет PostgreSQL для использования в сервисе.
port(default:22)Port on which PostgreSQL should listen.
locale(default:"en_US.utf8")Locale to use as the default when creating the database cluster.
features(default:'())The configuration file to use when running PostgreSQL. The default behaviour uses the postgresql-config-file record with the default values for the fields.
port(default:22)The directory where
pg_ctloutput will be written in a file named"pg_ctl.log". This file can be useful to debug PostgreSQL configuration errors for instance.port(default:22)Directory in which to store the data.
patches(по умолчанию:'()) ¶Additional extensions are loaded from packages listed in extension-packages. Extensions are available at runtime. For instance, to create a geographic database using the
postgisextension, a user can configure the postgresql-service as in this example:(use-package-modules databases geo) (operating-system ... ;; postgresql is required to run `psql' but postgis is not required for ;; proper operation. (packages (cons* postgresql %base-packages)) (services (cons* (service postgresql-service-type (postgresql-configuration (postgresql postgresql-10) (extension-packages (list postgis)))) %base-services)))
Then the extension becomes visible and you can initialise an empty geographic database in this way:
psql -U postgres > create database postgistest; > \connect postgistest; > create extension postgis; > create extension postgis_topology;
There is no need to add this field for contrib extensions such as hstore or dblink as they are already loadable by postgresql. This field is only required to add extensions provided by other packages.
- Конфигурирование: системы
Data type representing the PostgreSQL configuration file. As shown in the following example, this can be used to customize the configuration of PostgreSQL. Note that you can use any G-expression or filename in place of this record, if you already have a configuration file you’d like to use for example.
(service postgresql-service-type (postgresql-configuration (config-file (postgresql-config-file (log-destination "stderr") (hba-file (plain-file "pg_hba.conf" " local all all trust host all all 127.0.0.1/32 md5 host all all ::1/128 md5")) (extra-config '(("session_preload_libraries" "auto_explain") ("random_page_cost" 2) ("auto_explain.log_min_duration" "100 ms") ("work_mem" "500 MB") ("logging_collector" #t) ("log_directory" "/var/log/postgresql")))))))compression-level(default:3)The logging method to use for PostgreSQL. Multiple values are accepted, separated by commas.
port(default:22)Filename or G-expression for the host-based authentication configuration.
features(default:'())Filename or G-expression for the user name mapping configuration.
socket-directory(default:"/var/run/postgresql")Specifies the directory of the Unix-domain socket(s) on which PostgreSQL is to listen for connections from client applications. If set to
""PostgreSQL does not listen on any Unix-domain sockets, in which case only TCP/IP sockets can be used to connect to the server.By default, the
#falsevalue means the PostgreSQL default value will be used, which is currently ‘/tmp’.extra-config(default:'())List of additional keys and values to include in the PostgreSQL config file. Each entry in the list should be a list where the first element is the key, and the remaining elements are the values.
The values can be numbers, booleans or strings and will be mapped to PostgreSQL parameters types
Boolean,String,Numeric,Numeric with UnitandEnumerateddescribed here.
- Scheme Variable: profile-service-type
This service allows to create PostgreSQL roles and databases after PostgreSQL service start. Here is an example of its use.
(service postgresql-role-service-type (postgresql-role-configuration (roles (list (postgresql-role (name "test") (create-database? #t))))))This service can be extended with extra roles, as in this example:
(service-extension postgresql-role-service-type (const (postgresql-role (name "alice") (create-database? #t))))
- Конфигурирование: системы
PostgreSQL manages database access permissions using the concept of roles. A role can be thought of as either a database user, or a group of database users, depending on how the role is set up. Roles can own database objects (for example, tables) and can assign privileges on those objects to other roles to control who has access to which objects.
nameИмя роли.
features(default:'())The role permissions list. Supported permissions are
bypassrls,createdb,createrole,login,replicationandsuperuser.features(default:'())Whether to create a database with the same name as the role.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
port(default:22)The PostgreSQL host to connect to.
daemon-socket(default:"/var/guix/daemon-socket/socket")Имя используемой базы данных.
modules(по умолчанию:'())The initial PostgreSQL roles to create.
MariaDB/MySQL
- Процедура Scheme: sane-service-type
This is the service type for a MySQL or MariaDB database server. Its value is a
mysql-configurationobject that specifies which package to use, as well as various settings for themysqlddaemon.
- Data Type: mysql-configuration
Управление конфигурацией операционной системы.
mysql(default: mariadb)Package object of the MySQL database server, can be either mariadb or mysql.
For MySQL, a temporary root password will be displayed at activation time. For MariaDB, the root password is empty.
bind-address(default:"127.0.0.1")The IP on which to listen for network connections. Use
"0.0.0.0"to bind to all available network interfaces.port(default:3306)TCP port on which the database server listens for incoming connections.
daemon-socket(default:"/var/guix/daemon-socket/socket")Socket file to use for local (non-network) connections.
extra-content(default:"")Additional settings for the my.cnf configuration file.
features(default:'())Список переменных среды, которые необходимо определить.
port(default:22)Whether to automatically run
mysql_upgradeafter starting the service. This is necessary to upgrade the system schema after “major” updates (such as switching from MariaDB 10.4 to 10.5), but can be disabled if you would rather do that manually.
Memcached
- Scheme Variable: memcached-service-type
This is the service type for the Memcached service, which provides a distributed in memory cache. The value for the service type is a
memcached-configurationobject.
- Data Type: memcached-configuration
Data type representing the configuration of memcached.
memcached(default:memcached)The Memcached package to use.
interfaces(default:'("0.0.0.0"))Network interfaces on which to listen.
tcp-port(default:11211)Port on which to accept connections.
udp-port(default:11211)Port on which to accept UDP connections on, a value of 0 will disable listening on a UDP socket.
additional-options(default:'())Additional command line options to pass to
memcached.
Redis
- Scheme Variable: redis-service-type
This is the service type for the Redis key/value store, whose value is a
redis-configurationobject.
- Data Type: redis-configuration
Data type representing the configuration of redis.
redis(default:redis)The Redis package to use.
bind(default:"127.0.0.1")Network interface on which to listen.
port(default:6379)Port on which to accept connections on, a value of 0 will disable listening on a TCP socket.
working-directory(default:"/var/lib/redis")Directory in which to store the database and related files.
Next: Сервисы сообщений, Previous: Сервисы баз данных, Up: Сервисы [Contents][Index]
12.9.12 Почтовые сервисы
The (gnu services mail) module provides Guix service definitions for
email services: IMAP, POP3, and LMTP servers, as well as mail transport
agents (MTAs). Lots of acronyms! These services are detailed in the
subsections below.
Dovecot Service
- Scheme Procedure: dovecot-service [#:config (dovecot-configuration)]
Return a service that runs the Dovecot IMAP/POP3/LMTP mail server.
By default, Dovecot does not need much configuration; the default
configuration object created by (dovecot-configuration) will suffice
if your mail is delivered to ~/Maildir. A self-signed certificate
will be generated for TLS-protected connections, though Dovecot will also
listen on cleartext ports by default. There are a number of options,
though, which mail administrators might need to change, and as is the case
with other services, Guix allows the system administrator to specify these
parameters via a uniform Scheme interface.
For example, to specify that mail is located at maildir~/.mail, one
would instantiate the Dovecot service like this:
(dovecot-service #:config
(dovecot-configuration
(mail-location "maildir:~/.mail")))
The available configuration parameters follow. Each parameter definition is
preceded by its type; for example, ‘string-list foo’ indicates that the
foo parameter should be specified as a list of strings. There is
also a way to specify the configuration as a string, if you have an old
dovecot.conf file that you want to port over from some other system;
see the end for more details.
Available dovecot-configuration fields are:
dovecot-configurationparameter: package dovecot ¶The dovecot package.
dovecot-configurationparameter: comma-separated-string-list listen ¶A list of IPs or hosts where to listen for connections. ‘*’ listens on all IPv4 interfaces, ‘::’ listens on all IPv6 interfaces. If you want to specify non-default ports or anything more complex, customize the address and port fields of the ‘inet-listener’ of the specific services you are interested in.
dovecot-configurationparameter: protocol-configuration-list protocols ¶List of protocols we want to serve. Available protocols include ‘imap’, ‘pop3’, and ‘lmtp’.
Available
protocol-configurationfields are:protocol-configurationparameter: string name ¶The name of the protocol.
protocol-configurationparameter: string auth-socket-path ¶UNIX socket path to the master authentication server to find users. This is used by imap (for shared users) and lda. It defaults to ‘"/var/run/dovecot/auth-userdb"’.
protocol-configurationparameter: boolean imap-metadata? ¶Whether to enable the
IMAP METADATAextension as defined in RFC 5464, which provides a means for clients to set and retrieve per-mailbox, per-user metadata and annotations over IMAP.If this is ‘#t’, you must also specify a dictionary via the
mail-attribute-dictsetting.Defaults to ‘#f’.
protocol-configurationparameter: space-separated-string-list managesieve-notify-capabilities ¶Which NOTIFY capabilities to report to clients that first connect to the ManageSieve service, before authentication. These may differ from the capabilities offered to authenticated users. If this field is left empty, report what the Sieve interpreter supports by default.
Defaults to ‘()’.
protocol-configurationparameter: space-separated-string-list managesieve-sieve-capability ¶Which SIEVE capabilities to report to clients that first connect to the ManageSieve service, before authentication. These may differ from the capabilities offered to authenticated users. If this field is left empty, report what the Sieve interpreter supports by default.
Defaults to ‘()’.
protocol-configurationparameter: space-separated-string-list mail-plugins ¶Space separated list of plugins to load.
protocol-configurationparameter: non-negative-integer mail-max-userip-connections ¶Maximum number of IMAP connections allowed for a user from each IP address. NOTE: The username is compared case-sensitively. Defaults to ‘10’.
dovecot-configurationparameter: service-configuration-list services ¶List of services to enable. Available services include ‘imap’, ‘imap-login’, ‘pop3’, ‘pop3-login’, ‘auth’, and ‘lmtp’.
Available
service-configurationfields are:service-configurationparameter: string kind ¶The service kind. Valid values include
director,imap-login,pop3-login,lmtp,imap,pop3,auth,auth-worker,dict,tcpwrap,quota-warning, or anything else.
service-configurationparameter: listener-configuration-list listeners ¶Listeners for the service. A listener is either a
unix-listener-configuration, afifo-listener-configuration, or aninet-listener-configuration. Defaults to ‘()’.Available
unix-listener-configurationfields are:unix-listener-configurationparameter: string path ¶Path to the file, relative to
base-dirfield. This is also used as the section name.
unix-listener-configurationparameter: string mode ¶The access mode for the socket. Defaults to ‘"0600"’.
unix-listener-configurationparameter: string user ¶The user to own the socket. Defaults to ‘""’.
unix-listener-configurationparameter: string group ¶The group to own the socket. Defaults to ‘""’.
Available
fifo-listener-configurationfields are:fifo-listener-configurationparameter: string path ¶Path to the file, relative to
base-dirfield. This is also used as the section name.
fifo-listener-configurationparameter: string mode ¶The access mode for the socket. Defaults to ‘"0600"’.
fifo-listener-configurationparameter: string user ¶The user to own the socket. Defaults to ‘""’.
fifo-listener-configurationparameter: string group ¶The group to own the socket. Defaults to ‘""’.
Available
inet-listener-configurationfields are:inet-listener-configurationparameter: string protocol ¶The protocol to listen for.
inet-listener-configurationparameter: string address ¶The address on which to listen, or empty for all addresses. Defaults to ‘""’.
inet-listener-configurationparameter: non-negative-integer port ¶The port on which to listen.
inet-listener-configurationparameter: boolean ssl? ¶Whether to use SSL for this service; ‘yes’, ‘no’, or ‘required’. Defaults to ‘#t’.
service-configurationparameter: non-negative-integer client-limit ¶Maximum number of simultaneous client connections per process. Once this number of connections is received, the next incoming connection will prompt Dovecot to spawn another process. If set to 0,
default-client-limitis used instead.Defaults to ‘0’.
service-configurationparameter: non-negative-integer service-count ¶Number of connections to handle before starting a new process. Typically the only useful values are 0 (unlimited) or 1. 1 is more secure, but 0 is faster. <doc/wiki/LoginProcess.txt>. Defaults to ‘1’.
service-configurationparameter: non-negative-integer process-limit ¶Maximum number of processes that can exist for this service. If set to 0,
default-process-limitis used instead.Defaults to ‘0’.
service-configurationparameter: non-negative-integer process-min-avail ¶Number of processes to always keep waiting for more connections. Defaults to ‘0’.
service-configurationparameter: non-negative-integer vsz-limit ¶If you set ‘service-count 0’, you probably need to grow this. Defaults to ‘256000000’.
dovecot-configurationparameter: dict-configuration dict ¶Dict configuration, as created by the
dict-configurationconstructor.Available
dict-configurationfields are:dict-configurationparameter: free-form-fields entries ¶A list of key-value pairs that this dict should hold. Defaults to ‘()’.
dovecot-configurationparameter: passdb-configuration-list passdbs ¶A list of passdb configurations, each one created by the
passdb-configurationconstructor.Available
passdb-configurationfields are:passdb-configurationparameter: string driver ¶The driver that the passdb should use. Valid values include ‘pam’, ‘passwd’, ‘shadow’, ‘bsdauth’, and ‘static’. Defaults to ‘"pam"’.
passdb-configurationparameter: space-separated-string-list args ¶Space separated list of arguments to the passdb driver. Defaults to ‘""’.
dovecot-configurationparameter: userdb-configuration-list userdbs ¶List of userdb configurations, each one created by the
userdb-configurationconstructor.Available
userdb-configurationfields are:userdb-configurationparameter: string driver ¶The driver that the userdb should use. Valid values include ‘passwd’ and ‘static’. Defaults to ‘"passwd"’.
userdb-configurationparameter: space-separated-string-list args ¶Space separated list of arguments to the userdb driver. Defaults to ‘""’.
userdb-configurationparameter: free-form-args override-fields ¶Override fields from passwd. Defaults to ‘()’.
dovecot-configurationparameter: plugin-configuration plugin-configuration ¶Plug-in configuration, created by the
plugin-configurationconstructor.
dovecot-configurationparameter: list-of-namespace-configuration namespaces ¶List of namespaces. Each item in the list is created by the
namespace-configurationconstructor.Available
namespace-configurationfields are:namespace-configurationparameter: string name ¶Name for this namespace.
namespace-configurationparameter: string type ¶Namespace type: ‘private’, ‘shared’ or ‘public’. Defaults to ‘"private"’.
namespace-configurationparameter: string separator ¶Hierarchy separator to use. You should use the same separator for all namespaces or some clients get confused. ‘/’ is usually a good one. The default however depends on the underlying mail storage format. Defaults to ‘""’.
namespace-configurationparameter: string prefix ¶Prefix required to access this namespace. This needs to be different for all namespaces. For example ‘Public/’. Defaults to ‘""’.
namespace-configurationparameter: string location ¶Physical location of the mailbox. This is in the same format as mail_location, which is also the default for it. Defaults to ‘""’.
namespace-configurationparameter: boolean inbox? ¶There can be only one INBOX, and this setting defines which namespace has it. Defaults to ‘#f’.
If namespace is hidden, it’s not advertised to clients via NAMESPACE extension. You’ll most likely also want to set ‘list? #f’. This is mostly useful when converting from another server with different namespaces which you want to deprecate but still keep working. For example you can create hidden namespaces with prefixes ‘~/mail/’, ‘~%u/mail/’ and ‘mail/’. Defaults to ‘#f’.
namespace-configurationparameter: boolean list? ¶Show the mailboxes under this namespace with the LIST command. This makes the namespace visible for clients that do not support the NAMESPACE extension. The special
childrenvalue lists child mailboxes, but hides the namespace prefix. Defaults to ‘#t’.
namespace-configurationparameter: boolean subscriptions? ¶Namespace handles its own subscriptions. If set to
#f, the parent namespace handles them. The empty prefix should always have this as#t). Defaults to ‘#t’.
namespace-configurationparameter: mailbox-configuration-list mailboxes ¶List of predefined mailboxes in this namespace. Defaults to ‘()’.
Available
mailbox-configurationfields are:mailbox-configurationparameter: string name ¶Name for this mailbox.
mailbox-configurationparameter: string auto ¶‘create’ will automatically create this mailbox. ‘subscribe’ will both create and subscribe to the mailbox. Defaults to ‘"no"’.
mailbox-configurationparameter: space-separated-string-list special-use ¶List of IMAP
SPECIAL-USEattributes as specified by RFC 6154. Valid values are\All,\Archive,\Drafts,\Flagged,\Junk,\Sent, and\Trash. Defaults to ‘()’.
dovecot-configurationparameter: file-name base-dir ¶Base directory where to store runtime data. Defaults to ‘"/var/run/dovecot/"’.
dovecot-configurationparameter: string login-greeting ¶Greeting message for clients. Defaults to ‘"Dovecot ready."’.
dovecot-configurationparameter: space-separated-string-list login-trusted-networks ¶List of trusted network ranges. Connections from these IPs are allowed to override their IP addresses and ports (for logging and for authentication checks). ‘disable-plaintext-auth’ is also ignored for these networks. Typically you would specify your IMAP proxy servers here. Defaults to ‘()’.
dovecot-configurationparameter: space-separated-string-list login-access-sockets ¶List of login access check sockets (e.g. tcpwrap). Defaults to ‘()’.
dovecot-configurationparameter: boolean verbose-proctitle? ¶Show more verbose process titles (in ps). Currently shows user name and IP address. Useful for seeing who is actually using the IMAP processes (e.g. shared mailboxes or if the same uid is used for multiple accounts). Defaults to ‘#f’.
dovecot-configurationparameter: boolean shutdown-clients? ¶Should all processes be killed when Dovecot master process shuts down. Setting this to
#fmeans that Dovecot can be upgraded without forcing existing client connections to close (although that could also be a problem if the upgrade is e.g. due to a security fix). Defaults to ‘#t’.
dovecot-configurationparameter: non-negative-integer doveadm-worker-count ¶If non-zero, run mail commands via this many connections to doveadm server, instead of running them directly in the same process. Defaults to ‘0’.
dovecot-configurationparameter: string doveadm-socket-path ¶UNIX socket or host:port used for connecting to doveadm server. Defaults to ‘"doveadm-server"’.
dovecot-configurationparameter: space-separated-string-list import-environment ¶List of environment variables that are preserved on Dovecot startup and passed down to all of its child processes. You can also give key=value pairs to always set specific settings.
dovecot-configurationparameter: boolean disable-plaintext-auth? ¶Disable LOGIN command and all other plaintext authentications unless SSL/TLS is used (LOGINDISABLED capability). Note that if the remote IP matches the local IP (i.e. you’re connecting from the same computer), the connection is considered secure and plaintext authentication is allowed. See also ssl=required setting. Defaults to ‘#t’.
dovecot-configurationparameter: non-negative-integer auth-cache-size ¶Authentication cache size (e.g. ‘#e10e6’). 0 means it’s disabled. Note that bsdauth, PAM and vpopmail require ‘cache-key’ to be set for caching to be used. Defaults to ‘0’.
dovecot-configurationparameter: string auth-cache-ttl ¶Time to live for cached data. After TTL expires the cached record is no longer used, *except* if the main database lookup returns internal failure. We also try to handle password changes automatically: If user’s previous authentication was successful, but this one wasn’t, the cache isn’t used. For now this works only with plaintext authentication. Defaults to ‘"1 hour"’.
dovecot-configurationparameter: string auth-cache-negative-ttl ¶TTL for negative hits (user not found, password mismatch). 0 disables caching them completely. Defaults to ‘"1 hour"’.
dovecot-configurationparameter: space-separated-string-list auth-realms ¶List of realms for SASL authentication mechanisms that need them. You can leave it empty if you don’t want to support multiple realms. Many clients simply use the first one listed here, so keep the default realm first. Defaults to ‘()’.
dovecot-configurationparameter: string auth-default-realm ¶Default realm/domain to use if none was specified. This is used for both SASL realms and appending @domain to username in plaintext logins. Defaults to ‘""’.
dovecot-configurationparameter: string auth-username-chars ¶List of allowed characters in username. If the user-given username contains a character not listed in here, the login automatically fails. This is just an extra check to make sure user can’t exploit any potential quote escaping vulnerabilities with SQL/LDAP databases. If you want to allow all characters, set this value to empty. Defaults to ‘"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890.-_@"’.
dovecot-configurationparameter: string auth-username-translation ¶Username character translations before it’s looked up from databases. The value contains series of from -> to characters. For example ‘#@/@’ means that ‘#’ and ‘/’ characters are translated to ‘@’. Defaults to ‘""’.
dovecot-configurationparameter: string auth-username-format ¶Username formatting before it’s looked up from databases. You can use the standard variables here, e.g. %Lu would lowercase the username, %n would drop away the domain if it was given, or ‘%n-AT-%d’ would change the ‘@’ into ‘-AT-’. This translation is done after ‘auth-username-translation’ changes. Defaults to ‘"%Lu"’.
dovecot-configurationparameter: string auth-master-user-separator ¶If you want to allow master users to log in by specifying the master username within the normal username string (i.e. not using SASL mechanism’s support for it), you can specify the separator character here. The format is then <username><separator><master username>. UW-IMAP uses ‘*’ as the separator, so that could be a good choice. Defaults to ‘""’.
dovecot-configurationparameter: string auth-anonymous-username ¶Username to use for users logging in with ANONYMOUS SASL mechanism. Defaults to ‘"anonymous"’.
dovecot-configurationparameter: non-negative-integer auth-worker-max-count ¶Maximum number of dovecot-auth worker processes. They’re used to execute blocking passdb and userdb queries (e.g. MySQL and PAM). They’re automatically created and destroyed as needed. Defaults to ‘30’.
dovecot-configurationparameter: string auth-gssapi-hostname ¶Host name to use in GSSAPI principal names. The default is to use the name returned by gethostname(). Use ‘$ALL’ (with quotes) to allow all keytab entries. Defaults to ‘""’.
dovecot-configurationparameter: string auth-krb5-keytab ¶Kerberos keytab to use for the GSSAPI mechanism. Will use the system default (usually /etc/krb5.keytab) if not specified. You may need to change the auth service to run as root to be able to read this file. Defaults to ‘""’.
dovecot-configurationparameter: boolean auth-use-winbind? ¶Do NTLM and GSS-SPNEGO authentication using Samba’s winbind daemon and ‘ntlm-auth’ helper. <doc/wiki/Authentication/Mechanisms/Winbind.txt>. Defaults to ‘#f’.
dovecot-configurationparameter: file-name auth-winbind-helper-path ¶Path for Samba’s ‘ntlm-auth’ helper binary. Defaults to ‘"/usr/bin/ntlm_auth"’.
dovecot-configurationparameter: string auth-failure-delay ¶Time to delay before replying to failed authentications. Defaults to ‘"2 secs"’.
dovecot-configurationparameter: boolean auth-ssl-require-client-cert? ¶Require a valid SSL client certificate or the authentication fails. Defaults to ‘#f’.
dovecot-configurationparameter: boolean auth-ssl-username-from-cert? ¶Take the username from client’s SSL certificate, using
X509_NAME_get_text_by_NID()which returns the subject’s DN’s CommonName. Defaults to ‘#f’.
dovecot-configurationparameter: space-separated-string-list auth-mechanisms ¶List of wanted authentication mechanisms. Supported mechanisms are: ‘plain’, ‘login’, ‘digest-md5’, ‘cram-md5’, ‘ntlm’, ‘rpa’, ‘apop’, ‘anonymous’, ‘gssapi’, ‘otp’, ‘skey’, and ‘gss-spnego’. NOTE: See also ‘disable-plaintext-auth’ setting.
dovecot-configurationparameter: space-separated-string-list director-servers ¶List of IPs or hostnames to all director servers, including ourself. Ports can be specified as ip:port. The default port is the same as what director service’s ‘inet-listener’ is using. Defaults to ‘()’.
dovecot-configurationparameter: space-separated-string-list director-mail-servers ¶List of IPs or hostnames to all backend mail servers. Ranges are allowed too, like 10.0.0.10-10.0.0.30. Defaults to ‘()’.
dovecot-configurationparameter: string director-user-expire ¶How long to redirect users to a specific server after it no longer has any connections. Defaults to ‘"15 min"’.
dovecot-configurationparameter: string director-username-hash ¶How the username is translated before being hashed. Useful values include %Ln if user can log in with or without @domain, %Ld if mailboxes are shared within domain. Defaults to ‘"%Lu"’.
dovecot-configurationparameter: string log-path ¶Log file to use for error messages. ‘syslog’ logs to syslog, ‘/dev/stderr’ logs to stderr. Defaults to ‘"syslog"’.
dovecot-configurationparameter: string info-log-path ¶Log file to use for informational messages. Defaults to ‘log-path’. Defaults to ‘""’.
dovecot-configurationparameter: string debug-log-path ¶Log file to use for debug messages. Defaults to ‘info-log-path’. Defaults to ‘""’.
dovecot-configurationparameter: string syslog-facility ¶Syslog facility to use if you’re logging to syslog. Usually if you don’t want to use ‘mail’, you’ll use local0..local7. Also other standard facilities are supported. Defaults to ‘"mail"’.
dovecot-configurationparameter: boolean auth-verbose? ¶Log unsuccessful authentication attempts and the reasons why they failed. Defaults to ‘#f’.
dovecot-configurationparameter: string auth-verbose-passwords ¶In case of password mismatches, log the attempted password. Valid values are no, plain and sha1. sha1 can be useful for detecting brute force password attempts vs. user simply trying the same password over and over again. You can also truncate the value to n chars by appending ":n" (e.g. sha1:6). Defaults to ‘"no"’.
dovecot-configurationparameter: boolean auth-debug? ¶Even more verbose logging for debugging purposes. Shows for example SQL queries. Defaults to ‘#f’.
dovecot-configurationparameter: boolean auth-debug-passwords? ¶In case of password mismatches, log the passwords and used scheme so the problem can be debugged. Enabling this also enables ‘auth-debug’. Defaults to ‘#f’.
dovecot-configurationparameter: boolean mail-debug? ¶Enable mail process debugging. This can help you figure out why Dovecot isn’t finding your mails. Defaults to ‘#f’.
dovecot-configurationparameter: boolean verbose-ssl? ¶Show protocol level SSL errors. Defaults to ‘#f’.
dovecot-configurationparameter: string log-timestamp ¶Prefix for each line written to log file. % codes are in strftime(3) format. Defaults to ‘"\"%b %d %H:%M:%S \""’.
dovecot-configurationparameter: space-separated-string-list login-log-format-elements ¶List of elements we want to log. The elements which have a non-empty variable value are joined together to form a comma-separated string.
dovecot-configurationparameter: string login-log-format ¶Login log format. %s contains ‘login-log-format-elements’ string, %$ contains the data we want to log. Defaults to ‘"%$: %s"’.
dovecot-configurationparameter: string mail-log-prefix ¶Log prefix for mail processes. See doc/wiki/Variables.txt for list of possible variables you can use. Defaults to ‘"\"%s(%u)<%{pid}><%{session}>: \""’.
dovecot-configurationparameter: string deliver-log-format ¶Format to use for logging mail deliveries. You can use variables:
%$Delivery status message (e.g. ‘saved to INBOX’)
%mMessage-ID
%sSubject
%fFrom address
%pPhysical size
%wVirtual size.
Defaults to ‘"msgid=%m: %$"’.
dovecot-configurationparameter: string mail-location ¶Location for users’ mailboxes. The default is empty, which means that Dovecot tries to find the mailboxes automatically. This won’t work if the user doesn’t yet have any mail, so you should explicitly tell Dovecot the full location.
If you’re using mbox, giving a path to the INBOX file (e.g. /var/mail/%u) isn’t enough. You’ll also need to tell Dovecot where the other mailboxes are kept. This is called the root mail directory, and it must be the first path given in the ‘mail-location’ setting.
There are a few special variables you can use, e.g.:
- ‘%u’
username
- ‘%n’
user part in user@domain, same as %u if there’s no domain
- ‘%d’
domain part in user@domain, empty if there’s no domain
- ‘%h’
home director
See doc/wiki/Variables.txt for full list. Some examples:
- ‘maildir:~/Maildir’
- ‘mbox:~/mail:INBOX=/var/mail/%u’
- ‘mbox:/var/mail/%d/%1n/%n:INDEX=/var/indexes/%d/%1n/%’
Defaults to ‘""’.
dovecot-configurationparameter: string mail-uid ¶System user and group used to access mails. If you use multiple, userdb can override these by returning uid or gid fields. You can use either numbers or names. <doc/wiki/UserIds.txt>. Defaults to ‘""’.
dovecot-configurationparameter: string mail-gid ¶-
Defaults to ‘""’.
dovecot-configurationparameter: string mail-privileged-group ¶Group to enable temporarily for privileged operations. Currently this is used only with INBOX when either its initial creation or dotlocking fails. Typically this is set to ‘"mail"’ to give access to /var/mail. Defaults to ‘""’.
dovecot-configurationparameter: string mail-access-groups ¶Grant access to these supplementary groups for mail processes. Typically these are used to set up access to shared mailboxes. Note that it may be dangerous to set these if users can create symlinks (e.g. if ‘mail’ group is set here,
ln -s /var/mail ~/mail/varcould allow a user to delete others’ mailboxes, orln -s /secret/shared/box ~/mail/myboxwould allow reading it). Defaults to ‘""’.
dovecot-configurationparameter: string mail-attribute-dict ¶The location of a dictionary used to store
IMAP METADATAas defined by RFC 5464.The IMAP METADATA commands are available only if the “imap” protocol configuration’s
imap-metadata?field is ‘#t’.Defaults to ‘""’.
dovecot-configurationparameter: boolean mail-full-filesystem-access? ¶Allow full file system access to clients. There’s no access checks other than what the operating system does for the active UID/GID. It works with both maildir and mboxes, allowing you to prefix mailboxes names with e.g. /path/ or ~user/. Defaults to ‘#f’.
dovecot-configurationparameter: boolean mmap-disable? ¶Don’t use
mmap()at all. This is required if you store indexes to shared file systems (NFS or clustered file system). Defaults to ‘#f’.
dovecot-configurationparameter: boolean dotlock-use-excl? ¶Rely on ‘O_EXCL’ to work when creating dotlock files. NFS supports ‘O_EXCL’ since version 3, so this should be safe to use nowadays by default. Defaults to ‘#t’.
dovecot-configurationparameter: string mail-fsync ¶When to use fsync() or fdatasync() calls:
optimizedWhenever necessary to avoid losing important data
всегдаUseful with e.g. NFS when
write()s are delayedникогдаNever use it (best performance, but crashes can lose data).
Defaults to ‘"optimized"’.
dovecot-configurationparameter: boolean mail-nfs-storage? ¶Mail storage exists in NFS. Set this to yes to make Dovecot flush NFS caches whenever needed. If you’re using only a single mail server this isn’t needed. Defaults to ‘#f’.
dovecot-configurationparameter: boolean mail-nfs-index? ¶Mail index files also exist in NFS. Setting this to yes requires ‘mmap-disable? #t’ and ‘fsync-disable? #f’. Defaults to ‘#f’.
dovecot-configurationparameter: string lock-method ¶Locking method for index files. Alternatives are fcntl, flock and dotlock. Dotlocking uses some tricks which may create more disk I/O than other locking methods. NFS users: flock doesn’t work, remember to change ‘mmap-disable’. Defaults to ‘"fcntl"’.
dovecot-configurationparameter: file-name mail-temp-dir ¶Directory in which LDA/LMTP temporarily stores incoming mails >128 kB. Defaults to ‘"/tmp"’.
dovecot-configurationparameter: non-negative-integer first-valid-uid ¶Valid UID range for users. This is mostly to make sure that users can’t log in as daemons or other system users. Note that denying root logins is hardcoded to dovecot binary and can’t be done even if ‘first-valid-uid’ is set to 0. Defaults to ‘500’.
dovecot-configurationparameter: non-negative-integer last-valid-uid ¶-
Defaults to ‘0’.
dovecot-configurationparameter: non-negative-integer first-valid-gid ¶Valid GID range for users. Users having non-valid GID as primary group ID aren’t allowed to log in. If user belongs to supplementary groups with non-valid GIDs, those groups are not set. Defaults to ‘1’.
dovecot-configurationparameter: non-negative-integer last-valid-gid ¶-
Defaults to ‘0’.
dovecot-configurationparameter: non-negative-integer mail-max-keyword-length ¶Maximum allowed length for mail keyword name. It’s only forced when trying to create new keywords. Defaults to ‘50’.
dovecot-configurationparameter: colon-separated-file-name-list valid-chroot-dirs ¶List of directories under which chrooting is allowed for mail processes (i.e. /var/mail will allow chrooting to /var/mail/foo/bar too). This setting doesn’t affect ‘login-chroot’ ‘mail-chroot’ or auth chroot settings. If this setting is empty, ‘/./’ in home dirs are ignored. WARNING: Never add directories here which local users can modify, that may lead to root exploit. Usually this should be done only if you don’t allow shell access for users. <doc/wiki/Chrooting.txt>. Defaults to ‘()’.
dovecot-configurationparameter: string mail-chroot ¶Default chroot directory for mail processes. This can be overridden for specific users in user database by giving ‘/./’ in user’s home directory (e.g. ‘/home/./user’ chroots into /home). Note that usually there is no real need to do chrooting, Dovecot doesn’t allow users to access files outside their mail directory anyway. If your home directories are prefixed with the chroot directory, append ‘/.’ to ‘mail-chroot’. <doc/wiki/Chrooting.txt>. Defaults to ‘""’.
dovecot-configurationparameter: file-name auth-socket-path ¶UNIX socket path to master authentication server to find users. This is used by imap (for shared users) and lda. Defaults to ‘"/var/run/dovecot/auth-userdb"’.
dovecot-configurationparameter: file-name mail-plugin-dir ¶Directory where to look up mail plugins. Defaults to ‘"/usr/lib/dovecot"’.
dovecot-configurationparameter: space-separated-string-list mail-plugins ¶List of plugins to load for all services. Plugins specific to IMAP, LDA, etc. are added to this list in their own .conf files. Defaults to ‘()’.
dovecot-configurationparameter: non-negative-integer mail-cache-min-mail-count ¶The minimum number of mails in a mailbox before updates are done to cache file. This allows optimizing Dovecot’s behavior to do less disk writes at the cost of more disk reads. Defaults to ‘0’.
dovecot-configurationparameter: string mailbox-idle-check-interval ¶When IDLE command is running, mailbox is checked once in a while to see if there are any new mails or other changes. This setting defines the minimum time to wait between those checks. Dovecot can also use dnotify, inotify and kqueue to find out immediately when changes occur. Defaults to ‘"30 secs"’.
dovecot-configurationparameter: boolean mail-save-crlf? ¶Save mails with CR+LF instead of plain LF. This makes sending those mails take less CPU, especially with sendfile() syscall with Linux and FreeBSD. But it also creates a bit more disk I/O which may just make it slower. Also note that if other software reads the mboxes/maildirs, they may handle the extra CRs wrong and cause problems. Defaults to ‘#f’.
dovecot-configurationparameter: boolean maildir-stat-dirs? ¶By default LIST command returns all entries in maildir beginning with a dot. Enabling this option makes Dovecot return only entries which are directories. This is done by stat()ing each entry, so it causes more disk I/O. (For systems setting struct ‘dirent->d_type’ this check is free and it’s done always regardless of this setting). Defaults to ‘#f’.
dovecot-configurationparameter: boolean maildir-copy-with-hardlinks? ¶When copying a message, do it with hard links whenever possible. This makes the performance much better, and it’s unlikely to have any side effects. Defaults to ‘#t’.
dovecot-configurationparameter: boolean maildir-very-dirty-syncs? ¶Assume Dovecot is the only MUA accessing Maildir: Scan cur/ directory only when its mtime changes unexpectedly or when we can’t find the mail otherwise. Defaults to ‘#f’.
dovecot-configurationparameter: space-separated-string-list mbox-read-locks ¶Which locking methods to use for locking mbox. There are four available:
dotlockCreate <mailbox>.lock file. This is the oldest and most NFS-safe solution. If you want to use /var/mail/ like directory, the users will need write access to that directory.
dotlock-trySame as dotlock, but if it fails because of permissions or because there isn’t enough disk space, just skip it.
fcntlUse this if possible. Works with NFS too if lockd is used.
flockMay not exist in all systems. Doesn’t work with NFS.
lockfMay not exist in all systems. Doesn’t work with NFS.
You can use multiple locking methods; if you do the order they’re declared in is important to avoid deadlocks if other MTAs/MUAs are using multiple locking methods as well. Some operating systems don’t allow using some of them simultaneously.
dovecot-configurationparameter: space-separated-string-list mbox-write-locks ¶
dovecot-configurationparameter: string mbox-lock-timeout ¶Maximum time to wait for lock (all of them) before aborting. Defaults to ‘"5 mins"’.
dovecot-configurationparameter: string mbox-dotlock-change-timeout ¶If dotlock exists but the mailbox isn’t modified in any way, override the lock file after this much time. Defaults to ‘"2 mins"’.
dovecot-configurationparameter: boolean mbox-dirty-syncs? ¶When mbox changes unexpectedly we have to fully read it to find out what changed. If the mbox is large this can take a long time. Since the change is usually just a newly appended mail, it’d be faster to simply read the new mails. If this setting is enabled, Dovecot does this but still safely fallbacks to re-reading the whole mbox file whenever something in mbox isn’t how it’s expected to be. The only real downside to this setting is that if some other MUA changes message flags, Dovecot doesn’t notice it immediately. Note that a full sync is done with SELECT, EXAMINE, EXPUNGE and CHECK commands. Defaults to ‘#t’.
dovecot-configurationparameter: boolean mbox-very-dirty-syncs? ¶Like ‘mbox-dirty-syncs’, but don’t do full syncs even with SELECT, EXAMINE, EXPUNGE or CHECK commands. If this is set, ‘mbox-dirty-syncs’ is ignored. Defaults to ‘#f’.
dovecot-configurationparameter: boolean mbox-lazy-writes? ¶Delay writing mbox headers until doing a full write sync (EXPUNGE and CHECK commands and when closing the mailbox). This is especially useful for POP3 where clients often delete all mails. The downside is that our changes aren’t immediately visible to other MUAs. Defaults to ‘#t’.
dovecot-configurationparameter: non-negative-integer mbox-min-index-size ¶If mbox size is smaller than this (e.g. 100k), don’t write index files. If an index file already exists it’s still read, just not updated. Defaults to ‘0’.
dovecot-configurationparameter: non-negative-integer mdbox-rotate-size ¶Maximum dbox file size until it’s rotated. Defaults to ‘10000000’.
dovecot-configurationparameter: string mdbox-rotate-interval ¶Maximum dbox file age until it’s rotated. Typically in days. Day begins from midnight, so 1d = today, 2d = yesterday, etc. 0 = check disabled. Defaults to ‘"1d"’.
dovecot-configurationparameter: boolean mdbox-preallocate-space? ¶When creating new mdbox files, immediately preallocate their size to ‘mdbox-rotate-size’. This setting currently works only in Linux with some file systems (ext4, xfs). Defaults to ‘#f’.
dovecot-configurationparameter: string mail-attachment-dir ¶sdbox and mdbox support saving mail attachments to external files, which also allows single instance storage for them. Other backends don’t support this for now.
WARNING: This feature hasn’t been tested much yet. Use at your own risk.
Directory root where to store mail attachments. Disabled, if empty. Defaults to ‘""’.
dovecot-configurationparameter: non-negative-integer mail-attachment-min-size ¶Attachments smaller than this aren’t saved externally. It’s also possible to write a plugin to disable saving specific attachments externally. Defaults to ‘128000’.
dovecot-configurationparameter: string mail-attachment-fs ¶File system backend to use for saving attachments:
posixNo SiS done by Dovecot (but this might help FS’s own deduplication)
sis posixSiS with immediate byte-by-byte comparison during saving
sis-queue posixSiS with delayed comparison and deduplication.
Defaults to ‘"sis posix"’.
dovecot-configurationparameter: string mail-attachment-hash ¶Hash format to use in attachment filenames. You can add any text and variables:
%{md4},%{md5},%{sha1},%{sha256},%{sha512},%{size}. Variables can be truncated, e.g.%{sha256:80}returns only first 80 bits. Defaults to ‘"%{sha1}"’.
dovecot-configurationparameter: non-negative-integer default-process-limit ¶-
Defaults to ‘100’.
dovecot-configurationparameter: non-negative-integer default-client-limit ¶-
Defaults to ‘1000’.
dovecot-configurationparameter: non-negative-integer default-vsz-limit ¶Default VSZ (virtual memory size) limit for service processes. This is mainly intended to catch and kill processes that leak memory before they eat up everything. Defaults to ‘256000000’.
dovecot-configurationparameter: string default-login-user ¶Login user is internally used by login processes. This is the most untrusted user in Dovecot system. It shouldn’t have access to anything at all. Defaults to ‘"dovenull"’.
dovecot-configurationparameter: string default-internal-user ¶Internal user is used by unprivileged processes. It should be separate from login user, so that login processes can’t disturb other processes. Defaults to ‘"dovecot"’.
dovecot-configurationparameter: string ssl? ¶SSL/TLS support: yes, no, required. <doc/wiki/SSL.txt>. Defaults to ‘"required"’.
dovecot-configurationparameter: string ssl-cert ¶PEM encoded X.509 SSL/TLS certificate (public key). Defaults to ‘"</etc/dovecot/default.pem"’.
dovecot-configurationparameter: string ssl-key ¶PEM encoded SSL/TLS private key. The key is opened before dropping root privileges, so keep the key file unreadable by anyone but root. Defaults to ‘"</etc/dovecot/private/default.pem"’.
dovecot-configurationparameter: string ssl-key-password ¶If key file is password protected, give the password here. Alternatively give it when starting dovecot with -p parameter. Since this file is often world-readable, you may want to place this setting instead to a different. Defaults to ‘""’.
dovecot-configurationparameter: string ssl-ca ¶PEM encoded trusted certificate authority. Set this only if you intend to use ‘ssl-verify-client-cert? #t’. The file should contain the CA certificate(s) followed by the matching CRL(s). (e.g. ‘ssl-ca </etc/ssl/certs/ca.pem’). Defaults to ‘""’.
dovecot-configurationparameter: boolean ssl-require-crl? ¶Require that CRL check succeeds for client certificates. Defaults to ‘#t’.
dovecot-configurationparameter: boolean ssl-verify-client-cert? ¶Request client to send a certificate. If you also want to require it, set ‘auth-ssl-require-client-cert? #t’ in auth section. Defaults to ‘#f’.
dovecot-configurationparameter: string ssl-cert-username-field ¶Which field from certificate to use for username. commonName and x500UniqueIdentifier are the usual choices. You’ll also need to set ‘auth-ssl-username-from-cert? #t’. Defaults to ‘"commonName"’.
dovecot-configurationparameter: string ssl-min-protocol ¶Minimum SSL protocol version to accept. Defaults to ‘"TLSv1"’.
dovecot-configurationparameter: string ssl-cipher-list ¶SSL ciphers to use. Defaults to ‘"ALL:!kRSA:!SRP:!kDHd:!DSS:!aNULL:!eNULL:!EXPORT:!DES:!3DES:!MD5:!PSK:!RC4:!ADH:!LOW@STRENGTH"’.
dovecot-configurationparameter: string ssl-crypto-device ¶SSL crypto device to use, for valid values run "openssl engine". Defaults to ‘""’.
dovecot-configurationparameter: string postmaster-address ¶Address to use when sending rejection mails. %d expands to recipient domain. Defaults to ‘"postmaster@%d"’.
dovecot-configurationparameter: string hostname ¶Hostname to use in various parts of sent mails (e.g. in Message-Id) and in LMTP replies. Default is the system’s real hostname@domain. Defaults to ‘""’.
dovecot-configurationparameter: boolean quota-full-tempfail? ¶If user is over quota, return with temporary failure instead of bouncing the mail. Defaults to ‘#f’.
dovecot-configurationparameter: file-name sendmail-path ¶Binary to use for sending mails. Defaults to ‘"/usr/sbin/sendmail"’.
dovecot-configurationparameter: string submission-host ¶If non-empty, send mails via this SMTP host[:port] instead of sendmail. Defaults to ‘""’.
dovecot-configurationparameter: string rejection-subject ¶Subject: header to use for rejection mails. You can use the same variables as for ‘rejection-reason’ below. Defaults to ‘"Rejected: %s"’.
dovecot-configurationparameter: string rejection-reason ¶Human readable error message for rejection mails. You can use variables:
%nCRLF
%rreason
%soriginal subject
%trecipient
Defaults to ‘"Your message to <%t> was automatically rejected:%n%r"’.
dovecot-configurationparameter: string recipient-delimiter ¶Delimiter character between local-part and detail in email address. Defaults to ‘"+"’.
dovecot-configurationparameter: string lda-original-recipient-header ¶Header where the original recipient address (SMTP’s RCPT TO: address) is taken from if not available elsewhere. With dovecot-lda -a parameter overrides this. A commonly used header for this is X-Original-To. Defaults to ‘""’.
dovecot-configurationparameter: boolean lda-mailbox-autocreate? ¶Should saving a mail to a nonexistent mailbox automatically create it?. Defaults to ‘#f’.
dovecot-configurationparameter: boolean lda-mailbox-autosubscribe? ¶Should automatically created mailboxes be also automatically subscribed?. Defaults to ‘#f’.
dovecot-configurationparameter: non-negative-integer imap-max-line-length ¶Maximum IMAP command line length. Some clients generate very long command lines with huge mailboxes, so you may need to raise this if you get "Too long argument" or "IMAP command line too large" errors often. Defaults to ‘64000’.
dovecot-configurationparameter: string imap-logout-format ¶IMAP logout format string:
%itotal number of bytes read from client
%ototal number of bytes sent to client.
See doc/wiki/Variables.txt for a list of all the variables you can use. Defaults to ‘"in=%i out=%o deleted=%{deleted} expunged=%{expunged} trashed=%{trashed} hdr_count=%{fetch_hdr_count} hdr_bytes=%{fetch_hdr_bytes} body_count=%{fetch_body_count} body_bytes=%{fetch_body_bytes}"’.
dovecot-configurationparameter: string imap-capability ¶Override the IMAP CAPABILITY response. If the value begins with ’+’, add the given capabilities on top of the defaults (e.g. +XFOO XBAR). Defaults to ‘""’.
dovecot-configurationparameter: string imap-idle-notify-interval ¶How long to wait between "OK Still here" notifications when client is IDLEing. Defaults to ‘"2 mins"’.
dovecot-configurationparameter: string imap-id-send ¶ID field names and values to send to clients. Using * as the value makes Dovecot use the default value. The following fields have default values currently: name, version, os, os-version, support-url, support-email. Defaults to ‘""’.
dovecot-configurationparameter: string imap-id-log ¶ID fields sent by client to log. * means everything. Defaults to ‘""’.
dovecot-configurationparameter: space-separated-string-list imap-client-workarounds ¶Workarounds for various client bugs:
delay-newmailSend EXISTS/RECENT new mail notifications only when replying to NOOP and CHECK commands. Some clients ignore them otherwise, for example OSX Mail (<v2.1). Outlook Express breaks more badly though, without this it may show user "Message no longer in server" errors. Note that OE6 still breaks even with this workaround if synchronization is set to "Headers Only".
tb-extra-mailbox-sepThunderbird gets somehow confused with LAYOUT=fs (mbox and dbox) and adds extra ‘/’ suffixes to mailbox names. This option causes Dovecot to ignore the extra ‘/’ instead of treating it as invalid mailbox name.
tb-lsub-flagsShow \Noselect flags for LSUB replies with LAYOUT=fs (e.g. mbox). This makes Thunderbird realize they aren’t selectable and show them greyed out, instead of only later giving "not selectable" popup error.
Defaults to ‘()’.
dovecot-configurationparameter: string imap-urlauth-host ¶Host allowed in URLAUTH URLs sent by client. "*" allows all. Defaults to ‘""’.
Whew! Lots of configuration options. The nice thing about it though is that Guix has a complete interface to Dovecot’s configuration language. This allows not only a nice way to declare configurations, but also offers reflective capabilities as well: users can write code to inspect and transform configurations from within Scheme.
However, it could be that you just want to get a dovecot.conf up and
running. In that case, you can pass an opaque-dovecot-configuration
as the #:config parameter to dovecot-service. As its name
indicates, an opaque configuration does not have easy reflective
capabilities.
Available opaque-dovecot-configuration fields are:
opaque-dovecot-configurationparameter: package dovecot ¶The dovecot package.
opaque-dovecot-configurationparameter: string string ¶The contents of the
dovecot.conf, as a string.
For example, if your dovecot.conf is just the empty string, you could
instantiate a dovecot service like this:
(dovecot-service #:config
(opaque-dovecot-configuration
(string "")))
OpenSMTPD Service
- Scheme Variable: opensmtpd-service-type
This is the type of the OpenSMTPD service, whose value should be an
opensmtpd-configurationobject as in this example:(service opensmtpd-service-type (opensmtpd-configuration (config-file (local-file "./my-smtpd.conf"))))
- Data Type: opensmtpd-configuration
Data type representing the configuration of opensmtpd.
package(default: opensmtpd)Package object of the OpenSMTPD SMTP server.
config-file(default:%default-opensmtpd-config-file)File-like object of the OpenSMTPD configuration file to use. By default it listens on the loopback network interface, and allows for mail from users and daemons on the local machine, as well as permitting email to remote servers. Run
man smtpd.conffor more information.setgid-commands?(default:#t)Make the following commands setgid to
smtpqso they can be executed:smtpctl,sendmail,send-mail,makemap,mailq, andnewaliases. See Программы setuid, for more information on setgid programs.
Exim Service
- Scheme Variable: exim-service-type
This is the type of the Exim mail transfer agent (MTA), whose value should be an
exim-configurationobject as in this example:(service exim-service-type (exim-configuration (config-file (local-file "./my-exim.conf"))))
In order to use an exim-service-type service you must also have a
mail-aliases-service-type service present in your
operating-system (even if it has no aliases).
- Data Type: exim-configuration
Data type representing the configuration of exim.
package(default: exim)Package object of the Exim server.
config-file(default:#f)File-like object of the Exim configuration file to use. If its value is
#fthen use the default configuration file from the package provided inpackage. The resulting configuration file is loaded after setting theexim_userandexim_groupconfiguration variables.
Почтовые сервисы
- Scheme Variable: getmail-service-type
This is the type of the Getmail mail retriever, whose value should be an
getmail-configuration.
Available getmail-configuration fields are:
getmail-configurationparameter: symbol name ¶A symbol to identify the getmail service.
Defaults to ‘"unset"’.
getmail-configurationparameter: package package ¶Используемый пакет getmail.
getmail-configurationparameter: string user ¶The user to run getmail as.
Defaults to ‘"getmail"’.
getmail-configurationparameter: string group ¶The group to run getmail as.
Defaults to ‘"getmail"’.
getmail-configurationparameter: string directory ¶The getmail directory to use.
Defaults to ‘"/var/lib/getmail/default"’.
getmail-configurationparameter: getmail-configuration-file rcfile ¶Используемый файл конфигурации getmail.
Available
getmail-configuration-filefields are:getmail-configuration-fileparameter: getmail-retriever-configuration retriever ¶What mail account to retrieve mail from, and how to access that account.
Available
getmail-retriever-configurationfields are:getmail-retriever-configurationparameter: string type ¶The type of mail retriever to use. Valid values include ‘passwd’ and ‘static’.
Defaults to ‘"SimpleIMAPSSLRetriever"’.
getmail-retriever-configurationparameter: string server ¶Username to login to the mail server with.
Defaults to ‘unset’.
getmail-retriever-configurationparameter: string username ¶Username to login to the mail server with.
Defaults to ‘unset’.
getmail-retriever-configurationparameter: non-negative-integer port ¶Port number to connect to.
Defaults to ‘#f’.
getmail-retriever-configurationparameter: string password ¶Override fields from passwd.
Defaults to ‘""’.
getmail-retriever-configurationparameter: list password-command ¶Override fields from passwd.
Defaults to ‘()’.
getmail-retriever-configurationparameter: string keyfile ¶PEM-formatted key file to use for the TLS negotiation.
Defaults to ‘""’.
getmail-retriever-configurationparameter: string certfile ¶PEM-formatted certificate file to use for the TLS negotiation.
Defaults to ‘""’.
getmail-retriever-configurationparameter: string ca-certs ¶Сертификаты CA для использования.
Defaults to ‘""’.
getmail-retriever-configurationparameter: parameter-alist extra-parameters ¶Extra retriever parameters.
Defaults to ‘()’.
getmail-configuration-fileparameter: getmail-destination-configuration destination ¶What to do with retrieved messages.
Available
getmail-destination-configurationfields are:getmail-destination-configurationparameter: string type ¶The type of mail destination. Valid values include ‘Maildir’, ‘Mboxrd’ and ‘MDA_external’.
Defaults to ‘unset’.
getmail-destination-configurationparameter: string-or-filelike path ¶The path option for the mail destination. The behaviour depends on the chosen type.
Defaults to ‘""’.
getmail-destination-configurationparameter: parameter-alist extra-parameters ¶Extra destination parameters
Defaults to ‘()’.
getmail-configuration-fileparameter: getmail-options-configuration options ¶Configure getmail.
Available
getmail-options-configurationfields are:getmail-options-configurationparameter: non-negative-integer verbose ¶If set to ‘0’, getmail will only print warnings and errors. A value of ‘1’ means that messages will be printed about retrieving and deleting messages. If set to ‘2’, getmail will print messages about each of its actions.
Defaults to ‘1’.
getmail-options-configurationparameter: boolean read-all ¶If true, getmail will retrieve all available messages. Otherwise it will only retrieve messages it hasn’t seen previously.
Defaults to ‘#t’.
getmail-options-configurationparameter: boolean delete ¶If set to true, messages will be deleted from the server after retrieving and successfully delivering them. Otherwise, messages will be left on the server.
Defaults to ‘#f’.
getmail-options-configurationparameter: non-negative-integer delete-after ¶Getmail will delete messages this number of days after seeing them, if they have been delivered. This means messages will be left on the server this number of days after delivering them. A value of ‘0’ disabled this feature.
Defaults to ‘0’.
getmail-options-configurationparameter: non-negative-integer delete-bigger-than ¶Delete messages larger than this of bytes after retrieving them, even if the delete and delete-after options are disabled. A value of ‘0’ disables this feature.
Defaults to ‘0’.
getmail-options-configurationparameter: non-negative-integer max-bytes-per-session ¶Retrieve messages totalling up to this number of bytes before closing the session with the server. A value of ‘0’ disables this feature.
Defaults to ‘0’.
getmail-options-configurationparameter: non-negative-integer max-message-size ¶Don’t retrieve messages larger than this number of bytes. A value of ‘0’ disables this feature.
Defaults to ‘0’.
getmail-options-configurationparameter: boolean delivered-to ¶If true, getmail will add a Delivered-To header to messages.
Defaults to ‘#t’.
getmail-options-configurationparameter: boolean received ¶If set, getmail adds a Received header to the messages.
Defaults to ‘#t’.
getmail-options-configurationparameter: string message-log ¶Getmail will record a log of its actions to the named file. A value of ‘""’ disables this feature.
Defaults to ‘""’.
getmail-options-configurationparameter: boolean message-log-syslog ¶If true, getmail will record a log of its actions using the system logger.
Defaults to ‘#f’.
getmail-options-configurationparameter: boolean message-log-verbose ¶If true, getmail will log information about messages not retrieved and the reason for not retrieving them, as well as starting and ending information lines.
Defaults to ‘#f’.
getmail-options-configurationparameter: parameter-alist extra-parameters ¶Extra options to include.
Defaults to ‘()’.
getmail-configurationparameter: list idle ¶A list of mailboxes that getmail should wait on the server for new mail notifications. This depends on the server supporting the IDLE extension.
Defaults to ‘()’.
getmail-configurationparameter: list environment-variables ¶Environment variables to set for getmail.
Defaults to ‘()’.
Mail Aliases Service
- Scheme Variable: mail-aliases-service-type
This is the type of the service which provides
/etc/aliases, specifying how to deliver mail to users on this system.(service mail-aliases-service-type '(("postmaster" "bob") ("bob" "bob@example.com" "bob@example2.com")))
The configuration for a mail-aliases-service-type service is an
association list denoting how to deliver mail that comes to this system.
Each entry is of the form (alias addresses ...), with alias
specifying the local alias and addresses specifying where to deliver
this user’s mail.
The aliases aren’t required to exist as users on the local system. In the
above example, there doesn’t need to be a postmaster entry in the
operating-system’s user-accounts in order to deliver the
postmaster mail to bob (which subsequently would deliver mail
to bob@example.com and bob@example2.com).
GNU Mailutils IMAP4 Daemon
- Scheme Variable: imap4d-service-type
This is the type of the GNU Mailutils IMAP4 Daemon (see imap4d in GNU Mailutils Manual), whose value should be an
imap4d-configurationobject as in this example:(service imap4d-service-type (imap4d-configuration (config-file (local-file "imap4d.conf"))))
- Data Type: imap4d-configuration
Data type representing the configuration of
imap4d.package(default:mailutils)The package that provides
imap4d.config-file(default:%default-imap4d-config-file)File-like object of the configuration file to use, by default it will listen on TCP port 143 of
localhost. See Conf-imap4d in GNU Mailutils Manual, for details.
Почтовые сервисы
- Процедура Scheme: sane-service-type
This is the type of the Radicale CalDAV/CardDAV server whose value should be a
radicale-configuration.
- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
speed(default:1.0)The package that provides
radicale.features(default:'())File-like object of the configuration file to use, by default it will listen on TCP port 5232 of
localhostand use thehtpasswdfile at /var/lib/radicale/users with no (plain) encryption.
Next: Сервисы телефонии, Previous: Почтовые сервисы, Up: Сервисы [Contents][Index]
12.9.13 Сервисы сообщений
Модуль (guix inferior) предоставляет следующие процедуры для работы с
ранними версиями:
Prosody Service
- Scheme Variable: prosody-service-type
This is the type for the Prosody XMPP communication server. Its value must be a
prosody-configurationrecord as in this example:(service prosody-service-type (prosody-configuration (modules-enabled (cons* "groups" "mam" %default-modules-enabled)) (int-components (list (int-component-configuration (hostname "conference.example.net") (plugin "muc") (mod-muc (mod-muc-configuration))))) (virtualhosts (list (virtualhost-configuration (domain "example.net"))))))See below for details about
prosody-configuration.
By default, Prosody does not need much configuration. Only one
virtualhosts field is needed: it specifies the domain you wish
Prosody to serve.
You can perform various sanity checks on the generated configuration with
the prosodyctl check command.
Prosodyctl will also help you to import certificates from the
letsencrypt directory so that the prosody user can access
them. See https://prosody.im/doc/letsencrypt.
prosodyctl --root cert import /etc/letsencrypt/live
The available configuration parameters follow. Each parameter definition is
preceded by its type; for example, ‘string-list foo’ indicates that the
foo parameter should be specified as a list of strings. Types
starting with maybe- denote parameters that won’t show up in
prosody.cfg.lua when their value is left unspecified.
There is also a way to specify the configuration as a string, if you have an
old prosody.cfg.lua file that you want to port over from some other
system; see the end for more details.
The file-object type designates either a file-like object
(see file-like objects) or a file name.
Available prosody-configuration fields are:
prosody-configurationparameter: package prosody ¶The Prosody package.
prosody-configurationparameter: file-name data-path ¶Location of the Prosody data storage directory. See https://prosody.im/doc/configure. Defaults to ‘"/var/lib/prosody"’.
prosody-configurationparameter: file-object-list plugin-paths ¶Additional plugin directories. They are searched in all the specified paths in order. See https://prosody.im/doc/plugins_directory. Defaults to ‘()’.
prosody-configurationparameter: file-name certificates ¶Every virtual host and component needs a certificate so that clients and servers can securely verify its identity. Prosody will automatically load certificates/keys from the directory specified here. Defaults to ‘"/etc/prosody/certs"’.
prosody-configurationparameter: string-list admins ¶This is a list of accounts that are admins for the server. Note that you must create the accounts separately. See https://prosody.im/doc/admins and https://prosody.im/doc/creating_accounts. Example:
(admins '("user1@example.com" "user2@example.net"))Defaults to ‘()’.
prosody-configurationparameter: boolean use-libevent? ¶Enable use of libevent for better performance under high load. See https://prosody.im/doc/libevent. Defaults to ‘#f’.
prosody-configurationparameter: module-list modules-enabled ¶This is the list of modules Prosody will load on startup. It looks for
mod_modulename.luain the plugins folder, so make sure that exists too. Documentation on modules can be found at: https://prosody.im/doc/modules. Defaults to ‘("roster" "saslauth" "tls" "dialback" "disco" "carbons" "private" "blocklist" "vcard" "version" "uptime" "time" "ping" "pep" "register" "admin_adhoc")’.
prosody-configurationparameter: string-list modules-disabled ¶‘"offline"’, ‘"c2s"’ and ‘"s2s"’ are auto-loaded, but should you want to disable them then add them to this list. Defaults to ‘()’.
prosody-configurationparameter: file-object groups-file ¶Path to a text file where the shared groups are defined. If this path is empty then ‘mod_groups’ does nothing. See https://prosody.im/doc/modules/mod_groups. Defaults to ‘"/var/lib/prosody/sharedgroups.txt"’.
prosody-configurationparameter: boolean allow-registration? ¶Disable account creation by default, for security. See https://prosody.im/doc/creating_accounts. Defaults to ‘#f’.
prosody-configurationparameter: maybe-ssl-configuration ssl ¶These are the SSL/TLS-related settings. Most of them are disabled so to use Prosody’s defaults. If you do not completely understand these options, do not add them to your config, it is easy to lower the security of your server using them. See https://prosody.im/doc/advanced_ssl_config.
Available
ssl-configurationfields are:ssl-configurationparameter: maybe-string protocol ¶This determines what handshake to use.
ssl-configurationparameter: maybe-file-name key ¶Path to your private key file.
ssl-configurationparameter: maybe-file-name certificate ¶Path to your certificate file.
ssl-configurationparameter: file-object capath ¶Path to directory containing root certificates that you wish Prosody to trust when verifying the certificates of remote servers. Defaults to ‘"/etc/ssl/certs"’.
ssl-configurationparameter: maybe-file-object cafile ¶Path to a file containing root certificates that you wish Prosody to trust. Similar to
capathbut with all certificates concatenated together.
ssl-configurationparameter: maybe-string-list verify ¶A list of verification options (these mostly map to OpenSSL’s
set_verify()flags).
ssl-configurationparameter: maybe-string-list options ¶A list of general options relating to SSL/TLS. These map to OpenSSL’s
set_options(). For a full list of options available in LuaSec, see the LuaSec source.
ssl-configurationparameter: maybe-non-negative-integer depth ¶How long a chain of certificate authorities to check when looking for a trusted root certificate.
ssl-configurationparameter: maybe-string ciphers ¶An OpenSSL cipher string. This selects what ciphers Prosody will offer to clients, and in what order.
ssl-configurationparameter: maybe-file-name dhparam ¶A path to a file containing parameters for Diffie-Hellman key exchange. You can create such a file with:
openssl dhparam -out /etc/prosody/certs/dh-2048.pem 2048
ssl-configurationparameter: maybe-string curve ¶Curve for Elliptic curve Diffie-Hellman. Prosody’s default is ‘"secp384r1"’.
ssl-configurationparameter: maybe-string-list verifyext ¶A list of “extra” verification options.
ssl-configurationparameter: maybe-string password ¶Password for encrypted private keys.
prosody-configurationparameter: boolean c2s-require-encryption? ¶Whether to force all client-to-server connections to be encrypted or not. See https://prosody.im/doc/modules/mod_tls. Defaults to ‘#f’.
prosody-configurationparameter: string-list disable-sasl-mechanisms ¶Set of mechanisms that will never be offered. See https://prosody.im/doc/modules/mod_saslauth. Defaults to ‘("DIGEST-MD5")’.
prosody-configurationparameter: boolean s2s-require-encryption? ¶Whether to force all server-to-server connections to be encrypted or not. See https://prosody.im/doc/modules/mod_tls. Defaults to ‘#f’.
prosody-configurationparameter: boolean s2s-secure-auth? ¶Whether to require encryption and certificate authentication. This provides ideal security, but requires servers you communicate with to support encryption AND present valid, trusted certificates. See https://prosody.im/doc/s2s#security. Defaults to ‘#f’.
prosody-configurationparameter: string-list s2s-insecure-domains ¶Many servers don’t support encryption or have invalid or self-signed certificates. You can list domains here that will not be required to authenticate using certificates. They will be authenticated using DNS. See https://prosody.im/doc/s2s#security. Defaults to ‘()’.
prosody-configurationparameter: string-list s2s-secure-domains ¶Even if you leave
s2s-secure-auth?disabled, you can still require valid certificates for some domains by specifying a list here. See https://prosody.im/doc/s2s#security. Defaults to ‘()’.
prosody-configurationparameter: string authentication ¶Select the authentication backend to use. The default provider stores passwords in plaintext and uses Prosody’s configured data storage to store the authentication data. If you do not trust your server please see https://prosody.im/doc/modules/mod_auth_internal_hashed for information about using the hashed backend. See also https://prosody.im/doc/authentication Defaults to ‘"internal_plain"’.
prosody-configurationparameter: maybe-string log ¶Set logging options. Advanced logging configuration is not yet supported by the Prosody service. See https://prosody.im/doc/logging. Defaults to ‘"*syslog"’.
prosody-configurationparameter: file-name pidfile ¶File to write pid in. See https://prosody.im/doc/modules/mod_posix. Defaults to ‘"/var/run/prosody/prosody.pid"’.
prosody-configurationparameter: maybe-non-negative-integer http-max-content-size ¶Maximum allowed size of the HTTP body (in bytes).
prosody-configurationparameter: maybe-string http-external-url ¶Some modules expose their own URL in various ways. This URL is built from the protocol, host and port used. If Prosody sits behind a proxy, the public URL will be
http-external-urlinstead. See https://prosody.im/doc/http#external_url.
prosody-configurationparameter: virtualhost-configuration-list virtualhosts ¶A host in Prosody is a domain on which user accounts can be created. For example if you want your users to have addresses like ‘"john.smith@example.com"’ then you need to add a host ‘"example.com"’. All options in this list will apply only to this host.
Примечание: The name virtual host is used in configuration to avoid confusion with the actual physical host that Prosody is installed on. A single Prosody instance can serve many domains, each one defined as a VirtualHost entry in Prosody’s configuration. Conversely a server that hosts a single domain would have just one VirtualHost entry.
Available
virtualhost-configurationfields are:all these
prosody-configurationfields:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, plus:virtualhost-configurationparameter: string domain ¶Domain you wish Prosody to serve.
prosody-configurationparameter: int-component-configuration-list int-components ¶Components are extra services on a server which are available to clients, usually on a subdomain of the main server (such as ‘"mycomponent.example.com"’). Example components might be chatroom servers, user directories, or gateways to other protocols.
Internal components are implemented with Prosody-specific plugins. To add an internal component, you simply fill the hostname field, and the plugin you wish to use for the component.
See https://prosody.im/doc/components. Defaults to ‘()’.
Available
int-component-configurationfields are:all these
prosody-configurationfields:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, plus:int-component-configurationparameter: string hostname ¶Hostname of the component.
int-component-configurationparameter: string plugin ¶Plugin you wish to use for the component.
int-component-configurationparameter: maybe-mod-muc-configuration mod-muc ¶Multi-user chat (MUC) is Prosody’s module for allowing you to create hosted chatrooms/conferences for XMPP users.
General information on setting up and using multi-user chatrooms can be found in the “Chatrooms” documentation (https://prosody.im/doc/chatrooms), which you should read if you are new to XMPP chatrooms.
See also https://prosody.im/doc/modules/mod_muc.
Available
mod-muc-configurationfields are:mod-muc-configurationparameter: string name ¶The name to return in service discovery responses. Defaults to ‘"Prosody Chatrooms"’.
mod-muc-configurationparameter: string-or-boolean restrict-room-creation ¶If ‘#t’, this will only allow admins to create new chatrooms. Otherwise anyone can create a room. The value ‘"local"’ restricts room creation to users on the service’s parent domain. E.g. ‘user@example.com’ can create rooms on ‘rooms.example.com’. The value ‘"admin"’ restricts to service administrators only. Defaults to ‘#f’.
mod-muc-configurationparameter: non-negative-integer max-history-messages ¶Maximum number of history messages that will be sent to the member that has just joined the room. Defaults to ‘20’.
prosody-configurationparameter: ext-component-configuration-list ext-components ¶External components use XEP-0114, which most standalone components support. To add an external component, you simply fill the hostname field. See https://prosody.im/doc/components. Defaults to ‘()’.
Available
ext-component-configurationfields are:all these
prosody-configurationfields:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, plus:ext-component-configurationparameter: string component-secret ¶Password which the component will use to log in.
ext-component-configurationparameter: string hostname ¶Hostname of the component.
prosody-configurationparameter: non-negative-integer-list component-ports ¶Port(s) Prosody listens on for component connections. Defaults to ‘(5347)’.
prosody-configurationparameter: string component-interface ¶Interface Prosody listens on for component connections. Defaults to ‘"127.0.0.1"’.
prosody-configurationparameter: maybe-raw-content raw-content ¶Raw content that will be added to the configuration file.
It could be that you just want to get a prosody.cfg.lua up and
running. In that case, you can pass an opaque-prosody-configuration
record as the value of prosody-service-type. As its name indicates,
an opaque configuration does not have easy reflective capabilities.
Available opaque-prosody-configuration fields are:
opaque-prosody-configurationparameter: package prosody ¶The prosody package.
opaque-prosody-configurationparameter: string prosody.cfg.lua ¶The contents of the
prosody.cfg.luato use.
For example, if your prosody.cfg.lua is just the empty string, you
could instantiate a prosody service like this:
(service prosody-service-type
(opaque-prosody-configuration
(prosody.cfg.lua "")))
BitlBee Service
BitlBee is a gateway that provides an IRC interface to a variety of messaging protocols such as XMPP.
- Scheme Variable: bitlbee-service-type
This is the service type for the BitlBee IRC gateway daemon. Its value is a
bitlbee-configuration(see below).To have BitlBee listen on port 6667 on localhost, add this line to your services:
- Data Type: bitlbee-configuration
This is the configuration for BitlBee, with the following fields:
interface(default:"127.0.0.1")port(default:6667)Listen on the network interface corresponding to the IP address specified in interface, on port.
When interface is
127.0.0.1, only local clients can connect; when it is0.0.0.0, connections can come from any networking interface.port(default:22)The BitlBee package to use.
plugins(default:'())List of plugin packages to use—e.g.,
bitlbee-discord.extra-settings(default:"")Configuration snippet added as-is to the BitlBee configuration file.
Quassel Service
Quassel is a distributed IRC client, meaning that one or more clients can attach to and detach from the central core.
- Scheme Variable: quassel-service-type
This is the service type for the Quassel IRC backend daemon. Its value is a
quassel-configuration(see below).
- Data Type: quassel-configuration
This is the configuration for Quassel, with the following fields:
quassel(default:quassel)The Quassel package to use.
interface(default:"::,0.0.0.0")port(default:4242)Listen on the network interface(s) corresponding to the IPv4 or IPv6 interfaces specified in the comma delimited interface, on port.
loglevel(default:"Info")The level of logging desired. Accepted values are Debug, Info, Warning and Error.
Next: File-Sharing Services, Previous: Сервисы сообщений, Up: Сервисы [Contents][Index]
12.9.14 Сервисы телефонии
The (gnu services telephony) module contains Guix service definitions
for telephony services. Currently it provides the following services:
Jami
This section describes how to configure a Jami server that can be used to host video (or audio) conferences, among other uses. The following example demonstrates how to specify Jami account archives (backups) to be provisioned automatically:
(service jami-service-type
(jami-configuration
(accounts
(list (jami-account
(archive "/etc/jami/unencrypted-account-1.gz"))
(jami-account
(archive "/etc/jami/unencrypted-account-2.gz"))))))
When the accounts field is specified, the Jami account files of the service found under /var/lib/jami are recreated every time the service starts.
Jami accounts and their corresponding backup archives can be generated using
the jami or jami-gnome Jami clients. The accounts should not
be password-protected, but it is wise to ensure their files are only
readable by ‘root’.
The next example shows how to declare that only some contacts should be allowed to communicate with a given account:
(service jami-service-type
(jami-configuration
(accounts
(list (jami-account
(archive "/etc/jami/unencrypted-account-1.gz")
(peer-discovery? #t)
(rendezvous-point? #t)
(allowed-contacts
'("1dbcb0f5f37324228235564b79f2b9737e9a008f"
"2dbcb0f5f37324228235564b79f2b9737e9a008f")))))))
In this mode, only the declared allowed-contacts can initiate
communication with the Jami account. This can be used, for example, with
rendezvous point accounts to create a private video conferencing space.
To put the system administrator in full control of the conferences hosted on their system, the Jami service supports the following actions:
# herd doc jami list-actions (list-accounts list-account-details list-banned-contacts list-contacts list-moderators add-moderator ban-contact enable-account disable-account)
The above actions aim to provide the most valuable actions for moderation
purposes, not to cover the whole Jami API. Users wanting to interact with
the Jami daemon from Guile may be interested in experimenting with the
(gnu build jami-service) module, which powers the above Shepherd
actions.
The add-moderator and ban-contact actions accept a contact
fingerprint (40 characters long hash) as first argument and an
account fingerprint or username as second argument:
# herd add-moderator jami 1dbcb0f5f37324228235564b79f2b9737e9a008f \ f3345f2775ddfe07a4b0d95daea111d15fbc1199 # herd list-moderators jami Moderators for account f3345f2775ddfe07a4b0d95daea111d15fbc1199: - 1dbcb0f5f37324228235564b79f2b9737e9a008f
In the case of ban-contact, the second username argument is optional;
when omitted, the account is banned from all Jami accounts:
# herd ban-contact jami 1dbcb0f5f37324228235564b79f2b9737e9a008f # herd list-banned-contacts jami Banned contacts for account f3345f2775ddfe07a4b0d95daea111d15fbc1199: - 1dbcb0f5f37324228235564b79f2b9737e9a008f
Banned contacts are also stripped from their moderation privileges.
The disable-account action allows to completely disconnect an account
from the network, making it unreachable, while enable-account does
the inverse. They accept a single account username or fingerprint as first
argument:
# herd disable-account jami f3345f2775ddfe07a4b0d95daea111d15fbc1199 # herd list-accounts jami The following Jami accounts are available: - f3345f2775ddfe07a4b0d95daea111d15fbc1199 (dummy) [disabled]
The list-account-details action prints the detailed parameters of
each accounts in the Recutils format, which means the recsel
command can be used to select accounts of interest (see Selection
Expressions in GNU recutils manual). Note that period characters
(‘.’) found in the account parameter keys are mapped to underscores
(‘_’) in the output, to meet the requirements of the Recutils format.
The following example shows how to print the account fingerprints for all
accounts operating in the rendezvous point mode:
# herd list-account-details jami | \ recsel -p Account.username -e 'Account.rendezVous ~ "true"' Account_username: f3345f2775ddfe07a4b0d95daea111d15fbc1199
The remaining actions should be self-explanatory.
The complete set of available configuration options is detailed below.
- Data Type: jami-configuration
Available
jami-configurationfields are:libjami(default:libjami) (type: package)The Jami daemon package to use.
dbus(default:dbus-for-jami) (type: package)The D-Bus package to use to start the required D-Bus session.
nss-certs(default:nss-certs) (type: package)The nss-certs package to use to provide TLS certificates.
enable-logging?(default:#t) (type: boolean)Whether to enable logging to syslog.
debug?(default:#f) (type: boolean)Whether to enable debug level messages.
auto-answer?(default:#f) (type: boolean)Whether to force automatic answer to incoming calls.
accounts(type: maybe-jami-account-list)A list of Jami accounts to be (re-)provisioned every time the Jami daemon service starts. When providing this field, the account directories under /var/lib/jami/ are recreated every time the service starts, ensuring a consistent state.
- Data Type: jami-account
Available
jami-accountfields are:archive(type: string-or-computed-file)The account archive (backup) file name of the account. This is used to provision the account when the service starts. The account archive should not be encrypted. It is highly recommended to make it readable only to the ‘root’ user (i.e., not in the store), to guard against leaking the secret key material of the Jami account it contains.
allowed-contacts(type: maybe-account-fingerprint-list)The list of allowed contacts for the account, entered as their 40 characters long fingerprint. Messages or calls from accounts not in that list will be rejected. When left specified, the configuration of the account archive is used as-is with respect to contacts and public inbound calls/messaging allowance, which typically defaults to allow any contact to communicate with the account.
moderators(type: maybe-account-fingerprint-list)The list of contacts that should have moderation privileges (to ban, mute, etc. other users) in rendezvous conferences, entered as their 40 characters long fingerprint. When left unspecified, the configuration of the account archive is used as-is with respect to moderation, which typically defaults to allow anyone to moderate.
rendezvous-point?(type: maybe-boolean)Whether the account should operate in the rendezvous mode. In this mode, all the incoming audio/video calls are mixed into a conference. When left unspecified, the value from the account archive prevails.
peer-discovery?(type: maybe-boolean)Whether peer discovery should be enabled. Peer discovery is used to discover other OpenDHT nodes on the local network, which can be useful to maintain communication between devices on such network even when the connection to the Internet has been lost. When left unspecified, the value from the account archive prevails.
bootstrap-hostnames(type: maybe-string-list)A list of hostnames or IPs pointing to OpenDHT nodes, that should be used to initially join the OpenDHT network. When left unspecified, the value from the account archive prevails.
name-server-uri(type: maybe-string)The URI of the name server to use, that can be used to retrieve the account fingerprint for a registered username.
Mumble server
This section describes how to set up and run a Mumble server (formerly known as Murmur).
- Data Type: mumble-server-configuration
The service type for the Mumble server. An example configuration can look like this:
(service mumble-server-service-type (mumble-server-configuration (welcome-text "Welcome to this Mumble server running on Guix!") (cert-required? #t) ;disallow text password logins (ssl-cert "/etc/letsencrypt/live/mumble.example.com/fullchain.pem") (ssl-key "/etc/letsencrypt/live/mumble.example.com/privkey.pem")))After reconfiguring your system, you can manually set the mumble-server
SuperUserpassword with the command that is printed during the activation phase.It is recommended to register a normal Mumble user account and grant it admin or moderator rights. You can use the
mumbleclient to login as new normal user, register yourself, and log out. For the next step login with the nameSuperUseruse theSuperUserpassword that you set previously, and grant your newly registered mumble user administrator or moderator rights and create some channels.Available
mumble-server-configurationfields are:package(default:mumble)Package that contains
bin/mumble-server.user(default:"mumble-server")User who will run the Mumble-Server server.
group(default:"mumble-server")Group of the user who will run the mumble-server server.
port(default:64738)Port on which the server will listen.
welcome-text(default:"")Welcome text sent to clients when they connect.
server-password(default:"")Password the clients have to enter in order to connect.
max-users(default:100)Maximum of users that can be connected to the server at once.
max-user-bandwidth(default:#f)Maximum voice traffic a user can send per second.
database-file(default:"/var/lib/mumble-server/db.sqlite")File name of the sqlite database. The service’s user will become the owner of the directory.
log-file(default:"/var/log/mumble-server/mumble-server.log")File name of the log file. The service’s user will become the owner of the directory.
autoban-attempts(default:10)Maximum number of logins a user can make in
autoban-timeframewithout getting auto banned forautoban-time.autoban-timeframe(default:120)Timeframe for autoban in seconds.
autoban-time(default:300)Amount of time in seconds for which a client gets banned when violating the autoban limits.
opus-threshold(default:100)Percentage of clients that need to support opus before switching over to opus audio codec.
channel-nesting-limit(default:10)How deep channels can be nested at maximum.
channelname-regex(default:#f)A string in form of a Qt regular expression that channel names must conform to.
username-regex(default:#f)A string in form of a Qt regular expression that user names must conform to.
text-message-length(default:5000)Maximum size in bytes that a user can send in one text chat message.
image-message-length(default:(* 128 1024))Maximum size in bytes that a user can send in one image message.
cert-required?(default:#f)If it is set to
#tclients that use weak password authentication will not be accepted. Users must have completed the certificate wizard to join.remember-channel?(default:#f)Should mumble-server remember the last channel each user was in when they disconnected and put them into the remembered channel when they rejoin.
allow-html?(default:#f)Should html be allowed in text messages, user comments, and channel descriptions.
allow-ping?(default:#f)Setting to true exposes the current user count, the maximum user count, and the server’s maximum bandwidth per client to unauthenticated users. In the Mumble client, this information is shown in the Connect dialog.
Disabling this setting will prevent public listing of the server.
bonjour?(default:#f)Should the server advertise itself in the local network through the bonjour protocol.
send-version?(default:#f)Should the mumble-server server version be exposed in ping requests.
log-days(default:31)Mumble also stores logs in the database, which are accessible via RPC. The default is 31 days of months, but you can set this setting to 0 to keep logs forever, or -1 to disable logging to the database.
obfuscate-ips?(default:#t)Should logged ips be obfuscated to protect the privacy of users.
ssl-cert(default:#f)File name of the SSL/TLS certificate used for encrypted connections.
(ssl-cert "/etc/letsencrypt/live/example.com/fullchain.pem")ssl-key(default:#f)Filepath to the ssl private key used for encrypted connections.
(ssl-key "/etc/letsencrypt/live/example.com/privkey.pem")ssl-dh-params(default:#f)File name of a PEM-encoded file with Diffie-Hellman parameters for the SSL/TLS encryption. Alternatively you set it to
"@ffdhe2048","@ffdhe3072","@ffdhe4096","@ffdhe6144"or"@ffdhe8192"to use bundled parameters from RFC 7919.ssl-ciphers(default:#f)The
ssl-ciphersoption chooses the cipher suites to make available for use in SSL/TLS.This option is specified using OpenSSL cipher list notation.
It is recommended that you try your cipher string using ’openssl ciphers <string>’ before setting it here, to get a feel for which cipher suites you will get. After setting this option, it is recommend that you inspect your Mumble server log to ensure that Mumble is using the cipher suites that you expected it to.
Примечание: Changing this option may impact the backwards compatibility of your Mumble-Server server, and can remove the ability for older Mumble clients to be able to connect to it.
public-registration(default:#f)Must be a
<mumble-server-public-registration-configuration>record or#f.You can optionally register your server in the public server list that the
mumbleclient shows on startup. You cannot register your server if you have set aserver-password, or setallow-pingto#f.It might take a few hours until it shows up in the public list.
file(default:#f)Optional alternative override for this configuration.
- Data Type: mumble-server-public-registration-configuration
Configuration for public registration of a mumble-server service.
nameThis is a display name for your server. Not to be confused with the hostname.
passwordA password to identify your registration. Subsequent updates will need the same password. Don’t lose your password.
urlThis should be a
http://orhttps://link to your web site.hostname(default:#f)By default your server will be listed by its IP address. If it is set your server will be linked by this host name instead.
Deprecation notice: Due to historical reasons, all of the above
mumble-server-procedures are also exported with themurmur-prefix. It is recommended that you switch to usingmumble-server-going forward.
Next: Сервисы мониторинга, Previous: Сервисы телефонии, Up: Сервисы [Contents][Index]
12.9.15 File-Sharing Services
Модуль (gnu services file-sharing) предоставляет следующие сервисы,
помогающие с передачей файлов через одноранговые сети.
Сервисы упраления версиями
Transmission is a flexible BitTorrent
client that offers a variety of graphical and command-line interfaces. A
transmission-daemon-service-type service provides Transmission’s
headless variant, transmission-daemon, as a system service,
allowing users to share files via BitTorrent even when they are not logged
in.
- Процедура Scheme: sane-service-type
The service type for the Transmission Daemon BitTorrent client. Its value must be a
transmission-daemon-configurationobject as in this example:(service transmission-daemon-service-type (transmission-daemon-configuration ;; Restrict access to the RPC ("control") interface (rpc-authentication-required? #t) (rpc-username "transmission") (rpc-password (transmission-password-hash "transmission" ; desired password "uKd1uMs9")) ; arbitrary salt value ;; Accept requests from this and other hosts on the ;; local network (rpc-whitelist-enabled? #t) (rpc-whitelist '("::1" "127.0.0.1" "192.168.0.*")) ;; Limit bandwidth use during work hours (alt-speed-down (* 1024 2)) ; 2 MB/s (alt-speed-up 512) ; 512 kB/s (alt-speed-time-enabled? #t) (alt-speed-time-day 'weekdays) (alt-speed-time-begin (+ (* 60 8) 30)) ; 8:30 am (alt-speed-time-end (+ (* 60 (+ 12 5)) 30)))) ; 5:30 pm
Once the service is started, users can interact with the daemon through its
Web interface (at http://localhost:9091/) or by using the
transmission-remote command-line tool, available in the
transmission package. (Emacs users may want to also consider the
emacs-transmission package.) Both communicate with the daemon
through its remote procedure call (RPC) interface, which by default is
available to all users on the system; you may wish to change this by
assigning values to the rpc-authentication-required?,
rpc-username and rpc-password settings, as shown in the
example above and documented further below.
The value for rpc-password must be a password hash of the type
generated and used by Transmission clients. This can be copied verbatim
from an existing settings.json file, if another Transmission client
is already being used. Otherwise, the transmission-password-hash and
transmission-random-salt procedures provided by this module can be
used to obtain a suitable hash value.
- Процедура Scheme: lookup-inferior-packages inferior name Returns a string containing the result of hashing password together
with salt, in the format recognized by Transmission clients for their
rpc-passwordconfiguration setting.salt must be an eight-character string. The
transmission-random-saltprocedure can be used to generate a suitable salt value at random.
- Процедура Scheme: open-inferior directory Returns a string containing a random, eight-character salt value of the type
generated and used by Transmission clients, suitable for passing to the
transmission-password-hashprocedure.
These procedures are accessible from within a Guile REPL started with the
guix repl command (see Вызов guix repl). This is useful
for obtaining a random salt value to provide as the second parameter to
‘transmission-password-hash‘, as in this example session:
$ guix repl scheme@(guix-user)> ,use (gnu services file-sharing) scheme@(guix-user)> (transmission-random-salt) $1 = "uKd1uMs9"
Alternatively, a complete password hash can generated in a single step:
scheme@(guix-user)> (transmission-password-hash "transmission"
(transmission-random-salt))
$2 = "{c8bbc6d1740cd8dc819a6e25563b67812c1c19c9VtFPfdsX"
The resulting string can be used as-is for the value of rpc-password,
allowing the password to be kept hidden even in the operating-system
configuration.
Torrent files downloaded by the daemon are directly accessible only to users
in the “transmission” user group, who receive read-only access to the
directory specified by the download-dir configuration setting (and
also the directory specified by incomplete-dir, if
incomplete-dir-enabled? is #t). Downloaded files can be moved
to another directory or deleted altogether using
transmission-remote with its --move and
--remove-and-delete options.
If the watch-dir-enabled? setting is set to #t, users in the
“transmission” group are able also to place .torrent files in the
directory specified by watch-dir to have the corresponding torrents
added by the daemon. (The trash-original-torrent-files? setting
controls whether the daemon deletes these files after processing them.)
Some of the daemon’s configuration settings can be changed temporarily by
transmission-remote and similar tools. To undo these changes, use
the service’s reload action to have the daemon reload its settings
from disk:
herd start ssh-daemon
The full set of available configuration settings is defined by the
transmission-daemon-configuration data type.
- Тип данных: build-machine
The data type representing configuration settings for Transmission Daemon. These correspond directly to the settings recognized by Transmission clients in their settings.json file.
Available transmission-daemon-configuration fields are:
transmission-daemon-configurationparameter: package transmission ¶Используемый пакет nfs-utils.
transmission-daemon-configurationparameter: non-negative-integer stop-wait-period ¶The period, in seconds, to wait when stopping the service for
transmission-daemonto exit before killing its process. This allows the daemon time to complete its housekeeping and send a final update to trackers as it shuts down. On slow hosts, or hosts with a slow network connection, this value may need to be increased.Defaults to ‘10’.
transmission-daemon-configurationparameter: string download-dir ¶The directory to which torrent files are downloaded.
Defaults to ‘"/var/lib/transmission-daemon/downloads"’.
transmission-daemon-configurationparameter: boolean incomplete-dir-enabled? ¶If
#t, files will be held inincomplete-dirwhile their torrent is being downloaded, then moved todownload-dironce the torrent is complete. Otherwise, files for all torrents (including those still being downloaded) will be placed indownload-dir.Defaults to ‘#f’.
transmission-daemon-configurationparameter: maybe-string incomplete-dir ¶The directory in which files from incompletely downloaded torrents will be held when
incomplete-dir-enabled?is#t.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: umask umask ¶The file mode creation mask used for downloaded files. (See the
umaskman page for more information.)Defaults to ‘18’.
transmission-daemon-configurationparameter: boolean rename-partial-files? ¶When
#t, “.part” is appended to the name of partially downloaded files.Defaults to ‘#t’.
transmission-daemon-configurationparameter: preallocation-mode preallocation ¶The mode by which space should be preallocated for downloaded files, one of
none,fast(orsparse) andfull. Specifyingfullwill minimize disk fragmentation at a cost to file-creation speed.Defaults to ‘fast’.
transmission-daemon-configurationparameter: boolean watch-dir-enabled? ¶If
#t, the directory specified bywatch-dirwill be watched for new .torrent files and the torrents they describe added automatically (and the original files removed, iftrash-original-torrent-files?is#t).Defaults to ‘#f’.
transmission-daemon-configurationparameter: maybe-string watch-dir ¶The directory to be watched for .torrent files indicating new torrents to be added, when
watch-dir-enabledis#t.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: boolean trash-original-torrent-files? ¶When
#t, .torrent files will be deleted from the watch directory once their torrent has been added (seewatch-directory-enabled?).Defaults to ‘#f’.
transmission-daemon-configurationparameter: boolean speed-limit-down-enabled? ¶When
#t, the daemon’s download speed will be limited to the rate specified byspeed-limit-down.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-integer speed-limit-down ¶The default global-maximum download speed, in kilobytes per second.
Defaults to ‘100’.
transmission-daemon-configurationparameter: boolean speed-limit-up-enabled? ¶When
#t, the daemon’s upload speed will be limited to the rate specified byspeed-limit-up.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-integer speed-limit-up ¶The default global-maximum upload speed, in kilobytes per second.
Defaults to ‘100’.
transmission-daemon-configurationparameter: boolean alt-speed-enabled? ¶When
#t, the alternate speed limitsalt-speed-downandalt-speed-upare used (in place ofspeed-limit-downandspeed-limit-up, if they are enabled) to constrain the daemon’s bandwidth usage. This can be scheduled to occur automatically at certain times during the week; seealt-speed-time-enabled?.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-down ¶The alternate global-maximum download speed, in kilobytes per second.
Defaults to ‘50’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-up ¶The alternate global-maximum upload speed, in kilobytes per second.
Defaults to ‘50’.
transmission-daemon-configurationparameter: boolean alt-speed-time-enabled? ¶When
#t, the alternate speed limitsalt-speed-downandalt-speed-upwill be enabled automatically during the periods specified byalt-speed-time-day,alt-speed-time-beginandalt-time-speed-end.Defaults to ‘#f’.
transmission-daemon-configurationparameter: day-list alt-speed-time-day ¶The days of the week on which the alternate-speed schedule should be used, specified either as a list of days (
sunday,monday, and so on) or using one of the symbolsweekdays,weekendsorall.Defaults to ‘all’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-time-begin ¶The time of day at which to enable the alternate speed limits, expressed as a number of minutes since midnight.
Defaults to ‘540’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-time-end ¶The time of day at which to disable the alternate speed limits, expressed as a number of minutes since midnight.
Defaults to ‘1020’.
transmission-daemon-configurationparameter: string bind-address-ipv4 ¶The IP address at which to listen for peer connections, or “0.0.0.0” to listen at all available IP addresses.
Defaults to ‘"0.0.0.0"’.
transmission-daemon-configurationparameter: string bind-address-ipv6 ¶The IPv6 address at which to listen for peer connections, or “::” to listen at all available IPv6 addresses.
Defaults to ‘"::"’.
transmission-daemon-configurationparameter: boolean peer-port-random-on-start? ¶If
#t, when the daemon starts it will select a port at random on which to listen for peer connections, from the range specified (inclusively) bypeer-port-random-lowandpeer-port-random-high. Otherwise, it listens on the port specified bypeer-port.Defaults to ‘#f’.
transmission-daemon-configurationparameter: port-number peer-port-random-low ¶The lowest selectable port number when
peer-port-random-on-start?is#t.Defaults to ‘49152’.
transmission-daemon-configurationparameter: port-number peer-port-random-high ¶The highest selectable port number when
peer-port-random-on-startis#t.Defaults to ‘65535’.
transmission-daemon-configurationparameter: port-number peer-port ¶The port on which to listen for peer connections when
peer-port-random-on-start?is#f.Defaults to ‘51413’.
transmission-daemon-configurationparameter: boolean port-forwarding-enabled? ¶If
#t, the daemon will attempt to configure port-forwarding on an upstream gateway automatically using UPnP and NAT-PMP.Defaults to ‘#t’.
transmission-daemon-configurationparameter: encryption-mode encryption ¶The encryption preference for peer connections, one of
prefer-unencrypted-connections,prefer-encrypted-connectionsorrequire-encrypted-connections.Defaults to ‘prefer-encrypted-connections’.
transmission-daemon-configurationparameter: maybe-string peer-congestion-algorithm ¶The TCP congestion-control algorithm to use for peer connections, specified using a string recognized by the operating system in calls to
setsockopt. When left unspecified, the operating-system default is used.Note that on GNU/Linux systems, the kernel must be configured to allow processes to use a congestion-control algorithm not in the default set; otherwise, it will deny these requests with “Operation not permitted”. To see which algorithms are available on your system and which are currently permitted for use, look at the contents of the files tcp_available_congestion_control and tcp_allowed_congestion_control in the /proc/sys/net/ipv4 directory.
As an example, to have Transmission Daemon use the TCP Low Priority congestion-control algorithm, you’ll need to modify your kernel configuration to build in support for the algorithm, then update your operating-system configuration to allow its use by adding a
sysctl-service-typeservice (or updating the existing one’s configuration) with lines like the following:(service cups-service-type (cups-configuration (web-interface? #t) (extensions (list cups-filters epson-inkjet-printer-escpr hplip-minimal))))The Transmission Daemon configuration can then be updated with
(peer-congestion-algorithm "lp")and the system reconfigured to have the changes take effect.
Defaults to ‘disabled’.
transmission-daemon-configurationparameter: tcp-type-of-service peer-socket-tos ¶The type of service to request in outgoing TCP packets, one of
default,low-cost,throughput,low-delayandreliability.Defaults to ‘default’.
transmission-daemon-configurationparameter: non-negative-integer peer-limit-global ¶The global limit on the number of connected peers.
Defaults to ‘200’.
transmission-daemon-configurationparameter: non-negative-integer peer-limit-per-torrent ¶The per-torrent limit on the number of connected peers.
Defaults to ‘50’.
transmission-daemon-configurationparameter: non-negative-integer upload-slots-per-torrent ¶The maximum number of peers to which the daemon will upload data simultaneously for each torrent.
Defaults to ‘14’.
transmission-daemon-configurationparameter: non-negative-integer peer-id-ttl-hours ¶The maximum lifespan, in hours, of the peer ID associated with each public torrent before it is regenerated.
Defaults to ‘6’.
transmission-daemon-configurationparameter: boolean blocklist-enabled? ¶When
#t, the daemon will ignore peers mentioned in the blocklist it has most recently downloaded fromblocklist-url.Defaults to ‘#f’.
transmission-daemon-configurationparameter: maybe-string blocklist-url ¶The URL of a peer blocklist (in P2P-plaintext or eMule .dat format) to be periodically downloaded and applied when
blocklist-enabled?is#t.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: boolean download-queue-enabled? ¶If
#t, the daemon will be limited to downloading at mostdownload-queue-sizenon-stalled torrents simultaneously.Defaults to ‘#t’.
transmission-daemon-configurationparameter: non-negative-integer download-queue-size ¶The size of the daemon’s download queue, which limits the number of non-stalled torrents it will download at any one time when
download-queue-enabled?is#t.Defaults to ‘5’.
transmission-daemon-configurationparameter: boolean seed-queue-enabled? ¶If
#t, the daemon will be limited to seeding at mostseed-queue-sizenon-stalled torrents simultaneously.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-integer seed-queue-size ¶The size of the daemon’s seed queue, which limits the number of non-stalled torrents it will seed at any one time when
seed-queue-enabled?is#t.Defaults to ‘10’.
transmission-daemon-configurationparameter: boolean queue-stalled-enabled? ¶When
#t, the daemon will consider torrents for which it has not shared data in the pastqueue-stalled-minutesminutes to be stalled and not count them against itsdownload-queue-sizeandseed-queue-sizelimits.Defaults to ‘#t’.
transmission-daemon-configurationparameter: non-negative-integer queue-stalled-minutes ¶The maximum period, in minutes, a torrent may be idle before it is considered to be stalled, when
queue-stalled-enabled?is#t.Defaults to ‘30’.
transmission-daemon-configurationparameter: boolean ratio-limit-enabled? ¶When
#t, a torrent being seeded will automatically be paused once it reaches the ratio specified byratio-limit.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-rational ratio-limit ¶The ratio at which a torrent being seeded will be paused, when
ratio-limit-enabled?is#t.Defaults to ‘2.0’.
transmission-daemon-configurationparameter: boolean idle-seeding-limit-enabled? ¶When
#t, a torrent being seeded will automatically be paused once it has been idle foridle-seeding-limitminutes.Defaults to ‘#f’.
transmission-daemon-configurationparameter: non-negative-integer idle-seeding-limit ¶The maximum period, in minutes, a torrent being seeded may be idle before it is paused, when
idle-seeding-limit-enabled?is#t.Defaults to ‘30’.
transmission-daemon-configurationparameter: boolean dht-enabled? ¶Enable the distributed hash table (DHT) protocol, which supports the use of trackerless torrents.
Defaults to ‘#t’.
transmission-daemon-configurationparameter: boolean lpd-enabled? ¶Enable local peer discovery (LPD), which allows the discovery of peers on the local network and may reduce the amount of data sent over the public Internet.
Defaults to ‘#f’.
transmission-daemon-configurationparameter: boolean pex-enabled? ¶Enable peer exchange (PEX), which reduces the daemon’s reliance on external trackers and may improve its performance.
Defaults to ‘#t’.
transmission-daemon-configurationparameter: boolean utp-enabled? ¶Enable the micro transport protocol (uTP), which aims to reduce the impact of BitTorrent traffic on other users of the local network while maintaining full utilization of the available bandwidth.
Defaults to ‘#t’.
transmission-daemon-configurationparameter: boolean rpc-enabled? ¶If
#t, enable the remote procedure call (RPC) interface, which allows remote control of the daemon via its Web interface, thetransmission-remotecommand-line client, and similar tools.Defaults to ‘#t’.
transmission-daemon-configurationparameter: string rpc-bind-address ¶The IP address at which to listen for RPC connections, or “0.0.0.0” to listen at all available IP addresses.
Defaults to ‘"0.0.0.0"’.
transmission-daemon-configurationparameter: port-number rpc-port ¶The port on which to listen for RPC connections.
Defaults to ‘9091’.
transmission-daemon-configurationparameter: string rpc-url ¶The path prefix to use in the RPC-endpoint URL.
Defaults to ‘"/transmission/"’.
transmission-daemon-configurationparameter: boolean rpc-authentication-required? ¶When
#t, clients must authenticate (seerpc-usernameandrpc-password) when using the RPC interface. Note this has the side effect of disabling host-name whitelisting (seerpc-host-whitelist-enabled?.Defaults to ‘#f’.
transmission-daemon-configurationparameter: maybe-string rpc-username ¶The username required by clients to access the RPC interface when
rpc-authentication-required?is#t.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: maybe-transmission-password-hash rpc-password ¶The password required by clients to access the RPC interface when
rpc-authentication-required?is#t. This must be specified using a password hash in the format recognized by Transmission clients, either copied from an existing settings.json file or generated using thetransmission-password-hashprocedure.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: boolean rpc-whitelist-enabled? ¶When
#t, RPC requests will be accepted only when they originate from an address specified inrpc-whitelist.Defaults to ‘#t’.
transmission-daemon-configurationparameter: string-list rpc-whitelist ¶The list of IP and IPv6 addresses from which RPC requests will be accepted when
rpc-whitelist-enabled?is#t. Wildcards may be specified using ‘*’.Defaults to ‘("127.0.0.1" "::1")’.
transmission-daemon-configurationparameter: boolean rpc-host-whitelist-enabled? ¶When
#t, RPC requests will be accepted only when they are addressed to a host named inrpc-host-whitelist. Note that requests to “localhost” or “localhost.”, or to a numeric address, are always accepted regardless of these settings.Note also this functionality is disabled when
rpc-authentication-required?is#t.Defaults to ‘#t’.
transmission-daemon-configurationparameter: string-list rpc-host-whitelist ¶The list of host names recognized by the RPC server when
rpc-host-whitelist-enabled?is#t.Defaults to ‘()’.
transmission-daemon-configurationparameter: message-level message-level ¶The minimum severity level of messages to be logged (to /var/log/transmission.log) by the daemon, one of
none(no logging),error,infoanddebug.Defaults to ‘info’.
transmission-daemon-configurationparameter: boolean start-added-torrents? ¶When
#t, torrents are started as soon as they are added; otherwise, they are added in “paused” state.Defaults to ‘#t’.
transmission-daemon-configurationparameter: boolean script-torrent-done-enabled? ¶When
#t, the script specified byscript-torrent-done-filenamewill be invoked each time a torrent completes.Defaults to ‘#f’.
transmission-daemon-configurationparameter: maybe-file-object script-torrent-done-filename ¶A file name or file-like object specifying a script to run each time a torrent completes, when
script-torrent-done-enabled?is#t.Defaults to ‘disabled’.
transmission-daemon-configurationparameter: boolean scrape-paused-torrents-enabled? ¶When
#t, the daemon will scrape trackers for a torrent even when the torrent is paused.Defaults to ‘#t’.
transmission-daemon-configurationparameter: non-negative-integer cache-size-mb ¶The amount of memory, in megabytes, to allocate for the daemon’s in-memory cache. A larger value may increase performance by reducing the frequency of disk I/O.
Defaults to ‘4’.
transmission-daemon-configurationparameter: boolean prefetch-enabled? ¶When
#t, the daemon will try to improve I/O performance by hinting to the operating system which data is likely to be read next from disk to satisfy requests from peers.Defaults to ‘#t’.
Next: Сервисы Kerberos, Previous: File-Sharing Services, Up: Сервисы [Contents][Index]
12.9.16 Сервисы мониторинга
Tailon Service
Tailon is a web application for viewing and searching log files.
The following example will configure the service with default values. By
default, Tailon can be accessed on port 8080 (http://localhost:8080).
(service tailon-service-type)
The following example customises more of the Tailon configuration, adding
sed to the list of allowed commands.
(service tailon-service-type
(tailon-configuration
(config-file
(tailon-configuration-file
(allowed-commands '("tail" "grep" "awk" "sed"))))))
- Data Type: tailon-configuration
Data type representing the configuration of Tailon. This type has the following parameters:
config-file(default:(tailon-configuration-file))The configuration file to use for Tailon. This can be set to a tailon-configuration-file record value, or any gexp (see G-Expressions).
For example, to instead use a local file, the
local-filefunction can be used:(service tailon-service-type (tailon-configuration (config-file (local-file "./my-tailon.conf"))))package(default:tailon)The tailon package to use.
- Data Type: tailon-configuration-file
Data type representing the configuration options for Tailon. This type has the following parameters:
files(default:(list "/var/log"))List of files to display. The list can include strings for a single file or directory, or a list, where the first item is the name of a subsection, and the remaining items are the files or directories in that subsection.
bind(default:"localhost:8080")Address and port to which Tailon should bind on.
relative-root(default:#f)URL path to use for Tailon, set to
#fto not use a path.allow-transfers?(default:#t)Allow downloading the log files in the web interface.
follow-names?(default:#t)Allow tailing of not-yet existent files.
tail-lines(default:200)Number of lines to read initially from each file.
allowed-commands(default:(list "tail" "grep" "awk"))Commands to allow running. By default,
sedis disabled.debug?(default:#f)Set
debug?to#tto show debug messages.wrap-lines(default:#t)Initial line wrapping state in the web interface. Set to
#tto initially wrap lines (the default), or to#fto initially not wrap lines.http-auth(default:#f)HTTP authentication type to use. Set to
#fto disable authentication (the default). Supported values are"digest"or"basic".users(default:#f)If HTTP authentication is enabled (see
http-auth), access will be restricted to the credentials provided here. To configure users, use a list of pairs, where the first element of the pair is the username, and the 2nd element of the pair is the password.(tailon-configuration-file (http-auth "basic") (users '(("user1" . "password1") ("user2" . "password2"))))
Darkstat Service
Darkstat is a packet sniffer that captures network traffic, calculates statistics about usage, and serves reports over HTTP.
- Variable: Scheme Variable darkstat-service-type
This is the service type for the darkstat service, its value must be a
darkstat-configurationrecord as in this example:(service darkstat-service-type (darkstat-configuration (interface "eno1")))
- Data Type: darkstat-configuration
Data type representing the configuration of
darkstat.package(default:darkstat)The darkstat package to use.
interfaceCapture traffic on the specified network interface.
port(default:"667")Bind the web interface to the specified port.
bind-address(default:"127.0.0.1")Bind the web interface to the specified address.
base(default:"/")Specify the path of the base URL. This can be useful if
darkstatis accessed via a reverse proxy.
Prometheus Node Exporter Service
The Prometheus “node exporter” makes hardware and operating system statistics provided by the Linux kernel available for the Prometheus monitoring system. This service should be deployed on all physical nodes and virtual machines, where monitoring these statistics is desirable.
- Variable: Scheme variable prometheus-node-exporter-service-type
This is the service type for the prometheus-node-exporter service, its value must be a
prometheus-node-exporter-configuration.
- Data Type: prometheus-node-exporter-configuration
Data type representing the configuration of
node_exporter.package(default:go-github-com-prometheus-node-exporter)The prometheus-node-exporter package to use.
web-listen-address(default:":9100")Bind the web interface to the specified address.
port(default:22)This directory can be used to export metrics specific to this machine. Files containing metrics in the text format, with the filename ending in
.promshould be placed in this directory.extra-options(default:'())Extra options to pass to the Prometheus node exporter.
Zabbix server
Zabbix is a high performance monitoring system that can collect data from a variety of sources and provide the results in a web-based interface. Alerting and reporting is built-in, as well as templates for common operating system metrics such as network utilization, CPU load, and disk space consumption.
This service provides the central Zabbix monitoring service; you also need
zabbix-front-end-service-type to configure
Zabbix and display results, and optionally zabbix-agent-service-type on machines that should be monitored
(other data sources are supported, such as Prometheus Node Exporter).
- Variable: Scheme variable zabbix-server-service-type
This is the service type for the Zabbix server service. Its value must be a
zabbix-server-configurationrecord, shown below.
- Data Type: zabbix-server-configuration
Available
zabbix-server-configurationfields are:zabbix-server(default:zabbix-server) (type: file-like)The zabbix-server package.
user(default:"zabbix") (type: string)User who will run the Zabbix server.
group(default:"zabbix") (type: group)Group who will run the Zabbix server.
db-host(default:"127.0.0.1") (type: string)Database host name.
db-name(default:"zabbix") (type: string)Database name.
db-user(default:"zabbix") (type: string)Database user.
db-password(default:"") (type: string)Database password. Please, use
include-fileswithDBPassword=SECRETinside a specified file instead.db-port(default:5432) (type: number)Database port.
log-type(default:"") (type: string)Specifies where log messages are written to:
-
system- syslog. -
file- file specified withlog-fileparameter. -
console- standard output.
-
log-file(default:"/var/log/zabbix/server.log") (type: string)Log file name for
log-typefileparameter.pid-file(default:"/var/run/zabbix/zabbix_server.pid") (type: string)Name of PID file.
ssl-ca-location(default:"/etc/ssl/certs/ca-certificates.crt") (type: string)The location of certificate authority (CA) files for SSL server certificate verification.
ssl-cert-location(default:"/etc/ssl/certs") (type: string)Location of SSL client certificates.
extra-options(default:"") (type: extra-options)Extra options will be appended to Zabbix server configuration file.
include-files(default:()) (type: include-files)You may include individual files or all files in a directory in the configuration file.
Zabbix agent
The Zabbix agent gathers information about the running system for the Zabbix monitoring server. It has a variety of built-in checks, and can be extended with custom user parameters.
- Variable: Scheme variable zabbix-agent-service-type
This is the service type for the Zabbix agent service. Its value must be a
zabbix-agent-configurationrecord, shown below.
- Data Type: zabbix-agent-configuration
Available
zabbix-agent-configurationfields are:zabbix-agent(default:zabbix-agentd) (type: file-like)The zabbix-agent package.
user(default:"zabbix") (type: string)User who will run the Zabbix agent.
group(default:"zabbix") (type: group)Group who will run the Zabbix agent.
hostname(default:"") (type: string)Unique, case sensitive hostname which is required for active checks and must match hostname as configured on the server.
log-type(default:"") (type: string)Specifies where log messages are written to:
-
system- syslog. -
file- file specified withlog-fileparameter. -
console- standard output.
-
log-file(default:"/var/log/zabbix/agent.log") (type: string)Log file name for
log-typefileparameter.pid-file(default:"/var/run/zabbix/zabbix_agent.pid") (type: string)Name of PID file.
server(default:("127.0.0.1")) (type: list)List of IP addresses, optionally in CIDR notation, or hostnames of Zabbix servers and Zabbix proxies. Incoming connections will be accepted only from the hosts listed here.
server-active(default:("127.0.0.1")) (type: list)List of IP:port (or hostname:port) pairs of Zabbix servers and Zabbix proxies for active checks. If port is not specified, default port is used. If this parameter is not specified, active checks are disabled.
extra-options(default:"") (type: extra-options)Extra options will be appended to Zabbix server configuration file.
include-files(default:()) (type: include-files)You may include individual files or all files in a directory in the configuration file.
Zabbix front-end
The Zabbix front-end provides a web interface to Zabbix. It does not need to run on the same machine as the Zabbix server. This service works by extending the PHP-FPM and NGINX services with the configuration necessary for loading the Zabbix user interface.
- Variable: Scheme variable zabbix-front-end-service-type
This is the service type for the Zabbix web frontend. Its value must be a
zabbix-front-end-configurationrecord, shown below.
- Data Type: zabbix-front-end-configuration
Available
zabbix-front-end-configurationfields are:zabbix-server(default:zabbix-server) (type: file-like)The Zabbix server package to use.
nginx(default:()) (type: list)List of
nginx-server-configurationblocks for the Zabbix front-end. When empty, a default that listens on port 80 is used.db-host(default:"localhost") (type: string)Database host name.
db-port(default:5432) (type: number)Database port.
db-name(default:"zabbix") (type: string)Database name.
db-user(default:"zabbix") (type: string)Database user.
db-password(default:"") (type: string)Database password. Please, use
db-secret-fileinstead.db-secret-file(default:"") (type: string)Secret file which will be appended to zabbix.conf.php file. This file contains credentials for use by Zabbix front-end. You are expected to create it manually.
zabbix-host(default:"localhost") (type: string)Zabbix server hostname.
zabbix-port(default:10051) (type: number)Zabbix server port.
Next: LDAP Сервисы, Previous: Сервисы мониторинга, Up: Сервисы [Contents][Index]
12.9.17 Сервисы Kerberos
The (gnu services kerberos) module provides services relating to the
authentication protocol Kerberos.
Krb5 Service
Programs using a Kerberos client library normally expect a configuration file in /etc/krb5.conf. This service generates such a file from a definition provided in the operating system declaration. It does not cause any daemon to be started.
No “keytab” files are provided by this service—you must explicitly
create them. This service is known to work with the MIT client library,
mit-krb5. Other implementations have not been tested.
- Scheme Variable: krb5-service-type
A service type for Kerberos 5 clients.
Here is an example of its use:
(service krb5-service-type
(krb5-configuration
(default-realm "EXAMPLE.COM")
(allow-weak-crypto? #t)
(realms (list
(krb5-realm
(name "EXAMPLE.COM")
(admin-server "groucho.example.com")
(kdc "karl.example.com"))
(krb5-realm
(name "ARGRX.EDU")
(admin-server "kerb-admin.argrx.edu")
(kdc "keys.argrx.edu"))))))
This example provides a Kerberos 5 client configuration which:
- Recognizes two realms, viz: “EXAMPLE.COM” and “ARGRX.EDU”, both of which have distinct administration servers and key distribution centers;
- Will default to the realm “EXAMPLE.COM” if the realm is not explicitly specified by clients;
- Accepts services which only support encryption types known to be weak.
The krb5-realm and krb5-configuration types have many fields.
Only the most commonly used ones are described here. For a full list, and
more detailed explanation of each, see the MIT
krb5.conf
documentation.
- Data Type: krb5-realm
-
nameThis field is a string identifying the name of the realm. A common convention is to use the fully qualified DNS name of your organization, converted to upper case.
admin-serverThis field is a string identifying the host where the administration server is running.
kdcThis field is a string identifying the key distribution center for the realm.
- Data Type: krb5-configuration
-
allow-weak-crypto?(default:#f)If this flag is
#tthen services which only offer encryption algorithms known to be weak will be accepted.default-realm(default:#f)This field should be a string identifying the default Kerberos realm for the client. You should set this field to the name of your Kerberos realm. If this value is
#fthen a realm must be specified with every Kerberos principal when invoking programs such askinit.realmsThis should be a non-empty list of
krb5-realmobjects, which clients may access. Normally, one of them will have anamefield matching thedefault-realmfield.
PAM krb5 Service
The pam-krb5 service allows for login authentication and password
management via Kerberos. You will need this service if you want PAM enabled
applications to authenticate users using Kerberos.
- Scheme Variable: pam-krb5-service-type
A service type for the Kerberos 5 PAM module.
- Data Type: pam-krb5-configuration
Data type representing the configuration of the Kerberos 5 PAM module. This type has the following parameters:
pam-krb5(default:pam-krb5)The pam-krb5 package to use.
minimum-uid(default:1000)The smallest user ID for which Kerberos authentications should be attempted. Local accounts with lower values will silently fail to authenticate.
Next: Веб-сервисы, Previous: Сервисы Kerberos, Up: Сервисы [Contents][Index]
12.9.18 LDAP Сервисы
The (gnu services authentication) module provides the
nslcd-service-type, which can be used to authenticate against an LDAP
server. In addition to configuring the service itself, you may want to add
ldap as a name service to the Name Service Switch. See Служба выбора имён for detailed information.
Here is a simple operating system declaration with a default configuration
of the nslcd-service-type and a Name Service Switch configuration
that consults the ldap name service last:
(use-service-modules authentication) (use-modules (gnu system nss)) ... (operating-system ... (services (cons* (service nslcd-service-type) (service dhcp-client-service-type) %base-services)) (name-service-switch (let ((services (list (name-service (name "db")) (name-service (name "files")) (name-service (name "ldap"))))) (name-service-switch (inherit %mdns-host-lookup-nss) (password services) (shadow services) (group services) (netgroup services) (gshadow services)))))
Available nslcd-configuration fields are:
nslcd-configurationparameter: package nss-pam-ldapd ¶The
nss-pam-ldapdpackage to use.
nslcd-configurationparameter: maybe-number threads ¶The number of threads to start that can handle requests and perform LDAP queries. Each thread opens a separate connection to the LDAP server. The default is to start 5 threads.
Defaults to ‘disabled’.
nslcd-configurationparameter: string uid ¶This specifies the user id with which the daemon should be run.
Defaults to ‘"nslcd"’.
nslcd-configurationparameter: string gid ¶This specifies the group id with which the daemon should be run.
Defaults to ‘"nslcd"’.
nslcd-configurationparameter: log-option log ¶This option controls the way logging is done via a list containing SCHEME and LEVEL. The SCHEME argument may either be the symbols ‘none’ or ‘syslog’, or an absolute file name. The LEVEL argument is optional and specifies the log level. The log level may be one of the following symbols: ‘crit’, ‘error’, ‘warning’, ‘notice’, ‘info’ or ‘debug’. All messages with the specified log level or higher are logged.
Defaults to ‘("/var/log/nslcd" info)’.
nslcd-configurationparameter: list uri ¶The list of LDAP server URIs. Normally, only the first server will be used with the following servers as fall-back.
Defaults to ‘("ldap://localhost:389/")’.
nslcd-configurationparameter: maybe-string ldap-version ¶The version of the LDAP protocol to use. The default is to use the maximum version supported by the LDAP library.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string binddn ¶Specifies the distinguished name with which to bind to the directory server for lookups. The default is to bind anonymously.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string bindpw ¶Specifies the credentials with which to bind. This option is only applicable when used with binddn.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string rootpwmoddn ¶Specifies the distinguished name to use when the root user tries to modify a user’s password using the PAM module.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string rootpwmodpw ¶Specifies the credentials with which to bind if the root user tries to change a user’s password. This option is only applicable when used with rootpwmoddn
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string sasl-mech ¶Specifies the SASL mechanism to be used when performing SASL authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string sasl-realm ¶Specifies the SASL realm to be used when performing SASL authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string sasl-authcid ¶Specifies the authentication identity to be used when performing SASL authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string sasl-authzid ¶Specifies the authorization identity to be used when performing SASL authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean sasl-canonicalize? ¶Determines whether the LDAP server host name should be canonicalised. If this is enabled the LDAP library will do a reverse host name lookup. By default, it is left up to the LDAP library whether this check is performed or not.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string krb5-ccname ¶Set the name for the GSS-API Kerberos credentials cache.
Defaults to ‘disabled’.
nslcd-configurationparameter: string base ¶The directory search base.
Defaults to ‘"dc=example,dc=com"’.
nslcd-configurationparameter: scope-option scope ¶Specifies the search scope (subtree, onelevel, base or children). The default scope is subtree; base scope is almost never useful for name service lookups; children scope is not supported on all servers.
Defaults to ‘(subtree)’.
nslcd-configurationparameter: maybe-deref-option deref ¶Specifies the policy for dereferencing aliases. The default policy is to never dereference aliases.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean referrals ¶Specifies whether automatic referral chasing should be enabled. The default behaviour is to chase referrals.
Defaults to ‘disabled’.
nslcd-configurationparameter: list-of-map-entries maps ¶This option allows for custom attributes to be looked up instead of the default RFC 2307 attributes. It is a list of maps, each consisting of the name of a map, the RFC 2307 attribute to match and the query expression for the attribute as it is available in the directory.
Defaults to ‘()’.
nslcd-configurationparameter: list-of-filter-entries filters ¶A list of filters consisting of the name of a map to which the filter applies and an LDAP search filter expression.
Defaults to ‘()’.
nslcd-configurationparameter: maybe-number bind-timelimit ¶Specifies the time limit in seconds to use when connecting to the directory server. The default value is 10 seconds.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number timelimit ¶Specifies the time limit (in seconds) to wait for a response from the LDAP server. A value of zero, which is the default, is to wait indefinitely for searches to be completed.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number idle-timelimit ¶Specifies the period if inactivity (in seconds) after which the con‐ nection to the LDAP server will be closed. The default is not to time out connections.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number reconnect-sleeptime ¶Specifies the number of seconds to sleep when connecting to all LDAP servers fails. By default one second is waited between the first failure and the first retry.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number reconnect-retrytime ¶Specifies the time after which the LDAP server is considered to be permanently unavailable. Once this time is reached retries will be done only once per this time period. The default value is 10 seconds.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-ssl-option ssl ¶Specifies whether to use SSL/TLS or not (the default is not to). If ’start-tls is specified then StartTLS is used rather than raw LDAP over SSL.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-tls-reqcert-option tls-reqcert ¶Specifies what checks to perform on a server-supplied certificate. The meaning of the values is described in the ldap.conf(5) manual page.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-cacertdir ¶Specifies the directory containing X.509 certificates for peer authen‐ tication. This parameter is ignored when using GnuTLS.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-cacertfile ¶Specifies the path to the X.509 certificate for peer authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-randfile ¶Specifies the path to an entropy source. This parameter is ignored when using GnuTLS.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-ciphers ¶Specifies the ciphers to use for TLS as a string.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-cert ¶Specifies the path to the file containing the local certificate for client TLS authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string tls-key ¶Specifies the path to the file containing the private key for client TLS authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number pagesize ¶Set this to a number greater than 0 to request paged results from the LDAP server in accordance with RFC2696. The default (0) is to not request paged results.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-ignore-users-option nss-initgroups-ignoreusers ¶This option prevents group membership lookups through LDAP for the specified users. Alternatively, the value ’all-local may be used. With that value nslcd builds a full list of non-LDAP users on startup.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number nss-min-uid ¶This option ensures that LDAP users with a numeric user id lower than the specified value are ignored.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number nss-uid-offset ¶This option specifies an offset that is added to all LDAP numeric user ids. This can be used to avoid user id collisions with local users.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-number nss-gid-offset ¶This option specifies an offset that is added to all LDAP numeric group ids. This can be used to avoid user id collisions with local groups.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean nss-nested-groups ¶If this option is set, the member attribute of a group may point to another group. Members of nested groups are also returned in the higher level group and parent groups are returned when finding groups for a specific user. The default is not to perform extra searches for nested groups.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean nss-getgrent-skipmembers ¶If this option is set, the group member list is not retrieved when looking up groups. Lookups for finding which groups a user belongs to will remain functional so the user will likely still get the correct groups assigned on login.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean nss-disable-enumeration ¶If this option is set, functions which cause all user/group entries to be loaded from the directory will not succeed in doing so. This can dramatically reduce LDAP server load in situations where there are a great number of users and/or groups. This option is not recommended for most configurations.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string validnames ¶This option can be used to specify how user and group names are verified within the system. This pattern is used to check all user and group names that are requested and returned from LDAP.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean ignorecase ¶This specifies whether or not to perform searches using case-insensitive matching. Enabling this could open up the system to authorization bypass vulnerabilities and introduce nscd cache poisoning vulnerabilities which allow denial of service.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-boolean pam-authc-ppolicy ¶This option specifies whether password policy controls are requested and handled from the LDAP server when performing user authentication.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string pam-authc-search ¶By default nslcd performs an LDAP search with the user’s credentials after BIND (authentication) to ensure that the BIND operation was successful. The default search is a simple check to see if the user’s DN exists. A search filter can be specified that will be used instead. It should return at least one entry.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string pam-authz-search ¶This option allows flexible fine tuning of the authorisation check that should be performed. The search filter specified is executed and if any entries match, access is granted, otherwise access is denied.
Defaults to ‘disabled’.
nslcd-configurationparameter: maybe-string pam-password-prohibit-message ¶If this option is set password modification using pam_ldap will be denied and the specified message will be presented to the user instead. The message can be used to direct the user to an alternative means of changing their password.
Defaults to ‘disabled’.
nslcd-configurationparameter: list pam-services ¶List of pam service names for which LDAP authentication should suffice.
Defaults to ‘()’.
Next: Сервисы сертификатов, Previous: LDAP Сервисы, Up: Сервисы [Contents][Index]
12.9.19 Веб-сервисы
The (gnu services web) module provides the Apache HTTP Server, the
nginx web server, and also a fastcgi wrapper daemon.
Apache HTTP Server
- Scheme Variable: httpd-service-type
Service type for the Apache HTTP server (httpd). The value for this service type is a
httpd-configurationrecord.A simple example configuration is given below.
(service httpd-service-type (httpd-configuration (config (httpd-config-file (server-name "www.example.com") (document-root "/srv/http/www.example.com")))))Other services can also extend the
httpd-service-typeto add to the configuration.(simple-service 'www.example.com-server httpd-service-type (list (httpd-virtualhost "*:80" (list (string-join '("ServerName www.example.com" "DocumentRoot /srv/http/www.example.com") "\n")))))
The details for the httpd-configuration, httpd-module,
httpd-config-file and httpd-virtualhost record types are given
below.
- Data Type: httpd-configuration
This data type represents the configuration for the httpd service.
package(default:httpd)The httpd package to use.
pid-file(default:"/var/run/httpd")The pid file used by the shepherd-service.
config(default:(httpd-config-file))The configuration file to use with the httpd service. The default value is a
httpd-config-filerecord, but this can also be a different G-expression that generates a file, for example aplain-file. A file outside of the store can also be specified through a string.
- Data Type: httpd-module
This data type represents a module for the httpd service.
nameThe name of the module.
fileThe file for the module. This can be relative to the httpd package being used, the absolute location of a file, or a G-expression for a file within the store, for example
(file-append mod-wsgi "/modules/mod_wsgi.so").
- Scheme Variable: %default-httpd-modules
A default list of
httpd-moduleobjects.
- Data Type: httpd-config-file
This data type represents a configuration file for the httpd service.
modules(default:%default-httpd-modules)The modules to load. Additional modules can be added here, or loaded by additional configuration.
For example, in order to handle requests for PHP files, you can use Apache’s
mod_proxy_fcgimodule along withphp-fpm-service-type:(service httpd-service-type (httpd-configuration (config (httpd-config-file (modules (cons* (httpd-module (name "proxy_module") (file "modules/mod_proxy.so")) (httpd-module (name "proxy_fcgi_module") (file "modules/mod_proxy_fcgi.so")) %default-httpd-modules)) (extra-config (list "\ <FilesMatch \\.php$> SetHandler \"proxy:unix:/var/run/php-fpm.sock|fcgi://localhost/\" </FilesMatch>")))))) (service php-fpm-service-type (php-fpm-configuration (socket "/var/run/php-fpm.sock") (socket-group "httpd")))
server-root(default:httpd)The
ServerRootin the configuration file, defaults to the httpd package. Directives includingIncludeandLoadModuleare taken as relative to the server root.server-name(default:#f)The
ServerNamein the configuration file, used to specify the request scheme, hostname and port that the server uses to identify itself.This doesn’t need to be set in the server config, and can be specified in virtual hosts. The default is
#fto not specify aServerName.document-root(default:"/srv/http")The
DocumentRootfrom which files will be served.listen(default:'("80"))The list of values for the
Listendirectives in the config file. The value should be a list of strings, when each string can specify the port number to listen on, and optionally the IP address and protocol to use.pid-file(default:"/var/run/httpd")The
PidFileto use. This should match thepid-fileset in thehttpd-configurationso that the Shepherd service is configured correctly.error-log(default:"/var/log/httpd/error_log")The
ErrorLogto which the server will log errors.user(default:"httpd")The
Userwhich the server will answer requests as.group(default:"httpd")The
Groupwhich the server will answer requests as.extra-config(default:(list "TypesConfig etc/httpd/mime.types"))A flat list of strings and G-expressions which will be added to the end of the configuration file.
Any values which the service is extended with will be appended to this list.
- Data Type: httpd-virtualhost
This data type represents a virtualhost configuration block for the httpd service.
These should be added to the extra-config for the httpd-service.
(simple-service 'www.example.com-server httpd-service-type (list (httpd-virtualhost "*:80" (list (string-join '("ServerName www.example.com" "DocumentRoot /srv/http/www.example.com") "\n")))))addresses-and-portsThe addresses and ports for the
VirtualHostdirective.contentsThe contents of the
VirtualHostdirective, this should be a list of strings and G-expressions.
NGINX
- Scheme Variable: nginx-service-type
Service type for the NGinx web server. The value for this service type is a
<nginx-configuration>record.A simple example configuration is given below.
(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com"))))))In addition to adding server blocks to the service configuration directly, this service can be extended by other services to add server blocks, as in this example:
(simple-service 'my-extra-server nginx-service-type (list (nginx-server-configuration (root "/srv/http/extra-website") (try-files (list "$uri" "$uri/index.html")))))
At startup, nginx has not yet read its configuration file, so it
uses a default file to log error messages. If it fails to load its
configuration file, that is where error messages are logged. After the
configuration file is loaded, the default error log file changes as per
configuration. In our case, startup error messages can be found in
/var/run/nginx/logs/error.log, and after configuration in
/var/log/nginx/error.log. The second location can be changed with
the log-directory configuration option.
- Data Type: nginx-configuration
This data type represents the configuration for NGinx. Some configuration can be done through this and the other provided record types, or alternatively, a config file can be provided.
nginx(default:nginx)The nginx package to use.
shepherd-requirement(default:'())This is a list of symbols naming Shepherd services the nginx service will depend on.
This is useful if you would like
nginxto be started after a back-end web server or a logging service such as Anonip has been started.log-directory(default:"/var/log/nginx")The directory to which NGinx will write log files.
run-directory(default:"/var/run/nginx")The directory in which NGinx will create a pid file, and write temporary files.
server-blocks(default:'())A list of server blocks to create in the generated configuration file, the elements should be of type
<nginx-server-configuration>.The following example would setup NGinx to serve
www.example.comfrom the/srv/http/www.example.comdirectory, without using HTTPS.(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com"))))))upstream-blocks(default:'())A list of upstream blocks to create in the generated configuration file, the elements should be of type
<nginx-upstream-configuration>.Configuring upstreams through the
upstream-blockscan be useful when combined withlocationsin the<nginx-server-configuration>records. The following example creates a server configuration with one location configuration, that will proxy requests to a upstream configuration, which will handle requests with two servers.(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com") (locations (list (nginx-location-configuration (uri "/path1") (body '("proxy_pass http://server-proxy;")))))))) (upstream-blocks (list (nginx-upstream-configuration (name "server-proxy") (servers (list "server1.example.com" "server2.example.com")))))))file(default:#f)If a configuration file is provided, this will be used, rather than generating a configuration file from the provided
log-directory,run-directory,server-blocksandupstream-blocks. For proper operation, these arguments should match what is in file to ensure that the directories are created when the service is activated.This can be useful if you have an existing configuration file, or it’s not possible to do what is required through the other parts of the nginx-configuration record.
server-names-hash-bucket-size(default:#f)Bucket size for the server names hash tables, defaults to
#fto use the size of the processors cache line.server-names-hash-bucket-max-size(default:#f)Maximum bucket size for the server names hash tables.
modules(по умолчанию:'())List of nginx dynamic modules to load. This should be a list of file names of loadable modules, as in this example:
(modules (list (file-append nginx-accept-language-module "\ /etc/nginx/modules/ngx_http_accept_language_module.so") (file-append nginx-lua-module "\ /etc/nginx/modules/ngx_http_lua_module.so")))native-search-paths(default:'())List of nginx lua packages to load. This should be a list of package names of loadable lua modules, as in this example:
(lua-package-path (list lua-resty-core lua-resty-lrucache lua-resty-signal lua-tablepool lua-resty-shell))native-search-paths(default:'())List of nginx lua C packages to load. This should be a list of package names of loadable lua C modules, as in this example:
(lua-package-cpath (list lua-resty-signal))features(default:'())Association list of global directives for the top level of the nginx configuration. Values may themselves be association lists.
(global-directives `((worker_processes . 16) (pcre_jit . on) (events . ((worker_connections . 1024)))))extra-content(default:"")Extra content for the
httpblock. Should be string or a string valued G-expression.
- Data Type: nginx-server-configuration
Data type representing the configuration of an nginx server block. This type has the following parameters:
listen(default:'("80" "443 ssl"))Each
listendirective sets the address and port for IP, or the path for a UNIX-domain socket on which the server will accept requests. Both address and port, or only address or only port can be specified. An address may also be a hostname, for example:'("127.0.0.1:8000" "127.0.0.1" "8000" "*:8000" "localhost:8000")
server-name(default:(list 'default))A list of server names this server represents.
'defaultrepresents the default server for connections matching no other server.root(default:"/srv/http")Root of the website nginx will serve.
locations(default:'())A list of nginx-location-configuration or nginx-named-location-configuration records to use within this server block.
index(default:(list "index.html"))Index files to look for when clients ask for a directory. If it cannot be found, Nginx will send the list of files in the directory.
try-files(default:'())A list of files whose existence is checked in the specified order.
nginxwill use the first file it finds to process the request.ssl-certificate(default:#f)Where to find the certificate for secure connections. Set it to
#fif you don’t have a certificate or you don’t want to use HTTPS.ssl-certificate-key(default:#f)Where to find the private key for secure connections. Set it to
#fif you don’t have a key or you don’t want to use HTTPS.server-tokens?(default:#f)Whether the server should add its configuration to response.
raw-content(default:'())A list of raw lines added to the server block.
- Data Type: nginx-upstream-configuration
Data type representing the configuration of an nginx
upstreamblock. This type has the following parameters:nameName for this group of servers.
serversSpecify the addresses of the servers in the group. The address can be specified as a IP address (e.g. ‘127.0.0.1’), domain name (e.g. ‘backend1.example.com’) or a path to a UNIX socket using the prefix ‘unix:’. For addresses using an IP address or domain name, the default port is 80, and a different port can be specified explicitly.
extra-contentA string or list of strings to add to the upstream block.
- Data Type: nginx-location-configuration
Data type representing the configuration of an nginx
locationblock. This type has the following parameters:uriURI which this location block matches.
bodyBody of the location block, specified as a list of strings. This can contain many configuration directives. For example, to pass requests to a upstream server group defined using an
nginx-upstream-configurationblock, the following directive would be specified in the body ‘(list "proxy_pass http://upstream-name;")’.
- Data Type: nginx-named-location-configuration
Data type representing the configuration of an nginx named location block. Named location blocks are used for request redirection, and not used for regular request processing. This type has the following parameters:
nameName to identify this location block.
bodySee nginx-location-configuration body, as the body for named location blocks can be used in a similar way to the
nginx-location-configuration body. One restriction is that the body of a named location block cannot contain location blocks.
Varnish Cache
Varnish is a fast cache server that sits in between web applications and end users. It proxies requests from clients and caches the accessed URLs such that multiple requests for the same resource only creates one request to the back-end.
- Scheme Variable: varnish-service-type
Service type for the Varnish daemon.
- Data Type: varnish-configuration
Data type representing the
varnishservice configuration. This type has the following parameters:package(default:varnish)The Varnish package to use.
name(default:"default")A name for this Varnish instance. Varnish will create a directory in /var/varnish/ with this name and keep temporary files there. If the name starts with a forward slash, it is interpreted as an absolute directory name.
Pass the
-nargument to other Varnish programs to connect to the named instance, e.g.varnishncsa -n default.backend(default:"localhost:8080")The backend to use. This option has no effect if
vclis set.vcl(default: #f)The VCL (Varnish Configuration Language) program to run. If this is
#f, Varnish will proxybackendusing the default configuration. Otherwise this must be a file-like object with valid VCL syntax.For example, to mirror www.gnu.org with VCL you can do something along these lines:
(define %gnu-mirror (plain-file "gnu.vcl" "vcl 4.1; backend gnu { .host = \"www.gnu.org\"; }")) (operating-system ;; … (services (cons (service varnish-service-type (varnish-configuration (listen '(":80")) (vcl %gnu-mirror))) %base-services)))
The configuration of an already running Varnish instance can be inspected and changed using the
varnishadmprogram.Consult the Varnish User Guide and Varnish Book for comprehensive documentation on Varnish and its configuration language.
listen(default:'("localhost:80"))List of addresses Varnish will listen on.
storage(default:'("malloc,128m"))List of storage backends that will be available in VCL.
parameters(default:'())List of run-time parameters in the form
'(("parameter" . "value")).extra-options(default:'())Additional arguments to pass to the
varnishdprocess.
Patchwork
Patchwork is a patch tracking system. It can collect patches sent to a mailing list, and display them in a web interface.
- Scheme Variable: patchwork-service-type
Поделитесь своей работой.
The following example is an example of a minimal service for Patchwork, for
the patchwork.example.com domain.
(service patchwork-service-type
(patchwork-configuration
(domain "patchwork.example.com")
(settings-module
(patchwork-settings-module
(allowed-hosts (list domain))
(default-from-email "patchwork@patchwork.example.com")))
(getmail-retriever-config
(getmail-retriever-configuration
(type "SimpleIMAPSSLRetriever")
(server "imap.example.com")
(port 993)
(username "patchwork")
(password-command
(list (file-append coreutils "/bin/cat")
"/etc/getmail-patchwork-imap-password"))
(extra-parameters
'((mailboxes . ("Patches"))))))))
There are three records for configuring the Patchwork service. The
<patchwork-configuration> relates to the configuration for Patchwork
within the HTTPD service.
The settings-module field within the <patchwork-configuration>
record can be populated with the <patchwork-settings-module> record,
which describes a settings module that is generated within the Guix store.
For the database-configuration field within the
<patchwork-settings-module>, the
<patchwork-database-configuration> must be used.
- Data Type: patchwork-configuration
Data type representing the Patchwork service configuration. This type has the following parameters:
port(default:22)Используемый пакет Patchwork.
domainThe domain to use for Patchwork, this is used in the HTTPD service virtual host.
settings-moduleThe settings module to use for Patchwork. As a Django application, Patchwork is configured with a Python module containing the settings. This can either be an instance of the
<patchwork-settings-module>record, any other record that represents the settings in the store, or a directory outside of the store.port(default:22)The path under which the HTTPD service should serve the static files.
getmail-retriever-configThe getmail-retriever-configuration record value to use with Patchwork. Getmail will be configured with this value, the messages will be delivered to Patchwork.
- Data Type: patchwork-settings-module
Data type representing a settings module for Patchwork. Some of these settings relate directly to Patchwork, but others relate to Django, the web framework used by Patchwork, or the Django Rest Framework library. This type has the following parameters:
database-configuration(default:(patchwork-database-configuration))The database connection settings used for Patchwork. See the
<patchwork-database-configuration>record type for more information.daemon-socket(default:"/var/guix/daemon-socket/socket")Patchwork, as a Django web application uses a secret key for cryptographically signing values. This file should contain a unique unpredictable value.
If this file does not exist, it will be created and populated with a random value by the patchwork-setup shepherd service.
This setting relates to Django.
allowed-hostsA list of valid hosts for this Patchwork service. This should at least include the domain specified in the
<patchwork-configuration>record.This is a Django setting.
default-from-emailThe email address from which Patchwork should send email by default.
This is a Patchwork setting.
features(default:'())The URL to use when serving static assets. It can be part of a URL, or a full URL, but must end in a
/.If the default value is used, the
static-pathvalue from the<patchwork-configuration>record will be used.This is a Django setting.
features(default:'())Email addresses to send the details of errors that occur. Each value should be a list containing two elements, the name and then the email address.
This is a Django setting.
debug?(default:#f)Whether to run Patchwork in debug mode. If set to
#t, detailed error messages will be shown.This is a Django setting.
features(default:'())Whether to enable the Patchwork REST API.
This is a Patchwork setting.
port(default:22)Whether to enable the XML RPC API.
This is a Patchwork setting.
port(default:22)Whether to use HTTPS links on Patchwork pages.
This is a Patchwork setting.
extra-settings(default:"")Extra code to place at the end of the Patchwork settings module.
- Data Type: patchwork-database-configuration
Data type representing the database configuration for Patchwork.
port(default:22)The database engine to use.
port(default:22)Имя используемой базы данных.
user(default:"httpd")The user to connect to the database as.
port(default:22)The password to use when connecting to the database.
port(default:22)The host to make the database connection to.
port(default:22)The port on which to connect to the database.
Mumi
Mumi is a Web interface to the Debbugs bug tracker, by default for the GNU instance. Mumi is a Web server, but it also fetches and indexes mail retrieved from Debbugs.
- Scheme Variable: mumi-service-type
This is the service type for Mumi.
- Тип данных: build-machine
Тип данных, представляющий конфигурацию сервиса Mumi. Этот тип имеет следующие поля:
port(default:22)Используемый пакет Mumi.
speed(default:1.0)Whether to enable or disable the mailer component.
Конфигурирование системыThe email address used as the sender for comments.
Конфигурирование системыA URI to configure the SMTP settings for Mailutils. This could be something like
sendmail:///path/to/bin/msmtpor any other URI supported by Mailutils. See SMTP Mailboxes in GNU Mailutils.
FastCGI
FastCGI is an interface between the front-end and the back-end of a web service. It is a somewhat legacy facility; new web services should generally just talk HTTP between the front-end and the back-end. However there are a number of back-end services such as PHP or the optimized HTTP Git repository access that use FastCGI, so we have support for it in Guix.
To use FastCGI, you configure the front-end web server (e.g., nginx) to
dispatch some subset of its requests to the fastcgi backend, which listens
on a local TCP or UNIX socket. There is an intermediary fcgiwrap
program that sits between the actual backend process and the web server.
The front-end indicates which backend program to run, passing that
information to the fcgiwrap process.
- Scheme Variable: fcgiwrap-service-type
A service type for the
fcgiwrapFastCGI proxy.
- Data Type: fcgiwrap-configuration
Data type representing the configuration of the
fcgiwrapservice. This type has the following parameters:package(default:fcgiwrap)The fcgiwrap package to use.
socket(default:tcp:127.0.0.1:9000)The socket on which the
fcgiwrapprocess should listen, as a string. Valid socket values includeunix:/path/to/unix/socket,tcp:dot.ted.qu.ad:portandtcp6:[ipv6_addr]:port.user(default:fcgiwrap)group(default:fcgiwrap)The user and group names, as strings, under which to run the
fcgiwrapprocess. Thefastcgiservice will ensure that if the user asks for the specific user or group namesfcgiwrapthat the corresponding user and/or group is present on the system.It is possible to configure a FastCGI-backed web service to pass HTTP authentication information from the front-end to the back-end, and to allow
fcgiwrapto run the back-end process as a corresponding local user. To enable this capability on the back-end, runfcgiwrapas therootuser and group. Note that this capability also has to be configured on the front-end as well.
PHP-FPM
PHP-FPM (FastCGI Process Manager) is an alternative PHP FastCGI implementation with some additional features useful for sites of any size.
These features include:
- Adaptive process spawning
- Basic statistics (similar to Apache’s mod_status)
- Advanced process management with graceful stop/start
- Ability to start workers with different uid/gid/chroot/environment and different php.ini (replaces safe_mode)
- Stdout & stderr logging
- Emergency restart in case of accidental opcode cache destruction
- Accelerated upload support
- Support for a "slowlog"
- Enhancements to FastCGI, such as fastcgi_finish_request() - a special function to finish request & flush all data while continuing to do something time-consuming (video converting, stats processing, etc.)
... and much more.
- Scheme Variable: php-fpm-service-type
A Service type for
php-fpm.
- Data Type: php-fpm-configuration
Data Type for php-fpm service configuration.
php(default:php)The php package to use.
socket(default:(string-append "/var/run/php" (version-major (package-version php)) "-fpm.sock"))The address on which to accept FastCGI requests. Valid syntaxes are:
"ip.add.re.ss:port"Listen on a TCP socket to a specific address on a specific port.
"port"Listen on a TCP socket to all addresses on a specific port.
"/path/to/unix/socket"Listen on a unix socket.
user(default:php-fpm)User who will own the php worker processes.
group(default:php-fpm)Group of the worker processes.
socket-user(default:php-fpm)User who can speak to the php-fpm socket.
port(default:22)Group that can speak to the php-fpm socket.
pid-file(default:(string-append "/var/run/php" (version-major (package-version php)) "-fpm.pid"))The process id of the php-fpm process is written to this file once the service has started.
log-file(default:(string-append "/var/log/php" (version-major (package-version php)) "-fpm.log"))Log for the php-fpm master process.
process-manager(default:(php-fpm-dynamic-process-manager-configuration))Detailed settings for the php-fpm process manager. Must be one of:
<php-fpm-dynamic-process-manager-configuration><php-fpm-static-process-manager-configuration><php-fpm-on-demand-process-manager-configuration>
display-errors(default#f)Determines whether php errors and warning should be sent to clients and displayed in their browsers. This is useful for local php development, but a security risk for public sites, as error messages can reveal passwords and personal data.
timezone(default#f)Specifies
php_admin_value[date.timezone]parameter.workers-logfile(default(string-append "/var/log/php" (version-major (package-version php)) "-fpm.www.log"))This file will log the
stderroutputs of php worker processes. Can be set to#fto disable logging.file(default#f)An optional override of the whole configuration. You can use the
mixed-text-filefunction or an absolute filepath for it.speed(default:1.0)An optional override of the default php settings. It may be any “file-like” object (see file-like objects). You can use the
mixed-text-filefunction or an absolute filepath for it.For local development it is useful to set a higher timeout and memory limit for spawned php processes. This be accomplished with the following operating system configuration snippet:
(define %local-php-ini (plain-file "php.ini" "memory_limit = 2G max_execution_time = 1800")) (operating-system ;; … (services (cons (service php-fpm-service-type (php-fpm-configuration (php-ini-file %local-php-ini))) %base-services)))
Consult the core php.ini directives for comprehensive documentation on the acceptable php.ini directives.
- Data type: php-fpm-dynamic-process-manager-configuration
Data Type for the
dynamicphp-fpm process manager. With thedynamicprocess manager, spare worker processes are kept around based on its configured limits.max-children(default:5)Maximum of worker processes.
start-servers(default:2)How many worker processes should be started on start-up.
min-spare-servers(default:1)How many spare worker processes should be kept around at minimum.
max-spare-servers(default:3)How many spare worker processes should be kept around at maximum.
- Data type: php-fpm-static-process-manager-configuration
Data Type for the
staticphp-fpm process manager. With thestaticprocess manager, an unchanging number of worker processes are created.max-children(default:5)Maximum of worker processes.
- Data type: php-fpm-on-demand-process-manager-configuration
Data Type for the
on-demandphp-fpm process manager. With theon-demandprocess manager, worker processes are only created as requests arrive.max-children(default:5)Maximum of worker processes.
process-idle-timeout(default:10)The time in seconds after which a process with no requests is killed.
- Процедура Scheme: inferior-package-location package
[#:nginx-package nginx] [socket (string-append "/var/run/php" (version-major (package-version php)) "-fpm.sock")] A helper function to quickly add php to an
nginx-server-configuration.
A simple services setup for nginx with php can look like this:
(services (cons* (service dhcp-client-service-type)
(service php-fpm-service-type)
(service nginx-service-type
(nginx-server-configuration
(server-name '("example.com"))
(root "/srv/http/")
(locations
(list (nginx-php-location)))
(listen '("80"))
(ssl-certificate #f)
(ssl-certificate-key #f)))
%base-services))
The cat avatar generator is a simple service to demonstrate the use of
php-fpm in Nginx. It is used to generate cat avatar from a seed, for
instance the hash of a user’s email address.
- Scheme Procedure: cat-avatar-generator-service [#:cache-dir "/var/cache/cat-avatar-generator"] [#:package
cat-avatar-generator] [#:configuration (nginx-server-configuration)] Returns an nginx-server-configuration that inherits
configuration. It extends the nginx configuration to add a server block that servespackage, a version of cat-avatar-generator. During execution, cat-avatar-generator will be able to usecache-diras its cache directory.
A simple setup for cat-avatar-generator can look like this:
(services (cons* (cat-avatar-generator-service
#:configuration
(nginx-server-configuration
(server-name '("example.com"))))
...
%base-services))
Hpcguix-web
The hpcguix-web program is a customizable web interface to browse Guix packages, initially designed for users of high-performance computing (HPC) clusters.
- Scheme Variable: hpcguix-web-service-type
The service type for
hpcguix-web.
- Data Type: hpcguix-web-configuration
Data type for the hpcguix-web service configuration.
specsA gexp (see G-Expressions) specifying the hpcguix-web service configuration. The main items available in this spec are:
title-prefix(default:"hpcguix | ")The page title prefix.
guix-command(default:"guix")The
guixcommand.package-filter-proc(default:(const #t))A procedure specifying how to filter packages that are displayed.
package-page-extension-proc(default:(const '()))Extension package for
hpcguix-web.menu(default:'())Additional entry in page
menu.channels(default:%default-channels)List of channels from which the package list is built (see Каналы).
package-list-expiration(default:(* 12 3600))The expiration time, in seconds, after which the package list is rebuilt from the latest instances of the given channels.
See the hpcguix-web repository for a complete example.
package(default:hpcguix-web)The hpcguix-web package to use.
address(default:"127.0.0.1")The IP address to listen to.
port(default:5000)The port number to listen to.
A typical hpcguix-web service declaration looks like this:
(service hpcguix-web-service-type
(hpcguix-web-configuration
(specs
#~(define site-config
(hpcweb-configuration
(title-prefix "Guix-HPC - ")
(menu '(("/about" "ABOUT"))))))))
Примечание: The hpcguix-web service periodically updates the package list it publishes by pulling channels from Git. To that end, it needs to access X.509 certificates so that it can authenticate Git servers when communicating over HTTPS, and it assumes that /etc/ssl/certs contains those certificates.
Thus, make sure to add
nss-certsor another certificate package to thepackagesfield of your configuration. Сертификаты X.509, for more information on X.509 certificates.
gmnisrv
The gmnisrv program is a simple Gemini protocol server.
- Процедура Scheme: sane-service-type
This is the type of the gmnisrv service, whose value should be a
gmnisrv-configurationobject, as in this example:(service gmnisrv-service-type (gmnisrv-configuration (config-file (local-file "./my-gmnisrv.ini"))))
- Конфигурирование: системы
Управление конфигурацией операционной системы.
port(default:22)Package object of the gmnisrv server.
features(default:'())File-like object of the gmnisrv configuration file to use. The default configuration listens on port 1965 and serves files from /srv/gemini. Certificates are stored in /var/lib/gemini/certs. For more information, run
man gmnisrvandman gmnisrv.ini.
Agate
The Agate (GitHub page over HTTPS) program is a simple Gemini protocol server written in Rust.
- Процедура Scheme: sane-service-type
This is the type of the agate service, whose value should be an
agate-service-typeobject, as in this example:(service agate-service-type (agate-configuration (content "/srv/gemini") (cert "/srv/cert.pem") (key "/srv/key.rsa")))The example above represents the minimal tweaking necessary to get Agate up and running. Specifying the path to the certificate and key is always necessary, as the Gemini protocol requires TLS by default.
To obtain a certificate and a key, you could, for example, use OpenSSL, running a command similar to the following example:
openssl req -x509 -newkey rsa:4096 -keyout key.rsa -out cert.pem \ -days 3650 -nodes -subj "/CN=example.com"Of course, you’ll have to replace example.com with your own domain name, and then point the Agate configuration towards the path of the generated key and certificate.
- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
speed(default:1.0)Пакет для использования.
port(default:22)The directory from which Agate will serve files.
port(default:22)The path to the TLS certificate PEM file to be used for encrypted connections. Must be filled in with a value from the user.
key(default:#f)The path to the PKCS8 private key file to be used for encrypted connections. Must be filled in with a value from the user.
speed(default:1.0)A list of the addresses to listen on.
hostname(default:#f)The domain name of this Gemini server. Optional.
port(default:22)RFC 4646 language code(s) for text/gemini documents. Optional.
snippet(по умолчанию:#f)Set to
#tto disable logging output.features(default:'())Set to
#tto serve secret files (files/directories starting with a dot).port(default:22)Whether or not to output IP addresses when logging.
port(default:22)Owner of the
agateprocess.port(default:22)Owner’s group of the
agateprocess.daemon-socket(default:"/var/guix/daemon-socket/socket")The file which should store the logging output of Agate.
Next: Сервисы DNS, Previous: Веб-сервисы, Up: Сервисы [Contents][Index]
12.9.20 Сервисы сертификатов
The (gnu services certbot) module provides a service to automatically
obtain a valid TLS certificate from the Let’s Encrypt certificate
authority. These certificates can then be used to serve content securely
over HTTPS or other TLS-based protocols, with the knowledge that the client
will be able to verify the server’s authenticity.
Let’s Encrypt provides the certbot
tool to automate the certification process. This tool first securely
generates a key on the server. It then makes a request to the Let’s Encrypt
certificate authority (CA) to sign the key. The CA checks that the request
originates from the host in question by using a challenge-response protocol,
requiring the server to provide its response over HTTP. If that protocol
completes successfully, the CA signs the key, resulting in a certificate.
That certificate is valid for a limited period of time, and therefore to
continue to provide TLS services, the server needs to periodically ask the
CA to renew its signature.
The certbot service automates this process: the initial key generation, the initial certification request to the Let’s Encrypt service, the web server challenge/response integration, writing the certificate to disk, the automated periodic renewals, and the deployment tasks associated with the renewal (e.g. reloading services, copying keys with different permissions).
Certbot is run twice a day, at a random minute within the hour. It won’t do anything until your certificates are due for renewal or revoked, but running it regularly would give your service a chance of staying online in case a Let’s Encrypt-initiated revocation happened for some reason.
By using this service, you agree to the ACME Subscriber Agreement, which can be found there: https://acme-v01.api.letsencrypt.org/directory.
- Scheme Variable: certbot-service-type
A service type for the
certbotLet’s Encrypt client. Its value must be acertbot-configurationrecord as in this example:(define %nginx-deploy-hook (program-file "nginx-deploy-hook" #~(let ((pid (call-with-input-file "/var/run/nginx/pid" read))) (kill pid SIGHUP)))) (service certbot-service-type (certbot-configuration (email "foo@example.net") (certificates (list (certificate-configuration (domains '("example.net" "www.example.net")) (deploy-hook %nginx-deploy-hook)) (certificate-configuration (domains '("bar.example.net")))))))
See below for details about
certbot-configuration.
- Data Type: certbot-configuration
Data type representing the configuration of the
certbotservice. This type has the following parameters:package(default:certbot)The certbot package to use.
webroot(default:/var/www)The directory from which to serve the Let’s Encrypt challenge/response files.
certificates(default:())A list of
certificates-configurations for which to generate certificates and request signatures. Each certificate has anameand severaldomains.speed(default:1.0)Optional email address used for registration and recovery contact. Setting this is encouraged as it allows you to receive important notifications about the account and issued certificates.
features(default:'())Optional URL of ACME server. Setting this overrides certbot’s default, which is the Let’s Encrypt server.
rsa-key-size(default:2048)Size of the RSA key.
default-location(default: see below)The default
nginx-location-configuration. Becausecertbotneeds to be able to serve challenges and responses, it needs to be able to run a web server. It does so by extending thenginxweb service with annginx-server-configurationlistening on the domains on port 80, and which has anginx-location-configurationfor the/.well-known/URI path subspace used by Let’s Encrypt. See Веб-сервисы, for more on these nginx configuration data types.Requests to other URL paths will be matched by the
default-location, which if present is added to allnginx-server-configurations.By default, the
default-locationwill issue a redirect fromhttp://domain/...tohttps://domain/..., leaving you to define what to serve on your site viahttps.Pass
#fto not issue a default location.
- Data Type: certificate-configuration
Data type representing the configuration of a certificate. This type has the following parameters:
name(default: see below)This name is used by Certbot for housekeeping and in file paths; it doesn’t affect the content of the certificate itself. To see certificate names, run
certbot certificates.Its default is the first provided domain.
domains(default:())The first domain provided will be the subject CN of the certificate, and all domains will be Subject Alternative Names on the certificate.
challenge(default:#f)The challenge type that has to be run by certbot. If
#fis specified, default to the HTTP challenge. If a value is specified, defaults to the manual plugin (seeauthentication-hook,cleanup-hookand the documentation at https://certbot.eff.org/docs/using.html#hooks), and gives Let’s Encrypt permission to log the public IP address of the requesting machine.csr(default:#f)File name of Certificate Signing Request (CSR) in DER or PEM format. If
#fis specified, this argument will not be passed to certbot. If a value is specified, certbot will use it to obtain a certificate, instead of using a self-generated CSR. The domain-name(s) mentioned indomains, must be consistent with the domain-name(s) mentioned in CSR file.authentication-hook(default:#f)Command to be run in a shell once for each certificate challenge to be answered. For this command, the shell variable
$CERTBOT_DOMAINwill contain the domain being authenticated,$CERTBOT_VALIDATIONcontains the validation string and$CERTBOT_TOKENcontains the file name of the resource requested when performing an HTTP-01 challenge.cleanup-hook(default:#f)Command to be run in a shell once for each certificate challenge that have been answered by the
auth-hook. For this command, the shell variables available in theauth-hookscript are still available, and additionally$CERTBOT_AUTH_OUTPUTwill contain the standard output of theauth-hookscript.deploy-hook(default:#f)Command to be run in a shell once for each successfully issued certificate. For this command, the shell variable
$RENEWED_LINEAGEwill point to the config live subdirectory (for example, ‘"/etc/letsencrypt/live/example.com"’) containing the new certificates and keys; the shell variable$RENEWED_DOMAINSwill contain a space-delimited list of renewed certificate domains (for example, ‘"example.com www.example.com"’.
For each certificate-configuration, the certificate is saved to
/etc/letsencrypt/live/name/fullchain.pem and the key is saved
to /etc/letsencrypt/live/name/privkey.pem.
Next: VNC Services, Previous: Сервисы сертификатов, Up: Сервисы [Contents][Index]
12.9.21 Сервисы DNS
The (gnu services dns) module provides services related to the
domain name system (DNS). It provides a server service for hosting an
authoritative DNS server for multiple zones, slave or master. This
service uses Knot DNS. And also a caching
and forwarding DNS server for the LAN, which uses
dnsmasq.
Knot Service
An example configuration of an authoritative server for two zones, one master and one slave, is:
(define-zone-entries example.org.zone ;; Name TTL Class Type Data ("@" "" "IN" "A" "127.0.0.1") ("@" "" "IN" "NS" "ns") ("ns" "" "IN" "A" "127.0.0.1")) (define master-zone (knot-zone-configuration (domain "example.org") (zone (zone-file (origin "example.org") (entries example.org.zone))))) (define slave-zone (knot-zone-configuration (domain "plop.org") (dnssec-policy "default") (master (list "plop-master")))) (define plop-master (knot-remote-configuration (id "plop-master") (address (list "208.76.58.171")))) (operating-system ;; ... (services (cons* (service knot-service-type (knot-configuration (remotes (list plop-master)) (zones (list master-zone slave-zone)))) ;; ... %base-services)))
- Scheme Variable: knot-service-type
This is the type for the Knot DNS server.
Knot DNS is an authoritative DNS server, meaning that it can serve multiple zones, that is to say domain names you would buy from a registrar. This server is not a resolver, meaning that it can only resolve names for which it is authoritative. This server can be configured to serve zones as a master server or a slave server as a per-zone basis. Slave zones will get their data from masters, and will serve it as an authoritative server. From the point of view of a resolver, there is no difference between master and slave.
The following data types are used to configure the Knot DNS server:
- Data Type: knot-key-configuration
Data type representing a key. This type has the following parameters:
id(default:"")An identifier for other configuration fields to refer to this key. IDs must be unique and must not be empty.
algorithm(default:#f)The algorithm to use. Choose between
#f,'hmac-md5,'hmac-sha1,'hmac-sha224,'hmac-sha256,'hmac-sha384and'hmac-sha512.secret(default:"")The secret key itself.
- Data Type: knot-acl-configuration
Data type representing an Access Control List (ACL) configuration. This type has the following parameters:
id(default:"")An identifier for other configuration fields to refer to this key. IDs must be unique and must not be empty.
address(default:'())An ordered list of IP addresses, network subnets, or network ranges represented with strings. The query must match one of them. Empty value means that address match is not required.
key(default:'())An ordered list of references to keys represented with strings. The string must match a key ID defined in a
knot-key-configuration. No key means that a key is not require to match that ACL.action(default:'())An ordered list of actions that are permitted or forbidden by this ACL. Possible values are lists of zero or more elements from
'transfer,'notifyand'update.deny?(default:#f)When true, the ACL defines restrictions. Listed actions are forbidden. When false, listed actions are allowed.
- Data Type: zone-entry
Data type representing a record entry in a zone file. This type has the following parameters:
name(default:"@")The name of the record.
"@"refers to the origin of the zone. Names are relative to the origin of the zone. For example, in theexample.orgzone,"ns.example.org"actually refers tons.example.org.example.org. Names ending with a dot are absolute, which means that"ns.example.org."refers tons.example.org.ttl(default:"")The Time-To-Live (TTL) of this record. If not set, the default TTL is used.
class(default:"IN")The class of the record. Knot currently supports only
"IN"and partially"CH".type(default:"A")The type of the record. Common types include A (IPv4 address), AAAA (IPv6 address), NS (Name Server) and MX (Mail eXchange). Many other types are defined.
data(default:"")The data contained in the record. For instance an IP address associated with an A record, or a domain name associated with an NS record. Remember that domain names are relative to the origin unless they end with a dot.
- Data Type: zone-file
Data type representing the content of a zone file. This type has the following parameters:
entries(default:'())The list of entries. The SOA record is taken care of, so you don’t need to put it in the list of entries. This list should probably contain an entry for your primary authoritative DNS server. Other than using a list of entries directly, you can use
define-zone-entriesto define a object containing the list of entries more easily, that you can later pass to theentriesfield of thezone-file.origin(default:"")The name of your zone. This parameter cannot be empty.
ns(default:"ns")The domain of your primary authoritative DNS server. The name is relative to the origin, unless it ends with a dot. It is mandatory that this primary DNS server corresponds to an NS record in the zone and that it is associated to an IP address in the list of entries.
mail(default:"hostmaster")An email address people can contact you at, as the owner of the zone. This is translated as
<mail>@<origin>.serial(default:1)The serial number of the zone. As this is used to keep track of changes by both slaves and resolvers, it is mandatory that it never decreases. Always increment it when you make a change in your zone.
refresh(default:(* 2 24 3600))The frequency at which slaves will do a zone transfer. This value is a number of seconds. It can be computed by multiplications or with
(string->duration).retry(default:(* 15 60))The period after which a slave will retry to contact its master when it fails to do so a first time.
expiry(default:(* 14 24 3600))Default TTL of records. Existing records are considered correct for at most this amount of time. After this period, resolvers will invalidate their cache and check again that it still exists.
nx(default:3600)Default TTL of inexistent records. This delay is usually short because you want your new domains to reach everyone quickly.
- Data Type: knot-remote-configuration
Data type representing a remote configuration. This type has the following parameters:
id(default:"")An identifier for other configuration fields to refer to this remote. IDs must be unique and must not be empty.
address(default:'())An ordered list of destination IP addresses. Addresses are tried in sequence. An optional port can be given with the @ separator. For instance:
(list "1.2.3.4" "2.3.4.5@53"). Default port is 53.via(default:'())An ordered list of source IP addresses. An empty list will have Knot choose an appropriate source IP. An optional port can be given with the @ separator. The default is to choose at random.
key(default:#f)A reference to a key, that is a string containing the identifier of a key defined in a
knot-key-configurationfield.
- Data Type: knot-keystore-configuration
Data type representing a keystore to hold dnssec keys. This type has the following parameters:
id(default:"")The id of the keystore. It must not be empty.
backend(default:'pem)The backend to store the keys in. Can be
'pemor'pkcs11.config(default:"/var/lib/knot/keys/keys")The configuration string of the backend. An example for the PKCS#11 is:
"pkcs11:token=knot;pin-value=1234 /gnu/store/.../lib/pkcs11/libsofthsm2.so". For the pem backend, the string represents a path in the file system.
- Data Type: knot-policy-configuration
Data type representing a dnssec policy. Knot DNS is able to automatically sign your zones. It can either generate and manage your keys automatically or use keys that you generate.
Dnssec is usually implemented using two keys: a Key Signing Key (KSK) that is used to sign the second, and a Zone Signing Key (ZSK) that is used to sign the zone. In order to be trusted, the KSK needs to be present in the parent zone (usually a top-level domain). If your registrar supports dnssec, you will have to send them your KSK’s hash so they can add a DS record in their zone. This is not automated and need to be done each time you change your KSK.
The policy also defines the lifetime of keys. Usually, ZSK can be changed easily and use weaker cryptographic functions (they use lower parameters) in order to sign records quickly, so they are changed often. The KSK however requires manual interaction with the registrar, so they are changed less often and use stronger parameters because they sign only one record.
This type has the following parameters:
id(default:"")The id of the policy. It must not be empty.
keystore(default:"default")A reference to a keystore, that is a string containing the identifier of a keystore defined in a
knot-keystore-configurationfield. The"default"identifier means the default keystore (a kasp database that was setup by this service).manual?(default:#f)Whether the key management is manual or automatic.
single-type-signing?(default:#f)When
#t, use the Single-Type Signing Scheme.algorithm(default:"ecdsap256sha256")An algorithm of signing keys and issued signatures.
ksk-size(default:256)The length of the KSK. Note that this value is correct for the default algorithm, but would be unsecure for other algorithms.
zsk-size(default:256)The length of the ZSK. Note that this value is correct for the default algorithm, but would be unsecure for other algorithms.
dnskey-ttl(default:'default)The TTL value for DNSKEY records added into zone apex. The special
'defaultvalue means same as the zone SOA TTL.zsk-lifetime(default:(* 30 24 3600))The period between ZSK publication and the next rollover initiation.
propagation-delay(default:(* 24 3600))An extra delay added for each key rollover step. This value should be high enough to cover propagation of data from the master server to all slaves.
rrsig-lifetime(default:(* 14 24 3600))A validity period of newly issued signatures.
rrsig-refresh(default:(* 7 24 3600))A period how long before a signature expiration the signature will be refreshed.
nsec3?(default:#f)When
#t, NSEC3 will be used instead of NSEC.nsec3-iterations(default:5)The number of additional times the hashing is performed.
nsec3-salt-length(default:8)The length of a salt field in octets, which is appended to the original owner name before hashing.
nsec3-salt-lifetime(default:(* 30 24 3600))The validity period of newly issued salt field.
- Data Type: knot-zone-configuration
Data type representing a zone served by Knot. This type has the following parameters:
domain(default:"")The domain served by this configuration. It must not be empty.
file(default:"")The file where this zone is saved. This parameter is ignored by master zones. Empty means default location that depends on the domain name.
zone(default:(zone-file))The content of the zone file. This parameter is ignored by slave zones. It must contain a zone-file record.
master(default:'())A list of master remotes. When empty, this zone is a master. When set, this zone is a slave. This is a list of remotes identifiers.
ddns-master(default:#f)The main master. When empty, it defaults to the first master in the list of masters.
notify(default:'())A list of slave remote identifiers.
acl(default:'())A list of acl identifiers.
semantic-checks?(default:#f)When set, this adds more semantic checks to the zone.
zonefile-sync(default:0)The delay between a modification in memory and on disk. 0 means immediate synchronization.
zonefile-load(default:#f)The way the zone file contents are applied during zone load. Possible values are:
-
#ffor using the default value from Knot, -
'nonefor not using the zone file at all, -
'differencefor computing the difference between already available contents and zone contents and applying it to the current zone contents, -
'difference-no-serialfor the same as'difference, but ignoring the SOA serial in the zone file, while the server takes care of it automatically. -
'wholefor loading zone contents from the zone file.
-
journal-content(default:#f)The way the journal is used to store zone and its changes. Possible values are
'noneto not use it at all,'changesto store changes and'allto store contents.#fdoes not set this option, so the default value from Knot is used.max-journal-usage(default:#f)The maximum size for the journal on disk.
#fdoes not set this option, so the default value from Knot is used.max-journal-depth(default:#f)The maximum size of the history.
#fdoes not set this option, so the default value from Knot is used.max-zone-size(default:#f)The maximum size of the zone file. This limit is enforced for incoming transfer and updates.
#fdoes not set this option, so the default value from Knot is used.dnssec-policy(default:#f)A reference to a
knot-policy-configurationrecord, or the special name"default". If the value is#f, there is no dnssec signing on this zone.serial-policy(default:'increment)A policy between
'incrementand'unixtime.
- Data Type: knot-configuration
Data type representing the Knot configuration. This type has the following parameters:
knot(default:knot)The Knot package.
run-directory(default:"/var/run/knot")The run directory. This directory will be used for pid file and sockets.
includes(default:'())A list of strings or file-like objects denoting other files that must be included at the top of the configuration file.
This can be used to manage secrets out-of-band. For example, secret keys may be stored in an out-of-band file not managed by Guix, and thus not visible in /gnu/store—e.g., you could store secret key configuration in /etc/knot/secrets.conf and add this file to the
includeslist.One can generate a secret tsig key (for nsupdate and zone transfers with the keymgr command from the knot package. Note that the package is not automatically installed by the service. The following example shows how to generate a new tsig key:
keymgr -t mysecret > /etc/knot/secrets.conf chmod 600 /etc/knot/secrets.conf
Also note that the generated key will be named mysecret, so it is the name that needs to be used in the key field of the
knot-acl-configurationrecord and in other places that need to refer to that key.It can also be used to add configuration not supported by this interface.
listen-v4(default:"0.0.0.0")An ip address on which to listen.
listen-v6(default:"::")An ip address on which to listen.
listen-port(default:53)A port on which to listen.
keys(default:'())The list of knot-key-configuration used by this configuration.
acls(default:'())The list of knot-acl-configuration used by this configuration.
remotes(default:'())The list of knot-remote-configuration used by this configuration.
zones(default:'())The list of knot-zone-configuration used by this configuration.
Сервисы Kerberos
- Scheme Variable: knot-resolver-service-type
This is the type of the knot resolver service, whose value should be an
knot-resolver-configurationobject as in this example:(service knot-resolver-service-type (knot-resolver-configuration (kresd-config-file (plain-file "kresd.conf" " net.listen('192.168.0.1', 5353) user('knot-resolver', 'knot-resolver') modules = { 'hints > iterate', 'stats', 'predict' } cache.size = 100 * MB "))))For more information, refer its manual.
- Data Type: knot-resolver-configuration
Управление конфигурацией операционной системы.
port(default:22)Package object of the knot DNS resolver.
compression-level(default:3)File-like object of the kresd configuration file to use, by default it will listen on
127.0.0.1and::1.parallel-builds(default:1)Number of milliseconds for
kres-cache-gcto periodically trim the cache.
Dnsmasq Service
- Scheme Variable: dnsmasq-service-type
This is the type of the dnsmasq service, whose value should be an
dnsmasq-configurationobject as in this example:(service dnsmasq-service-type (dnsmasq-configuration (no-resolv? #t) (servers '("192.168.1.1"))))
- Data Type: dnsmasq-configuration
Data type representing the configuration of dnsmasq.
package(default: dnsmasq)Package object of the dnsmasq server.
no-hosts?(default:#f)When true, don’t read the hostnames in /etc/hosts.
port(default:53)The port to listen on. Setting this to zero completely disables DNS responses, leaving only DHCP and/or TFTP functions.
local-service?(default:#t)Accept DNS queries only from hosts whose address is on a local subnet, ie a subnet for which an interface exists on the server.
listen-addresses(default:'())Listen on the given IP addresses.
resolv-file(default:"/etc/resolv.conf")The file to read the IP address of the upstream nameservers from.
no-resolv?(default:#f)When true, don’t read resolv-file.
forward-private-reverse-lookup?(default:#t)When false, all reverse lookups for private IP ranges are answered with "no such domain" rather than being forwarded upstream.
query-servers-in-order?(default:#f)When true, dnsmasq queries the servers in the same order as they appear in servers.
servers(default:'())Specify IP address of upstream servers directly.
features(default:'())For each entry, specify an IP address to return for any host in the given domains. Queries in the domains are never forwarded and always replied to with the specified IP address.
This is useful for redirecting hosts locally, for example:
(service dnsmasq-service-type (dnsmasq-configuration (addresses '(; Redirect to a local web-server. "/example.org/127.0.0.1" ; Redirect subdomain to a specific IP. "/subdomain.example.org/192.168.1.42"))))Note that rules in /etc/hosts take precedence over this.
cache-size(default:150)Set the size of dnsmasq’s cache. Setting the cache size to zero disables caching.
negative-cache?(default:#t)When false, disable negative caching.
cpe-id(default:#f)If set, add a CPE (Customer-Premises Equipment) identifier to DNS queries which are forwarded upstream.
speed(default:1.0)Whether to enable the built-in TFTP server.
speed(default:1.0)If true, does not fail dnsmasq if the TFTP server could not start up.
port(default:22)Whether to use only one single port for TFTP.
speed(default:1.0)If true, only files owned by the user running the dnsmasq process are accessible.
If dnsmasq is being run as root, different rules apply:
tftp-secure?has no effect, but only files which have the world-readable bit set are accessible.speed(default:1.0)If set, sets the maximal number of concurrent connections allowed.
port(default:22)If set, sets the MTU for TFTP packets to that value.
port(default:22)If true, stops the TFTP server from negotiating the blocksize with a client.
port(default:22)Whether to convert all filenames in TFTP requests to lowercase.
port(default:22)If set, fixes the dynamical ports (one per client) to the given range (
"<start>,<end>").port(default:22)Look for files to transfer using TFTP relative to the given directory. When this is set, TFTP paths which include ‘..’ are rejected, to stop clients getting outside the specified root. Absolute paths (starting with ‘/’) are allowed, but they must be within the TFTP-root. If the optional interface argument is given, the directory is only used for TFTP requests via that interface.
port(default:22)If set, add the IP or hardware address of the TFTP client as a path component on the end of the TFTP-root. Only valid if a TFTP root is set and the directory exists. Defaults to adding IP address (in standard dotted-quad format).
For instance, if --tftp-root is ‘/tftp’ and client ‘1.2.3.4’ requests file myfile then the effective path will be /tftp/1.2.3.4/myfile if /tftp/1.2.3.4 exists or /tftp/myfile otherwise. When ‘=mac’ is specified it will append the MAC address instead, using lowercase zero padded digits separated by dashes, e.g.: ‘01-02-03-04-aa-bb’. Note that resolving MAC addresses is only possible if the client is in the local network or obtained a DHCP lease from dnsmasq.
ddclient Service
The ddclient service described below runs the ddclient daemon, which takes care of automatically updating DNS entries for service providers such as Dyn.
The following example show instantiates the service with its default configuration:
(service ddclient-service-type)
Note that ddclient needs to access credentials that are stored in a
secret file, by default /etc/ddclient/secrets (see
secret-file below). You are expected to create this file manually,
in an “out-of-band” fashion (you could make this file part of the
service configuration, for instance by using plain-file, but it will
be world-readable via /gnu/store). See the examples in the
share/ddclient directory of the ddclient package.
Available ddclient-configuration fields are:
ddclient-configurationparameter: package ddclient ¶The ddclient package.
ddclient-configurationparameter: integer daemon ¶The period after which ddclient will retry to check IP and domain name.
Defaults to ‘300’.
ddclient-configurationparameter: boolean syslog ¶Use syslog for the output.
Defaults to ‘#t’.
ddclient-configurationparameter: string mail ¶Mail to user.
Defaults to ‘"root"’.
ddclient-configurationparameter: string mail-failure ¶Mail failed update to user.
Defaults to ‘"root"’.
ddclient-configurationparameter: string pid ¶The ddclient PID file.
Defaults to ‘"/var/run/ddclient/ddclient.pid"’.
ddclient-configurationparameter: boolean ssl ¶Enable SSL support.
Defaults to ‘#t’.
ddclient-configurationparameter: string user ¶Specifies the user name or ID that is used when running ddclient program.
Defaults to ‘"ddclient"’.
ddclient-configurationparameter: string group ¶Group of the user who will run the ddclient program.
Defaults to ‘"ddclient"’.
ddclient-configurationparameter: string secret-file ¶Secret file which will be appended to ddclient.conf file. This file contains credentials for use by ddclient. You are expected to create it manually.
Defaults to ‘"/etc/ddclient/secrets.conf"’.
ddclient-configurationparameter: list extra-options ¶Extra options will be appended to ddclient.conf file.
Defaults to ‘()’.
Next: VPN-сервисы, Previous: Сервисы DNS, Up: Сервисы [Contents][Index]
12.9.22 VNC Services
The (gnu services vnc) module provides services related to
Virtual Network Computing (VNC), which makes it possible to locally
use graphical Xorg applications running on a remote machine. Combined with
a graphical manager that supports the X Display Manager Control
Protocol, such as GDM (see gdm) or LightDM (see lightdm), it is
possible to remote an entire desktop for a multi-user environment.
Xvnc
Xvnc is a VNC server that spawns its own X window server; which means it can
run on headless servers. The Xvnc implementations provided by the
tigervnc-server and turbovnc aim to be fast and efficient.
- Variable: Scheme Variable xvnc-service-type
-
The
xvnc-server-typeservice can be configured via thexvnc-configurationrecord, documented below. A second virtual display could be made available on a remote machine via the following configuration:
(service xvnc-service-type
(xvnc-configuration (display-number 10)))
As a demonstration, the xclock command could then be started on
the remote machine on display number 10, and it could be displayed locally
via the vncviewer command:
# Start xclock on the remote machine. ssh -L5910:localhost:5910 -- guix shell xclock -- env DISPLAY=:10 xclock # Access it via VNC. guix shell tigervnc-client -- vncviewer localhost:5910
The following configuration combines XDMCP and Inetd to allow multiple users to concurrently use the remote system, login in graphically via the GDM display manager:
(operating-system
[...]
(services (cons*
[...]
(service xvnc-service-type (xvnc-configuration
(display-number 5)
(localhost? #f)
(xdmcp? #t)
(inetd? #t)))
(modify-services %desktop-services
(gdm-service-type config => (gdm-configuration
(inherit config)
(auto-suspend? #f)
(xdmcp? #t)))))))
A remote user could then connect to it by using the vncviewer
command or a compatible VNC client and start a desktop session of their
choosing:
vncviewer remote-host:5905
Внимание: Unless your machine is in a controlled environment, for security reasons, the
localhost?configuration of thexvnc-configurationrecord should be left to its default#tvalue and exposed via a secure means such as an SSH port forward. The XDMCP port, UDP 177 should also be blocked from the outside by a firewall, as it is not a secure protocol and can expose login credentials in clear.
- Data Type: xvnc-configuration
Available
xvnc-configurationfields are:xvnc(default:tigervnc-server) (type: file-like)The package that provides the Xvnc binary.
display-number(default:0) (type: number)The display number used by Xvnc. You should set this to a number not already used a Xorg server.
geometry(default:"1024x768") (type: string)The size of the desktop to be created.
depth(default:24) (type: color-depth)The pixel depth in bits of the desktop to be created. Accepted values are 16, 24 or 32.
port(type: maybe-port)The port on which to listen for connections from viewers. When left unspecified, it defaults to 5900 plus the display number.
ipv4?(default:#t) (type: boolean)Use IPv4 for incoming and outgoing connections.
ipv6?(default:#t) (type: boolean)Use IPv6 for incoming and outgoing connections.
password-file(type: maybe-string)The password file to use, if any. Refer to vncpasswd(1) to learn how to generate such a file.
xdmcp?(default:#f) (type: boolean)Query the XDMCP server for a session. This enables users to log in a desktop session from the login manager screen. For a multiple users scenario, you’ll want to enable the
inetd?option as well, so that each connection to the VNC server is handled separately rather than shared.inetd?(default:#f) (type: boolean)Use an Inetd-style service, which runs the Xvnc server on demand.
frame-rate(default:60) (type: number)The maximum number of updates per second sent to each client.
security-types(default:("None")) (type: security-types)The allowed security schemes to use for incoming connections. The default is "None", which is safe given that Xvnc is configured to authenticate the user via the display manager, and only for local connections. Accepted values are any of the following: ("None" "VncAuth" "Plain" "TLSNone" "TLSVnc" "TLSPlain" "X509None" "X509Vnc")
localhost?(default:#t) (type: boolean)Only allow connections from the same machine. It is set to #true by default for security, which means SSH or another secure means should be used to expose the remote port.
log-level(default:30) (type: log-level)The log level, a number between 0 and 100, 100 meaning most verbose output. The log messages are output to syslog.
extra-options(default:()) (type: strings)This can be used to provide extra Xvnc options not exposed via this <xvnc-configuration> record.
Next: Сетевые файловые системы, Previous: VNC Services, Up: Сервисы [Contents][Index]
12.9.23 VPN-сервисы
Модуль (gnu services file-sharing) предоставляет следующие сервисы,
помогающие с передачей файлов через одноранговые сети.
Bitmask
- Scheme Variable: bitmask-service-type
A service type for the Bitmask VPN client. It makes the client available in the system and loads its polkit policy. Please note that the client expects an active polkit-agent, which is either run by your desktop-environment or should be run manually.
OpenVPN
It provides a client service for your machine to connect to a VPN, and a server service for your machine to host a VPN.
- Scheme Procedure: openvpn-client-service [#:config (openvpn-client-configuration)]
-
Return a service that runs
openvpn, a VPN daemon, as a client.
- Scheme Procedure: openvpn-server-service [#:config (openvpn-server-configuration)]
-
Return a service that runs
openvpn, a VPN daemon, as a server.Both can be run simultaneously.
- Data Type: openvpn-client-configuration
Available
openvpn-client-configurationfields are:openvpn(default:openvpn) (type: file-like)The OpenVPN package.
pid-file(default:"/var/run/openvpn/openvpn.pid") (type: string)The OpenVPN pid file.
proto(default:udp) (type: proto)The protocol (UDP or TCP) used to open a channel between clients and servers.
dev(default:tun) (type: dev)The device type used to represent the VPN connection.
ca(default:"/etc/openvpn/ca.crt") (type: maybe-string)The certificate authority to check connections against.
cert(default:"/etc/openvpn/client.crt") (type: maybe-string)The certificate of the machine the daemon is running on. It should be signed by the authority given in
ca.key(default:"/etc/openvpn/client.key") (type: maybe-string)The key of the machine the daemon is running on. It must be the key whose certificate is
cert.comp-lzo?(default:#t) (type: boolean)Whether to use the lzo compression algorithm.
persist-key?(default:#t) (type: boolean)Don’t re-read key files across SIGUSR1 or –ping-restart.
persist-tun?(default:#t) (type: boolean)Don’t close and reopen TUN/TAP device or run up/down scripts across SIGUSR1 or –ping-restart restarts.
fast-io?(default:#f) (type: boolean)(Experimental) Optimize TUN/TAP/UDP I/O writes by avoiding a call to poll/epoll/select prior to the write operation.
verbosity(default:3) (type: number)Verbosity level.
tls-auth(default:#f) (type: tls-auth-client)Add an additional layer of HMAC authentication on top of the TLS control channel to protect against DoS attacks.
auth-user-pass(type: maybe-string)Authenticate with server using username/password. The option is a file containing username/password on 2 lines. Do not use a file-like object as it would be added to the store and readable by any user.
verify-key-usage?(default:#t) (type: key-usage)Whether to check the server certificate has server usage extension.
bind?(default:#f) (type: bind)Bind to a specific local port number.
resolv-retry?(default:#t) (type: resolv-retry)Retry resolving server address.
remote(default:()) (type: openvpn-remote-list)A list of remote servers to connect to.
- Data Type: openvpn-remote-configuration
Available
openvpn-remote-configurationfields are:name(default:"my-server") (type: string)Server name.
port(default:1194) (type: number)Port number the server listens to.
- Data Type: openvpn-server-configuration
Available
openvpn-server-configurationfields are:openvpn(default:openvpn) (type: file-like)The OpenVPN package.
pid-file(default:"/var/run/openvpn/openvpn.pid") (type: string)The OpenVPN pid file.
proto(default:udp) (type: proto)The protocol (UDP or TCP) used to open a channel between clients and servers.
dev(default:tun) (type: dev)The device type used to represent the VPN connection.
ca(default:"/etc/openvpn/ca.crt") (type: maybe-string)The certificate authority to check connections against.
cert(default:"/etc/openvpn/client.crt") (type: maybe-string)The certificate of the machine the daemon is running on. It should be signed by the authority given in
ca.key(default:"/etc/openvpn/client.key") (type: maybe-string)The key of the machine the daemon is running on. It must be the key whose certificate is
cert.comp-lzo?(default:#t) (type: boolean)Whether to use the lzo compression algorithm.
persist-key?(default:#t) (type: boolean)Don’t re-read key files across SIGUSR1 or –ping-restart.
persist-tun?(default:#t) (type: boolean)Don’t close and reopen TUN/TAP device or run up/down scripts across SIGUSR1 or –ping-restart restarts.
fast-io?(default:#f) (type: boolean)(Experimental) Optimize TUN/TAP/UDP I/O writes by avoiding a call to poll/epoll/select prior to the write operation.
verbosity(default:3) (type: number)Verbosity level.
tls-auth(default:#f) (type: tls-auth-server)Add an additional layer of HMAC authentication on top of the TLS control channel to protect against DoS attacks.
port(default:1194) (type: number)Specifies the port number on which the server listens.
server(default:"10.8.0.0 255.255.255.0") (type: ip-mask)An ip and mask specifying the subnet inside the virtual network.
server-ipv6(default:#f) (type: cidr6)A CIDR notation specifying the IPv6 subnet inside the virtual network.
dh(default:"/etc/openvpn/dh2048.pem") (type: string)The Diffie-Hellman parameters file.
ifconfig-pool-persist(default:"/etc/openvpn/ipp.txt") (type: string)The file that records client IPs.
redirect-gateway?(default:#f) (type: gateway)When true, the server will act as a gateway for its clients.
client-to-client?(default:#f) (type: boolean)When true, clients are allowed to talk to each other inside the VPN.
keepalive(default:(10 120)) (type: keepalive)Causes ping-like messages to be sent back and forth over the link so that each side knows when the other side has gone down.
keepaliverequires a pair. The first element is the period of the ping sending, and the second element is the timeout before considering the other side down.max-clients(default:100) (type: number)The maximum number of clients.
status(default:"/var/run/openvpn/status") (type: string)The status file. This file shows a small report on current connection. It is truncated and rewritten every minute.
client-config-dir(default:()) (type: openvpn-ccd-list)The list of configuration for some clients.
strongSwan
Currently, the strongSwan service only provides legacy-style configuration with ipsec.conf and ipsec.secrets files.
- Scheme Variable: strongswan-service-type
A service type for configuring strongSwan for IPsec VPN (Virtual Private Networking). Its value must be a
strongswan-configurationrecord as in this example:(service strongswan-service-type (strongswan-configuration (ipsec-conf "/etc/ipsec.conf") (ipsec-secrets "/etc/ipsec.secrets")))
- Data Type: strongswan-configuration
Data type representing the configuration of the StrongSwan service.
strongswanThe strongSwan package to use for this service.
ipsec-conf(default:#f)The file name of your ipsec.conf. If not
#f, then this andipsec-secretsmust both be strings.ipsec-secrets(default#f)The file name of your ipsec.secrets. If not
#f, then this andipsec-confmust both be strings.
Wireguard
- Процедура Scheme: sane-service-type
A service type for a Wireguard tunnel interface. Its value must be a
wireguard-configurationrecord as in this example:
- Тип данных: build-machine
Управление конфигурацией операционной системы.
wireguardПакет
ganetiдля использования в этой службе.port(default:22)The interface name for the VPN.
speed(default:1.0)The IP addresses to be assigned to the above interface.
port(default:51820)The port on which to listen for incoming connections.
dns(default:#f)The DNS server(s) to announce to VPN clients via DHCP.
features(default:'())The private key file for the interface. It is automatically generated if the file does not exist.
features(default:'())The authorized peers on this interface. This is a list of wireguard-peer records.
pre-up(default:'())The script commands to be run before setting up the interface.
post-up(default:'())The script commands to be run after setting up the interface.
pre-down(default:'())The script commands to be run before tearing down the interface.
post-down(default:'())The script commands to be run after tearing down the interface.
table(default:"auto")The routing table to which routes are added, as a string. There are two special values:
"off"that disables the creation of routes altogether, and"auto"(the default) that adds routes to the default table and enables special handling of default routes.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
nameИмя роли.
port(default:22)The optional endpoint for the peer, such as
"demo.wireguard.com:51820".public-keyThe peer public-key represented as a base64 string.
allowed-ipsA list of IP addresses from which incoming traffic for this peer is allowed and to which incoming traffic for this peer is directed.
speed(default:1.0)An optional time interval in seconds. A packet will be sent to the server endpoint once per time interval. This helps receiving incoming connections from this peer when you are behind a NAT or a firewall.
Next: Samba Services, Previous: VPN-сервисы, Up: Сервисы [Contents][Index]
12.9.24 Сетевые файловые системы
The (gnu services nfs) module provides the following services, which
are most commonly used in relation to mounting or exporting directory trees
as network file systems (NFS).
While it is possible to use the individual components that together make up
a Network File System service, we recommended to configure an NFS server
with the nfs-service-type.
Сервисы DNS
The NFS service takes care of setting up all NFS component services, kernel configuration file systems, and installs configuration files in the locations that NFS expects.
- Scheme Variable: nfs-service-type
A service type for a complete NFS server.
- Конфигурирование: системы
This data type represents the configuration of the NFS service and all of its subsystems.
GNU Guix зависит от следующих пакетов:
nfs-utils(default:nfs-utils)Используемый пакет nfs-utils.
speed(default:1.0)If a list of string values is provided, the
rpc.nfsddaemon will be limited to supporting the given versions of the NFS protocol.port(default:22)This is a list of directories the NFS server should export. Each entry is a list consisting of two elements: a directory name and a string containing all options. This is an example in which the directory /export is served to all NFS clients as a read-only share:
(nfs-configuration (exports '(("/export" "*(ro,insecure,no_subtree_check,crossmnt,fsid=0)"))))port(default:22)The network port that the
rpc.mountddaemon should use.port(default:22)The network port that the
rpc.statddaemon should use.rpcbind(default:rpcbind)The rpcbind package to use.
port(default:22)The local NFSv4 domain name.
port(default:22)The network port that the
nfsddaemon should use.features(default:'())The number of threads used by the
nfsddaemon.port(default:22)Whether the
nfsddaemon should listen on a TCP socket.port(default:22)Whether the
nfsddaemon should listen on a UDP socket.pipefs-directory(default:"/var/lib/nfs/rpc_pipefs")The directory where the pipefs file system is mounted.
features(default:'())A list of subsystems for which debugging output should be enabled. This is a list of symbols. Any of these symbols are valid:
nfsd,nfs,rpc,idmap,statd, ormountd.
If you don’t need a complete NFS service or prefer to build it yourself you can use the individual component services that are documented below.
RPC Bind Service
The RPC Bind service provides a facility to map program numbers into universal addresses. Many NFS related services use this facility. Hence it is automatically started when a dependent service starts.
- Scheme Variable: rpcbind-service-type
A service type for the RPC portmapper daemon.
- Data Type: rpcbind-configuration
Data type representing the configuration of the RPC Bind Service. This type has the following parameters:
rpcbind(default:rpcbind)The rpcbind package to use.
warm-start?(default:#t)If this parameter is
#t, then the daemon will read a state file on startup thus reloading state information saved by a previous instance.
Pipefs Pseudo File System
The pipefs file system is used to transfer NFS related data between the kernel and user space programs.
- Scheme Variable: pipefs-service-type
A service type for the pipefs pseudo file system.
- Data Type: pipefs-configuration
Data type representing the configuration of the pipefs pseudo file system service. This type has the following parameters:
mount-point(default:"/var/lib/nfs/rpc_pipefs")The directory to which the file system is to be attached.
GSS Daemon Service
The global security system (GSS) daemon provides strong security for
RPC based protocols. Before exchanging RPC requests an RPC client must
establish a security context. Typically this is done using the Kerberos
command kinit or automatically at login time using PAM services
(see Сервисы Kerberos).
- Scheme Variable: gss-service-type
A service type for the Global Security System (GSS) daemon.
- Data Type: gss-configuration
Data type representing the configuration of the GSS daemon service. This type has the following parameters:
nfs-utils(default:nfs-utils)The package in which the
rpc.gssdcommand is to be found.pipefs-directory(default:"/var/lib/nfs/rpc_pipefs")The directory where the pipefs file system is mounted.
IDMAP Daemon Service
The idmap daemon service provides mapping between user IDs and user names. Typically it is required in order to access file systems mounted via NFSv4.
- Scheme Variable: idmap-service-type
A service type for the Identity Mapper (IDMAP) daemon.
- Data Type: idmap-configuration
Data type representing the configuration of the IDMAP daemon service. This type has the following parameters:
nfs-utils(default:nfs-utils)The package in which the
rpc.idmapdcommand is to be found.pipefs-directory(default:"/var/lib/nfs/rpc_pipefs")The directory where the pipefs file system is mounted.
domain(default:#f)The local NFSv4 domain name. This must be a string or
#f. If it is#fthen the daemon will use the host’s fully qualified domain name.port(default:22)Уровень детализации демона.
Next: Длительная интеграция, Previous: Сетевые файловые системы, Up: Сервисы [Contents][Index]
12.9.25 Samba Services
The (gnu services samba) module provides service definitions for
Samba as well as additional helper services. Currently it provides the
following services.
Samba
Samba provides network shares for folders and printers using the SMB/CIFS protocol commonly used on Windows. It can also act as an Active Directory Domain Controller (AD DC) for other hosts in an heterougenious network with different types of Computer systems.
- Variable: Scheme variable samba-service-type
-
The service type to enable the samba services
samba,nmbd,smbdandwinbindd. By default this service type does not run any of the Samba daemons; they must be enabled individually.Below is a basic example that configures a simple, anonymous (unauthenticated) Samba file share exposing the /public directory.
Tip: The /public directory and its contents must be world readable/writable, so you’ll want to run ‘chmod -R 777 /public’ on it.
Caution: Such a Samba configuration should only be used in controlled environments, and you should not share any private files using it, as anyone connecting to your network would be able to access them.
(service samba-service-type (samba-configuration (enable-smbd? #t) (config-file (plain-file "smb.conf" "\ [global] map to guest = Bad User logging = syslog@1 [public] browsable = yes path = /public read only = no guest ok = yes guest only = yes\n"))))
- Data Type: samba-service-configuration Configuration record for the
Samba suite.
package(default:samba)The samba package to use.
config-file(default:#f)The config file to use. To learn about its syntax, run ‘man smb.conf’.
enable-samba?(default:#f)Enable the
sambadaemon.enable-smbd?(default:#f)Enable the
smbddaemon.enable-nmbd?(default:#f)Enable the
nmbddaemon.enable-winbindd?(default:#f)Enable the
winbindddaemon.
Web Service Discovery Daemon
The WSDD (Web Service Discovery daemon) implements the Web Services Dynamic Discovery protocol that enables host discovery over Multicast DNS, similar to what Avahi does. It is a drop-in replacement for SMB hosts that have had SMBv1 disabled for security reasons.
- Scheme Variable: wsdd-service-type
Service type for the WSD host daemon. The value for this service type is a
wsdd-configurationrecord. The details for thewsdd-configurationrecord type are given below.
- Data Type: wsdd-configuration
This data type represents the configuration for the wsdd service.
package(default:wsdd)The wsdd package to use.
ipv4only?(default:#f)Only listen to IPv4 addresses.
ipv6only(default:#f)Only listen to IPv6 addresses. Please note: Activating both options is not possible, since there would be no IP versions to listen to.
chroot(default:#f)Chroot into a separate directory to prevent access to other directories. This is to increase security in case there is a vulnerability in
wsdd.hop-limit(default:1)Limit to the level of hops for multicast packets. The default is 1 which should prevent packets from leaving the local network.
interface(default:'())Limit to the given list of interfaces to listen to. By default wsdd will listen to all interfaces. Except the loopback interface is never used.
uuid-device(default:#f)The WSD protocol requires a device to have a UUID. Set this to manually assign the service a UUID.
domain(default:#f)Notify this host is a member of an Active Directory.
host-name(default:#f)Manually set the hostname rather than letting
wsddinherit this host’s hostname. Only the host name part of a possible FQDN will be used in the default case.preserve-case?(default:#f)By default
wsddwill convert the hostname in workgroup to all uppercase. The opposite is true for hostnames in domains. Setting this parameter will preserve case.workgroup(default: "WORKGROUP")Change the name of the workgroup. By default
wsddreports this host being member of a workgroup.
Next: Сервисы управления питанием, Previous: Samba Services, Up: Сервисы [Contents][Index]
12.9.26 Длительная интеграция
Cuirass is a continuous integration tool for Guix. It can be used both for development and for providing substitutes to others (see Подстановки).
The (gnu services cuirass) module provides the following service.
- Scheme Procedure: cuirass-service-type
The type of the Cuirass service. Its value must be a
cuirass-configurationobject, as described below.
To add build jobs, you have to set the specifications field of the
configuration. For instance, the following example will build all the
packages provided by the my-channel channel.
(define %cuirass-specs #~(list (specification (name "my-channel") (build '(channels my-channel)) (channels (cons (channel (name 'my-channel) (url "https://my-channel.git")) %default-channels))))) (service cuirass-service-type (cuirass-configuration (specifications %cuirass-specs)))
To build the linux-libre package defined by the default Guix channel,
one can use the following configuration.
(define %cuirass-specs #~(list (specification (name "my-linux") (build '(packages "linux-libre"))))) (service cuirass-service-type (cuirass-configuration (specifications %cuirass-specs)))
The other configuration possibilities, as well as the specification record itself are described in the Cuirass manual (see Specifications in Cuirass).
While information related to build jobs is located directly in the
specifications, global settings for the cuirass process are
accessible in other cuirass-configuration fields.
- Data Type: cuirass-configuration
Data type representing the configuration of Cuirass.
cuirass(default:cuirass)The Cuirass package to use.
log-file(default:"/var/log/cuirass.log")Location of the log file.
daemon-socket(default:"/var/guix/daemon-socket/socket")Location of the log file used by the web interface.
cache-directory(default:"/var/cache/cuirass")Location of the repository cache.
user(default:"cuirass")Owner of the
cuirassprocess.group(default:"cuirass")Owner’s group of the
cuirassprocess.interval(default:60)Number of seconds between the poll of the repositories followed by the Cuirass jobs.
port(default:22)Read parameters from the given parameters file. The supported parameters are described here (see Parameters in Cuirass).
features(default:'())A
cuirass-remote-server-configurationrecord to use the build remote mechanism or#fto use the default build mechanism.port(default:22)Use database as the database containing the jobs and the past build results. Since Cuirass uses PostgreSQL as a database engine, database must be a string such as
"dbname=cuirass host=localhost".port(default:8081)Port number used by the HTTP server.
host(default:"localhost")Listen on the network interface for host. The default is to accept connections from localhost.
specifications(default:#~'())A gexp (see G-Expressions) that evaluates to a list of specifications records. The specification record is described in the Cuirass manual (see Specifications in Cuirass).
use-substitutes?(default:#f)This allows using substitutes to avoid building every dependencies of a job from source.
one-shot?(default:#f)Only evaluate specifications and build derivations once.
fallback?(default:#f)When substituting a pre-built binary fails, fall back to building packages locally.
extra-options(default:'())Extra options to pass when running the Cuirass processes.
последний коммит, сборка
Cuirass supports two mechanisms to build derivations.
- Запуск демона сборки. This is the default build mechanism. Once the build jobs are evaluated, they are sent to the local Guix daemon. Cuirass then listens to the Guix daemon output to detect the various build events.
- Подготовка отдельного окружения сборки. The build jobs are not submitted to the local Guix daemon. Instead, a remote server dispatches build requests to the connect remote workers, according to the build priorities.
To enable this build mode a cuirass-remote-server-configuration
record must be passed as remote-server argument of the
cuirass-configuration record. The
cuirass-remote-server-configuration record is described below.
This build mode scales way better than the default build mode. This is the build mode that is used on the GNU Guix build farm at https://ci.guix.gnu.org. It should be preferred when using Cuirass to build large amount of packages.
- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
port(default:22)The TCP port for communicating with
remote-workerprocesses using ZMQ. It defaults to5555.port(default:22)The TCP port of the log server. It defaults to
5556.port(default:22)The TCP port of the publish server. It defaults to
5557.daemon-socket(default:"/var/guix/daemon-socket/socket")Location of the log file.
daemon-socket(default:"/var/guix/daemon-socket/socket")Use cache directory to cache build log files.
features(default:'())Once a substitute is successfully fetched, trigger substitute baking at trigger-url.
publish?(default:#t)If set to false, do not start a publish server and ignore the
publish-portargument. This can be useful if there is already a standalone publish server standing next to the remote server.public-keyprivate-keyUse the specific files as the public/private key pair used to sign the store items being published.
At least one remote worker must also be started on any machine of the local network to actually perform the builds and report their status.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
cuirass(default:cuirass)The Cuirass package to use.
features(default:'())Start workers parallel workers.
features(default:'())Do not use Avahi discovery and connect to the given
serverIP address instead.port(default:22)Only request builds for the given systems.
daemon-socket(default:"/var/guix/daemon-socket/socket")Location of the log file.
port(default:22)The TCP port of the publish server. It defaults to
5558.port(default:22)The list of URLs where to look for substitutes by default.
public-keyprivate-keyUse the specific files as the public/private key pair used to sign the store items being published.
Laminar
Laminar is a lightweight and modular Continuous Integration service. It doesn’t have a configuration web UI instead uses version-controllable configuration files and scripts.
Laminar encourages the use of existing tools such as bash and cron instead of reinventing them.
- Процедура Scheme: sane-service-type
The type of the Laminar service. Its value must be a
laminar-configurationobject, as described below.All configuration values have defaults, a minimal configuration to get Laminar running is shown below. By default, the web interface is available on port 8080.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет Mumi.
port(default:22)The directory for job configurations and run directories.
port(default:22)The interface/port or unix socket on which laminard should listen for incoming connections to the web frontend.
port(default:22)The interface/port or unix socket on which laminard should listen for incoming commands such as build triggers.
port(default:22)Сервис rottlog.
features(default:'())Set to an integer defining how many rundirs to keep per job. The lowest-numbered ones will be deleted. The default is 0, meaning all run dirs will be immediately deleted.
features(default:'())The web frontend served by laminard will use this URL to form links to artefacts archived jobs.
features(default:'())URI для использования в базе данных.
Next: Сервисы аудио, Previous: Длительная интеграция, Up: Сервисы [Contents][Index]
12.9.27 Сервисы управления питанием
TLP daemon
The (gnu services pm) module provides a Guix service definition for
the Linux power management tool TLP.
TLP enables various powersaving modes in userspace and kernel. Contrary to
upower-service, it is not a passive, monitoring tool, as it will
apply custom settings each time a new power source is detected. More
information can be found at TLP
home page.
- Scheme Variable: tlp-service-type
The service type for the TLP tool. The default settings are optimised for battery life on most systems, but you can tweak them to your heart’s content by adding a valid
tlp-configuration:(service tlp-service-type (tlp-configuration (cpu-scaling-governor-on-ac (list "performance")) (sched-powersave-on-bat? #t)))
Each parameter definition is preceded by its type; for example,
‘boolean foo’ indicates that the foo parameter should be
specified as a boolean. Types starting with maybe- denote parameters
that won’t show up in TLP config file when their value is left unset, or is
explicitly set to the %unset-value value.
Available tlp-configuration fields are:
tlp-configurationparameter: package tlp ¶The TLP package.
tlp-configurationparameter: boolean tlp-enable? ¶Set to true if you wish to enable TLP.
Defaults to ‘#t’.
tlp-configurationparameter: string tlp-default-mode ¶Default mode when no power supply can be detected. Alternatives are AC and BAT.
Defaults to ‘"AC"’.
tlp-configurationparameter: non-negative-integer disk-idle-secs-on-ac ¶Number of seconds Linux kernel has to wait after the disk goes idle, before syncing on AC.
Defaults to ‘0’.
tlp-configurationparameter: non-negative-integer disk-idle-secs-on-bat ¶Same as
disk-idle-acbut on BAT mode.Defaults to ‘2’.
tlp-configurationparameter: non-negative-integer max-lost-work-secs-on-ac ¶Dirty pages flushing periodicity, expressed in seconds.
Defaults to ‘15’.
tlp-configurationparameter: non-negative-integer max-lost-work-secs-on-bat ¶Same as
max-lost-work-secs-on-acbut on BAT mode.Defaults to ‘60’.
tlp-configurationparameter: maybe-space-separated-string-list cpu-scaling-governor-on-ac ¶CPU frequency scaling governor on AC mode. With intel_pstate driver, alternatives are powersave and performance. With acpi-cpufreq driver, alternatives are ondemand, powersave, performance and conservative.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-space-separated-string-list cpu-scaling-governor-on-bat ¶Same as
cpu-scaling-governor-on-acbut on BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-scaling-min-freq-on-ac ¶Set the min available frequency for the scaling governor on AC.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-scaling-max-freq-on-ac ¶Set the max available frequency for the scaling governor on AC.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-scaling-min-freq-on-bat ¶Set the min available frequency for the scaling governor on BAT.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-scaling-max-freq-on-bat ¶Set the max available frequency for the scaling governor on BAT.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-min-perf-on-ac ¶Limit the min P-state to control the power dissipation of the CPU, in AC mode. Values are stated as a percentage of the available performance.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-max-perf-on-ac ¶Limit the max P-state to control the power dissipation of the CPU, in AC mode. Values are stated as a percentage of the available performance.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-min-perf-on-bat ¶Same as
cpu-min-perf-on-acon BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer cpu-max-perf-on-bat ¶Same as
cpu-max-perf-on-acon BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: maybe-boolean cpu-boost-on-ac? ¶Enable CPU turbo boost feature on AC mode.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-boolean cpu-boost-on-bat? ¶Same as
cpu-boost-on-ac?on BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: boolean sched-powersave-on-ac? ¶Allow Linux kernel to minimize the number of CPU cores/hyper-threads used under light load conditions.
Defaults to ‘#f’.
tlp-configurationparameter: boolean sched-powersave-on-bat? ¶Same as
sched-powersave-on-ac?but on BAT mode.Defaults to ‘#t’.
tlp-configurationparameter: boolean nmi-watchdog? ¶Enable Linux kernel NMI watchdog.
Defaults to ‘#f’.
tlp-configurationparameter: maybe-string phc-controls ¶For Linux kernels with PHC patch applied, change CPU voltages. An example value would be ‘"F:V F:V F:V F:V"’.
Defaults to ‘disabled’.
tlp-configurationparameter: string energy-perf-policy-on-ac ¶Set CPU performance versus energy saving policy on AC. Alternatives are performance, normal, powersave.
Defaults to ‘"performance"’.
tlp-configurationparameter: string energy-perf-policy-on-bat ¶Same as
energy-perf-policy-acbut on BAT mode.Defaults to ‘"powersave"’.
tlp-configurationparameter: space-separated-string-list disks-devices ¶Hard disk devices.
tlp-configurationparameter: space-separated-string-list disk-apm-level-on-ac ¶Hard disk advanced power management level.
tlp-configurationparameter: space-separated-string-list disk-apm-level-on-bat ¶Same as
disk-apm-batbut on BAT mode.
tlp-configurationparameter: maybe-space-separated-string-list disk-spindown-timeout-on-ac ¶Hard disk spin down timeout. One value has to be specified for each declared hard disk.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-space-separated-string-list disk-spindown-timeout-on-bat ¶Same as
disk-spindown-timeout-on-acbut on BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: maybe-space-separated-string-list disk-iosched ¶Select IO scheduler for disk devices. One value has to be specified for each declared hard disk. Example alternatives are cfq, deadline and noop.
Defaults to ‘disabled’.
tlp-configurationparameter: string sata-linkpwr-on-ac ¶SATA aggressive link power management (ALPM) level. Alternatives are min_power, medium_power, max_performance.
Defaults to ‘"max_performance"’.
tlp-configurationparameter: string sata-linkpwr-on-bat ¶Same as
sata-linkpwr-acbut on BAT mode.Defaults to ‘"min_power"’.
tlp-configurationparameter: maybe-string sata-linkpwr-blacklist ¶Exclude specified SATA host devices for link power management.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-on-off-boolean ahci-runtime-pm-on-ac? ¶Enable Runtime Power Management for AHCI controller and disks on AC mode.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-on-off-boolean ahci-runtime-pm-on-bat? ¶Same as
ahci-runtime-pm-on-acon BAT mode.Defaults to ‘disabled’.
tlp-configurationparameter: non-negative-integer ahci-runtime-pm-timeout ¶Seconds of inactivity before disk is suspended.
Defaults to ‘15’.
tlp-configurationparameter: string pcie-aspm-on-ac ¶PCI Express Active State Power Management level. Alternatives are default, performance, powersave.
Defaults to ‘"performance"’.
tlp-configurationparameter: string pcie-aspm-on-bat ¶Same as
pcie-aspm-acbut on BAT mode.Defaults to ‘"powersave"’.
tlp-configurationparameter: maybe-non-negative-integer start-charge-thresh-bat0 ¶Percentage when battery 0 should begin charging. Only supported on some laptops.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer stop-charge-thresh-bat0 ¶Percentage when battery 0 should stop charging. Only supported on some laptops.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer start-charge-thresh-bat1 ¶Percentage when battery 1 should begin charging. Only supported on some laptops.
Defaults to ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer stop-charge-thresh-bat1 ¶Percentage when battery 1 should stop charging. Only supported on some laptops.
Defaults to ‘disabled’.
tlp-configurationparameter: string radeon-power-profile-on-ac ¶Radeon graphics clock speed level. Alternatives are low, mid, high, auto, default.
Defaults to ‘"high"’.
tlp-configurationparameter: string radeon-power-profile-on-bat ¶Same as
radeon-power-acbut on BAT mode.Defaults to ‘"low"’.
tlp-configurationparameter: string radeon-dpm-state-on-ac ¶Radeon dynamic power management method (DPM). Alternatives are battery, performance.
Defaults to ‘"performance"’.
tlp-configurationparameter: string radeon-dpm-state-on-bat ¶Same as
radeon-dpm-state-acbut on BAT mode.Defaults to ‘"battery"’.
tlp-configurationparameter: string radeon-dpm-perf-level-on-ac ¶Radeon DPM performance level. Alternatives are auto, low, high.
Defaults to ‘"auto"’.
tlp-configurationparameter: string radeon-dpm-perf-level-on-bat ¶Same as
radeon-dpm-perf-acbut on BAT mode.Defaults to ‘"auto"’.
tlp-configurationparameter: on-off-boolean wifi-pwr-on-ac? ¶Wifi power saving mode.
Defaults to ‘#f’.
tlp-configurationparameter: on-off-boolean wifi-pwr-on-bat? ¶Same as
wifi-power-ac?but on BAT mode.Defaults to ‘#t’.
tlp-configurationparameter: y-n-boolean wol-disable? ¶Disable wake on LAN.
Defaults to ‘#t’.
tlp-configurationparameter: non-negative-integer sound-power-save-on-ac ¶Timeout duration in seconds before activating audio power saving on Intel HDA and AC97 devices. A value of 0 disables power saving.
Defaults to ‘0’.
tlp-configurationparameter: non-negative-integer sound-power-save-on-bat ¶Same as
sound-powersave-acbut on BAT mode.Defaults to ‘1’.
tlp-configurationparameter: y-n-boolean sound-power-save-controller? ¶Disable controller in powersaving mode on Intel HDA devices.
Defaults to ‘#t’.
tlp-configurationparameter: boolean bay-poweroff-on-bat? ¶Enable optical drive in UltraBay/MediaBay on BAT mode. Drive can be powered on again by releasing (and reinserting) the eject lever or by pressing the disc eject button on newer models.
Defaults to ‘#f’.
tlp-configurationparameter: string bay-device ¶Name of the optical drive device to power off.
Defaults to ‘"sr0"’.
tlp-configurationparameter: string runtime-pm-on-ac ¶Runtime Power Management for PCI(e) bus devices. Alternatives are on and auto.
Defaults to ‘"on"’.
tlp-configurationparameter: string runtime-pm-on-bat ¶Same as
runtime-pm-acbut on BAT mode.Defaults to ‘"auto"’.
tlp-configurationparameter: boolean runtime-pm-all? ¶Runtime Power Management for all PCI(e) bus devices, except blacklisted ones.
Defaults to ‘#t’.
tlp-configurationparameter: maybe-space-separated-string-list runtime-pm-blacklist ¶Exclude specified PCI(e) device addresses from Runtime Power Management.
Defaults to ‘disabled’.
tlp-configurationparameter: space-separated-string-list runtime-pm-driver-blacklist ¶Exclude PCI(e) devices assigned to the specified drivers from Runtime Power Management.
tlp-configurationparameter: boolean usb-autosuspend? ¶Enable USB autosuspend feature.
Defaults to ‘#t’.
tlp-configurationparameter: maybe-string usb-blacklist ¶Exclude specified devices from USB autosuspend.
Defaults to ‘disabled’.
tlp-configurationparameter: boolean usb-blacklist-wwan? ¶Exclude WWAN devices from USB autosuspend.
Defaults to ‘#t’.
tlp-configurationparameter: maybe-string usb-whitelist ¶Include specified devices into USB autosuspend, even if they are already excluded by the driver or via
usb-blacklist-wwan?.Defaults to ‘disabled’.
tlp-configurationparameter: maybe-boolean usb-autosuspend-disable-on-shutdown? ¶Enable USB autosuspend before shutdown.
Defaults to ‘disabled’.
tlp-configurationparameter: boolean restore-device-state-on-startup? ¶Restore radio device state (bluetooth, wifi, wwan) from previous shutdown on system startup.
Defaults to ‘#f’.
Thermald daemon
The (gnu services pm) module provides an interface to thermald, a CPU
frequency scaling service which helps prevent overheating.
- Scheme Variable: thermald-service-type
This is the service type for thermald, the Linux Thermal Daemon, which is responsible for controlling the thermal state of processors and preventing overheating.
- Data Type: thermald-configuration
Data type representing the configuration of
thermald-service-type.adaptive?(default:#f)Use DPTF (Dynamic Power and Thermal Framework) adaptive tables when present.
ignore-cpuid-check?(default:#f)Ignore cpuid check for supported CPU models.
thermald(default: thermald)Package object of thermald.
Next: Сервисы виртуализации, Previous: Сервисы управления питанием, Up: Сервисы [Contents][Index]
12.9.28 Сервисы аудио
The (gnu services audio) module provides a service to start MPD (the
Music Player Daemon).
Music Player Daemon
The Music Player Daemon (MPD) is a service that can play music while being controlled from the local machine or over the network by a variety of clients.
The following example shows how one might run mpd as user
"bob" on port 6666. It uses pulseaudio for output.
(service mpd-service-type
(mpd-configuration
(user "bob")
(port "6666")))
- Scheme Variable: mpd-service-type
The service type for
mpd
- Data Type: mpd-configuration
Data type representing the configuration of
mpd.user(default:"mpd")The user to run mpd as.
music-dir(default:"~/Music")The directory to scan for music files.
playlist-dir(default:"~/.mpd/playlists")The directory to store playlists.
db-file(default:"~/.mpd/tag_cache")The location of the music database.
state-file(default:"~/.mpd/state")The location of the file that stores current MPD’s state.
sticker-file(default:"~/.mpd/sticker.sql")The location of the sticker database.
port(default:"6600")The port to run mpd on.
address(default:"any")The address that mpd will bind to. To use a Unix domain socket, an absolute path can be specified here.
features(default:'())The audio outputs that MPD can use. By default this is a single output using pulseaudio.
- Data Type: mpd-output
Data type representing an
mpdaudio output.port(default:22)The name of the audio output.
port(default:22)The type of audio output.
speed(default:1.0)Specifies whether this audio output is enabled when MPD is started. By default, all audio outputs are enabled. This is just the default setting when there is no state file; with a state file, the previous state is restored.
port(default:22)If set to
#f, then MPD will not send tags to this output. This is only useful for output plugins that can receive tags, for example thehttpdoutput plugin.port(default:22)If set to
#t, then MPD attempts to keep this audio output always open. This may be useful for streaming servers, when you don’t want to disconnect all listeners even when playback is accidentally stopped.mixer-typeThis field accepts a symbol that specifies which mixer should be used for this audio output: the
hardwaremixer, thesoftwaremixer, thenullmixer (allows setting the volume, but with no effect; this can be used as a trick to implement an external mixer External Mixer) or no mixer (none).extra-options(default:'())An association list of option symbols to string values to be appended to the audio output configuration.
The following example shows a configuration of mpd that provides an
HTTP audio streaming output.
(service mpd-service-type
(mpd-configuration
(outputs
(list (mpd-output
(name "streaming")
(type "httpd")
(mixer-type 'null)
(extra-options
`((encoder . "vorbis")
(port . "8080"))))))))
Next: Сервисы упраления версиями, Previous: Сервисы аудио, Up: Сервисы [Contents][Index]
12.9.29 Сервисы виртуализации
The (gnu services virtualization) module provides services for the
libvirt and virtlog daemons, as well as other virtualization-related
services.
Libvirt daemon
libvirtd is the server side daemon component of the libvirt
virtualization management system. This daemon runs on host servers and
performs required management tasks for virtualized guests.
- Scheme Variable: libvirt-service-type
This is the type of the libvirt daemon. Its value must be a
libvirt-configuration.(service libvirt-service-type (libvirt-configuration (unix-sock-group "libvirt") (tls-port "16555")))
Available libvirt-configuration fields are:
libvirt-configurationparameter: package libvirt ¶Libvirt package.
libvirt-configurationparameter: boolean listen-tls? ¶Flag listening for secure TLS connections on the public TCP/IP port. You must set
listenfor this to have any effect.It is necessary to setup a CA and issue server certificates before using this capability.
Defaults to ‘#t’.
libvirt-configurationparameter: boolean listen-tcp? ¶Listen for unencrypted TCP connections on the public TCP/IP port. You must set
listenfor this to have any effect.Using the TCP socket requires SASL authentication by default. Only SASL mechanisms which support data encryption are allowed. This is DIGEST_MD5 and GSSAPI (Kerberos5).
Defaults to ‘#f’.
libvirt-configurationparameter: string tls-port ¶Port for accepting secure TLS connections. This can be a port number, or service name.
Defaults to ‘"16514"’.
libvirt-configurationparameter: string tcp-port ¶Port for accepting insecure TCP connections. This can be a port number, or service name.
Defaults to ‘"16509"’.
libvirt-configurationparameter: string listen-addr ¶IP address or hostname used for client connections.
Defaults to ‘"0.0.0.0"’.
libvirt-configurationparameter: boolean mdns-adv? ¶Flag toggling mDNS advertisement of the libvirt service.
Alternatively can disable for all services on a host by stopping the Avahi daemon.
Defaults to ‘#f’.
libvirt-configurationparameter: string mdns-name ¶Default mDNS advertisement name. This must be unique on the immediate broadcast network.
Defaults to ‘"Virtualization Host <hostname>"’.
libvirt-configurationparameter: string unix-sock-group ¶UNIX domain socket group ownership. This can be used to allow a ’trusted’ set of users access to management capabilities without becoming root.
Defaults to ‘"root"’.
libvirt-configurationparameter: string unix-sock-ro-perms ¶UNIX socket permissions for the R/O socket. This is used for monitoring VM status only.
Defaults to ‘"0777"’.
libvirt-configurationparameter: string unix-sock-rw-perms ¶UNIX socket permissions for the R/W socket. Default allows only root. If PolicyKit is enabled on the socket, the default will change to allow everyone (eg, 0777)
Defaults to ‘"0770"’.
libvirt-configurationparameter: string unix-sock-admin-perms ¶UNIX socket permissions for the admin socket. Default allows only owner (root), do not change it unless you are sure to whom you are exposing the access to.
Defaults to ‘"0777"’.
libvirt-configurationparameter: string unix-sock-dir ¶The directory in which sockets will be found/created.
Defaults to ‘"/var/run/libvirt"’.
libvirt-configurationparameter: string auth-unix-ro ¶Authentication scheme for UNIX read-only sockets. By default socket permissions allow anyone to connect
Defaults to ‘"polkit"’.
libvirt-configurationparameter: string auth-unix-rw ¶Authentication scheme for UNIX read-write sockets. By default socket permissions only allow root. If PolicyKit support was compiled into libvirt, the default will be to use ’polkit’ auth.
Defaults to ‘"polkit"’.
libvirt-configurationparameter: string auth-tcp ¶Authentication scheme for TCP sockets. If you don’t enable SASL, then all TCP traffic is cleartext. Don’t do this outside of a dev/test scenario.
Defaults to ‘"sasl"’.
libvirt-configurationparameter: string auth-tls ¶Authentication scheme for TLS sockets. TLS sockets already have encryption provided by the TLS layer, and limited authentication is done by certificates.
It is possible to make use of any SASL authentication mechanism as well, by using ’sasl’ for this option
Defaults to ‘"none"’.
libvirt-configurationparameter: optional-list access-drivers ¶API access control scheme.
By default an authenticated user is allowed access to all APIs. Access drivers can place restrictions on this.
Defaults to ‘()’.
libvirt-configurationparameter: string key-file ¶Server key file path. If set to an empty string, then no private key is loaded.
Defaults to ‘""’.
libvirt-configurationparameter: string cert-file ¶Server key file path. If set to an empty string, then no certificate is loaded.
Defaults to ‘""’.
libvirt-configurationparameter: string ca-file ¶Server key file path. If set to an empty string, then no CA certificate is loaded.
Defaults to ‘""’.
libvirt-configurationparameter: string crl-file ¶Certificate revocation list path. If set to an empty string, then no CRL is loaded.
Defaults to ‘""’.
libvirt-configurationparameter: boolean tls-no-sanity-cert ¶Disable verification of our own server certificates.
When libvirtd starts it performs some sanity checks against its own certificates.
Defaults to ‘#f’.
libvirt-configurationparameter: boolean tls-no-verify-cert ¶Disable verification of client certificates.
Client certificate verification is the primary authentication mechanism. Any client which does not present a certificate signed by the CA will be rejected.
Defaults to ‘#f’.
libvirt-configurationparameter: optional-list tls-allowed-dn-list ¶Whitelist of allowed x509 Distinguished Name.
Defaults to ‘()’.
libvirt-configurationparameter: optional-list sasl-allowed-usernames ¶Whitelist of allowed SASL usernames. The format for username depends on the SASL authentication mechanism.
Defaults to ‘()’.
libvirt-configurationparameter: string tls-priority ¶Override the compile time default TLS priority string. The default is usually ‘"NORMAL"’ unless overridden at build time. Only set this is it is desired for libvirt to deviate from the global default settings.
Defaults to ‘"NORMAL"’.
libvirt-configurationparameter: integer max-clients ¶Maximum number of concurrent client connections to allow over all sockets combined.
Defaults to ‘5000’.
libvirt-configurationparameter: integer max-queued-clients ¶Maximum length of queue of connections waiting to be accepted by the daemon. Note, that some protocols supporting retransmission may obey this so that a later reattempt at connection succeeds.
Defaults to ‘1000’.
libvirt-configurationparameter: integer max-anonymous-clients ¶Maximum length of queue of accepted but not yet authenticated clients. Set this to zero to turn this feature off
Defaults to ‘20’.
libvirt-configurationparameter: integer min-workers ¶Number of workers to start up initially.
Defaults to ‘5’.
libvirt-configurationparameter: integer max-workers ¶Maximum number of worker threads.
If the number of active clients exceeds
min-workers, then more threads are spawned, up to max_workers limit. Typically you’d want max_workers to equal maximum number of clients allowed.Defaults to ‘20’.
libvirt-configurationparameter: integer prio-workers ¶Number of priority workers. If all workers from above pool are stuck, some calls marked as high priority (notably domainDestroy) can be executed in this pool.
Defaults to ‘5’.
libvirt-configurationparameter: integer max-requests ¶Total global limit on concurrent RPC calls.
Defaults to ‘20’.
libvirt-configurationparameter: integer max-client-requests ¶Limit on concurrent requests from a single client connection. To avoid one client monopolizing the server this should be a small fraction of the global max_requests and max_workers parameter.
Defaults to ‘5’.
libvirt-configurationparameter: integer admin-min-workers ¶Same as
min-workersbut for the admin interface.Defaults to ‘1’.
libvirt-configurationparameter: integer admin-max-workers ¶Same as
max-workersbut for the admin interface.Defaults to ‘5’.
libvirt-configurationparameter: integer admin-max-clients ¶Same as
max-clientsbut for the admin interface.Defaults to ‘5’.
libvirt-configurationparameter: integer admin-max-queued-clients ¶Same as
max-queued-clientsbut for the admin interface.Defaults to ‘5’.
libvirt-configurationparameter: integer admin-max-client-requests ¶Same as
max-client-requestsbut for the admin interface.Defaults to ‘5’.
libvirt-configurationparameter: integer log-level ¶Logging level. 4 errors, 3 warnings, 2 information, 1 debug.
Defaults to ‘3’.
libvirt-configurationparameter: string log-filters ¶Logging filters.
A filter allows to select a different logging level for a given category of logs. The format for a filter is one of:
- x:name
- x:+name
where
nameis a string which is matched against the category given in theVIR_LOG_INIT()at the top of each libvirt source file, e.g., ‘"remote"’, ‘"qemu"’, or ‘"util.json"’ (the name in the filter can be a substring of the full category name, in order to match multiple similar categories), the optional ‘"+"’ prefix tells libvirt to log stack trace for each message matching name, andxis the minimal level where matching messages should be logged:- 1: DEBUG
- 2: INFO
- 3: WARNING
- 4: ERROR
Multiple filters can be defined in a single filters statement, they just need to be separated by spaces.
Defaults to ‘"3:remote 4:event"’.
libvirt-configurationparameter: string log-outputs ¶Logging outputs.
An output is one of the places to save logging information. The format for an output can be:
x:stderroutput goes to stderr
x:syslog:nameuse syslog for the output and use the given name as the ident
x:file:file_pathoutput to a file, with the given filepath
x:journaldoutput to journald logging system
In all case the x prefix is the minimal level, acting as a filter
- 1: DEBUG
- 2: INFO
- 3: WARNING
- 4: ERROR
Multiple outputs can be defined, they just need to be separated by spaces.
Defaults to ‘"3:stderr"’.
libvirt-configurationparameter: integer audit-level ¶Allows usage of the auditing subsystem to be altered
- 0: disable all auditing
- 1: enable auditing, only if enabled on host
- 2: enable auditing, and exit if disabled on host.
Defaults to ‘1’.
libvirt-configurationparameter: boolean audit-logging ¶Send audit messages via libvirt logging infrastructure.
Defaults to ‘#f’.
libvirt-configurationparameter: optional-string host-uuid ¶Host UUID. UUID must not have all digits be the same.
Defaults to ‘""’.
libvirt-configurationparameter: string host-uuid-source ¶Source to read host UUID.
-
smbios: fetch the UUID fromdmidecode -s system-uuid -
machine-id: fetch the UUID from/etc/machine-id
If
dmidecodedoes not provide a valid UUID a temporary UUID will be generated.Defaults to ‘"smbios"’.
-
libvirt-configurationparameter: integer keepalive-interval ¶A keepalive message is sent to a client after
keepalive_intervalseconds of inactivity to check if the client is still responding. If set to -1, libvirtd will never send keepalive requests; however clients can still send them and the daemon will send responses.Defaults to ‘5’.
libvirt-configurationparameter: integer keepalive-count ¶Maximum number of keepalive messages that are allowed to be sent to the client without getting any response before the connection is considered broken.
In other words, the connection is automatically closed approximately after
keepalive_interval * (keepalive_count + 1)seconds since the last message received from the client. Whenkeepalive-countis set to 0, connections will be automatically closed afterkeepalive-intervalseconds of inactivity without sending any keepalive messages.Defaults to ‘5’.
libvirt-configurationparameter: integer admin-keepalive-interval ¶Same as above but for admin interface.
Defaults to ‘5’.
libvirt-configurationparameter: integer admin-keepalive-count ¶Same as above but for admin interface.
Defaults to ‘5’.
libvirt-configurationparameter: integer ovs-timeout ¶Timeout for Open vSwitch calls.
The
ovs-vsctlutility is used for the configuration and its timeout option is set by default to 5 seconds to avoid potential infinite waits blocking libvirt.Defaults to ‘5’.
Virtlog daemon
The virtlogd service is a server side daemon component of libvirt that is used to manage logs from virtual machine consoles.
This daemon is not used directly by libvirt client applications, rather it
is called on their behalf by libvirtd. By maintaining the logs in a
standalone daemon, the main libvirtd daemon can be restarted without
risk of losing logs. The virtlogd daemon has the ability to
re-exec() itself upon receiving SIGUSR1, to allow live upgrades
without downtime.
- Scheme Variable: virtlog-service-type
This is the type of the virtlog daemon. Its value must be a
virtlog-configuration.(service virtlog-service-type (virtlog-configuration (max-clients 1000)))
- Variable:
libvirtparameter package libvirt ¶ Libvirt package.
virtlog-configurationparameter: integer log-level ¶Logging level. 4 errors, 3 warnings, 2 information, 1 debug.
Defaults to ‘3’.
virtlog-configurationparameter: string log-filters ¶Logging filters.
A filter allows to select a different logging level for a given category of logs The format for a filter is one of:
- x:name
- x:+name
where
nameis a string which is matched against the category given in theVIR_LOG_INIT()at the top of each libvirt source file, e.g., "remote", "qemu", or "util.json" (the name in the filter can be a substring of the full category name, in order to match multiple similar categories), the optional "+" prefix tells libvirt to log stack trace for each message matching name, andxis the minimal level where matching messages should be logged:- 1: DEBUG
- 2: INFO
- 3: WARNING
- 4: ERROR
Multiple filters can be defined in a single filters statement, they just need to be separated by spaces.
Defaults to ‘"3:remote 4:event"’.
virtlog-configurationparameter: string log-outputs ¶Logging outputs.
An output is one of the places to save logging information The format for an output can be:
x:stderroutput goes to stderr
x:syslog:nameuse syslog for the output and use the given name as the ident
x:file:file_pathoutput to a file, with the given filepath
x:journaldoutput to journald logging system
In all case the x prefix is the minimal level, acting as a filter
- 1: DEBUG
- 2: INFO
- 3: WARNING
- 4: ERROR
Multiple outputs can be defined, they just need to be separated by spaces.
Defaults to ‘"3:stderr"’.
virtlog-configurationparameter: integer max-clients ¶Maximum number of concurrent client connections to allow over all sockets combined.
Defaults to ‘1024’.
virtlog-configurationparameter: integer max-size ¶Maximum file size before rolling over.
Defaults to ‘2MB’
virtlog-configurationparameter: integer max-backups ¶Maximum number of backup files to keep.
Defaults to ‘3’
Transparent Emulation with QEMU
qemu-binfmt-service-type provides support for transparent emulation
of program binaries built for different architectures—e.g., it allows you
to transparently execute an ARMv7 program on an x86_64 machine. It achieves
this by combining the QEMU emulator and the
binfmt_misc feature of the kernel Linux. This feature only allows
you to emulate GNU/Linux on a different architecture, but see below for
GNU/Hurd support.
- Scheme Variable: qemu-binfmt-service-type
This is the type of the QEMU/binfmt service for transparent emulation. Its value must be a
qemu-binfmt-configurationobject, which specifies the QEMU package to use as well as the architecture we want to emulated:(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm" "aarch64"))))In this example, we enable transparent emulation for the ARM and aarch64 platforms. Running
herd stop qemu-binfmtturns it off, and runningherd start qemu-binfmtturns it back on (see theherdcommand in The GNU Shepherd Manual).
- Data Type: qemu-binfmt-configuration
This is the configuration for the
qemu-binfmtservice.platforms(default:'())The list of emulated QEMU platforms. Each item must be a platform object as returned by
lookup-qemu-platforms(see below).For example, let’s suppose you’re on an x86_64 machine and you have this service:
(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm" "aarch64"))))You can run:
guix build -s armhf-linux inkscape
and it will build Inkscape for ARMv7 as if it were a native build, transparently using QEMU to emulate the ARMv7 CPU. Pretty handy if you’d like to test a package build for an architecture you don’t have access to!
qemu(default:qemu)The QEMU package to use.
- Scheme Procedure: lookup-qemu-platforms platforms…
Return the list of QEMU platform objects corresponding to platforms…. platforms must be a list of strings corresponding to platform names, such as
"arm","sparc","mips64el", and so on.
- Scheme Procedure: qemu-platform? obj
Return true if obj is a platform object.
- Scheme Procedure: qemu-platform-name platform
Return the name of platform—a string such as
"arm".
QEMU Guest Agent
The QEMU guest agent provides control over the emulated system to the host.
The qemu-guest-agent service runs the agent on Guix guests. To
control the agent from the host, open a socket by invoking QEMU with the
following arguments:
qemu-system-x86_64 \ -chardev socket,path=/tmp/qga.sock,server=on,wait=off,id=qga0 \ -device virtio-serial \ -device virtserialport,chardev=qga0,name=org.qemu.guest_agent.0 \ ...
This creates a socket at /tmp/qga.sock on the host. Once the guest
agent is running, you can issue commands with socat:
$ guix shell socat -- socat unix-connect:/tmp/qga.sock stdio
{"execute": "guest-get-host-name"}
{"return": {"host-name": "guix"}}
See QEMU guest agent documentation for more options and commands.
- Scheme Variable: qemu-guest-agent-service-type
Service type for the QEMU guest agent service.
- Data Type: qemu-guest-agent-configuration
Configuration for the
qemu-guest-agentservice.port(default:22)The QEMU package to use.
device(default:"")File name of the device or socket the agent uses to communicate with the host. If empty, QEMU uses a default file name.
Установка Guix на виртуальную машину (VM)
Service hurd-vm provides support for running GNU/Hurd in a virtual
machine (VM), a so-called childhurd. This service is meant to be used
on GNU/Linux and the given GNU/Hurd operating system configuration is
cross-compiled. The virtual machine is a Shepherd service that can be
referred to by the names hurd-vm and childhurd and be
controlled with commands such as:
herd start hurd-vm herd stop childhurd
When the service is running, you can view its console by connecting to it with a VNC client, for example with:
guix shell tigervnc-client -- vncviewer localhost:5900
The default configuration (see hurd-vm-configuration below) spawns a
secure shell (SSH) server in your GNU/Hurd system, which QEMU (the virtual
machine emulator) redirects to port 10222 on the host. Thus, you can
connect over SSH to the childhurd with:
ssh root@localhost -p 10022
The childhurd is volatile and stateless: it starts with a fresh root file
system every time you restart it. By default though, all the files under
/etc/childhurd on the host are copied as is to the root file system
of the childhurd when it boots. This allows you to initialize “secrets”
inside the VM: SSH host keys, authorized substitute keys, and so on—see
the explanation of secret-root below.
- Процедура Scheme: sane-service-type
This is the type of the Hurd in a Virtual Machine service. Its value must be a
hurd-vm-configurationobject, which specifies the operating system (seeoperating-systemReference) and the disk size for the Hurd Virtual Machine, the QEMU package to use as well as the options for running it.For example:
(service hurd-vm-service-type (hurd-vm-configuration (disk-size (* 5000 (expt 2 20))) ;5G (memory-size 1024))) ;1024MiB
would create a disk image big enough to build GNU Hello, with some extra memory.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
features(default:'())The operating system to instantiate. This default is bare-bones with a permissive OpenSSH secure shell daemon listening on port 2222 (see
openssh-service-type).port(default:22)The QEMU package to use.
port(default:22)The procedure used to build the disk-image built from this configuration.
features(default:'())Лицензия этого руководства.
port(default:22)The memory size of the Virtual Machine in mebibytes.
outputs(default:'("out"))The extra options for running QEMU.
id(default:#f)If set, a non-zero positive integer used to parameterize Childhurd instances. It is appended to the service’s name, e.g.
childhurd1.features(default:'())The procedure used to produce the list of QEMU networking options.
By default, it produces
'("--device" "rtl8139,netdev=net0" "--netdev" (string-append "user,id=net0," "hostfwd=tcp:127.0.0.1:secrets-port-:1004," "hostfwd=tcp:127.0.0.1:ssh-port-:2222," "hostfwd=tcp:127.0.0.1:vnc-port-:5900"))
with forwarded ports:
secrets-port:
(+ 11004 (* 1000 ID))ssh-port:(+ 10022 (* 1000 ID))vnc-port:(+ 15900 (* 1000 ID))private-key(default: ~root/.ssh/id_rsa)The root directory with out-of-band secrets to be installed into the childhurd once it runs. Childhurds are volatile which means that on every startup, secrets such as the SSH host keys and Guix signing key are recreated.
If the /etc/childhurd directory does not exist, the
secret-servicerunning in the Childhurd will be sent an empty list of secrets.By default, the service automatically populates /etc/childhurd with the following non-volatile secrets, unless they already exist:
/etc/childhurd/etc/guix/acl /etc/childhurd/etc/guix/signing-key.pub /etc/childhurd/etc/guix/signing-key.sec /etc/childhurd/etc/ssh/ssh_host_ed25519_key /etc/childhurd/etc/ssh/ssh_host_ecdsa_key /etc/childhurd/etc/ssh/ssh_host_ed25519_key.pub /etc/childhurd/etc/ssh/ssh_host_ecdsa_key.pub
These files are automatically sent to the guest Hurd VM when it boots, including permissions.
Having these files in place means that only a couple of things are missing to allow the host to offload
i586-gnubuilds to the childhurd:- Authorizing the childhurd’s key on the host so that the host accepts build
results coming from the childhurd, which can be done like so:
guix archive --authorize < \ /etc/childhurd/etc/guix/signing-key.pub
- Adding the childhurd to /etc/guix/machines.scm (see Использование функционала разгрузки).
We’re working towards making that happen automatically—get in touch with us at guix-devel@gnu.org to discuss it!
- Authorizing the childhurd’s key on the host so that the host accepts build
results coming from the childhurd, which can be done like so:
Note that by default the VM image is volatile, i.e., once stopped the
contents are lost. If you want a stateful image instead, override the
configuration’s image and options without the
--snapshot flag using something along these lines:
(service hurd-vm-service-type
(hurd-vm-configuration
(image (const "/out/of/store/writable/hurd.img"))
(options '())))
Ganeti
Примечание: This service is considered experimental. Configuration options may be changed in a backwards-incompatible manner, and not all features have been thorougly tested. Users of this service are encouraged to share their experience at guix-devel@gnu.org.
Ganeti is a virtual machine management system. It is designed to keep
virtual machines running on a cluster of servers even in the event of
hardware failures, and to make maintenance and recovery tasks easy. It
consists of multiple services which are described later in this section. In
addition to the Ganeti service, you will need the OpenSSH service
(see openssh-service-type), and update the
/etc/hosts file (see hosts-file) with the cluster name and address (or use a DNS server).
All nodes participating in a Ganeti cluster should have the same Ganeti and
/etc/hosts configuration. Here is an example configuration for a
Ganeti cluster node that supports multiple storage backends, and installs
the debootstrap and guix OS providers:
(use-package-modules virtualization) (use-service-modules base ganeti networking ssh) (operating-system ;; … (host-name "node1") (hosts-file (plain-file "hosts" (format #f " 127.0.0.1 localhost ::1 localhost 192.168.1.200 ganeti.example.com 192.168.1.201 node1.example.com node1 192.168.1.202 node2.example.com node2 "))) ;; Install QEMU so we can use KVM-based instances, and LVM, DRBD and Ceph ;; in order to use the "plain", "drbd" and "rbd" storage backends. (packages (append (map specification->package '("qemu" "lvm2" "drbd-utils" "ceph" ;; Add the debootstrap and guix OS providers. "ganeti-instance-guix" "ganeti-instance-debootstrap")) %base-packages)) (services (append (list (service static-networking-service-type (list (static-networking (addresses (list (network-address (device "eth0") (value "192.168.1.201/24")))) (routes (list (network-route (destination "default") (gateway "192.168.1.254")))) (name-servers '("192.168.1.252" "192.168.1.253"))))) ;; Ganeti uses SSH to communicate between nodes. (service openssh-service-type (openssh-configuration (permit-root-login 'prohibit-password))) (service ganeti-service-type (ganeti-configuration ;; This list specifies allowed file system paths ;; for storing virtual machine images. (file-storage-paths '("/srv/ganeti/file-storage")) ;; This variable configures a single "variant" for ;; both Debootstrap and Guix that works with KVM. (os %default-ganeti-os)))) %base-services)))
Users are advised to read the Ganeti administrators guide to learn about the various cluster options and day-to-day operations. There is also a blog post describing how to configure and initialize a small cluster.
- Процедура Scheme: sane-service-type
This is a service type that includes all the various services that Ganeti nodes should run.
Its value is a
ganeti-configurationobject that defines the package to use for CLI operations, as well as configuration for the various daemons. Allowed file storage paths and available guest operating systems are also configured through this data type.
- Конфигурирование: системы
Модуль
(guix inferior)предоставляет следующие процедуры для работы с ранними версиями:port(default:22)The
ganetipackage to use. It will be installed to the system profile and makegnt-cluster,gnt-instance, etc available. Note that the value specified here does not affect the other services as each refer to a specificganetipackage (see below).port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)port(default:22)-
These options control the various daemons and cron jobs that are distributed with Ganeti. The possible values for these are described in detail below. To override a setting, you must use the configuration type for that service:
(service ganeti-service-type (ganeti-configuration (rapi-configuration (ganeti-rapi-configuration (interface "eth1")))) (watcher-configuration (ganeti-watcher-configuration (rapi-ip "10.0.0.1")))) native-search-paths(default:'())List of allowed directories for file storage backend.
port(default:22)List of
<ganeti-os>records.
In essence
ganeti-service-typeis shorthand for declaring each service individually:(service ganeti-noded-service-type) (service ganeti-confd-service-type) (service ganeti-wconfd-service-type) (service ganeti-luxid-service-type) (service ganeti-kvmd-service-type) (service ganeti-mond-service-type) (service ganeti-metad-service-type) (service ganeti-watcher-service-type) (service ganeti-cleaner-service-type)
Plus a service extension for
etc-service-typethat configures the file storage backend and OS variants.
- Тип данных: build-machine
This data type is suitable for passing to the
osparameter ofganeti-configuration. It takes the following parameters:nameThe name for this OS provider. It is only used to specify where the configuration ends up. Setting it to “debootstrap” will create /etc/ganeti/instance-debootstrap.
extension(default:#f)The file extension for variants of this OS type. For example .conf or .scm. It will be appended to the variant file name if set.
inputs(default:'())This must be either a list of
ganeti-os-variantobjects for this OS, or a “file-like” object (see file-like objects) representing the variants directory.To use the Guix OS provider with variant definitions residing in a local directory instead of declaring individual variants (see guix-variants below), you can do:
(ganeti-os (name "guix") (variants (local-file "ganeti-guix-variants" #:recursive? #true)))Note that you will need to maintain the variants.list file (see
ganeti-os-interface(7)) manually in this case.
- Тип данных: build-machine
This is the data type for a Ganeti OS variant. It takes the following parameters:
nameЛицензия этого руководства.
Конфигурирование системыФайл конфигурации для этого варианта.
- Scheme Variable: ant-build-system
This variable contains hooks to configure networking and the GRUB bootloader.
- Scheme Variable: ant-build-system
This variable contains a list of packages suitable for a fully-virtualized guest.
- Конфигурирование: системы
-
This data type creates configuration files suitable for the debootstrap OS provider.
port(default:22)When not
#f, this must be a G-expression that specifies a directory with scripts that will run when the OS is installed. It can also be a list of(name . file-like)pairs. For example:`((99-hello-world . ,(plain-file "#!/bin/sh\necho Hello, World")))
That will create a directory with one executable named
99-hello-worldand run it every time this variant is installed. If set to#f, hooks in /etc/ganeti/instance-debootstrap/hooks will be used, if any.port(default:22)Optional HTTP proxy to use.
features(default:'())The Debian mirror. Typically something like
http://ftp.no.debian.org/debian. The default varies depending on the distribution.features(default:'())The dpkg architecture. Set to
armhfto debootstrap an ARMv7 instance on an AArch64 host. Default is to use the current system architecture.port(default:22)When set, this must be a Debian distribution “suite” such as
busterorfocal. If set to#f, the default for the OS provider is used.port(default:22)List of extra packages that will get installed by dpkg in addition to the minimal system.
speed(default:1.0)When set, must be a list of Debian repository “components”. For example
'("main" "contrib").speed(default:1.0)Whether to automatically cache the generated debootstrap archive.
port(default:22)Discard the cache after this amount of days. Use
#fto never clear the cache.features(default:'())The type of partition to create. When set, it must be one of
'msdos,'noneor a string.arguments(default:'())Alignment of the partition in sectors.
- Процедура Scheme: lookup-inferior-packages inferior name This is a helper procedure that creates a
ganeti-os-variantrecord. It takes two parameters: a name and a
debootstrap-configurationobject.
- Процедура Scheme: lookup-inferior-packages inferior name This is a helper procedure that creates a
ganeti-osrecord. It takes a list of variants created with
debootstrap-variant.
- Процедура Scheme: lookup-inferior-packages inferior name This is a helper procedure that creates a
ganeti-os-variantrecord for use with the Guix OS provider. It takes a name and a G-expression that returns a “file-like” (see file-like objects) object containing a Guix System configuration.
- Процедура Scheme: lookup-inferior-packages inferior name This is a helper procedure that creates a
ganeti-osrecord. It takes a list of variants produced by
guix-variant.
- Процедура Scheme: sane-service-type
This is a convenience variable to make the debootstrap provider work “out of the box” without users having to declare variants manually. It contains a single debootstrap variant with the default configuration:
(list (debootstrap-variant "default" (debootstrap-configuration)))
- Scheme Variable: ant-build-system
This is a convenience variable to make the Guix OS provider work without additional configuration. It creates a virtual machine that has an SSH server, a serial console, and authorizes the Ganeti hosts SSH keys.
(list (guix-variant "default" (file-append ganeti-instance-guix "/share/doc/ganeti-instance-guix/examples/dynamic.scm")))
Users can implement support for OS providers unbeknownst to Guix by
extending the ganeti-os and ganeti-os-variant records
appropriately. For example:
(ganeti-os
(name "custom")
(extension ".conf")
(variants
(list (ganeti-os-variant
(name "foo")
(configuration (plain-file "bar" "this is fine"))))))
That creates /etc/ganeti/instance-custom/variants/foo.conf which
points to a file in the store with contents this is fine. It also
creates /etc/ganeti/instance-custom/variants/variants.list with
contents foo.
Obviously this may not work for all OS providers out there. If you find the interface limiting, please reach out to guix-devel@gnu.org.
The rest of this section documents the various services that are included by
ganeti-service-type.
- Процедура Scheme: sane-service-type
ganeti-nodedis the daemon responsible for node-specific functions within the Ganeti system. The value of this service must be aganeti-noded-configurationobject.
- Data Type: pagekite-configuration
This is the configuration for the
ganeti-nodedservice.port(default:22)Пакет
ganetiдля использования в этой службе.port(default:22)The TCP port on which the node daemon listens for network requests.
speed(default:1.0)The network address that the daemon will bind to. The default address means bind to all available addresses.
interface(default:#f)When this is set, it must be a specific network interface (e.g.
eth0) that the daemon will bind to.inputs(default:'())This sets a limit on the maximum number of simultaneous client connections that the daemon will handle. Connections above this count are accepted, but no responses will be sent until enough connections have closed.
port(default:22)Whether to use SSL/TLS to encrypt network communications. The certificate is automatically provisioned by the cluster and can be rotated with
gnt-cluster renew-crypto.daemon-socket(default:"/var/guix/daemon-socket/socket")This can be used to provide a specific encryption key for TLS communications.
speed(default:1.0)This can be used to provide a specific certificate for TLS communications.
debug?(default:#f)When true, the daemon performs additional logging for debugging purposes. Note that this will leak encryption details to the log files, use with caution.
- Процедура Scheme: sane-service-type
ganeti-confdanswers queries related to the configuration of a Ganeti cluster. The purpose of this daemon is to have a highly available and fast way to query cluster configuration values. It is automatically active on all master candidates. The value of this service must be aganeti-confd-configurationobject.
- Конфигурирование: системы
This is the configuration for the
ganeti-confdservice.port(default:22)Пакет
ganetiдля использования в этой службе.port(default:22)The UDP port on which to listen for network requests.
speed(default:1.0)Network address that the daemon will bind to.
debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-wconfdis the daemon that has authoritative knowledge about the cluster configuration and is the only entity that can accept changes to it. All jobs that need to modify the configuration will do so by sending appropriate requests to this daemon. It only runs on the master node and will automatically disable itself on other nodes.The value of this service must be a
ganeti-wconfd-configurationobject.
- Конфигурирование: системы
This is the configuration for the
ganeti-wconfdservice.port(default:22)Пакет
ganetiдля использования в этой службе.port(default:22)The daemon will refuse to start if the majority of cluster nodes does not agree that it is running on the master node. Set to
#tto start even if a quorum can not be reached (dangerous, use with caution).debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-luxidis a daemon used to answer queries related to the configuration and the current live state of a Ganeti cluster. Additionally, it is the authoritative daemon for the Ganeti job queue. Jobs can be submitted via this daemon and it schedules and starts them.It takes a
ganeti-luxid-configurationobject.
- Тип данных: build-machine
This is the configuration for the
ganeti-luxidservice.port(default:22)Пакет
ganetiдля использования в этой службе.port(default:22)The daemon will refuse to start if it cannot verify that the majority of cluster nodes believes that it is running on the master node. Set to
#tto ignore such checks and start anyway (this can be dangerous).debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-rapiprovides a remote API for Ganeti clusters. It runs on the master node and can be used to perform cluster actions programmatically via a JSON-based RPC protocol.Most query operations are allowed without authentication (unless require-authentication? is set), whereas write operations require explicit authorization via the /var/lib/ganeti/rapi/users file. See the Ganeti Remote API documentation for more information.
The value of this service must be a
ganeti-rapi-configurationobject.
- Конфигурирование: системы
This is the configuration for the
ganeti-rapiservice.port(default:22)Пакет
ganetiдля использования в этой службе.features(default:'())Whether to require authentication even for read-only operations.
port(default:22)The TCP port on which to listen to API requests.
speed(default:1.0)The network address that the service will bind to. By default it listens on all configured addresses.
interface(default:#f)When set, it must specify a specific network interface such as
eth0that the daemon will bind to.inputs(default:'())The maximum number of simultaneous client requests to handle. Further connections are allowed, but no responses are sent until enough connections have closed.
port(default:22)Whether to use SSL/TLS encryption on the RAPI port.
daemon-socket(default:"/var/guix/daemon-socket/socket")This can be used to provide a specific encryption key for TLS communications.
speed(default:1.0)This can be used to provide a specific certificate for TLS communications.
debug?(default:#f)When true, the daemon performs additional logging for debugging purposes. Note that this will leak encryption details to the log files, use with caution.
- Процедура Scheme: sane-service-type
ganeti-kvmdis responsible for determining whether a given KVM instance was shut down by an administrator or a user. Normally Ganeti will restart an instance that was not stopped through Ganeti itself. If the cluster optionuser_shutdownis true, this daemon monitors theQMPsocket provided by QEMU and listens for shutdown events, and marks the instance as USER_down instead of ERROR_down when it shuts down gracefully by itself.It takes a
ganeti-kvmd-configurationobject.
- Тип данных: build-machine
-
port(default:22)Пакет
ganetiдля использования в этой службе.debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-mondis an optional daemon that provides Ganeti monitoring functionality. It is responsible for running data collectors and publish the collected information through a HTTP interface.It takes a
ganeti-mond-configurationobject.
- Тип данных: build-machine
-
port(default:22)Пакет
ganetiдля использования в этой службе.port(default:22)The port on which the daemon will listen.
speed(default:1.0)The network address that the daemon will bind to. By default it binds to all available interfaces.
debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-metadis an optional daemon that can be used to provide information about the cluster to instances or OS install scripts.It takes a
ganeti-metad-configurationobject.
- Тип данных: build-machine
-
port(default:22)Пакет
ganetiдля использования в этой службе.port(default:80)The port on which the daemon will listen.
features(default:'())If set, the daemon will bind to this address only. If left unset, the behavior depends on the cluster configuration.
debug?(default:#f)When true, the daemon performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-watcheris a script designed to run periodically and ensure the health of a cluster. It will automatically restart instances that have stopped without Ganeti’s consent, and repairs DRBD links in case a node has rebooted. It also archives old cluster jobs and restarts Ganeti daemons that are not running. If the cluster parameterensure_node_healthis set, the watcher will also shutdown instances and DRBD devices if the node it is running on is declared offline by known master candidates.It can be paused on all nodes with
gnt-cluster watcher pause.The service takes a
ganeti-watcher-configurationobject.
- Data Type: pagekite-configuration
-
port(default:22)Пакет
ganetiдля использования в этой службе.schedule(default:'(next-second-from (next-minute (range 0 60 5))))How often to run the script. The default is every five minutes.
speed(default:1.0)This option needs to be specified only if the RAPI daemon is configured to use a particular interface or address. By default the cluster address is used.
features(default:'())Archive cluster jobs older than this age, specified in seconds. The default is 6 hours. This keeps
gnt-job listmanageable.port(default:22)If this is
#f, the watcher will not try to repair broken DRBD links automatically. Administrators will need to usegnt-cluster verify-disksmanually instead.debug?(default:#f)When
#t, the script performs additional logging for debugging purposes.
- Процедура Scheme: sane-service-type
ganeti-cleaneris a script designed to run periodically and remove old files from the cluster. This service type controls two cron jobs: one intended for the master node that permanently purges old cluster jobs, and one intended for every node that removes expired X509 certificates, keys, and outdatedganeti-watcherinformation. Like all Ganeti services, it is safe to include even on non-master nodes as it will disable itself as necessary.It takes a
ganeti-cleaner-configurationobject.
- Тип данных: build-machine
-
port(default:22)The
ganetipackage to use for thegnt-cleanercommand.port(default:22)How often to run the master cleaning job. The default is once per day, at 01:45:00.
port(default:22)How often to run the node cleaning job. The default is once per day, at 02:45:00.
Next: Игровые службы, Previous: Сервисы виртуализации, Up: Сервисы [Contents][Index]
12.9.30 Сервисы упраления версиями
The (gnu services version-control) module provides a service to allow
remote access to local Git repositories. There are three options: the
git-daemon-service, which provides access to repositories via the
git:// unsecured TCP-based protocol, extending the nginx web
server to proxy some requests to git-http-backend, or providing a web
interface with cgit-service-type.
- Scheme Procedure: git-daemon-service [#:config (git-daemon-configuration)]
-
Return a service that runs
git daemon, a simple TCP server to expose repositories over the Git protocol for anonymous access.The optional config argument should be a
<git-daemon-configuration>object, by default it allows read-only access to exported32 repositories under /srv/git.
- Data Type: git-daemon-configuration
Data type representing the configuration for
git-daemon-service.speed(default:1.0)Package object of the Git distributed version control system.
speed(default:1.0)Whether to allow access for all Git repositories, even if they do not have the git-daemon-export-ok file.
base-path(default: /srv/git)Whether to remap all the path requests as relative to the given path. If you run
git daemonwith(base-path "/srv/git")on ‘example.com’, then if you later try to pull ‘git://example.com/hello.git’, git daemon will interpret the path as /srv/git/hello.git.features(default:'())Whether to allow
~usernotation to be used in requests. When specified with empty string, requests to ‘git://host/~alice/foo’ is taken as a request to accessfoorepository in the home directory of useralice. If(user-path "path")is specified, the same request is taken as a request to access path/foo repository in the home directory of useralice.inputs(default:'())Whether to listen on specific IP addresses or hostnames, defaults to all.
port(default:22)Whether to listen on an alternative port, which defaults to 9418.
inputs(default:'())If not empty, only allow access to this list of directories.
extra-options(default:'())Extra options will be passed to
git daemon, please runman git-daemonfor more information.
The git:// protocol lacks authentication. When you pull from a
repository fetched via git://, you don’t know whether the data you
receive was modified or is even coming from the specified host, and your
connection is subject to eavesdropping. It’s better to use an authenticated
and encrypted transport, such as https. Although Git allows you to
serve repositories using unsophisticated file-based web servers, there is a
faster protocol implemented by the git-http-backend program. This
program is the back-end of a proper Git web service. It is designed to sit
behind a FastCGI proxy. See Веб-сервисы, for more on running the
necessary fcgiwrap daemon.
Guix has a separate configuration data type for serving Git repositories over HTTP.
- Data Type: git-http-configuration
Data type representing the configuration for a future
git-http-service-type; can currently be used to configure Nginx throughgit-http-nginx-location-configuration.package(default: git)Package object of the Git distributed version control system.
git-root(default: /srv/git)Directory containing the Git repositories to expose to the world.
speed(default:1.0)Whether to expose access for all Git repositories in git-root, even if they do not have the git-daemon-export-ok file.
port(default:22)Path prefix for Git access. With the default ‘/git/’ prefix, this will map ‘
http://server/git/repo.git’ to /srv/git/repo.git. Requests whose URI paths do not begin with this prefix are not passed on to this Git instance.fcgiwrap-socket(default:127.0.0.1:9000)The socket on which the
fcgiwrapdaemon is listening. See Веб-сервисы.
There is no git-http-service-type, currently; instead you can create
an nginx-location-configuration from a git-http-configuration
and then add that location to a web server.
- Scheme Procedure: git-http-nginx-location-configuration [config=(git-http-configuration)] Compute an
nginx-location-configurationthat corresponds to the given Git http configuration. An example nginx service definition to serve the default /srv/git over HTTPS might be:(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (listen '("443 ssl")) (server-name "git.my-host.org") (ssl-certificate "/etc/letsencrypt/live/git.my-host.org/fullchain.pem") (ssl-certificate-key "/etc/letsencrypt/live/git.my-host.org/privkey.pem") (locations (list (git-http-nginx-location-configuration (git-http-configuration (uri-path "/"))))))))))This example assumes that you are using Let’s Encrypt to get your TLS certificate. See Сервисы сертификатов. The default
certbotservice will redirect all HTTP traffic ongit.my-host.orgto HTTPS. You will also need to add anfcgiwrapproxy to your system services. See Веб-сервисы.
Cgit Service
Cgit is a web frontend for Git repositories written in C.
The following example will configure the service with default values. By
default, Cgit can be accessed on port 80 (http://localhost:80).
(service cgit-service-type)
The file-object type designates either a file-like object
(see file-like objects) or a string.
Available cgit-configuration fields are:
cgit-configurationparameter: package package ¶The CGIT package.
cgit-configurationparameter: nginx-server-configuration-list nginx ¶NGINX configuration.
cgit-configurationparameter: file-object about-filter ¶Specifies a command which will be invoked to format the content of about pages (both top-level and for each repository).
Defaults to ‘""’.
cgit-configurationparameter: string agefile ¶Specifies a path, relative to each repository path, which can be used to specify the date and time of the youngest commit in the repository.
Defaults to ‘""’.
cgit-configurationparameter: file-object auth-filter ¶Specifies a command that will be invoked for authenticating repository access.
Defaults to ‘""’.
cgit-configurationparameter: string branch-sort ¶Flag which, when set to ‘age’, enables date ordering in the branch ref list, and when set ‘name’ enables ordering by branch name.
Defaults to ‘"name"’.
cgit-configurationparameter: string cache-root ¶Path used to store the cgit cache entries.
Defaults to ‘"/var/cache/cgit"’.
cgit-configurationparameter: integer cache-static-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of repository pages accessed with a fixed SHA1.
Defaults to ‘-1’.
cgit-configurationparameter: integer cache-dynamic-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of repository pages accessed without a fixed SHA1.
Defaults to ‘5’.
cgit-configurationparameter: integer cache-repo-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of the repository summary page.
Defaults to ‘5’.
cgit-configurationparameter: integer cache-root-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of the repository index page.
Defaults to ‘5’.
cgit-configurationparameter: integer cache-scanrc-ttl ¶Number which specifies the time-to-live, in minutes, for the result of scanning a path for Git repositories.
Defaults to ‘15’.
cgit-configurationparameter: integer cache-about-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of the repository about page.
Defaults to ‘15’.
cgit-configurationparameter: integer cache-snapshot-ttl ¶Number which specifies the time-to-live, in minutes, for the cached version of snapshots.
Defaults to ‘5’.
cgit-configurationparameter: integer cache-size ¶The maximum number of entries in the cgit cache. When set to ‘0’, caching is disabled.
Defaults to ‘0’.
cgit-configurationparameter: boolean case-sensitive-sort? ¶Sort items in the repo list case sensitively.
Defaults to ‘#t’.
cgit-configurationparameter: list clone-prefix ¶List of common prefixes which, when combined with a repository URL, generates valid clone URLs for the repository.
Defaults to ‘()’.
cgit-configurationparameter: list clone-url ¶List of
clone-urltemplates.Defaults to ‘()’.
cgit-configurationparameter: file-object commit-filter ¶Command which will be invoked to format commit messages.
Defaults to ‘""’.
cgit-configurationparameter: string commit-sort ¶Flag which, when set to ‘date’, enables strict date ordering in the commit log, and when set to ‘topo’ enables strict topological ordering.
Defaults to ‘"git log"’.
cgit-configurationparameter: file-object css ¶URL which specifies the css document to include in all cgit pages.
Defaults to ‘"/share/cgit/cgit.css"’.
cgit-configurationparameter: file-object email-filter ¶Specifies a command which will be invoked to format names and email address of committers, authors, and taggers, as represented in various places throughout the cgit interface.
Defaults to ‘""’.
cgit-configurationparameter: boolean embedded? ¶Flag which, when set to ‘#t’, will make cgit generate a HTML fragment suitable for embedding in other HTML pages.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-commit-graph? ¶Flag which, when set to ‘#t’, will make cgit print an ASCII-art commit history graph to the left of the commit messages in the repository log page.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-filter-overrides? ¶Flag which, when set to ‘#t’, allows all filter settings to be overridden in repository-specific cgitrc files.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-follow-links? ¶Flag which, when set to ‘#t’, allows users to follow a file in the log view.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-http-clone? ¶If set to ‘#t’, cgit will act as an dumb HTTP endpoint for Git clones.
Defaults to ‘#t’.
cgit-configurationparameter: boolean enable-index-links? ¶Flag which, when set to ‘#t’, will make cgit generate extra links "summary", "commit", "tree" for each repo in the repository index.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-index-owner? ¶Flag which, when set to ‘#t’, will make cgit display the owner of each repo in the repository index.
Defaults to ‘#t’.
cgit-configurationparameter: boolean enable-log-filecount? ¶Flag which, when set to ‘#t’, will make cgit print the number of modified files for each commit on the repository log page.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-log-linecount? ¶Flag which, when set to ‘#t’, will make cgit print the number of added and removed lines for each commit on the repository log page.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-remote-branches? ¶Flag which, when set to
#t, will make cgit display remote branches in the summary and refs views.Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-subject-links? ¶Flag which, when set to
1, will make cgit use the subject of the parent commit as link text when generating links to parent commits in commit view.Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-html-serving? ¶Flag which, when set to ‘#t’, will make cgit use the subject of the parent commit as link text when generating links to parent commits in commit view.
Defaults to ‘#f’.
cgit-configurationparameter: boolean enable-tree-linenumbers? ¶Flag which, when set to ‘#t’, will make cgit generate linenumber links for plaintext blobs printed in the tree view.
Defaults to ‘#t’.
cgit-configurationparameter: boolean enable-git-config? ¶Flag which, when set to ‘#f’, will allow cgit to use Git config to set any repo specific settings.
Defaults to ‘#f’.
cgit-configurationparameter: file-object favicon ¶URL used as link to a shortcut icon for cgit.
Defaults to ‘"/favicon.ico"’.
The content of the file specified with this option will be included verbatim at the bottom of all pages (i.e. it replaces the standard "generated by..." message).
Defaults to ‘""’.
cgit-configurationparameter: string head-include ¶The content of the file specified with this option will be included verbatim in the HTML HEAD section on all pages.
Defaults to ‘""’.
cgit-configurationparameter: string header ¶The content of the file specified with this option will be included verbatim at the top of all pages.
Defaults to ‘""’.
cgit-configurationparameter: file-object include ¶Name of a configfile to include before the rest of the current config- file is parsed.
Defaults to ‘""’.
cgit-configurationparameter: string index-header ¶The content of the file specified with this option will be included verbatim above the repository index.
Defaults to ‘""’.
cgit-configurationparameter: string index-info ¶The content of the file specified with this option will be included verbatim below the heading on the repository index page.
Defaults to ‘""’.
cgit-configurationparameter: boolean local-time? ¶Flag which, if set to ‘#t’, makes cgit print commit and tag times in the servers timezone.
Defaults to ‘#f’.
cgit-configurationparameter: file-object logo ¶URL which specifies the source of an image which will be used as a logo on all cgit pages.
Defaults to ‘"/share/cgit/cgit.png"’.
cgit-configurationparameter: string logo-link ¶URL loaded when clicking on the cgit logo image.
Defaults to ‘""’.
cgit-configurationparameter: file-object owner-filter ¶Command which will be invoked to format the Owner column of the main page.
Defaults to ‘""’.
cgit-configurationparameter: integer max-atom-items ¶Number of items to display in atom feeds view.
Defaults to ‘10’.
cgit-configurationparameter: integer max-commit-count ¶Number of entries to list per page in "log" view.
Defaults to ‘50’.
cgit-configurationparameter: integer max-message-length ¶Number of commit message characters to display in "log" view.
Defaults to ‘80’.
cgit-configurationparameter: integer max-repo-count ¶Specifies the number of entries to list per page on the repository index page.
Defaults to ‘50’.
cgit-configurationparameter: integer max-repodesc-length ¶Specifies the maximum number of repo description characters to display on the repository index page.
Defaults to ‘80’.
cgit-configurationparameter: integer max-blob-size ¶Specifies the maximum size of a blob to display HTML for in KBytes.
Defaults to ‘0’.
cgit-configurationparameter: string max-stats ¶Maximum statistics period. Valid values are ‘week’,‘month’, ‘quarter’ and ‘year’.
Defaults to ‘""’.
cgit-configurationparameter: mimetype-alist mimetype ¶Mimetype for the specified filename extension.
Defaults to ‘((gif "image/gif") (html "text/html") (jpg "image/jpeg") (jpeg "image/jpeg") (pdf "application/pdf") (png "image/png") (svg "image/svg+xml"))’.
cgit-configurationparameter: file-object mimetype-file ¶Specifies the file to use for automatic mimetype lookup.
Defaults to ‘""’.
cgit-configurationparameter: string module-link ¶Text which will be used as the formatstring for a hyperlink when a submodule is printed in a directory listing.
Defaults to ‘""’.
cgit-configurationparameter: boolean nocache? ¶If set to the value ‘#t’ caching will be disabled.
Defaults to ‘#f’.
cgit-configurationparameter: boolean noplainemail? ¶If set to ‘#t’ showing full author email addresses will be disabled.
Defaults to ‘#f’.
cgit-configurationparameter: boolean noheader? ¶Flag which, when set to ‘#t’, will make cgit omit the standard header on all pages.
Defaults to ‘#f’.
cgit-configurationparameter: project-list project-list ¶A list of subdirectories inside of
repository-directory, relative to it, that should loaded as Git repositories. An empty list means that all subdirectories will be loaded.Defaults to ‘()’.
cgit-configurationparameter: file-object readme ¶Text which will be used as default value for
cgit-repo-readme.Defaults to ‘""’.
cgit-configurationparameter: boolean remove-suffix? ¶If set to
#tandrepository-directoryis enabled, if any repositories are found with a suffix of.git, this suffix will be removed for the URL and name.Defaults to ‘#f’.
cgit-configurationparameter: integer renamelimit ¶Maximum number of files to consider when detecting renames.
Defaults to ‘-1’.
cgit-configurationparameter: string repository-sort ¶The way in which repositories in each section are sorted.
Defaults to ‘""’.
cgit-configurationparameter: robots-list robots ¶Text used as content for the
robotsmeta-tag.Defaults to ‘("noindex" "nofollow")’.
cgit-configurationparameter: string root-desc ¶Text printed below the heading on the repository index page.
Defaults to ‘"a fast webinterface for the git dscm"’.
cgit-configurationparameter: string root-readme ¶The content of the file specified with this option will be included verbatim below the “about” link on the repository index page.
Defaults to ‘""’.
cgit-configurationparameter: string root-title ¶Text printed as heading on the repository index page.
Defaults to ‘""’.
If set to ‘#t’ and repository-directory is enabled, repository-directory will recurse into directories whose name starts with a period. Otherwise, repository-directory will stay away from such directories, considered as “hidden”. Note that this does not apply to the .git directory in non-bare repos.
Defaults to ‘#f’.
cgit-configurationparameter: list snapshots ¶Text which specifies the default set of snapshot formats that cgit generates links for.
Defaults to ‘()’.
cgit-configurationparameter: repository-directory repository-directory ¶Name of the directory to scan for repositories (represents
scan-path).Defaults to ‘"/srv/git"’.
cgit-configurationparameter: string section ¶The name of the current repository section - all repositories defined after this option will inherit the current section name.
Defaults to ‘""’.
cgit-configurationparameter: string section-sort ¶Flag which, when set to ‘1’, will sort the sections on the repository listing by name.
Defaults to ‘""’.
cgit-configurationparameter: integer section-from-path ¶A number which, if defined prior to repository-directory, specifies how many path elements from each repo path to use as a default section name.
Defaults to ‘0’.
cgit-configurationparameter: boolean side-by-side-diffs? ¶If set to ‘#t’ shows side-by-side diffs instead of unidiffs per default.
Defaults to ‘#f’.
cgit-configurationparameter: file-object source-filter ¶Specifies a command which will be invoked to format plaintext blobs in the tree view.
Defaults to ‘""’.
cgit-configurationparameter: integer summary-branches ¶Specifies the number of branches to display in the repository “summary” view.
Defaults to ‘10’.
cgit-configurationparameter: integer summary-log ¶Specifies the number of log entries to display in the repository “summary” view.
Defaults to ‘10’.
Specifies the number of tags to display in the repository “summary” view.
Defaults to ‘10’.
cgit-configurationparameter: string strict-export ¶Filename which, if specified, needs to be present within the repository for cgit to allow access to that repository.
Defaults to ‘""’.
cgit-configurationparameter: string virtual-root ¶URL which, if specified, will be used as root for all cgit links.
Defaults to ‘"/"’.
cgit-configurationparameter: repository-cgit-configuration-list repositories ¶A list of cgit-repo records to use with config.
Defaults to ‘()’.
Available
repository-cgit-configurationfields are:repository-cgit-configurationparameter: repo-list snapshots ¶A mask of snapshot formats for this repo that cgit generates links for, restricted by the global
snapshotssetting.Defaults to ‘()’.
repository-cgit-configurationparameter: repo-file-object source-filter ¶Override the default
source-filter.Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string url ¶The relative URL used to access the repository.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-file-object about-filter ¶Override the default
about-filter.Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string branch-sort ¶Flag which, when set to ‘age’, enables date ordering in the branch ref list, and when set to ‘name’ enables ordering by branch name.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-list clone-url ¶A list of URLs which can be used to clone repo.
Defaults to ‘()’.
repository-cgit-configurationparameter: repo-file-object commit-filter ¶Override the default
commit-filter.Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string commit-sort ¶Flag which, when set to ‘date’, enables strict date ordering in the commit log, and when set to ‘topo’ enables strict topological ordering.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string defbranch ¶The name of the default branch for this repository. If no such branch exists in the repository, the first branch name (when sorted) is used as default instead. By default branch pointed to by HEAD, or “master” if there is no suitable HEAD.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string desc ¶The value to show as repository description.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string homepage ¶The value to show as repository homepage.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-file-object email-filter ¶Override the default
email-filter.Defaults to ‘""’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-commit-graph? ¶A flag which can be used to disable the global setting
enable-commit-graph?.Defaults to ‘disabled’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-log-filecount? ¶A flag which can be used to disable the global setting
enable-log-filecount?.Defaults to ‘disabled’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-log-linecount? ¶A flag which can be used to disable the global setting
enable-log-linecount?.Defaults to ‘disabled’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-remote-branches? ¶Flag which, when set to
#t, will make cgit display remote branches in the summary and refs views.Defaults to ‘disabled’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-subject-links? ¶A flag which can be used to override the global setting
enable-subject-links?.Defaults to ‘disabled’.
repository-cgit-configurationparameter: maybe-repo-boolean enable-html-serving? ¶A flag which can be used to override the global setting
enable-html-serving?.Defaults to ‘disabled’.
repository-cgit-configurationparameter: repo-boolean hide? ¶Flag which, when set to
#t, hides the repository from the repository index.Defaults to ‘#f’.
repository-cgit-configurationparameter: repo-boolean ignore? ¶Flag which, when set to ‘#t’, ignores the repository.
Defaults to ‘#f’.
repository-cgit-configurationparameter: repo-file-object logo ¶URL which specifies the source of an image which will be used as a logo on this repo’s pages.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string logo-link ¶URL loaded when clicking on the cgit logo image.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-file-object owner-filter ¶Override the default
owner-filter.Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string module-link ¶Text which will be used as the formatstring for a hyperlink when a submodule is printed in a directory listing. The arguments for the formatstring are the path and SHA1 of the submodule commit.
Defaults to ‘""’.
repository-cgit-configurationparameter: module-link-path module-link-path ¶Text which will be used as the formatstring for a hyperlink when a submodule with the specified subdirectory path is printed in a directory listing.
Defaults to ‘()’.
repository-cgit-configurationparameter: repo-string max-stats ¶Override the default maximum statistics period.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string name ¶The value to show as repository name.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string owner ¶A value used to identify the owner of the repository.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string path ¶An absolute path to the repository directory.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string readme ¶A path (relative to repo) which specifies a file to include verbatim as the “About” page for this repo.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-string section ¶The name of the current repository section - all repositories defined after this option will inherit the current section name.
Defaults to ‘""’.
repository-cgit-configurationparameter: repo-list extra-options ¶Extra options will be appended to cgitrc file.
Defaults to ‘()’.
cgit-configurationparameter: list extra-options ¶Extra options will be appended to cgitrc file.
Defaults to ‘()’.
However, it could be that you just want to get a cgitrc up and
running. In that case, you can pass an opaque-cgit-configuration as
a record to cgit-service-type. As its name indicates, an opaque
configuration does not have easy reflective capabilities.
Available opaque-cgit-configuration fields are:
opaque-cgit-configurationparameter: package cgit ¶The cgit package.
opaque-cgit-configurationparameter: string string ¶The contents of the
cgitrc, as a string.
For example, if your cgitrc is just the empty string, you could
instantiate a cgit service like this:
(service cgit-service-type
(opaque-cgit-configuration
(cgitrc "")))
Gitolite Service
Gitolite is a tool for hosting Git repositories on a central server.
Gitolite can handle multiple repositories and users, and supports flexible configuration of the permissions for the users on the repositories.
The following example will configure Gitolite using the default git
user, and the provided SSH public key.
(service gitolite-service-type
(gitolite-configuration
(admin-pubkey (plain-file
"yourname.pub"
"ssh-rsa AAAA... guix@example.com"))))
Gitolite is configured through a special admin repository which you can
clone, for example, if you setup Gitolite on example.com, you would
run the following command to clone the admin repository.
git clone git@example.com:gitolite-admin
When the Gitolite service is activated, the provided admin-pubkey
will be inserted in to the keydir directory in the gitolite-admin
repository. If this results in a change in the repository, it will be
committed using the message “gitolite setup by GNU Guix”.
- Data Type: gitolite-configuration
Data type representing the configuration for
gitolite-service-type.package(default: gitolite)Gitolite package to use. There are optional Gitolite dependencies that are not included in the default package, such as Redis and git-annex. These features can be made available by using the
make-gitoliteprocedure in the(gnu packages version-control) module to produce a variant of Gitolite with the desired additional dependencies.The following code returns a package in which the Redis and git-annex programs can be invoked by Gitolite’s scripts:
(use-modules (gnu packages databases) (gnu packages haskell-apps) (gnu packages version-control)) (make-gitolite (list redis git-annex))user(default: git)User to use for Gitolite. This will be user that you use when accessing Gitolite over SSH.
group(default: git)Group to use for Gitolite.
home-directory(default: "/var/lib/gitolite")Directory in which to store the Gitolite configuration and repositories.
rc-file(default: (gitolite-rc-file))A “file-like” object (see file-like objects), representing the configuration for Gitolite.
admin-pubkey(default: #f)A “file-like” object (see file-like objects) used to setup Gitolite. This will be inserted in to the keydir directory within the gitolite-admin repository.
To specify the SSH key as a string, use the
plain-filefunction.(plain-file "yourname.pub" "ssh-rsa AAAA... guix@example.com")
- Data Type: gitolite-rc-file
Data type representing the Gitolite RC file.
umask(default:#o0077)This controls the permissions Gitolite sets on the repositories and their contents.
A value like
#o0027will give read access to the group used by Gitolite (by default:git). This is necessary when using Gitolite with software like cgit or gitweb.local-code(default:"$rc{GL_ADMIN_BASE}/local")Allows you to add your own non-core programs, or even override the shipped ones with your own.
Please supply the FULL path to this variable. By default, directory called "local" in your gitolite clone is used, providing the benefits of versioning them as well as making changes to them without having to log on to the server.
unsafe-pattern(default:#f)An optional Perl regular expression for catching unsafe configurations in the configuration file. See Gitolite’s documentation for more information.
When the value is not
#f, it should be a string containing a Perl regular expression, such as ‘"[`~#\$\&()|;<>]"’, which is the default value used by gitolite. It rejects any special character in configuration that might be interpreted by a shell, which is useful when sharing the administration burden with other people that do not otherwise have shell access on the server.git-config-keys(default:"")Gitolite allows you to set git config values using the ‘config’ keyword. This setting allows control over the config keys to accept.
roles(default:'(("READERS" . 1) ("WRITERS" . )))Set the role names allowed to be used by users running the perms command.
enable(default:'("help" "desc" "info" "perms" "writable" "ssh-authkeys" "git-config" "daemon" "gitweb"))This setting controls the commands and features to enable within Gitolite.
Gitile Service
Gitile is a Git forge for viewing public git repository contents from a web browser.
Gitile works best in collaboration with Gitolite, and will serve the public repositories from Gitolite by default. The service should listen only on a local port, and a webserver should be configured to serve static resources. The gitile service provides an easy way to extend the Nginx service for that purpose (see NGINX).
The following example will configure Gitile to serve repositories from a custom location, with some default messages for the home page and the footers.
(service gitile-service-type
(gitile-configuration
(repositories "/srv/git")
(base-git-url "https://myweb.site/git")
(index-title "My git repositories")
(intro '((p "This is all my public work!")))
(footer '((p "This is the end")))
(nginx-server-block
(nginx-server-configuration
(ssl-certificate
"/etc/letsencrypt/live/myweb.site/fullchain.pem")
(ssl-certificate-key
"/etc/letsencrypt/live/myweb.site/privkey.pem")
(listen '("443 ssl http2" "[::]:443 ssl http2"))
(locations
(list
;; Allow for https anonymous fetch on /git/ urls.
(git-http-nginx-location-configuration
(git-http-configuration
(uri-path "/git/")
(git-root "/var/lib/gitolite/repositories")))))))))
In addition to the configuration record, you should configure your git repositories to contain some optional information. First, your public repositories need to contain the git-daemon-export-ok magic file that allows Git to export the repository. Gitile uses the presence of this file to detect public repositories it should make accessible. To do so with Gitolite for instance, modify your conf/gitolite.conf to include this in the repositories you want to make public:
repo foo
R = daemon
In addition, Gitile can read the repository configuration to display more information on the repository. Gitile uses the gitweb namespace for its configuration. As an example, you can use the following in your conf/gitolite.conf:
repo foo
R = daemon
desc = A long description, optionally with <i>HTML</i>, shown on the index page
config gitweb.name = The Foo Project
config gitweb.synopsis = A short description, shown on the main page of the project
Do not forget to commit and push these changes once you are satisfied. You may need to change your gitolite configuration to allow the previous configuration options to be set. One way to do that is to add the following service definition:
(service gitolite-service-type
(gitolite-configuration
(admin-pubkey (local-file "key.pub"))
(rc-file
(gitolite-rc-file
(umask #o0027)
;; Allow to set any configuration key
(git-config-keys ".*")
;; Allow any text as a valid configuration value
(unsafe-patt "^$")))))
- Data Type: gitile-configuration
Data type representing the configuration for
gitile-service-type.package(default: gitile)Gitile package to use.
host(default:"localhost")The host on which gitile is listening.
port(default:8080)The port on which gitile is listening.
database(default:"/var/lib/gitile/gitile-db.sql")The location of the database.
repositories(default:"/var/lib/gitolite/repositories")The location of the repositories. Note that only public repositories will be shown by Gitile. To make a repository public, add an empty git-daemon-export-ok file at the root of that repository.
base-git-urlThe base git url that will be used to show clone commands.
index-title(default:"Index")The page title for the index page that lists all the available repositories.
intro(default:'())The intro content, as a list of sxml expressions. This is shown above the list of repositories, on the index page.
footer(default:'())The footer content, as a list of sxml expressions. This is shown on every page served by Gitile.
nginx-server-blockAn nginx server block that will be extended and used as a reverse proxy by Gitile to serve its pages, and as a normal web server to serve its assets.
You can use this block to add more custom URLs to your domain, such as a
/git/URL for anonymous clones, or serving any other files you would like to serve.
Next: Службы подключения PAM, Previous: Сервисы упраления версиями, Up: Сервисы [Contents][Index]
12.9.31 Игровые службы
The Battle for Wesnoth Service
The Battle for Wesnoth is a fantasy, turn based tactical strategy game, with several single player campaigns, and multiplayer games (both networked and local).
- Variable: Scheme Variable wesnothd-service-type
Service type for the wesnothd service. Its value must be a
wesnothd-configurationobject. To run wesnothd in the default configuration, instantiate it as:(service wesnothd-service-type)
- Data Type: wesnothd-configuration
Data type representing the configuration of
wesnothd.package(default:wesnoth-server)The wesnoth server package to use.
port(default:15000)The port to bind the server to.
Next: Сервисы Guix, Previous: Игровые службы, Up: Сервисы [Contents][Index]
12.9.32 Службы подключения PAM
The (gnu services pam-mount) module provides a service allowing users
to mount volumes when they log in. It should be able to mount any volume
format supported by the system.
- Variable: Scheme Variable pam-mount-service-type
Service type for PAM Mount support.
- Data Type: pam-mount-configuration
Управление конфигурацией операционной системы.
It takes the following parameters:
МодулиThe configuration rules that will be used to generate /etc/security/pam_mount.conf.xml.
The configuration rules are SXML elements (see SXML in GNU Guile Reference Manual), and the default ones don’t mount anything for anyone at login:
`((debug (@ (enable "0"))) (mntoptions (@ (allow ,(string-join '("nosuid" "nodev" "loop" "encryption" "fsck" "nonempty" "allow_root" "allow_other") ",")))) (mntoptions (@ (require "nosuid,nodev"))) (logout (@ (wait "0") (hup "0") (term "no") (kill "no"))) (mkmountpoint (@ (enable "1") (remove "true"))))
Some
volumeelements must be added to automatically mount volumes at login. Here’s an example allowing the useraliceto mount her encryptedHOMEdirectory and allowing the userbobto mount the partition where he stores his data:(define pam-mount-rules `((debug (@ (enable "0"))) (volume (@ (user "alice") (fstype "crypt") (path "/dev/sda2") (mountpoint "/home/alice"))) (volume (@ (user "bob") (fstype "auto") (path "/dev/sdb3") (mountpoint "/home/bob/data") (options "defaults,autodefrag,compress"))) (mntoptions (@ (allow ,(string-join '("nosuid" "nodev" "loop" "encryption" "fsck" "nonempty" "allow_root" "allow_other") ",")))) (mntoptions (@ (require "nosuid,nodev"))) (logout (@ (wait "0") (hup "0") (term "no") (kill "no"))) (mkmountpoint (@ (enable "1") (remove "true"))))) (service pam-mount-service-type (pam-mount-configuration (rules pam-mount-rules)))
The complete list of possible options can be found in the man page for pam_mount.conf.
Next: Службы Linux, Previous: Службы подключения PAM, Up: Сервисы [Contents][Index]
12.9.33 Сервисы Guix
Guix Build Coordinator
The Guix Build Coordinator aids in distributing derivation builds among machines running an agent. The build daemon is still used to build the derivations, but the Guix Build Coordinator manages allocating builds and working with the results.
The Guix Build Coordinator consists of one coordinator, and one or more connected agent processes. The coordinator process handles clients submitting builds, and allocating builds to agents. The agent processes talk to a build daemon to actually perform the builds, then send the results back to the coordinator.
There is a script to run the coordinator component of the Guix Build Coordinator, but the Guix service uses a custom Guile script instead, to provide better integration with G-expressions used in the configuration.
- Variable: Scheme Variable boot-service-type
Service type for the Guix Build Coordinator. Its value must be a
guix-build-coordinator-configurationobject.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Используемый пакет Guix Build Coordinator.
speed(default:1.0)Сервис mcron.
port(default:22)The system group to run the service as.
database-uri-string(default:"sqlite:///var/lib/guix-build-coordinator/guix_build_coordinator.db")URI для использования в базе данных.
speed(default:1.0)The URI describing how to listen to requests from agent processes.
speed(default:1.0)The URI describing how to listen to requests from clients. The client API allows submitting builds and currently isn’t authenticated, so take care when configuring this value.
features(default:'())A G-expression for the allocation strategy to be used. This is a procedure that takes the datastore as an argument and populates the allocation plan in the database.
inputs(default:'())An association list of hooks. These provide a way to execute arbitrary code upon certain events, like a build result being processed.
parallel-hooks(default: ’())Hooks can be configured to run in parallel. This parameter is an association list of hooks to do in parallel, where the key is the symbol for the hook and the value is the number of threads to run.
port(default:22)The Guile package with which to run the Guix Build Coordinator.
- Variable: Процедура Scheme sane-service-type
Service type for a Guix Build Coordinator agent. Its value must be a
guix-build-coordinator-agent-configurationobject.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
package(default:guix-build-coordinator/agent-only)Используемый пакет Guix Build Coordinator.
speed(default:1.0)Сервис mcron.
port(default:22)The URI to use when connecting to the coordinator.
channel-authenticationRecord describing how this agent should authenticate with the coordinator. Possible record types are described below.
speed(default:1.0)The systems for which this agent should fetch builds. The agent process will use the current system it’s running on as the default.
parallel-builds(default:1)Число сборок, которые могут быть запущены на машине.
max-allocated-builds(default:#f)The maximum number of builds this agent can be allocated.
port(default:22)Load average value to look at when considering starting new builds, if the 1 minute load average exceeds this value, the agent will wait before starting new builds.
This will be unspecified if the value is
#f, and the agent will use the number of cores reported by the system as the max 1 minute load average.port(default:22)URLs from which to attempt to fetch substitutes for derivations, if the derivations aren’t already available.
native-inputs(default:'())URLs from which to attempt to fetch substitutes for build inputs, if the input store items aren’t already available.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
uuidThe UUID of the agent. This should be generated by the coordinator process, stored in the coordinator database, and used by the intended agent.
passwordThe password to use when connecting to the coordinator.
- Конфигурирование: системы
Data type representing an agent authenticating with a coordinator via a UUID and password read from a file.
uuidThe UUID of the agent. This should be generated by the coordinator process, stored in the coordinator database, and used by the intended agent.
профильA file containing the password to use when connecting to the coordinator.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
каналыName of an agent, this is used to match up to an existing entry in the database if there is one. When no existing entry is found, a new entry is automatically added.
tokenDynamic auth token, this is created and stored in the coordinator database, and is used by the agent to authenticate.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
каналыName of an agent, this is used to match up to an existing entry in the database if there is one. When no existing entry is found, a new entry is automatically added.
профильFile containing the dynamic auth token, this is created and stored in the coordinator database, and is used by the agent to authenticate.
The Guix Build Coordinator package contains a script to query an instance of the Guix Data Service for derivations to build, and then submit builds for those derivations to the coordinator. The service type below assists in running this script. This is an additional tool that may be useful when building derivations contained within an instance of the Guix Data Service.
- Variable: Процедура Scheme sane-service-type
Service type for the guix-build-coordinator-queue-builds-from-guix-data-service script. Its value must be a
guix-build-coordinator-queue-builds-configurationobject.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Используемый пакет Guix Build Coordinator.
speed(default:1.0)Сервис mcron.
port(default:22)The URI to use when connecting to the coordinator.
speed(default:1.0)The systems for which to fetch derivations to build.
port(default:22)An association list of system and target pairs for which to fetch derivations to build.
speed(default:1.0)The Guix Data Service instance from which to query to find out about derivations to build.
guix-data-service-build-server-id(default:#f)The Guix Data Service build server ID corresponding to the builds being submitted. Providing this speeds up the submitting of builds as derivations that have already been submitted can be skipped before asking the coordinator to build them.
processed-commits-file(default:"/var/cache/guix-build-coordinator-queue-builds/processed-commits")A file to record which commits have been processed, to avoid needlessly processing them again if the service is restarted.
Сервисы баз данных
The Guix Data Service processes, stores and provides data about GNU Guix. This includes information about packages, derivations and lint warnings.
The data is stored in a PostgreSQL database, and available through a web interface.
- Variable: Scheme Variable guix-data-service-type
Service type for the Guix Data Service. Its value must be a
guix-data-service-configurationobject. The service optionally extends the getmail service, as the guix-commits mailing list is used to find out about changes in the Guix git repository.
- Data Type: guix-data-service-configuration
Data type representing the configuration of the Guix Data Service.
speed(default:1.0)The Guix Data Service package to use.
speed(default:1.0)Сервис mcron.
port(default:22)The system group to run the service as.
port(default:22)Сервис rottlog.
speed(default:1.0)Сервис rottlog.
parallel-builds(default:1)If set, this is the list of mailboxes that the getmail service will be configured to listen to.
compression-level(default:3)If set, this is the
getmail-retriever-configurationobject with which to configure getmail to fetch mail from the guix-commits mailing list.extra-options(default: ’())Дополнительные параметры командной строки для
guix-data-service.features(default:'())Extra command line options for
guix-data-service-process-jobs.
Nar Herder
The Nar Herder is a utility for managing a collection of nars.
- Variable: Scheme Variable nar-herder-type
Service type for the Guix Data Service. Its value must be a
nar-herder-configurationobject. The service optionally extends the getmail service, as the guix-commits mailing list is used to find out about changes in the Guix git repository.
- Data Type: nar-herder-configuration
Data type representing the configuration of the Guix Data Service.
package(default:nar-herder)The Nar Herder package to use.
user(default:"nar-herder")Сервис mcron.
group(default:"nar-herder")The system group to run the service as.
port(default:8734)The port to bind the server to.
speed(default:1.0)The host to bind the server to.
features(default:'())Optional URL of the other Nar Herder instance which should be mirrored. This means that this Nar Herder instance will download it’s database, and keep it up to date.
database(default:"/var/lib/nar-herder/nar_herder.db")Location for the database. If this Nar Herder instance is mirroring another, the database will be downloaded if it doesn’t exist. If this Nar Herder instance isn’t mirroring another, an empty database will be created.
database-dump(default:"/var/lib/nar-herder/nar_herder_dump.db")Location of the database dump. This is created and regularly updated by taking a copy of the database. This is the version of the database that is available to download.
storage(default:#f)Optional location in which to store nars.
storage-limit(default:"none")Limit in bytes for the nars stored in the storage location. This can also be set to “none” so that there is no limit.
When the storage location exceeds this size, nars are removed according to the nar removal criteria.
storage-nar-removal-criteria(default:'())Criteria used to remove nars from the storage location. These are used in conjunction with the storage limit.
When the storage location exceeds the storage limit size, nars will be checked against the nar removal criteria and if any of the criteria match, they will be removed. This will continue until the storage location is below the storage limit size.
Each criteria is specified by a string, then an equals sign, then another string. Currently, only one criteria is supported, checking if a nar is stored on another Nar Herder instance.
ttl(default:#f)Produce
Cache-ControlHTTP headers that advertise a time-to-live (TTL) of ttl. ttl must denote a duration:5dmeans 5 days,1mmeans 1 month, and so on.This allows the user’s Guix to keep substitute information in cache for ttl.
negative-ttl(default:#f)Similarly produce
Cache-ControlHTTP headers to advertise the time-to-live (TTL) of negative lookups—missing store items, for which the HTTP 404 code is returned. By default, no negative TTL is advertised.log-level(default:'DEBUG)Log level to use, specify a log level like
'INFOto stop logging individual requests.
Next: Сервисы Hurd, Previous: Сервисы Guix, Up: Сервисы [Contents][Index]
12.9.34 Службы Linux
Почтовые сервисы
Early OOM, also known as Earlyoom, is a minimalist out of memory (OOM) daemon that runs in user space and provides a more responsive and configurable alternative to the in-kernel OOM killer. It is useful to prevent the system from becoming unresponsive when it runs out of memory.
- Scheme Variable: earlyoom-service-type
The service type for running
earlyoom, the Early OOM daemon. Its value must be aearlyoom-configurationobject, described below. The service can be instantiated in its default configuration with:
- Data Type: earlyoom-configuration
This is the configuration record for the
earlyoom-service-type.port(default:22)Используемый пакет Earlyoom.
parallel-builds(default:1)The threshold for the minimum available memory, in percentages.
speed(default:1.0)The threshold for the minimum free swap memory, in percentages.
speed(default:1.0)A regular expression (as a string) to match the names of the processes that should be preferably killed.
port(default:22)A regular expression (as a string) to match the names of the processes that should not be killed.
port(default:22)The interval in seconds at which a memory report is printed. It is disabled by default.
compression-level(default:3)A boolean indicating whether the positive adjustments set in /proc/*/oom_score_adj should be ignored.
speed(default:1.0)A boolean indicating whether debug messages should be printed. The logs are saved at /var/log/earlyoom.log.
speed(default:1.0)This can be used to provide a custom command used for sending notifications.
Сервисы Kerberos
The kernel module loader service allows one to load loadable kernel modules
at boot. This is especially useful for modules that don’t autoload and need
to be manually loaded, as is the case with ddcci.
- Процедура Scheme: sane-service-type
The service type for loading loadable kernel modules at boot with
modprobe. Its value must be a list of strings representing module names. For example loading the drivers provided byddcci-driver-linux, in debugging mode by passing some module parameters, can be done as follow:(use-modules (gnu) (gnu services)) (use-package-modules linux) (use-service-modules linux) (define ddcci-config (plain-file "ddcci.conf" "options ddcci dyndbg delay=120")) (operating-system ... (services (cons* (service kernel-module-loader-service-type '("ddcci" "ddcci_backlight")) (simple-service 'ddcci-config etc-service-type (list `("modprobe.d/ddcci.conf" ,ddcci-config))) %base-services)) (kernel-loadable-modules (list ddcci-driver-linux)))
Почтовые сервисы
The Rasdaemon service provides a daemon which monitors platform RAS (Reliability, Availability, and Serviceability) reports from Linux kernel trace events, logging them to syslogd.
Reliability, Availability and Serviceability is a concept used on servers meant to measure their robustness.
Relability is the probability that a system will produce correct outputs:
- Generally measured as Mean Time Between Failures (MTBF), and
- Enhanced by features that help to avoid, detect and repair hardware по умолчанию
Availability is the probability that a system is operational at a given time:
- Generally measured as a percentage of downtime per a period of time, and
- Often uses mechanisms to detect and correct hardware faults in runtime.
Serviceability is the simplicity and speed with which a system can be repaired or maintained:
- Generally measured on Mean Time Between Repair (MTBR).
Among the monitoring measures, the most usual ones include:
- CPU – detect errors at instruction execution and at L1/L2/L3 caches;
- Memory – add error correction logic (ECC) to detect and correct errors;
- I/O – add CRC checksums for transferred data;
- Storage – RAID, journal file systems, checksums, Self-Monitoring, Analysis and Reporting Technology (SMART).
By monitoring the number of occurrences of error detections, it is possible to identify if the probability of hardware errors is increasing, and, on such case, do a preventive maintenance to replace a degraded component while those errors are correctable.
For detailed information about the types of error events gathered and how to make sense of them, see the kernel administrator’s guide at https://www.kernel.org/doc/html/latest/admin-guide/ras.html.
- Процедура Scheme: sane-service-type
Service type for the
rasdaemonservice. It accepts arasdaemon-configurationobject. Instantiating likewill load with a default configuration, which monitors all events and logs to syslogd.
- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
features(default:'())-
A boolean indicating whether to record the events in an SQLite database. This provides a more structured access to the information contained in the log file. The database location is hard-coded to /var/lib/rasdaemon/ras-mc_event.db.
Игровые службы
The Zram device service provides a compressed swap device in system memory. The Linux Kernel documentation has more information about zram devices.
- Процедура Scheme: sane-service-type
This service creates the zram block device, formats it as swap and enables it as a swap device. The service’s value is a
zram-device-configurationrecord.- Data Type: pagekite-configuration
Управление конфигурацией операционной системы.
port(default:22)This is the amount of space you wish to provide for the zram device. It accepts a string and can be a number of bytes or use a suffix, eg.:
"512M"or1024000.compression-level(default:3)This is the compression algorithm you wish to use. It is difficult to list all the possible compression options, but common ones supported by Guix’s Linux Libre Kernel include
'lzo,'lz4and'zstd.port(default:22)This is the maximum amount of memory which the zram device can use. Setting it to ’0’ disables the limit. While it is generally expected that compression will be 2:1, it is possible that uncompressable data can be written to swap and this is a method to limit how much memory can be used. It accepts a string and can be a number of bytes or use a suffix, eg.:
"2G".priority(default#f)This is the priority of the swap device created from the zram device. See Swap Space for a description of swap priorities. You might want to set a specific priority for the zram device, otherwise it could end up not being used much for the reasons described there.
Next: Разнообразные службы, Previous: Службы Linux, Up: Сервисы [Contents][Index]
12.9.35 Сервисы Hurd
- Процедура Scheme: sane-service-type
This service starts the fancy
VGAconsole client on the Hurd.The service’s value is a
hurd-console-configurationrecord.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет Hurd.
- Процедура Scheme: sane-service-type
This service starts a tty using the Hurd
gettyprogram.The service’s value is a
hurd-getty-configurationrecord.
- Тип данных: build-machine
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет Hurd.
ttyThe name of the console this Getty runs on—e.g.,
"tty1".port(default:22)An integer specifying the baud rate of the tty.
Previous: Сервисы Hurd, Up: Сервисы [Contents][Index]
12.9.36 Разнообразные службы
Fingerprint Service
The (gnu services authentication) module provides a DBus service to
read and identify fingerprints via a fingerprint sensor.
- Scheme Variable: fprintd-service-type
The service type for
fprintd, which provides the fingerprint reading capability.
System Control Service
The (gnu services sysctl) provides a service to configure kernel
parameters at boot.
- Scheme Variable: sysctl-service-type
The service type for
sysctl, which modifies kernel parameters under /proc/sys/. To enable IPv4 forwarding, it can be instantiated as:(service sysctl-service-type (sysctl-configuration (settings '(("net.ipv4.ip_forward" . "1")))))Поскольку
sysctl-service-typeиспользуется в списках служб по умолчанию,%base-servicesи%desktop-services, вы можете использоватьmodify-services, чтобы изменить его конфигурации и добить нужные параметры ядра (seemodify-services).
- Data Type: sysctl-configuration
The data type representing the configuration of
sysctl.sysctl(default:(file-append procps "/sbin/sysctl")The
sysctlexecutable to use.port(default:22)An association list specifies kernel parameters and their values.
- Scheme Variable: ant-build-system
An association list specifying the default
sysctlparameters on Guix System.
PC/SC Smart Card Daemon Service
The (gnu services security-token) module provides the following
service to run pcscd, the PC/SC Smart Card Daemon.
pcscd is the daemon program for pcsc-lite and the MuscleCard
framework. It is a resource manager that coordinates communications with
smart card readers, smart cards and cryptographic tokens that are connected
to the system.
- Scheme Variable: pcscd-service-type
Service type for the
pcscdservice. Its value must be apcscd-configurationobject. To run pcscd in the default configuration, instantiate it as:
- Data Type: pcscd-configuration
The data type representing the configuration of
pcscd.pcsc-lite(default:pcsc-lite)The pcsc-lite package that provides pcscd.
usb-drivers(default:(list ccid))List of packages that provide USB drivers to pcscd. Drivers are expected to be under pcsc/drivers in the store directory of the package.
Lirc Service
The (gnu services lirc) module provides the following service.
- Scheme Procedure: lirc-service [#:lirc lirc] [#:device #f] [#:driver #f] [#:config-file #f] [#:extra-options '()]
Return a service that runs LIRC, a daemon that decodes infrared signals from remote controls.
Optionally, device, driver and config-file (configuration file name) may be specified. See
lircdmanual for details.Finally, extra-options is a list of additional command-line options passed to
lircd.
Spice Service
The (gnu services spice) module provides the following service.
- Scheme Procedure: spice-vdagent-service [#:spice-vdagent]
Returns a service that runs VDAGENT, a daemon that enables sharing the clipboard with a vm and setting the guest display resolution when the graphical console window resizes.
inputattach Service
The inputattach service allows you to use input devices such as Wacom tablets, touchscreens, or joysticks with the Xorg display server.
- Scheme Variable: inputattach-service-type
Type of a service that runs
inputattachon a device and dispatches events from it.
- Data Type: inputattach-configuration
device-type(default:"wacom")The type of device to connect to. Run
inputattach --help, from theinputattachpackage, to see the list of supported device types.device(default:"/dev/ttyS0")The device file to connect to the device.
baud-rate(default:#f)Baud rate to use for the serial connection. Should be a number or
#f.log-file(default:#f)If true, this must be the name of a file to log messages to.
Создание служб
The (gnu services dict) module provides the following service:
- Процедура Scheme: sane-service-type
This is the type of the service that runs the
dicoddaemon, an implementation of DICT server (see Dicod in GNU Dico Manual).
- Scheme Procedure: dicod-service [#:config (dicod-configuration)]
Return a service that runs the
dicoddaemon, an implementation of DICT server (see Dicod in GNU Dico Manual).The optional config argument specifies the configuration for
dicod, which should be a<dicod-configuration>object, by default it serves the GNU Collaborative International Dictionary of English.You can add
open localhostto your ~/.dico file to makelocalhostthe default server fordicoclient (see Initialization File in GNU Dico Manual).
- Data Type: dicod-configuration
Data type representing the configuration of dicod.
dico(default: dico)Package object of the GNU Dico dictionary server.
interfaces(default: ’("localhost"))This is the list of IP addresses and ports and possibly socket file names to listen to (see
listendirective in GNU Dico Manual).handlers(default: ’())List of
<dicod-handler>objects denoting handlers (module instances).databases(default: (list %dicod-database:gcide))List of
<dicod-database>objects denoting dictionaries to be served.
- Data Type: dicod-handler
Data type representing a dictionary handler (module instance).
nameName of the handler (module instance).
module(default: #f)Name of the dicod module of the handler (instance). If it is
#f, the module has the same name as the handler. (see Modules in GNU Dico Manual).optionsList of strings or gexps representing the arguments for the module handler
- Data Type: dicod-database
Data type representing a dictionary database.
nameName of the database, will be used in DICT commands.
handlerName of the dicod handler (module instance) used by this database (see Handlers in GNU Dico Manual).
complex?(default: #f)Whether the database configuration complex. The complex configuration will need a corresponding
<dicod-handler>object, otherwise not.optionsList of strings or gexps representing the arguments for the database (see Databases in GNU Dico Manual).
- Scheme Variable: %dicod-database:gcide
A
<dicod-database>object serving the GNU Collaborative International Dictionary of English using thegcidepackage.
The following is an example dicod-service configuration.
(dicod-service #:config
(dicod-configuration
(handlers (list (dicod-handler
(name "wordnet")
(module "dictorg")
(options
(list #~(string-append "dbdir=" #$wordnet))))))
(databases (list (dicod-database
(name "wordnet")
(complex? #t)
(handler "wordnet")
(options '("database=wn")))
%dicod-database:gcide))))
Docker Service
Модуль (gnu services docker) предоставляет следующие сервисы.
- Scheme Variable: docker-service-type
-
This is the type of the service that runs Docker, a daemon that can execute application bundles (sometimes referred to as “containers”) in isolated environments.
- Data Type: docker-configuration
This is the data type representing the configuration of Docker and Containerd.
docker(default:docker)Используемый пакет Docker демона.
docker-cli(default:docker-cli)Используемый Docker клиент.
containerd(default: containerd)The Containerd package to use.
port(default:22)Используемый пользователей сетевой прокси-пакет Docker.
speed(default:1.0)Enable or disable the use of the Docker user-land networking proxy.
features(default:'())Как включить или отключить подстановки.
speed(default:1.0)Enable or disable the addition of iptables rules.
environment-variables(default:())List of environment variables to set for
dockerd.This must be a list of strings where each string has the form ‘key=value’ as in this example:
(list "LANGUAGE=eo:ca:eu" "TMPDIR=/tmp/dockerd")
- Scheme Variable: singularity-service-type
This is the type of the service that allows you to run Singularity, a Docker-style tool to create and run application bundles (aka. “containers”). The value for this service is the Singularity package to use.
The service does not install a daemon; instead, it installs helper programs as setuid-root (see Программы setuid) such that unprivileged users can invoke
singularity runand similar commands.
Сервисы аудио
Модуль (gnu services auditd) предоставляет следующие сервисы.
- Scheme Variable: auditd-service-type
-
This is the type of the service that runs auditd, a daemon that tracks security-relevant information on your system.
Examples of things that can be tracked:
- Файловые системы
- Установка системы
- Вызов
guix gc - Failed login attempts
- Firewall filtering
- Сервисы сети
auditctlfrom theauditpackage can be used in order to add or remove events to be tracked (until the next reboot). In order to permanently track events, put the command line arguments of auditctl into a file calledaudit.rulesin the configuration directory (see below).aureportfrom theauditpackage can be used in order to view a report of all recorded events. The audit daemon by default logs into the file /var/log/audit.log.
- Тип данных: build-machine
This is the data type representing the configuration of auditd.
port(default:22)Пакет аудита для использования.
features(default:'())The directory containing the configuration file for the audit package, which must be named
auditd.conf, and optionally some audit rules to instantiate on startup.
Сервисы DNS
Модуль (gnu services science) предоставляет следующие сервис.
- Процедура Scheme: sane-service-type
-
This is a type of service which is used to run a webapp created with
r-shiny. This service sets theR_LIBS_USERenvironment variable and runs the provided script to callrunApp.- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Пакет для использования.
binary(default"rshiny")The name of the binary or shell script located at
package/bin/to run when the service is run.The common way to create this file is as follows:
… (let* ((out (assoc-ref %outputs "out")) (targetdir (string-append out "/share/" ,name)) (app (string-append out "/bin/" ,name)) (Rbin (search-input-file %build-inputs "/bin/Rscript"))) ;; … (mkdir-p (string-append out "/bin")) (call-with-output-file app (lambda (port) (format port "#!~a library(shiny) setwd(\"~a\") runApp(launch.browser=0, port=4202)~%\n" Rbin targetdir))))
Сервисы DNS
Модуль (gnu services nix) предоставляет следующий сервис.
- Scheme Variable: nix-service-type
-
This is the type of the service that runs build daemon of the Nix package manager. Here is an example showing how to use it:
(use-modules (gnu)) (use-service-modules nix) (use-package-modules package-management) (operating-system ;; … (packages (append (list nix) %base-packages)) (services (append (list (service nix-service-type)) %base-services)))
After
guix system reconfigureconfigure Nix for your user:- Add a Nix channel and update it. See Nix Package Manager Guide.
- Create a symlink to your profile and activate Nix profile:
$ ln -s "/nix/var/nix/profiles/per-user/$USER/profile" ~/.nix-profile $ source /run/current-system/profile/etc/profile.d/nix.sh
- Конфигурирование: системы
Управление конфигурацией операционной системы.
speed(default:1.0)Используемый пакет Nix.
port(default:22)Specifies whether builds are sandboxed by default.
inputs(default:'())This is a list of strings or objects appended to the
build-sandbox-itemsfield of the configuration file.extra-config(default:'())This is a list of strings or objects appended to the configuration file. It is used to pass extra text to be added verbatim to the configuration file.
extra-options(default:'())Дополнительные параметры командной строки для
nix-service-type.
Fail2Ban service
fail2ban scans log files
(e.g. /var/log/apache/error_log) and bans IP addresses that show
malicious signs – repeated password failures, attempts to make use of
exploits, etc.
fail2ban-service-type service type is provided by the (gnu
services security) module.
This service type runs the fail2ban daemon. It can be configured in
various ways, which are:
- Basic configuration
The basic parameters of the Fail2Ban service can be configured via its
fail2banconfiguration, which is documented below.- User-specified jail extensions
The
fail2ban-jail-servicefunction can be used to add new Fail2Ban jails.- Shepherd extension mechanism
Service developers can extend the
fail2ban-service-typeservice type itself via the usual service extension mechanism.
- Scheme Variable: fail2ban-service-type
-
This is the type of the service that runs
fail2bandaemon. Below is an example of a basic, explicit configuration:(append (list (service fail2ban-service-type (fail2ban-configuration (extra-jails (list (fail2ban-jail-configuration (name "sshd") (enabled? #t)))))) ;; There is no implicit dependency on an actual SSH ;; service, so you need to provide one. (service openssh-service-type)) %base-services)
- Scheme Procedure: fail2ban-jail-service svc-type jail
Extend svc-type, a
<service-type>object with jail, afail2ban-jail-configurationobject.For example:
(append (list (service ;; The 'fail2ban-jail-service' procedure can extend any service type ;; with a fail2ban jail. This removes the requirement to explicitly ;; extend services with fail2ban-service-type. (fail2ban-jail-service openssh-service-type (fail2ban-jail-configuration (name "sshd") (enabled? #t))) (openssh-configuration ...))))
Below is the reference for the different jail-service-type
configuration records.
- Data Type: fail2ban-configuration
Available
fail2ban-configurationfields are:fail2ban(default:fail2ban) (type: package)The
fail2banpackage to use. It is used for both binaries and as base default configuration that is to be extended with<fail2ban-jail-configuration>objects.run-directory(default:"/var/run/fail2ban") (type: string)The state directory for the
fail2bandaemon.jails(default:()) (type: list-of-fail2ban-jail-configurations)Instances of
<fail2ban-jail-configuration>collected from extensions.extra-jails(default:()) (type: list-of-fail2ban-jail-configurations)Instances of
<fail2ban-jail-configuration>explicitly provided.extra-content(default:()) (type: text-config)Extra raw content to add to the end of the jail.local file, provided as a list of file-like objects.
- Data Type: fail2ban-ignore-cache-configuration
Available
fail2ban-ignore-cache-configurationfields are:key(type: string)Cache key.
max-count(type: integer)Cache size.
max-time(type: integer)Cache time.
- Data Type: fail2ban-jail-action-configuration
Available
fail2ban-jail-action-configurationfields are:name(type: string)Action name.
arguments(default:()) (type: list-of-arguments)Action arguments.
- Data Type: fail2ban-jail-configuration
Available
fail2ban-jail-configurationfields are:name(type: string)Required name of this jail configuration.
enabled?(default:#t) (type: boolean)Whether this jail is enabled.
backend(type: maybe-symbol)Backend to use to detect changes in the
log-path. The default is ’auto. To consult the defaults of the jail configuration, refer to the /etc/fail2ban/jail.conf file of thefail2banpackage.max-retry(type: maybe-integer)The number of failures before a host get banned (e.g.
(max-retry 5)).max-matches(type: maybe-integer)The number of matches stored in ticket (resolvable via tag
<matches>) in action.find-time(type: maybe-string)The time window during which the maximum retry count must be reached for an IP address to be banned. A host is banned if it has generated
max-retryduring the lastfind-timeseconds (e.g.(find-time "10m")). It can be provided in seconds or using Fail2Ban’s "time abbreviation format", as described inman 5 jail.conf.ban-time(type: maybe-string)The duration, in seconds or time abbreviated format, that a ban should last. (e.g.
(ban-time "10m")).ban-time-increment?(type: maybe-boolean)Whether to consider past bans to compute increases to the default ban time of a specific IP address.
ban-time-factor(type: maybe-string)The coefficient to use to compute an exponentially growing ban time.
ban-time-formula(type: maybe-string)This is the formula used to calculate the next value of a ban time.
ban-time-multipliers(type: maybe-string)Used to calculate next value of ban time instead of formula.
ban-time-max-time(type: maybe-string)The maximum number of seconds a ban should last.
ban-time-rnd-time(type: maybe-string)The maximum number of seconds a randomized ban time should last. This can be useful to stop “clever” botnets calculating the exact time an IP address can be unbanned again.
ban-time-overall-jails?(type: maybe-boolean)When true, it specifies the search of an IP address in the database should be made across all jails. Otherwise, only the current jail of the ban IP address is considered.
ignore-self?(type: maybe-boolean)Never ban the local machine’s own IP address.
ignore-ip(default:()) (type: list-of-strings)A list of IP addresses, CIDR masks or DNS hosts to ignore.
fail2banwill not ban a host which matches an address in this list.ignore-cache(type: maybe-fail2ban-ignore-cache-configuration)Provide cache parameters for the ignore failure check.
filter(type: maybe-fail2ban-jail-filter-configuration)The filter to use by the jail, specified via a
<fail2ban-jail-filter-configuration>object. By default, jails have names matching their filter name.log-time-zone(type: maybe-string)The default time zone for log lines that do not have one.
log-encoding(type: maybe-symbol)The encoding of the log files handled by the jail. Possible values are:
'ascii,'utf-8and'auto.log-path(default:()) (type: list-of-strings)The file names of the log files to be monitored.
action(default:()) (type: list-of-fail2ban-jail-actions)A list of
<fail2ban-jail-action-configuration>.extra-content(default:()) (type: text-config)Extra content for the jail configuration, provided as a list of file-like objects.
- Data Type: fail2ban-jail-filter-configuration
Available
fail2ban-jail-filter-configurationfields are:name(type: string)Filter to use.
mode(type: maybe-string)Mode for filter.
Next: Сертификаты X.509, Previous: Сервисы, Up: Конфигурирование системы [Contents][Index]
12.10 Программы setuid
Some programs need to run with elevated privileges, even when they are
launched by unprivileged users. A notorious example is the passwd
program, which users can run to change their password, and which needs to
access the /etc/passwd and /etc/shadow files—something
normally restricted to root, for obvious security reasons. To address that,
passwd should be setuid-root, meaning that it always runs
with root privileges (see How Change Persona in The GNU C Library
Reference Manual, for more info about the setuid mechanism).
The store itself cannot contain setuid programs: that would be a security issue since any user on the system can write derivations that populate the store (see Хранилище). Thus, a different mechanism is used: instead of changing the setuid or setgid bits directly on files that are in the store, we let the system administrator declare which programs should be entrusted with these additional privileges.
The setuid-programs field of an operating-system declaration
contains a list of <setuid-program> denoting the names of programs to
have a setuid or setgid bit set (see Использование системы конфигурации).
For instance, the mount.nfs program, which is part of the
nfs-utils package, with a setuid root can be designated like this:
(setuid-program
(program (file-append nfs-utils "/sbin/mount.nfs")))
And then, to make mount.nfs setuid on your system, add the
previous example to your operating system declaration by appending it to
%setuid-programs like this:
(operating-system
;; Some fields omitted...
(setuid-programs
(append (list (setuid-program
(program (file-append nfs-utils "/sbin/mount.nfs"))))
%setuid-programs)))
- Data Type: setuid-program
This data type represents a program with a setuid or setgid bit set.
programA file-like object having its setuid and/or setgid bit set.
setuid?(default:#t)Whether to set user setuid bit.
setgid?(default:#f)Whether to set group setgid bit.
user(default:0)UID (integer) or user name (string) for the user owner of the program, defaults to root.
group(default:0)GID (integer) goup name (string) for the group owner of the program, defaults to root.
A default set of setuid programs is defined by the %setuid-programs
variable of the (gnu system) module.
- Scheme Variable: %setuid-programs
A list of
<setuid-program>denoting common programs that are setuid-root.The list includes commands such as
passwd,ping,su, andsudo.
Under the hood, the actual setuid programs are created in the /run/setuid-programs directory at system activation time. The files in this directory refer to the “real” binaries, which are in the store.
Next: Служба выбора имён, Previous: Программы setuid, Up: Конфигурирование системы [Contents][Index]
12.11 Сертификаты X.509
Web servers available over HTTPS (that is, HTTP over the transport-layer security mechanism, TLS) send client programs an X.509 certificate that the client can then use to authenticate the server. To do that, clients verify that the server’s certificate is signed by a so-called certificate authority (CA). But to verify the CA’s signature, clients must have first acquired the CA’s certificate.
Web browsers such as GNU IceCat include their own set of CA certificates, such that they are able to verify CA signatures out-of-the-box.
However, most other programs that can talk HTTPS—wget,
git, w3m, etc.—need to be told where CA certificates
can be found.
In Guix, this is done by adding a package that provides certificates to the
packages field of the operating-system declaration
(see operating-system Reference). Guix includes one such package,
nss-certs, which is a set of CA certificates provided as part of
Mozilla’s Network Security Services.
Note that it is not part of %base-packages, so you need to
explicitly add it. The /etc/ssl/certs directory, which is where most
applications and libraries look for certificates by default, points to the
certificates installed globally.
Unprivileged users, including users of Guix on a foreign distro, can also
install their own certificate package in their profile. A number of
environment variables need to be defined so that applications and libraries
know where to find them. Namely, the OpenSSL library honors the
SSL_CERT_DIR and SSL_CERT_FILE variables. Some applications add
their own environment variables; for instance, the Git version control
system honors the certificate bundle pointed to by the GIT_SSL_CAINFO
environment variable. Thus, you would typically run something like:
guix install nss-certs export SSL_CERT_DIR="$HOME/.guix-profile/etc/ssl/certs" export SSL_CERT_FILE="$HOME/.guix-profile/etc/ssl/certs/ca-certificates.crt" export GIT_SSL_CAINFO="$SSL_CERT_FILE"
As another example, R requires the CURL_CA_BUNDLE environment variable
to point to a certificate bundle, so you would have to run something like
this:
$ guix install glibc-locales $ export GUIX_LOCPATH=$HOME/.guix-profile/lib/locale
For other applications you may want to look up the required environment variable in the relevant documentation.
Next: Начальный RAM-диск, Previous: Сертификаты X.509, Up: Конфигурирование системы [Contents][Index]
12.12 Служба выбора имён
The (gnu system nss) module provides bindings to the configuration
file of the libc name service switch or NSS (see NSS
Configuration File in The GNU C Library Reference Manual). In a
nutshell, the NSS is a mechanism that allows libc to be extended with new
“name” lookup methods for system databases, which includes host names,
service names, user accounts, and more (see System
Databases and Name Service Switch in The GNU C Library Reference
Manual).
The NSS configuration specifies, for each system database, which lookup
method is to be used, and how the various methods are chained together—for
instance, under which circumstances NSS should try the next method in the
list. The NSS configuration is given in the name-service-switch
field of operating-system declarations (see name-service-switch).
As an example, the declaration below configures the NSS to use the
nss-mdns
back-end, which supports host name lookups over multicast DNS (mDNS) for
host names ending in .local:
(name-service-switch
(hosts (list %files ;first, check /etc/hosts
;; If the above did not succeed, try
;; with 'mdns_minimal'.
(name-service
(name "mdns_minimal")
;; 'mdns_minimal' is authoritative for
;; '.local'. When it returns "not found",
;; no need to try the next methods.
(reaction (lookup-specification
(not-found => return))))
;; Then fall back to DNS.
(name-service
(name "dns"))
;; Finally, try with the "full" 'mdns'.
(name-service
(name "mdns")))))
Do not worry: the %mdns-host-lookup-nss variable (see below)
contains this configuration, so you will not have to type it if all you want
is to have .local host lookup working.
Note that, in this case, in addition to setting the
name-service-switch of the operating-system declaration, you
also need to use avahi-service-type (see avahi-service-type), or %desktop-services, which includes it
(see Сервисы рабочего стола). Doing this makes nss-mdns accessible to
the name service cache daemon (see nscd-service).
For convenience, the following variables provide typical NSS configurations.
- Scheme Variable: %default-nss
This is the default name service switch configuration, a
name-service-switchobject.
- Scheme Variable: %mdns-host-lookup-nss
This is the name service switch configuration with support for host name lookup over multicast DNS (mDNS) for host names ending in
.local.
The reference for name service switch configuration is given below. It is a
direct mapping of the configuration file format of the C library , so please
refer to the C library manual for more information (see NSS Configuration
File in The GNU C Library Reference Manual). Compared to the
configuration file format of libc NSS, it has the advantage not only of
adding this warm parenthetic feel that we like, but also static checks: you
will know about syntax errors and typos as soon as you run guix
system.
- Data Type: name-service-switch
-
This is the data type representation the configuration of libc’s name service switch (NSS). Each field below represents one of the supported system databases.
aliasesethersgroupgshadowhostsinitgroupsnetgroupnetworkspasswordpublic-keyrpcservicesshadowThe system databases handled by the NSS. Each of these fields must be a list of
<name-service>objects (see below).
- Data Type: name-service
-
This is the data type representing an actual name service and the associated lookup action.
nameA string denoting the name service (see Services in the NSS configuration in The GNU C Library Reference Manual).
Note that name services listed here must be visible to nscd. This is achieved by passing the
#:name-servicesargument tonscd-servicethe list of packages providing the needed name services (seenscd-service).reactionAn action specified using the
lookup-specificationmacro (see Actions in the NSS configuration in The GNU C Library Reference Manual). For example:
Next: Настройка загрузчика, Previous: Служба выбора имён, Up: Конфигурирование системы [Contents][Index]
12.13 Начальный RAM-диск
For bootstrapping purposes, the Linux-Libre kernel is passed an initial RAM disk, or initrd. An initrd contains a temporary root file system as well as an initialization script. The latter is responsible for mounting the real root file system, and for loading any kernel modules that may be needed to achieve that.
The initrd-modules field of an operating-system declaration
allows you to specify Linux-libre kernel modules that must be available in
the initrd. In particular, this is where you would list modules needed to
actually drive the hard disk where your root partition is—although the
default value of initrd-modules should cover most use cases. For
example, assuming you need the megaraid_sas module in addition to the
default modules to be able to access your root file system, you would write:
(operating-system
;; …
(initrd-modules (cons "megaraid_sas" %base-initrd-modules)))
- Scheme Variable: %base-initrd-modules
This is the list of kernel modules included in the initrd by default.
Furthermore, if you need lower-level customization, the initrd field
of an operating-system declaration allows you to specify which initrd
you would like to use. The (gnu system linux-initrd) module provides
three ways to build an initrd: the high-level base-initrd procedure
and the low-level raw-initrd and expression->initrd
procedures.
The base-initrd procedure is intended to cover most common uses. For
example, if you want to add a bunch of kernel modules to be loaded at boot
time, you can define the initrd field of the operating system
declaration like this:
(initrd (lambda (file-systems . rest)
;; Create a standard initrd but set up networking
;; with the parameters QEMU expects by default.
(apply base-initrd file-systems
#:qemu-networking? #t
rest)))
The base-initrd procedure also handles common use cases that involves
using the system as a QEMU guest, or as a “live” system with volatile root
file system.
The base-initrd procedure is built from raw-initrd procedure.
Unlike base-initrd, raw-initrd doesn’t do anything high-level,
such as trying to guess which kernel modules and packages should be included
to the initrd. An example use of raw-initrd is when a user has a
custom Linux kernel configuration and default kernel modules included by
base-initrd are not available.
The initial RAM disk produced by base-initrd or raw-initrd
honors several options passed on the Linux kernel command line (that is,
arguments passed via the linux command of GRUB, or the
-append option of QEMU), notably:
gnu.load=bootTell the initial RAM disk to load boot, a file containing a Scheme program, once it has mounted the root file system.
Guix uses this option to yield control to a boot program that runs the service activation programs and then spawns the GNU Shepherd, the initialization system.
root=rootMount root as the root file system. root can be a device name like
/dev/sda1, a file system label, or a file system UUID. When unspecified, the device name from the root file system of the operating system declaration is used.rootfstype=typeSet the type of the root file system. It overrides the
typefield of the root file system specified via theoperating-systemdeclaration, if any.rootflags=optionsSet the mount options of the root file system. It overrides the
optionsfield of the root file system specified via theoperating-systemdeclaration, if any.fsck.mode=modeWhether to check the root file system for errors before mounting it. mode is one of
skip(never check),force(always check), orautoto respect the root<file-system>object’scheck?setting (see Файловые системы) and run a full scan only if the file system was not cleanly shut down.autois the default if this option is not present or if mode is not one of the above.fsck.repair=levelThe level of repairs to perform automatically if errors are found in the root file system. level is one of
no(do not write to root at all if possible),yes(repair as much as possible), orpreento repair problems considered safe to repair automatically.preenis the default if this option is not present or if level is not one of the above.gnu.system=systemHave /run/booted-system and /run/current-system point to system.
modprobe.blacklist=modules…¶-
Instruct the initial RAM disk as well as the
modprobecommand (from the kmod package) to refuse to load modules. modules must be a comma-separated list of module names—e.g.,usbkbd,9pnet. gnu.replStart a read-eval-print loop (REPL) from the initial RAM disk before it tries to load kernel modules and to mount the root file system. Our marketing team calls it boot-to-Guile. The Schemer in you will love it. See Using Guile Interactively in GNU Guile Reference Manual, for more information on Guile’s REPL.
Now that you know all the features that initial RAM disks produced by
base-initrd and raw-initrd provide, here is how to use it and
customize it further.
- Scheme Procedure: raw-initrd file-systems [#:linux-modules '()] [#:pre-mount #t] [#:mapped-devices '()] [#:keyboard-layout #f] [#:helper-packages '()] [#:qemu-networking? #f]
[#:volatile-root? #f] Return a derivation that builds a raw initrd. file-systems is a list of file systems to be mounted by the initrd, possibly in addition to the root file system specified on the kernel command line via root. linux-modules is a list of kernel modules to be loaded at boot time. mapped-devices is a list of device mappings to realize before file-systems are mounted (see Размеченные устройства). pre-mount is a G-expression to evaluate before realizing mapped-devices. helper-packages is a list of packages to be copied in the initrd. It may include
e2fsck/staticor other packages needed by the initrd to check the root file system.When true, keyboard-layout is a
<keyboard-layout>record denoting the desired console keyboard layout. This is done before mapped-devices are set up and before file-systems are mounted such that, should the user need to enter a passphrase or use the REPL, this happens using the intended keyboard layout.When qemu-networking? is true, set up networking with the standard QEMU parameters. When virtio? is true, load additional modules so that the initrd can be used as a QEMU guest with para-virtualized I/O drivers.
When volatile-root? is true, the root file system is writable but any changes to it are lost.
- Scheme Procedure: base-initrd file-systems [#:mapped-devices '()] [#:keyboard-layout #f] [#:qemu-networking? #f]
[#:volatile-root? #f] [#:linux-modules ’()] Return as a file-like object a generic initrd, with kernel modules taken from linux. file-systems is a list of file-systems to be mounted by the initrd, possibly in addition to the root file system specified on the kernel command line via root. mapped-devices is a list of device mappings to realize before file-systems are mounted.
When true, keyboard-layout is a
<keyboard-layout>record denoting the desired console keyboard layout. This is done before mapped-devices are set up and before file-systems are mounted such that, should the user need to enter a passphrase or use the REPL, this happens using the intended keyboard layout.qemu-networking? and volatile-root? behaves as in
raw-initrd.The initrd is automatically populated with all the kernel modules necessary for file-systems and for the given options. Additional kernel modules can be listed in linux-modules. They will be added to the initrd, and loaded at boot time in the order in which they appear.
Needless to say, the initrds we produce and use embed a statically-linked
Guile, and the initialization program is a Guile program. That gives a lot
of flexibility. The expression->initrd procedure builds such an
initrd, given the program to run in that initrd.
- Scheme Procedure: expression->initrd exp [#:guile %guile-static-stripped] [#:name "guile-initrd"] Return as a
file-like object a Linux initrd (a gzipped cpio archive) containing guile and that evaluates exp, a G-expression, upon booting. All the derivations referenced by exp are automatically copied to the initrd.
Next: Invoking guix system, Previous: Начальный RAM-диск, Up: Конфигурирование системы [Contents][Index]
12.14 Настройка загрузчика
The operating system supports multiple bootloaders. The bootloader is
configured using bootloader-configuration declaration. All the
fields of this structure are bootloader agnostic except for one field,
bootloader that indicates the bootloader to be configured and
installed.
Some of the bootloaders do not honor every field of
bootloader-configuration. For instance, the extlinux bootloader does
not support themes and thus ignores the theme field.
- Data Type: bootloader-configuration
The type of a bootloader configuration declaration.
bootloader¶-
The bootloader to use, as a
bootloaderobject. For nowgrub-bootloader,grub-efi-bootloader,grub-efi-netboot-bootloader,grub-efi-removable-bootloader,extlinux-bootloaderandu-boot-bootloaderare supported.Available bootloaders are described in
(gnu bootloader …)modules. In particular,(gnu bootloader u-boot)contains definitions of bootloaders for a wide range of ARM and AArch64 systems, using the U-Boot bootloader.grub-efi-bootloaderallows to boot on modern systems using the Unified Extensible Firmware Interface (UEFI). This is what you should use if the installation image contains a /sys/firmware/efi directory when you boot it on your system.grub-bootloaderallows you to boot in particular Intel-based machines in “legacy” BIOS mode.grub-efi-netboot-bootloaderallows you to boot your system over network through TFTP. In combination with an NFS root file system this allows you to build a diskless Guix system.The installation of the
grub-efi-netboot-bootloadergenerates the content of the TFTP root directory attargets(seetargets), to be served by a TFTP server. You may want to mount your TFTP server directories onto thetargetsto move the required files to the TFTP server automatically.If you plan to use an NFS root file system as well (actually if you mount the store from an NFS share), then the TFTP server needs to serve the file /boot/grub/grub.cfg and other files from the store (like GRUBs background image, the kernel (see
kernel) and the initrd (seeinitrd)), too. All these files from the store will be accessed by GRUB through TFTP with their normal store path, for example as tftp://tftp-server/gnu/store/…-initrd/initrd.cpio.gz.Two symlinks are created to make this possible. For each target in the
targetsfield, the first symlink is ‘target’/efi/Guix/boot/grub/grub.cfg pointing to ../../../boot/grub/grub.cfg, where ‘target’ may be /boot. In this case the link is not leaving the served TFTP root directory, but otherwise it does. The second link is ‘target’/gnu/store and points to ../gnu/store. This link is leaving the served TFTP root directory.The assumption behind all this is that you have an NFS server exporting the root file system for your Guix system, and additionally a TFTP server exporting your
targetsdirectories—usually a single /boot—from that same root file system for your Guix system. In this constellation the symlinks will work.For other constellations you will have to program your own bootloader installer, which then takes care to make necessary files from the store accessible through TFTP, for example by copying them into the TFTP root directory to your
targets.It is important to note that symlinks pointing outside the TFTP root directory may need to be allowed in the configuration of your TFTP server. Further the store link exposes the whole store through TFTP. Both points need to be considered carefully for security aspects.
Beside the
grub-efi-netboot-bootloader, the already mentioned TFTP and NFS servers, you also need a properly configured DHCP server to make the booting over netboot possible. For all this we can currently only recommend you to look for instructions about PXE (Preboot eXecution Environment).grub-efi-removable-bootloaderallows you to boot your system from removable media by writing the GRUB file to the UEFI-specification location of /EFI/BOOT/BOOTX64.efi of the boot directory, usually /boot/efi. This is also useful for some UEFI firmwares that “forget” their configuration from their non-volatile storage. Likegrub-efi-bootloader, this can only be used if the /sys/firmware/efi directory is available.Примечание: This will overwrite the GRUB file from any other operating systems that also place their GRUB file in the UEFI-specification location; making them unbootable.
targetsThis is a list of strings denoting the targets onto which to install the bootloader.
The interpretation of targets depends on the bootloader in question. For
grub-bootloader, for example, they should be device names understood by the bootloaderinstallercommand, such as/dev/sdaor(hd0)(see Invoking grub-install in GNU GRUB Manual). Forgrub-efi-bootloaderandgrub-efi-removable-bootloaderthey should be mount points of the EFI file system, usually /boot/efi. Forgrub-efi-netboot-bootloader,targetsshould be the mount points corresponding to TFTP root directories served by your TFTP server.menu-entries(default:())A possibly empty list of
menu-entryobjects (see below), denoting entries to appear in the bootloader menu, in addition to the current system entry and the entry pointing to previous system generations.default-entry(default:0)The index of the default boot menu entry. Index 0 is for the entry of the current system.
timeout(default:5)The number of seconds to wait for keyboard input before booting. Set to 0 to boot immediately, and to -1 to wait indefinitely.
keyboard-layout(default:#f)If this is
#f, the bootloader’s menu (if any) uses the default keyboard layout, usually US English (“qwerty”).Otherwise, this must be a
keyboard-layoutobject (see Раскладка клавиатуры).Примечание: This option is currently ignored by bootloaders other than
grubandgrub-efi.theme(default: #f)The bootloader theme object describing the theme to use. If no theme is provided, some bootloaders might use a default theme, that’s true for GRUB.
features(default:'())The output terminals used for the bootloader boot menu, as a list of symbols. GRUB accepts the values:
console,serial,serial_{0-3},gfxterm,vga_text,mda_text,morse, andpkmodem. This field corresponds to the GRUB variableGRUB_TERMINAL_OUTPUT(see Simple configuration in GNU GRUB manual).terminal-inputs(default:'())The input terminals used for the bootloader boot menu, as a list of symbols. For GRUB, the default is the native platform terminal as determined at run-time. GRUB accepts the values:
console,serial,serial_{0-3},at_keyboard, andusb_keyboard. This field corresponds to the GRUB variableGRUB_TERMINAL_INPUT(see Simple configuration in GNU GRUB manual).serial-unit(default:#f)The serial unit used by the bootloader, as an integer from 0 to 3. For GRUB, it is chosen at run-time; currently GRUB chooses 0, which corresponds to COM1 (see Serial terminal in GNU GRUB manual).
serial-speed(default:#f)The speed of the serial interface, as an integer. For GRUB, the default value is chosen at run-time; currently GRUB chooses 9600 bps (see Serial terminal in GNU GRUB manual).
device-tree-support?(default:#t)Whether to support Linux device tree files loading.
This option in enabled by default. In some cases involving the
u-bootbootloader, where the device tree has already been loaded in RAM, it can be handy to disable the option by setting it to#f.
Should you want to list additional boot menu entries via the
menu-entries field above, you will need to create them with the
menu-entry form. For example, imagine you want to be able to boot
another distro (hard to imagine!), you can define a menu entry along these
lines:
(menu-entry
(label "The Other Distro")
(linux "/boot/old/vmlinux-2.6.32")
(linux-arguments '("root=/dev/sda2"))
(initrd "/boot/old/initrd"))
Details below.
The type of an entry in the bootloader menu.
labelThe label to show in the menu—e.g.,
"GNU".port(default:22)The Linux kernel image to boot, for example:
(file-append linux-libre "/bzImage")For GRUB, it is also possible to specify a device explicitly in the file path using GRUB’s device naming convention (see Naming convention in GNU GRUB manual), for example:
"(hd0,msdos1)/boot/vmlinuz"
If the device is specified explicitly as above, then the
devicefield is ignored entirely.linux-arguments(default:())The list of extra Linux kernel command-line arguments—e.g.,
("console=ttyS0").speed(default:1.0)A G-Expression or string denoting the file name of the initial RAM disk to use (see G-Expressions).
device(default:#f)The device where the kernel and initrd are to be found—i.e., for GRUB, root for this menu entry (see root in GNU GRUB manual).
This may be a file system label (a string), a file system UUID (a bytevector, see Файловые системы), or
#f, in which case the bootloader will search the device containing the file specified by thelinuxfield (see search in GNU GRUB manual). It must not be an OS device name such as /dev/sda1.port(default:22)The kernel to boot in Multiboot-mode (see multiboot in GNU GRUB manual). When this field is set, a Multiboot menu-entry is generated. For example:
(file-append mach "/boot/gnumach")arguments(default:'())The list of extra command-line arguments for the multiboot-kernel.
features(default:'())The list of commands for loading Multiboot modules. For example:
(list (list (file-append hurd "/hurd/ext2fs.static") "ext2fs" …) (list (file-append libc "/lib/ld.so.1") "exec" …))chain-loader(default:#f)A string that can be accepted by
grub’schainloaderdirective. This has no effect if eitherlinuxormultiboot-kernelfields are specified. The following is an example of chainloading a different GNU/Linux system.(bootloader (bootloader-configuration ;; … (menu-entries (list (menu-entry (label "GNU/Linux") (device (uuid "1C31-A17C" 'fat)) (chain-loader "/EFI/GNULinux/grubx64.efi"))))))
For now only GRUB has theme support. GRUB themes are created using the
grub-theme form, which is not fully documented yet.
- Тип данных: build-machine
Data type representing the configuration of the GRUB theme.
port(default:22)The GRUB
gfxmodeto set (a list of screen resolution strings, see gfxmode in GNU GRUB manual).
- Процедура Scheme: sane-service-type
Return the default GRUB theme used by the operating system if no
themefield is specified inbootloader-configurationrecord.It comes with a fancy background image displaying the GNU and Guix logos.
For example, to override the default resolution, you may use something like
(bootloader
(bootloader-configuration
;; …
(theme (grub-theme
(inherit (grub-theme))
(gfxmode '("1024x786x32" "auto"))))))
Next: Invoking guix deploy, Previous: Настройка загрузчика, Up: Конфигурирование системы [Contents][Index]
12.15 Invoking guix system
Однажды объявленное описание операционной системы, описанное в предыдущих
разделах, может быть применено с помощью команды guix
system. Синопсис:
guix system options… action file
file должно быть именем файла, содержащего определение
operating-system. action указывает, как воспроизводится
операционная система. В настоящее время поддерживаются следующие значения:
searchПоказывает доступные определения типов служб, в соответствии с указанным регулярным выражениям, отсортированные по релевантности:
$ guix system search console name: console-fonts location: gnu/services/base.scm:806:2 extends: shepherd-root description: Install the given fonts on the specified ttys (fonts are per + virtual console on GNU/Linux). The value of this service is a list of + tty/font pairs. The font can be the name of a font provided by the `kbd' + package or any valid argument to `setfont', as in this example: + + '(("tty1" . "LatGrkCyr-8x16") + ("tty2" . (file-append + font-tamzen + "/share/kbd/consolefonts/TamzenForPowerline10x20.psf")) + ("tty3" . (file-append + font-terminus + "/share/consolefonts/ter-132n"))) ; for HDPI relevance: 9 name: mingetty location: gnu/services/base.scm:1190:2 extends: shepherd-root description: Provide console login using the `mingetty' program. relevance: 2 name: login location: gnu/services/base.scm:860:2 extends: pam description: Provide a console log-in service as specified by its + configuration value, a `login-configuration' object. relevance: 2 …Так же как для
guix package --search, результат будет выведен вrecutilsформате, что делает его простым для фильтрации и вывода (see (GNU recutils manual)recutils).editEdit or view the definition of the given service types.
For example, the command below opens your editor, as specified by the
EDITORenvironment variable, on the definition of theopensshservice type:guix system edit openssh
reconfigureСобирает операционную систему описанную в file, активирует её и переключается на неё33.
Примечание: Настоятельно рекомендуется запустить команду
guix pullперед первым запускомguix system reconfigure(see Вызовguix pull). В противном случае вы можете получить старую версию Guix после завершенияreconfigureЭто действие повлияет на всю конфигурацию, указанную в file: учетные записи пользователей, системные службы, глобальный список пакетов, программы setuid и т.д. Команда запустит системные службы, указанные в file, которые в данный момент не запущены; если служба в данный момент запущена, изменения вступят в силу при следующем перезапуске (например по
herd stop Xилиherd restart X).Эта команда создает новое поколение, число которого на единицу больше, чем у текущего поколения (как описано
guix system list-generations). Если это поколение уже существует, оно будет перезаписано. Это поведение описано вguix package(see Вызовguix package).Она также добавляет пункты меню загрузчика для новой конфигурации ОС, если не передана опция --no-bootloader. Для GRUB она перемещает записи для более старых конфигураций вподменю, позволяя вам выбрать более старое поколение системы во время загрузки, если вам это понадобится.
По завершении новая система развертывается в /run/current-system. Этот каталог содержит метаданные о происхождении: список используемых каналов (see Каналы) и сам file, если он доступен. Вы можете просмотреть его, запустив:
guix system describe
Эта информация пригодится, если позже вы захотите проверить, как было собрано это конкретное поколение. Фактически, предполагая, что file содержит всё необходимое, вы можете позже пересобрать поколение n в вашей операционной системы с помощью:
guix time-machine \ -C /var/guix/profiles/system-n-link/channels.scm -- \ system reconfigure \ /var/guix/profiles/system-n-link/configuration.scm
Вы можете думать об этом как о чем-то вроде встроенного контроля версий! Ваша система теперь не просто набор двоичных файлов: она содержит свой собственный источник. See
provenance-service-type, для получения дополнительной информации об отслеживании происхождения.По умолчанию
reconfigureпрепятствует откату вашей системы, что может (пере)внести уязвимости безопасности, а также вызвать проблемы со службами "отслеживающими состояние", такими как системы управления базами данных. Вы можете переопределить это поведение, передав --allow-downgrades.switch-generation¶Переключает на существующее поколение системы. Эта команда атомарной операцией переключает системный профиль на указанное поколение системы. Она также изменяет порядок существующих элементов меню загрузчика системы. Она устанавливает в загрузчике запуск по умолчанию указанного поколения и перемещает другие поколения в подменю, если это поддерживается используемым загрузчиком. При следующей загрузке системы она будет использовать указанное поколение системы.
Сам загрузчик не переустанавливается при использовании этой команды. Таким образом, установленный загрузчик используется с обновленным файлом конфигурации.
Нужное поколение может быть явно указано по его номеру. Например, следующий вызов переключится на поколение 7:
guix system switch-generation 7
Нужное поколение также может быть указано относительно текущего поколения
+Nили-N, где+3означает "на 3 поколения старше текущего", а-1означает "на 1 поколение младше текущего". При задании отрицательного значения-1, перед ним нужно поставить--чтобы не воспринимать его в качестве опции. Например:guix system switch-generation -- -1
В настоящее время результатом вызова этого действия является только переключение профиля на существующее поколение и изменение элементов меню загрузчика. Чтобы начать использовать указанное поколение, вы должны перезагрузиться. В будущем поведение будет аналогично
reconfigure, например, запуск и остановка служб.Это действие завершится ошибкой, если указанное поколение не существует.
roll-back¶Переключает на предыдущее поколение системы. При следующей загрузке система будет использовать предыдущее. Команда отменяет
reconfigure, и делает то же самое, чтоswitch-generationс аргументом-1.В настоящее время, как и в случае с
switch-generation, вы должны перезагрузиться после выполнения этого действия, чтобы фактически начать использовать предыдущее поколение системы.delete-generations¶-
Удаляет поколение, делая их кандидатами на для сборщика мусора (see Вызов
guix gc, для получения информации о том, как запустить "сборщик мусора").Работает так же, как и ‘guix package --delete-generations’ (see --delete-generations). Без аргументов удаляются все системные поколения, кроме текущего:
guix system delete-generations
You can also select the generations you want to delete. The example below deletes all the system generations that are more than two months old:
guix system delete-generations 2m
Выполнение этой команды автоматически переустановит загрузчик с обновлением меню—например, подменю "old generations" в GRUB не будет содержать удаленные поколения.
buildСобирает деривацию операционной системы, которая включает в себя все файлы конфигурации и программы, необходимые для загрузки и запуска системы. Это действие на самом деле ничего не устанавливает.
initНаполняет указанную директорию всем необходимым для запуска операционной системы, указанным в файле. Это полезно при первой установке системы Guix. В качестве примера:
guix system init my-os-config.scm /mnt
копирует в /mnt все элементы хранилища, необходимые для конфигурации, указанной в my-os-config.scm. Включая файлы конфигурации, пакеты и так далее. Он также создает другие важные файлы, необходимые для правильной работы системы, такие как каталоги /etc, /var и /run и файл /bin/sh.
This command also installs bootloader on the targets specified in my-os-config, unless the --no-bootloader option was passed.
vm¶-
Build a virtual machine (VM) that contains the operating system declared in file, and return a script to run that VM.
Примечание: Параметры
vmи другие, приведенные ниже, могут использовать поддержку KVM ядра Linux-libre. В частности, если машина поддерживает аппаратную виртуализацию,следует загрузить соответствующий модуль ядра KVM а файл устройства /dev/kvm должен существовать и быть доступен для чтения и записи пользователю и процессамсборки демона (see Установка окружения сборки).Аргументы, переданные скрипту, передаются в QEMU, как в приведенном ниже примере,который включает сеть и запрашивает 1 GiB оперативной памяти для эмулируемоймашины:
$ /gnu/store/…-run-vm.sh -m 1024 -smp 2 -nic user,model=virtio-net-pci
It’s possible to combine the two steps into one:
$ $(guix system vm my-config.scm) -m 1024 -smp 2 -nic user,model=virtio-net-pci
Виртуальная машина использует свое хранилище совместно с хост-системой.
By default, the root file system of the VM is mounted volatile; the --persistent option can be provided to make it persistent instead. In that case, the VM disk-image file will be copied from the store to the
TMPDIRdirectory to make it writable.Дополнительные файловые системы могут быть разделены между хостом и виртуальной машиной с помощью параметров --share и --expose: первый указывает директорию, к которой должен быть предоставлен общий доступ с правом на запись, последний обеспечивает доступ только на чтение.
Пример ниже создает виртуальную машину, которой доступна домашняя директория пользователя с правами на чтение, а директория $HOME/tmp хоста размещена в /exchange с правами на чтение и запись:
guix system vm my-config.scm \ --expose=$HOME --share=$HOME/tmp=/exchange
В GNU / Linux по умолчанию загрузка выполняется непосредственно в ядро; это имеет преимущество в том, что требуется только очень крошечный образ корневого диска, так как затем можно смонтировать хранилище хоста.
The --full-boot option forces a complete boot sequence, starting with the bootloader. This requires more disk space since a root image containing at least the kernel, initrd, and bootloader data files must be created.
The --image-size option can be used to specify the size of the image.
The --no-graphic option will instruct
guix systemto spawn a headless VM that will use the invoking tty for IO. Among other things, this enables copy-pasting, and scrollback. Use the ctrl-a prefix to issue QEMU commands; e.g. ctrl-a h prints a help, ctrl-a x quits the VM, and ctrl-a c switches between the QEMU monitor and the VM. image¶The
imagecommand can produce various image types. The image type can be selected using the --image-type option. It defaults toefi-raw. When its value isiso9660, the --label option can be used to specify a volume ID withimage. By default, the root file system of a disk image is mounted non-volatile; the --volatile option can be provided to make it volatile instead. When usingimage, the bootloader installed on the generated image is taken from the providedoperating-systemdefinition. The following example demonstrates how to generate an image that uses thegrub-efi-bootloaderbootloader and boot it with QEMU:image=$(guix system image --image-type=qcow2 \ gnu/system/examples/lightweight-desktop.tmpl) cp $image /tmp/my-image.qcow2 chmod +w /tmp/my-image.qcow2 qemu-system-x86_64 -enable-kvm -hda /tmp/my-image.qcow2 -m 1000 \ -bios $(guix build ovmf)/share/firmware/ovmf_x64.binWhen using the
efi-rawimage type, a raw disk image is produced; it can be copied as is to a USB stick, for instance. Assuming/dev/sdcis the device corresponding to a USB stick, one can copy the image to it using the following command:# dd if=$(guix system image my-os.scm) of=/dev/sdc status=progress
The
--list-image-typescommand lists all the available image types.When using the
qcow2image type, the returned image is in qcow2 format, which the QEMU emulator can efficiently use. See Running Guix in a Virtual Machine, for more information on how to run the image in a virtual machine. Thegrub-bootloaderbootloader is always used independently of what is declared in theoperating-systemfile passed as argument. This is to make it easier to work with QEMU, which uses the SeaBIOS BIOS by default, expecting a bootloader to be installed in the Master Boot Record (MBR).When using the
dockerimage type, a Docker image is produced. Guix builds the image from scratch, not from a pre-existing Docker base image. As a result, it contains exactly what you define in the operating system configuration file. You can then load the image and launch a Docker container using commands like the following:image_id="$(docker load < guix-system-docker-image.tar.gz)" container_id="$(docker create $image_id)" docker start $container_id
This command starts a new Docker container from the specified image. It will boot the Guix system in the usual manner, which means it will start any services you have defined in the operating system configuration. You can get an interactive shell running in the container using
docker exec:docker exec -ti $container_id /run/current-system/profile/bin/bash --login
Depending on what you run in the Docker container, it may be necessary to give the container additional permissions. For example, if you intend to build software using Guix inside of the Docker container, you may need to pass the --privileged option to
docker create.Last, the --network option applies to
guix system docker-image: it produces an image where network is supposedly shared with the host, and thus without services like nscd or NetworkManager.контейнерReturn a script to run the operating system declared in file within a container. Containers are a set of lightweight isolation mechanisms provided by the kernel Linux-libre. Containers are substantially less resource-demanding than full virtual machines since the kernel, shared objects, and other resources can be shared with the host system; this also means they provide thinner isolation.
Currently, the script must be run as root in order to support more than a single user and group. The container shares its store with the host system.
As with the
vmaction (see guix system vm), additional file systems to be shared between the host and container can be specified using the --share and --expose options:guix system container my-config.scm \ --expose=$HOME --share=$HOME/tmp=/exchange
The --share and --expose options can also be passed to the generated script to bind-mount additional directories into the container.
Примечание: This option requires Linux-libre 3.19 or newer.
options can contain any of the common build options (see Стандартные параметры сборки). In addition, options can contain one of the following:
- --expression=expr
- -e expr
Consider the operating-system expr evaluates to. This is an alternative to specifying a file which evaluates to an operating system. This is used to generate the Guix system installer see Сборка установочного образа).
- --system=system
- -s system
Attempt to build for system instead of the host system type. This works as per
guix build(see Запускguix build).- --target=triplet
Cross-сборка для triplet, который должен быть допустимым GNU triplet, например
\ "aarch64-linux-gnu\"(see GNU configuration triplets in Autoconf).- --derivation
- -d
Return the derivation file name of the given operating system without building anything.
- --save-provenance
As discussed above,
guix system initandguix system reconfigurealways save provenance information via a dedicated service (seeprovenance-service-type). However, other commands don’t do that by default. If you wish to, say, create a virtual machine image that contains provenance information, you can run:guix system image -t qcow2 --save-provenance config.scm
That way, the resulting image will effectively “embed its own source” in the form of meta-data in /run/current-system. With that information, one can rebuild the image to make sure it really contains what it pretends to contain; or they could use that to derive a variant of the image.
- --target=triplet
- -t type
For the
imageaction, create an image with given type.When this option is omitted,
guix systemuses theefi-rawimage type.--image-type=iso9660 produces an ISO-9660 image, suitable for burning on CDs and DVDs.
- --image-size=size
Если задана min, остановиться, когда min байт собрано. min может быть числом байт или может содержать единицу измерения в суффиксе, как например,
MiBдля мебибайт иGBгигабайт (see size specifications in GNU Coreutils).When this option is omitted,
guix systemcomputes an estimate of the image size as a function of the size of the system declared in file.- --network
- -N
For the
containeraction, allow containers to access the host network, that is, do not create a network namespace.- --root=file
- -r file
Make file a symlink to the result, and register it as a garbage collector root.
- --skip-checks
Skip pre-installation safety checks.
By default,
guix system initandguix system reconfigureperform safety checks: they make sure the file systems that appear in theoperating-systemdeclaration actually exist (see Файловые системы), and that any Linux kernel modules that may be needed at boot time are listed ininitrd-modules(see Начальный RAM-диск). Passing this option skips these tests altogether.- --allow-downgrades
Instruct
guix system reconfigureto allow system downgrades.By default,
reconfigureprevents you from downgrading your system. It achieves that by comparing the provenance info of your system (shown byguix system describe) with that of yourguixcommand (shown byguix describe). If the commits forguixare not descendants of those used for your system,guix system reconfigureerrors out. Passing --allow-downgrades allows you to bypass these checks.Примечание: Прежде чем использовать --allow-downgrades, убедитесь, что вы понимаете его последствия для безопасности.
- --on-error=strategy
Apply strategy when an error occurs when reading file. strategy may be one of the following:
nothing-specialReport the error concisely and exit. This is the default strategy.
backtraceLikewise, but also display a backtrace.
debugReport the error and enter Guile’s debugger. From there, you can run commands such as
,btto get a backtrace,,localsto display local variable values, and more generally inspect the state of the program. See Debug Commands in GNU Guile Reference Manual, for a list of available debugging commands.
Once you have built, configured, re-configured, and re-re-configured your Guix installation, you may find it useful to list the operating system generations available on disk—and that you can choose from the bootloader boot menu:
describeDescribe the running system generation: its file name, the kernel and bootloader used, etc., as well as provenance information when available.
The
--list-installedflag is available, with the same syntax that is used inguix package --list-installed(see Вызовguix package). When the flag is used, the description will include a list of packages that are currently installed in the system profile, with optional filtering based on a regular expression.Примечание: The running system generation—referred to by /run/current-system—is not necessarily the current system generation—referred to by /var/guix/profiles/system: it differs when, for instance, you chose from the bootloader menu to boot an older generation.
It can also differ from the booted system generation—referred to by /run/booted-system—for instance because you reconfigured the system in the meantime.
list-generationsList a summary of each generation of the operating system available on disk, in a human-readable way. This is similar to the --list-generations option of
guix package(see Вызовguix package).Optionally, one can specify a pattern, with the same syntax that is used in
guix package --list-generations, to restrict the list of generations displayed. For instance, the following command displays generations that are up to 10 days old:$ guix system list-generations 10d
The
--list-installedflag may also be specified, with the same syntax that is used inguix package --list-installed. This may be helpful if trying to determine when a package was added to the system.
The guix system command has even more to offer! The following
sub-commands allow you to visualize how your system services relate to each
other:
extension-graphEmit to standard output the service extension graph of the operating system defined in file (see Структура сервисов, for more information on service extensions). By default the output is in Dot/Graphviz format, but you can choose a different format with --graph-backend, as with
guix graph(see --backend):The command:
$ guix system extension-graph file | xdot -
shows the extension relations among services.
Примечание: The
dotprogram is provided by thegraphvizpackage.shepherd-graphEmit to standard output the dependency graph of shepherd services of the operating system defined in file. See Сервисы Shepherd, for more information and for an example graph.
Again, the default output format is Dot/Graphviz, but you can pass --graph-backend to select a different one.
Next: Running Guix in a Virtual Machine, Previous: Invoking guix system, Up: Конфигурирование системы [Contents][Index]
12.16 Invoking guix deploy
We’ve already seen operating-system declarations used to manage a
machine’s configuration locally. Suppose you need to configure multiple
machines, though—perhaps you’re managing a service on the web that’s
comprised of several servers. guix deploy enables you to use
those same operating-system declarations to manage multiple remote
hosts at once as a logical “deployment”.
Примечание: The functionality described in this section is still under development and is subject to change. Get in touch with us on guix-devel@gnu.org!
guix deploy file
Such an invocation will deploy the machines that the code within file evaluates to. As an example, file might contain a definition like this:
;; This is a Guix deployment of a "bare bones" setup, with ;; no X11 display server, to a machine with an SSH daemon ;; listening on localhost:2222. A configuration such as this ;; may be appropriate for virtual machine with ports ;; forwarded to the host's loopback interface. (use-service-modules networking ssh) (use-package-modules bootloaders) (define %system (operating-system (host-name "gnu-deployed") (timezone "Etc/UTC") (bootloader (bootloader-configuration (bootloader grub-bootloader) (targets '("/dev/vda")) (terminal-outputs '(console)))) (file-systems (cons (file-system (mount-point "/") (device "/dev/vda1") (type "ext4")) %base-file-systems)) (services (append (list (service dhcp-client-service-type) (service openssh-service-type (openssh-configuration (permit-root-login #t) (allow-empty-passwords? #t)))) %base-services)))) (list (machine (operating-system %system) (environment managed-host-environment-type) (configuration (machine-ssh-configuration (host-name "localhost") (system "x86_64-linux") (user "alice") (identity "./id_rsa") (port 2222)))))
The file should evaluate to a list of machine objects. This example,
upon being deployed, will create a new generation on the remote system
realizing the operating-system declaration %system.
environment and configuration specify how the machine should
be provisioned—that is, how the computing resources should be created and
managed. The above example does not create any resources, as a
'managed-host is a machine that is already running the Guix system
and available over the network. This is a particularly simple case; a more
complex deployment may involve, for example, starting virtual machines
through a Virtual Private Server (VPS) provider. In such a case, a
different environment type would be used.
Есть ещё одна вещь, которую нужно выполнить после размещения
machines.scm. Выше описано, что при разгрузке файлы передаются вперёд
и назад между складами на машинах. Для этого необходимо сгенерировать
ключ-пару на кадой машине, чтобы позволить демону экспортировать подписанные
архивы файлов из склада (see Вызов guix archive):
# guix archive --generate-key
Каждая машина для сорки должна авторизовать ключ машины-инициатора, чтобы принимать элементы из склада, которые присылает инициатор:
# guix archive --authorize < master-public-key.txt
user, in this example, specifies the name of the user account to log
in as to perform the deployment. Its default value is root, but root
login over SSH may be forbidden in some cases. To work around this,
guix deploy can log in as an unprivileged user and employ
sudo to escalate privileges. This will only work if sudo is
currently installed on the remote and can be invoked non-interactively as
user. That is, the line in sudoers granting user the
ability to use sudo must contain the NOPASSWD tag. This can
be accomplished with the following operating system configuration snippet:
(use-modules ... (gnu system)) ;for %sudoers-specification (define %user "username") (operating-system ... (sudoers-file (plain-file "sudoers" (string-append (plain-file-content %sudoers-specification) (format #f "~a ALL = NOPASSWD: ALL~%" %user)))))
For more information regarding the format of the sudoers file,
consult man sudoers.
Once you’ve deployed a system on a set of machines, you may find it useful
to run a command on all of them. The --execute or -x
option lets you do that; the example below runs uname -a on all
the machines listed in the deployment file:
guix deploy file -x -- uname -a
One thing you may often need to do after deployment is restart specific services on all the machines, which you can do like so:
guix deploy file -x -- herd restart service
The guix deploy -x command returns zero if and only if the command
succeeded on all the machines.
Below are the data types you need to know about when writing a deployment file.
- Тип данных: build-machine
This is the data type representing a single machine in a heterogeneous Guix deployment.
operating-systemУправление конфигурацией операционной системы.
guix environmentAn
environment-typedescribing how the machine should be provisioned.port(default:22)An object describing the configuration for the machine’s
environment. If theenvironmenthas a default configuration,#fmay be used. If#fis used for an environment with no default configuration, however, an error will be thrown.
- Тип данных: build-machine
This is the data type representing the SSH client parameters for a machine with an
environmentofmanaged-host-environment-type.host-namespeed(default:1.0)If false, system derivations will be built on the machine being deployed to.
systemТип системы удалённой машины, то есть
x86_64-linux.port(default:22)If true, the coordinator’s signing key will be added to the remote’s ACL keyring.
port(default:22)port(default:22)speed(default:1.0)If specified, the path to the SSH private key to use to authenticate with the remote host.
port(default:22)This should be the SSH host key of the machine, which looks like this:
ssh-ed25519 AAAAC3NzaC…mde+UhL hint@example.org
When
host-keyis#f, the server is authenticated against the ~/.ssh/known_hosts file, just like the OpenSSHsshclient does.port(default:22)Whether to allow potential downgrades.
Like
guix system reconfigure,guix deploycompares the channel commits currently deployed on the remote host (as returned byguix system describe) to those currently in use (as returned byguix describe) to determine whether commits currently in use are descendants of those deployed. When this is not the case andallow-downgrades?is false, it raises an error. This ensures you do not accidentally downgrade remote machines.safety-checks?(default:#t)Whether to perform “safety checks” before deployment. This includes verifying that devices and file systems referred to in the operating system configuration actually exist on the target machine, and making sure that Linux modules required to access storage devices at boot time are listed in the
initrd-modulesfield of the operating system.These safety checks ensure that you do not inadvertently deploy a system that would fail to boot. Be careful before turning them off!
- Data Type: digital-ocean-configuration
This is the data type describing the Droplet that should be created for a machine with an
environmentofdigital-ocean-environment-type.host-keyThe path to the SSH private key to use to authenticate with the remote host. In the future, this field may not exist.
tagsA list of string “tags” that uniquely identify the machine. Must be given such that no two machines in the deployment have the same set of tags.
regionA Digital Ocean region slug, such as
"nyc3".sizeA Digital Ocean size slug, such as
"s-1vcpu-1gb"enable-ipv6?Whether or not the droplet should be created with IPv6 networking.
Next: Создание служб, Previous: Invoking guix deploy, Up: Конфигурирование системы [Contents][Index]
12.17 Running Guix in a Virtual Machine
To run Guix in a virtual machine (VM), one can use the pre-built Guix VM image distributed at https://ftp.gnu.org/gnu/guix/guix-system-vm-image-1.4.0.x86_64-linux.qcow2. This image is a compressed image in QCOW format. You can pass it to an emulator such as QEMU (see below for details).
This image boots the Xfce graphical environment and it contains some
commonly used tools. You can install more software in the image by running
guix package in a terminal (see Вызов guix package). You
can also reconfigure the system based on its initial configuration file
available as /run/current-system/configuration.scm (see Использование системы конфигурации).
Instead of using this pre-built image, one can also build their own image
using guix system image (see Invoking guix system).
If you built your own image, you must copy it out of the store (see Хранилище) and give yourself permission to write to the copy before you can use
it. When invoking QEMU, you must choose a system emulator that is suitable
for your hardware platform. Here is a minimal QEMU invocation that will
boot the result of guix system image -t qcow2 on x86_64 hardware:
$ qemu-system-x86_64 \ -nic user,model=virtio-net-pci \ -enable-kvm -m 2048 \ -device virtio-blk,drive=myhd \ -drive if=none,file=guix-system-vm-image-1.4.0.x86_64-linux.qcow2,id=myhd
Here is what each of these options means:
qemu-system-x86_64This specifies the hardware platform to emulate. This should match the host.
-nic user,model=virtio-net-pciEnable the unprivileged user-mode network stack. The guest OS can access the host but not vice versa. This is the simplest way to get the guest OS online.
modelspecifies which network device to emulate:virtio-net-pciis a special device made for virtualized operating systems and recommended for most uses. Assuming your hardware platform is x86_64, you can get a list of available NIC models by runningqemu-system-x86_64 -nic model=help.-enable-kvmIf your system has hardware virtualization extensions, enabling the virtual machine support (KVM) of the Linux kernel will make things run faster.
-m 2048RAM available to the guest OS, in mebibytes. Defaults to 128 MiB, which may be insufficient for some operations.
-device virtio-blk,drive=myhdCreate a
virtio-blkdrive called “myhd”.virtio-blkis a “paravirtualization” mechanism for block devices that allows QEMU to achieve better performance than if it were emulating a complete disk drive. See the QEMU and KVM documentation for more info.-drive if=none,file=/tmp/qemu-image,id=myhdUse our QCOW image, the guix-system-vm-image-1.4.0.x86_64-linux.qcow2 file, as the backing store of the “myhd” drive.
The default run-vm.sh script that is returned by an invocation of
guix system vm does not add a -nic user flag by
default. To get network access from within the vm add the
(dhcp-client-service) to your system definition and start the VM
using $(guix system vm config.scm) -nic user. An important caveat
of using -nic user for networking is that ping will not
work, because it uses the ICMP protocol. You’ll have to use a different
command to check for network connectivity, for example guix
download.
12.17.1 Connecting Through SSH
To enable SSH inside a VM you need to add an SSH server like
openssh-service-type to your VM (see openssh-service-type). In addition you need to forward the SSH
port, 22 by default, to the host. You can do this with
$(guix system vm config.scm) -nic user,model=virtio-net-pci,hostfwd=tcp::10022-:22
To connect to the VM you can run
ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -p 10022 localhost
The -p tells ssh the port you want to connect to.
-o UserKnownHostsFile=/dev/null prevents ssh from
complaining every time you modify your config.scm file and the
-o StrictHostKeyChecking=no prevents you from having to allow a
connection to an unknown host every time you connect.
Примечание: If you find the above ‘hostfwd’ example not to be working (e.g., your SSH client hangs attempting to connect to the mapped port of your VM), make sure that your Guix System VM has networking support, such as by using the
dhcp-client-service-typeservice type.
12.17.2 Using virt-viewer with Spice
As an alternative to the default qemu graphical client you can use
the remote-viewer from the virt-viewer package. To
connect pass the -spice port=5930,disable-ticketing flag to
qemu. See previous section for further information on how to do
this.
Spice also allows you to do some nice stuff like share your clipboard with
your VM. To enable that you’ll also have to pass the following flags to
qemu:
-device virtio-serial-pci,id=virtio-serial0,max_ports=16,bus=pci.0,addr=0x5 -chardev spicevmc,name=vdagent,id=vdagent -device virtserialport,nr=1,bus=virtio-serial0.0,chardev=vdagent,\ name=com.redhat.spice.0
You’ll also need to add the (spice-vdagent-service) to your system
definition (see Spice service).
Previous: Running Guix in a Virtual Machine, Up: Конфигурирование системы [Contents][Index]
12.18 Создание служб
The previous sections show the available services and how one can combine
them in an operating-system declaration. But how do we define them
in the first place? And what is a service anyway?
- Структура сервисов
- Типы сервисов и сервисы
- Интерфейс сервиса
- Сервисы Shepherd
- Complex Configurations
Next: Типы сервисов и сервисы, Up: Создание служб [Contents][Index]
12.18.1 Структура сервисов
Here we define a service as, broadly, something that extends the
functionality of the operating system. Often a service is a process—a
daemon—started when the system boots: a secure shell server, a Web
server, the Guix build daemon, etc. Sometimes a service is a daemon whose
execution can be triggered by another daemon—e.g., an FTP server started
by inetd or a D-Bus service activated by dbus-daemon.
Occasionally, a service does not map to a daemon. For instance, the
“account” service collects user accounts and makes sure they exist when
the system runs; the “udev” service collects device management rules and
makes them available to the eudev daemon; the /etc service populates
the /etc directory of the system.
Guix system services are connected by extensions. For instance, the
secure shell service extends the Shepherd—the initialization
system, running as PID 1—by giving it the command lines to start and
stop the secure shell daemon (see openssh-service-type); the UPower service extends the D-Bus service
by passing it its .service specification, and extends the udev
service by passing it device management rules (see upower-service); the Guix daemon service extends the Shepherd by
passing it the command lines to start and stop the daemon, and extends the
account service by passing it a list of required build user accounts
(see Базовые службы).
All in all, services and their “extends” relations form a directed acyclic graph (DAG). If we represent services as boxes and extensions as arrows, a typical system might provide something like this:

At the bottom, we see the system service, which produces the directory
containing everything to run and boot the system, as returned by the
guix system build command. See Интерфейс сервиса, to learn
about the other service types shown here. See the
guix system extension-graph command, for information on how to
generate this representation for a particular operating system definition.
Technically, developers can define service types to express these
relations. There can be any number of services of a given type on the
system—for instance, a system running two instances of the GNU secure
shell server (lsh) has two instances of lsh-service-type, with
different parameters.
The following section describes the programming interface for service types and services.
Next: Интерфейс сервиса, Previous: Структура сервисов, Up: Создание служб [Contents][Index]
12.18.2 Типы сервисов и сервисы
A service type is a node in the DAG described above. Let us start
with a simple example, the service type for the Guix build daemon
(see Вызов guix-daemon):
(define guix-service-type
(service-type
(name 'guix)
(extensions
(list (service-extension shepherd-root-service-type guix-shepherd-service)
(service-extension account-service-type guix-accounts)
(service-extension activation-service-type guix-activation)))
(default-value (guix-configuration))))
It defines three things:
- A name, whose sole purpose is to make inspection and debugging easier.
- A list of service extensions, where each extension designates the
target service type and a procedure that, given the parameters of the
service, returns a list of objects to extend the service of that type.
Every service type has at least one service extension. The only exception is the boot service type, which is the ultimate service.
- Optionally, a default value for instances of this type.
In this example, guix-service-type extends three services:
shepherd-root-service-typeThe
guix-shepherd-serviceprocedure defines how the Shepherd service is extended. Namely, it returns a<shepherd-service>object that defines howguix-daemonis started and stopped (see Сервисы Shepherd).account-service-typeThis extension for this service is computed by
guix-accounts, which returns a list ofuser-groupanduser-accountobjects representing the build user accounts (see Вызовguix-daemon).activation-service-typeHere
guix-activationis a procedure that returns a gexp, which is a code snippet to run at “activation time”—e.g., when the service is booted.
A service of this type is instantiated like this:
(service guix-service-type
(guix-configuration
(build-accounts 5)
(use-substitutes? #f)))
The second argument to the service form is a value representing the
parameters of this specific service instance.
See guix-configuration, for information
about the guix-configuration data type. When the value is omitted,
the default value specified by guix-service-type is used:
guix-service-type is quite simple because it extends other services
but is not extensible itself.
The service type for an extensible service looks like this:
(define udev-service-type
(service-type (name 'udev)
(extensions
(list (service-extension shepherd-root-service-type
udev-shepherd-service)))
(compose concatenate) ;concatenate the list of rules
(extend (lambda (config rules)
(match config
(($ <udev-configuration> udev initial-rules)
(udev-configuration
(udev udev) ;the udev package to use
(rules (append initial-rules rules)))))))))
This is the service type for the
eudev device management
daemon. Compared to the previous example, in addition to an extension of
shepherd-root-service-type, we see two new fields:
composeThis is the procedure to compose the list of extensions to services of this type.
Services can extend the udev service by passing it lists of rules; we compose those extensions simply by concatenating them.
extendThis procedure defines how the value of the service is extended with the composition of the extensions.
Udev extensions are composed into a list of rules, but the udev service value is itself a
<udev-configuration>record. So here, we extend that record by appending the list of rules it contains to the list of contributed rules.описаниеThis is a string giving an overview of the service type. The string can contain Texinfo markup (see Overview in GNU Texinfo). The
guix system searchcommand searches these strings and displays them (see Invokingguix system).
There can be only one instance of an extensible service type such as
udev-service-type. If there were more, the service-extension
specifications would be ambiguous.
Still here? The next section provides a reference of the programming interface for services.
Next: Сервисы Shepherd, Previous: Типы сервисов и сервисы, Up: Создание служб [Contents][Index]
12.18.3 Интерфейс сервиса
We have seen an overview of service types (see Типы сервисов и сервисы). This section provides a reference on how to manipulate services
and service types. This interface is provided by the (gnu services)
module.
- Scheme Procedure: service type [value]
Return a new service of type, a
<service-type>object (see below). value can be any object; it represents the parameters of this particular service instance.When value is omitted, the default value specified by type is used; if type does not specify a default value, an error is raised.
Например:
равнозачно этому:
In both cases the result is an instance of
openssh-service-typewith the default configuration.
- Scheme Procedure: service? obj
Return true if obj is a service.
- Scheme Procedure: service-kind service
Return the type of service—i.e., a
<service-type>object.
- Scheme Procedure: service-value service
Return the value associated with service. It represents its parameters.
Here is an example of how a service is created and manipulated:
(define s (service nginx-service-type (nginx-configuration (nginx nginx) (log-directory log-directory) (run-directory run-directory) (file config-file)))) (service? s) ⇒ #t (eq? (service-kind s) nginx-service-type) ⇒ #t
The modify-services form provides a handy way to change the
parameters of some of the services of a list such as %base-services
(see %base-services). It evaluates to a list of
services. Of course, you could always use standard list combinators such as
map and fold to do that (see List Library in GNU Guile Reference Manual); modify-services simply provides a more
concise form for this common pattern.
- Scheme Syntax: modify-services services (type variable => body) …
-
Modify the services listed in services according to the given clauses. Each clause has the form:
(type variable => body)
where type is a service type—e.g.,
guix-service-type—and variable is an identifier that is bound within the body to the service parameters—e.g., aguix-configurationinstance—of the original service of that type.The body should evaluate to the new service parameters, which will be used to configure the new service. This new service will replace the original in the resulting list. Because a service’s service parameters are created using
define-record-type*, you can write a succinct body that evaluates to the new service parameters by using theinheritfeature thatdefine-record-type*provides.Clauses can also have the following form:
(delete type)Such a clause removes all services of the given type from services.
See Использование системы конфигурации, for example usage.
Next comes the programming interface for service types. This is something
you want to know when writing new service definitions, but not necessarily
when simply looking for ways to customize your operating-system
declaration.
- Data Type: service-type
-
This is the representation of a service type (see Типы сервисов и сервисы).
nameThis is a symbol, used only to simplify inspection and debugging.
extensionsA non-empty list of
<service-extension>objects (see below).compose(default:#f)If this is
#f, then the service type denotes services that cannot be extended—i.e., services that do not receive “values” from other services.Otherwise, it must be a one-argument procedure. The procedure is called by
fold-servicesand is passed a list of values collected from extensions. It may return any single value.extend(default:#f)If this is
#f, services of this type cannot be extended.Otherwise, it must be a two-argument procedure:
fold-servicescalls it, passing it the initial value of the service as the first argument and the result of applyingcomposeto the extension values as the second argument. It must return a value that is a valid parameter value for the service instance.описаниеThis is a string, possibly using Texinfo markup, describing in a couple of sentences what the service is about. This string allows users to find about the service through
guix system search(see Invokingguix system).port(default:22)The default value associated for instances of this service type. This allows users to use the
serviceform without its second argument:(service type)The returned service in this case has the default value specified by type.
See Типы сервисов и сервисы, for examples.
- Scheme Procedure: service-extension target-type compute Return a new extension for services of type
target-type. compute must be a one-argument procedure:
fold-servicescalls it, passing it the value associated with the service that provides the extension; it must return a valid value for the target service.
- Scheme Procedure: service-extension? obj
Return true if obj is a service extension.
Occasionally, you might want to simply extend an existing service. This
involves creating a new service type and specifying the extension of
interest, which can be verbose; the simple-service procedure provides
a shorthand for this.
- Scheme Procedure: simple-service name target value
Return a service that extends target with value. This works by creating a singleton service type name, of which the returned service is an instance.
For example, this extends mcron (see Запланированное исполнения задач) with an additional job:
(simple-service 'my-mcron-job mcron-service-type #~(job '(next-hour (3)) "guix gc -F 2G"))
At the core of the service abstraction lies the fold-services
procedure, which is responsible for “compiling” a list of services down to
a single directory that contains everything needed to boot and run the
system—the directory shown by the guix system build command
(see Invoking guix system). In essence, it propagates service
extensions down the service graph, updating each node parameters on the way,
until it reaches the root node.
- Scheme Procedure: fold-services services [#:target-type system-service-type] Fold services by propagating
their extensions down to the root of type target-type; return the root service adjusted accordingly.
Lastly, the (gnu services) module also defines several essential
service types, some of which are listed below.
- Scheme Variable: system-service-type
This is the root of the service graph. It produces the system directory as returned by the
guix system buildcommand.
- Scheme Variable: boot-service-type
The type of the “boot service”, which produces the boot script. The boot script is what the initial RAM disk runs when booting.
- Scheme Variable: etc-service-type
The type of the /etc service. This service is used to create files under /etc and can be extended by passing it name/file tuples such as:
(list `("issue" ,(plain-file "issue" "Welcome!\n")))In this example, the effect would be to add an /etc/issue file pointing to the given file.
- Scheme Variable: setuid-program-service-type
Type for the “setuid-program service”. This service collects lists of executable file names, passed as gexps, and adds them to the set of setuid and setgid programs on the system (see Программы setuid).
- Scheme Variable: profile-service-type
Type of the service that populates the system profile—i.e., the programs under /run/current-system/profile. Other services can extend it by passing it lists of packages to add to the system profile.
- Scheme Variable: provenance-service-type
This is the type of the service that records provenance meta-data in the system itself. It creates several files under /run/current-system:
- каналы
This is a “channel file” that can be passed to
guix pull -Corguix time-machine -C, and which describes the channels used to build the system, if that information was available (see Каналы).- Конфигурирование системы
This is the file that was passed as the value for this
provenance-service-typeservice. By default,guix system reconfigureautomatically passes the OS configuration file it received on the command line.- provenance
This contains the same information as the two other files but in a format that is more readily processable.
In general, these two pieces of information (channels and configuration file) are enough to reproduce the operating system “from source”.
Caveats: This information is necessary to rebuild your operating system, but it is not always sufficient. In particular, configuration.scm itself is insufficient if it is not self-contained—if it refers to external Guile modules or to extra files. If you want configuration.scm to be self-contained, we recommend that modules or files it refers to be part of a channel.
Besides, provenance meta-data is “silent” in the sense that it does not change the bits contained in your system, except for the meta-data bits themselves. Two different OS configurations or sets of channels can lead to the same system, bit-for-bit; when
provenance-service-typeis used, these two systems will have different meta-data and thus different store file names, which makes comparison less trivial.This service is automatically added to your operating system configuration when you use
guix system reconfigure,guix system init, orguix deploy.
- Процедура Scheme: sane-service-type
Type of the service that collects lists of packages containing kernel-loadable modules, and adds them to the set of kernel-loadable modules.
This service type is intended to be extended by other service types, such as below:
(simple-service 'installing-module linux-loadable-module-service-type (list module-to-install-1 module-to-install-2))This does not actually load modules at bootup, only adds it to the kernel profile so that it can be loaded by other means.
Next: Complex Configurations, Previous: Интерфейс сервиса, Up: Создание служб [Contents][Index]
12.18.4 Сервисы Shepherd
The (gnu services shepherd) module provides a way to define services
managed by the GNU Shepherd, which is the initialization system—the
first process that is started when the system boots, also known as
PID 1 (see Introduction in The GNU Shepherd Manual).
Services in the Shepherd can depend on each other. For instance, the SSH daemon may need to be started after the syslog daemon has been started, which in turn can only happen once all the file systems have been mounted. The simple operating system defined earlier (see Использование системы конфигурации) results in a service graph like this:

You can actually generate such a graph for any operating system definition
using the guix system shepherd-graph command
(see guix system shepherd-graph).
The %shepherd-root-service is a service object representing
PID 1, of type shepherd-root-service-type; it can be extended by
passing it lists of <shepherd-service> objects.
- Data Type: shepherd-service
The data type representing a service managed by the Shepherd.
provisionThis is a list of symbols denoting what the service provides.
These are the names that may be passed to
herd start,herd status, and similar commands (see Invoking herd in The GNU Shepherd Manual). See theprovidesslot in The GNU Shepherd Manual, for details.features(default:'())List of symbols denoting the Shepherd services this one depends on.
one-shot?(default:#f)Whether this service is one-shot. One-shot services stop immediately after their
startaction has completed. See Slots of services in The GNU Shepherd Manual, for more info.respawn?(default:#t)Whether to restart the service when it stops, for instance when the underlying process dies.
startstop(default:#~(const #f))The
startandstopfields refer to the Shepherd’s facilities to start and stop processes (see Service De- and Constructors in The GNU Shepherd Manual). They are given as G-expressions that get expanded in the Shepherd configuration file (see G-Expressions).actions(default:'()) ¶This is a list of
shepherd-actionobjects (see below) defining actions supported by the service, in addition to the standardstartandstopactions. Actions listed here become available asherdsub-commands:herd action service [arguments…]
auto-start?(default:#t)Whether this service should be started automatically by the Shepherd. If it is
#fthe service has to be started manually withherd start.документацияA documentation string, as shown when running:
herd doc service-name
where service-name is one of the symbols in
provision(see Invoking herd in The GNU Shepherd Manual).modules(default:%default-modules)This is the list of modules that must be in scope when
startandstopare evaluated.
The example below defines a Shepherd service that spawns syslogd,
the system logger from the GNU Networking Utilities (see syslogd in GNU Inetutils):
(let ((config (plain-file "syslogd.conf" "…")))
(shepherd-service
(documentation "Run the syslog daemon (syslogd).")
(provision '(syslogd))
(requirement '(user-processes))
(start #~(make-forkexec-constructor
(list #$(file-append inetutils "/libexec/syslogd")
"--rcfile" #$config)
#:pid-file "/var/run/syslog.pid"))
(stop #~(make-kill-destructor))))
Key elements in this example are the start and stop fields:
they are staged code snippets that use the
make-forkexec-constructor procedure provided by the Shepherd and its
dual, make-kill-destructor (see Service De- and Constructors in The GNU Shepherd Manual). The start field will have
shepherd spawn syslogd with the given option; note that
we pass config after --rcfile, which is a configuration file
declared above (contents of this file are omitted). Likewise, the
stop field tells how this service is to be stopped; in this case, it
is stopped by making the kill system call on its PID. Code staging
is achieved using G-expressions: #~ stages code, while #$
“escapes” back to host code (see G-Expressions).
- Data Type: shepherd-action
This is the data type that defines additional actions implemented by a Shepherd service (see above).
nameSymbol naming the action.
документацияThis is a documentation string for the action. It can be viewed by running:
herd doc service action action
процедураThis should be a gexp that evaluates to a procedure of at least one argument, which is the “running value” of the service (see Slots of services in The GNU Shepherd Manual).
The following example defines an action called
say-hellothat kindly greets the user:(shepherd-action (name 'say-hello) (documentation "Say hi!") (procedure #~(lambda (running . args) (format #t "Hello, friend! arguments: ~s\n" args) #t)))Assuming this action is added to the
exampleservice, then you can do:# herd say-hello example Hello, friend! arguments: () # herd say-hello example a b c Hello, friend! arguments: ("a" "b" "c")This, as you can see, is a fairly sophisticated way to say hello. See Service Convenience in The GNU Shepherd Manual, for more info on actions.
- Scheme Procedure: shepherd-configuration-action
Return a
configurationaction to display file, which should be the name of the service’s configuration file.It can be useful to equip services with that action. For example, the service for the Tor anonymous router (see
tor-service-type) is defined roughly like this:(let ((torrc (plain-file "torrc" …))) (shepherd-service (provision '(tor)) (requirement '(user-processes loopback syslogd)) (start #~(make-forkexec-constructor (list #$(file-append tor "/bin/tor") "-f" #$torrc) #:user "tor" #:group "tor")) (stop #~(make-kill-destructor)) (actions (list (shepherd-configuration-action torrc))) (documentation "Run the Tor anonymous network overlay.")))Thanks to this action, administrators can inspect the configuration file passed to
torwith this shell command:cat $(herd configuration tor)
This can come in as a handy debugging tool!
- Scheme Variable: shepherd-root-service-type
The service type for the Shepherd “root service”—i.e., PID 1.
This is the service type that extensions target when they want to create shepherd services (see Типы сервисов и сервисы, for an example). Each extension must pass a list of
<shepherd-service>. Its value must be ashepherd-configuration, as described below.
- Конфигурирование: системы
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет Hurd.
features(default:'())A list of
<shepherd-service>to start. You should probably use the service extension mechanism instead (see Сервисы Shepherd).
Следующий пример порождает новую оболочку, установленную для разработки GNU Guile:
(operating-system
;; ...
(services (append (list openssh-service-type))
;; ...
%desktop-services)
;; ...
;; Use own Shepherd package.
(essential-services
(modify-services (operating-system-default-essential-services
this-operating-system)
(shepherd-root-service-type config => (shepherd-configuration
(inherit config)
(shepherd my-shepherd))))))
- Scheme Variable: %shepherd-root-service
This service represents PID 1.
Previous: Сервисы Shepherd, Up: Создание служб [Contents][Index]
12.18.5 Complex Configurations
Some programs might have rather complex configuration files or formats, and
to make it easier to create Scheme bindings for these configuration files,
you can use the utilities defined in the (gnu services configuration)
module.
The main utility is the define-configuration macro, which you will
use to define a Scheme record type (see Record Overview in GNU
Guile Reference Manual). The Scheme record will be serialized to a
configuration file by using serializers, which are procedures that
take some kind of Scheme value and returns a G-expression
(see G-Expressions), which should, once serialized to the disk, return a
string. More details are listed below.
- Scheme Syntax: define-configuration name clause1 clause2 ... Create a record type named
namethat contains the fields found in the clauses.
A clause can have one of the following forms:
(field-name (type default-value) documentation) (field-name (type default-value) documentation serializer) (field-name (type) documentation) (field-name (type) documentation serializer)
field-name is an identifier that denotes the name of the field in the generated record.
type is the type of the value corresponding to field-name; since Guile is untyped, a predicate procedure—
type?—will be called on the value corresponding to the field to ensure that the value is of the correct type. This means that if say, type ispackage, then a procedure namedpackage?will be applied on the value to make sure that it is indeed a<package>object.default-value is the default value corresponding to the field; if none is specified, the user is forced to provide a value when creating an object of the record type.
documentation is a string formatted with Texinfo syntax which should provide a description of what setting this field does.
serializer is the name of a procedure which takes two arguments, the first is the name of the field, and the second is the value corresponding to the field. The procedure should return a string or G-expression (see G-Expressions) that represents the content that will be serialized to the configuration file. If none is specified, a procedure of the name
serialize-typewill be used.A simple serializer procedure could look like this:
(define (serialize-boolean field-name value) (let ((value (if value "true" "false"))) #~(string-append #$field-name #$value)))In some cases multiple different configuration records might be defined in the same file, but their serializers for the same type might have to be different, because they have different configuration formats. For example, the
serialize-booleanprocedure for the Getmail service would have to be different from the one for the Transmission service. To make it easier to deal with this situation, one can specify a serializer prefix by using theprefixliteral in thedefine-configurationform. This means that one doesn’t have to manually specify a custom serializer for every field.(define (foo-serialize-string field-name value) …) (define (bar-serialize-string field-name value) …) (define-configuration foo-configuration (label (string) "The name of label.") (prefix foo-)) (define-configuration bar-configuration (ip-address (string) "The IPv4 address for this device.") (prefix bar-))
However, in some cases you might not want to serialize any of the values of the record, to do this, you can use the
no-serializationliteral. There is also thedefine-configuration/no-serializationmacro which is a shorthand of this.
- Scheme Syntax: define-maybe type
Sometimes a field should not be serialized if the user doesn’t specify a value. To achieve this, you can use the
define-maybemacro to define a “maybe type”; if the value of a maybe type is left unset, or is set to the%unset-valuevalue, then it will not be serialized.When defining a “maybe type”, the corresponding serializer for the regular type will be used by default. For example, a field of type
maybe-stringwill be serialized using theserialize-stringprocedure by default, you can of course change this by specifying a custom serializer procedure. Likewise, the type of the value would have to be a string, or left unspecified.(define-maybe string) (define (serialize-string field-name value) …) (define-configuration baz-configuration (name ;; If set to a string, the `serialize-string' procedure will be used ;; to serialize the string. Otherwise this field is not serialized. maybe-string "The name of this module."))
Like with
define-configuration, one can set a prefix for the serializer name by using theprefixliteral.(define-maybe integer (prefix baz-)) (define (baz-serialize-integer field-name value) …)
There is also the
no-serializationliteral, which when set means that no serializer will be defined for the “maybe type”, regardless of whether its value is set or not.define-maybe/no-serializationis a shorthand for specifying theno-serializationliteral.(define-maybe/no-serialization symbol) (define-configuration/no-serialization test-configuration (mode maybe-symbol "Docstring."))
- (Scheme: Procedure) maybe-value-set? value
Predicate to check whether a user explicitly specified the value of a maybe field.
- Scheme Procedure: serialize-configuration configuration fields Return a G-expression that contains the values corresponding to
the fields of configuration, a record that has been generated by
define-configuration. The G-expression can then be serialized to disk by using something likemixed-text-file.
- Scheme Procedure: empty-serializer field-name value
A serializer that just returns an empty string. The
serialize-packageprocedure is an alias for this.
Once you have defined a configuration record, you will most likely also want to document it so that other people know to use it. To help with that, there are two procedures, both of which are documented below.
- Scheme Procedure: generate-documentation documentation documentation-name Generate a Texinfo fragment from the docstrings in
documentation, a list of
(label fields sub-documentation ...). label should be a symbol and should be the name of the configuration record. fields should be a list of all the fields available for the configuration record.sub-documentation is a
(field-name configuration-name)tuple. field-name is the name of the field which takes another configuration record as its value, and configuration-name is the name of that configuration record.sub-documentation is only needed if there are nested configuration records. For example, the
getmail-configurationrecord (see Почтовые сервисы) accepts agetmail-configuration-filerecord in one of itsrcfilefield, therefore documentation forgetmail-configuration-fileis nested ingetmail-configuration.(generate-documentation `((getmail-configuration ,getmail-configuration-fields (rcfile getmail-configuration-file)) …) 'getmail-configuration)documentation-name should be a symbol and should be the name of the configuration record.
- Scheme Procedure: configuration->documentation
configuration-symbol Take configuration-symbol, the symbol corresponding to the name used when defining a configuration record with
define-configuration, and print the Texinfo documentation of its fields. This is useful if there aren’t any nested configuration records since it only prints the documentation for the top-level fields.
As of right now, there is no automated way to generate documentation for
configuration records and put them in the manual. Instead, every time you
make a change to the docstrings of a configuration record, you have to
manually call generate-documentation or
configuration->documentation, and paste the output into the
doc/guix.texi file.
Below is an example of a record type created using
define-configuration and friends.
(use-modules (gnu services) (guix gexp) (gnu services configuration) (srfi srfi-26) (srfi srfi-1)) ;; Turn field names, which are Scheme symbols into strings (define (uglify-field-name field-name) (let ((str (symbol->string field-name))) ;; field? -> is-field (if (string-suffix? "?" str) (string-append "is-" (string-drop-right str 1)) str))) (define (serialize-string field-name value) #~(string-append #$(uglify-field-name field-name) " = " #$value "\n")) (define (serialize-integer field-name value) (serialize-string field-name (number->string value))) (define (serialize-boolean field-name value) (serialize-string field-name (if value "true" "false"))) (define (serialize-contact-name field-name value) #~(string-append "\n[" #$value "]\n")) (define (list-of-contact-configurations? lst) (every contact-configuration? lst)) (define (serialize-list-of-contact-configurations field-name value) #~(string-append #$@(map (cut serialize-configuration <> contact-configuration-fields) value))) (define (serialize-contacts-list-configuration configuration) (mixed-text-file "contactrc" #~(string-append "[Owner]\n" #$(serialize-configuration configuration contacts-list-configuration-fields)))) (define-maybe integer) (define-maybe string) (define-configuration contact-configuration (name (string) "The name of the contact." serialize-contact-name) (phone-number maybe-integer "The person's phone number.") (email maybe-string "The person's email address.") (married? (boolean) "Whether the person is married.")) (define-configuration contacts-list-configuration (name (string) "The name of the owner of this contact list.") (email (string) "The owner's email address.") (contacts (list-of-contact-configurations '()) "A list of @code{contact-configuation} records which contain information about all your contacts."))
A contacts list configuration could then be created like this:
(define my-contacts
(contacts-list-configuration
(name "Alice")
(email "alice@example.org")
(contacts
(list (contact-configuration
(name "Bob")
(phone-number 1234)
(email "bob@gnu.org")
(married? #f))
(contact-configuration
(name "Charlie")
(phone-number 0000)
(married? #t))))))
After serializing the configuration to disk, the resulting file would look like this:
[owner] name = Alice email = alice@example.org [Bob] phone-number = 1234 email = bob@gnu.org is-married = false [Charlie] phone-number = 0 is-married = true
Next: Документация, Previous: Конфигурирование системы, Up: GNU Guix [Contents][Index]
13 Home Configuration
Guix supports declarative configuration of home environments by
utilizing the configuration mechanism described in the previous chapter
(see Создание служб), but for user’s dotfiles and packages. It works
both on Guix System and foreign distros and allows users to declare all the
packages and services that should be installed and configured for the user.
Once a user has written a file containing home-environment record,
such a configuration can be instantiated by an unprivileged user with
the guix home command (see Invoking guix home).
Примечание: The functionality described in this section is still under development and is subject to change. Get in touch with us on guix-devel@gnu.org!
The user’s home environment usually consists of three basic parts: software,
configuration, and state. Software in mainstream distros are usually
installed system-wide, but with GNU Guix most software packages can be
installed on a per-user basis without needing root privileges, and are thus
considered part of the user’s home environment. Packages on their own
are not very useful in many cases, because often they require some
additional configuration, usually config files that reside in
XDG_CONFIG_HOME (~/.config by default) or other directories.
Everything else can be considered state, like media files, application
databases, and logs.
Using Guix for managing home environments provides a number of advantages:
- All software can be configured in one language (Guile Scheme), this gives users the ability to share values between configurations of different programs.
- A well-defined home environment is self-contained and can be created in a declarative and reproducible way—there is no need to grab external binaries or manually edit some configuration file.
- After every
guix home reconfigureinvocation, a new home environment generation will be created. This means that users can rollback to a previous home environment generation so they don’t have to worry about breaking their configuration. - It is possible to manage stateful data with Guix Home, this
includes the ability to automatically clone Git repositories on the initial
setup of the machine, and periodically running commands like
rsyncto sync data with another host. This functionality is still in an experimental stage, though.
Next: Configuring the Shell, Up: Home Configuration [Contents][Index]
13.1 Declaring the Home Environment
The home environment is configured by providing a home-environment
declaration in a file that can be passed to the guix home command
(see Invoking guix home). The easiest way to get started is by
generating an initial configuration with guix home import:
guix home import ~/src/guix-config
The guix home import command reads some of the “dot files” such
as ~/.bashrc found in your home directory and copies them to the
given directory, ~/src/guix-config in this case; it also reads the
contents of your profile, ~/.guix-profile, and, based on that, it
populates ~/src/guix-config/home-configuration.scm with a Home
configuration that resembles your current configuration.
A simple setup can include Bash and a custom text configuration, like in the example below. Don’t be afraid to declare home environment parts, which overlaps with your current dot files: before installing any configuration files, Guix Home will back up existing config files to a separate place in the home directory.
Примечание: It is highly recommended that you manage your shell or shells with Guix Home, because it will make sure that all the necessary scripts are sourced by the shell configuration file. Otherwise you will need to do it manually. (see Configuring the Shell).
(use-modules (gnu home) (gnu home services) (gnu home services shells) (gnu services) (gnu packages admin) (guix gexp)) (home-environment (packages (list htop)) (services (list (service home-bash-service-type (home-bash-configuration (guix-defaults? #t) (bash-profile (list (plain-file "bash-profile" "\ export HISTFILE=$XDG_CACHE_HOME/.bash_history"))))) (simple-service 'test-config home-xdg-configuration-files-service-type (list `("test.conf" ,(plain-file "tmp-file.txt" "the content of ~/.config/test.conf")))))))
The packages field should be self-explanatory, it will install the
list of packages into the user’s profile. The most important field is
services, it contains a list of home services, which are the
basic building blocks of a home environment.
There is no daemon (at least not necessarily) related to a home service, a home service is just an element that is used to declare part of home environment and extend other parts of it. The extension mechanism discussed in the previous chapter (see Создание служб) should not be confused with Shepherd services (see Сервисы Shepherd). Using this extension mechanism and some Scheme code that glues things together gives the user the freedom to declare their own, very custom, home environments.
Once the configuration looks good, you can first test it in a throw-away “container”:
guix home container config.scm
The command above spawns a shell where your home environment is running. The shell runs in a container, meaning it’s isolated from the rest of the system, so it’s a good way to try out your configuration—you can see if configuration bits are missing or misbehaving, if daemons get started, and so on. Once you exit that shell, you’re back to the prompt of your original shell “in the real world”.
Once you have a configuration file that suits your needs, you can reconfigure your home by running:
guix home reconfigure config.scm
This “builds” your home environment and creates ~/.guix-home pointing to it. Voilà!
Примечание: Make sure the operating system has elogind, systemd, or a similar mechanism to create the XDG run-time directory and has the
XDG_RUNTIME_DIRvariable set. Failing that, the on-first-login script will not execute anything, and processes like user Shepherd and its descendants will not start.
Next: Home Services, Previous: Declaring the Home Environment, Up: Home Configuration [Contents][Index]
13.2 Configuring the Shell
This section is safe to skip if your shell or shells are managed by Guix Home. Otherwise, read it carefully.
There are a few scripts that must be evaluated by a login shell to activate
the home environment. The shell startup files only read by login shells
often have profile suffix. For more information about login shells
see Invoking Bash in The GNU Bash Reference Manual and see
Bash Startup Files in The GNU Bash Reference Manual.
The first script that needs to be sourced is setup-environment, which
sets all the necessary environment variables (including variables declared
by the user) and the second one is on-first-login, which starts
Shepherd for the current user and performs actions declared by other home
services that extends home-run-on-first-login-service-type.
Guix Home will always create ~/.profile, which contains the following lines:
HOME_ENVIRONMENT=$HOME/.guix-home . $HOME_ENVIRONMENT/setup-environment $HOME_ENVIRONMENT/on-first-login
This makes POSIX compliant login shells activate the home environment. However, in most cases this file won’t be read by most modern shells, because they are run in non POSIX mode by default and have their own *profile startup files. For example Bash will prefer ~/.bash_profile in case it exists and only if it doesn’t will it fallback to ~/.profile. Zsh (if no additional options are specified) will ignore ~/.profile, even if ~/.zprofile doesn’t exist.
To make your shell respect ~/.profile, add . ~/.profile or
source ~/.profile to the startup file for the login shell. In case
of Bash, it is ~/.bash_profile, and in case of Zsh, it is
~/.zprofile.
Примечание: This step is only required if your shell is not managed by Guix Home. Otherwise, everything will be done automatically.
Next: Invoking guix home, Previous: Configuring the Shell, Up: Home Configuration [Contents][Index]
13.3 Home Services
A home service is not necessarily something that has a daemon and is
managed by Shepherd (see Jump Start in The GNU Shepherd
Manual), in most cases it doesn’t. It’s a simple building block of the
home environment, often declaring a set of packages to be installed in the
home environment profile, a set of config files to be symlinked into
XDG_CONFIG_HOME (~/.config by default), and environment
variables to be set by a login shell.
There is a service extension mechanism (see Структура сервисов) which
allows home services to extend other home services and utilize capabilities
they provide; for example: declare mcron jobs (see GNU Mcron) by extending Scheduled User’s Job Execution; declare daemons by
extending Managing User Daemons; add commands, which will be invoked
on by the Bash by extending home-bash-service-type.
A good way to discover available home services is using the guix
home search command (see Invoking guix home). After the required home
services are found, include its module with the use-modules form
(see Using Guile Modules in The GNU Guile Reference
Manual), or the #:use-modules directive (see Creating Guile Modules in The GNU Guile Reference Manual) and declare
a home service using the service function, or extend a service type
by declaring a new service with the simple-service procedure from
(gnu services).
- Essential Home Services
- Shells
- Scheduled User’s Job Execution
- Power Management Home Services
- Managing User Daemons
- Secure Shell
- Desktop Home Services
- Guix Home Services
Next: Shells, Up: Home Services [Contents][Index]
13.3.1 Essential Home Services
There are a few essential home services defined in (gnu services),
they are mostly for internal use and are required to build a home
environment, but some of them will be useful for the end user.
- Scheme Variable: home-environment-variables-service-type
The service of this type will be instantiated by every home environment automatically by default, there is no need to define it, but someone may want to extend it with a list of pairs to set some environment variables.
(list ("ENV_VAR1" . "value1") ("ENV_VAR2" . "value2"))The easiest way to extend a service type, without defining a new service type is to use the
simple-servicehelper from(gnu services).(simple-service 'some-useful-env-vars-service home-environment-variables-service-type `(("LESSHISTFILE" . "$XDG_CACHE_HOME/.lesshst") ("SHELL" . ,(file-append zsh "/bin/zsh")) ("USELESS_VAR" . #f) ("_JAVA_AWT_WM_NONREPARENTING" . #t)))If you include such a service in you home environment definition, it will add the following content to the setup-environment script (which is expected to be sourced by the login shell):
export LESSHISTFILE=$XDG_CACHE_HOME/.lesshst export SHELL=/gnu/store/2hsg15n644f0glrcbkb1kqknmmqdar03-zsh-5.8/bin/zsh export _JAVA_AWT_WM_NONREPARENTING
Примечание: Make sure that module
(gnu packages shells)is imported withuse-modulesor any other way, this namespace contains the definition of thezshpackage, which is used in the example above.The association list (see Association Lists in The GNU Guile Reference manual) is a data structure containing key-value pairs, for
home-environment-variables-service-typethe key is always a string, the value can be a string, string-valued gexp (see G-Expressions), file-like object (see file-like object) or boolean. For gexps, the variable will be set to the value of the gexp; for file-like objects, it will be set to the path of the file in the store (see Хранилище); for#t, it will export the variable without any value; and for#f, it will omit variable.
- Scheme Variable: home-profile-service-type
The service of this type will be instantiated by every home environment automatically, there is no need to define it, but you may want to extend it with a list of packages if you want to install additional packages into your profile. Other services, which need to make some programs available to the user will also extend this service type.
The extension value is just a list of packages:
(list htop vim emacs)The same approach as
simple-service(see simple-service) forhome-environment-variables-service-typecan be used here, too. Make sure that modules containing the specified packages are imported withuse-modules. To find a package or information about its module useguix search(see Вызовguix package). Alternatively,specification->packagecan be used to get the package record from string without importing related module.
There are few more essential services, but users are not expected to extend them.
- Scheme Variable: home-service-type
The root of home services DAG, it generates a folder, which later will be symlinked to ~/.guix-home, it contains configurations, profile with binaries and libraries, and some necessary scripts to glue things together.
- Scheme Variable: home-run-on-first-login-service-type
The service of this type generates a Guile script, which is expected to be executed by the login shell. It is only executed if the special flag file inside
XDG_RUNTIME_DIRhasn’t been created, this prevents redundant executions of the script if multiple login shells are spawned.It can be extended with a gexp. However, to autostart an application, users should not use this service, in most cases it’s better to extend
home-shepherd-service-typewith a Shepherd service (see Сервисы Shepherd), or extend the shell’s startup file with the required command using the appropriate service type.
- Scheme Variable: home-files-service-type
The service of this type allows to specify a list of files, which will go to ~/.guix-home/files, usually this directory contains configuration files (to be more precise it contains symlinks to files in /gnu/store), which should be placed in $XDG_CONFIG_DIR or in rare cases in $HOME. It accepts extension values in the following format:
`((".sway/config" ,sway-file-like-object) (".tmux.conf" ,(local-file "./tmux.conf")))
Each nested list contains two values: a subdirectory and file-like object. After building a home environment ~/.guix-home/files will be populated with apropiate content and all nested directories will be created accordingly, however, those files won’t go any further until some other service will do it. By default a
home-symlink-manager-service-type, which creates necessary symlinks in home folder to files from ~/.guix-home/files and backs up already existing, but clashing configs and other things, is a part of essential home services (enabled by default), but it’s possible to use alternative services to implement more advanced use cases like read-only home. Feel free to experiment and share your results.
- Scheme Variable: home-xdg-configuration-files-service-type
The service is very similiar to
home-files-service-type(and actually extends it), but used for defining files, which will go to ~/.guix-home/files/.config, which will be symlinked to $XDG_CONFIG_DIR byhome-symlink-manager-service-type(for example) during activation. It accepts extension values in the following format:`(("sway/config" ,sway-file-like-object) ;; -> ~/.guix-home/files/.config/sway/config ;; -> $XDG_CONFIG_DIR/sway/config (by symlink-manager) ("tmux/tmux.conf" ,(local-file "./tmux.conf")))
- Scheme Variable: home-activation-service-type
The service of this type generates a guile script, which runs on every
guix home reconfigureinvocation or any other action, which leads to the activation of the home environment.
- Scheme Variable: home-symlink-manager-service-type
The service of this type generates a guile script, which will be executed during activation of home environment, and do a few following steps:
- Reads the content of files/ directory of current and pending home environments.
- Cleans up all symlinks created by symlink-manager on previous activation. Also, sub-directories, which become empty also will be cleaned up.
- Creates new symlinks the following way: It looks files/ directory
(usually defined with
home-files-service-type,home-xdg-configuration-files-service-typeand maybe some others), takes the files from files/.config/ subdirectory and put respective links inXDG_CONFIG_DIR. For example symlink for files/.config/sway/config will end up in $XDG_CONFIG_DIR/sway/config. The rest files in files/ outside of files/.config/ subdirectory will be treated slightly different: symlink will just go to $HOME. files/.some-program/config will end up in $HOME/.some-program/config. - If some sub-directories are missing, they will be created.
- If there is a clashing files on the way, they will be backed up.
symlink-manager is a part of essential home services and is enabled and used by default.
Next: Scheduled User’s Job Execution, Previous: Essential Home Services, Up: Home Services [Contents][Index]
13.3.2 Shells
Shells play a quite important role in the environment initialization process, you can configure them manually as described in section Configuring the Shell, but the recommended way is to use home services listed below. It’s both easier and more reliable.
Each home environment instantiates home-shell-profile-service-type,
which creates a ~/.profile startup file for all POSIX-compatible
shells. This file contains all the necessary steps to properly initialize
the environment, but many modern shells like Bash or Zsh prefer their own
startup files, that’s why the respective home services
(home-bash-service-type and home-zsh-service-type) ensure that
~/.profile is sourced by ~/.bash_profile and
~/.zprofile, respectively.
Shell Profile Service
- Data Type: home-shell-profile-configuration
Available
home-shell-profile-configurationfields are:profile(default:()) (type: text-config)home-shell-profileis instantiated automatically byhome-environment, DO NOT create this service manually, it can only be extended.profileis a list of file-like objects, which will go to ~/.profile. By default ~/.profile contains the initialization code which must be evaluated by the login shell to make home-environment’s profile available to the user, but other commands can be added to the file if it is really necessary. In most cases shell’s configuration files are preferred places for user’s customizations. Extend home-shell-profile service only if you really know what you do.
Bash Home Service
- Data Type: home-bash-configuration
Available
home-bash-configurationfields are:package(default:bash) (type: package)The Bash package to use.
guix-defaults?(default:#t) (type: boolean)Add sane defaults like reading /etc/bashrc and coloring the output of
lsto the top of the .bashrc file.environment-variables(default:()) (type: alist)Association list of environment variables to set for the Bash session. The rules for the
home-environment-variables-service-typeapply here (see Essential Home Services). The contents of this field will be added after the contents of thebash-profilefield.aliases(default:()) (type: alist)Association list of aliases to set for the Bash session. The aliases will be defined after the contents of the
bashrcfield has been put in the .bashrc file. The alias will automatically be quoted, so something like this:'(("ls" . "ls -alF"))
turns into
alias ls="ls -alF"
bash-profile(default:()) (type: text-config)List of file-like objects, which will be added to .bash_profile. Used for executing user’s commands at start of login shell (In most cases the shell started on tty just after login). .bash_login won’t be ever read, because .bash_profile always present.
bashrc(default:()) (type: text-config)List of file-like objects, which will be added to .bashrc. Used for executing user’s commands at start of interactive shell (The shell for interactive usage started by typing
bashor by terminal app or any other program).bash-logout(default:()) (type: text-config)List of file-like objects, which will be added to .bash_logout. Used for executing user’s commands at the exit of login shell. It won’t be read in some cases (if the shell terminates by exec’ing another process for example).
You can extend the Bash service by using the home-bash-extension
configuration record, whose fields must mirror that of
home-bash-configuration (see home-bash-configuration). The
contents of the extensions will be added to the end of the corresponding
Bash configuration files (see Bash Startup Files in The GNU Bash
Reference Manual.
For example, here is how you would define a service that extends the Bash
service such that ~/.bash_profile defines an additional environment
variable, PS1:
(define bash-fancy-prompt-service
(simple-service 'bash-fancy-prompt
home-bash-service-type
(home-bash-extension
(environment-variables
'(("PS1" . "\\u \\wλ "))))))
You would then add bash-fancy-prompt-service to the list in the
services field of your home-environment. The reference of
home-bash-extension follows.
- Data Type: home-bash-extension
Available
home-bash-extensionfields are:environment-variables(default:()) (type: alist)Additional environment variables to set. These will be combined with the environment variables from other extensions and the base service to form one coherent block of environment variables.
aliases(default:()) (type: alist)Additional aliases to set. These will be combined with the aliases from other extensions and the base service.
bash-profile(default:()) (type: text-config)Additional text blocks to add to .bash_profile, which will be combined with text blocks from other extensions and the base service.
bashrc(default:()) (type: text-config)Additional text blocks to add to .bashrc, which will be combined with text blocks from other extensions and the base service.
bash-logout(default:()) (type: text-config)Additional text blocks to add to .bash_logout, which will be combined with text blocks from other extensions and the base service.
Zsh Home Service
- Data Type: home-zsh-configuration
Available
home-zsh-configurationfields are:package(default:zsh) (type: package)The Zsh package to use.
xdg-flavor?(default:#t) (type: boolean)Place all the configs to $XDG_CONFIG_HOME/zsh. Makes ~/.zshenv to set
ZDOTDIRto $XDG_CONFIG_HOME/zsh. Shell startup process will continue with $XDG_CONFIG_HOME/zsh/.zshenv.environment-variables(default:()) (type: alist)Association list of environment variables to set for the Zsh session.
zshenv(default:()) (type: text-config)List of file-like objects, which will be added to .zshenv. Used for setting user’s shell environment variables. Must not contain commands assuming the presence of tty or producing output. Will be read always. Will be read before any other file in
ZDOTDIR.zprofile(default:()) (type: text-config)List of file-like objects, which will be added to .zprofile. Used for executing user’s commands at start of login shell (In most cases the shell started on tty just after login). Will be read before .zlogin.
zshrc(default:()) (type: text-config)List of file-like objects, which will be added to .zshrc. Used for executing user’s commands at start of interactive shell (The shell for interactive usage started by typing
zshor by terminal app or any other program).zlogin(default:()) (type: text-config)List of file-like objects, which will be added to .zlogin. Used for executing user’s commands at the end of starting process of login shell.
zlogout(default:()) (type: text-config)List of file-like objects, which will be added to .zlogout. Used for executing user’s commands at the exit of login shell. It won’t be read in some cases (if the shell terminates by exec’ing another process for example).
Next: Power Management Home Services, Previous: Shells, Up: Home Services [Contents][Index]
13.3.3 Scheduled User’s Job Execution
The (gnu home services mcron) module provides an interface to
GNU mcron, a daemon to run jobs at scheduled times (see GNU mcron). The information about system’s mcron is applicable
here (see Запланированное исполнения задач), the only difference for home
services is that they have to be declared in a home-environment
record instead of an operating-system record.
- Scheme Variable: home-mcron-service-type
This is the type of the
mcronhome service, whose value is anhome-mcron-configurationobject. It allows to manage scheduled tasks.This service type can be the target of a service extension that provides additional job specifications (see Структура сервисов). In other words, it is possible to define services that provide additional mcron jobs to run.
- Data Type: home-mcron-configuration
Available
home-mcron-configurationfields are:mcron(default:mcron) (type: file-like)The mcron package to use.
jobs(default:()) (type: list-of-gexps)This is a list of gexps (see G-Expressions), where each gexp corresponds to an mcron job specification (see mcron job specifications in GNU mcron).
log?(default:#t) (type: boolean)Log messages to standard output.
log-format(default:"~1@*~a ~a: ~a~%") (type: string)(ice-9 format)format string for log messages. The default value produces messages like "‘pid name: message"’ (see Invoking in GNU mcron). Each message is also prefixed by a timestamp by GNU Shepherd.
Next: Managing User Daemons, Previous: Scheduled User’s Job Execution, Up: Home Services [Contents][Index]
13.3.4 Power Management Home Services
The (gnu home services pm) module provides home services pertaining
to battery power.
- Scheme Variable: home-batsignal-service-type
Service for
batsignal, a program that monitors battery levels and warns the user through desktop notifications when their battery is getting low. You can also configure a command to be run when the battery level passes a point deemed “dangerous”. This service is configured with thehome-batsignal-configurationrecord.
- Data Type: home-batsignal-configuration
Data type representing the configuration for batsignal.
warning-level(default:15)The battery level to send a warning message at.
warning-message(default:#f)The message to send as a notification when the battery level reaches the
warning-level. Setting to#fuses the default message.critical-level(default:5)The battery level to send a critical message at.
critical-message(default:#f)The message to send as a notification when the battery level reaches the
critical-level. Setting to#fuses the default message.danger-level(default:2)The battery level to run the
danger-commandat.danger-command(default:#f)The command to run when the battery level reaches the
danger-level. Setting to#fdisables running the command entirely.full-level(default:#f)The battery level to send a full message at. Setting to
#fdisables sending the full message entirely.full-message(default:#f)The message to send as a notification when the battery level reaches the
full-level. Setting to#fuses the default message.batteries(default:'())The batteries to monitor. Setting to
'()tries to find batteries automatically.poll-delay(default:60)The time in seconds to wait before checking the batteries again.
icon(default:#f)A file-like object to use as the icon for battery notifications. Setting to
#fdisables notification icons entirely.notifications?(default:#t)Whether to send any notifications.
notifications-expire?(default:#f)Whether notifications sent expire after a time.
notification-command(default:#f)Command to use to send messages. Setting to
#fsends a notification throughlibnotify.ignore-missing?(default:#f)Whether to ignore missing battery errors.
Next: Secure Shell, Previous: Power Management Home Services, Up: Home Services [Contents][Index]
13.3.5 Managing User Daemons
The (gnu home services shepherd) module supports the definitions of
per-user Shepherd services (see Introduction in The GNU
Shepherd Manual). You extend home-shepherd-service-type with new
services; Guix Home then takes care of starting the shepherd daemon
for you when you log in, which in turns starts the services you asked for.
- Scheme Variable: home-shepherd-service-type
The service type for the userland Shepherd, which allows one to manage long-running processes or one-shot tasks. User’s Shepherd is not an init process (PID 1), but almost all other information described in (see Сервисы Shepherd) is applicable here too.
This is the service type that extensions target when they want to create shepherd services (see Типы сервисов и сервисы, for an example). Each extension must pass a list of
<shepherd-service>. Its value must be ahome-shepherd-configuration, as described below.
- Data Type: home-shepherd-configuration
Управление конфигурацией операционной системы.
port(default:22)Используемый пакет Hurd.
auto-start? (default:#t)Whether or not to start Shepherd on first login.
features(default:'())A list of
<shepherd-service>to start. You should probably use the service extension mechanism instead (see Сервисы Shepherd).
Next: Desktop Home Services, Previous: Managing User Daemons, Up: Home Services [Contents][Index]
13.3.6 Secure Shell
The OpenSSH package includes a client, the
ssh command, that allows you to connect to remote machines using
the SSH (secure shell) protocol. With the (gnu home services
ssh) module, you can set up OpenSSH so that it works in a predictable
fashion, almost independently of state on the local machine. To do that,
you instantiate home-openssh-service-type in your Home configuration,
as explained below.
- Scheme Variable: home-openssh-service-type
This is the type of the service to set up the OpenSSH client. It takes care of several things:
- providing a ~/.ssh/config file based on your configuration so that
sshknows about hosts you regularly connect to and their associated parameters; - providing a ~/.ssh/authorized_keys, which lists public keys that the
local SSH server,
sshd, may accept to connect to this user account; - optionally providing a ~/.ssh/known_hosts file so that ssh can authenticate hosts you connect to.
Here is an example of a service and its configuration that you could add to the
servicesfield of yourhome-environment:(service home-openssh-service-type (home-openssh-configuration (hosts (list (openssh-host (name "ci.guix.gnu.org") (user "charlie")) (openssh-host (name "chbouib") (host-name "chbouib.example.org") (user "supercharlie") (port 10022)))) (authorized-keys (list (local-file "alice.pub")))))The example above lists two hosts and their parameters. For instance, running
ssh chbouibwill automatically connect tochbouib.example.orgon port 10022, logging in as user ‘supercharlie’. Further, it marks the public key in alice.pub as authorized for incoming connections.The value associated with a
home-openssh-service-typeinstance must be ahome-openssh-configurationrecord, as describe below.- providing a ~/.ssh/config file based on your configuration so that
- Data Type: home-openssh-configuration
This is the datatype representing the OpenSSH client and server configuration in one’s home environment. It contains the following fields:
hosts(default:'())A list of
openssh-hostrecords specifying host names and associated connection parameters (see below). This host list goes into ~/.ssh/config, whichsshreads at startup.known-hosts(default:*unspecified*)This must be either:
-
*unspecified*, in which casehome-openssh-service-typeleaves it up tosshand to the user to maintain the list of known hosts at ~/.ssh/known_hosts, or - a list of file-like objects, in which case those are concatenated and emitted as ~/.ssh/known_hosts.
The ~/.ssh/known_hosts contains a list of host name/host key pairs that allow
sshto authenticate hosts you connect to and to detect possible impersonation attacks. By default,sshupdates it in a TOFU, trust-on-first-use fashion, meaning that it records the host’s key in that file the first time you connect to it. This behavior is preserved whenknown-hostsis set to*unspecified*.If you instead provide a list of host keys upfront in the
known-hostsfield, your configuration becomes self-contained and stateless: it can be replicated elsewhere or at another point in time. Preparing this list can be relatively tedious though, which is why*unspecified*is kept as a default.-
authorized-keys(default:'())This must be a list of file-like objects, each of which containing an SSH public key that should be authorized to connect to this machine.
Concretely, these files are concatenated and made available as ~/.ssh/authorized_keys. If an OpenSSH server,
sshd, is running on this machine, then it may take this file into account: this is whatsshddoes by default, but be aware that it can also be configured to ignore it.
- Data Type: openssh-host
Available
openssh-hostfields are:name(type: string)Name of this host declaration.
host-name(type: maybe-string)Host name—e.g.,
"foo.example.org"or"192.168.1.2".address-family(type: address-family)Address family to use when connecting to this host: one of
AF_INET(for IPv4 only),AF_INET6(for IPv6 only), or*unspecified*(allowing any address family).identity-file(type: maybe-string)The identity file to use—e.g.,
"/home/charlie/.ssh/id_ed25519".port(type: maybe-natural-number)TCP port number to connect to.
user(type: maybe-string)User name on the remote host.
forward-x11?(default:#f) (type: boolean)Whether to forward remote client connections to the local X11 graphical display.
forward-x11-trusted?(default:#f) (type: boolean)Whether remote X11 clients have full access to the original X11 graphical display.
forward-agent?(default:#f) (type: boolean)Whether the authentication agent (if any) is forwarded to the remote machine.
compression?(default:#f) (type: boolean)Whether to compress data in transit.
proxy-command(type: maybe-string)The command to use to connect to the server. As an example, a command to connect via an HTTP proxy at 192.0.2.0 would be:
"nc -X connect -x 192.0.2.0:8080 %h %p".host-key-algorithms(type: maybe-string-list)The list of accepted host key algorithms—e.g.,
'("ssh-ed25519").accepted-key-types(type: maybe-string-list)The list of accepted user public key types.
extra-content(default:"") (type: raw-configuration-string)Extra content appended as-is to this
Hostblock in ~/.ssh/config.
Next: Guix Home Services, Previous: Secure Shell, Up: Home Services [Contents][Index]
13.3.7 Desktop Home Services
The (gnu home services desktop) module provides services that you may
find useful on “desktop” systems running a graphical user environment such
as Xorg.
- Scheme Variable: home-redshift-service-type
This is the service type for Redshift, a program that adjusts the display color temperature according to the time of day. Its associated value must be a
home-redshift-configurationrecord, as shown below.A typical configuration, where we manually specify the latitude and longitude, might look like this:
(service home-redshift-service-type (home-redshift-configuration (location-provider 'manual) (latitude 35.81) ;northern hemisphere (longitude -0.80))) ;west of Greenwich
- Data Type: home-redshift-configuration
Available
home-redshift-configurationfields are:redshift(default:redshift) (type: file-like)Redshift package to use.
location-provider(default:geoclue2) (type: symbol)Geolocation provider—
'manualor'geoclue2. In the former case, you must also specify thelatitudeandlongitudefields so Redshift can determine daytime at your place. In the latter case, the Geoclue system service must be running; it will be queried for location information.adjustment-method(default:randr) (type: symbol)Color adjustment method.
daytime-temperature(default:6500) (type: integer)Daytime color temperature (kelvins).
nighttime-temperature(default:4500) (type: integer)Nighttime color temperature (kelvins).
daytime-brightness(type: maybe-inexact-number)Daytime screen brightness, between 0.1 and 1.0, or left unspecified.
nighttime-brightness(type: maybe-inexact-number)Nighttime screen brightness, between 0.1 and 1.0, or left unspecified.
latitude(type: maybe-inexact-number)Latitude, when
location-provideris'manual.longitude(type: maybe-inexact-number)Longitude, when
location-provideris'manual.dawn-time(type: maybe-string)Custom time for the transition from night to day in the morning—
"HH:MM"format. When specified, solar elevation is not used to determine the daytime/nighttime period.dusk-time(type: maybe-string)Likewise, custom time for the transition from day to night in the evening.
extra-content(default:"") (type: raw-configuration-string)Extra content appended as-is to the Redshift configuration file. Run
man redshiftfor more information about the configuration file format.
- Scheme Variable: home-dbus-service-type
This is the service type for running a session-specific D-Bus, for unprivileged applications that require D-Bus to be running.
- Data Type: home-dbus-configuration
The configuration record for
home-dbus-service-type.dbus(default:dbus)The package providing the
/bin/dbus-daemoncommand.
Previous: Desktop Home Services, Up: Home Services [Contents][Index]
13.3.8 Guix Home Services
The (gnu home services guix) module provides services for
user-specific Guix configuration.
- Scheme Variable: home-channels-service-type
This is the service type for managing $XDG_CONFIG_HOME/guix/channels.scm, the file that controls the channels received on
guix pull(see Каналы). Its associated value is a list ofchannelrecords, defined in the(guix channels)module.Generally, it is better to extend this service than to directly configure it, as its default value is the default guix channel(s) defined by
%default-channels. If you configure this service directly, be sure to include a guix channel. See Указание дополнительных каналов and Использование отдельного канала Guix for more details.A typical extension for adding a channel might look like this:
(simple-service 'variant-packages-service home-channels-service-type (list (channel (name 'variant-packages) (url "https://example.org/variant-packages.git"))))
Previous: Home Services, Up: Home Configuration [Contents][Index]
13.4 Invoking guix home
Once you have written a home environment declaration (see Declaring the Home Environment, it can be instantiated using the guix
home command. The synopsis is:
guix home options… action file
file must be the name of a file containing a home-environment
declaration. action specifies how the home environment is
instantiated, but there are few auxiliary actions which don’t instantiate
it. Currently the following values are supported:
searchDisplay available home service type definitions that match the given regular expressions, sorted by relevance:
$ guix home search shell name: home-shell-profile location: gnu/home/services/shells.scm:100:2 extends: home-files description: Create `~/.profile', which is used for environment initialization of POSIX compliant login shells. + This service type can be extended with a list of file-like objects. relevance: 6 name: home-fish location: gnu/home/services/shells.scm:640:2 extends: home-files home-profile description: Install and configure Fish, the friendly interactive shell. relevance: 3 name: home-zsh location: gnu/home/services/shells.scm:290:2 extends: home-files home-profile description: Install and configure Zsh. relevance: 1 name: home-bash location: gnu/home/services/shells.scm:508:2 extends: home-files home-profile description: Install and configure GNU Bash. relevance: 1 …
As for
guix search, the result is written inrecutilsformat, which makes it easy to filter the output (see GNU recutils databases in GNU recutils manual).контейнерSpawn a shell in an isolated environment—a container—containing your home as specified by file.
For example, this is how you would start an interactive shell in a container with your home:
guix home container config.scm
This is a throw-away container where you can lightheartedly fiddle with files; any changes made within the container, any process started—all this disappears as soon as you exit that shell.
As with
guix shell, several options control that container:- --network
- -N
Enable networking within the container (it is disabled by default).
- --expose=source[=target]
- --share=source[=target]
As with
guix shell, make directory source of the host system available as target inside the container—read-only if you pass --expose, and writable if you pass --share (see --expose and --share).
Additionally, you can run a command in that container, instead of spawning an interactive shell. For instance, here is how you would check which Shepherd services are started in a throw-away home container:
guix home container config.scm -- herd status
The command to run in the container must come after
--(double hyphen).editEdit or view the definition of the given Home service types.
For example, the command below opens your editor, as specified by the
EDITORenvironment variable, on the definition of thehome-mcronservice type:guix home edit home-mcron
reconfigureBuild the home environment described in file, and switch to it. Switching means that the activation script will be evaluated and (in basic scenario) symlinks to configuration files generated from
home-environmentdeclaration will be created in ~. If the file with the same path already exists in home folder it will be moved to ~/timestamp-guix-home-legacy-configs-backup, where timestamp is a current UNIX epoch time.Примечание: It is highly recommended to run
guix pullonce before you runguix home reconfigurefor the first time (see Вызовguix pull).This effects all the configuration specified in file. The command starts Shepherd services specified in file that are not currently running; if a service is currently running, this command will arrange for it to be upgraded the next time it is stopped (e.g. by
herd stop serviceorherd restart service).This command creates a new generation whose number is one greater than the current generation (as reported by
guix home list-generations). If that generation already exists, it will be overwritten. This behavior mirrors that ofguix package(see Вызовguix package).Upon completion, the new home is deployed under ~/.guix-home. This directory contains provenance meta-data: the list of channels in use (see Каналы) and file itself, when available. You can view the provenance information by running:
guix home describe
This information is useful should you later want to inspect how this particular generation was built. In fact, assuming file is self-contained, you can later rebuild generation n of your home environment with:
guix time-machine \ -C /var/guix/profiles/per-user/USER/guix-home-n-link/channels.scm -- \ home reconfigure \ /var/guix/profiles/per-user/USER/guix-home-n-link/configuration.scm
You can think of it as some sort of built-in version control! Your home is not just a binary artifact: it carries its own source.
switch-generation¶Switch to an existing home generation. This action atomically switches the home profile to the specified home generation.
The target generation can be specified explicitly by its generation number. For example, the following invocation would switch to home generation 7:
guix home switch-generation 7
Нужное поколение также может быть указано относительно текущего поколения
+Nили-N, где+3означает "на 3 поколения старше текущего", а-1означает "на 1 поколение младше текущего". При задании отрицательного значения-1, перед ним нужно поставить--чтобы не воспринимать его в качестве опции. Например:guix home switch-generation -- -1
Это действие завершится ошибкой, если указанное поколение не существует.
roll-back¶Switch to the preceding home generation. This is the inverse of
reconfigure, and it is exactly the same as invokingswitch-generationwith an argument of-1.delete-generations¶-
Delete home generations, making them candidates for garbage collection (see Вызов
guix gc, for information on how to run the “garbage collector”).This works in the same way as ‘guix package --delete-generations’ (see --delete-generations). With no arguments, all home generations but the current one are deleted:
guix home delete-generations
You can also select the generations you want to delete. The example below deletes all the home generations that are more than two months old:
guix home delete-generations 2m
buildBuild the derivation of the home environment, which includes all the configuration files and programs needed. This action does not actually install anything.
describeDescribe the current home generation: its file name, as well as provenance information when available.
To show installed packages in the current home generation’s profile, the
--list-installedflag is provided, with the same syntax that is used inguix package --list-installed(see Вызовguix package). For instance, the following command shows a table of all the packages with “emacs” in their name that are installed in the current home generation’s profile:guix home describe --list-installed=emacs
list-generationsList a summary of each generation of the home environment available on disk, in a human-readable way. This is similar to the --list-generations option of
guix package(see Вызовguix package).Optionally, one can specify a pattern, with the same syntax that is used in
guix package --list-generations, to restrict the list of generations displayed. For instance, the following command displays generations that are up to 10 days old:guix home list-generations 10d
The
--list-installedflag may also be specified, with the same syntax that is used inguix home describe. This may be helpful if trying to determine when a package was added to the home profile.importGenerate a home environment from the packages in the default profile and configuration files found in the user’s home directory. The configuration files will be copied to the specified directory, and a home-configuration.scm will be populated with the home environment. Note that not every home service that exists is supported (see Home Services).
$ guix home import ~/guix-config guix home: '/home/alice/guix-config' populated with all the Home configuration files
And there’s more! guix home also provides the following
sub-commands to visualize how the services of your home environment relate
to one another:
extension-graphEmit to standard output the service extension graph of the home environment defined in file (see Структура сервисов, for more information on service extensions). By default the output is in Dot/Graphviz format, but you can choose a different format with --graph-backend, as with
guix graph(see --backend):The command:
guix home extension-graph file | xdot -
shows the extension relations among services.
shepherd-graphEmit to standard output the dependency graph of shepherd services of the home environment defined in file. See Сервисы Shepherd, for more information and for an example graph.
Again, the default output format is Dot/Graphviz, but you can pass --graph-backend to select a different one.
options can contain any of the common build options (see Стандартные параметры сборки). In addition, options can contain one of the following:
- --expression=expr
- -e expr
Consider the home-environment expr evaluates to. This is an alternative to specifying a file which evaluates to a home environment.
- --allow-downgrades
Instruct
guix home reconfigureto allow system downgrades.Just like
guix system,guix home reconfigure, by default, prevents you from downgrading your home to older or unrelated revisions compared to the channel revisions that were used to deploy it—those shown byguix home describe. Using --allow-downgrades allows you to bypass that check, at the risk of downgrading your home—be careful!
Next: Platforms, Previous: Home Configuration, Up: GNU Guix [Contents][Index]
14 Документация
In most cases packages installed with Guix come with documentation. There
are two main documentation formats: “Info”, a browsable hypertext format
used for GNU software, and “manual pages” (or “man pages”), the linear
documentation format traditionally found on Unix. Info manuals are accessed
with the info command or with Emacs, and man pages are accessed
using man.
You can look for documentation of software installed on your system by keyword. For example, the following command searches for information about “TLS” in Info manuals:
$ info -k TLS "(emacs)Network Security" -- STARTTLS "(emacs)Network Security" -- TLS "(gnutls)Core TLS API" -- gnutls_certificate_set_verify_flags "(gnutls)Core TLS API" -- gnutls_certificate_set_verify_function …
The command below searches for the same keyword in man pages34:
$ man -k TLS SSL (7) - OpenSSL SSL/TLS library certtool (1) - GnuTLS certificate tool …
These searches are purely local to your computer so you have the guarantee that documentation you find corresponds to what you have actually installed, you can access it off-line, and your privacy is respected.
Once you have these results, you can view the relevant documentation by running, say:
$ info "(gnutls)Core TLS API"
или:
$ man certtool
Info manuals contain sections and indices as well as hyperlinks like those
found in Web pages. The info reader (see Info reader in Stand-alone GNU Info) and its Emacs counterpart (see Misc
Help in The GNU Emacs Manual) provide intuitive key bindings to
navigate manuals. See Getting Started in Info: An Introduction,
for an introduction to Info navigation.
Next: Creating System Images, Previous: Документация, Up: GNU Guix [Contents][Index]
15 Platforms
The packages and systems built by Guix are intended, like most computer
programs, to run on a CPU with a specific instruction set, and under a
specific operating system. Those programs are often also targeting a
specific kernel and system library. Those constraints are captured by Guix
in platform records.
Next: Supported Platforms, Up: Platforms [Contents][Index]
15.1 platform Reference
The platform data type describes a platform: an ISA (instruction set architecture), combined with an operating system and
possibly additional system-wide settings such as the ABI (application binary interface).
- Data Type: platform
This is the data type representing a platform.
targetThis field specifies the platform’s GNU triplet as a string (see GNU configuration triplets in Autoconf).
systemThis string is the system type as it is known to Guix and passed, for instance, to the --system option of most commands.
It usually has the form
"cpu-kernel", where cpu is the target CPU and kernel the target operating system kernel.It can be for instance
"aarch64-linux"or"armhf-linux". You will encounter system types when you perform native builds (see Native Builds).linux-architecture(default:#false)This optional string field is only relevant if the kernel is Linux. In that case, it corresponds to the ARCH variable used when building Linux,
"mips"for instance.glibc-dynamic-linkerThis field is the name of the GNU C Library dynamic linker for the corresponding system, as a string. It can be
"/lib/ld-linux-armhf.so.3".
Previous: platform Reference, Up: Platforms [Contents][Index]
15.2 Supported Platforms
The (guix platforms …) modules export the following variables,
each of which is bound to a platform record.
- Scheme Variable: armv7-linux
Platform targeting ARM v7 CPU running GNU/Linux.
- Scheme Variable: aarch64-linux
Platform targeting ARM v8 CPU running GNU/Linux.
- Scheme Variable: mips64-linux
Platform targeting MIPS little-endian 64-bit CPU running GNU/Linux.
- Scheme Variable: powerpc-linux
Platform targeting PowerPC big-endian 32-bit CPU running GNU/Linux.
- Scheme Variable: powerpc64le-linux
Platform targeting PowerPC little-endian 64-bit CPU running GNU/Linux.
- Scheme Variable: riscv64-linux
Platform targeting RISC-V 64-bit CPU running GNU/Linux.
- Scheme Variable: i686-linux
Platform targeting x86 CPU running GNU/Linux.
- Scheme Variable: x86_64-linux
Platform targeting x86 64-bit CPU running GNU/Linux.
- Scheme Variable: i686-mingw
Platform targeting x86 CPU running Windows, with run-time support from MinGW.
- Scheme Variable: x86_64-mingw
Platform targeting x86 64-bit CPU running Windows, with run-time support from MinGW.
- Scheme Variable: i586-gnu
Platform targeting x86 CPU running GNU/Hurd (also referred to as “GNU”).
Next: Установка файлов отладки, Previous: Platforms, Up: GNU Guix [Contents][Index]
16 Creating System Images
When it comes to installing Guix System for the first time on a new machine,
you can basically proceed in three different ways. The first one is to use
an existing operating system on the machine to run the guix system
init command (see Invoking guix system). The second one, is to produce
an installation image (see Сборка установочного образа). This is a
bootable system which role is to eventually run guix system init.
Finally, the third option would be to produce an image that is a direct
instantiation of the system you wish to run. That image can then be copied
on a bootable device such as an USB drive or a memory card. The target
machine would then directly boot from it, without any kind of installation
procedure.
The guix system image command is able to turn an operating system
definition into a bootable image. This command supports different image
types, such as efi-raw, iso9660 and docker. Any modern
x86_64 machine will probably be able to boot from an iso9660
image. However, there are a few machines out there that require specific
image types. Those machines, in general using ARM processors, may
expect specific partitions at specific offsets.
This chapter explains how to define customized system images and how to turn them into actual bootable images.
Next: Instantiate an Image, Up: Creating System Images [Contents][Index]
16.1 image Reference
The image record, described right after, allows you to define a
customized bootable system image.
- Data Type: image
This is the data type representing a system image.
name(default:#false)The image name as a symbol,
'my-iso9660for instance. The name is optional and it defaults to#false.formatThe image format as a symbol. The following formats are supported:
-
disk-image, a raw disk image composed of one or multiple partitions. -
compressed-qcow2, a compressed qcow2 image composed of one or multiple partitions. -
docker, a Docker image. -
iso9660, an ISO-9660 image. -
tarball, a tar.gz image archive. -
wsl2, a WSL2 image.
-
platform(default:#false)The
platformrecord the image is targeting (see Platforms),aarch64-linuxfor instance. By default, this field is set to#falseand the image will target the host platform.size(default:'guess)The image size in bytes or
'guess. The'guesssymbol, which is the default, means that the image size will be inferred based on the image content.operating-systemThe image’s
operating-systemrecord that is instanciated.partition-table-type(default:'mbr)The image partition table type as a symbol. Possible values are
'mbrand'gpt. It default to'mbr.partitions(default:'())The image partitions as a list of
partitionrecords (seepartitionReference).compression?(default:#true)Whether the image content should be compressed, as a boolean. It defaults to
#trueand only applies to'iso9660image formats.volatile-root?(default:#true)Whether the image root partition should be made volatile, as a boolean.
This is achieved by using a RAM backed file system (overlayfs) that is mounted on top of the root partition by the initrd. It defaults to
#true. When set to#false, the image root partition is mounted as read-write partition by the initrd.shared-store?(default:#false)Whether the image’s store should be shared with the host system, as a boolean. This can be useful when creating images dedicated to virtual machines. When set to
#false, which is the default, the image’soperating-systemclosure is copied to the image. Otherwise, when set to#true, it is assumed that the host store will be made available at boot, using a9pmount for instance.shared-network?(default:#false)Whether to use the host network interfaces within the image, as a boolean. This is only used for the
'dockerimage format. It defaults to#false.substitutable?(default:#true)Whether the image derivation should be substitutable, as a boolean. It defaults to
true.
Up: image Reference [Contents][Index]
16.1.1 partition Reference
In image record may contain some partitions.
- Data Type: partition
This is the data type representing an image partition.
size(default:'guess)The partition size in bytes or
'guess. The'guesssymbol, which is the default, means that the partition size will be inferred based on the partition content.offset(default:0)The partition’s start offset in bytes, relative to the image start or the previous partition end. It defaults to
0which means that there is no offset applied.file-system(default:"ext4")The partition file system as a string, defaulting to
"ext4". The supported values are"vfat","fat16","fat32"and"ext4".file-system-options(default:'())The partition file system creation options that should be passed to the partition creation tool, as a list of strings. This is only supported when creating
"ext4"partitions.See the
"extended-options"man page section of the"mke2fs"tool for a more complete reference.labelThe partition label as a mandatory string,
"my-root"for instance.uuid(default:#false)The partition UUID as an
uuidrecord (see Файловые системы). By default it is#false, which means that the partition creation tool will attribute a random UUID to the partition.flags(default:'())The partition flags as a list of symbols. Possible values are
'bootand'esp. The'bootflags should be set if you want to boot from this partition. Exactly one partition should have this flag set, usually the root one. The'espflag identifies a UEFI System Partition.initializer(default:#false)The partition initializer procedure as a gexp. This procedure is called to populate a partition. If no initializer is passed, the
initialize-root-partitionprocedure from the(gnu build image)module is used.
Next: image-type Reference, Previous: image Reference, Up: Creating System Images [Contents][Index]
16.2 Instantiate an Image
Let’s say you would like to create an MBR image with three distinct partitions:
- The ESP (EFI System Partition), a partition of 40 MiB at offset 1024 KiB with a vfat file system.
- an ext4 partition of 50 MiB data file, and labeled “data”.
- an ext4 bootable partition containing the
%simple-osoperating-system.
You would then write the following image definition in a my-image.scm
file for instance.
(use-modules (gnu) (gnu image) (gnu tests) (gnu system image) (guix gexp)) (define MiB (expt 2 20)) (image (format 'disk-image) (operating-system %simple-os) (partitions (list (partition (size (* 40 MiB)) (offset (* 1024 1024)) (label "GNU-ESP") (file-system "vfat") (flags '(esp)) (initializer (gexp initialize-efi-partition))) (partition (size (* 50 MiB)) (label "DATA") (file-system "ext4") (initializer #~(lambda* (root . rest) (mkdir root) (call-with-output-file (string-append root "/data") (lambda (port) (format port "my-data")))))) (partition (size 'guess) (label root-label) (file-system "ext4") (flags '(boot)) (initializer (gexp initialize-root-partition))))))
Note that the first and third partitions use generic initializers
procedures, initialize-efi-partition and initialize-root-partition
respectively. The initialize-efi-partition installs a GRUB EFI loader that
is loading the GRUB bootloader located in the root partition. The
initialize-root-partition instantiates a complete system as defined by the
%simple-os operating-system.
You can now run:
guix system image my-image.scm
to instantiate the image definition. That produces a disk image
which has the expected structure:
$ parted $(guix system image my-image.scm) print … Model: (file) Disk /gnu/store/yhylv1bp5b2ypb97pd3bbhz6jk5nbhxw-disk-image: 1714MB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 43.0MB 41.9MB primary fat16 esp 2 43.0MB 95.4MB 52.4MB primary ext4 3 95.4MB 1714MB 1619MB primary ext4 boot
The size of the boot partition has been inferred to 1619MB so
that it is large enough to host the %simple-os operating-system.
You can also use existing image record definitions and inherit from
them to simplify the image definition. The (gnu system image)
module provides the following image definition variables.
- Scheme Variable: efi-disk-image
A MBR disk-image composed of two partitions: a 64 bits ESP partition and a ROOT boot partition. This image can be used on most
x86_64andi686machines, supporting BIOS or UEFI booting.
- Scheme Variable: efi32-disk-image
Same as
efi-disk-imagebut with a 32 bits EFI partition.
- Scheme Variable: iso9660-image
An ISO-9660 image composed of a single bootable partition. This image can also be used on most
x86_64andi686machines.
- Scheme Variable: docker-image
A Docker image that can be used to spawn a Docker container.
Using the efi-disk-image we can simplify our previous image
declaration this way:
(use-modules (gnu) (gnu image) (gnu tests) (gnu system image) (guix gexp) (ice-9 match)) (define MiB (expt 2 20)) (define data (partition (size (* 50 MiB)) (label "DATA") (file-system "ext4") (initializer #~(lambda* (root . rest) (mkdir root) (call-with-output-file (string-append root "/data") (lambda (port) (format port "my-data"))))))) (image (inherit efi-disk-image) (operating-system %simple-os) (partitions (match (image-partitions efi-disk-image) ((esp root) (list esp data root)))))
This will give the exact same image instantiation but the
image declaration is simpler.
Next: Image Modules, Previous: Instantiate an Image, Up: Creating System Images [Contents][Index]
16.3 image-type Reference
The guix system image command can, as we saw above, take a file
containing an image declaration as argument and produce an actual
disk image from it. The same command can also handle a file containing an
operating-system declaration as argument. In that case, how is the
operating-system turned into an image?
That’s where the image-type record intervenes. This record defines
how to transform an operating-system record into an image
record.
- Data Type: image-type
This is the data type representing an image-type.
nameThe image-type name as a mandatory symbol,
'efi32-rawfor instance.constructorThe image-type constructor, as a mandatory procedure that takes an
operating-systemrecord as argument and returns animagerecord.
There are several image-type records provided by the (gnu
system image) and the (gnu system images …) modules.
- Scheme Variable: efi-raw-image-type
Build an image based on the
efi-disk-imageimage.
- Scheme Variable: efi32-raw-image-type
Build an image based on the
efi32-disk-imageimage.
- Scheme Variable: qcow2-image-type
Build an image based on the
efi-disk-imageimage but with thecompressed-qcow2image format.
- Scheme Variable: iso-image-type
Build a compressed image based on the
iso9660-imageimage.
- Scheme Variable: uncompressed-iso-image-type
Build an image based on the
iso9660-imageimage but with thecompression?field set to#false.
- Scheme Variable: docker-image-type
Build an image based on the
docker-imageimage.
- Scheme Variable: raw-with-offset-image-type
Build an MBR image with a single partition starting at a
1024KiBoffset. This is useful to leave some room to install a bootloader in the post-MBR gap.
- Scheme Variable: pinebook-pro-image-type
Build an image that is targeting the Pinebook Pro machine. The MBR image contains a single partition starting at a
9MiBoffset. Theu-boot-pinebook-pro-rk3399-bootloaderbootloader will be installed in this gap.
- Scheme Variable: rock64-image-type
Build an image that is targeting the Rock64 machine. The MBR image contains a single partition starting at a
16MiBoffset. Theu-boot-rock64-rk3328-bootloaderbootloader will be installed in this gap.
- Scheme Variable: novena-image-type
Build an image that is targeting the Novena machine. It has the same characteristics as
raw-with-offset-image-type.
- Scheme Variable: pine64-image-type
Build an image that is targeting the Pine64 machine. It has the same characteristics as
raw-with-offset-image-type.
- Scheme Variable: hurd-image-type
Build an image that is targeting a
i386machine running the Hurd kernel. The MBR image contains a single ext2 partitions with specificfile-system-optionsflags.
- Scheme Variable: hurd-qcow2-image-type
Build an image similar to the one built by the
hurd-image-typebut with theformatset to'compressed-qcow2.
- Scheme Variable: wsl2-image-type
Build an image for the WSL2 (Windows Subsystem for Linux 2). It can be imported by running:
wsl --import Guix ./guix ./wsl2-image.tar.gz wsl -d Guix
So, if we get back to the guix system image command taking an
operating-system declaration as argument. By default, the
efi-raw-image-type is used to turn the provided
operating-system into an actual bootable image.
To use a different image-type, the --image-type option can be
used. The --list-image-types option will list all the supported
image types. It turns out to be a textual listing of all the
image-types variables described just above (see Invoking guix system).
Previous: image-type Reference, Up: Creating System Images [Contents][Index]
16.4 Image Modules
Let’s take the example of the Pine64, an ARM based machine. To be able to produce an image targeting this board, we need the following elements:
- An
operating-systemrecord containing at least an appropriate kernel (linux-libre-arm64-generic) and bootloaderu-boot-pine64-lts-bootloader) for the Pine64. - Possibly, an
image-typerecord providing a way to turn anoperating-systemrecord to animagerecord suitable for the Pine64. - An actual
imagethat can be instantiated with theguix system imagecommand.
The (gnu system images pine64) module provides all those elements:
pine64-barebones-os, pine64-image-type and
pine64-barebones-raw-image respectively.
The module returns the pine64-barebones-raw-image in order for users
to be able to run:
guix system image gnu/system/images/pine64.scm
Now, thanks to the pine64-image-type record declaring the
'pine64-raw image-type, one could also prepare a
my-pine.scm file with the following content:
(use-modules (gnu system images pine64)) (operating-system (inherit pine64-barebones-os) (timezone "Europe/Athens"))
to customize the pine64-barebones-os, and run:
$ guix system image --image-type=pine64-raw my-pine.scm
Note that there are other modules in the gnu/system/images directory
targeting Novena, Pine64, PinebookPro and Rock64
machines.
Next: Using TeX and LaTeX, Previous: Creating System Images, Up: GNU Guix [Contents][Index]
17 Установка файлов отладки
Program binaries, as produced by the GCC compilers for instance, are typically written in the ELF format, with a section containing debugging information. Debugging information is what allows the debugger, GDB, to map binary code to source code; it is required to debug a compiled program in good conditions.
This chapter explains how to use separate debug info when packages provide it, and how to rebuild packages with debug info when it’s missing.
Next: Сборка с отладочной информацией, Up: Установка файлов отладки [Contents][Index]
17.1 Отдельная информация об отладке
The problem with debugging information is that is takes up a fair amount of disk space. For example, debugging information for the GNU C Library weighs in at more than 60 MiB. Thus, as a user, keeping all the debugging info of all the installed programs is usually not an option. Yet, space savings should not come at the cost of an impediment to debugging—especially in the GNU system, which should make it easier for users to exert their computing freedom (see Дистрибутив GNU).
Thankfully, the GNU Binary Utilities (Binutils) and GDB provide a mechanism that allows users to get the best of both worlds: debugging information can be stripped from the binaries and stored in separate files. GDB is then able to load debugging information from those files, when they are available (see Separate Debug Files in Debugging with GDB).
The GNU distribution takes advantage of this by storing debugging
information in the lib/debug sub-directory of a separate package
output unimaginatively called debug (see Пакеты со множественным выходом). Users can choose to install the debug output of a package
when they need it. For instance, the following command installs the
debugging information for the GNU C Library and for GNU Guile:
guix install glibc:debug guile:debug
GDB must then be told to look for debug files in the user’s profile, by
setting the debug-file-directory variable (consider setting it from
the ~/.gdbinit file, see Startup in Debugging with GDB):
(gdb) set debug-file-directory ~/.guix-profile/lib/debug
From there on, GDB will pick up debugging information from the .debug files under ~/.guix-profile/lib/debug.
Below is an alternative GDB script which is useful when working with other profiles. It takes advantage of the optional Guile integration in GDB. This snippet is included by default on Guix System in the ~/.gdbinit file.
guile
(use-modules (gdb))
(execute (string-append "set debug-file-directory "
(or (getenv "GDB_DEBUG_FILE_DIRECTORY")
"~/.guix-profile/lib/debug")))
end
In addition, you will most likely want GDB to be able to show the source
code being debugged. To do that, you will have to unpack the source code of
the package of interest (obtained with guix build --source,
see Запуск guix build), and to point GDB to that source directory
using the directory command (see directory in Debugging with GDB).
The debug output mechanism in Guix is implemented by the
gnu-build-system (see Системы сборки). Currently, it is
opt-in—debugging information is available only for the packages with
definitions explicitly declaring a debug output. To check whether a
package has a debug output, use guix package
--list-available (see Вызов guix package).
Read on for how to deal with packages lacking a debug output.
Previous: Отдельная информация об отладке, Up: Установка файлов отладки [Contents][Index]
17.2 Сборка с отладочной информацией
As we saw above, some packages, but not all, provide debugging info in a
debug output. What can you do when debugging info is missing? The
--with-debug-info option provides a solution to that: it allows you
to rebuild the package(s) for which debugging info is missing—and only
those—and to graft those onto the application you’re debugging. Thus,
while it’s not as fast as installing a debug output, it is relatively
inexpensive.
Let’s illustrate that. Suppose you’re experiencing a bug in Inkscape and
would like to see what’s going on in GLib, a library that’s deep down in its
dependency graph. As it turns out, GLib does not have a debug output
and the backtrace GDB shows is all sadness:
(gdb) bt
#0 0x00007ffff5f92190 in g_getenv ()
from /gnu/store/…-glib-2.62.6/lib/libglib-2.0.so.0
#1 0x00007ffff608a7d6 in gobject_init_ctor ()
from /gnu/store/…-glib-2.62.6/lib/libgobject-2.0.so.0
#2 0x00007ffff7fe275a in call_init (l=<optimized out>, argc=argc@entry=1, argv=argv@entry=0x7fffffffcfd8,
env=env@entry=0x7fffffffcfe8) at dl-init.c:72
#3 0x00007ffff7fe2866 in call_init (env=0x7fffffffcfe8, argv=0x7fffffffcfd8, argc=1, l=<optimized out>)
at dl-init.c:118
To address that, you install Inkscape linked against a variant GLib that contains debug info:
guix install inkscape --with-debug-info=glib
This time, debugging will be a whole lot nicer:
$ gdb --args sh -c 'exec inkscape'
…
(gdb) b g_getenv
Function "g_getenv" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (g_getenv) pending.
(gdb) r
Starting program: /gnu/store/…-profile/bin/sh -c exec\ inkscape
…
(gdb) bt
#0 g_getenv (variable=variable@entry=0x7ffff60c7a2e "GOBJECT_DEBUG") at ../glib-2.62.6/glib/genviron.c:252
#1 0x00007ffff608a7d6 in gobject_init () at ../glib-2.62.6/gobject/gtype.c:4380
#2 gobject_init_ctor () at ../glib-2.62.6/gobject/gtype.c:4493
#3 0x00007ffff7fe275a in call_init (l=<optimized out>, argc=argc@entry=3, argv=argv@entry=0x7fffffffd088,
env=env@entry=0x7fffffffd0a8) at dl-init.c:72
…
Much better!
Note that there can be packages for which --with-debug-info will not have the desired effect. See --with-debug-info, for more information.
Next: Обновления безопасности, Previous: Установка файлов отладки, Up: GNU Guix [Contents][Index]
18 Using TeX and LaTeX
Guix provides packages for the TeX, LaTeX, ConTeXt, LuaTeX, and related typesetting systems, taken from the TeX Live distribution. However, because TeX Live is so huge and because finding your way in this maze is tricky, we thought that you, dear user, would welcome guidance on how to deploy the relevant packages so you can compile your TeX and LaTeX documents.
TeX Live currently comes in two flavors in Guix:
- The “monolithic”
texlivepackage: it comes with every single TeX Live package (more than 7,000 of them), but it is huge (more than 4 GiB for a single package!). - The “modular”
texlive-packages: you installtexlive-base, which provides core functionality and the main commands—pdflatex,dvips,luatex,mf, etc.—together with individual packages that provide just the features you need—texlive-listingsfor thelistingspackage,texlive-hyperrefforhyperref,texlive-beamerfor Beamer,texlive-pgffor PGF/TikZ, and so on.
We recommend using the modular package set because it is much less resource-hungry. To build your documents, you would use commands such as:
guix shell texlive-base texlive-wrapfig \ texlive-hyperref texlive-cm-super -- pdflatex doc.tex
You can quickly end up with unreasonably long command lines though. The solution is to instead write a manifest, for example like this one:
(specifications->manifest
'("rubber"
"texlive-base"
"texlive-wrapfig"
"texlive-microtype"
"texlive-listings" "texlive-hyperref"
;; PGF/TikZ
"texlive-pgf"
;; Additional fonts.
"texlive-cm-super" "texlive-amsfonts"
"texlive-times" "texlive-helvetic" "texlive-courier"))
You can then pass it to any command with the -m option:
guix shell -m manifest.scm -- pdflatex doc.tex
See Writing Manifests, for more on manifests. In the future, we plan to
provide packages for TeX Live collections—“meta-packages” such
as fontsrecommended, humanities, or langarabic that
provide the set of packages needed in this particular domain. That will
allow you to list fewer packages.
The main difficulty here is that using the modular package set forces you to
select precisely the packages that you need. You can use guix
search, but finding the right package can prove to be tedious. When a
package is missing, pdflatex and similar commands fail with an
obscure message along the lines of:
doc.tex: File `tikz.sty' not found. doc.tex:7: Emergency stop.
or, for a missing font:
kpathsea: Running mktexmf phvr7t ! I can't find file `phvr7t'.
How do you determine what the missing package is? In the first case, you’ll find the answer by running:
$ guix search texlive tikz name: texlive-pgf version: 59745 …
In the second case, guix search turns up nothing. Instead, you
can search the TeX Live package database using the tlmgr
command:
$ guix shell texlive-base -- tlmgr info phvr7t
tlmgr: cannot find package phvr7t, searching for other matches:
Packages containing `phvr7t' in their title/description:
Packages containing files matching `phvr7t':
helvetic:
texmf-dist/fonts/tfm/adobe/helvetic/phvr7t.tfm
texmf-dist/fonts/tfm/adobe/helvetic/phvr7tn.tfm
texmf-dist/fonts/vf/adobe/helvetic/phvr7t.vf
texmf-dist/fonts/vf/adobe/helvetic/phvr7tn.vf
tex4ht:
texmf-dist/tex4ht/ht-fonts/alias/adobe/helvetic/phvr7t.htf
The file is available in the TeX Live helvetic package, which is
known in Guix as texlive-helvetic. Quite a ride, but we found it!
There is one important limitation though: Guix currently provides a subset
of the TeX Live packages. If you stumble upon a missing package, you can
try and import it (see Вызов guix import):
guix import texlive package
Дополительные опции включаю:
--recursive-rTraverse the dependency graph of the given upstream package recursively and generate package expressions for all those packages that are not yet in Guix.
Примечание: TeX Live packaging is still very much work in progress, but you can help! See Содействие, for more information.
Next: Начальная загрузка, Previous: Using TeX and LaTeX, Up: GNU Guix [Contents][Index]
19 Обновления безопасности
Occasionally, important security vulnerabilities are discovered in software
packages and must be patched. Guix developers try hard to keep track of
known vulnerabilities and to apply fixes as soon as possible in the
master branch of Guix (we do not yet provide a “stable” branch
containing only security updates). The guix lint tool helps
developers find out about vulnerable versions of software packages in the
distribution:
$ guix lint -c cve gnu/packages/base.scm:652:2: glibc@2.21: probably vulnerable to CVE-2015-1781, CVE-2015-7547 gnu/packages/gcc.scm:334:2: gcc@4.9.3: probably vulnerable to CVE-2015-5276 gnu/packages/image.scm:312:2: openjpeg@2.1.0: probably vulnerable to CVE-2016-1923, CVE-2016-1924 …
See Вызов guix lint, для получения дополнительной информации.
Guix follows a functional package management discipline (see Введение), which implies that, when a package is changed, every package that depends on it must be rebuilt. This can significantly slow down the deployment of fixes in core packages such as libc or Bash, since basically the whole distribution would need to be rebuilt. Using pre-built binaries helps (see Подстановки), but deployment may still take more time than desired.
To address this, Guix implements grafts, a mechanism that allows for fast deployment of critical updates without the costs associated with a whole-distribution rebuild. The idea is to rebuild only the package that needs to be patched, and then to “graft” it onto packages explicitly installed by the user and that were previously referring to the original package. The cost of grafting is typically very low, and order of magnitudes lower than a full rebuild of the dependency chain.
For instance, suppose a security update needs to be applied to Bash. Guix
developers will provide a package definition for the “fixed” Bash, say
bash-fixed, in the usual way (see Описание пакетов). Then, the
original package definition is augmented with a replacement field
pointing to the package containing the bug fix:
(define bash
(package
(name "bash")
;; …
(replacement bash-fixed)))
From there on, any package depending directly or indirectly on Bash—as
reported by guix gc --requisites (see Вызов guix gc)—that
is installed is automatically “rewritten” to refer to bash-fixed
instead of bash. This grafting process takes time proportional to
the size of the package, usually less than a minute for an “average”
package on a recent machine. Grafting is recursive: when an indirect
dependency requires grafting, then grafting “propagates” up to the package
that the user is installing.
Currently, the length of the name and version of the graft and that of the
package it replaces (bash-fixed and bash in the example above)
must be equal. This restriction mostly comes from the fact that grafting
works by patching files, including binary files, directly. Other
restrictions may apply: for instance, when adding a graft to a package
providing a shared library, the original shared library and its replacement
must have the same SONAME and be binary-compatible.
The --no-grafts command-line option allows you to forcefully avoid grafting (see --no-grafts). Thus, the command:
guix build bash --no-grafts
returns the store file name of the original Bash, whereas:
guix build bash
returns the store file name of the “fixed”, replacement Bash. This allows you to distinguish between the two variants of Bash.
Чтобы проверить, к какому именно Bash установлен в вашем профилt, вы можете
запустить (see Вызов guix gc):
guix gc -R `readlink -f ~/.guix-profile` | grep bash
… and compare the store file names that you get with those above. Likewise for a complete Guix system generation:
guix gc -R `guix system build my-config.scm` | grep bash
Lastly, to check which Bash running processes are using, you can use the
lsof command:
lsof | grep /gnu/store/.*bash
Next: Портирование на новую платформу, Previous: Обновления безопасности, Up: GNU Guix [Contents][Index]
20 Начальная загрузка
Bootstrapping in our context refers to how the distribution gets built “from nothing”. Remember that the build environment of a derivation contains nothing but its declared inputs (see Введение). So there’s an obvious chicken-and-egg problem: how does the first package get built? How does the first compiler get compiled?
It is tempting to think of this question as one that only die-hard hackers may care about. However, while the answer to that question is technical in nature, its implications are wide-ranging. How the distribution is bootstrapped defines the extent to which we, as individuals and as a collective of users and hackers, can trust the software we run. It is a central concern from the standpoint of security and from a user freedom viewpoint.
The GNU system is primarily made of C code, with libc at its core. The GNU
build system itself assumes the availability of a Bourne shell and
command-line tools provided by GNU Coreutils, Awk, Findutils, ‘sed’, and
‘grep’. Furthermore, build programs—programs that run ./configure,
make, etc.—are written in Guile Scheme (see Деривации).
Consequently, to be able to build anything at all, from scratch, Guix relies
on pre-built binaries of Guile, GCC, Binutils, libc, and the other packages
mentioned above—the bootstrap binaries.
These bootstrap binaries are “taken for granted”, though we can also re-create them if needed (see Подготовка к использованию двоичных файлов первоначальной загрузки).
- The Reduced Binary Seed Bootstrap
- Подготовка к использованию двоичных файлов первоначальной загрузки
- Сборка инструментов сборки
- Сборка двоичных файлов двоичной загрузки
- Сокращение набора Bootstrap Binaries
Next: Подготовка к использованию двоичных файлов первоначальной загрузки, Up: Начальная загрузка [Contents][Index]
20.1 The Reduced Binary Seed Bootstrap
Guix—like other GNU/Linux distributions—is traditionally bootstrapped from a set of bootstrap binaries: Bourne shell, command-line tools provided by GNU Coreutils, Awk, Findutils, ‘sed’, and ‘grep’ and Guile, GCC, Binutils, and the GNU C Library (see Начальная загрузка). Usually, these bootstrap binaries are “taken for granted.”
Taking the bootstrap binaries for granted means that we consider them to be a correct and trustworthy “seed” for building the complete system. Therein lies a problem: the combined size of these bootstrap binaries is about 250MB (see Bootstrappable Builds in GNU Mes). Auditing or even inspecting these is next to impossible.
For i686-linux and x86_64-linux, Guix now features a “Reduced
Binary Seed” bootstrap 35.
The Reduced Binary Seed bootstrap removes the most critical tools—from a
trust perspective—from the bootstrap binaries: GCC, Binutils and the GNU C
Library are replaced by: bootstrap-mescc-tools (a tiny assembler and
linker) and bootstrap-mes (a small Scheme Interpreter and a C
compiler written in Scheme and the Mes C Library, built for TinyCC and for
GCC).
Using these new binary seeds the “missing” Binutils, GCC, and the GNU C Library are built from source. From here on the more traditional bootstrap process resumes. This approach has reduced the bootstrap binaries in size to about 145MB in Guix v1.1.
The next step that Guix has taken is to replace the shell and all its utilities with implementations in Guile Scheme, the Scheme-only bootstrap. Gash (see Gash in The Gash manual) is a POSIX-compatible shell that replaces Bash, and it comes with Gash Utils which has minimalist replacements for Awk, the GNU Core Utilities, Grep, Gzip, Sed, and Tar. The rest of the bootstrap binary seeds that were removed are now built from source.
Building the GNU System from source is currently only possible by adding
some historical GNU packages as intermediate steps36. As Gash and Gash Utils mature, and
GNU packages become more bootstrappable again (e.g., new releases of GNU Sed
will also ship as gzipped tarballs again, as alternative to the hard to
bootstrap xz-compression), this set of added packages can hopefully
be reduced again.
The graph below shows the resulting dependency graph for
gcc-core-mesboot0, the bootstrap compiler used for the traditional
bootstrap of the rest of the Guix System.

The only significant binary bootstrap seeds that remain37 are a Scheme interpreter and a Scheme compiler: GNU Mes and GNU Guile38.
This further reduction has brought down the size of the binary seed to about
60MB for i686-linux and x86_64-linux.
Work is ongoing to remove all binary blobs from our free software bootstrap
stack, working towards a Full Source Bootstrap. Also ongoing is work to
bring these bootstraps to the arm-linux and aarch64-linux
architectures and to the Hurd.
If you are interested, join us on ‘#bootstrappable’ on the Freenode IRC network or discuss on bug-mes@gnu.org or gash-devel@nongnu.org.
Previous: The Reduced Binary Seed Bootstrap, Up: Начальная загрузка [Contents][Index]
20.2 Подготовка к использованию двоичных файлов первоначальной загрузки

The figure above shows the very beginning of the dependency graph of the
distribution, corresponding to the package definitions of the (gnu
packages bootstrap) module. A similar figure can be generated with
guix graph (see Вызов guix graph), along the lines of:
guix graph -t derivation \ -e '(@@ (gnu packages bootstrap) %bootstrap-gcc)' \ | dot -Tps > gcc.ps
or, for the further Reduced Binary Seed bootstrap
guix graph -t derivation \ -e '(@@ (gnu packages bootstrap) %bootstrap-mes)' \ | dot -Tps > mes.ps
At this level of detail, things are slightly complex. First, Guile itself
consists of an ELF executable, along with many source and compiled Scheme
files that are dynamically loaded when it runs. This gets stored in the
guile-2.0.7.tar.xz tarball shown in this graph. This tarball is part
of Guix’s “source” distribution, and gets inserted into the store with
add-to-store (see Хранилище).
But how do we write a derivation that unpacks this tarball and adds it to
the store? To solve this problem, the guile-bootstrap-2.0.drv
derivation—the first one that gets built—uses bash as its
builder, which runs build-bootstrap-guile.sh, which in turn calls
tar to unpack the tarball. Thus, bash, tar, xz,
and mkdir are statically-linked binaries, also part of the Guix
source distribution, whose sole purpose is to allow the Guile tarball to be
unpacked.
Once guile-bootstrap-2.0.drv is built, we have a functioning Guile
that can be used to run subsequent build programs. Its first task is to
download tarballs containing the other pre-built binaries—this is what the
.tar.xz.drv derivations do. Guix modules such as
ftp-client.scm are used for this purpose. The
module-import.drv derivations import those modules in a directory in
the store, using the original layout. The module-import-compiled.drv
derivations compile those modules, and write them in an output directory
with the right layout. This corresponds to the #:modules argument of
build-expression->derivation (see Деривации).
Finally, the various tarballs are unpacked by the derivations
gcc-bootstrap-0.drv, glibc-bootstrap-0.drv, or
bootstrap-mes-0.drv and bootstrap-mescc-tools-0.drv, at which
point we have a working C tool chain.
Сборка инструментов сборки
Bootstrapping is complete when we have a full tool chain that does not
depend on the pre-built bootstrap tools discussed above. This no-dependency
requirement is verified by checking whether the files of the final tool
chain contain references to the /gnu/store directories of the
bootstrap inputs. The process that leads to this “final” tool chain is
described by the package definitions found in the (gnu packages
commencement) module.
The guix graph command allows us to “zoom out” compared to the
graph above, by looking at the level of package objects instead of
individual derivations—remember that a package may translate to several
derivations, typically one derivation to download its source, one to build
the Guile modules it needs, and one to actually build the package from
source. The command:
guix graph -t bag \
-e '(@@ (gnu packages commencement)
glibc-final-with-bootstrap-bash)' | xdot -
displays the dependency graph leading to the “final” C library39, depicted below.

Первый инструмент, который собирается с помощью двоичных файлов начальной
загрузки, - это GNU Make—отмеченный make-boot0 выше—который
является обязательным для всех следующих пакетов. После собираются Findutils
и Diffutils.
Затем идут Binutils и GCC, построенные как псевдо-кросс-инструменты—т.е. с
--target, равным --host. Они используются для сборки
libc. Благодаря этому кросс-сборочному трюку, libc гарантированно не будет
содержать никаких ссылок на начальный набор инструментов.
Оттуда создаются финальные версии Binutils и GCC (не показаны выше). GCC
использует ld из финального Binutils и связывает программы с только
что созданным libc. Эта цепочка инструментов используется для сборки других
пакетов, используемых Guix и система сборки GNU: Guile, Bash, Coreutils и
т.д.
И вуаля! Теперь у нас есть полный набор инструментов сборки, который ожидает
система сборки GNU. Они находятся в переменной %final-input модуля
(gnu packages commencement) и неявно используются любым пакетом,
использующим gnu-build-system (see gnu-build-system).
Сборка двоичных файлов двоичной загрузки
Поскольку окончательный набор инструментов не зависит от двоичных файлов
начальной загрузки, их редко требуется обновлять. Тем не менее, полезно
иметь автоматический способ их создания, если произойдет обновление, и это
то, что обеспечивает модуль (gnu packages make-bootstrap).
Следующая команда создает tar-архивы, содержащие двоичные файлы начальной загрузки (Binutils, GCC, glibc, для традиционной загрузки и linux-libre-headers, bootstrap-mescc-tools, bootstrap-mes для начальной загрузки Reduced Binary Seed, Guile и tarball содержащий смесь Coreutils и других основных инструментов командной строки):
tar архив начальной сборки guix
Сгенерированные тарболы - это те, на которые нужно ссылаться в модуле
(gnu packages bootstrap), упомянутом в начале этого раздела.
Все еще здесь? Тогда, может быть, вы задались вопросом: когда мы достигнем фиксированной точки? Это интересный вопрос! Ответ неизвестен, но если вы хотите продолжить исследование (и располагаете значительными вычислительными ресурсами для этого), сообщите нам.
Сокращение набора Bootstrap Binaries
Our traditional bootstrap includes GCC, GNU Libc, Guile, etc. That’s a lot of binary code! Why is that a problem? It’s a problem because these big chunks of binary code are practically non-auditable, which makes it hard to establish what source code produced them. Every unauditable binary also leaves us vulnerable to compiler backdoors as described by Ken Thompson in the 1984 paper Reflections on Trusting Trust.
This is mitigated by the fact that our bootstrap binaries were generated from an earlier Guix revision. Nevertheless it lacks the level of transparency that we get in the rest of the package dependency graph, where Guix always gives us a source-to-binary mapping. Thus, our goal is to reduce the set of bootstrap binaries to the bare minimum.
The Bootstrappable.org web site lists on-going projects to do that. One of these is about replacing the bootstrap GCC with a sequence of assemblers, interpreters, and compilers of increasing complexity, which could be built from source starting from a simple and auditable assembler.
Our first major achievement is the replacement of of GCC, the GNU C Library and Binutils by MesCC-Tools (a simple hex linker and macro assembler) and Mes (see GNU Mes Reference Manual in GNU Mes, a Scheme interpreter and C compiler in Scheme). Neither MesCC-Tools nor Mes can be fully bootstrapped yet and thus we inject them as binary seeds. We call this the Reduced Binary Seed bootstrap, as it has halved the size of our bootstrap binaries! Also, it has eliminated the C compiler binary; i686-linux and x86_64-linux Guix packages are now bootstrapped without any binary C compiler.
Work is ongoing to make MesCC-Tools and Mes fully bootstrappable and we are also looking at any other bootstrap binaries. Your help is welcome!
Next: Содействие, Previous: Начальная загрузка, Up: GNU Guix [Contents][Index]
21 Портирование на новую платформу
As discussed above, the GNU distribution is self-contained, and
self-containment is achieved by relying on pre-built “bootstrap binaries”
(see Начальная загрузка). These binaries are specific to an operating system
kernel, CPU architecture, and application binary interface (ABI). Thus, to
port the distribution to a platform that is not yet supported, one must
build those bootstrap binaries, and update the (gnu packages
bootstrap) module to use them on that platform.
Fortunately, Guix can cross compile those bootstrap binaries. When everything goes well, and assuming the GNU tool chain supports the target platform, this can be as simple as running a command like this one:
guix build --target=armv5tel-linux-gnueabi bootstrap-tarballs
For this to work, it is first required to register a new platform as defined
in the (guix platform) module. A platform is making the connection
between a GNU triplet (see GNU configuration
triplets in Autoconf), the equivalent system in Nix
notation, the name of the glibc-dynamic-linker, and the corresponding
Linux architecture name if applicable (see Platforms).
Once the bootstrap tarball are built, the (gnu packages bootstrap)
module needs to be updated to refer to these binaries on the target
platform. That is, the hashes and URLs of the bootstrap tarballs for the
new platform must be added alongside those of the currently supported
platforms. The bootstrap Guile tarball is treated specially: it is expected
to be available locally, and gnu/local.mk has rules to download it
for the supported architectures; a rule for the new platform must be added
as well.
In practice, there may be some complications. First, it may be that the
extended GNU triplet that specifies an ABI (like the eabi suffix
above) is not recognized by all the GNU tools. Typically, glibc recognizes
some of these, whereas GCC uses an extra --with-abi configure flag
(see gcc.scm for examples of how to handle this). Second, some of
the required packages could fail to build for that platform. Lastly, the
generated binaries could be broken for some reason.
Next: Благодарности, Previous: Портирование на новую платформу, Up: GNU Guix [Contents][Index]
22 Содействие
Этот проект развивается совместными усилиями. Нам нужна ваша помощь!
Пожалуйста, свяжитесь с нами через guix-devel@gnu.org и
#guix в сети Freenode IRC. Мы приветствуем идеи, принимаем отчёты об
ошибках, патчи и любую помощь проекту. Например, вы можете создавать
описания пакетов (see Принципы опакечивания).
Мы хотим создать теплую, дружелюбную среду, свободную от оскорблений, чтобы каждый мог внести свой вклад в меру своих возможностей. Для этого в нашем проекте используется “Соглашение для авторов”, основанное на https://contributor-covenant.org/. Вы можете найти локальную версию в файле CODE-OF-CONDUCT в исходном репозитории.
Участники не обязаны указывать реальные имена в патчах и в общении онлайн. Они могут пользоваться любым именем или псеводнимом по своему выбору.
- Сборка из Git
- Запуск Guix перед его установкой
- Совершенная установка
- Принципы опакечивания
- Стиль кодирования
- Отправка исправлений
- Отслеживание ошибок и патчей
- Доступ к коммитам
- Обновление пакета Guix
- Writing Documentation
- Тестирование Guix.
Next: Запуск Guix перед его установкой, Up: Содействие [Contents][Index]
22.1 Сборка из Git
Если вы собираетесь хакать сам Guix, рекомендуется использовать последнюю версию из репозитория Git:
git clone https://git.savannah.gnu.org/git/guix.git
Как убедиться, что вы получили подлинную копию репозитория? Для этого
запустите guix git authenticate, передав ему коммит и отпечаток
ключа OpenPGP channel introduction (see Вызов guix package):
git fetch origin keyring:keyring guix git authenticate 9edb3f66fd807b096b48283debdcddccfea34bad \ "BBB0 2DDF 2CEA F6A8 0D1D E643 A2A0 6DF2 A33A 54FA"
Эта команда возвращает нуль в случае успеха; в противном случае будет напечатано сообщение об ошибке и команда завершит работу, вернув ненулевой код.
Как видите, здесь возникает проблема курицы и яйца: сначала вам нужно установить Guix. Обычно вы устанавливаете Guix System (see Установка системы) или Guix поверх другого дистрибутива (see Бинарная установка); в любом случае вы должны проверить подпись OpenPGP на установочном носителе. Это “запускает” (“bootstraps”) цепочку доверия.
Самый простой способ установить развернуть среду разработки для Guix — это, конечно, использовать Guix! Следующая команда запустит новую оболочку во всеми зависимостями и необходимыми переменными окружения:
guix shell -D guix --pure
Подробные сведения об этой команде см. в See Вызов guix shell.
Если вам Guix не удаётся использовать при сборке из чекаута, установите следующие пакеты в дополнение к тем, что были указаны в инструкции по установке (see Требования).
В Guix дополнительные зависимости можно добавить, запустив guix
shell:
guix shell -D guix help2man git strace --pure
From there you can generate the build system infrastructure using Autoconf and Automake:
./bootstrap
If you get an error like this one:
configure.ac:46: error: possibly undefined macro: PKG_CHECK_MODULES
это означает, скорее всего, что Autoconf не смог найти файл pkg.m4, который предоставляется pkg-config. Убедитесь, что файл pkg.m4 доступен. То же относится к guile.m4, набору макросов, предоставляемых Guile. Например, если вы установили Automake в /usr/local, он не будет искать файлы .m4 в /usr/share. Тогда нужно выполнить следующую команду:
export ACLOCAL_PATH=/usr/share/aclocal
см. See Macro Search Path in The GNU Automake Manual, чтобы получить больше информации.
Then, run:
./configure --localstatedir=/var
... where /var is the normal localstatedir value (see Хранилище, for information about this). Note that you will probably not run
make install at the end (you don’t have to) but it’s still
important to pass the right localstatedir.
Finally, you can build Guix and, if you feel so inclined, run the tests (see Запуск набора тестов):
make make check
If anything fails, take a look at installation instructions (see Установка) or send a message to the mailing list.
После этого вы можете аутентифицировать все проверенные коммиты, запустив:
make authenticate
Первый запуск занимает пару минут, но последующие запускаются быстрее.
Или, если ваша конфигурация для локального git репозиотория не соответствует
конфигурации по умолчанию, вы можете укащать ссылку для ветки keyring
с помощью переменной GUIX_GIT_KEYRING. В следующем примере
предполагается, что у ваш git remote с именем ‘myremote’, указывающий
на официальный репозиторий:
make authenticate GUIX_GIT_KEYRING=myremote/keyring
Примечание: Рекомендуется запускать
make authenticateпосле каждого вызоваgit pull. Это гарантирует, что вы продолжаете получать актуальные изменения в репозитории.
After updating the repository, make might fail with an error
similar to the following example:
error: failed to load 'gnu/packages/dunst.scm': ice-9/eval.scm:293:34: In procedure abi-check: #<record-type <origin>>: record ABI mismatch; recompilation needed
This means that one of the record types that Guix defines (in this example,
the origin record) has changed, and all of guix needs to be
recompiled to take that change into account. To do so, run make
clean-go followed by make.
Next: Совершенная установка, Previous: Сборка из Git, Up: Содействие [Contents][Index]
22.2 Запуск Guix перед его установкой
Чтобы держать в порядке рабочее окружение, удобно тестировать изменения, сделанные в вашем локальном дереве исходников, без их установки. Так вы сможете отличить ’наряд’ вашего конечного пользователя от ’пёстрого костюма’.
С этой целью можно использовать все инструменты командной строки, даже если
вы не запускали make install. Для этого вам сначала нужно создать
окружение со всеми доступными зависимостями (see Сборка из Git), и
затем просто начните каждую команду с ./pre-inst-env (скрипт
pre-inst-env находится на верху дерева сборки Guix; он генерируется
запуском ./bootstrap, за которым следует ./configure).
В качестве примера, вот как вы собрали бы пакет hello
(подразумевается, что guix-daemon уже запущена на вашей системе;
ничего страшного, если это другая версия):
$ ./pre-inst-env guix build hello
Аналогично, пример для Guile сессии с использованием модулей Guix:
$ ./pre-inst-env guile -c '(use-modules (guix utils)) (pk (%current-system))'
;;; ("x86_64-linux")
… and for a REPL (see Using Guix Interactively):
$ ./pre-inst-env guile
scheme@(guile-user)> ,use(guix)
scheme@(guile-user)> ,use(gnu)
scheme@(guile-user)> (define snakes
(fold-packages
(lambda (package lst)
(if (string-prefix? "python"
(package-name package))
(cons package lst)
lst))
'()))
scheme@(guile-user)> (length snakes)
$1 = 361
Если вы изучаете демона и его исзодники, или если guix-daemon еще
не запущена в вашей системе, вы можете запустить его прямо из дерева
сборки40:
$ sudo -E ./pre-inst-env guix-daemon --build-users-group=guixbuild
Скрипт pre-inst-env устанавливает все переменные окружения,
которые необходимы для этой задачи, включая PATH и
GUILE_LOAD_PATH.
Заметим, что ./pre-inst-env guix pull не обновляет
локальное дерево исходников. Эта команда только обновляет символическую
ссылку ~/.config/guix/current (see Вызов guix pull). Выполните
git pull, если вы хотите обновить локальное дерево исходников.
Sometimes, especially if you have recently updated your repository, running
./pre-inst-env will print a message similar to the following
example:
;;; note: source file /home/user/projects/guix/guix/progress.scm ;;; newer than compiled /home/user/projects/guix/guix/progress.go
This is only a note and you can safely ignore it. You can get rid of the
message by running make -j4. Until you do, Guile will run
slightly slower because it will interpret the code instead of using prepared
Guile object (.go) files.
You can run make automatically as you work using
watchexec from the watchexec package. For example, to
build again each time you update a package file, run ‘watchexec -w
gnu/packages -- make -j4’.
Next: Принципы опакечивания, Previous: Запуск Guix перед его установкой, Up: Содействие [Contents][Index]
22.3 Совершенная установка
Совершенная установка для программирования Guix — это лучший способ разработки Guix (see Using Guile in Emacs in Guile Reference Manual). Во-первых, здесь нужен мощный текстовый редактор, нужен Emacs, дополненный замечательным Geiser. Чтобы установить это, введите:
guix install emacs guile emacs-geiser emacs-geiser-guile
Geiser добавляет возможности интерактивной пошаговой разработки внутри Emacs: компиляция и запуск кода в буферах, доступ к онлайн-документации (docstrings), контекстные дополнения, M-. для перемещения к определениям объектов, REPL для тестирования кода и многое другое (see Introduction in Geiser User Manual). Для удобной разработки Guix обязательно настройте Guile для загрузки файлов из вашей инстанции:
;; Assuming the Guix checkout is in ~/src/guix. (with-eval-after-load 'geiser-guile (add-to-list 'geiser-guile-load-path "~/src/guix"))
Вообще, для редактирования кода, в Emacs уже есть Scheme mode. Но также обратите внимание на Paredit. Данный пакет предоставляет средства для непосредственной работы с синтаксическим деревом, такие как объявление s-выражений, их упаковка, отклонение следующего s-выражения и т.д.
We also provide templates for common git commit messages and package definitions in the etc/snippets directory. These templates can be used to expand short trigger strings to interactive text snippets. If you use YASnippet, you may want to add the etc/snippets/yas snippets directory to the yas-snippet-dirs variable. If you use Tempel, you may want to add the etc/snippets/tempel/* path to the tempel-path variable in Emacs.
;; Assuming the Guix checkout is in ~/src/guix. ;; Yasnippet configuration (with-eval-after-load 'yasnippet (add-to-list 'yas-snippet-dirs "~/src/guix/etc/snippets/yas")) ;; Tempel configuration (with-eval-after-load 'tempel ;; Ensure tempel-path is a list -- it may also be a string. (unless (listp 'tempel-path) (setq tempel-path (list tempel-path))) (add-to-list 'tempel-path "~/src/guix/etc/snippets/tempel/*"))
Тексты сообщений коммитов зависят от отображения затронутых файлов
Magit. Во время редактирования сообщения коммита
типа add нажмите TAB после его ввода, чтобы вставить шаблон
сообщения коммита добавления пакета; редактируя тип update, нажмите
TAB, чтобы вставить шаблон обновления пакета; тип https -
кнопка TAB вставит шаблон изменения адреса домашней страницы пакета на
HTTPS.
Основной код для scheme-mode вызывается при вводе package... и
кнопки TAB. Этот код также вставляет строку триггера origin...,
который может быть расширен в дальнейшем. Код origin..., в свою
очередь, может вставить строки других триггеров, завершающихся ...,
который также может быть расширен в дальнейшем.
Мы дополнительно обеспечиваем автоматическое обновление информации об авторских правах в etc/copyright.el. Вы можете указать свое полное имя, почту и загрузить файл.
(setq user-full-name "Alice Doe") (setq user-mail-address "alice@mail.org") ;; Assuming the Guix checkout is in ~/src/guix. (load-file "~/src/guix/etc/copyright.el")
Чтобы ввести авторское право в текущей строке, вызовите M-x
guix-copyright.
Для обновления авторских прав необходимо указать
copyright-names-regexp.
(setq copyright-names-regexp
(format "%s <%s>" user-full-name user-mail-address))
Вы можете проверить актуальность своих авторских прав, вызвав M-x
copyright-update. Если вы хотите делать это автоматически после каждого
сохранения в буфер, то добавьте (add-hook 'after-save-hook
'copyright-update) в Emacs.
Next: Стиль кодирования, Previous: Совершенная установка, Up: Содействие [Contents][Index]
22.4 Принципы опакечивания
Дистрибутив GNU - в процессе возникновения и может не содержать ваши любимые пакеты. Этот раздел описывает как можно помочь с развитием дистрибутива.
Пакеты свободного программного обеспечения обычно распространяются в виде архивов исходного кода (файлы tar.gz), которые содержат все исходные файлы. Добавить пакет в дистрибутив означает, по существу, две вещи: добавление рецепта, в котором обозначено, как собирать пакет, включая список других пакетов, необходимых для сборки данного, а также добавление метаданных пакета вместе с рецептом, как например, описание информации о лицензировании.
В Guix вся эта информация включена в определения пакетов. Определения пакетов представляют собой высокоуровневый обзор пакета. Они написаны с использованием синтаксиса языка программирования Scheme. Для каждого пакета задаётся набор переменных, которые составляют определение пакета, и затем это определение пакета экспортируется из модуля (see Пакетные модули). Однако основательные знания Scheme not не обязательны для создания пакетов. Для информации об определении пакетов см. see Описание пакетов.
Когда определение пакета создано, сохранено в файле в дереве исходников
Guix, оно может быть протестировано командой guix build
(see Запуск guix build). Например, допустим, новый пакет называется
gnew, тогда можно запустить эту команду из дерева сборки Guix
(see Запуск Guix перед его установкой):
./pre-inst-env guix build gnew --keep-failed
Использование --keep-failed помогает при отладке ошибок сборки, так
как эта опция предоставляет доступ к дереву неудачных сборок. Другая
полезная опция командной строки при отладке - --log-file, которая
даёт доступ к логу сборки.
Если пакет не известен команде guix, это может означать, что файл
исходника содержит синтаксическую ошибку или не имеет предложения
define-public, которое экспортирует переменную пакета. Чтобы
разобраться, можно загрузить модуль из Guile и получить больше информации о
текущей ошибке:
./pre-inst-env guile -c '(use-modules (gnu packages gnew))'
Если ваш пакет собирается без ошибок, пришлите нам свой патч (see Отправка исправлений). Если вам нужна помощь, мы будем рады помочь вам со своей стороны. После фиксации патча в репозитории Guix новый пакет будет автоматически собран для всех поддерживаемых платформ нашей https://ci.guix.gnu.org CI-системой.
Пользователи могут получать новые доступные определения пакетов простым
запуском guix pull (see Вызов guix pull). Если
ci.guix.gnu.org выполнил сборку пакета, установка пакета
выполнит автоматическое скачивание бинарных файлов оттуда
(see Подстановки). Единственное место, где нужна активность человека, -
обзор и применение патча.
- Свобода программного обеспечения
- Как называть пакеты
- Номера версий
- Краткие обзоры и описания
- Сниппеты против Фаз
- Пакеты Emacs
- Модули Python
- Модули Perl
- Пакеты Java
- Rust Crates пакеты
- Elm Packages
- Шрифты
Next: Как называть пакеты, Up: Принципы опакечивания [Contents][Index]
22.4.1 Свобода программного обеспечения
Операционная система GNU разработана, чтобы пользователи имели свободу при работе за компьютером. GNU — это свободное программное обеспечение, то есть пользователи могут иметь четыре важнейшие свободы: запускать программу, изучать и изменять исходный код программы, распространять самостоятельно точные копии и распространять изменённые версии. Пакеты, включенные в дистрибутив GNU, поставляют только программное обеспечение, которое даёт эти четыре свободы.
Также дистрибутив GNU следует рекомендациям для свободных дистрибутивов. Эти рекомендации, среди прочих указаний, также отклоняют несвободные встроенные программы, рекомендации несвободного программного обеспечения и содержат доводы о том, как взаимодействовать с торговыми марками и патентами.
Но тем не менее, некоторые источники пакетов в оригинале содержат небольшие
необязательные компоненты, которые нарушают указанные рекомендации,
например, это может быть несвободный код. Если это происходит, такие
компоненты удаляются применением соответствующих патчей или сниппетов в
исходный код пакета see Описание пакетов). Так guix build
--source возвращает "восстановленный свободный" исходный код вместо
изначального исходника.
Next: Номера версий, Previous: Свобода программного обеспечения, Up: Принципы опакечивания [Contents][Index]
22.4.2 Как называть пакеты
Пакет, в действительности, имеет два имени, ассоциированных с ним: первое
— это имя переменной Scheme, которая указана в
define-public. Это имя делает пакет доступным в коде Scheme,
например, может использоваться как входные данные другого пакета. Второе —
это строка в поле name в определении пакета. Это имя используется
командами управления пакетами, например, guix package и
guix build.
Оба обычно представляют собой строки в нижнем регистре, содержащие имя
оригинального проекта с дефисами вместо символов нижнего
подчёркивания. Например, GNUnet доступен как gnunet, а SDL_net —
как sdl-net.
Заслуживающим внимания исключением из этого правила является случай, когда
имя проекта состоит только из одного символа, или если уже существует более
старый поддерживаемый проект с таким же именем—независимо от того, был ли
он уже упакован для Guix. Пользуйтесь здравым смыслом, чтобы сделать такие
имена однозначными и значимыми. Например, пакет Guix для оболочки (shell)
под названием “s ”—это s-shell и нет s. Не
стесняйтесь обращаться к своим коллегам-хакерам за вдохновением.
Мы не добавляем приставку lib для пакетов библиотек, несмотря на то,
что это уже часть официального имени пакета. Но для see Модули Python и
Модули Perl есть исключения, касающиеся модулей для языков Python и
Perl.
При именовании пакетов шрифтов имена меняются, see Шрифты.
Next: Краткие обзоры и описания, Previous: Как называть пакеты, Up: Принципы опакечивания [Contents][Index]
22.4.3 Номера версий
Обычно мы опакечиваем только последнюю версию некоторого программного
обеспечения. Но иногда, например, при наличии несовместимых версий
библиотек, нужны две (или более) версии одного пакета. Это требует разных
имён переменных Scheme. Мы используем имя, определённое в Как называть пакеты, для самой последней версии; предыдущие версии используют такое же
имя с добавлением - и номера версии, что позволяет отличить две
версии.
Имя внутри описания пакета остаётся одно для всех версий пакета и не содержит номера версии.
Например, версии GTK+ 2.24.20 и 3.9.12 могут опакечиваться так:
(define-public gtk+ (package (name "gtk+") (version "3.9.12") ...)) (define-public gtk+-2 (package (name "gtk+") (version "2.24.20") ...))
Если нам также нужен GTK+ 3.8.2, он будет размещён в пакете
Порой мы опакечиваем снепшоты исходников из системы контроля версий (СКВ)
вместо официальных релизов. Это остаётся исключением, потому что только
разработчики оригинальных программ решают, что является стабильным
релизом. Иногда это имеет значение. Что же мы должны писать в поле
версия?
Ясно, что нужно сделать отображение идентификатора коммита снепшота СКВ
внутри строки версии, но мы также должны убедиться, что строка "версия"
монотонно увеличивается, так чтобы guix package --upgrade могла
определить, какая версия новее. Так как идентификаторы коммитов, что точно,
Git, не увеличиваются, мы добавляем номер ревизии, которую мы увеличиваем
каждый раз, когда мы обновляем до нового снепшота. Результирующая строка
версии выглядит так:
2.0.11-3.cabba9e ^ ^ ^ | | `-- ID коммита оригинала | | | `--- версия пакета Guix | последняя версия оригинала
It is a good idea to strip commit identifiers in the version field
to, say, 7 digits. It avoids an aesthetic annoyance (assuming aesthetics
have a role to play here) as well as problems related to OS limits such as
the maximum shebang length (127 bytes for the Linux kernel). There are
helper functions for doing this for packages using git-fetch or
hg-fetch (see below). It is best to use the full commit identifiers
in origins, though, to avoid ambiguities. A typical package
definition may look like this:
(define my-package
(let ((commit "c3f29bc928d5900971f65965feaae59e1272a3f7")
(revision "1")) ;Guix package revision
(package
(version (git-version "0.9" revision commit))
(source (origin
(method git-fetch)
(uri (git-reference
(url "git://example.org/my-package.git")
(commit commit)))
(sha256 (base32 "1mbikn…"))
(file-name (git-file-name name version))))
;; …
)))
- Scheme Procedure: git-version VERSION REVISION COMMIT
Return the version string for packages using
git-fetch.(git-version "0.2.3" "0" "93818c936ee7e2f1ba1b315578bde363a7d43d05") ⇒ "0.2.3-0.93818c9"
- Scheme Procedure: hg-version VERSION REVISION CHANGESET
Return the version string for packages using
hg-fetch. It works in the same way asgit-version.
Next: Сниппеты против Фаз, Previous: Номера версий, Up: Принципы опакечивания [Contents][Index]
22.4.4 Краткие обзоры и описания
Как мы видели ранее, каждый пакет в GNU Guix включает краткое описание
и полное описание (see Описание пакетов). Краткие описания и полные
описания важны: по ним производится поиск guix package --search, и
это важная информация, которая помогает пользователям определить, насколько
пакет соответствует их потребностям. Следовательно, пакеты должны отвечать
требованиям, предъявляемым к ним.
Краткие описания должны начинаться с прописной буквы и не должны заканчиваться точкой. Они не должны начинаться с артикля (англ. "a" или "the"), что обычно ничего не значит; например, лучше начать "File-frobbing tool" вместо "A tool that frobs files". Краткое описание должно сообщать о том, что представляет собой пакет, то есть: "Основные утилиты GNU (файлы, текст, оболочка)", - или для чего он используется, то есть краткое описание для GNU grep таково: "Печать строк, содержащих паттерн".
Помните, что краткое описание должно быть понятным для очень широкой аудитории. Например, "Манипулирование выравниванием в формате SAM" может быть понятно продвинутым исследователям в области биоинформатики, но совершенно бесполезно или может ввести в заблужение не специалистов. Хорошая идея — включать в краткое описание идею группы приложений, к которой относится пакет. В данном примере можно предложить такой вариант: "Манипулирование выравниванием нуклеотидных последовательностей", что, в целом, даёт пользователю лучшее представление о том, на что они смотрят.
Описания должны занимать от 5 до 10 строк. Используйте полные предложения, использование аббревиатур возможно при их первичной расшифровке. Пожалуйста, не пишите маркетинговые фразы типа "мировой лидер", "промышленный", "следующего поколения", также избегайте признаки превосходства, как "самый продвинутый" — это не помогает пользователям отыскать пакет, и возможно, звучит сомнительно. Вместо этого рассказывайте о фактах, упоминая особенности и применение.
Descriptions can include Texinfo markup, which is useful to introduce
ornaments such as @code or @dfn, bullet lists, or hyperlinks
(see Overview in GNU Texinfo). However you should be careful
when using some characters for example ‘@’ and curly braces which are
the basic special characters in Texinfo (see Special Characters in GNU Texinfo). User interfaces such as guix show take
care of rendering it appropriately.
Синопсисы и описания перевелены волонтерами at Weblate чтобы как можно больше пользователей могли читать их на своем родном языке. Пользовательские интерфейсы ищут их и отображают на языке, заданном текущей локалью.
Чтобы дать возможность xgettext извлекать их как текст для
перевода, краткие и полные описания должны быть буквенными
строками. Это означает, что нельзя пользоваться string-append или
format при составлении этих строк:
(package
;; …
(synopsis "Эту строку можно переводить")
(description (string-append "Эта строка " "*не поддерживает*" " перевод.")))
Перевод — трудоёмкая работа. Как автор пакета, пожалуйста, уделите внимание краткому и полному описаниям, потому что каждое изменение влечет дополнительную работу для переводчиков. Чтобы помочь им, можно сделать рекомендации или инструкции, вставив специальные комментарии, как этот (see xgettext Invocation in GNU Gettext):
;; TRANSLATORS: "X11 resize-and-rotate" should not be translated. (description "ARandR is designed to provide a simple visual front end for the X11 resize-and-rotate (RandR) extension. …")
Next: Пакеты Emacs, Previous: Краткие обзоры и описания, Up: Принципы опакечивания [Contents][Index]
22.4.5 Сниппеты против Фаз
Граница между использованием сниппета и фазы сборки для изменения исходных
кодов пакета может быть неуловимой. Обычно сниппеты используются для
удаления нежелательных файлов, таких как связанные библиотеки, несвободные
исходники, или для простых замен. Исходник, производный от оригинального
исходника, должен создавать исходник, который можно использовать для сборки
пакета в любой системе, поддерживаемой апстримом пакета. (т.е. действовать
как соответствующий исходник). В частности, сниппеты не должны встраивать
элементы хранилища в источники; такое исправление лучше производить на
этапах сборки. Обратитель к origin документации за дополнительной
информацией (see origin Справка).
Next: Модули Python, Previous: Сниппеты против Фаз, Up: Принципы опакечивания [Contents][Index]
22.4.6 Пакеты Emacs
Emacs пакеты должны предпочтительно использовать систему сборки Emacs
(see emacs-build-system), для единообразия и преимуществ,
предоставляемых этапами сборки, таких как автоматическое создание файла
автозагрузки и байтовая компиляция исходников. Поскольку не существует
стандартизированного способа запуска набора тестов для пакетов Emacs, тесты
по умолчанию отключены. Когда доступен набор тестов, его следует включить,
дав аргументу #:tests? значение #true. По умолчанию команда
для запуска теста—make check, но может быть использована любая
команда , указанная в аргументе #:test-command. Аргумент
#:test-command ожидает, что список, содержащий команду и ее
аргументы, будет вызван во время check фазы.
Elisp зависимости пакетов Emacs обычно предоставляются как
propagated-inputs, если они необходимы во время работы программы.
Что касается других пакетов, зависимости сборки или тестирования должны быть
указаны как native-inputs.
Пакеты Emacs иногда зависят от каталогов с ресурсами, которые должны быть
установлены вместе с файлами Elisp. Аргумент #:include можно
использовать для этой цели, указав список совпадающих регулярных выражений.
Лучшая практика при использовании аргумента #:include заключается в
расширении, а не изменении его значения по умолчанию (доступный через
переменную %default-include variable). Например, пакет расширения
yasnippet обычно включает каталог snippets, который можно скопировать
в каталог установки, используя:
#:include (cons "^snippets/" %default-include)
При возникновении проблем целесообразно проверить наличие заголовка
расширения Package-Requires в основном исходном файле пакета, а также
соответствие перечисленным в нем зависимостям и их версиям.
Next: Модули Perl, Previous: Пакеты Emacs, Up: Принципы опакечивания [Contents][Index]
22.4.7 Модули Python
В настоящее время мы поставляем пакеты Python 2 и Python 3 через переменную
Scheme под именами python-2 и python в соответствии с
Номера версий. Чтобы предотвратить путанницу и конфликты имён других
языков программирования, модули Python содержат слово python.
Некоторые модули совместимы только с одной версией Python, другие - с
обоими. Если пакет Foo работает только с Python 3, мы называем его
python-foo. Если он работает только с Python 2, мы называем его
python2-foo. Если он совместим с обеими версиями, мы создаём два
пакета с соответствующими именами.
Если проект уже содержит слово python, мы отбрасываем его; например,
модуль python-dateutil опакечен под именем python-dateutil и
python2-dateutil. Если имя проекта начинается с py (т.е.
pytz), мы оставляем такое имя и добавляем префикс, как это описано
выше.
Примечание: Currently there are two different build systems for Python packages in Guix: python-build-system and pyproject-build-system. For the longest time, Python packages were built from an informally specified setup.py file. That worked amazingly well, considering Python’s success, but was difficult to build tooling around. As a result, a host of alternative build systems emerged and the community eventually settled on a formal standard for specifying build requirements. pyproject-build-system is Guix’s implementation of this standard. It is considered “experimental” in that it does not yet support all the various PEP-517 build backends, but you are encouraged to try it for new Python packages and report any problems. It will eventually be deprecated and merged into python-build-system.
22.4.7.1 Перечисление зависимостей
Dependency information for Python packages is usually available in the package source tree, with varying degrees of accuracy: in the pyproject.toml file, the setup.py file, in requirements.txt, or in tox.ini (the latter mostly for test dependencies).
Ваша миссия при написании рецепта сборки пакета Python — отобразить эти
зависимости в должном типе "input" (see inputs). Хотя
импортёр pypi обычно отрабатывает хорошо (see Вызов guix import), возможно, вы желаете просмотреть приведённый чек-лист, чтобы
узнать о зависимостях.
- We currently package Python with
setuptoolsandpipinstalled per default. This is about to change, and users are encouraged to usepython-toolchainif they want a build environment for Python.guix lintwill warn ifsetuptoolsorpipare added as native-inputs because they are generally not necessary. - Зависимости Python, необходимые во время работы, идут в
propagated-inputs. Они обычно определены с ключевым словомinstall_requiresв setup.py или в файле requirements.txt. - Python packages required only at build time—e.g., those listed under
build-system.requiresin pyproject.toml or with thesetup_requireskeyword in setup.py—or dependencies only for testing—e.g., those intests_requireor tox.ini—go intonative-inputs. The rationale is that (1) they do not need to be propagated because they are not needed at run time, and (2) in a cross-compilation context, it’s the “native” input that we’d want.Примерами являются фреймворки тестирования
pytest,mockиnose. Конечно, если какой-либо из этих пакетов также необходим во время запуска и работы, его следует указывать вpropagated-inputs. - Всё, что не попало в предыдущие категории, указывается в
inputs, например, программы или библиотеки C, необходимые для сборки пакетов Python, которые используют расширения C. - Если у пакета Python есть необязательные зависимости
(
extras_require), самостоятельно решите, нужно ли их добавлять в зависимости от их полезности или избыточности (seeguix size).
Next: Пакеты Java, Previous: Модули Python, Up: Принципы опакечивания [Contents][Index]
22.4.8 Модули Perl
Программы Perl именуются как и любой другой пакет, используя исходное имя в
нижнем регистре. Для пакетов Perl, содержащих отдельный класс мы используем
имя класса в нижнем регистре, заменяем все вхождения :: на дефисы и
добавляем приставку perl-. Так класс XML::Parser становится
perl-xml-parser. Модули, содержащие несколько классов, сохраняют свои
изначальные имена в нижнем регистре и также имеют префикс
perl-. Подобные модули имеют тенденцию писать слово perl
где-либо в их имени, так что это слово удаляется, так как префикс содержит
это слово. Например, libwww-perl становится perl-libwww.
Next: Rust Crates пакеты, Previous: Модули Perl, Up: Принципы опакечивания [Contents][Index]
22.4.9 Пакеты Java
Программы Java именуются как любой другой пакет, используя исходное им в нижнем регистре.
Чтобы избежать путанницы и конфликтов имён с другими языками
программирования, желательно именовать пакет, поставляющий программу Java, с
префиксом java-. Если проект уже содержит слово java, мы
обрезаем его. Например, пакет ngsjava опакечивается под именем
java-ngs.
Для пакетов Java, содержащих отдельный класс или небольшую ирархию, мы
используем имя в нижнем регистре, заменяя все вхождения . на дефисы,
и указываем префикс java-. Так класс apache.commons.cli
становится пакетом java-apache-commons-cli.
Next: Elm Packages, Previous: Пакеты Java, Up: Принципы опакечивания [Contents][Index]
22.4.10 Rust Crates пакеты
Программы Java именуются как любой другой пакет, используя исходное им в нижнем регистре.
Чтобы предотвратить конфликты пространства имен, мы используем префикс
rust- для всех остальных пакетов Rust. Имя должно быть изменено на
строчные буквы, если необходимо, и тире должны остаться на месте.
В экосистеме rust использование нескольких несовместимых версий пакета в
любой момент времени является нормой, поэтому у всех пакетов должен быть
версионный суффикс. Если пакет прошел версию 1.0.0, тогда достаточно только
основного номера версии (например, rust-clap-2), в противном случае
суффикс версии должен содержать как основную, так и вспомогательную версию
(например, rust-rand-0,6).
Из-за сложности повторного использования rust пакетов в качестве
предварительно скомпилированных входных данных для других пакетов система
сборки Cargo (see cargo-build-system) представляет
#:cargo-input и ключевые слова cargo-development-input в
качестве аргументов для системы сборки. Было бы полезно думать о них как о
propagated-inputs и native-inputs. Rust dependencies и
build-dependencies должны идти в #:cargo-input, а
dev-dependencies должен идти в #:cargo-development-input. Если
пакет Rust ссылается на другие библиотеки, то следует использовать
стандартное размещение в input и т.п.
Следует позаботиться о том, чтобы была использована корректная версия
зависимостей; с этой целью мы стараемся не пропускать тесты или использовать
#:skip-build?, когда это возможно. Конечно, это не всегда возможно,
так как пакет может быть разработан для другой операционной системы,
зависить от новых функций компилятора Rust для разработчиков (Nightly), или
тесты могли устареть с момента выпуска.
Next: Шрифты, Previous: Rust Crates пакеты, Up: Принципы опакечивания [Contents][Index]
22.4.11 Elm Packages
Elm applications can be named like other software: their names need not mention Elm.
Packages in the Elm sense (see elm-build-system under Системы сборки) are required use names of the format
author/project, where both the author and the
project may contain hyphens internally, and the author sometimes
contains uppercase letters.
To form the Guix package name from the upstream name, we follow a convention
similar to Python packages (see Модули Python), adding an elm-
prefix unless the name would already begin with elm-.
In many cases we can reconstruct an Elm package’s upstream name
heuristically, but, since conversion to a Guix-style name involves a loss of
information, this is not always possible. Care should be taken to add the
'upstream-name property when necessary so that ‘guix import elm’
will work correctly (see Вызов guix import). The most notable
scenarios when explicitly specifying the upstream name is necessary are:
- When the author is
elmand the project contains one or more hyphens, as withelm/virtual-dom; and - When the author contains hyphens or uppercase letters, as with
Elm-Canvas/raster-shapes—unless the author iselm-explorations, which is handled as a special case, so packages likeelm-explorations/markdowndo not need to use the'upstream-nameproperty.
The module (guix build-system elm) provides the following utilities
for working with names and related conventions:
- Scheme procedure: elm-package-origin elm-name version hash Returns a Git origin using the repository naming and tagging
regime required for a published Elm package with the upstream name elm-name at version version with sha256 checksum hash.
For example:
(package (name "elm-html") (version "1.0.0") (source (elm-package-origin "elm/html" version (base32 "15k1679ja57vvlpinpv06znmrxy09lbhzfkzdc89i01qa8c4gb4a"))) ...)
- Scheme procedure: elm->package-name elm-name
Returns the Guix-style package name for an Elm package with upstream name elm-name.
Note that there is more than one possible elm-name for which
elm->package-namewill produce a given result.
- Scheme procedure: guix-package->elm-name package
Given an Elm package, returns the possibly-inferred upstream name, or
#fthe upstream name is not specified via the'upstream-nameproperty and can not be inferred byinfer-elm-package-name.
- Scheme procedure: infer-elm-package-name guix-name
Given the guix-name of an Elm package, returns the inferred upstream name, or
#fif the upstream name can’t be inferred. If the result is not#f, supplying it toelm->package-namewould produce guix-name.
Previous: Elm Packages, Up: Принципы опакечивания [Contents][Index]
22.4.12 Шрифты
Для шрифтов, которые не установлены пользователем, исходя из настроек печати, или рааспространяемые как часть большого пакета программного обеспечения, мы применяем обычные правила опакечивания программного обеспечения. Например, это относится к шрифтам, поставляемым как часть системы X.Org, или шрифтов TeX Live.
Чтобы облегчить пользовательский поиск шрифтов, имена пакетов, содержащих только шрифты, создаются следующим образом, независимо от изначального имени пакета.
Имя пакета, содержащего только одно семейство шрифтов, начинается с
font-; далее идёт литейное имя и дефис -, если литейное имя
известно, а затем - имя семейства шрифтов, в котором пробелы заменяются
дефисами (и обычно все буквы в верхнем регистре заменяются на нижний
регистр). Например, семейство шрифтов Gentium от SIL опакечивается под
именем font-sil-gentium.
Пакет с несколькими семействами шрифтов имеет в названии имя коллекции
вместо имени семейства. Например, шрифты Liberation состоят из трёх
семейств: Liberation Sans, Liberation Serfif и Liberation Mono. Они могли бы
опакечиваться отдельно под именами font-liberation-sans и так далее,
но так как они распространяются вместе под общим именем, мы предпочитаем
опакечивать их вместе как font-liberation.
В случае, когда несколько форматов одного семейства щрифтов или коллекции
шрифтов опакечена отдельно, в имени присутствует небольшая отметка о формате
с предваряющим дефисом. Мы используем -ttf для шрифтов TrueType,
-otf - для шрифтов OpenType - и -type1 - для шрифтов
PostScript Type 1.
Next: Отправка исправлений, Previous: Принципы опакечивания, Up: Содействие [Contents][Index]
22.5 Стиль кодирования
В основном наш код следует стандартам кодирования GNU (see GNU Coding Standards). Но они не имеют исчерпывающих указаний для Scheme, так что есть дополнительные правила.
Next: Модули, Up: Стиль кодирования [Contents][Index]
22.5.1 Парадигма программирования
Код Scheme в Guix написан в чисто функциональном стиле. Одно исключение -
это код, который вызывает ввод/вывод и процедуры, которые реализуют
низкоровневые операции, как например, процедура memoize.
Next: Типы данных и поиск образцов, Previous: Парадигма программирования, Up: Стиль кодирования [Contents][Index]
22.5.2 Модули
Модули Guile, которые вызываются для сборки, должны жить в пространстве имён
(guix build …). Они не должны ссылаться на другие модули Guix
или GNU. Однако это нормально, если модуль типа "host-side" использует
модуль типа build-side.
Модули, которые работают во всей системе GNU, должны быть в пространстве
имён (gnu …), но не (guix …).
Next: Форматирование кода, Previous: Модули, Up: Стиль кодирования [Contents][Index]
22.5.3 Типы данных и поиск образцов
Правило классического Lisp - использование списков для представления всего и
просмотр списков "вручную", используя car, cdr, cadr и
тому подобное. Возникают некоторые проблемы этого стиля, например, это
тяжело читается, провоцирует ошибки, и создаёт отчёты об ошибках без должной
детализации.
Guix code should define appropriate data types (for instance, using
define-record-type*) rather than abuse lists. In addition, it should
use pattern matching, via Guile’s (ice-9 match) module, especially
when matching lists (see Pattern Matching in GNU Guile Reference
Manual); pattern matching for records is better done using
match-record from (guix records), which, unlike match,
verifies field names at macro-expansion time.
Previous: Типы данных и поиск образцов, Up: Стиль кодирования [Contents][Index]
22.5.4 Форматирование кода
При написании кода Scheme мы пользуемся мудростью программистов Scheme. В основном мы следуем Riastradh’s Lisp Style Rules. Этот документ, к счастью, содержит большинство соглашений, которые применимы также для кода Guile. Это очень вдумчиая работа, пожалуйста, прочтите её.
Некоторые специальные формы, вводимые в Guix, как например, макрос
substitute*, имеют специальные правила отступов. Они определены в
файле .dir-locals.el, которые использует Emacs автоматически. Также
отметим, что Emacs-Guix предоставляет режим guix-devel-mode, который
вставляет отступы и подсвечивает код Guix должным образом
(see Development in The Emacs-Guix Reference Manual).
Если вы не пользуетесь Emacs, пожалуйста убедитесь, что ваш редактор знает эти правила. Для автоматической расстановки отступов можно запустить:
./pre-inst-env guix style package
See Invoking guix style, for more information.
Если вы редактируете код в Vim, мы рекомендуем запустить :set
autoindent, так отступы будут автоматически вставляться в ваш код, пока вы
печатаете. В дополнение вам может помочь для работы со всеми этими скобками
paredit.vim.
Мы требуем, чтобы все высокоуровневые процедуры содержали строки
документации. Хотя это требование может не учитываться для простых приватных
процедур в пространстве имён (guix build …).
Процедуры должны иметь не более четырёх параметров. Передавайте параметры по ключевым словам в процедурах, которые принимают более четырёх параметров.
Next: Отслеживание ошибок и патчей, Previous: Стиль кодирования, Up: Содействие [Contents][Index]
22.6 Отправка исправлений
Development is done using the Git distributed version control system. Thus,
access to the repository is not strictly necessary. We welcome
contributions in the form of patches as produced by git format-patch
sent to the guix-patches@gnu.org mailing list (see Submitting
patches to a project in Git User Manual). Contributors are encouraged
to take a moment to set some Git repository options (see Конфигурирование Git) first, which can improve the readability of patches. Seasoned Guix
developers may also want to look at the section on commit access
(see Доступ к коммитам).
This mailing list is backed by a Debbugs instance, which allows us to keep
track of submissions (see Отслеживание ошибок и патчей). Each message sent
to that mailing list gets a new tracking number assigned; people can then
follow up on the submission by sending email to
ISSUE_NUMBER@debbugs.gnu.org, where ISSUE_NUMBER is the
tracking number (see Отправка пакета исправлений).
Пожалуйста, пишите логи коммита в формате ChangeLog (see Change Logs in GNU Coding Standards); можно просмотреть историю коммитов, например.
Перед отправкой патча, который добавляет или изменяет описание пакета, пожалуйста, выполните следующие проверки:
- Если авторы пакета программного обеспечения преоставляют криптографическую
подпись для архива релиза, выполните проверку аутентичности архива. Для
отдельного файла GPG-подписи это можно сделать командой
gpg --verify. - Потратьте немного времени, чтобы предоставить адекватное краткое описание и полное описание пакета. Смотрите See Краткие обзоры и описания для подробностей.
- Запустите
guix lint package, где package - это имя нового изменённого пакета, и устраните любые ошибки из отчёта (see Вызовguix lint). - Run
guix style packageto format the new package definition according to the project’s conventions (see Invokingguix style). - Убедитесь, что пакет собирается на вашей платформе, используя
guix build package. - We recommend you also try building the package on other supported
platforms. As you may not have access to actual hardware platforms, we
recommend using the
qemu-binfmt-service-typeto emulate them. In order to enable it, add thevirtualizationservice module and the following service to the list of services in youroperating-systemconfiguration:(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm" "aarch64"))))И тогда запустите переконфигурирование системы.
Также можно собирать пакеты под различные платформы, обозначив опцию
--system. Например, чтобы собрать пакет "hello" для архитектур armhf, aarch64, или mips64 вы должны выполнить соответственно следующее:"guix build --system=armhf-linux --rounds=2 hello "guix build --system=aarch64-linux --rounds=2 hello
-
Убедитесь, что пакет не использует связанные копии программ, которые уже
доступны как отдельные пакеты.
Иногда пакеты включают копии исходных кодов своих зависимостей, исходя из удобства для пользователей. Однако как дистрибутив, мы должны убедиться, что подобные пакеты ставятся, используя копию, которую мы уже имеем в дистрибутиве, если таковая имеется. Это улучшает использование ресурсов (зависимость собирается и сохраняется один раз) и позволяет дистрибутиву производить поперечные изменения, как например, применение обновлений безопасности для поставляемого пакета программного обеспечения в одном месте, и эти изменения будут иметь силу во всей системе, устраняя проблему лишних копий.
- Просмотрите отчеты
guix size(see Вызовguix size). Это позволит найти связь с другими пакетами, сохранившуюся без необходимости. Это также позволяет решить, как разделить пакет (see Пакеты со множественным выходом) и какие должны использоваться опциональные зависимости. В частности, это способ избежать использование большогоtexliveкак зависимости и использоватьtexlive-tinyилиtexlive-unionвместо него. - For important changes, check that dependent packages (if applicable) are not
affected by the change;
guix refresh --list-dependent packagewill help you do that (see Вызовguix refresh).В зависимости от числа пакетов зависимостей и, как следствие, числа вызываемых пересборок, коммиты отправляются в разные бренчи следующим образом:
- 300 пакетов зависимостей или менее
бренч
master(не разрушающие изменения).- от 300 до 1200 пакетов зависимостей
бренч
staging(не разрушающие изменения). Этот бренч предназначен для включения вmasterкаждые 3 недели (примерно). Тематические изменения (т.е. обновление стека GNOME) могут отправляться в специальный бренч, скажем,gnome-updates.- более 1200 пакетов зависимостей
бренч
core-updates(может включать главные и потенциально разрушительные изменения). Этот бренч предназначен для включения вmasterкаждые 2,5 месяца примерно.
All these branches are tracked by our build farm and merged into
masteronce everything has been successfully built. This allows us to fix issues before they hit users, and to reduce the window during which pre-built binaries are not available.Когда мы решим начать сборку веток
stagingилиcore-updates, они будут форкнуты (forked) и переименованы с суффиксом-frozen, после чего замороженные ветки будут получать только исправления ошибок. Веткиcore-updatesиstagingостануться открыты для патчей в следующем цикле. Если вы не знаете, где разместить патч, спросите в списке рассылки или в IRC. -
Проверьте, является ли процесс сборки пакета детеминистическим. Это обычно
означает необходимость проверки того, что независимая сборка пакета
производит точно такой же результат, которым вы располагаете, бит к биту.
Простой способ выполнить это - собрать такой же пакет несколько раз подряд на вашей машине (see Запуск
guix build):guix build --rounds=2 my-package
Этого достаточно, чтобы отловить привычный набор проблем, нарушающих детерминизм, как например, отпечаток времени или случайно генерируемый выход на результате сборке.
Другой способ — использовать
guix challenge(see Вызовguix challenge). Можно запустить это один раз, когда коммит пакета был отправлен, и собрать с помощьюci.guix.gnu.org, чтобы проверить, что это даёт результат такой же, как у вас. Ещё лучше найти другую машину, на которой можно собрать это и выполнитьguix publish. Так как другая удалённая машина дл сборки отличается от вашей, это может выявить проблемы, нарушающие детерминизм, связанные с аппаратным обеспечением, то есть вызванные использованием различных расширений ассемблера или другого ядра операционной системы, то есть касательно файловunameили /proc. - При написании документации, пожалуйста, используйте нейтральную по гендеру лексику, когда речь идёт о людях, как например, тут singular "they", "their", "them" и т.д.
- Проверьте, что ваш патч содержит изменения, связанные только с одной
темой. Связывая вместе изменения, касающиеся различных тем, делает обзор
сложным и медленным.
Примеры несвязанных изменений включают, в том числе, добавление некоторых пакетов или обновление пакета вместе с исправлениями в этом пакете.
- Please follow our code formatting rules, possibly running
guix stylescript to do that automatically for you (see Форматирование кода). - Если это возможно, используйте зеркала при указании URL исходников
(see Вызов
guix download). Используйте надёжные URL’ы, а не сгенерированные. Например, архивы GitHub не являются идентичными между поколениями, так что в этом случае часто лучше клонировать репозиторий. Не используйте полеnameв URL, это не очень удобно: если имя изменится, тогда URL будет неправильным. - Проверьте, собирается ли Guix (see Сборка из Git), и устраните предупреждения, особенно те, которые касаются использования неопределенных символов.
- Убедитесь, что ваши изменения не ломают Guix и имитируйте
guix pullвместе с:guix pull --url=/path/to/your/checkout --profile=/tmp/guix.master
When posting a patch to the mailing list, use ‘[PATCH] …’ as a
subject, if your patch is to be applied on a branch other than
master, say core-updates, specify it in the subject like
‘[PATCH core-updates] …’.
You may use your email client or the git send-email command
(see Отправка пакета исправлений). We prefer to get patches in plain text
messages, either inline or as MIME attachments. You are advised to pay
attention if your email client changes anything like line breaks or
indentation which could potentially break the patches.
Когда отправите свой самый первый патч на guix-patches@gnu.org, ожидайте некоторой задержки. Вам нужно подождать, пока вы не получите подтверждение с присвоенным номером отслеживания. Дальнейшие подтверждения не следует откладывать.
When a bug is resolved, please close the thread by sending an email to ISSUE_NUMBER-done@debbugs.gnu.org.
Next: Отправка пакета исправлений, Up: Отправка исправлений [Contents][Index]
22.6.1 Конфигурирование Git
If you have not done so already, you may wish to set a name and email that
will be associated with your commits (see Telling Git your name in Git User Manual). If you wish to use a
different name or email just for commits in this repository, you can use
git config --local, or edit .git/config in the repository
instead of ~/.gitconfig.
We provide some default settings in etc/git/gitconfig which modify how patches are generated, making them easier to read and apply. These settings can be applied by manually copying them to .git/config in your checkout, or by telling Git to include the whole file:
git config --local include.path ../etc/git/gitconfig
From then on, any changes to etc/git/gitconfig would automatically take effect.
Since the first patch in a series must be sent separately (see Отправка пакета исправлений), it can also be helpful to tell git format-patch to
handle the e-mail threading instead of git send-email:
git config --local format.thread shallow git config --local sendemail.thread no
Next: Teams, Previous: Конфигурирование Git, Up: Отправка исправлений [Contents][Index]
22.6.2 Отправка пакета исправлений
Single Patches
The git send-email command is the best way to send both single
patches and patch series (see Multiple Patches) to the Guix mailing
list. Sending patches as email attachments may make them difficult to
review in some mail clients, and git diff does not store commit
metadata.
Примечание: The
git send-emailcommand is provided by thesend-emailoutput of thegitpackage, i.e.git:send-email.
The following command will create a patch email from the latest commit, open it in your EDITOR or VISUAL for editing, and send it to the Guix mailing list to be reviewed and merged:
$ git send-email -1 -a --base=auto --to=guix-patches@gnu.org
Tip: To add a prefix to the subject of your patch, you may use the --subject-prefix option. The Guix project uses this to specify that the patch is intended for a branch or repository other than the
masterbranch of https://git.savannah.gnu.org/cgit/guix.git.git send-email -1 -a --base=auto \ --subject-prefix='PATCH core-updates' \ --to=guix-patches@gnu.org
The patch email contains a three-dash separator line after the commit message. You may “annotate” the patch with explanatory text by adding it under this line. If you do not wish to annotate the email, you may drop the -a flag (which is short for --annotate).
The --base=auto flag automatically adds a note at the bottom of the patch of the commit it was based on, making it easier for maintainers to rebase and merge your patch.
If you need to send a revised patch, don’t resend it like this or send a
“fix” patch to be applied on top of the last one; instead, use
git commit -a or git rebase
to modify the commit, and use the
ISSUE_NUMBER@debbugs.gnu.org address and the -v flag
with git send-email.
$ git commit -a
$ git send-email -1 -a --base=auto -v REVISION \
--to=ISSUE_NUMBER@debbugs.gnu.org
You can find out ISSUE_NUMBER either by searching on the mumi interface at issues.guix.gnu.org for the name of your patch or reading the acknowledgement email sent automatically by Debbugs in reply to incoming bugs and patches, which contains the bug number.
Notifying Teams
The etc/teams.scm script may be used to notify all those who may be
interested in your patch of its existence (see Teams). Use
etc/teams.scm list-teams to display all the teams, decide which
team(s) your patch relates to, and use etc/teams.scm cc to output
various git send-email flags which will notify the appropriate
team members, or use etc/teams.scm cc-members to detect the
appropriate teams automatically.
Multiple Patches
While git send-email alone will suffice for a single patch, an
unfortunate flaw in Debbugs means you need to be more careful when sending
multiple patches: if you send them all to the guix-patches@gnu.org
address, a new issue will be created for each patch!
When sending a series of patches, it’s best to send a Git “cover letter”
first, to give reviewers an overview of the patch series. We can create a
directory called outgoing containing both our patch series and a
cover letter called 0000-cover-letter.patch with git
format-patch.
$ git format-patch -NUMBER_COMMITS -o outgoing \
--cover-letter --base=auto
We can now send just the cover letter to the guix-patches@gnu.org address, which will create an issue that we can send the rest of the patches to.
$ git send-email outgoing/0000-cover-letter.patch -a \
--to=guix-patches@gnu.org \
$(etc/teams.scm cc-members ...)
$ rm outgoing/0000-cover-letter.patch # we don't want to resend it!
Ensure you edit the email to add an appropriate subject line and blurb before sending it. Note the automatically generated shortlog and diffstat below the blurb.
Once the Debbugs mailer has replied to your cover letter email, you can send the actual patches to the newly-created issue address.
$ git send-email outgoing/*.patch \
--to=ISSUE_NUMBER@debbugs.gnu.org \
$(etc/teams.scm cc-members ...)
$ rm -rf outgoing # we don't need these anymore
Thankfully, this git format-patch dance is not necessary to send
an amended patch series, since an issue already exists for the patchset.
$ git send-email -NUMBER_COMMITS \
-vREVISION --base=auto \
--to ISSUE_NUMBER@debbugs.gnu.org
If need be, you may use --cover-letter -a to send another cover letter, e.g. for explaining what’s changed since the last revision, and these changes are necessary.
Previous: Отправка пакета исправлений, Up: Отправка исправлений [Contents][Index]
22.6.3 Teams
There are several teams mentoring different parts of the Guix source code. To list all those teams, you can run from a Guix checkout:
$ ./etc/teams.scm list-teams id: mentors name: Mentors description: A group of mentors who chaperone contributions by newcomers. members: + Christopher Baines <mail@cbaines.net> + Ricardo Wurmus <rekado@elephly.net> + Mathieu Othacehe <othacehe@gnu.org> + jgart <jgart@dismail.de> + Ludovic Courtès <ludo@gnu.org> …
You can run the following command to have the Mentors team put in CC
of a patch series:
$ git send-email --to ISSUE_NUMBER@debbugs.gnu.org $(./etc/teams.scm cc mentors) *.patch
The appropriate team or teams can also be inferred from the modified files. For instance, if you want to send the two latest commits of the current Git repository to review, you can run:
$ guix shell -D guix [env]$ git send-email --to ISSUE_NUMBER@debbugs.gnu.org $(./etc/teams.scm cc-members HEAD~2 HEAD) *.patch
Next: Доступ к коммитам, Previous: Отправка исправлений, Up: Содействие [Contents][Index]
22.7 Отслеживание ошибок и патчей
This section describes how the Guix project tracks its bug reports and patch submissions.
Next: Debbugs User Interfaces, Up: Отслеживание ошибок и патчей [Contents][Index]
22.7.1 The Issue Tracker
Отчёты об ошибках и предложенные исправления сейчас отслеживаются с помощью
Debbugs на веб-сайте https://bugs.gnu.org. Отчёты об ошибках,
относящиеся к пакету guix (на языке Debbugs), отправляйте по адресу
bug-guix@gnu.org, а предлагаемые исправления для пакета
guix-patches — по адресу guix-patches@gnu.org
(see Отправка исправлений).
Next: Debbugs Usertags, Previous: The Issue Tracker, Up: Отслеживание ошибок и патчей [Contents][Index]
22.7.2 Debbugs User Interfaces
Для просмотра вопросов доступен веб-интерфейс (на самом деле даже два веб-интерфейса):
- https://issues.guix.gnu.org предоставляет приятный интерфейс41 чтобы просматривать отчеты об ошибках и исправлениях, а также участвовать в обсуждениях;
- GNU libgcrypt списки отчётов об ошибках;
- https://bugs.gnu.org/guix-patches списки патчей на рассмотрении.
Чтобы просмотреть обсуждения, связанные с номером проблемы n,
перейдите на ‘https://issues.guix.gnu.org/n’ или
‘https://bugs.gnu.org/n’.
Если вы используете Emacs, вам может быть удобнее взаимодействовать с проблемами при помощи debbugs.el, который вы можете установить с помощью:
guix install emacs-debbugs
Например, чтбы уввидеть все открытые заявки на guix-patches, введите:
C-u M-x debbugs-gnu RET RET guix-patches RET n y
See Debbugs User Guide для подробной информации об этом полезном инструменте!
Previous: Debbugs User Interfaces, Up: Отслеживание ошибок и патчей [Contents][Index]
22.7.3 Debbugs Usertags
Debbugs provides a feature called usertags that allows any user to tag any bug with an arbitrary label. Bugs can be searched by usertag, so this is a handy way to organize bugs42.
For example, to view all the bug reports (or patches, in the case of
guix-patches) tagged with the usertag powerpc64le-linux for
the user guix, open a URL like the following in a web browser:
https://debbugs.gnu.org/cgi-bin/pkgreport.cgi?tag=powerpc64le-linux;users=guix.
For more information on how to use usertags, please refer to the documentation for Debbugs or the documentation for whatever tool you use to interact with Debbugs.
In Guix, we are experimenting with usertags to keep track of
architecture-specific issues. To facilitate collaboration, all our usertags
are associated with the single user guix. The following usertags
currently exist for that user:
aarch64-linuxThe purpose of this usertag is to make it easy to find the issues that matter most for the
powerpc64le-linuxsystem type. Please assign this usertag to bugs or patches that affectpowerpc64le-linuxbut not other system types. In addition, you may use it to identify issues that for some reason are particularly important for thepowerpc64le-linuxsystem type, even if the issue affects other system types, too.воспроизводимостьFor issues related to reproducibility. For example, it would be appropriate to assign this usertag to a bug report for a package that fails to build reproducibly.
If you’re a committer and you want to add a usertag, just start using it
with the guix user. If the usertag proves useful to you, consider
updating this section of the manual so that others will know what your
usertag means.
Next: Обновление пакета Guix, Previous: Отслеживание ошибок и патчей, Up: Содействие [Contents][Index]
22.8 Доступ к коммитам
Everyone can contribute to Guix without having commit access (see Отправка исправлений). However, for frequent contributors, having write access to the repository can be convenient. As a rule of thumb, a contributor should have accumulated fifty (50) reviewed commits to be considered as a committer and have sustained their activity in the project for at least 6 months. This ensures enough interactions with the contributor, which is essential for mentoring and assessing whether they are ready to become a committer. Commit access should not be thought of as a “badge of honor” but rather as a responsibility a contributor is willing to take to help the project.
The following sections explain how to get commit access, how to be ready to push commits, and the policies and community expectations for commits pushed upstream.
22.8.1 Applying for Commit Access
When you deem it necessary, consider applying for commit access by following these steps:
- Найдите трех коммиттеров, которые поручаются за вас. Вы можете просмотреть
список коммиттеров по адресу
https://savannah.gnu.org/project/memberlist.php?group=guix. Каждый из
них должен отправить заявление по электронной почте на адрес
guix-maintainers@gnu.org (личный псевдоним коллектива
сопровождающих), подписанный ключом OpenPGP.
Ожидается, что коммиттеры взаимодействовали с вами как c участником и могли судить, достаточно ли вы знакомы с проектом. Это не суждение о ценности вашей работы, поэтому отказ следует скорее интерпретировать как «давайте попробуем позже».
- Отправьте guix-keepers@gnu.org сообщение с указанием ваших
намерений, перечисляя трех коммиттеров, поддерживающих вашу заявку,
подписанных ключом OpenPGP, который вы будете использовать для подписания
коммитов, и указав свой отпечаток (смотри ниже). Ознакомся с
https://emailselfdefense.fsf.org/ru/, чтобы познакомиться с
криптографией с открытым ключом с помощью GnuPG.
Настройте GnuPG так, чтобы он никогда не использовал хэш-алгоритм SHA1 для цифровых подписей, который, как известно, небезопасен с 2019 года. Например, добавив следующую строку в ~/.gnupg/gpg.conf (see GPG Esoteric Options in The GNU Privacy Guard Manual):
digest-algo sha512
- Маинтайнеры решают, предоставлять ли вам доступ к коммитам, обычно следуя рекомендациям ваших рефералов.
-
Получив доступ, пожалуйста, отправьте сообщение на адрес
guix-devel@gnu.org, чтобы снова подписать его ключом OpenPGP,
который вы будете использовать для подписания коммитов (сделайте это перед
отправкой первого коммита). Таким образом, каждый может заметить и
убедиться, что это ваш ключ OpenPGP.
Важно: Перед тем, как вы отправите изменения впервые, сопровождающие должны:
- добавить ваш OpenPGP ключ в
keyringветку; - добавьте отпечаток вашего OpenPGP ключа в .guix-authorizations файл ветки (-ок), которые вы подпишите (commit).
- добавить ваш OpenPGP ключ в
- Обязательно прочтите остальную часть этого раздела!
Примечание: Маинтейнеры с радостью предоставят доступ к коммитам людям, которые внесли свой вклад в течение некоторого времени и имеют послужной список - не стесняйтесь и не недооценивайте свою работу!
Тем не менее, обратите внимание, что проект работает над созданием более автоматизированной системы проверки и объединения исправлений, что, как следствие, может привести к тому, что у нас будет меньше людей, имеющих доступ к главному репозиторию. Будьте на связи!
Все коммиты, которые передаются в центральный репозиторий в Саванне, должны
быть подписаны ключом OpenPGP, а открытый ключ должен быть загружен в вашу
учетную запись пользователя на Саванне и на серверы открытых ключей, такие
как keys.openpgp.org. Чтобы настроить Git для автоматической подписи
коммитов, запустите:
git config commit.gpgsign true # Substitute the fingerprint of your public PGP key. git config user.signingkey CABBA6EA1DC0FF33
To check that commits are signed with correct key, use:
make authenticate
You can prevent yourself from accidentally pushing unsigned or signed with the wrong key commits to Savannah by using the pre-push Git hook located at etc/git/pre-push:
cp etc/git/pre-push .git/hooks/pre-push
It additionally calls make check-channel-news to be sure
news.scm file is correct.
22.8.2 Commit Policy
Если вы получили доступ к коммиту, пожалуйста, следуйте приведенной ниже политике (обсуждение политики может проходить по адресу guix-devel@gnu.org).
Нетривиальные патчи всегда должны публиковаться на guix-patches@gnu.org (тривиальные патчи включают исправление опечаток и т.д.). Этот список рассылки заполняет базу данных отслеживания патчей (see Отслеживание ошибок и патчей).
Для патчей, которые просто добавляют новый пакет или внсит небольшие
изменения считается нормальным отправить коммит, если вы уверены (что
означает, что вы успешно встроили его в настройку chroot и провели разумный
аудит авторских прав и лицензий). Аналогично для обновлений пакетов, за
исключением обновлений, которые вызывают много перестроений (например,
обновление GnuTLS или GLib). У нас есть список рассылки для уведомлений о
коммитах (guix-commits@gnu.org), так что люди могут это
заметить. Перед отправкой изменений обязательно запустите git pull
--rebase.
Когда вы отправляете коммит от имени кого-то другого, добавьте строку
Signed-off-by в конце сообщения коммит лога—например, с
git am --signoff. Это улучшает отслеживание того, кто что сделал.
При добавлении новостей канала (see Writing Channel News), убедитесь, что они правильно сформированы, выполнив следующую команду прямо перед нажатием:
make check-channel-news
Для чего-либо еще, пожалуйста, отправьте сообщение на guix-patches@gnu.org и оставьте время для обзора, ничего не коммитя (see Отправка исправлений). Если вы не получили никакого ответа через две недели, и если вы уверены, что все в порядке, будь нормальным совершить коммит.
Эта последняя часть подлежит корректировке, что позволяет отдельным лицам вносить непосредственные изменения в не противоречивые изменения в тех частях, с которыми они знакомы.
22.8.3 Addressing Issues
Peer review (see Отправка исправлений) and tools such as guix
lint (see Вызов guix lint) and the test suite (see Запуск набора тестов) should catch issues before they are pushed. Yet, commits that
“break” functionality might occasionally go through. When that happens,
there are two priorities: mitigating the impact, and understanding what
happened to reduce the chance of similar incidents in the future. The
responsibility for both these things primarily lies with those involved, but
like everything this is a group effort.
Some issues can directly affect all users—for instance because they make
guix pull fail or break core functionality, because they break
major packages (at build time or run time), or because they introduce known
security vulnerabilities.
The people involved in authoring, reviewing, and pushing such commit(s) should be at the forefront to mitigate their impact in a timely fashion: by pushing a followup commit to fix it (if possible), or by reverting it to leave time to come up with a proper fix, and by communicating with other developers about the problem.
If these persons are unavailable to address the issue in time, other committers are entitled to revert the commit(s), explaining in the commit log and on the mailing list what the problem was, with the goal of leaving time to the original committer, reviewer(s), and author(s) to propose a way forward.
Once the problem has been dealt with, it is the responsibility of those involved to make sure the situation is understood. If you are working to understand what happened, focus on gathering information and avoid assigning any blame. Do ask those involved to describe what happened, do not ask them to explain the situation—this would implicitly blame them, which is unhelpful. Accountability comes from a consensus about the problem, learning from it and improving processes so that it’s less likely to reoccur.
22.8.4 Commit Revocation
Чтобы уменьшить вероятность ошибок, учетные записи контрибьюторов будут удалены из проекта Guix на Savannah, а их ключи - из .guix-authorizations после 12 месяцев бездействия; они могут попросить восстановить доступ к отправке коммитов, отправив электронное письмо мэйнтейнеров, не проходя через процесс подтверждения.
Maintainers43 may also revoke an individual’s commit rights, as a last resort, if cooperation with the rest of the community has caused too much friction—even within the bounds of the project’s code of conduct (see Содействие). They would only do so after public or private discussion with the individual and a clear notice. Examples of behavior that hinders cooperation and could lead to such a decision include:
- repeated violation of the commit policy stated above;
- repeated failure to take peer criticism into account;
- breaching trust through a series of grave incidents.
When maintainers resort to such a decision, they notify developers on guix-devel@gnu.org; inquiries may be sent to guix-maintainers@gnu.org. Depending on the situation, the individual may still be welcome to contribute.
22.8.5 Helping Out
И последнее: проект продолжает двигаться вперед, потому что коммиттеры не только вносят свои собственные потрясающие изменения, но также уделяют свое время на reviewing и продвижение изменений других людей. Как коммиттер, вы можете использовать свой опыт и передавать права, чтобы помочь и другим участникам!
Next: Writing Documentation, Previous: Доступ к коммитам, Up: Содействие [Contents][Index]
22.9 Обновление пакета Guix
Иногда желательно обновить сам пакет guix (пакет определен в
(gnu packages package-management)), например, чтобы сделать новые
функции демона доступными для использования сервисом
guix-service-type. Чтобы упростить эту задачу, можно использовать
следующую команду:
make authenticate
update-guix-package make target воспользуется последним известным
коммитом, согласно HEAD вашего Guix checkout, вычислить хэш
источников Guix, соответствующих этому коммиту и обновите commit,
revision и хэш guix.
Чтобы убедиться, что обновленные хеш-суммы пакета guix верны и что он
может быть успешно собран, следующая команда может быть запущена из каталога
Guix (from the directory of your Guix checkout):
./pre-inst-env guix build gnew --keep-failed
Чтобы предотвратить случайное обновление пакета guix к коммиту, на
которую другие не могут ссылаться, выполняется проверка того, что
использованный коммит уже был отправлен в репозиторий Guix, размещенный в
Savannah.
Эту проверку можно отключить на свой страх и риск, установив
переменну окружения GUIX_ALLOW_ME_TO_USE_PRIVATE_COMMIT. Когда эта
переменная установлена, обновленный исходник пакета также добавляется в
хранилище. Это часть процесса выпуска Guix.
Next: Тестирование Guix., Previous: Обновление пакета Guix, Up: Содействие [Contents][Index]
22.10 Writing Documentation
Guix is documented using the Texinfo system. If you are not yet familiar with it, we accept contributions for documentation in most formats. That includes plain text, Markdown, Org, etc.
Documentation contributions can be sent to guix-patches@gnu.org. Prepend ‘[DOCUMENTATION]’ to the subject.
When you need to make more than a simple addition to the documentation, we prefer that you send a proper patch as opposed to sending an email as described above. See Отправка исправлений for more information on how to send your patches.
To modify the documentation, you need to edit doc/guix.texi and doc/contributing.texi (which contains this documentation section), or doc/guix-cookbook.texi for the cookbook. If you compiled the Guix repository before, you will have many more .texi files that are translations of these documents. Do not modify them, the translation is managed through Weblate. See Тестирование Guix. for more information.
To render documentation, you must first make sure that you ran
./configure in your source tree (see Запуск Guix перед его установкой). After that you can run one of the following commands:
- ‘make doc/guix.info’ to compile the Info manual.
You can check it with
info doc/guix.info. - ‘make doc/guix.html’ to compile the HTML version. You can point your browser to the relevant file in the doc/guix.html directory.
- ‘make doc/guix-cookbook.info’ for the cookbook Info manual.
- ‘make doc/guix-cookbook.html’ for the cookbook HTML version.
Previous: Writing Documentation, Up: Содействие [Contents][Index]
22.11 Тестирование Guix.
Написание кода и пакетов - не единственный способ внести значимый вклад в Guix. Перевод на язык, на котором вы говорите—еще один пример вашего ценного вклада. Этот раздел предназначен для описания процесса перевода. Здесь представлены советы о том, как вы можете принять участие, что можно перевести, каких ошибок следует избегать и что мы можем сделать, чтобы вам помочь!
Guix - это большой проект, состоящий из нескольких компонентов, которые можно перевести. Мы координируем работу по переводу на Weblate instance, размещенном нашими друзьями в Fedora. Для отправки переводов вам потребуется учетная запись.
Некоторое программное обеспечение, упакованное в Guix, также содержит
переводы. Мы не хостим для них платформу для перевода. Если вы хотите
перевести пакет, предоставленный Guix, вам следует связаться с их
разработчиками или найти информацию на их веб-сайтах. Например, вы можете
найти домашнюю страницу пакета hello, набрав guix show
hello. В строке “домашняя страница” вы увидите
https://www.gnu.org/software/hello/ в качестве домашней страницы.
Многие пакеты GNU и не-GNU можно перевести на Translation Project. Некоторые проекты с несколькими компонентами имеют собственную платформу. Например, GNOME имеет собственную платформу Damned Lies.
Guix состоит из пяти компонентов, размещенных на Weblate.
-
guixсодержит все строки из программного обеспечения Guix ( установщик системы, менеджер пакетов и т.д.), за исключением пакетов. -
packagesсодержит синопсис (описание пакета из одного предложения ) и (более подробное) описание пакетов в Guix. -
websiteсодержит официальный сайт Guix, за исключением сообщения в блогах и мультимедийный контент. -
documentation-manualсоответствует этому руководству. -
documentation-cookbook- компонент для поваренной книги.
поколения
После создания учетной записи вы сможете выбрать компонент из the guix project и выбрать язык. Если вашего языка нет в списке, пройдите вниз и нажмите кнопку “Начать новый перевод”. Выберите из списка язык, на который вы хотите перевести, чтобы начать новый перевод.
Как и многие другие бесплатные программные пакеты, Guix использует GNU Gettext для своих переводов, с помощью которых переводимые строки извлекаются из исходного кода в так называемые PO-файлы.
Несмотря на то, что файлы PO являются текстовыми файлами, изменения следует вносить не с помощью текстового редактора, а с помощью программного обеспечения для редактирования PO. Weblate интегрирует функции редактирования PO. В качестве альтернативы переводчики могут использовать любой из различных бесплатных программных инструментов для заполнения переводов, одним из примеров которых является Poedit и (после входа в систему) загрузить измененный файл. Существует также специальный PO режим редактирования для пользователей GNU Emacs. Со временем переводчики узнают, какое программное обеспечение им нравится и какие функции им нужны.
На Weblate вы найдете различные ссылки на редактор, который покажет различные подмножества (или все) строк (-и). Посмотрите вокруг и на documentation, чтобы ознакомиться с платформой.
Компоненты перевода
В этом разделе мы даем более подробные инструкции по процессу перевода, а также подробности о том, что вам следует или не следует делать. В случае сомнений свяжитесь с нами, мы будем рады помочь!
- guix
Guix is written in the Guile programming language, and some strings contain special formatting that is interpreted by Guile. These special formatting should be highlighted by Weblate. They start with
~followed by one or more characters.When printing the string, Guile replaces the special formatting symbols with actual values. For instance, the string ‘ambiguous package specification `~a'’ would be substituted to contain said package specification instead of
~a. To properly translate this string, you must keep the formatting code in your translation, although you can place it where it makes sense in your language. For instance, the French translation says ‘spécification du paquet « ~a » ambiguë’ because the adjective needs to be placed in the end of the sentence.If there are multiple formatting symbols, make sure to respect the order. Guile does not know in which order you intended the string to be read, so it will substitute the symbols in the same order as the English sentence.
As an example, you cannot translate ‘package '~a' has been superseded by '~a'’ by ‘'~a' superseeds package '~a'’, because the meaning would be reversed. If foo is superseded by bar, the translation would read ‘'foo' superseeds package 'bar'’. To work around this problem, it is possible to use more advanced formatting to select a given piece of data, instead of following the default English order. See Formatted Output in GNU Guile Reference Manual, for more information on formatting in Guile.
- пакеты
-
Описания пакетов иногда содержат разметку Texinfo (see Краткие обзоры и описания). Разметка Texinfo выглядит как ‘@code{rm -rf}’, ‘@emph{important}’ и т.д. При переводе оставляйте разметку как есть.
The characters after “@” form the name of the markup, and the text between “{” and “}” is its content. In general, you should not translate the content of markup like
@code, as it contains literal code that do not change with language. You can translate the content of formatting markup such as@emph,@i,@itemize,@item. However, do not translate the name of the markup, or it will not be recognized. Do not translate the word after@end, it is the name of the markup that is closed at this position (e.g.@itemize ... @end itemize). - documentation-manual and documentation-cookbook
-
Первый шаг к успешному переводу руководства—найти и перевести следующие строки первыми:
-
version.texi: переведите эту строку какversion-xx.texi, гдеxx—код вашего языка (тот, который показан в URL-адресе на weblate). -
contributing.texi: переведите эту строку какcontributing.xx.texi, гдеxx- код того же языка. -
Top: Не переводите эту строку, это важно для Texinfo. Если вы переведете его, документ будет пустым (missing a Top node). Найдите его и зарегистрируйтеTopв качестве его перевода.
Перевод этих строк гарантирует, что мы сможем включить ваш перевод в репозиторий guix, не нарушая процесс make или механизм
guix pull.The manual and the cookbook both use Texinfo. As for
packages, please keep Texinfo markup as is. There are more possible markup types in the manual than in the package descriptions. In general, do not translate the content of@code,@file,@var,@value, etc. You should translate the content of formatting markup such as@emph,@i, etc.The manual contains sections that can be referred to by name by
@ref,@xrefand@pxref. We have a mechanism in place so you do not have to translate their content. If you keep the English title, we will automatically replace it with your translation of that title. This ensures that Texinfo will always be able to find the node. If you decide to change the translation of the title, the references will automatically be updated and you will not have to update them all yourself.При переводе ссылок из cookbook в мануал нужно заменить название мануала и название раздела. Например, чтобы перевести
@pxref{Defining Packages,,, guix, GNU Guix Reference Manual}, вы должны заменитьDefining Packagesзаголовком этого раздела в переведенном руководстве только если это название переведено. Если название еще не переведено на ваш язык, не переводите его здесь, иначе ссылка будет неработающей. Заменитеguixнаguix.xx, гдеxx- код вашего языка.GNU Guix Reference Manual—это текст ссылки. Вы можете перевести его как хотите. -
- официальный веб-сайт
-
Страницы веб-сайта написаны с использованием SXML, версии HTML (основного языка Интернета) с s-выражениями. У нас есть процесс извлечения переводимых строк из источника и замены сложных s-выражений на более знакомую разметку XML, где каждая разметка пронумерована. Переводчики могут произвольно изменять порядок, как в следующем примере.
#. TRANSLATORS: Defining Packages is a section name #. in the English (en) manual. #: apps/base/templates/about.scm:64 msgid "Packages are <1>defined<1.1>en</1.1><1.2>Defining-Packages.html</1.2></1> as native <2>Guile</2> modules." msgstr "Pakete werden als reine <2>Guile</2>-Module <1>definiert<1.1>de</1.1><1.2>Pakete-definieren.html</1.2></1>."
Обратите внимание, что вам нужно включить такие же разметки. Вы не можете ничего пропустить.
Если вы допустили ошибку, компонент может не работать должным образом с вашим языком или даже привести к сбою guix pull. Чтобы предотвратить это, у нас есть процесс проверки содержимого файлов перед отправкой в наш репозиторий. Если, мы не сможем обновить перевод для вашего языка в Guix, мы уведомим вас (через веб-сайт и/или по электронной почте), чтобы решить проблему.
Вне Weblate
В настоящее время некоторые части Guix не могут быть переведены на Weblate—требуется помощь!
-
guix pullновости можно перевести в news.scm, но не available from Weblate. If you want to provide a translation, you can prepare a patch as described above, or simply send us your translation with the name of the news entry you translated and your language. See Написание новостей канала, for more information about channel news. - Guix blog posts cannot currently be translated.
- The installer script (for foreign distributions) is entirely in English.
- Some of the libraries Guix uses cannot be translated or are translated outside of the Guix project. Guile itself is not internationalized.
- Other manuals linked from this manual or the cookbook might not be транзакции
Conditions for Inclusion
There are no conditions for adding new translations of the guix and
guix-packages components, other than they need at least one
translated string. New languages will be added to Guix as soon as
possible. The files may be removed if they fall out of sync and have no
more translated strings.
Given that the web site is dedicated to new users, we want its translation to be as complete as possible before we include it in the language menu. For a new language to be included, it needs to reach at least 80% completion. When a language is included, it may be removed in the future if it stays out of sync and falls below 60% completion.
The manual and cookbook are automatically added in the default compilation target. Every time we synchronize translations, developers need to recompile all the translated manuals and cookbooks. This is useless for what is essentially the English manual or cookbook. Therefore, we will only include a new language when it reaches 10% completion in the component. When a language is included, it may be removed in the future if it stays out of sync and falls below 5% completion.
Translation Infrastructure
Weblate is backed by a git repository from which it discovers new strings to translate and pushes new and updated translations. Normally, it would be enough to give it commit access to our repositories. However, we decided to use a separate repository for two reasons. First, we would have to give Weblate commit access and authorize its signing key, but we do not trust it in the same way we trust guix developers, especially since we do not manage the instance ourselves. Second, if translators mess something up, it can break the generation of the website and/or guix pull for all our users, independently of their language.
For these reasons, we use a dedicated repository to host translations, and we synchronize it with our guix and artworks repositories after checking no issue was introduced in the translation.
Developers can download the latest PO files from weblate in the Guix
repository by running the make download-po command. It will
automatically download the latest files from weblate, reformat them to a
canonical form, and check they do not contain issues. The manual needs to
be built again to check for additional issues that might crash Texinfo.
Before pushing new translation files, developers should add them to the make machinery so the translations are actually available. The process differs for the various components.
- New po files for the
guixandpackagescomponents must be registered by adding the new language to po/guix/LINGUAS or po/packages/LINGUAS. - New po files for the
documentation-manualcomponent must be registered by adding the file name toDOC_PO_FILESin po/doc/local.mk, the generated %D%/guix.xx.texi manual toinfo_TEXINFOSin doc/local.mk and the generated %D%/guix.xx.texi and %D%/contributing.xx.texi toTRANSLATED_INFOalso in doc/local.mk. - New po files for the
documentation-cookbookcomponent must be registered by adding the file name toDOC_COOKBOOK_PO_FILESin po/doc/local.mk, the generated %D%/guix-cookbook.xx.texi manual toinfo_TEXINFOSin doc/local.mk and the generated %D%/guix-cookbook.xx.texi toTRANSLATED_INFOalso in doc/local.mk. - New po files for the
websitecomponent must be added to theguix-artworkrepository, in website/po/. website/po/LINGUAS and website/po/ietf-tags.scm must be updated accordingly (see website/i18n-howto.txt for more information on the process).
Next: Лицензия свободной документации GNU, Previous: Содействие, Up: GNU Guix [Contents][Index]
23 Благодарности
Guix is based on the Nix package manager, which was designed and implemented by Eelco Dolstra, with contributions from other people (see the nix/AUTHORS file in Guix). Nix pioneered functional package management, and promoted unprecedented features, such as transactional package upgrades and rollbacks, per-user profiles, and referentially transparent build processes. Without this work, Guix would not exist.
Дистрибутивы, основанный на Nix, Nixpkgs and NixOS, также были источником вдохновения для Guix.
GNU Guix itself is a collective work with contributions from a number of people. See the AUTHORS file in Guix for more information on these fine people. The THANKS file lists people who have helped by reporting bugs, taking care of the infrastructure, providing artwork and themes, making suggestions, and more—thank you!
Next: Термины и указатели, Previous: Благодарности, Up: GNU Guix [Contents][Index]
Appendix A Лицензия свободной документации GNU
Copyright © 2000, 2001, 2002, 2007, 2008 Free Software Foundation, Inc. https://fsf.org/ Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
- PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document free in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of “copyleft”, which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
- APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The “Document”, below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as “you”. You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A “Modified Version” of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A “Secondary Section” is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document’s overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The “Invariant Sections” are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The “Cover Texts” are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A “Transparent” copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not “Transparent” is called “Opaque”.
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The “Title Page” means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, “Title Page” means the text near the most prominent appearance of the work’s title, preceding the beginning of the body of the text.
The “publisher” means any person or entity that distributes copies of the Document to the public.
A section “Entitled XYZ” means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as “Acknowledgements”, “Dedications”, “Endorsements”, or “History”.) To “Preserve the Title” of such a section when you modify the Document means that it remains a section “Entitled XYZ” according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
- VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
- COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document’s license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
- MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
- Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
- List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
- State on the Title page the name of the publisher of the Modified Version, as the publisher.
- Preserve all the copyright notices of the Document.
- Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
- Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
- Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document’s license notice.
- Include an unaltered copy of this License.
- Preserve the section Entitled “History”, Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled “History” in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
- Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the “History” section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
- For any section Entitled “Acknowledgements” or “Dedications”, Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
- Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
- Delete any section Entitled “Endorsements”. Such a section may not be included in the Modified Version.
- Do not retitle any existing section to be Entitled “Endorsements” or to conflict in title with any Invariant Section.
- Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version’s license notice. These titles must be distinct from any other section titles.
You may add a section Entitled “Endorsements”, provided it contains nothing but endorsements of your Modified Version by various parties—for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
- COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled “History” in the various original documents, forming one section Entitled “History”; likewise combine any sections Entitled “Acknowledgements”, and any sections Entitled “Dedications”. You must delete all sections Entitled “Endorsements.”
- COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
- AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an “aggregate” if the copyright resulting from the compilation is not used to limit the legal rights of the compilation’s users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document’s Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
- TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled “Acknowledgements”, “Dedications”, or “History”, the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
- TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, or distribute it is void, and will automatically terminate your rights under this License.
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, receipt of a copy of some or all of the same material does not give you any rights to use it.
- FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See https://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License “or any later version” applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation. If the Document specifies that a proxy can decide which future versions of this License can be used, that proxy’s public statement of acceptance of a version permanently authorizes you to choose that version for the Document.
- RELICENSING
“Massive Multiauthor Collaboration Site” (or “MMC Site”) means any World Wide Web server that publishes copyrightable works and also provides prominent facilities for anybody to edit those works. A public wiki that anybody can edit is an example of such a server. A “Massive Multiauthor Collaboration” (or “MMC”) contained in the site means any set of copyrightable works thus published on the MMC site.
“CC-BY-SA” means the Creative Commons Attribution-Share Alike 3.0 license published by Creative Commons Corporation, a not-for-profit corporation with a principal place of business in San Francisco, California, as well as future copyleft versions of that license published by that same organization.
“Incorporate” means to publish or republish a Document, in whole or in part, as part of another Document.
An MMC is “eligible for relicensing” if it is licensed under this License, and if all works that were first published under this License somewhere other than this MMC, and subsequently incorporated in whole or in part into the MMC, (1) had no cover texts or invariant sections, and (2) were thus incorporated prior to November 1, 2008.
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (C) year your name. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled ``GNU Free Documentation License''.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with…Texts.” line with this:
with the Invariant Sections being list their titles, with
the Front-Cover Texts being list, and with the Back-Cover Texts
being list.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Next: Программный индекс, Previous: Лицензия свободной документации GNU, Up: GNU Guix [Contents][Index]
Термины и указатели
| Jump to: | -
.
/
A B C D E F G H I J K L M N O P Q R S T U V W X Z А Б В Г Д Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Э Я |
|---|
| Jump to: | -
.
/
A B C D E F G H I J K L M N O P Q R S T U V W X Z А Б В Г Д Ж З И К Л М Н О П Р С Т У Ф Х Ц Ч Ш Э Я |
|---|
Previous: Термины и указатели, Up: GNU Guix [Contents][Index]
Программный индекс
| Jump to: | #
$
%
'
(
,
>
`
A B C D E F G H I J K L M N O P Q R S T U V W X Z П С Ц |
|---|
| Jump to: | #
$
%
'
(
,
>
`
A B C D E F G H I J K L M N O P Q R S T U V W X Z П С Ц |
|---|